对于了解Celery任务预取感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解celery获取任务状态,并且为您提供关于celery分布式异步任务框架(celery简单使用、celery多任务
对于了解Celery任务预取感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解celery获取任务状态,并且为您提供关于celery 分布式异步任务框架(celery简单使用、celery多任务结构、celery定时任务、celery计划任务、celery在Django项目中使用Python脚本调用Django环境)、Celery任务列表执行、celery任务和自定义装饰器、Celery任务队列的宝贵知识。
本文目录一览:- 了解Celery任务预取(celery获取任务状态)
- celery 分布式异步任务框架(celery简单使用、celery多任务结构、celery定时任务、celery计划任务、celery在Django项目中使用Python脚本调用Django环境)
- Celery任务列表执行
- celery任务和自定义装饰器
- Celery任务队列
")
了解Celery任务预取(celery获取任务状态)
我刚刚发现了有关配置选项CELERYD_PREFETCH_MULTIPLIER(docs)的信息。默认值为4,但是(我相信)我希望预取尽可能少。我现在将其设置为1,这与我要查找的值足够接近,但是仍有一些我不理解的地方:
为什么这样预取一个好主意?我并没有真正找到原因,除非消息队列和工作线程之间存在大量延迟(就我而言,它们当前正在同一主机上运行,最糟糕的是最终可能在同一数据中的不同主机上运行)中央)。该文档仅提到了缺点,但没有解释优点是什么。
许多人似乎将此设置为0,期望能够以这种方式关闭预取功能(我认为这是一个合理的假设)。但是,0表示无限的预取。为什么有人会想要无限的预取,而这并不能完全消除您最初为任务队列引入的并发/异步性呢?
为什么不能关闭预取?在大多数情况下,关闭性能可能不是一个好主意,但是有没有技术上的理由无法做到这一点?还是只是没有实施?
有时,此选项连接到
CELERY_ACKS_LATE。例如。罗杰·胡(Roger Hu)写道«[…]通常,[用户]真正想要的是让一个工人只保留与子进程一样多的任务。但是,如果不启用较晚的确认,就不可能做到这一点[…]»我不明白这两个选项是如何连接的,以及为什么一个选项不能没有另一个选项是不可能的。可以在这里找到有关连接的另一个提示。有人可以解释为什么两个选项连接在一起吗?
答案1
小编典典预取可以提高性能。工人无需等待来自代理的下一条消息即可处理。与代理进行一次通信并处理大量消息可提高性能。与本地内存访问相比,从代理(甚至从本地代理)获取消息的成本很高。还允许工人分批确认消息
将预取设置为零意味着“没有特定限制”,而不是无限
据记载,将预取设置为1等同于将其关闭,但这并非总是如此(请参阅:
只是警告:在对Redis经纪人+ Celery 3.1.15进行测试时,我阅读的有关CELERYD_PREFETCH_MULTIPLIER = 1禁用预取的所有建议显然都是错误的。
为了证明这一点:
- 组
CELERYD_PREFETCH_MULTIPLIER = 1 - 排队5个任务,每个任务将花费几秒钟的时间(例如,time.sleep(5))
开始在Redis中观察任务队列的长度:
watch redis-cli -c llen default开始
celery worker -c 1请注意,Redis中的队列长度将立即从5降至
3``CELERYD_PREFETCH_MULTIPLIER = 1`不会阻止预取,它只是将预取限制为每个队列1个任务。
-Ofair,尽管文档中说什么,也不会阻止预取。
除了修改源代码外,我还没有找到完全禁用预取的任何方法。
- 预取允许分批确认消息。CELERY_ACKS_LATE =当邮件到达工作人员时,True阻止确认邮件
")
celery 分布式异步任务框架(celery简单使用、celery多任务结构、celery定时任务、celery计划任务、celery在Django项目中使用Python脚本调用Django环境)
一.celery简介
Celery 是一个强大的 分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。我们通常使用它来实现异步任务(async task)和定时任务(crontab)。
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
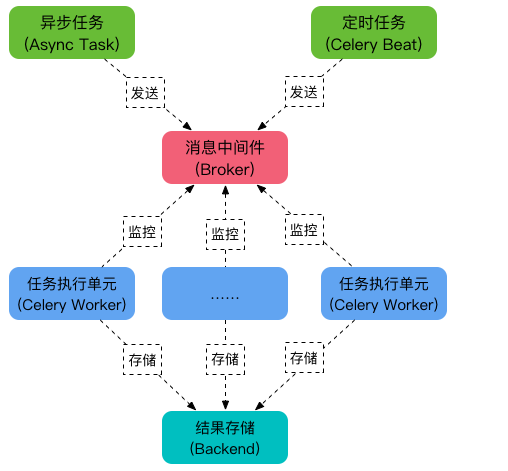
可以看到,Celery 主要包含以下几个模块:
-
任务模块 Task
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
-
消息中间件 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
-
任务执行单元 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
-
任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, redis 和 MongoDB 等。
所以总结一下celery:它是一个处理大量消息的分布式系统,能异步任务、定时任务,使用场景一般用于耗时操作的多任务或者定时性的任务。
二.celery安装与使用
pycharm安装:
pip3 install celery初步使用:(创建一个python项目)
① 实例化一个celery对象,使用该对象.task装饰需要管理的任务函数:
# celery_task.py
from celery import Celery
"""
# 如果redis没有设置密码
broker = ''redis://127.0.0.1:6379/1''
backend = ''redis://127.0.0.1:6379/2''
"""
broker = ''redis://:12345@127.0.0.1:6379/1''
backend = ''redis://:12345@127.0.0.1:6379/2''
# c1是实例化产生的celery的名字,因为会存在多个celery
app = Celery(''c1'', broker=broker, backend=backend)
# 需要使用一个装饰器,来管理该任务(函数)
@app.task
def add(x, y):
import time
time.sleep(1)
return x + y② 将装饰的任务函数条件到消息队列中,此时提交的任务函数并没有执行,只是提交到worker,它会返回一个标识任务的字符串
# submit.task.py
# 用于提交任务
from celery_task import add
# 提交任务到消息队列中,这里只是将任务提交,并没有执行
res = add. delay(3, 8)
print(res)
# 结果是标识任务的字符串(id号)
# 7811a028-428c-4dd5-9135-788e26e694a7③ 使用命令启动worker去刚才提交的执行任务
linux: celery worker -A celery_task -l info
windows下:celery worker -A celery_task -l info -P eventlet④ 查看结果,根据提交任务返回的字符串去查询
from celery.result import AsyncResult
from celery_task import app
async = AsyncResult(id=''bd600820-9366-4220-a679-3e435ae91e71'', app=app)
if async.successful():
result = async.get()
print(result)
elif async.failed():
print(''执行失败'')
elif async.status == ''PENDING'':
print(''任务等待中'')
elif async.status == ''RETRY'':
print(''任务异常后重试'')
elif async.status == ''STARTED'':
print(''任务正在执行'')
celery简单使用流程:
-celery的使用
-pip3 install celery
-写一个py文件:celery_task
-1 指定broker(消息中间件),指定backend(结果存储)
-2 实例化产生一个Celery对象 app=Celery(''名字'',broker,backend)
-3 加装饰器绑定任务,在函数(add)上加装饰器app.task
-4 其他程序提交任务,先导入add,add.delay(参,参数),会将该函数提交到消息中间件,但是并不会执行,有个返回值,直接print会打印出任务的id,以后用id去查询任务是否执行完成
-5 启动worker去执行任务:
linux: celery worker -A celery_task_s1 -l info
windows下:celery worker -A celery_task_s1 -l info -P eventlet
-6 查看结果:根据id去查询
async = AsyncResult(id="bd600820-9366-4220-a679-3e435ae91e71", app=app)
if async.successful():
#取出它return的值
result = async.get()
print(result)celery的多任务
# celery的多任务结构
-项目结构:
pro_cel
├── celery_task# celery相关文件夹
│ ├── celery.py # celery连接和配置相关文件,必须叫这个名字
│ └── tasks1.py # 所有任务函数
│ └── tasks2.py # 所有任务函数
├── check_result.py # 检查结果
└── send_task.py # 触发任务
-启动worker,celery_task是包的名字
celery worker -A celery_task -l info -P eventlet按照多任务文件结构创建文件:
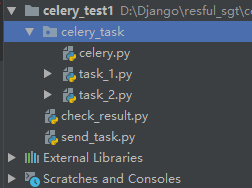
注意celery.py这个文件的文件名是固定的,不能改,task_1和task_2可以自己定义,他俩代表自定义的任务分类,还可以再创建task_3。。。等其它名字的任务文件,send_task.py是提交任务到worker,check_result.py是查看结果的
# celery.py
from celery import Celery
broker = ''redis://:12345@127.0.0.1:6379/1''
backend = ''redis://:12345@127.0.0.1:6379/2''
# c1是实例化产生的celery的名字,因为会存在多个celery
app = Celery(''c1'', broker=broker, backend=backend,
# 包含一些2个任务文件,去相应的py文件找任务,对多个任务进行分类
include=[
''celery_task.task_1'',
''celery_task.task_2'',
])
# celery提供一些配置,具体可查看官方文档
# app.conf.timezone = ''Asia/Shanghai''在send_task.py种右键运行,提交任务到worker(这里打印了提交的2个任务的id)
# task_1.py
from celery_task.celery import app
@app.task
def add1(x, y):
import time
time.sleep(0.5)
return x + y
# task_2.py
from celery_task.celery import app
@app.task
def add2(x, y):
import time
time.sleep(1)
return x * y# send_task.py
from celery_task.task_1 import add1
from celery_task.task_2 import add2
res1 = add1.delay(3, 8)
print(res1) # 16e847f3-fc14-4391-89e2-e2b3546872cf
res2 = add2.delay(4, 9)
print(res2) # 858c0ae5-8516-4473-8be5-7501fb856ff4启动worker,celery_task是包的名字
celery worker -A celery_task -l info -P eventlet
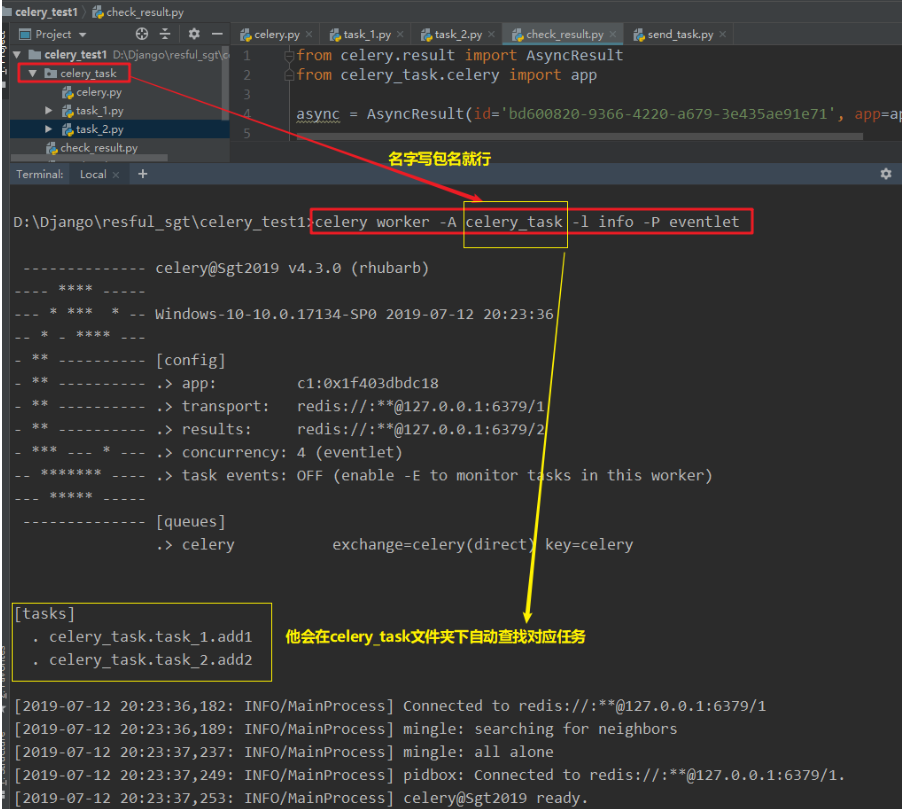
然后将打印的2个id在check_result.py中进行查询结果
# check_reslut.py
from celery.result import AsyncResult
from celery_task.celery import app
for i in [''16e847f3-fc14-4391-89e2-e2b3546872cf'', ''858c0ae5-8516-4473-8be5-7501fb856ff4'']:
async = AsyncResult(id=i, app=app)
if async.successful():
result = async.get()
print(result)
elif async.failed():
print(''执行失败'')
elif async.status == ''PENDING'':
print(''任务等待中'')
elif async.status == ''RETRY'':
print(''任务异常后重试'')
elif async.status == ''STARTED'':
print(''任务正在执行'')
celery的定时任务
方式一:执行时间在年月日时分秒
在提交任务的地方修改:
# send_task.py
from celery_task.task_1 import add1
from celery_task.task_2 import add2
# 执行定时任务,3s以后执行add1、add2任务
from datetime import datetime
# 设置任务执行时间2019年7月12日21点45分12秒
v1 = datetime(2019, 7, 12, 21, 48, 12)
print(v1) # 2019-07-12 21:45:12
# 将v1时间转成utc时间
v2 = datetime.utcfromtimestamp(v1.timestamp())
print(v2) # 2019-07-12 13:45:12
# 取出要执行任务的时间对象,调用apply_async方法,args是任务函数传的参数,eta是执行的时间
result1 = add1.apply_async(args=[3, 8], eta=v2)
result2 = add2.apply_async(args=[4, 9], eta=v2)
print(result1.id)
print(result2.id)方式二:通过延迟执行的时间算出执行的具体utc时间,与方式一基本相同
# send_task.py
# 方式二:实际上和方法一类似,多了一个延迟时间,也就是用现在时间和推迟执行的时间计算出任务执行的最终utc时间
# 然后也是调用apply_async方法。
from datetime import datetime
ctime = datetime.now()
# 默认使用utc时间
utc_ctime = datetime.utcfromtimestamp(ctime.timestamp())
from datetime import timedelta
# 使用timedelta模块,拿到10秒后的时间对象,这里参数可以传秒、毫秒、微秒、分、小时、周、天
time_delay = timedelta(seconds=10)
# 得到任务运行时间:
task_time = utc_ctime + time_delay
result1 = add1.apply_async(args=[3, 8], eta=task_time)
result2 = add2.apply_async(args=[4, 9], eta=task_time)
print(result1.id)
print(result2.id)celery的计划任务
计划任务需要在celery.py中添加代码,然后需要beat一下,才能将计划开启
# celery.py中
from celery import Celery
broker = ''redis://:12345@127.0.0.1:6379/1''
backend = ''redis://:12345@127.0.0.1:6379/2''
# c1是实例化产生的celery的名字,因为会存在多个celery
app = Celery(''c1'', broker=broker, backend=backend,
# 包含一些2个任务文件,去相应的py文件找任务,对多个任务进行分类
include=[
''celery_task.task_1'',
''celery_task.task_2'',
''celery_task.task_3'',
])
# celery提供一些配置,具体可查看官方文档
# app.conf.timezone = "Asia/Shanghai"
# app.conf.enable_utc = True
# 计划任务
from datetime import timedelta
from celery.schedules import crontab
app.conf.beat_schedule = {
''submit_every_2_seconds'': {
# 计划的任务执行函数
''task'': ''celery_task.task_1.add1'',
# 每个2秒执行一次
''schedule'': timedelta(seconds=2),
# 传递的任务函数参数
''args'': (3, 9)
},
''submit_every_3_seconds'': {
# 计划的任务执行函数
''task'': ''celery_task.task_2.add2'',
# 每个3秒执行一次
''schedule'': timedelta(seconds=3),
# 传递的任务函数参数
''args'': (4, 7)
},
''submit_in_fix_datetime'': {
''task'': ''celery_task.task_3.add3'',
# 比如每年的7月13日10点53分执行
# 注意:默认使用utc时间,当前的时间中的小时必须要-8个小时才会到点提交
''schedule'': crontab(minute=53, hour=2, day_of_month=13, month_of_year=7),
''''''
# 如果不想-8,可以先设置时区,再按正常时间设置
app.conf.timezone = "Asia/Shanghai"
app.conf.enable_utc = True
''''''
''args'': (''Hello World'',)
}
}
# 上面写完后,需要起一个进程,启动计划任务
# celery beat -A celery_task -l info
# 启动worker:
# celery worker -A celery_task -l info -P eventletDjango中使用celery
django-celery:由于djang-celery模块对版本的要求过于严格,而且容易出现很多bug,所以不建议使用
直接使用celery多任务结构的,将celery多任务结构的代码文件夹celery_task拷贝到Django项目中,然后在视图函数中进行任务提交、然后进行结构查看。(启动项目时候记得将worker启动起来,注意启动路径要跟你拷贝的celery_task文件同级)
注意:当我们在Django项目中使用celery,在celery的任务函数中不能直接调用django的环境(比如orm方法查询数据库),需要添加代码调用Django环境
在Python脚本中调用Django环境
import os
# 加载Django环境,bbs是所在的Django项目名称
os.environ.setdefault("DJANGO_SETTINGS_MODULE", ''bbs.settings'')
# 引入Django模块
import django
# 初始化Django环境
django.setup()
# 从app当中导入models
from app01 import models
# 调用操作,拿到数据库中的所有Book数据对象
books = models.Books.objects.all()

Celery任务列表执行
创建计划任务:
from celery import Celery
import time
my_task=Celery("task",broker="redis://:123456@127.0.0.1:6379",backend="redis://:123456@127.0.0.1:6379")
@my_task.task
def my_func1():
time.sleep(10)
return "任务1"
@my_task.task
def my_func2():
return "任务2"
@my_task.task
def my_func3():
return "任务"调用方法执行指定的任务:
from s1 import my_func1
res=my_func1.delay()
print(res)获取返回值中运行计划的ID
判断计划是否执行完成:
from celery.result import AsyncResult
from s1 import my_task
async_task=AsyncResult(id="48029f4f-769e-438b-ac97-e89cc0bb1157",app=my_task)
# result=async_task.get()
if async_task.successful():
result=async_task.get()
print(result+"OK!")
else:
print("任务还未执行完成!")启动celery在命令行执行: Celery worker -A s1 -l INFO -P eventlet -c 6
-A:指定要执行的目录
-l: 指定要使用的打印日志级别
-p:指定使用eventlet插件 让高版本celery支持window平台
-c:指定可执行的计划数量

celery任务和自定义装饰器
如何解决celery任务和自定义装饰器?
不太确定为什么传递参数无效?
如果使用此示例:
@task()
def add(x, y):
return x + y
让我们向MyCoolTask添加一些日志记录:
from celery import task
from celery.registry import tasks
import logging
import celery
logger = logging.getLogger(__name__)
class MyCoolTask(celery.Task):
def __call__(self, *args, **kwargs):
"""In celery task this function call the run method, here you can
set some environment variable before the run of the task"""
logger.info("Starting to run")
return self.run(*args, **kwargs)
def after_return(self, status, retval, task_id, args, kwargs, einfo):
#exit point of the task whatever is the state
logger.info("Ending run")
pass
并创建一个扩展类(扩展MyCoolTask,但现在带有参数):
class AddTask(MyCoolTask):
def run(self,x,y):
if x and y:
result=add(x,y)
logger.info(''result = %d'' % result)
return result
else:
logger.error(''No x or y in arguments'')
tasks.register(AddTask)
并确保将kwargs作为json数据传递:
{"x":8,"y":9}
我得到结果:
[2019-03-05 17:30:25,853: INFO/MainProcess] Starting to run
[2019-03-05 17:30:25,855: INFO/MainProcess] result = 17
[2019-03-05 17:30:26,739: INFO/MainProcess] Ending run
[2019-03-05 17:30:26,741: INFO/MainProcess] Task iamscheduler.tasks.AddTask[6a62641d-16a6-44b6-a1cf-7d4bdc8ea9e0] succeeded in 0.888684988022s: 17
解决方法
我正在使用django和celery(django-celery)进行项目。我们的团队决定将所有数据访问代码(app-name)/manager.py包装在其中(不要像django这样包装到Manager中),而将代码放入(应用程序名称)/task.py中,仅处理用celery组装和执行任务(因此我们没有django在这一层的ORM依赖性)。
在我的manager.py,我有这样的事情:
def get_tag(tag_name):
ctype = ContentType.objects.get_for_model(Photo)
try:
tag = Tag.objects.get(name=tag_name)
except ObjectDoesNotExist:
return Tag.objects.none()
return tag
def get_tagged_photos(tag):
ctype = ContentType.objects.get_for_model(Photo)
return TaggedItem.objects.filter(content_type__pk=ctype.pk,tag__pk=tag.pk)
def get_tagged_photos_count(tag):
return get_tagged_photos(tag).count()
在我的task.py中,我喜欢将它们包装成任务(然后可以使用这些任务来完成更复杂的任务),因此我编写了这个装饰器:
import manager #the module within same app containing data access functions
class mfunc_to_task(object):
def __init__(mfunc_type=''get''):
self.mfunc_type = mfunc_type
def __call__(self,f):
def wrapper_f(*args,**kwargs):
callback = kwargs.pop(''callback'',None)
mfunc = getattr(manager,f.__name__)
result = mfunc(*args,**kwargs)
if callback:
if self.mfunc_type == ''get'':
subtask(callback).delay(result)
elif self.mfunc_type == ''get_or_create'':
subtask(callback).delay(result[0])
else:
subtask(callback).delay()
return result
return wrapper_f
然后(仍在task.py):
#@task
@mfunc_to_task()
def get_tag():
pass
#@task
@mfunc_to_task()
def get_tagged_photos():
pass
#@task
@mfunc_to_task()
def get_tagged_photos_count():
pass
一切正常@task。但是,在应用了该@task装饰器之后(按照celery文档的指示放到顶部),事情就开始崩溃了。显然,每次mfunc_to_task.__call__调用时,task.get_tag都会传递与相同的函数f。所以我wrapper_f每次都得到相同的结果,现在我唯一要做的就是得到一个标签。

Celery任务队列
文档
- 中文文档
- 官方文档
- celery定时服务、celery与django结合使用
简介
Celery 是一个“自带电池”的的任务队列。它易于使用,所以你可以无视其所解决问题的复杂程度而轻松入门。它遵照最佳实践设计,所以你的产品可以扩展,或与其他语言集成,并且它自带了在生产环境中运行这样一个系统所需的工具和支持。
Celery 的最基础部分。包括:
-
选择和安装消息传输方式(中间人)----broker,如RabbitMQ,redis等。
- RabbitMQ的安装:sudo apt-get install rabbitmq-server
- 本文使用redis
- 官方推荐RabbitMQ
- 当然部分nosql也可以
- 安装 Celery 并创建第一个任务
- 运行职程并调用任务。
- 追踪任务在不同状态间的迁移,并检视返回值。
安装
pip install celery简单使用
定义任务
tasks.py
from celery import Celery
#第一个参数是你的celery名称
#backen 用于存储结果
#broker 用于存储消息队列
app = Celery(''tasks'',backend=''redis://:password@host:port/db'', broker=''redis://:password@host:port/db'')
@app.task
def add(x, y):
return x + yCelery 的第一个参数是当前模块的名称,这个参数是必须的,这样的话名称可以自动生成。第二个参数是中间人关键字参数,指定你所使用的消息中间人的 URL,此处使用了 RabbitMQ,也是默认的选项。更多可选的中间人见上面的 选择中间人 一节。例如,对于 RabbitMQ 你可以写 amqp://localhost ,而对于 Redis 你可以写 redis://localhost .
你定义了一个单一任务,称为 add ,返回两个数字的和。
启动celery服务
步骤:
- 启动任务工作者worker
- 讲任务放入celery队列
- worker读取队列,并执行任务
启动一个工作者,创建一个任务队列
// -A 指定celery名称,loglevel制定log级别,只有大于或等于该级别才会输出到日志文件
celery -A tasks worker --loglevel=info如果你没有安装redis库,请先pip install redis
使用celery
现在我们已经有一个celery队列了,我门只需要将工作所需的参数放入队列即可
from tasks import add
#调用任务会返回一个 AsyncResult 实例,可用于检查任务的状态,等待任务完成或获取返回值(如果任务失败,则为异常和回溯)。
#但这个功能默认是不开启的,你需要设置一个 Celery 的结果后端(即backen,我们在tasks.py中已经设置了,backen就是用来存储我们的计算结果)
result=add.delay(4, 4)
#如果任务已经完成
if(result.ready()):
#获取任务执行结果
print(result.get(timeout=1))常用接口
- tasks.add(4,6) ---> 本地执行
- tasks.add.delay(3,4) --> worker执行
- t=tasks.add.delay(3,4) --> t.get() 获取结果,或卡住,阻塞
- t.ready()---> False:未执行完,True:已执行完
- t.get(propagate=False) 抛出简单异常,但程序不会停止
- t.traceback 追踪完整异常
使用配置
- 使用配置来运行,对于正式项目来说可维护性更好。配置可以使用app.config.XXXXX_XXX=''XXX''的形式如app.conf.CELERY_TASK_SERIALIZER = ''json''来进行配置
- 配置资料
配置文件
config.py
#broker
BROKER_URL = ''redis://:password@host:port/db''
#backen
CELERY_RESULT_BACKEND = ''redis://:password@host:port/db''
#导入任务,如tasks.py
CELERY_IMPORTS = (''tasks'', )
#列化任务载荷的默认的序列化方式
CELERY_TASK_SERIALIZER = ''json''
#结果序列化方式
CELERY_RESULT_SERIALIZER = ''json''
CELERY_ACCEPT_CONTENT=[''json'']
#时间地区与形式
CELERY_TIMEZONE = ''Europe/Oslo''
#时间是否使用utc形式
CELERY_ENABLE_UTC = True
#设置任务的优先级或任务每分钟最多执行次数
CELERY_ROUTES = {
# 如果设置了低优先级,则可能很久都没结果
#''tasks.add'': ''low-priority'',
#''tasks.add'': {''rate_limit'': ''10/m''},
#''tasks.add'': {''rate_limit'': ''10/s''},
#''*'': {''rate_limit'': ''10/s''}
}
#borker池,默认是10
BROKER_POOL_LIMIT = 10
#任务过期时间,单位为s,默认为一天
CELERY_TASK_RESULT_EXPIRES = 3600
#backen缓存结果的数目,默认5000
CELERY_MAX_CACHED_RESULTS = 10000开启服务
celery.py
from celery import Celery
#指定名称
app = Celery(''mycelery'')
#加载配置模块
app.config_from_object(''config'')
if __name__==''__main__'':
app.start()任务定义
tasks.py
from .celery import app
@app.task
def add(a, b):
return a + b启动
// -l 是 --loglevel的简写
celery -A mycelery worker -l info执行/调用服务
from tasks import add
#调用任务会返回一个 AsyncResult 实例,可用于检查任务的状态,等待任务完成或获取返回值(如果任务失败,则为异常和回溯)。
#但这个功能默认是不开启的,你需要设置一个 Celery 的结果后端(即backen,我们在tasks.py中已经设置了,backen就是用来存储我们的计算结果)
result=add.delay(4, 4)
#如果任务已经完成
if(result.ready()):
#获取任务执行结果
print(result.get(timeout = 1))分布式
-
启动多个celery worker,这样即使一个worker挂掉了其他worker也能继续提供服务
- 方法一
// 启动三个worker:w1,w2,w3 celery multi start w1 -A project -l info celery multi start w2 -A project -l info celery multi start w3 -A project -l info // 立即停止w1,w2,即便现在有正在处理的任务 celery multi stop w1 w2 // 重启w1 celery multi restart w1 -A project -l info // celery multi stopwait w1 w2 w3 # 待任务执行完,停止- 方法二
// 启动多个worker,但是不指定worker名字 // 你可以在同一台机器上运行多个worker,但要为每个worker指定一个节点名字,使用--hostname或-n选项 // concurrency指定处理进程数,默认与cpu数量相同,因此一般无需指定 $ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker1@%h $ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker2@%h $ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker3@%h
错误处理
celery可以指定在发生错误的情况下进行自定义的处理
config.py
def my_on_failure(self, exc, task_id, args, kwargs, einfo):
print(''Oh no! Task failed: {0!r}''.format(exc))
// 对所有类型的任务,当发生执行失败的时候所执行的操作
CELERY_ANNOTATIONS = {''*'': {''on_failure'': my_on_failure}} 我们今天的关于了解Celery任务预取和celery获取任务状态的分享已经告一段落,感谢您的关注,如果您想了解更多关于celery 分布式异步任务框架(celery简单使用、celery多任务结构、celery定时任务、celery计划任务、celery在Django项目中使用Python脚本调用Django环境)、Celery任务列表执行、celery任务和自定义装饰器、Celery任务队列的相关信息,请在本站查询。
本文标签:




