在本文中,我们将带你了解NoSQL数据库如何对聚合函数在这篇文章中,我们将为您详细介绍NoSQL数据库如何对聚合函数的方方面面,并解答AVG,SUM等执行常见的疑惑,同时我们还将给您一些技巧,以帮助您
在本文中,我们将带你了解NoSQL数据库如何对聚合函数在这篇文章中,我们将为您详细介绍NoSQL数据库如何对聚合函数的方方面面,并解答AVG,SUM等执行常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的071:【Django数据库】ORM聚合函数详解-Avg、CentOS Mysql数据库如何实现定时备份、Django / Postgres - 按其他注释分组时,Sum 聚合函数会重复结果、group by 与聚合函数(T-sql)。
本文目录一览:- NoSQL数据库如何对聚合函数(AVG,SUM等)执行(sql中聚合函数的使用规则)
- 071:【Django数据库】ORM聚合函数详解-Avg
- CentOS Mysql数据库如何实现定时备份
- Django / Postgres - 按其他注释分组时,Sum 聚合函数会重复结果
- group by 与聚合函数(T-sql)
执行(sql中聚合函数的使用规则)")
NoSQL数据库如何对聚合函数(AVG,SUM等)执行(sql中聚合函数的使用规则)
我们需要定期处理相当大的数据集(30-40GB)。它有很多按时间排序的值(以及更多信息),但我们基本上需要按月执行一些数学运算。
我们的第一种方法是使用MySQL数据库来备份数据,因为我们对引擎和关系方法有一定的经验。但是,该过程耗时太长,我们想知道NoSQL方法是否可以做得更好。
基本上,我们需要表达的数据是:
Value: { NumericalValue, Year, Month }Entity: List of ''Value''我们处理此列表三次,执行简单的数学运算,当我说“处理”时,我的意思是遍历数据集并执行演算。当一切都结束时,我们具有相同的结构(但具有不同的数据):
Value: { NumericalValue, Year, Month }Entity: List of ''Value''现在是我们发现最大问题的时候,我们需要计算一些平均数,这需要很多时间。当我们重复此过程几次时,我认为最耗时的任务是:
1)将数据集导出到MySQL。这意味着很多来自文本文件的插入。
当数据转换时:
2)计算一些包含带有LIMIT的聚合函数(AVG,SUM)的查询。3)使用整个数据集计算一些包含聚合函数的查询。
通常,即使添加了一些索引,我们也会感觉花费的时间太长(某些查询需要20分钟)。任何技巧或解决方法将不胜感激。我觉得NoSQL数据库不是专门为此设计的,但是也许有些经验可以有所帮助:)。
谢谢你的时间,
答案1
小编典典您的任务非常适合Columnar数据库。面向列的NoSQL(例如Cassandra)数据库将数据表存储为数据列的一部分,而不是数据行。这大大提高了聚合速度。这与依赖硬盘进行存储的系统有关。如果不是这种情况(例如内存数据库),则有更多选择可以降低性能。

071:【Django数据库】ORM聚合函数详解-Avg
ORM聚合函数详解-Avg:
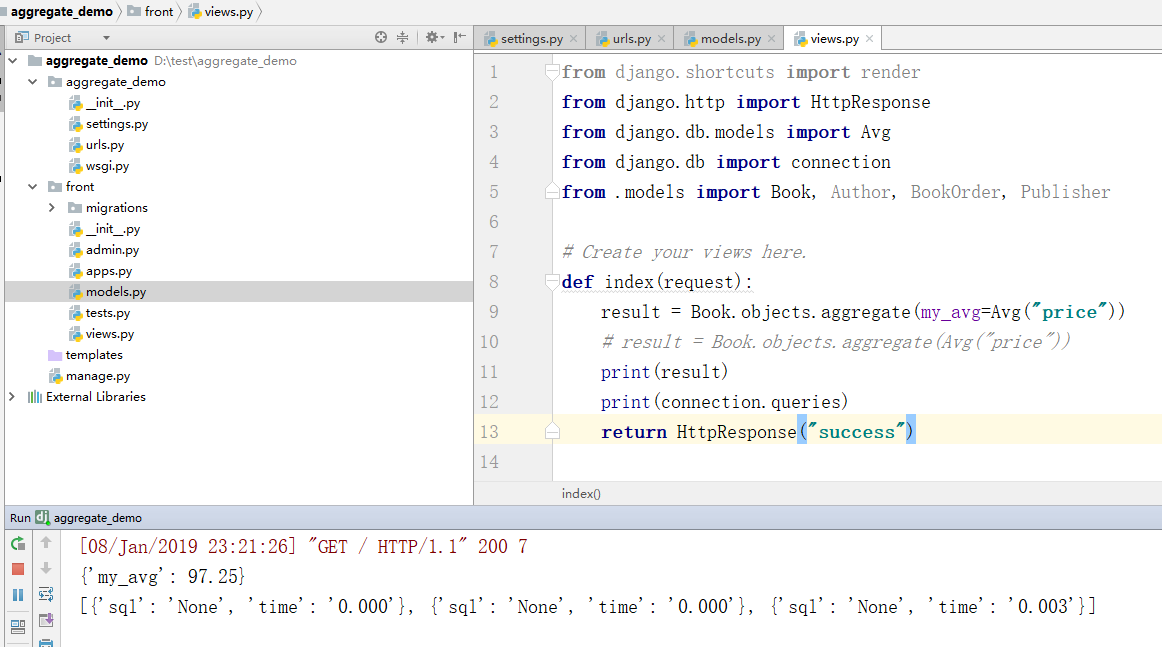
Avg:求平均值。比如想要获取所有图书的价格平均值。那么可以使用以下代码实现:
from django.db.models import Avg
result = Book.objects.aggregate(Avg(''price''))
print(result)以上的打印结果是:
{"price__avg":23.0}
其中price__avg的结构是根据field__avg规则构成的。如果想要修改默认的名字,那么可以将Avg赋值给一个关键字参数。示例代码如下:
from django.db.models import Avg
result = Book.objects.aggregate(my_avg=Avg(''price''))
print(result)那么以上的结果打印为:
{"my_avg":23}
实例工程截图如下:

CentOS Mysql数据库如何实现定时备份
如下脚本用于mysql全库定时备份
mysql_dump_script.sh
#!/bin/bash
#保存备份个数,最多保留4个文件
number=4
#备份保存路径
backup_dir=/db/backup_mysql
#日期
dd=`date +%Y-%m-%d-%H-%M-%S`
#备份工具
tool=mysqldump
#用户名
username=root
#密码
password=yourpassword
#将要备份的数据库
database_name=mydb
#如果文件夹不存在则创建
if [ ! -d $backup_dir ];
then
mkdir -p $backup_dir;
fi
#简单写法 mysqldump -u root -p123456 users > /root/mysqlbackup/users-$filename.sql
$tool -h127.0.0.1 -u $username -p$password $database_name > $backup_dir/$database_name-$dd.sql
#写创建备份日志
echo "create $backup_dir/$database_name-$dd.dupm" >> $backup_dir/log.txt
#找出需要删除的备份
delfile=`ls -l -crt $backup_dir/*.sql | awk ''{print $9 }'' | head -1`
#判断现在的备份数量是否大于$number
count=`ls -l -crt $backup_dir/*.sql | awk ''{print $9 }'' | wc -l`
if [ $count -gt $number ]
then
#删除最早生成的备份,只保留number数量的备份
rm $delfile
#写删除文件日志
echo "delete $delfile" >> $backup_dir/log.txt
fi
centos 设置crontab
yum install crontabs
systemctl enable crond (设为开机启动)
systemctl start crond(启动crond服务)
systemctl status crond (查看状态)
vi /etc/crontab
添加定时任务

加载任务,使之生效:
crontab /etc/crontab
查看任务:
crontab -l
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
- MySQL数据库备份过程的注意事项
- shell脚本定时备份MySQL数据库数据并保留指定时间
- Mysql数据库定时备份脚本分享
- MySQL数据库备份恢复实现代码
- MySQL数据库入门之备份数据库操作详解
- mysql数据备份与恢复实现方法分析
- MySQL定时备份数据库操作示例
- mysql 数据库备份的多种实现方式总结
- Linux实现定时备份MySQL数据库并删除30天前的备份文件
- linux定时备份MySQL数据库并删除以前的备份文件(推荐)
- Mysql备份多个数据库代码实例
- MySQL数据备份方法的选择与思考

Django / Postgres - 按其他注释分组时,Sum 聚合函数会重复结果
如何解决Django / Postgres - 按其他注释分组时,Sum 聚合函数会重复结果?
Django Sum() 聚合方法在与多个注释结合使用时会产生错误结果,当一行数据可以适合多个类别时,通常会导致重复数据
以以下为例:
class Item(models.Model):
id = models.BigAutoField(primary_key=True)
name = models.TextField(blank=True,null=True)
class ItemLink(models.Model):
id = models.BigAutoField(primary_key=True)
parent_item = models.ForeignKey(Item,blank=False,related_name=''parent_item_links'')
child_item = models.ForeignKey(Item,related_name=''child_item_links'')
class Aggregate(models.Model):
id = models.BigAutoField(primary_key=True)
item_id = models.ForeignKey(Item,blank=False)
data = models.FloatField(blank=True,null=True)
这 3 个表描述了一个项目,项目与其他项目之间的关系,以及一些包含与特定项目相关联的数据的聚合表。
如果我要按其具有的任何父关系对项目和组的聚合数据求和,我会收到重复的结果。
例如:
[{
name: parent_1,id: 1
},{
name: parent_2,id: 2
},{
name: child_1,data: 1.0,(via aggregate)
id: 3
}]
如果我要查询这个数据集,我希望得到两个父对象的数据:1,但是当我按项目名称分组时,我得到 2。
Aggregate.objects
.annotate(''item_name'': F(''item__parent_item_links__parent_item__name''))
.annotate(agg_value=Sum(''data''))
.filter(''item_id__is'': 3)
.values_list(''item_name'',''agg_value'')
会给你
[{
item_name: parent_1,agg_value: 2.0,},{
item_name: parent_2,}]
我希望它改为按 item_name 分组,因此每个 agg_value 只给出 1。关于如何解决这个问题的任何想法?
我在 django 错误中看到有人谈论将其作为子查询 (https://code.djangoproject.com/ticket/10060#comment:70) 执行此操作,但这似乎仅在您在注释中执行多个聚合函数时才相关。我没有看到将此 Sum 函数作为子查询包含在内的方法。
谢谢!
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
")
group by 与聚合函数(T-sql)
select A.productID,B.title,A.OuterNo,A.CustomerID,ShopID,ISdel,sum(D.Amount),sum(D.Count),Session from V5ESB_Customer_CustomerItem A inner join V5ESB_Customer_CustomerChannel B on A.CustomerID =B.CustomerID inner join V5ESB_Order_Order C on A.CustomerID =C.CustomerID inner join V5ESB_Order_Product D on C.Code=D.OrderCode where D.productID=1266 GROUP BY a.customerID,A.productID,Session
group by 后面的分组字段要有一一对应关系,才能分成一个分组,不能有一一对应关系的可以使用where过滤之后进行分组;
要select 的字段需要放在group by 中,如果不放的,要使用聚合函数sum, avg,count等等
今天关于NoSQL数据库如何对聚合函数和AVG,SUM等执行的介绍到此结束,谢谢您的阅读,有关071:【Django数据库】ORM聚合函数详解-Avg、CentOS Mysql数据库如何实现定时备份、Django / Postgres - 按其他注释分组时,Sum 聚合函数会重复结果、group by 与聚合函数(T-sql)等更多相关知识的信息可以在本站进行查询。
本文标签:




