本文的目的是介绍PostgreSQLROW_NUMBER()OVER()的用法说明的详细情况,特别关注plsqlrow_number函数的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您
本文的目的是介绍PostgreSQL ROW_NUMBER() OVER()的用法说明的详细情况,特别关注plsql row_number函数的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解PostgreSQL ROW_NUMBER() OVER()的用法说明的机会,同时也不会遗漏关于HiveSQL——row_number() over() 使用、mysql row_number() over()、MYSQL row_number()与over()函数用法详解、mysql 实现 sqlserver的row_number over() 方法的知识。
本文目录一览:- PostgreSQL ROW_NUMBER() OVER()的用法说明(plsql row_number函数)
- HiveSQL——row_number() over() 使用
- mysql row_number() over()
- MYSQL row_number()与over()函数用法详解
- mysql 实现 sqlserver的row_number over() 方法
 OVER()的用法说明(plsql row_number函数)")
PostgreSQL ROW_NUMBER() OVER()的用法说明(plsql row_number函数)
项目招商找A5 快速获取精准代理名单
这篇文章主要介绍了PostgreSQL ROW_NUMBER() OVER()的用法说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧。
语法:
1ROW_NUMBER() OVER( [ PRITITION BY col1] ORDER BY col2[ DESC ] )
解释:
ROW_NUMBER()为返回的记录定义个行编号, PARTITION BY col1 是根据col1分组,ORDER BY col2[ DESC ]是根据col2进行排序。
举例:
postgres=# create table student(id serial,name character varying,course character varying,score integer);
CREATE TABLE
postgres=#
postgres=# \d student
Table "public.student"
Column | Type | Modifiers
--------+-------------------+----------------------------------------------
id | integer | not null default nextval('student_id_seq'::regclass)
name | character varying |
course | character varying |
score | integer |
insert into student (name,course,score) values('周润发','语文',89);
insert into student (name,course,score) values('周润发','数学',99);
insert into student (name,course,score) values('周润发','外语',67);
insert into student (name,course,score) values('周润发','物理',77);
insert into student (name,course,score) values('周润发','化学',87);
insert into student (name,course,score) values('周星驰','语文',91);
insert into student (name,course,score) values('周星驰','数学',81);
insert into student (name,course,score) values('周星驰','外语',88);
insert into student (name,course,score) values('周星驰','物理',68);
insert into student (name,course,score) values('周星驰','化学',83);
insert into student (name,course,score) values('黎明','语文',85);
insert into student (name,course,score) values('黎明','数学',65);
insert into student (name,course,score) values('黎明','外语',95);
insert into student (name,course,score) values('黎明','物理',90);
insert into student (name,course,score) values('黎明','化学',78);
1. 根据分数排序
postgres=# select *,row_number() over(order by score desc)rn from student;
id | name | course | score | rn
----+--------+--------+-------+----
2 | 周润发 | 数学 | 99 | 1
13 | 黎明 | 外语 | 95 | 2
6 | 周星驰 | 语文 | 91 | 3
14 | 黎明 | 物理 | 90 | 4
1 | 周润发 | 语文 | 89 | 5
8 | 周星驰 | 外语 | 88 | 6
5 | 周润发 | 化学 | 87 | 7
11 | 黎明 | 语文 | 85 | 8
10 | 周星驰 | 化学 | 83 | 9
7 | 周星驰 | 数学 | 81 | 10
15 | 黎明 | 化学 | 78 | 11
4 | 周润发 | 物理 | 77 | 12
9 | 周星驰 | 物理 | 68 | 13
3 | 周润发 | 外语 | 67 | 14
12 | 黎明 | 数学 | 65 | 15
(15 rows)
rn是给我们的一个排序。
2. 根据科目分组,按分数排序
postgres=# select *,row_number() over(partition by course order by score desc)rn from student;
id | name | course | score | rn
----+--------+--------+-------+----
5 | 周润发 | 化学 | 87 | 1
10 | 周星驰 | 化学 | 83 | 2
15 | 黎明 | 化学 | 78 | 3
13 | 黎明 | 外语 | 95 | 1
8 | 周星驰 | 外语 | 88 | 2
3 | 周润发 | 外语 | 67 | 3
2 | 周润发 | 数学 | 99 | 1
7 | 周星驰 | 数学 | 81 | 2
12 | 黎明 | 数学 | 65 | 3
14 | 黎明 | 物理 | 90 | 1
4 | 周润发 | 物理 | 77 | 2
9 | 周星驰 | 物理 | 68 | 3
6 | 周星驰 | 语文 | 91 | 1
1 | 周润发 | 语文 | 89 | 2
11 | 黎明 | 语文 | 85 | 3
(15 rows)
3. 获取每个科目的最高分
postgres=# select * from(select *,row_number() over(partition by course order by score desc)rn from student)t where rn=1;
id | name | course | score | rn
----+--------+--------+-------+----
5 | 周润发 | 化学 | 87 | 1
13 | 黎明 | 外语 | 95 | 1
2 | 周润发 | 数学 | 99 | 1
14 | 黎明 | 物理 | 90 | 1
6 | 周星驰 | 语文 | 91 | 1
(5 rows)
4. 每个科目的最低分也是一样的
postgres=# select * from(select *,row_number() over(partition by course order by score)rn from student)t where rn=1;
id | name | course | score | rn
----+--------+--------+-------+----
15 | 黎明 | 化学 | 78 | 1
3 | 周润发 | 外语 | 67 | 1
12 | 黎明 | 数学 | 65 | 1
9 | 周星驰 | 物理 | 68 | 1
11 | 黎明 | 语文 | 85 | 1
(5 rows)
只要在根据科目排序的时候按低到高顺序排列就好了。
补充:SQL:postgresql中为查询结果增加一个自增序列之ROW_NUMBER () OVER ()的使用
举例说明:
SELECT ROW_NUMBER
() OVER ( ORDER BY starttime DESC ) "id",
starttime AS "text",
starttime
FROM
warning_products
WHERE
pid_model = '结果'
AND starttime IS NOT NULL
GROUP BY
starttime
在这一段代码中:
查询语句就不说了, select …from…where
GROUP BY的作用:
这一段代码执行的结果是:

如果将GROUP BY删除,那么执行结果为:
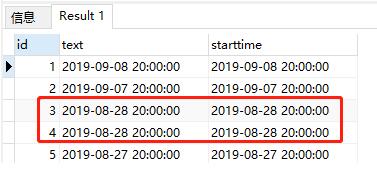
可以看到查询出了两个相同starttime数据.
由此得出:
GROUP BY的作用是分类汇总.也就是说,查询结果中,starttime每一种查询结果只有一个
GROUP BY的作用:
如果将DESC换成
1() OVER ( ORDER BY starttime ASC ) "id",
则运行结果为:
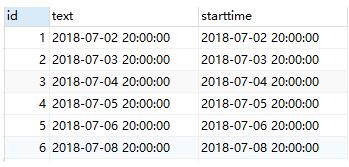
相比可以发现,ORDER BY的作用为进行排序.
按照某种要求进行固定的排序
1ROW_NUMBER () OVER() “id”
先来看一下,如果把这一段删掉,运行结果:
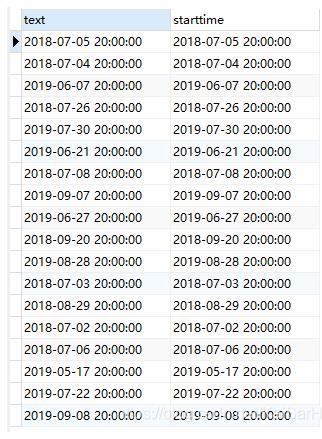
加上呢?
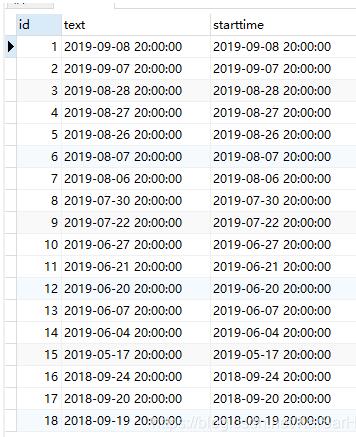
明显的对比,我们为最终的查询结果增加了一列自增的id序列(这里id可以改名,"id"改为其他的即可)
由此得到结论,在执行带有row_number() over() "xx"的SQL语句时候,代码会先执行查询语句,然后执行over中的命令,最后为结果增加一列自增的序列.
文章来源:
来源地址:https://www.jb51.net/article/205212.htm

 over() 使用")
HiveSQL——row_number() over() 使用
语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
例一:
表数据:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,''a'',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,''a2'',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,''b'',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,''b2'',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,''c'',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,''c2'',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,''d'',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,''d2'',17,1800);
一次排序:对查询结果进行排序(无分组)
select id,name,age,salary,row_number()over(order by salary desc) rn
from TEST_ROW_NUMBER_OVER t
结果:
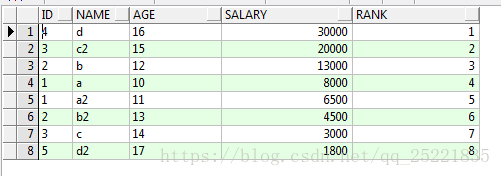
进一步排序:根据id分组排序
select id,name,age,salary,row_number()over(partition by id order by salary desc) rank
from TEST_ROW_NUMBER_OVER t
结果:
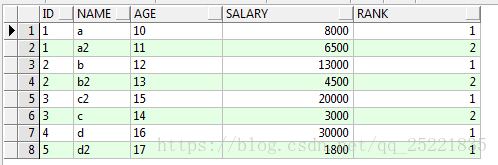
再一次排序:找出每一组中序号为一的数据
select * from(select id,name,age,salary,row_number()over(partition by id order by salary desc) rank
from TEST_ROW_NUMBER_OVER t)
where rank <2
结果:
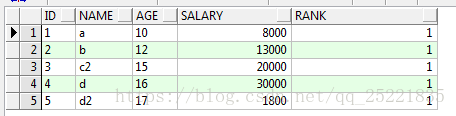
排序找出年龄在13岁到16岁数据,按salary排序
select id,name,age,salary,row_number()over(order by salary desc) rank
from TEST_ROW_NUMBER_OVER t where age between ''13'' and ''16''
结果:结果中 rank 的序号,其实就表明了 over(order by salary desc) 是在where age between and 后执行的

例二:
1.使用row_number()函数进行编号,如
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理:先按psd进行排序,排序完后,给每条数据进行编号。
2.在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3.统计出每一个各户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样就知道每个客户下几单了:
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
4.统计每一个客户最近下的订单是第几次下的订单:
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
)
select MAX(rows) as ''下单次数'',customerID from tabs
group by customerID
5.统计每一个客户所有的订单中购买的金额最小,而且并统计改订单中,客户是第几次购买的:
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT)
as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)
6.筛选出客户第一次下的订单。
思路。利用rows=1来查询客户第一次下的订单记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order
7.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>''2011-07-22''
原文链接:https://blog.csdn.net/qq_25221835/article/details/82762416
 over()")
mysql row_number() over()
select inn.rank from(
select (@rowno\\:=@rowno+1) rank,c.user_id from t_company c,(select @rowno\\:=0) rowno where c.company_id=?
) inn where inn.user_id=?
与over()函数用法详解")
MYSQL row_number()与over()函数用法详解
语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
例一:
表数据:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,''a'',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,''a2'',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,''b'',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,''b2'',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,''c'',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,''c2'',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,''d'',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,''d2'',17,1800);
一次排序:对查询结果进行排序(无分组)
select id,name,age,salary,row_number()over(order by salary desc) rn from TEST_ROW_NUMBER_OVER t
结果:

进一步排序:根据id分组排序
select id,name,age,salary,row_number()over(partition by id order by salary desc) rank from TEST_ROW_NUMBER_OVER t
结果:

再一次排序:找出每一组中序号为一的数据
select * from(select id,name,age,salary,row_number()over(partition by id order by salary desc) rank from TEST_ROW_NUMBER_OVER t) where rank <2
结果:

排序找出年龄在13岁到16岁数据,按salary排序
select id,name,age,salary,row_number()over(order by salary desc) rank from TEST_ROW_NUMBER_OVER t where age between ''13'' and ''16''
结果:结果中 rank 的序号,其实就表明了 over(order by salary desc) 是在where age between and 后执行的

例二:
1.使用row_number()函数进行编号,如
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理:先按psd进行排序,排序完后,给每条数据进行编号。
2.在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3.统计出每一个各户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样就知道每个客户下几单了:
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4.统计每一个客户最近下的订单是第几次下的订单:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as ''下单次数'',customerID from tabs group by customerID
5.统计每一个客户所有的订单中购买的金额最小,而且并统计改订单中,客户是第几次购买的:
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT)
as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)
6.筛选出客户第一次下的订单。
思路。利用rows=1来查询客户第一次下的订单记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order
7.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>''2011-07-22''
到此这篇关于MYSQL row_number()与over()函数用法详解的文章就介绍到这了,更多相关MYSQL row_number()与over()函数内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- MySQL rownumber SQL生成自增长序号使用介绍
- mysql简单实现查询结果添加序列号的方法
- mysql序号rownum行号实现方式
 方法")
mysql 实现 sqlserver的row_number over() 方法
1.创建表
CREATE TABLE `heyf_t10` (
`empid` int(11) DEFAULT NULL,
`deptid` int(11) DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.添加数据
INSERT INTO `heyf_t10` VALUES (1, 10, 5500.00);
INSERT INTO `heyf_t10` VALUES (2, 10, 4500.00);
INSERT INTO `heyf_t10` VALUES (3, 20, 1900.00);
INSERT INTO `heyf_t10` VALUES (4, 20, 4800.00);
INSERT INTO `heyf_t10` VALUES (5, 40, 6500.00);
INSERT INTO `heyf_t10` VALUES (6, 40, 14500.00);
INSERT INTO `heyf_t10` VALUES (7, 40, 44500.00);
INSERT INTO `heyf_t10` VALUES (8, 50, 6500.00);
INSERT INTO `heyf_t10` VALUES (9, 50, 7500.00);
3.按着deptid分组,empid排序,去前两行
select empid,deptid,salary,rank from (
select b.empid,b.deptid,b.salary,@rownum:=@rownum+1 ,
if(@pdept=b.deptid,@rank:=@rank+1,@rank:=1) as rank,
@pdept:=b.deptid
from (
select empid,deptid,salary from heyf_t10 order by empid
) b ,(select @rownum :=0 , @pdept := null ,@rank:=0) c ) result
having rank <3;
我们今天的关于PostgreSQL ROW_NUMBER() OVER()的用法说明和plsql row_number函数的分享已经告一段落,感谢您的关注,如果您想了解更多关于HiveSQL——row_number() over() 使用、mysql row_number() over()、MYSQL row_number()与over()函数用法详解、mysql 实现 sqlserver的row_number over() 方法的相关信息,请在本站查询。
本文标签:




