在本文中,我们将详细介绍在休眠搜索AnalyzerDiscriminator中使用现有分析器的各个方面,并为您提供关于在休眠吧的相关解答,同时,我们也将为您带来关于Elasticsearch之分析(a
在本文中,我们将详细介绍在休眠搜索AnalyzerDiscriminator中使用现有分析器的各个方面,并为您提供关于在休眠吧的相关解答,同时,我们也将为您带来关于Elasticsearch之分析(analysis)和分析器(analyzer)、Hibernate"discriminator-value"用法、iphone – XCode Static Analyzer:由于解析错误,Analyzer跳过了这个文件、Linear discriminant analysis (LDA)学习笔记的有用知识。
本文目录一览:- 在休眠搜索AnalyzerDiscriminator中使用现有分析器(在休眠吧)
- Elasticsearch之分析(analysis)和分析器(analyzer)
- Hibernate"discriminator-value"用法
- iphone – XCode Static Analyzer:由于解析错误,Analyzer跳过了这个文件
- Linear discriminant analysis (LDA)学习笔记
")
在休眠搜索AnalyzerDiscriminator中使用现有分析器(在休眠吧)
@Entity@Indexed@AnalyzerDefs({ @AnalyzerDef(name = "en", tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = { @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = EnglishPorterFilterFactory.class ) }), @AnalyzerDef(name = "de", tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = { @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = GermanStemFilterFactory.class) })})public class BlogEntry { @Id @GeneratedValue @DocumentId private Integer id; @Field @AnalyzerDiscriminator(impl = LanguageDiscriminator.class) private String language; @Field private String text; private Set<BlogEntry> references; // standard getter/setter // ...}public class LanguageDiscriminator implements Discriminator { public String getAnalyzerDefinitionName(Object value, Object entity, String field) { if ( value == null || !( entity instanceof Article ) ) { return null; } return (String) value; }}从参考文档,
我怎样可以使用现有的分析一样org.apache.lucene.analysis.cjk.CJKAnalyzer,沿en和de我所动态定义的呢?我只能在此处返回分析器的名称,返回时我CJKAnalyzer未定义分析器。
如何将现有分析仪添加到分析仪定义中?
答案1
小编典典这是一个很好的问题,我很惊讶以前没有人问过这个问题。
答案是不可能的。
我已经在项目中打开了功能请求,以对此进行改进:
- https://hibernate.atlassian.net/browse/HSEARCH-2518
和分析器(analyzer)")
Elasticsearch之分析(analysis)和分析器(analyzer)
分析(analysis)是这样一个过程:
- 首先,表征化一个文本块为适用于倒排索引单独的词(term)。
- 然后标准化这些词为标准形式,提高他们的“可搜索性”或“查全率” 。
这个工作是分析器(analyzer)完成的。一个分析器(analyzer)只是一个包装用于将三个功能放到一个包里:
字符过滤器
首先字符串经过过滤器(character filter),他们的工作是在表征化(注:这个词叫做断词更适合)前处理字符串。字符过滤器能够去除HTML标记,或者转化为“&”为“and”。
分词器
下一步,分词器(tokenizer)被表征化(断词)为独立的词。一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开(注:这个在中文中不适用)。
表征过滤
最后,每个词都通过所有表征过滤(token filters),他可以修改词(例如将“Quick”转为小写),去掉词(例如停用词像“a”、“and”、“the”等等),或者增加词(例如同义词像“a”、“and”、“the”等等)或者增加词(例如同义词像“jump”和“leap”)。
內建的分析器
不过,Elasticsearch还附带了一些预装的分析器,你可以直接使用它们。下面我们列出了最重要的几个分析器,来演示这个字符串分词后的表现差异:

标准分析器
标准分析器是Elasticsearch默认使用的分析器。对于文本分析,它对于任何语言都是最佳选择(注:就是没啥特殊需求,对于任何一个国家的语言,这个分析器就够用了)。它根据Unicode Consortium的定义的单词边界(word boundaries)来切分文本,然后去掉大部分标点符号。最后。把所有词转为小写。产生的结果为:
简单分析器
简单分析器将非单个字母的文本切分,然后把每个词转化为小写。产生的结果为:
空格分析器
空格分析器依据空格切分文本。他不转换小写。产生结果为:
语言分析器
特定语言分析器适用于很多语言。他们能够考虑到特定语言的特性。例如English分析器自带一套语言停用词库——像and或the这些与语义无关的通用词。这些词被移除后,因为语法规则的存在,英语单词的主体含义依旧能被理解(注:stem English word,大概意思应该是将英语语句比作一株植物,去掉无用的枝叶,主干依旧存在,停用词好比枝叶,存在与否并不影响对这句话的理解。)。
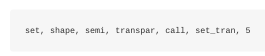
English分析器将会产生以下结果:
注意“transparent”、“calling”和“set_trans”是如何转为词干的。



当分析器被使用
当我们索引(index)一个文档,全文字段会被分析为单独的词来创建倒排索引。不过,当我们在全文字段搜索(search)时,我们要让查询字符串经过同样的分析流程处理,以确保这些词在索引中存在。
- 当你查询全文(full text)字段,查询将使用相同的分析器来分析查询字符串,以产生正确的词列表。
- 当你查询一个确切值(exact value)字段,查询将不分析查询字符串,但是你可以自己指定。
前一个例子会产生那种结果:
- date字段包含一个确切值:单独的一个词“2014-09-15” 。
- _all字段是一个全文字段,所以分析过程转为三个词:“2014”、“09”和“15”。
当我们在_all字段查询2014,它一个匹配到12条推文,因为这些推文都包含词2014:
GET /_search?q=2014 # 12 results
当我们在_all字段中查询2014-09-15,首先分析查询字符串,产生匹配任意词2014、09或15的查询语句,它依旧匹配12个推文,因为他们都包含词2014。
GET /_search?q=2014-09-15 # 12 results
当我们在date字段中查询2014-09-15,它查询一个确切的日期,然后只找到一条推文:
GET /_search?q=date:2014-09-15 # 1 results
当我们在date字段中查询2014,没有找到文档,因为没有文档包含那个确切的日期:
GET /_search?q=date:2014 # 0 results
测试分析器
尤其当你是Elasticsearch新手时,对于如何分词以及存储到索引中理解起来比较。为了更好的理解如何进行,你可以使用analyze API来查看文本是如何被分析的。在查询字符串参数中指定要使用的分析器,被分析的文本作为请求体:
GET /_analyze?analyzer=standard
Text to analyze
结果中每个节点在代表一个词:

token是一个实际被存储在索引的词。position指明词在原文本中是第几个出现的。start_offset和end_offset表示词在原文本中占据的位置。
analyze API对于理解Elasticsearch索引的内在细节是分厂有用的工具。
指定分析器
当Elasticsearch在你的文档中探测到一个新的字符串字段,它将自动设置它为全文string字段并用standard分析器分析。
你不可能总是想这么做。也许你想使用一个更适合这个数据的语言分析器。或者,你只想把字符串字段当做一个普通的字段——不做任何分析,只存储确切值,就像字符串类型的用户ID或者内部状态字段或者标签。
为了达到这种效果,我们必须通过映射(mapping)人工设置这些字段。

Hibernate"discriminator-value"用法
可能经常遇到这样的情况:
在数据库表中会有这样的一个字段用来区别记录的属性,如:在客户表中有一个字段表示客户级别,当这个记录为A时是一级客户,为B时是二级客户。在用hiberante做OR表示时类可能是这样的:
public class Customer{
private String flag; //表示客户的级别
...
}
然后,在程序中手动控制flag的值,但是这样当每个级的客户有不同的属性时Customer类将包含所有级别的属性,这样不是很好。
hibernate提供一个Discriminator映射的方法,就是把一个表映射成不同的类,有不同的属性。
public class Customer{
//包含所有级别的公共属性
...
}
public class CustomerA extends Customer{
//只包括一级客户的特有属性
}
public class CustomerB extends Customer{
//只包含二级客户特有的属性
}
这样更符合面向对象的原则,然后在hbm.xml中这样写:
<id name="id" type="int">
...
</id>
<discriminator column="flag" type="string" />
<!-- 公共属性的映射 -->
<subclass name="CustomerA" discriminator-value="A">
<!-- 一级客户特有属性的映射 -->
</subclass>
<subclass name="CustomerB" discriminator-value="B">
<!-- 二级客户特有属性的映射 -->
</subclass>
这样就可以单独的用CustomerA,CustomerB这样的实例了,做数据库修改时就不用关心flag字段的值了,会自动的加A或B。
如果是使用hibernate Annotation而不是xml来描述映谢关系,代码如下:
@Entity
@Table(name = "customer")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "flag", discriminatorType = DiscriminatorType.STRING)
public class Customer{
}
@Entity
@DiscriminatorValue(value = "A")
public class CustomerA extends Customer{
}
@Entity
@DiscriminatorValue(value = "B")
public class CustomerB extends Customer{
}
这样就可以了。

iphone – XCode Static Analyzer:由于解析错误,Analyzer跳过了这个文件
<command line>:0:0 Analyzer skipped this file due to parse errors
不确定如何诊断.
它跳过的第一个瓷砖是:
/Developer/Platforms/iPhonesimulator.platform/Developer/SDKs/iPhonesimulator4.1.sdk/System/Library/Frameworks/CoreGraphics.framework/Headers/CGPDFContext.h:0:0由于解析错误,分析器跳过此文件
解决方法
学习笔记")
Linear discriminant analysis (LDA)学习笔记
上次写篇文章各种蛋疼,各种调格式,这回直接把写好的截图吧。


















关于在休眠搜索AnalyzerDiscriminator中使用现有分析器和在休眠吧的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于Elasticsearch之分析(analysis)和分析器(analyzer)、Hibernate"discriminator-value"用法、iphone – XCode Static Analyzer:由于解析错误,Analyzer跳过了这个文件、Linear discriminant analysis (LDA)学习笔记等相关内容,可以在本站寻找。
本文标签:




