对于使用Java在SeleniumWebDriver感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍Selenium2中向上或向下滚动页面,并为您提供关于java–chrome无法在Seleni
对于使用Java在Selenium WebDriver感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍Selenium 2中向上或向下滚动页面,并为您提供关于java – chrome无法在Selenium Webdriver中运行.我使用的是selenium 3.0.1 chrome v-54.0、JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测、Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效、Selenium WebDriver原理(一):Selenium WebDriver 是怎么工作的?的有用信息。
本文目录一览:- 使用Java在Selenium WebDriver(Selenium 2)中向上或向下滚动页面(java selenium处理内嵌滚动条)
- java – chrome无法在Selenium Webdriver中运行.我使用的是selenium 3.0.1 chrome v-54.0
- JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测
- Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效
- Selenium WebDriver原理(一):Selenium WebDriver 是怎么工作的?
中向上或向下滚动页面(java selenium处理内嵌滚动条)")
使用Java在Selenium WebDriver(Selenium 2)中向上或向下滚动页面(java selenium处理内嵌滚动条)
我已经在Selenium 1(又名Selenium RC)中编写了以下代码,以便使用Java进行页面滚动:
selenium.getEval("scrollBy(0, 250)");Selenium 2(WebDriver)中的等效代码是什么?
答案1
小编典典场景/测试步骤:
1.打开浏览器并导航到TestURL
2.向下滚动一些像素并向上滚动
对于 向下滚动 :
WebDriver driver = new FirefoxDriver();JavascriptExecutor jse = (JavascriptExecutor)driver;jse.executeScript("window.scrollBy(0,250)");或者,您可以执行以下操作:
jse.executeScript("scroll(0, 250);");对于 向上滚动 :
jse.executeScript("window.scrollBy(0,-250)");OR,jse.executeScript("scroll(0, -250);");滚动到页面底部:
场景/测试步骤:
1.打开浏览器并导航到TestURL。2
.滚动到页面底部
方法1:通过使用JavaScriptExecutor
jse.executeScript("window.scrollTo(0, document.body.scrollHeight)");方法2:按Ctrl + End
driver.findElement(By.cssSelector("body")).sendKeys(Keys.CONTROL, Keys.END);方法3:通过使用Java Robot类
Robot robot = new Robot();robot.keyPress(KeyEvent.VK_CONTROL);robot.keyPress(KeyEvent.VK_END);robot.keyRelease(KeyEvent.VK_END);robot.keyRelease(KeyEvent.VK_CONTROL);
java – chrome无法在Selenium Webdriver中运行.我使用的是selenium 3.0.1 chrome v-54.0
public class sikuli {
public static void main(String[] args) throws Exception {
//Screen screen=new Screen();
//screen.click("//home//exeter//Pictures//googlechrome.png");
System.setProperty("webdriver.chrome.driver","//home//exeter//Documents//chromedriver");
WebDriver driver=new ChromeDriver();
driver.get("https://mail.google.com");
Starting ChromeDriver 2.24.417424 (c5c5ea873213ee72e3d0929b47482681555340c3) on port 11320
Only local connections are allowed.
Oct 19,2016 10:07:22 AM org.openqa.selenium.remote.ProtocolHandshake createSession
INFO: Attempting bi-dialect session,assuming Postel’s Law holds true on the remote end
Oct 19,2016 10:08:22 AM org.openqa.selenium.remote.ProtocolHandshake createSession
INFO: Detected dialect: OSS
Exception in thread “main” org.openqa.selenium.NoSuchSessionException: no such session
(Driver info: chromedriver=2.24.417424 (c5c5ea873213ee72e3d0929b47482681555340c3),platform=Linux 4.4.0-43-generic x86_64) (WARNING: The server did not provide any stacktrace information)
Command duration or timeout: 9 milliseconds
Build info: version: ‘unkNown’,revision: ‘350cf60’,time: ‘2016-10-13 10:43:56 -0700’
Driver info: org.openqa.selenium.chrome.ChromeDriver
Capabilities [{message=unkNown error: Chrome Failed to start: exited abnormally
解决方法

JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测
如何解决JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测?
从当前的实现开始,一种理想的访问网页而不被检测到的方法是使用ChromeOptions()该类向以下参数添加几个参数:
排除enable-automation开关的集合
关掉 useAutomationExtension
通过以下实例ChromeOptions:
Java示例:
System.setProperty("webdriver.chrome.driver", "C:\\Utility\\browserDrivers\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("excludeSwitches", Collections.singletonList("enable-automation"));
options.setExperimentalOption("useAutomationExtension", false);
WebDriver driver = new ChromeDriver(options);
driver.get("https://www.google.com/");
Python范例
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option(''useAutomationExtension'', False)
driver = webdriver.Chrome(options=options, executable_path=r''C:\path\to\chromedriver.exe'')
driver.get("https://www.google.com/")
解决方法
我正在尝试使用selenium和铬在网站中自动化一个非常基本的任务,但是以某种方式网站会检测到铬是由selenium驱动的,并阻止每个请求。我怀疑该网站是否依赖像这样的公开DOM变量https://stackoverflow.com/a/41904453/648236来检测selenium驱动的浏览器。
我的问题是,有没有办法使navigator.webdriver标志为假?我愿意尝试修改后重新尝试编译selenium源,但是似乎无法在存储库中的任何地方找到NavigatorAutomationInformation源https://github.com/SeleniumHQ/selenium
任何帮助深表感谢
PS:我还从https://w3c.github.io/webdriver/#interface尝试了以下操作
Object.defineProperty(navigator,''webdriver'',{
get: () => false,});
但是它仅在初始页面加载后更新属性。我认为网站会在执行脚本之前检测到变量。

Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效
如何解决Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效?
我正在尝试抓取一些 LinkedIn 个人资料,但是,使用下面的代码,给了我一个错误:
错误:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-b6cfafdd5b52> in <module>
25 #sending our driver as the driver to be used by srape_linkedin
26 #you can also create driver options and pass it as an argument
---> 27 ps = ProfileScraper(cookie=myLI_AT_Key,scroll_increment=random.randint(10,50),scroll_pause=0.8 + random.uniform(0.8,1),driver=my_driver) #changed name,default driver and scroll_pause time and scroll_increment made a little random
28 print(''Currently scraping: '',link,''Time: '',datetime.Now())
29 profile = ps.scrape(url=link) #changed name
~\Anaconda3\lib\site-packages\scrape_linkedin\Scraper.py in __init__(self,cookie,scraperInstance,driver,driver_options,scroll_pause,scroll_increment,timeout)
37
38 self.was_passed_instance = False
---> 39 self.driver = driver(**driver_options)
40 self.scroll_pause = scroll_pause
41 self.scroll_increment = scroll_increment
TypeError: ''WebDriver'' object is not callable
代码:
from datetime import datetime
from scrape_linkedin import ProfileScraper
import random #new import made
from selenium import webdriver #new import made
import pandas as pd
import json
import os
import re
import time
os.chdir("C:\\Users\\MyUser\\DropBox\\linkedInScrapper\\")
my_profile_list = [''https://www.linkedin.com/in/williamhgates/'',''https://www.linkedin.com/in/christinelagarde/'',''https://www.linkedin.com/in/ursula-von-der-leyen/'']
myLI_AT_Key = MyKey # you need to obtain one from Linkedin using these steps:
# To get LI_AT key
# Navigate to www.linkedin.com and log in
# Open browser developer tools (Ctrl-Shift-I or right click -> inspect element)
# Select the appropriate tab for your browser (Application on Chrome,Storage on Firefox)
# Click the Cookies dropdown on the left-hand menu,and select the www.linkedin.com option
# Find and copy the li_at value
for link in my_profile_list:
#my_driver = webdriver.Chrome() #if you don''t have Chromedrive in the environment path then use the next line instead of this
#my_driver = webdriver.Chrome()
my_driver = webdriver.Firefox(executable_path=r''C:\Users\MyUser\DropBox\linkedInScrapper\geckodriver.exe'')
#my_driver = webdriver.Chrome(executable_path=r''C:\Users\MyUser\DropBox\linkedInScrapper\chromedriver.exe'')
#sending our driver as the driver to be used by srape_linkedin
#you can also create driver options and pass it as an argument
ps = ProfileScraper(cookie=myLI_AT_Key,default driver and scroll_pause time and scroll_increment made a little random
print(''Currently scraping: '',datetime.Now())
profile = ps.scrape(url=link) #changed name
dataJSON = profile.to_dict()
profileName = re.sub(''https://www.linkedin.com/in/'','''',link)
profileName = profileName.replace("?originalSubdomain=es","")
profileName = profileName.replace("?originalSubdomain=pe","")
profileName = profileName.replace("?locale=en_US","")
profileName = profileName.replace("?locale=es_ES","")
profileName = profileName.replace("?originalSubdomain=uk","")
profileName = profileName.replace("/","")
with open(os.path.join(os.getcwd(),''ScrapedLinkedInprofiles'',profileName + ''.json''),''w'') as json_file:
json.dump(dataJSON,json_file)
time.sleep(10 + random.randint(0,5)) #added randomness to the sleep time
#this will close your browser at the end of every iteration
my_driver.quit()
print(''The first observation scraped was:'',my_profile_list[0:])
print(''The last observation scraped was:'',my_profile_list[-1:])
print(''END'')
我尝试了许多不同的方法来尝试让 webdriver.Chrome() 工作,但没有任何运气。我曾尝试使用 Chrome (chromedriver) 和 Firefox (geckodriver),尝试以多种不同的方式加载 selenium 包,但我一直收到错误 TypeError: ''WebDriver'' object is not callable。
我下面的原始代码仍然有效。 (即它会打开 Google Chrome 浏览器并转到 my_profiles_list 中的每个配置文件,但我想使用上面的代码。
from datetime import datetime
from scrape_linkedin import ProfileScraper
import pandas as pd
import json
import os
import re
import time
my_profile_list = [''https://www.linkedin.com/in/williamhgates/'',''https://www.linkedin.com/in/ursula-von-der-leyen/'']
# To get LI_AT key
# Navigate to www.linkedin.com and log in
# Open browser developer tools (Ctrl-Shift-I or right click -> inspect element)
# Select the appropriate tab for your browser (Application on Chrome,Storage on Firefox)
# Click the Cookies dropdown on the left-hand menu,and select the www.linkedin.com option
# Find and copy the li_at value
myLI_AT_Key = ''INSERT LI_AT Key''
with ProfileScraper(cookie=myLI_AT_Key,scroll_increment = 50,scroll_pause = 0.8) as scraper:
for link in my_profile_list:
print(''Currently scraping: '',datetime.Now())
profile = scraper.scrape(url=link)
dataJSON = profile.to_dict()
profileName = re.sub(''https://www.linkedin.com/in/'',link)
profileName = profileName.replace("?originalSubdomain=es","")
profileName = profileName.replace("?originalSubdomain=pe","")
profileName = profileName.replace("?locale=en_US","")
profileName = profileName.replace("?locale=es_ES","")
profileName = profileName.replace("?originalSubdomain=uk","")
profileName = profileName.replace("/","")
with open(os.path.join(os.getcwd(),''w'') as json_file:
json.dump(dataJSON,json_file)
time.sleep(10)
print(''The first observation scraped was:'',my_profile_list[0:])
print(''The last observation scraped was:'',my_profile_list[-1:])
print(''END'')
注意事项:
代码略有不同,因为我在 SO here 上提出了一个问题,@Ananth 帮助我给出了解决方案。
我也知道在线和 SO 存在与 selenium 和 chromedriver 相关的“类似”问题,但在尝试了每个建议的解决方案后,我仍然无法使其正常工作。 (即常见的解决方案是 webdriver.Chrome() 中的拼写错误)。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
:Selenium WebDriver 是怎么工作的?")
Selenium WebDriver原理(一):Selenium WebDriver 是怎么工作的?
首先我们来看一个经典的例子: 搭出租车
在出租车驾驶中,通常有3个角色:
- 乘客 : 他告诉出租车司机他想去哪里以及如何到达那里
对出租车司机说:
1、去阳光棕榈园东门
2、从这里转左
3、然后直行 200米,第一个红绿灯右转
4、再直行 50米,到阳光棕榈园东门
5、停车- 出租车司机 : 他按照客户的要求; 出租车司机使用方向盘和汽车踏板驾驶汽车送乘客去目的地
出租车司机操作汽车:
1、插钥匙点火,启动汽车引擎
2、开一小段路后左转
3、加速,直行200米
4、右转,直行50米
5、减速停车,到达阳光棕榈园东门- 汽车 : 汽车执行出租车司机的操作
1、启动引擎
2、左转
3、直行
4、右转
5、停车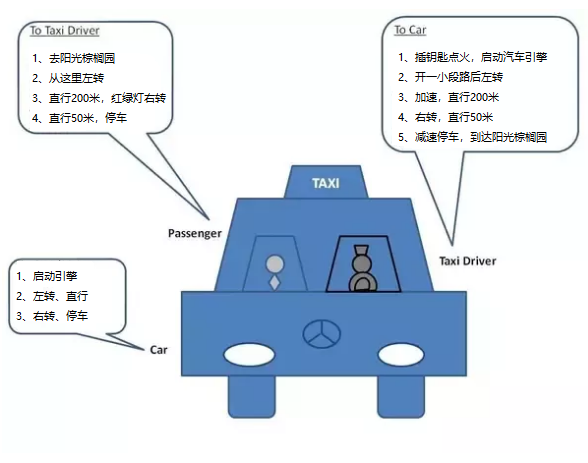
在使用Selenium WebDriver的测试自动化中,有3个角色
- 编写自动化代码的测试工程师 : 运行自动化代码将请求发送到浏览器驱动
告诉浏览器 :
1、打开 www.abc.com
2、做一个关键字搜索 selenium
3、检查实际结果,与预期结果做比较- 浏览器驱动 : 它执行测试工程师的请求,然后它向浏览器发送请求
告诉浏览器 :
1、给我打开这个页面 www.abc.com
2、当textbox显示可见,保存这个web element 3、操作textbox这个对象,输入selenium 4、当确认按钮可以点击,保存这个web element对象 5、点击这个按钮对象- 浏览器 : 它执行浏览器驱动的请求
1、打开www.abc.com
2、找到搜索框textbox,输入selenium 3、点击搜索按钮 4、展示搜索结果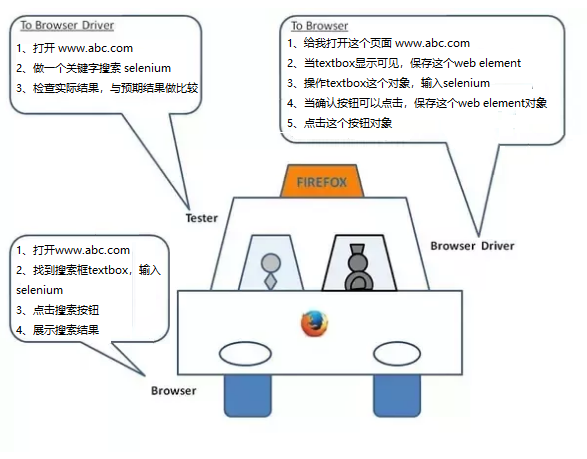
做一个类比:
- 测试工程师就像客户
- 浏览器驱动就像一个出租车司机
- 浏览器就像一辆车租车
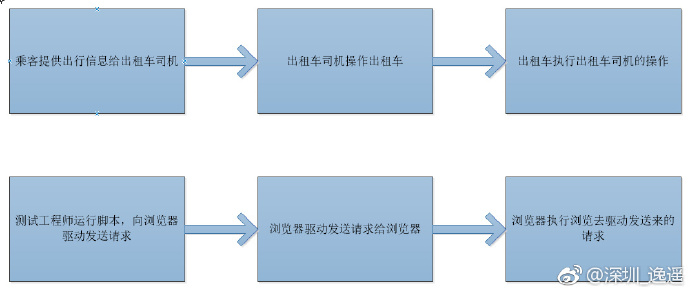
执行自动化脚本,会执行以下步骤:
- 对于每个Selenium命令,都会创建一个HTTP请求并将其发送到浏览器驱动程序
- 浏览器驱动使用HTTP服务器来获取HTTP请求
- HTTP服务器确定实现Selenium命令所需的步骤
- 实现步骤在浏览器上执行
- 执行状态被发送回HTTP服务器
- 在HTTP服务器返回该状态的自动化脚本
今天的关于使用Java在Selenium WebDriver和Selenium 2中向上或向下滚动页面的分享已经结束,谢谢您的关注,如果想了解更多关于java – chrome无法在Selenium Webdriver中运行.我使用的是selenium 3.0.1 chrome v-54.0、JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测、Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效、Selenium WebDriver原理(一):Selenium WebDriver 是怎么工作的?的相关知识,请在本站进行查询。
本文标签:




