本文将分享Java为什么不建议使用StringTokenizer?的详细内容,并且还将对javastringutils不能用进行详尽解释,此外,我们还将为大家带来关于14.Java中的StringTo
本文将分享Java为什么不建议使用StringTokenizer?的详细内容,并且还将对java stringutils不能用进行详尽解释,此外,我们还将为大家带来关于14.Java中的StringTokenizer类的使用方法、AG 百家家乐最新官网《 787977.tv 飞机 @gb560 》stringtokenizer java,Java 中的 StringTokenizer「建议收藏」、java java中subString、split、stringTokenizer三种截取字符串方法的性能比较、JAVA StringBuffer类与StringTokenizer类代码解析的相关知识,希望对你有所帮助。
本文目录一览:- Java为什么不建议使用StringTokenizer?(java stringutils不能用)
- 14.Java中的StringTokenizer类的使用方法
- AG 百家家乐最新官网《 787977.tv 飞机 @gb560 》stringtokenizer java,Java 中的 StringTokenizer「建议收藏」
- java java中subString、split、stringTokenizer三种截取字符串方法的性能比较
- JAVA StringBuffer类与StringTokenizer类代码解析
")
Java为什么不建议使用StringTokenizer?(java stringutils不能用)
Java文档似乎并未提及有关的弃用的任何内容StringTokenizer,但我一直很早就听说过它的弃用情况。是因为它具有错误/错误而被弃用,还是String.split()整体上更好使用?
我有一些使用的代码,StringTokenizer我想知道我是否应该认真考虑将其重构为使用String.split(),还是弃用纯粹是为了方便而我的代码是安全的。
答案1
小编典典从javadoc中获取StringTokenizer:
StringTokenizer是旧类,出于兼容性原因保留,尽管在新代码中不鼓励使用它。建议任何寻求此功能的人改用String的split方法或java.util.regex软件包。
如果你String.split()将其与进行比较StringTokenizer,则相关的区别是String.split()使用正则表达式,而StringTokenizer仅使用逐字分割字符。因此,如果我想用比单个字符更复杂的逻辑来标记字符串(例如,分割开\r\n),则不能使用,StringTokenizer但可以使用String.split()。

14.Java中的StringTokenizer类的使用方法
StringTokenizer是字符串分隔解析类型,属于:java.util包。
1.StringTokenizer的构造函数
StringTokenizer(String str):构造一个用来解析str的StringTokenizer对象。java默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”。
StringTokenizer(String str,String delim):构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符。
StringTokenizer(String str,String delim,boolean returnDelims):构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符,同时,指定是否返回分隔符。
2.StringTokenizer的一些常用方法
说明:
1.所有方法均为public;
2.书写格式:[修饰符] <返回类型><方法名([参数列表])>
int countTokens():返回nextToken方法被调用的次数。
boolean hasMoreTokens():返回是否还有分隔符。
boolean hasMoreElements():返回是否还有分隔符。
String nextToken():返回从当前位置到下一个分隔符的字符串。
Object nextElement():返回从当前位置到下一个分隔符的字符串。
String nextToken(String delim):与4类似,以指定的分隔符返回结果。
String s=new String("The Java platform is the ideal platform for network computing");
StringTokenizer st=new StringTokenizer(s);
System.out.println("Token Total:"+st.countTokens());
while ( st.hasMoreElements() ){
System.out.println(st.nextToken());
}
String s=new String("The=Java=platform=is=the=ideal=platform=for=network=computing");
StringTokenizer st=new StringTokenizer(s,"=",true);
System.out.println("Token Total:"+st.countTokens());
while ( st.hasMoreElements() ){
System.out.println(st.nextToken());
}

AG 百家家乐最新官网《 787977.tv 飞机 @gb560 》stringtokenizer java,Java 中的 StringTokenizer「建议收藏」
大家好,又见面了,我是你们的朋友全栈君。
Java 中的 StringTokenizer
java.util.StringTokenizer 类允许您将字符串分成令牌。这是打破字符串的简单方法。
它没有提供区分数字,带引号的字符串,标识符等的功能,例如 StreamTokenizer 类。我们将在 I/O 一章中讨论 StreamTokenizer 类。
StringTokenizer 类的构造方法
StringTokenizer 类中定义了 3 个构造函数。
Constructor
Description
StringTokenizer(String str)
creates StringTokenizer with specified string.
StringTokenizer(String str, String delim)
creates StringTokenizer with specified string and delimeter.
StringTokenizer(String str, String delim, boolean returnValue)
creates StringTokenizer with specified string, delimeter and returnValue. If return value is true, delimiter characters are considered to be tokens. If it is false, delimiter characters serve to separate tokens.
StringTokenizer 类的方法
StringTokenizer 类的 6 个有用方法如下:
Public method
Description
boolean hasMoreTokens()
checks if there is more tokens available.
String nextToken()
returns the next token from the StringTokenizer object.
String nextToken(String delim)
returns the next token based on the delimeter.
boolean hasMoreElements()
same as hasMoreTokens() method.
Object nextElement()
same as nextToken() but its return type is Object.
int countTokens()
returns the total number of tokens.
StringTokenizer 类的简单示例
让我们看一下 StringTokenizer 类的简单示例,该类在空格的基础上标记字符串 “我的名字是可汗”。
StringTokenizer 类的 nextToken (String delim) 方法的示例
现在不建议使用 StringTokenizer 类。建议使用 String 类或 regex (正则表达式) 的 split () 方法。
0
相关文章:Java 中的 JVM 的关闭挂钩 关闭挂钩是一种特殊的结构,允许开发人员插入要在 JVM 关闭时执行的代码。这在需要关闭 VM 的情况下需要执行特殊清理 […]…
Java 中的 for-each 循环 For-each 是 Java5 中引入的另一种数组遍历技术,例如 for 循环,while 循环,do-while 循环。 […]…
在 Java 中使用_(下划线) 作为变量名 Java 9 对 Java 语言的功能进行了更改,而从合法名称中删除下划线是甲骨文 Oracle 的一项重大更改: 绝不 […]…
了解 Java 中 “public static void main” 中的 “ static” 以下几点解释了 main () 方法中的 “static”: main () 方法:Java 中的 main () 方 […]…
Java 中的按位运算符 按位运算符用于对数字的各个位进行操作。它们可以与任何整数类型 (char,short,int 等) 一起使用。在执行 […]…
修剪 Java 中的字符串 (删除前导和尾随空格) 给定字符串,请从字符串中删除所有前导和尾随空格,然后将其返回。 例子: Input : str = ” Hel […]…
Java 中的 volatile 关键字 使用 volatile 是使类线程安全的另一种方式 (如同步的原子包装)。线程安全意味着一个方法或类实例可以被多个线 […]…
Java 中的构造函数链接 (带示例) 先决条件: Java 中的构造函数 构造函数链接是相对于当前对象从另一个构造函数调用一个构造函数的过程。 构造函 […]…

java java中subString、split、stringTokenizer三种截取字符串方法的性能比较
最近在阅读java.lang下的源码,读到String时,突然想起面试的时候曾经被人问过:都知道在大数据量情况下,使用String的split截取字符串效率很低,有想过用其他的方法替代吗?用什么替代?我当时的回答很斩钉截铁:没有。
google了一下,发现有2中替代方法,于是在这里我将对这三种方式进行测试。
测试的软件环境为:Windows XP、eclipse、JDK1.6。
测试用例使用类ip形式的字符串,即3位一组,使用”.”间隔。数据分别使用:5组、10组、100组、1000组、10000组、100000组。
实现
闲话不说,先上代码:
package test.java.lang.ref;
import java.util.Random;
import java.util.StringTokenizer;
/**
* String测试类
* @author xiaori.Liu
*
*/
public class StringTest {
public static void main(String args[]){
String orginStr = getOriginStr(10);
//////////////String.splic()表现//////////////////////////////////////////////
System.out.println("使用String.splic()的切分字符串");
long st1 = System.nanoTime();
String [] result = orginStr.split("\\.");
System.out.println("String.splic()截取字符串用时:" + (System.nanoTime()-st1));
System.out.println("String.splic()截取字符串结果个数:" + result.length);
System.out.println();
//////////////StringTokenizer表现//////////////////////////////////////////////
System.out.println("使用StringTokenizer的切分字符串");
long st3 = System.nanoTime();
StringTokenizer token=new StringTokenizer(orginStr,".");
System.out.println("StringTokenizer截取字符串用时:"+(System.nanoTime()-st3));
System.out.println("StringTokenizer截取字符串结果个数:" + token.countTokens());
System.out.println();
////////////////////String.substring()表现//////////////////////////////////////////
long st5 = System.nanoTime();
int len = orginStr.lastIndexOf(".");
System.out.println("使用String.substring()切分字符串");
int k=0,count=0;
for (int i = 0; i <= len; i++) {
if(orginStr.substring(i, i+1).equals(".")){
if(count==0){
orginStr.substring(0, i);
}else{
orginStr.substring(k+1, i);
if(i == len){
orginStr.substring(len+1, orginStr.length());
}
}
k=i;count++;
}
}
System.out.println("String.substring()截取字符串用时"+(System.nanoTime()-st5));
System.out.println("String.substring()截取字符串结果个数:" + (count + 1));
}
/**
* 构造目标字符串
* eg:10.123.12.154.154
* @param len 目标字符串组数(每组由3个随机数组成)
* @return
*/
private static String getOriginStr(int len){
StringBuffer sb = new StringBuffer();
StringBuffer result = new StringBuffer();
Random random = new Random();
for(int i = 0; i < len; i++){
sb.append(random.nextInt(9)).append(random.nextInt(9)).append(random.nextInt(9));
result.append(sb.toString());
sb.delete(0, sb.length());
if(i != len-1)
result.append(".");
}
return result.toString();
}
}
改变目标数据长度修改getOriginStr的len参数即可。
5组测试数据结果如下图:

下面这张图对比了下,split耗时为substring和StringTokenizer耗时的倍数:
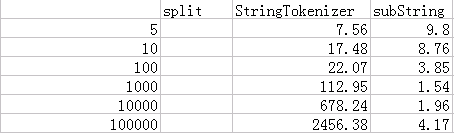
好吧,我又花了点儿时间,做了几张图表来分析这3中方式的性能。
首先来一张柱状图对比一下这5组数据截取所花费的时间:
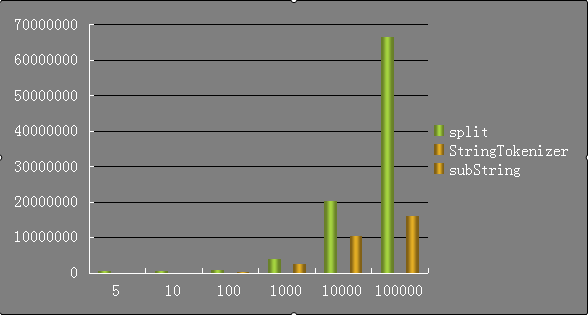
从上图可以看出StringTokenizer的性能实在是太好了(对比另两种),几乎在图表中看不见它的身影。遥遥领先。substring花费的时间始终比split要少,但是耗时也在随着数据量的增加而增加。
下面3张折线图可以很明显看出split、substring、StringTokenizer3中实现随着数据量增加,耗时的趋势。
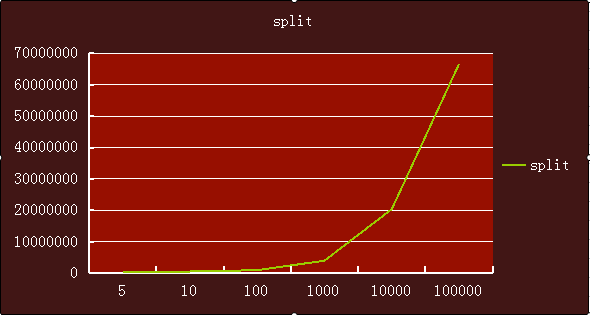
split是变化最大的,也就是数据量越大,截取所需要的时间增长越快。
substring则比split要平稳一点点,但是也在增长。
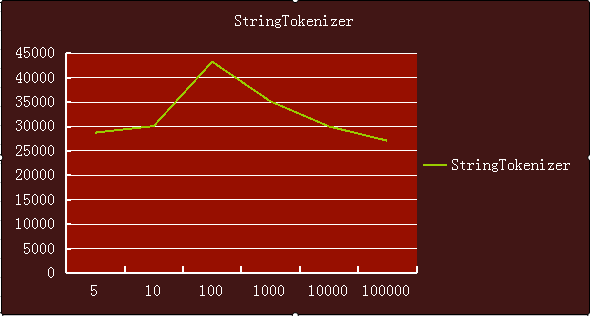
StringTokenizer则是表现最优秀的,基本上平稳,始终保持在5000ns一下。
结论
最终,StringTokenizer在截取字符串中效率最高,不论数据量大小,几乎持平。substring则要次之,数据量增加耗时也要随之增加。split则是表现最差劲的。
究其原因,split的实现方式是采用正则表达式实现,所以其性能会比较低。至于正则表达式为何低,还未去验证。split源码如下:
public String[] split(String regex, int limit) {
return Pattern.compile(regex).split(this, limit);
}
转自:http://www.congmo.net/blog/2012/02/13/1/

JAVA StringBuffer类与StringTokenizer类代码解析
StringBuffer类提供了一个字符串的可变序列,类似于String类,但它对存储的字符序列可以任意修改,使用起来比String类灵活得多。它常用的构造函数为:
StringBuffer()
构造一个空StringBuffer对象,初始容量为16个字符。
StringBuffer(Stringstr)
构造一个StringBuffer对象,初始内容为字符串str的拷贝。
对于StringBuffer类,除了String类中常用的像长度、字符串截取、字符串检索的方法可以使用之外,还有两个较为方便的方法系列,即append方法系列和insert方法系列。
(1)append方法系列根据参数的数据类型在StringBuffer对象的末尾直接进行数据添加。
public StringBuffer append(boolean b) public StringBuffer append(char c) public StringBuffer append(char[] str) public StringBuffer append(char[] str,int offset,int len) public StringBuffer append(double d) public StringBuffer append(float f) public StringBuffer append(int i) public StringBuffer append(long l) public StringBuffer append(Object obj) public StringBuffer append(String str) public StringBuffer append(StringBuffer sb)
(2) insert方法系列根据参数的数据类型在StringBuffer的offset位置进行数据插入。
public StringBuffer insert(int offset,boolean b) public StringBuffer insert(int offset,char c) public StringBuffer insert(int offset,char[] str) public StringBuffer insert(int index,char[] str,int len) public StringBuffer insert(int offset,double d) public StringBuffer insert(int offset,float f) public StringBuffer insert(int offset,int i) public StringBuffer insert(int offset,long l) public StringBuffer insert(int offset,Object obj) public StringBuffer insert(int offset,String str)
(3) 下面这个方法用于将stringbuffer对象的数据转换成字符串:
public String toString()
【例3.12】基于例3.11进行修改,使用StringBuffer对象得到如图3.10所示的输出界面。
//程序文件名为TestString.java
public class TestString
{
public static void main(String[] args)
{
StringBuffer str = new StringBuffer("The substring begins at the specified beginIndex.");
StringBuffer str1 = new StringBuffer("string");
String str2 = new String();
int size = str.length();
int flag = str.indexOf("substring");
str2 = str.substring(flag,flag + 9);
StringBuffer strOut = new StringBuffer("字符串");
strOut.append(str);
strOut.append("总长度为:");
strOut.append(size);
int f = strOut.indexOf("总");
strOut.insert(f,'\n');
System.out.println(strOut.toString());
if(str1.toString().equals(str2))
System.out.println("截取的字符串为:" + str1.toString());
else
System.out.println("截取的字符串为:" + str2);
}
}
StringTokenizer(Stringstr,Stringdelim)
使用delim分隔符,以初始字符串str构建StringTokenizer对象。
intcountTokens()
返回识别的总记号数。
booleanhasMoretokens()
测试是否还有识别的记号。
booleannextToken(Stringdelim)
返回字符串delim分隔的下一个记号。
StringnextToken()
返回下一个识别的记号。
import java.util.*;
public class Usetoken
{
public static void main(String[] args)
{
String str = "数学::英语::语文::化学";
StringTokenizer st = new StringTokenizer(str,"::");
System.out.println(str + "\n课程数为:" +st.countTokens());
while (st.hasMoretokens())
{
System.out.println(st.nextToken("::"));
}
str = "Hello this is a test";
st = new StringTokenizer(str);
System.out.println(str + "\n单词数为:" +st.countTokens());
while (st.hasMoretokens())
{
System.out.println(st.nextToken());
}
}
}
总结
以上就是本文关于JAVA StringBuffer类与StringTokenizer类代码解析的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
今天关于Java为什么不建议使用StringTokenizer?和java stringutils不能用的分享就到这里,希望大家有所收获,若想了解更多关于14.Java中的StringTokenizer类的使用方法、AG 百家家乐最新官网《 787977.tv 飞机 @gb560 》stringtokenizer java,Java 中的 StringTokenizer「建议收藏」、java java中subString、split、stringTokenizer三种截取字符串方法的性能比较、JAVA StringBuffer类与StringTokenizer类代码解析等相关知识,可以在本站进行查询。
本文标签:




