对于阿里中间件技术:应用服务器篇感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解阿里中间件,并且为您提供关于10Gmysqlbinlog重放并传输到另一台服务器执行,阿里中间件大赛、2018
对于阿里中间件技术:应用服务器篇感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解阿里 中间件,并且为您提供关于10G mysql binlog重放并传输到另一台服务器执行,阿里中间件大赛、2018年阿里中间件性能挑战赛--个人总结、C++ Web应用服务器中间件 MYCP 全面介绍、ESB 系列之中间件技术入门教程的宝贵知识。
本文目录一览:- 阿里中间件技术:应用服务器篇(阿里 中间件)
- 10G mysql binlog重放并传输到另一台服务器执行,阿里中间件大赛
- 2018年阿里中间件性能挑战赛--个人总结
- C++ Web应用服务器中间件 MYCP 全面介绍
- ESB 系列之中间件技术入门教程
")
阿里中间件技术:应用服务器篇(阿里 中间件)
应用服务器——系统运行的托管员
综述
阿里巴巴集团有国内最大规模的Java系统,几万台的应用服务器规模也空前庞大,目前主要使用的应用服务器有Tomcat,JBoss和Jetty三种。阿里巴巴自从2004年开始转向Java技术平台后,先后经历了从WebLogic到Jboss和Tomcat迁移。到了2008年,随着更为轻量级的Tomcat和Jetty容器的迅速发展,越来越多的应用系统开始尝试使用Tomcat或Jetty作为底层应用服务器。2013年上半年,阿里巴巴集团中间件成立了独立的应用服务器团队,主要面向整个集团进行应用服务器相关的工作,目前在公司内部主推Tomcat服务器。
本文将从中间件团队在2013年双十一大促前针对应用服务器上进行的工作展开,重点讲解Tomcat监控诊断工具,以及Pandora隔离技术两方面内容。
6.1、Tomcat监控管理工具
Tomcat Monitor模块是一个Tomcat的监控和诊断模块,提供了一些基本的工具,可以对Tomcat的连接池、线程、内存、类加载以及JVM相关等进行监控和诊断。Tomcat Monitor的出现,解决了广大开发人员无法快速定位线上问题的尴尬问题,同时也帮助开发人员能够通过简单且统一的命令行工具来排查问题、查看程序运行时状态,而不需要使用各种包括jmap、jstat和BTrace等工具。
Tomcat Monitor模块集成于Tomcat服务器内部,能够对线程、连接池、内存和类加载等方面进行详细且实时的监控与诊断。
-
进行连接池的监控和管理
图6-1-查看Tomcat连接基本状态
图6-1-查看Tomcat连接基本状态
-
检测出当前Tomcat服务器中那些慢连接
图6-2-检测慢连接
图6-2-检测慢连接
-
线程死锁检测
图6-3-线程死锁检测
图6-3-线程死锁检测
可以看出,线程 pool-1-thread-1 和 pool-1-thread-2 发生死锁.下面两行清晰描述了死锁原因:
图6-4-死锁原因
thread-2 阻塞在被 thread-1 锁住的对象 java.lang.String@114a3c6 上,
thread-1 阻塞在被 thread-2 锁住的对象 java.lang.String@c4cee 上,
两个线程互相等待, 导致死锁.
输出结果还显示了发生死锁的线程堆栈, 以便开发人员进一步排查发生死锁的原因.
-
诊断出CPU占用高的线程
显示最近一段时间 cpu% 持续过高的线程列表, 及其最近一次统计的 cpu%.
在碰到烦人的ClassNotFoundException或是NoClassDefFoundError这些异常的时候,可以定位类的加载情况
图6-6-检测类加载情况
图6-6-检测类加载情况
针对应用服务器的监控和诊断,后续的发展规划是在目前Tomcat Monitor的基础上,集成其他诸如HouseMD这样优秀的Java监控与诊断工具,使得不同的工具能够以一种统一方式给开发人员使用。同时,还会和公司内部已经成熟的监控报警系统打通,作为数据提供方来帮助更深入的监控应用的运行情况。
6.2、隔离容器Pandora
Pandora,中文名潘多拉,是阿里中间件团队打造的,基于HSF隔离技术构建的全新一代隔离容器。从解决二方包依赖冲突出发,致力于统一管理通用的二方包,包括方便的二方包升级管理,监控和管理,建立统一的二方包扩展编程方式等。基于Pandora容器基础上进行改造而来的Pandora-Framework,是一个类OSGi的模块化运行框架。它的产出,使得OSGi这个一直以来隐藏在应用服务器和IDE工具中的神秘技术,第一次在生产环境中走入了我们的前台应用系统。2013年9月在共享业务交易流程系统上线以来,目前将逐步应用于整个阿里交易流程系统,构建了交易系统的模块化运行环境。
功能介绍
-
隔离解决三方包依赖冲突问题。针对三方包的依赖冲突问题,比如:log4j,httpclient,通常我们在开发过程中,常常碰到不同的二方包依赖了不同版本的三方包。面对这种情况,我们都是使用 Maven 工具强行将这些三方包指定到一个版本。但是,针对那些兼容性不好的三方包,这存在很大的风险。
-
提供了一套完整的二方包大规模快速升级机制提供方便的二方包大规模升级方式,用户只需要将自己的包及依赖的包按照隔离容器的规范放到隔离容器里面,就可以达到升级的效果。不需要业务方做任何事情。Pandora 容器已经和 Freedom(新版发布系统)打通,在原有应用发布流程上,添加了 Pandora 发布流程,发布的时候,可以很方便的选择需要使用那个版本的 Pandora 容器,哪个版本
-
运行期开关和 Stableswitch(Stableswitch 是中间件团队开发的,嵌入在应用内部,当服务器压力比较大时,会通过开关功能来关闭一些不太重要的功能点)开关有区别,Stableswitch 开关是业务逻辑开关,面向的对象是应用,也就是应用里面的开关。而 Pandora 容器面向的是二方包的开关。运行期可以对所有应用里面使用的二方包做调配,是一个轻量级的方案。另外,相对于订阅 diamond 数据方式实现的开关,这个粒度更细,可以针对每一个单机进行调控。
-
监控管理Pandora 容器提供方便的命令行模式,二方包提供者只需要简单的实现 Pandora 的接口,就可以实现自己的命令行命令了。比如:可以实现一个功能,在运行期查看所有使用该二方包的应用的运行期数据,方便跟踪及排查问题。
6.3、应用服务器双11准备与优化
这里重点讲解下Pandora容器针对交易系统在双十一之前进行的模块化改造。谈到模块化,相信很多读者都会在第一时间联想到OSGi。没错,OSGi(JSR 291)是Open Services Gateway initiative的缩写,为系统的模块化开发定义了一个基础规范和架构模型。迄今为止,在一些著名的IDE产品(Eclipse是第一个也是目前最成熟的OSGi实践者)和应用服务器厂商(IBM、BEA、Oracle)中都已经采用了OSGi来创建“微内核与插件”的软件架构,这样一来,这些IDE和容器就可以被更好的模块化,并且可以在运行时被动态装配。
显然,模块化和动态化,是OSGi最显著的两大特性。模块化,尤其是他的隔离机制,基本得到了大家的认可,但是针对动态化这个特性,是公认的OSGi中最具争议的地方。
-
从实用性角度来讲,目前我们其实对于热部署,动态替换等并没有太强烈的需求,开发人员通常都能够接受应用重启。
-
从复杂性角度来讲,想要做到平滑热替换,尤其是对于那些运行期有状态的bundle而言,实现动态化相当复杂。
-
从可行性角度来讲,实现动态化,需要改变开发人员和运维人员的开发与运维习惯,在推广上面临极大的挑战。
-
废弃OSGi,实现应用系统模块化
因此,Panodrar容器废弃了OSGi框架,只是引入了OSGi隔离机制的思想,自己重新实现了ClassLoader的隔离,形成了一个全新的轻量级的隔离容器。如图6-7所示。
图6-7-Pandora体系结构
图6-7-Pandora体系结构
下面重点从Bundle和类加载两方面来讲解下Pandora针对业务模块化的改造。
-
Bundle – 最小的业务单元
首先引入了Bundle的概念,使得业务系统内部逻辑能够按照bundle为单元进行组织。同时提供了Maven插件用于bundle的生成,使得一个标准的Maven Web工程能够按照子工程为单位进行无缝迁移。 -
类加载 – 隔离的核心
类加载机制是模块化隔离的核心。根据业务系统模块化的需要,我们需要设计一种既要使bundle具有严格的私密性,又要使bundle和主应用以及bundle之间具有灵活的互通性,因此重新设计了类加载机制。大体的类加载可以分为以下三步:
第一步:尝试从import中加载。
Pandora在加载bundle的类的时候,首先会判断当前类是否需要从其他bundle中获取一些共享类。
第二步:尝试从bundle自己类路径下进行类加载。
Bundle的私有性需求已经规定了,每个bundle都应该有能力和外部业务系统环境隔离开来,因此一些三方包的加载,bundle自身目录下的都会优先于业务系统环境。
第三步:尝试从外部三方容器中加载。
如果bundle声明了需要从外部三方容器的biz classloader中来加载这个类,那么会尝试从这个biz classloader中去加载。
小结
总的来说,Pandora的这次改造,伴随着阿里交易系统第三次大规模的改造升级过程,不仅满足了业务模块化改造的需求,同时也使得Pandora容器在原有解决二方包问题的基础上,新增解决业务系统模块化改造需求的能力。传统IT公司的出现与发展远早于互联网,因此,很多早期的应用服务器,包括WebLogic和WebSphere在内,更多都是为大型的单机的系统设计,尤其是从运维角度来说,都已经无法满足互联网时代大规模分布式系统。越来越多的互联网应用转移到了以Tomcat、Jboss和Jetty等为代表的轻量级的应用服务器上。然而,随着互联网应用多样性的不断发展,分布式系统规模的不断增大,尤其是移动互联网时代的到来,目前的主流服务器可能都无法满足未来日益变化需求,因此我们还正在探索下一代应用服务器的路上。
原文链接:http://jm.taobao.org/2014/03/07/3495/

10G mysql binlog重放并传输到另一台服务器执行,阿里中间件大赛
转载自:https://tianchi.aliyun.com/forum/new_articleDetail.html?spm=5176.11165310.0.0.90a57f61Sy5xTQ&raceId=231600&postsId=2035
这个冠军的方案确实赞,10G的mysql binlog重放并传输只用了2秒!
总决赛冠军队伍 作死小分队 比赛攻略
决赛答辩PPT已上传!点这里查看。
赛题分析
给定一批固定的增量数据变更信息(存放在Server端),程序需要单线程顺序读取文件,进行数据重放计算,然后将最终结果输出到给定的目标文件(在Client端)中。
增量数据的变更主要包含数据库的Insert/Update/Delete三种类型的数据。主键可能发生变更。
为了降低数据在网络中的传输开销,我们的设计是在Server端完成数据的重放计算,再将结果发送到Client端,写入结果文件中。
比赛采用16核机器运行程序。显然,我们需要设计一个并行算法,充分利用多核CPU。
解题思路
由于数据的重放计算在Server端,Client主要负责接收结果和写入文件,因此核心的算法都在Server端。本节将首先给出Server端算法的系统架构,之后具体介绍多线程算法的细节与实现。
系统架构
为了最大限度利用多核CPU的计算能力,我们将整个重放过程按照流水线的方式分成三个部分:
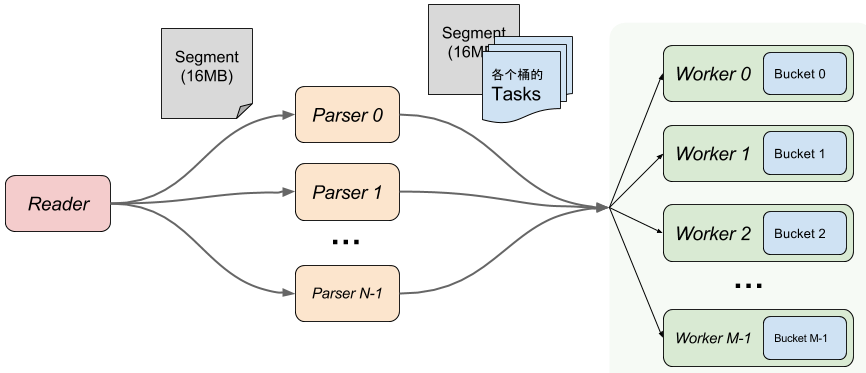
Fig.1 系统架构图
1) Reader 按照赛题要求,负责单线程读取文件。事实上,由于单线程的内存拷贝速度已经跟不上流水线速度,我们用 MappedByteBuffer 将文件按照16M的大小切分成多个的分段(Segment)映射到内存,交由Parser处理。
为防止最后的一个 Task 被从中间切成两段,Segment 除了 16MB 数据以外还多保留了 128KB 的 Margin。
2) Parser 负责从 Segment 中初步 Parse 出 Task的操作类型 (Insert/Update/Delete) 以及主键值。根据主键值,将 Task 分成 N 个 Bucket 分别交给 Worker 处理。 Parser支持多线程执行,可伸缩。
如果是 UpdatePK, 则产生 UpdatePKSrc 和 UpdatePKDst 两个 task 以及对应的 Promise 对象,按照各自的 PK , 分别发给对应的 Bucket (Promise对象及Bucket之间如何协作处理主键更新问题下文会详细说明)。
Parser 产生的 task 不是一个一个发给 Worker/Bucket 的。这样吞吐量上不去。更好的方案是按批发送。如图所示,每个 Segment 对于每个 Bucket 产生一批 tasks,这些 tasks 被附加到对应的 Segment 上,供 Worker 读取。
容易误解的一点:Parser 并不是 Parse 全部的 key-value,这不够高效。Parser 只负责第一列也就是主键,剩下的部分,通过把当前的 offset 传给 Worker,从而交给 Worker 来处理。
3) Worker 和 Bucket 是一一对应关系,Worker 根据 Parser 产生的结果,在自己的 Bucket 上依次重放 task,多线程执行,可伸缩。
当所有 Worker 处理完最后的 task 时,意味着回放完成,可以准备输出了。输出其实是 merge K 个有序 stream 的经典问题,可以用堆来高效的解决。
上述的流水线非常适合用 RingBuffer 实现,原因如下:
* RingBuffer 相比 BlockingQueue 速度更快,且本身不产生新对象,减少 GC
* RingBuffer 能够方便地为 slot 静态分配内存空间
这里我们用了 Disruptor 框架,它是一个高性能的线程间消息通讯的库,底层用 RingBuffer 实现。它不仅能取代 ArrayBlockingQueue,功能上还要丰富的多。对于本题的架构,只需要一个 RingBuffer 就能完成。
以下的示意图是和 Fig.1 是 完全等价 的:
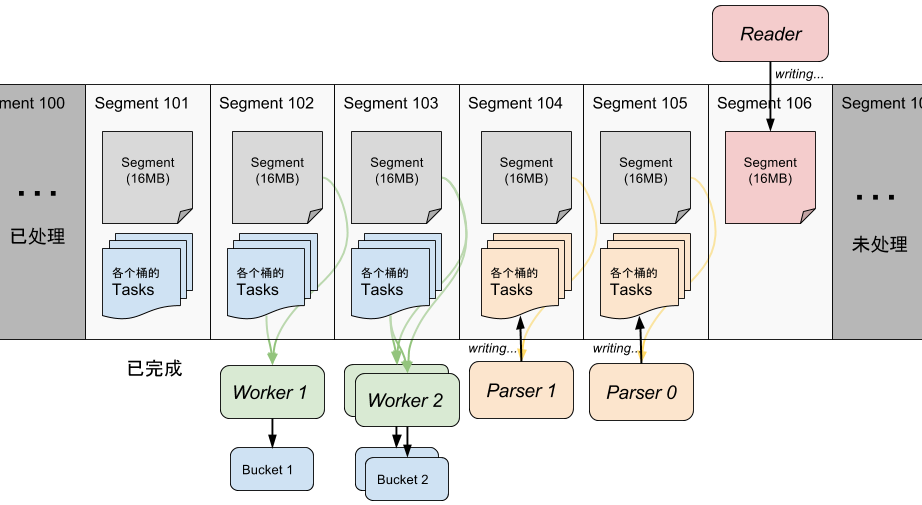
Fig.2 RingBuffer流水线效果图
图中白色部分为当前RingBuffer内的数据。图中 Worker 2 和 Worker 0 都在处理 Segment 103 中对应自己 Bucket 的 task。
并行算法
为了发挥并行性能,在每个Parser中我们将数据表按 hash(PK) 切分成 N 个 Bucket, 每个Bucket都由一个独立的Worker线程完成重放计算。
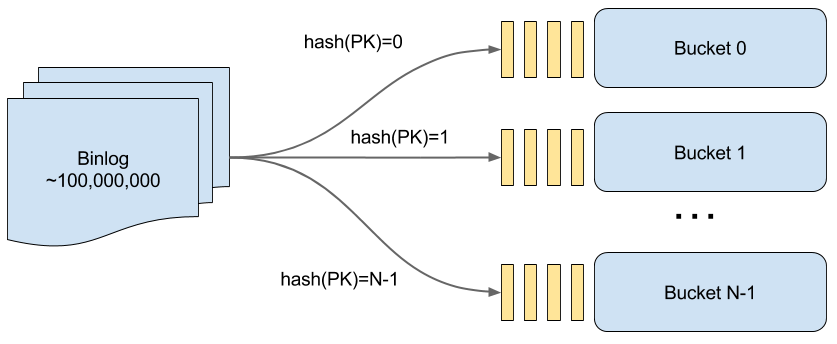
Fig.3 Hash 分桶示意图
对于Insert,Delete 和一般的 Update 事件,只要分配到对应的 Bucket 去做就可以了;唯独 UpdatePK(更新主键)事件例外,必须要 Bucket 间协作才能保证正确地把数据移动过去。
何谓“Bucket 间协作”?
一行数据被“拿走”的时候,如果还存在对该行的操作没完成,那这些修改就丢失了!所以,必须要保证一行数据被“拿走”前,所有的修改都已经 apply 到上面。反之同理,必须要“拿到”数据以后,才能把后续的操作 apply 上去。
也就是说,我们要让这两个线程在这一点(UpdatePK 这条操作)上同步才行。
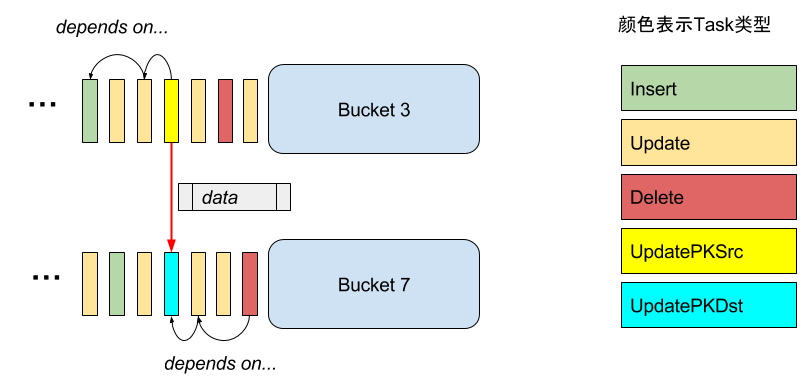
Fig.4 UpdatePK 对 Bucket 的影响,接收方要等待发送方也处理到这个task
很自然的想到,可以用 CountDownLatch 来阻塞 UpdatePK 的接收方(数据被移到此 Bucket),直到 UpdatePK 的发送方发出这行数据,它才拿到数据、接着运行。然而,当 UpdatePK 操作较为密集的时候,这个解决方案非常低效!
另一种思路是内存中维护一张主键变更表,记录主键的变更历史,将所有 UpdatePK 后新主键的所有操作都分配到旧主键所在的Bucket中。然而每个task分配时都需要从主键变更表中查找对应的Bucket,并且Parser也无法并行执行,同样十分低效。
有什么更高效的解决方法呢?
针对这一问题, 最终设计出下文的并行算法, 本算法的核心在于通过 Promise 对象,解决了 Update 主键这一难题,从而使得数据表的各个 Bucket 的线程能够无锁、高效地协作。
所谓 Promise,是借鉴 Future/Promise 异步编程范式设计的一个数据结构。实现很简单,只要封装一个 volatile 的变量,如下所示(实际代码实现更复杂,仅为示例):
final class Promise {
volatile T data;
public boolean ready() { return data != null; }
public T get() { return data; }
public void set(T data) { this.data = data; }
}Promise 在 Parser parse 到 UpdatePK 事件时产生,发送方和接收方都持有它的引用:发送方获得 UpdatePKSrc 任务,只能写入Promise(set);接收方获得 UpdatePKDst 任务,只能读取Promise(get)、以及检查数据是否 ready。通过 Promise 作为中间媒介,被操作的数据记录 data 就能从源 Bucket:hash(srcKey) 移动到目标 Bucket:hash(dstKey)。

Fig.5 Promise与发送方和接收方的关系
相比上一小节提到的 Latch 解决方案,Promise 不是阻塞接收方,而是告诉他:你要的数据还没准备好。明智的接收方将会先“搁置”这个消息,并把后来遇到的所有对这个 Key 的操作都暂存起来(放在blockedTable中,如图所示)。一旦某一时刻 Promise.ready() 为真,就可以把这个 data 放到对应的 Key 上了!暂存的操作也可以那时候再做。
如何从 blockedTable 中高效地找到 promise.ready() 的 task?事实上对于每个发送者(也就是其他bucket),我们只要检查最早阻塞的那个 task 是否 ready 就可以了。
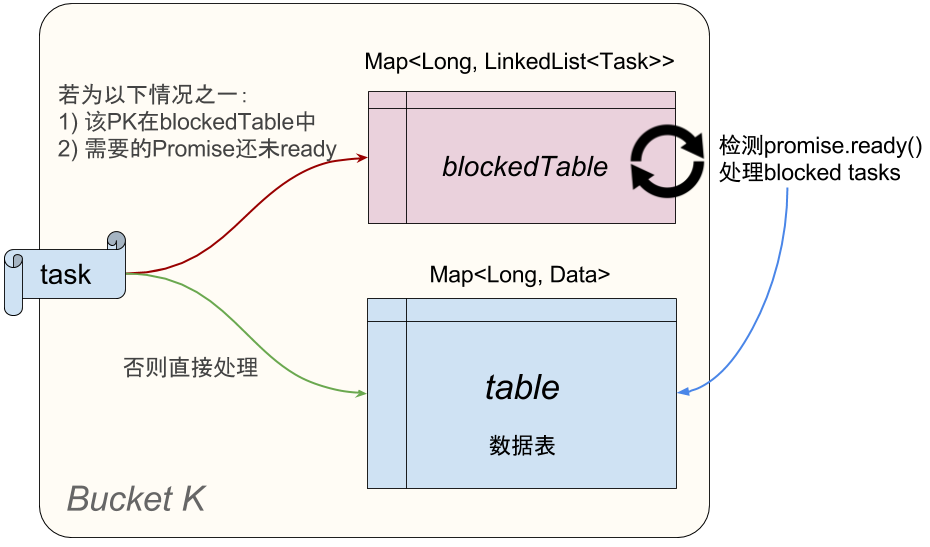
Fig.6 Task 处理效果图,暂存被阻塞的Task
对于被 block 的 PK 的操作,会以一个链表保存下来。如果不巧操作很多,这个链表就会变的很长。一个简单的改进:如果来的是一个普通 Update 操作,其实可以直接 apply 到上一个操作上的 data 上,例如 A=5 B=6 可以叠加到 PK=3 A=4上, 就变成 PK=3 A=5 B=6,从而避免把 Update 操作追加到链表上。
附上关键逻辑的伪代码:
// 当 Parse 到 UpdatePK (SET PK=dstKey WHERE PK=srcKey)
Promise promise = new Promise();
bucket[hash(srcKey)].send(new UpdatePKSrcTask(srcKey, promise, ...));
bucket[hash(dstKey)].send(new UpdatePKDstTask(dstKey, promise, ...));// 当接收方 Bucket 收到 UpdatePKDstTask task
if (!task.promise.ready()) {
LinkedList<Task> blockedTasksOnThisKey = new LinkedList<>(); // 存放阻塞的Task
blockedTasksOnThisKey.add(task);
blockedTable.put(task.key, blockedTasksOnThisKey); // 暂存,以后再处理
} else {
table.put(task.key, task.getData()); // 直接处理
}// 当发送方 Bucket 收到 UpdatePKSrcTask task
task.promise.set(table.remove(key));// 当接受方发现 blockedTable 中的 task.promise 已经 ready,则取出来处理掉
for (Task task : blockedTasks) {
applyUnblockedTask(task);
}如果阻塞的 Tasks 中包含一个 Delete,后面又来了一个 UpdatePKDst,要注意,可能会再次阻塞。
您可能担心 blockedTable 的查询增加了单个 Bucket 的计算负担。实验表明,由于各个 Bucket 的工作进度差异相差不会很大,blockedTable 的最大 size 也在 25000 以内,远小于数据表大小,所以这个代价是完全可接受的。
健壮性分析
算法的正确性是最重要的。对于任意的输入数据集,算法都能保证输出正确的结果。
可以从理论上证明:本算法可以处理以任何顺序出现的 UpdatePK / Update / Delete / Insert 操作,保证重放结束后一定查询到正确的结果。
其实很简单,算法保证了所有的操作都在它们可以执行的时候被执行,换句话说,对于一切有互相依赖关系的操作,算法不会破坏它们的先后关系。算法的并行性,是在保证了该前提的情况下做到的。
以下的例子可能帮助您获得一个感性的认识。
从一个简单的例子开始。如果遇到如下的序列
Insert PK=1 A=1 B=2 Update A=2 Where PK=1 Update PK=2 Where PK=1 Update A=3 Where PK=2假设 PK = 1 和 2 分别被 hash 到 Bucket 1 和 Bucket 2,那么会有如下情况:
Insert PK=1 A=1 B=2 // Bucket 1 新增记录 Update A=2 Where PK=1 // Bucket 1 更新记录 Update PK=2 Where PK=1 // Bucket 1 接到 UpdatePKSrc,移除并把该数据 set 到 promise // Bucket 2 如果拿到了 data,那就成功了;假设它没拿到,PK=2加入阻塞表 Update A=3 Where PK=2 // Bucket 2 把这条 Update 追加到 PK=2 的操作列表上 ... // Bucket 2 等到了 data,Update A=3 也被重放了举一个更极端的例子来说明。如果遇到这样的情况:
Insert PK=1 A=1 B=2 Update A=2 Where PK=1 Update PK=2 Where PK=1 Update PK=3 Where PK=2 // 连续的更新 Update A=3 Where PK=3算法会做如下处理:
Insert PK=1 A=1 B=2 // Bucket 1 新增记录 Update A=2 Where PK=1 // Bucket 1 更新记录 Update PK=2 Where PK=1 // Bucket 1 接到 UpdatePKSrc,移除并把该数据 set 到 promise // Bucket 2 如果拿到了 data,那就成功了;假设它没拿到,PK=2加入阻塞表 Update PK=3 Where PK=2 // Bucket 2 发现 2 这个主键在阻塞表中,所以本操作也放入阻塞表 // Bucket 3 无法拿到 data,所以把 PK=3 加入阻塞表 Update A=3 Where PK=3 // Bucket 3 把这条 Update 追加到 PK=3 的操作列表上 ... // Bucket 2 等到了 data,UpdatePK 也被重放了 ... // Bucket 3 等到了 data,Update A=3 也被重放了不妨自己尝试更多的情况。
关于表结构的健壮性, 程序会根据第一次遇到的 Insert log 来确定表结构,包括各个列的名字、类型、主键信息等。
程序严格按照比赛要求。对于数字,支持 long 型正数范围;对于文本,最长支持 65536 个字符。具体实现参考下文“数据存储”一小节。
优势与创新点
在健壮性的基础上,本算法还有以下几点优势:
* 完全无锁(Lock-free),无阻塞(Non-blocking)。在16核CPU的测试场景下,锁竞争将会导致不小的开销;而阻塞更不用说,极端情况下可能多线程会退化成协程。(例如 Latch 的解决方案,连续 UpdatePK 就会导致这样的情况)。本算法完全摈弃了wait()或lock(),而是用 代价极低 的 volatile 实现同步,这是最大的创新点。
* 可伸缩(Scalability)。除了 Reader 根据题意必须单线程,算法中没有任何不可伸缩的数据结构,理论上为线性加速比。若 CPU 核数增加,只要提升 Parser 和 Worker/Bucket 的线程数即可。(一些解决方案用到全局的 KeyMap,导致无法伸缩)
* 流处理(Streaming)。本算法是一个真正的流处理系统,在真实场景中可以不断灌入新数据并提供查询(保证最终一致性)。这也与比赛的初衷一致。
细节实现和优化
上述算法和架构给出了大致的代码编写思路。细节上,为了追求极致的性能,我们还做了各种优化。
原生类型数据结构
Java 的范型对于 primitive type 的数据是严重的浪费。比如 Map 是非常低效的,不仅浪费了大量内存,还产生了大量冗余的 boxing/unboxing。
对此,我们利用 fastutil 和 koloboke 这两个库代替 Java 标准库中范型实现的 HashMap、ArrayList 等数据结构,极大提升了性能。
数据存储
我们使用 long 数组来存储每一行数据。
由于列值的类型为 long 或者 String。对于 long 类型值, 将其解析成 long 数据存储即可。而对于String 类型的数据, 如果通过将其转换成 String 存储, 至少有两个问题:
- Encode/decode 造成无谓的性能损耗;
- 内存开销很大,对象数量非常多,对 GC 造成巨大压力。
StringStore 类能够将 String 类型的列也“变成” long,从而放到 long 数组中。利用中间结果文件,创建一个 MappedByteBuffer, 将字符串 bytes 写入 MappedByteBuffer 中,并将 position 和 length 用位运算压缩到一个 long 值中返回。根据这个值即可从 MappedByteBuffer中读取出字符串数据。
一个优化是:如果字符串的 bytes 的长度小于等于 7: 那么直接利用 long 里面的 7 个字节存储,剩下一个字节存长度,避免了磁盘写入。附上StringStore类的核心代码:
// 写入byte[]类型的数据,范围long值作为读取的索引
public long put(byte[] data, int len) {
if (len <= 7) {
long value = unsafe.getLong(data, BYTE_ARRAY_BASE_OFFSET);
return uint64(len) << 56 | (value & 0xffffffffffffffL);
} else {
long pos = doPut(data, len);
return 0xffL << 56 | pos << 32 | len;
}
}
// 根据写入时获得的long值,读取相应的数据
// 为了减少内存中的对象拷贝,直接将结果写入ByteBuffer中
public static void get(long value, ByteBuffer buf) {
int h = (int) (value >>> 56);
if (h != 0xff) {
buf.putLong(value);
buf.position(buf.position() - 8 + h);
} else {
int pos = (int) ((value & 0xffffff00000000L) >>> 32);
int len = (int) (value & 0xffffffffL);
doGet(pos, len, buf);
}
}数组池
如果为每行数据都创建一个 long[],需要频繁地 new 出大量对象。为此,我们实现了一个 LongArrayPool 来管理所有的行数据,用 offset 来查找所需的数据。
对象池 + 数组化
以 Segment 中附加的 tasks 为例,如果每次 new Task() 将产生总计近亿个 Task 对象,造成严重的 GC 压力,显然不可取。
使用对象池可以解决一半的问题。通过复用 Task,减轻了 new Task() 的压力。但这还不够好!让我们看看 Task 的结构:
final class Task {
byte opcode;
long key;
int promise;
int data;
}可见,Task 本身结构很简单,相比之下对象头的代价显得很浪费。如果不用对象,其实可以用数组来代替:
// In Segment.ensureAllocated()
opcodes = new byte[Constants.SEGMENT_MAX_EVENTS_NUM_PER_BUCKET];
offsets = new int[Constants.SEGMENT_MAX_EVENTS_NUM_PER_BUCKET];
keys = new long[Constants.SEGMENT_MAX_EVENTS_NUM_PER_BUCKET];
promises = new int[Constants.SEGMENT_MAX_EVENTS_NUM_PER_BUCKET];这样做有以下几个优点:
- 创建(分配内存)速度大大提升
- 内存占用大幅下降,省掉了对象头的开销
- 确保连续的内存分配,顺序访问更快
对于 Promise 可以做类似的优化,参考 PromisePool,这里不再赘述。
Pool 的懒初始化
做了上述数组池和对象池优化后,程序启动时间大大增加,这是因为创建 Pool 需要大量分配内存,如果发生在类加载期间,就会阻塞 main 函数的运行。
解决方案是适当延迟部分 Pool 的分配,对它们采用 lazy 的初始化策略,即第一次使用时才分配所需的内存空间。
GC 调优
JVM 会在新生代不够分配时触发 GC。考虑到我们有 1G 的新生代内存,而事实上要动态 new 的对象很少,通过调节 Pool 的初始化时机,可以做到只发生一次 ParNew GC。
对于老年代的 CMS GC 代价很大,我们在比赛中尽可能避免触发 CMS GC。而这就要求尽可能节约内存,上文提到的对象池和数组池发挥了重要作用。
线程数调优
根据比赛数据集选取最合适的 Parser 和 Worker 线程数,对榨干最后一点 CPU 性能至关重要。
为了调优, 我们启动一个 monitor 的 daemon 线程, 定时打印 Reader, Parser 和 Worker的进度,从而推测性能瓶颈在哪一方。经尝试,我们将 Parser 线程定为 6 个,Worker(即 Bucket 数)定为 10 个。
Parser 读取预测
由于题目规定为单库单表,"变更类型"(U/I/D)之前的字符(下称 header)没有必要解析,可直接跳过。不过这部分的字符长度并不确定, 因此我们尝试预测这个跳过的长度。对于每一行,如果推测正确,则可以直接跳过这部分字符;否则,从行首开始解析直到到达"变更类型", 同时更新预估的 header 长度。
由于大部分的 log 的 header 长度是一样的, 这个技巧有效地避免大量不必要字符的解析。
同理,对于 Parser 来说除了主键以外剩下 key-value 并没有用。用类似的思路也可以预测长度并直接跳过。附上 skipHeader的代码:
if (buffer[pos + opcodeOffset - 1] == (byte) '|'
&& buffer[pos + opcodeOffset + 1] == (byte) '|') {
// Fast pass
pos += opcodeOffset;
} else {
int lineBegin = pos;
pos++; // Skip '|'
pos = skipNext(buffer, pos, '|'); // Skip binlog ID
pos = skipNext(buffer, pos, '|'); // Skip timestamp
pos = skipNext(buffer, pos, '|'); // Skip database name
pos = skipNext(buffer, pos, '|'); // Skip table name
opcodeOffset = pos - lineBegin;
} 重写网络传输和 Logging
实验发现 Netty 和 logback 都比较重量级,拖慢了启动速度。因此自己实现了网络传输和 Logger,减少启动时间。
总结与感想
算法决定了性能的上限,工程实现的好坏决定了能多大程度接近这个上限。
大赛过程竞争非常激烈,可谓高手云集。通过这场比赛,我们的技术得到了锻炼,收获了解决问题的成就感。同时也真诚感谢大赛的主办方,让我们有机会在赛场上证明自己的能力。

2018年阿里中间件性能挑战赛--个人总结
1.比赛结果
2.比赛整体感觉
初赛的题目是写一个代理实现高性能的协议解析和转发,复赛是是实现一个单机的100g的mq存储。
题目都和io有关,自己实际在比赛过程中,实现了一套能跑的方案后,后续优化的效果不明显,例如
初赛第一版6140qps,后续只优化到6470qps。
复赛第一版67w,后续只优化到115w。
在初期我的排名还能进前20,后面就迅速被n多人超越。
其实关键效果的提升,都是以好的方案为基础,调参和细节优化,提升的并不明显,所以当落后第1梯队的时候,肯定是方案有瑕疵,所以竞赛的关键
是方案优化,针对痛点的优化,不要过于依赖随机的测试。要学会在比赛中学习,学习用到比赛,提高成绩。
第1版方案很重要,其实如果一开始差距太大,对于后期自己能不能赶上,是有自我效能的降低。
对于自己的技术水平过于自信,对于别人的水平预判过低,思想上就没有重视对手。
3.比赛欠缺的东西
关键有效方案的优化,拿复赛举例子,如果把写缓冲和lru做了的话,预期应该能上180w。
当时没做,是用mmap方式发现加大buffer对于效果无明显提升,事后想想其实是mmap导致,如果用pwrite等系统api追加
效果应该会有提升,所以好的方案应该是符合常理,如果不符合常理应该是自己用的有问题。
把性能追求极致,之前工作总感觉用性价比最高的方式实现是有好处的,其实这样不适合比赛,因为比赛是以成绩为导向,只有把
性能追求到极致,才能竞争过别人,这个追求极致不是把n多细节优化到极致,而是大的方案基本对路,关键点做到位,其实进20不难。
不能因为方案复杂就放弃,可以考虑用开源等等。
珍惜好时间,尤其是复赛的时间,非常宝贵。
4.比赛好的方面
工程实现方面,复赛基本实现了bugfree,发现小问题,也基本能很快解决
把一个不太会的东西,通过测试,上线,整个流程还是很快,比如mmap的应用
复赛熬了3天到晚上2点,战斗意志很高。

C++ Web应用服务器中间件 MYCP 全面介绍
MYCP是一种利用C++编写,来简化企业解决方案的开发、部署和管理相关的复杂问题的体系结构。MYCP技术的基础就是核心C++语言平台,所以MYCP不仅拥有,例如“编写一次、随处运行”、“性能稳定”的特性,方便存取数据库的CDBC API、C++ APP技术,以及能够在Internet应用中保护数据的安全模式等等,同时还提供了对RCA(Remote C++ APP)、C++ Servlets API、CSP(C++ Server Pages)以及XML技术的全面支持。其最终目的就是成为一个能够使企业开发者加速产品开发,大幅缩短投放市场时间的体系结构。
MYCP体系结构提供中间层集成框架用来满足低费用(甚至免费)而又需要高可用性、高可靠性以及可扩展性的应用的需求。通过提供统一的开发平台,MYCP降低了开发多层应用的费用和复杂性,同时提供对现有应用程序集成强有力支持,完全支持远程连接,增强了安全机制,提高了性能。
2、MYCP 的优势MYCP为搭建具有可伸缩性、灵活性、易维护性的商务系统提供了良好的机制:
- 保留现存的IT资产:由于企业必须适应新的商业需求,利用已有的企业信息系统方面的投资,一个以渐进的方式建立在已有系统之上的服务器端平台机制是公司所需求的。基于MYCP平台的产品几乎能够在任何操作系统和硬件配置上运行,现有的操作系统和硬件也能被保留使用,MYCP架构可以充分利用用户原有的投资,节省投资。
- 高效的开发: MYCP提供丰富标准API接口,实现一些通用的、很繁琐的服务端任务,同时通过灵活可配置方式,方便组件化开发。这样开发人员可以集中精力在如何创建商业逻辑上,相应地缩短了开发时间。
- 支持异构环境: 通过标准C++编译器,MYCP能够开发部署在异构环境中的可移植程序。基于MYCP的应用程序不依赖任何特定操作系统、中间件、硬件。因此设计合理的MYCP程序只需开发一次就可部署到各种环境。
- 可伸缩性: 基于MYCP平台的应用程序可被部署到各种操作系统上,例如可被部署到高端的UNIX与大型机系统,这种系统单机可支持64与256个处理器;同时通过合理设计MYCP应用程序,支持应用开发商提供更为广泛的负载平衡策略,实现可高度伸缩的系统,满足未来商业应用的需要。
- 稳定的可用性: 一个服务器端平台必须能全天候运转以满足公司客户、合作伙伴的需要。MYCP采用专门设计的通讯能力、业务逻辑流转机制等核心技术,使MYCP平台达到最大限度的稳定性;MYCP部署到可靠的操作环境中,他们支持长期的可用性,最健壮的操作系统可达到99.999%的可用性。
MYCP使用多层的分布式应用模型,应用逻辑按功能划分为组件,各个应用组件根据他们所在的层分布在不同的机器上。MYCP的多层企业级应用模型把传统两层化模型中的不同层面切分成许多层,一个多层化应用能够为不同的每种服务提供一个独立的层,以下是 MYCP 典型的四层结构:
- 运行在客户端机器上的客户层组件
- 运行在MYCP服务器上的Web层组件
- 运行在MYCP服务器上的业务逻辑层组件
- 运行在EIS服务器上的企业信息系统层软件

3.1. MYCP应用组件
MYCP应用组件包括客户端应用组件和服务端应用组件;MYCP客户端应用组件是指能够访问MYCP服务器,具有独立功能的软件单元。
MYCP定义了以下的应用组件:
- 应用客户端程序客户层组件。
- C++ Servlet和C++ Server Pages(CSP)是web层组件。
- C++ APP和RCA是业务层组件。
- 其他所有支持TCP+SOTP协议的客户应用程序组件。
所有的MYCP组件通过配置,或者编程方式,方便与其他组件交互。
3.2. 客户层组件MYCP客户层组件应用程序可以是基于web方式的,也可以是基于传统方式的。
MYCP基于传统方式的,支持目前所有编程语言或工具(不单单C/C++语言),使用TCP+SOTP协议(一种简单对象传输协议)访问,实现更多异构环境客户端应用。
3.3. web组件MYCP web层组件可以是CSP 页面或者C++ Servlet。
如下图所示,web层可能包含某些 C++ APP对象来处理用户输入,并把业务数据发送给运行在业务层上的RCA(或者本地其他C++ APP)进行处理。

3.4. 业务层组件
业务层代码的逻辑用来实现各种业务需要,由运行在业务层上的RCA 进行处理. 下图表明了一个业务层组件的应用模型:

RCA是一种远程的C++ APP应用组件。
3.5. 企业信息系统层企业信息系统层处理企业信息系统软件,包括企业基础建设系统(例如企业资源计划ERP、客户关系管理CRM等),大型机事务处理,数据库系统,和其它信息系统等。
4、MYCP 的结构MYCP这种基于组件,具有平台无关性的结构,使得MYCP程序的编写十分简单,各种业务逻辑被封装成可复用的组件,并且MYCP服务器为所有的组件类型提供后台容器服务。
利用MYCP可以让你只专注于业务开发,提高工作效率。
4.1. 容器和服务MYCP实现标准CSP容器,同时内置支持,包括安全,组件调度管理,远程访问等服务,以下列出最重要的几种服务:
- MYCP安全(Security)模型可以让你灵活配置MYCP应用组件安全,支持组件级别、接口级别的授权模式;开放所有或者只有被授权的用户才能访问系统资源;同时支持可配置帐号信息,静态验证、动态验证和自动验证等。
- MYCP远程连接(Remote Client Connectivity)模型管理客户端和RCA间的低层交互。当一个RCA组件被MYCP服务器创建,远程调用跟本地调用使用同样的接口。
- 生存周期管理(Life Cycle Management)模型管理所有MYCP应用组件的的创建和移除。
- 数据库连接池(Database Connection Pooling)模型是一个有价值的资源。MYCP容器通过管理数据库连接池来减少数据库连接资源,提高访问的效率,同时使开发者方便在业务开发中使用。
MYCP平台由一整套服务(Services)、应用程序接口(APIs)和协议构成,它对开发基于Web的多层应用提供了功能支持,下面对MYCP中的主要几种技术规范进行简单的描述:
- CDBC(C++ Database Connectivity):CDBC是用于执行SQL语句的C++应用程序接口,由一组C++语言编写的类和接口组成;CDBC是一种规范,利用CDBC可以让开发人员或者数据库厂商为C++程序员提供标准的数据库访问类的接口,为访问不同的数据库提供了一种统一的途径。
- CSP(C++ Server Pages):CSP是一套基于 XML格式标签的页面开发技术,CSP页面由HTML代码和嵌入其中的CSP标签代码所组成。服务器在页面被客户端所请求以后,对请求进行处理,然后生成HTML页面返回给客户端的浏览器。
- C++ Servlet:Servlet扩展了web服务器的功能,Servlet不单实现CSP类似功能,还可以实现更多业务逻辑处理。
- C++ APP:MYCP最大的优势,是能够真正跟C++语言平台集成应用,利用编写C++ APP应用组件,可以利用C++语言的所有优势,集成所有C++应用产品和技术。
- RCA(Remote C++ APP):RCA是一种远程的C++ APP应用组件,类似J2EE的EJB;MYCP利用RCA能够实现大型企业分布式应用系统。
- XML(Extensible Markup Language): XML是一种可以用来定义其它标记语言的语言。它被用来在不同的商务过程中共享数据。XML同样具有平台独立性。通过将MYCP和XML的组合,您可以得到一个完美的具有平台独立性的解决方案。

ESB 系列之中间件技术入门教程
文章目录
## 前言 ##
本博客介绍 Java 中间件的一些知识,仅仅是一些知识储备。
## 中间件 ##
### 中间件概念 ###
中间件:中间件是一种介于操作系统和应用软件之间的一种软件,它使用系统软件所提供的基础服务(功能),衔接网络上应用系统的各个部分或不同的应用,能够达到资源共享、功能共享的目的。
若是以新一代的中间件系列产品来组合应用,同时配合以可复用的商务对象构件,则应用开发费用可节省至 80%。
### 中间件分类 ###
- 消息中间件
消息中间件适用与进行网络通讯的系统,建立网络通讯的通道,进行数据和文件的传送
产品:ActiveMQ、ZeroMQ、RabbitMQ、IBM webSphere MQ… - 交易中间件
交易中间件管理分布与不同操作系统的数据,实现数据一致性,保证系统的负载均衡
产品:IBM CICS,Bea tuxedo… - 对象中间件
保证不同厂家的软件之间的交互访问
产品:IBM componentbroker, iona orbix,borland visibroker… - 应用服务器
用来构造 internet/intranet 应用和其它分布式构件应用
产品:IBM Websphere,Bea weblogic… - 安全中间件
以公钥基础设施(pki)为核心的、建立在一系列相关国际安全标准之上的一个开放式应用开发平台
产品:entrust entrust… - 应用集成服务器
把工作流和应用开发技术如消息及分布式构件结合在一起,使处理能方便自动地和构件、script 应用、工作流行为结合在一起,同时集成文档和电子邮件
产品:lss flowman、ibm flowmark、vitria businessagiliti
##ESB##
ESB,即企业服务总线
松散耦合一直是企业软件开发中的一个很重要的内容,而面向服务的 SOA 编程在随着 ESB 的应用得到了进一步的发展,ESB 就像服务提供者和服务使用者之间的中间层
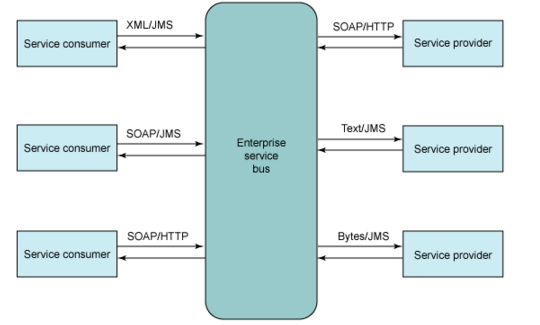
##JMS##
JMS,即 Java Message Service
ESB 仅仅是作为一个中间层,所以应用程序之间的消息通讯必须借助 JMS,即通过 JMS 从服务使用者接收消息,并将其转发到相应的服务提供者。
而且,JMS 还定义了可发送的若干不同类型的消息。例如,Text 消息包含消息的字符串表示形式;Object 消息包含序列化的 Java 对象;Map 消息包含键 / 值对的映射,等等。
附录:
MQ DEMO:
package com.wms.batchMsg;
import java.io.File;
import java.io.IOException;
import java.sql.Timestamp;
import java.text.ParseException;
import java.util.Date;
import org.apache.log4j.Logger;
import com.ibm.mq.MQEnvironment;
import com.ibm.mq.MQException;
import com.ibm.mq.MQGetMessageOptions;
import com.ibm.mq.MQMessage;
import com.ibm.mq.MQPutMessageOptions;
import com.ibm.mq.MQQueue;
import com.ibm.mq.MQQueueManager;
import com.ibm.mq.constants.MQConstants;
public class MQUtil {
private static String qmName;
private static MQQueueManager qMgr;
private static Logger logger = Logger.getLogger(MQUtil.class);
static{
try{
MQEnvironment.hostname=ConfigManager.getValue("MQ_MQHost");
MQEnvironment.channel=ConfigManager.getValue("MQ_Server_Channel");
MQEnvironment.CCSID=Integer.parseInt(ConfigManager.getValue("MQ_CCSID"));
MQEnvironment.port=Integer.parseInt(ConfigManager.getValue("MQ_port"));
//MQEnvironment.userID = ConfigManager.getValue("MQ_UserId");
//MQEnvironment.password = ConfigManager.getValue("MQ_pass");
qmName = ConfigManager.getValue("MQ_QMname");
MQEnvironment.properties.put(MQConstants.TRANSPORT_PROPERTY,MQConstants.TRANSPORT_MQSERIES_CLIENT);
qMgr = new MQQueueManager(qmName);
}catch(MQException e){
e.printStackTrace();
logger.info("qManager failed: Completion code " + e.completionCode + " Reason Code is "
+ e.reasonCode);
}
}
public static MQQueue getSendQueue(String queueName) {
MQQueue sQueue;
int openSendOptions = MQConstants.MQOO_OUTPUT | MQConstants.MQOO_FAIL_IF_QUIESCING
| MQConstants.MQOO_SET_IDENTITY_CONTEXT;
try {
sQueue = qMgr.accessQueue(queueName, openSendOptions);
} catch (MQException e) {
e.printStackTrace();
return null;
}
return sQueue;
}
public static MQQueue getReceiveQueue(String revQueueName){
MQQueue rQueue ;
int openRcvOptions = MQConstants.MQOO_INPUT_AS_Q_DEF | MQConstants.MQOO_FAIL_IF_QUIESCING;
try{
rQueue = qMgr.accessQueue(revQueueName, openRcvOptions);
}catch(MQException e){
e.printStackTrace();
return null;
}
return rQueue;
}
public static void sendMsg(MQMsgEntity entity,String queueName) {
MQQueue sendQ = null;
try {
MQMessage qMsg = new MQMessage();
byte[] qByte = entity.getMsgStr().getBytes("UTF-8");
// String message = entity.getMsgStr();
qMsg.messageId = MQConstants.MQMI_NONE;
//TODO send and receive
if(entity.getCorrelId()!=null){
qMsg.correlationId = entity.getCorrelId();
}
qMsg.format = MQConstants.MQFMT_STRING;
qMsg.write(qByte);
MQPutMessageOptions pmo = new MQPutMessageOptions();
pmo.options = pmo.options + MQConstants.MQPMO_NEW_MSG_ID;
pmo.options = pmo.options + MQConstants.MQPMO_NO_SYNCPOINT;
pmo.options = pmo.options + MQConstants.MQPMO_SET_IDENTITY_CONTEXT;
sendQ = getSendQueue(queueName);
sendQ.put(qMsg, pmo);
qMgr.commit();
//logger.info("The send message is: " +new String(qByte,"UTF-8"));
} catch (MQException e) {
logger.info("A WebSphere MQ error occurred : Completion code "
+ e.completionCode + " Reason Code is "
+ e.reasonCode);
} catch (java.io.IOException e) {
logger.info("An error occurred whilst to the message buffer "
+ e);
}finally{
try{
if(sendQ!=null){
sendQ.close();
}
}catch(MQException e){
// TODO Auto-generated catch block
e.printStackTrace();
logger.info("Error for MQ connection:"+e.getMessage());
}
}
}
// public static void messageHandlerByQueueName(MQMsgEntity entity,String queueName) {
// try {
// if(queueName.equalsIgnoreCase("sap_OrdersQueue")){
// ECOrder order = new ECOrder();
// order.CallOrderCURFC(entity, "ZECI001");
// }else if(queueName.equalsIgnoreCase("sap_OrderPendReqQueue")){
// ECOrderPending orderPending = new ECOrderPending();
// orderPending.CallOrderPendRFC(entity, "ZECI005");
// }else if(queueName.equalsIgnoreCase("sap_OrderPendCancelQueue")){
// ECOrderPending orderPending = new ECOrderPending();
// orderPending.CallCancelOrderPendRFC(entity, "ZECI006");
// }else if(queueName.equalsIgnoreCase("sap_ECReturnsQueue")){
// ECOrder order = new ECOrder();
// order.callOrderCancelRFC(entity, "ZECI001");
// }else if(queueName.equalsIgnoreCase("sap_downpaymentQueue")){
// ECDownPayment downPayment = new ECDownPayment();
// downPayment.callDownPaymentRFC(entity, "ZECI007");
// }else if(queueName.equalsIgnoreCase("sap_360LBPQueue")){
// EC360LBP lbp = new EC360LBP();
// lbp.generateHtmlFromQueue(entity.getMsgStr());
// }
// } catch (Exception e) {
// e.printStackTrace();
// logger.error(e.getMessage());
// }
//
// }
public MQQueueManager generateNewMQQM(){
MQQueueManager qMgr = null;
try{
MQEnvironment.hostname=ConfigManager.getValue("MQ_MQHost");
MQEnvironment.channel=ConfigManager.getValue("MQ_Server_Channel");
MQEnvironment.CCSID=Integer.parseInt(ConfigManager.getValue("MQ_CCSID"));
MQEnvironment.port=Integer.parseInt(ConfigManager.getValue("MQ_port"));
String qmName = ConfigManager.getValue("MQ_QMname");
MQEnvironment.properties.put(MQConstants.TRANSPORT_PROPERTY,MQConstants.TRANSPORT_MQSERIES_CLIENT);
qMgr = new MQQueueManager(qmName);
}catch(MQException e){
e.printStackTrace();
logger.info("qManager failed: Completion code " + e.completionCode + " Reason Code is "
+ e.reasonCode);
}
return qMgr;
}
public void MultiThreadGetMqMessage(MQQueueManager qMgr,String queueName){
MQQueue revQ = null;
String mqString = null;
MQMsgEntity entity = new MQMsgEntity();
int openRcvOptions = MQConstants.MQOO_INPUT_AS_Q_DEF | MQConstants.MQOO_FAIL_IF_QUIESCING;
try {
MQMessage retrievedMessage = new MQMessage();
MQGetMessageOptions gmo = new MQGetMessageOptions();
gmo.options += MQConstants.MQPMO_NO_SYNCPOINT;//
gmo.options = gmo.options + MQConstants.MQGMO_WAIT;//
gmo.options = gmo.options + MQConstants.MQGMO_FAIL_IF_QUIESCING;//
gmo.waitInterval = MQConstants.MQWI_UNLIMITED;//
gmo.matchOptions = MQConstants.MQMO_MATCH_MSG_ID;
retrievedMessage.format=MQConstants.MQFMT_STRING;
// MQC.MQWI_UNLIMITED;
revQ = qMgr.accessQueue(queueName, openRcvOptions);
revQ.get(retrievedMessage, gmo);
qMgr.commit();
int length = retrievedMessage.getDataLength();
if(length >0){
long startTime = System.currentTimeMillis();
byte[] msg = new byte[length];
retrievedMessage.readFully(msg);
mqString = new String(msg, "UTF-8");
if(queueName.equalsIgnoreCase("sap_360LBPQueue")){
mqString = mqString.replace("''", "\"");
}
long timeuse = System.currentTimeMillis() - startTime;
Date currentDate = new Date();
Timestamp receiveTimestamp = new Timestamp(currentDate.getTime());
logger.info("=========mqString from "+queueName+" :"+mqString);
DBUtil.insertIntoMQLog("Receive",queueName, mqString, timeuse, "success", "", null, receiveTimestamp);
entity.setMsgStr(mqString);
//messageHandlerByQueueName(entity,queueName);
}else{
logger.info("Error MQ string Sent!");
}
}
catch (MQException e) {
e.printStackTrace();
if (e.reasonCode != 2033)
{
logger.info(e.getMessage());
logger.info("Completion code "
+ e.completionCode + " Reason Code is " + e.reasonCode);
}
} catch (IOException e) {
logger.info("IO error:" + e.getMessage());
} finally{
try{
if(revQ!=null){
revQ.close();
}
}catch(MQException mqEx){
int rc = mqEx.reasonCode;
if (rc != MQException.MQRC_NO_MSG_AVAILABLE)
{
logger.info(" PUT Message failed with rc = "
+ rc);
}
}
}
}
public static String getMQMessage(String queueName) throws ParseException {
MQQueue revQ = null;
String mqString = null;
MQMsgEntity entity = new MQMsgEntity();
try {
MQMessage retrievedMessage = new MQMessage();
MQGetMessageOptions gmo = new MQGetMessageOptions();
gmo.options += MQConstants.MQPMO_NO_SYNCPOINT;//
gmo.options = gmo.options + MQConstants.MQGMO_WAIT;//
gmo.options = gmo.options + MQConstants.MQGMO_FAIL_IF_QUIESCING;//
gmo.waitInterval = MQConstants.MQWI_UNLIMITED;//
gmo.matchOptions = MQConstants.MQMO_MATCH_MSG_ID;
retrievedMessage.format=MQConstants.MQFMT_STRING;
// MQC.MQWI_UNLIMITED;
revQ = getReceiveQueue(queueName);
revQ.get(retrievedMessage, gmo);
qMgr.commit();
int length = retrievedMessage.getDataLength();
if(length >0){
byte[] msg = new byte[length];
retrievedMessage.readFully(msg);
mqString = new String(msg, "UTF-8");
logger.info("=========getMQMessage===mqString from "+queueName+" :"+mqString);
entity.setMsgStr(mqString);
//messageHandlerByQueueName(entity,queueName);
}else{
logger.info("Error MQ string Sent!");
}
}
catch (MQException e) {
e.printStackTrace();
if (e.reasonCode != 2033)
{
e.printStackTrace();
logger.info("Completion code "
+ e.completionCode + " Reason Code is " + e.reasonCode);
}
} catch (java.io.IOException e) {
System.out.println("error" + e.getMessage());
}finally{
try{
if(revQ!=null){
revQ.close();
}
}catch(MQException mqEx){
int rc = mqEx.reasonCode;
if (rc != MQException.MQRC_NO_MSG_AVAILABLE)
{
System.out.println(" PUT Message failed with rc = "
+ rc);
}
}
}
return mqString;
}
public void revAndSend(MQMsgEntity entity,String queueName){
//
sendMsg(entity,queueName);
}
public void subscribeMessage() throws ParseException{
while(true){
logger.info("waiting to get message.....");
getMQMessage("sap_OrdersQueue");
}
}
public void subscribeOrderPendMessage() throws ParseException{
while(true){
logger.info("waiting to get message.....");
getMQMessage("sap_ECReturnsQueue");
}
}
public static void main(String[] args) throws IOException, ParseException {
MQMsgEntity entity = new MQMsgEntity();
String sendMsg = XMLBeanUtil.readFileToString(new File("D://batchXML0108.txt"));
int intPktCtlNbr = 1;
String StrPkt = null;
String newPktCtlNbr =null;
for (int i = 0; i < 20000; i++) {
newPktCtlNbr = String.format("%09d", intPktCtlNbr+i);
StrPkt="<PktCtlNbr>"+"V"+newPktCtlNbr+"</PktCtlNbr>";
String changeSendMsg = sendMsg.replaceAll("<PktCtlNbr>6001996171</PktCtlNbr>", StrPkt);
System.out.println(StrPkt);
entity.setMsgStr(changeSendMsg);
sendMsg(entity,"wms_SAPOrderQueue");
}
// MQUtil util = new MQUtil();
// util.subscribeMessage();
// util.subscribeOrderPendMessage();
// util.messageHandlerByQueueName(entity, "sap_360LBPQueue");
// getMQMessage("sap_OrderPendCancelQueue");
// System.out.println("rev message is:"+message);
}
}
本文分享 CSDN - smileNicky。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
关于阿里中间件技术:应用服务器篇和阿里 中间件的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于10G mysql binlog重放并传输到另一台服务器执行,阿里中间件大赛、2018年阿里中间件性能挑战赛--个人总结、C++ Web应用服务器中间件 MYCP 全面介绍、ESB 系列之中间件技术入门教程的相关信息,请在本站寻找。
本文标签:




