在这里,我们将给大家分享关于在SeleniumWebdriver上设置超时的知识,让您更了解selenium设置超时时间的本质,同时也会涉及到如何更有效地JavaSeleniumWebdriver:修
在这里,我们将给大家分享关于在Selenium Webdriver上设置超时的知识,让您更了解selenium设置超时时间的本质,同时也会涉及到如何更有效地JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测、selenium webdriver (5)— 超时设置、Selenium Webdriver Chromedriver在无头模式下启动时超时、Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效的内容。
本文目录一览:- 在Selenium Webdriver上设置超时(selenium设置超时时间)
- JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测
- selenium webdriver (5)— 超时设置
- Selenium Webdriver Chromedriver在无头模式下启动时超时
- Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效
")
在Selenium Webdriver上设置超时(selenium设置超时时间)
情况
我有一个简单的python脚本来获取给定URL的HTML源:
browser = webdriver.PhantomJS() browser.get(url) content = browser.page_source有时,URL指向外部资源加载缓慢的页面(例如,视频文件或非常慢的广告内容)。
在完成.get(url)请求之前,Webdriver将等待直到加载了这些资源。
注意:由于其他原因,我需要使用PhantomJS而不是requests或urllib2
问题
我想在PhantomJS资源加载上设置一个超时,以便如果资源加载时间太长,浏览器只会认为它不存在或其他原因。
这将允许我.pagesource基于浏览器已加载的内容执行后续查询。
关于webdriver.PhantomJS的文档非常薄,我还没有找到类似的问题。
提前致谢!
答案1
小编典典PhantomJS提供了resourceTimeout,可能适合您的需求。我在这里引用文档
(以毫秒为单位)定义了超时,在此超时之后,所请求的任何资源将停止尝试并继续处理页面的其他部分。onResourceTimeout回调将在超时时被调用。
因此,在Ruby中,您可以执行以下操作
require ''selenium-webdriver''capabilities = Selenium::WebDriver::Remote::Capabilities.phantomjs("phantomjs.page.settings.resourceTimeout" => "5000")driver = Selenium::WebDriver.for :phantomjs, :desired_capabilities => capabilities我相信Python,就像(未经测试,仅提供逻辑,您是Python开发人员,希望您能弄清楚)
driver = webdriver.PhantomJS(desired_capabilities={''phantomjs.page.settings.resourceTimeout'': ''5000''})
JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测
如何解决JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测?
从当前的实现开始,一种理想的访问网页而不被检测到的方法是使用ChromeOptions()该类向以下参数添加几个参数:
排除enable-automation开关的集合
关掉 useAutomationExtension
通过以下实例ChromeOptions:
Java示例:
System.setProperty("webdriver.chrome.driver", "C:\\Utility\\browserDrivers\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("excludeSwitches", Collections.singletonList("enable-automation"));
options.setExperimentalOption("useAutomationExtension", false);
WebDriver driver = new ChromeDriver(options);
driver.get("https://www.google.com/");
Python范例
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option(''useAutomationExtension'', False)
driver = webdriver.Chrome(options=options, executable_path=r''C:\path\to\chromedriver.exe'')
driver.get("https://www.google.com/")
解决方法
我正在尝试使用selenium和铬在网站中自动化一个非常基本的任务,但是以某种方式网站会检测到铬是由selenium驱动的,并阻止每个请求。我怀疑该网站是否依赖像这样的公开DOM变量https://stackoverflow.com/a/41904453/648236来检测selenium驱动的浏览器。
我的问题是,有没有办法使navigator.webdriver标志为假?我愿意尝试修改后重新尝试编译selenium源,但是似乎无法在存储库中的任何地方找到NavigatorAutomationInformation源https://github.com/SeleniumHQ/selenium
任何帮助深表感谢
PS:我还从https://w3c.github.io/webdriver/#interface尝试了以下操作
Object.defineProperty(navigator,''webdriver'',{
get: () => false,});
但是它仅在初始页面加载后更新属性。我认为网站会在执行脚本之前检测到变量。
— 超时设置")
selenium webdriver (5)— 超时设置
自动化测试中,等待时间的运用占据了举足轻重的地位,平常我们需要处理很多和时间息息相关的场景,例如:
打开新页面,只要特定元素出现而不用等待页面全部加载完成就对其进行操作
设置等待某元素出现的时间,超时则抛出异常
设置页面加载的时间
…..
webdriver 类中有三个和时间相关的方法:
1.pageLoadTimeout 设置页面完全加载
2.setScriptTimeout 设置异步脚本的超时时间
3.implicitlyWait 识别对象的超时时间
我们就从这里开始,慢慢揭开他神秘的面纱。
pageLoadTimeout
pageLoadTimeout 方法用来设置页面完全加载的超时时间,完全加载即页面全部渲染,异步同步脚本都执行完成。前面的文章都是使用 get 方法登录安居客网站,大家应该能感觉到每次打开网页后要等很长一段时间才会进行下一步的操作,那是因为没有设置超时时间而 get 方法默认是等待页面全部加 载完成才会进入下一步骤,加入将超时时间设置为 3S 就会中断操作抛出异常。
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.WebElement;
public class NewTest{
public static void main(String[] args) throws InterruptedException {
System.setProperty ( "webdriver.chrome.driver" ,
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe" );
WebDriver driver = new ChromeDriver();
try{
//设置超时时间为3S
driver.manage().timeouts().pageLoadTimeout(3, TimeUnit.SECONDS);
driver.get("http://shanghai.anjuke.com");
WebElement input=driver.findElement(By.xpath("//input[@id=''glb_search0'']"));
input.sendKeys("selenium");
}catch(Exception e){
e.printStackTrace();
}finally{
Thread.sleep(3000);
driver.quit();
}
}ps: 如果时间参数为负数,效果没有使用这个方法是一样的,接口注释中有相关说明:”If the timeout is negative, page loads can be indefinite”.
如果想在抛出异常后并不中断而是继续执行下面的操作那该怎么办呢?可以使用 try,catch 的组合来实现这个功能
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.WebElement;
public class NewTest{
public static void main(String[] args) throws InterruptedException {
System.setProperty ( "webdriver.chrome.driver" ,
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe" );
WebDriver driver = new ChromeDriver();
try{
//设置超时时间为3S
driver.manage().timeouts().pageLoadTimeout(3, TimeUnit.SECONDS);
driver.get("http://shanghai.anjuke.com");
}catch(Exception e){
}finally{
WebElement input=driver.findElement(By.xpath("//input[@id=''glb_search0'']"));
if(input.isDisplayed())
input.sendKeys("selenium");
}
}这样,当页面加载 3S 后就会执行下面的操作了。
setScriptTimeout
设置异步脚本的超时时间,用法同 pageLoadTimeout 一样就不再写了,异步脚本也就是有 async 属性的 JS 脚本,可以在页面解析的同时执行。
implicitlywait
识别对象的超时时间,如果在设置的时间类没有找到就抛出一个 NoSuchElement 异常,用法参数也是和 pageLoadTimeout 一样,大家可以自己试验试验。
上文中介绍了如何才能在使用 pageLoadTimeout 抛出异常的同时继续执行,但是现有的方法还是不完美,如果输入框在 3S 后没有出现还是会 报错,怎么办呢?机智的同学可以想到用 sleep 方法来实现,为了方便演示换个更明显的需求来说明。安居客的首页上有个切换城市的链接,当点击城市的时候 就会显示全部的城市以供选择这时 display 属性就会变化
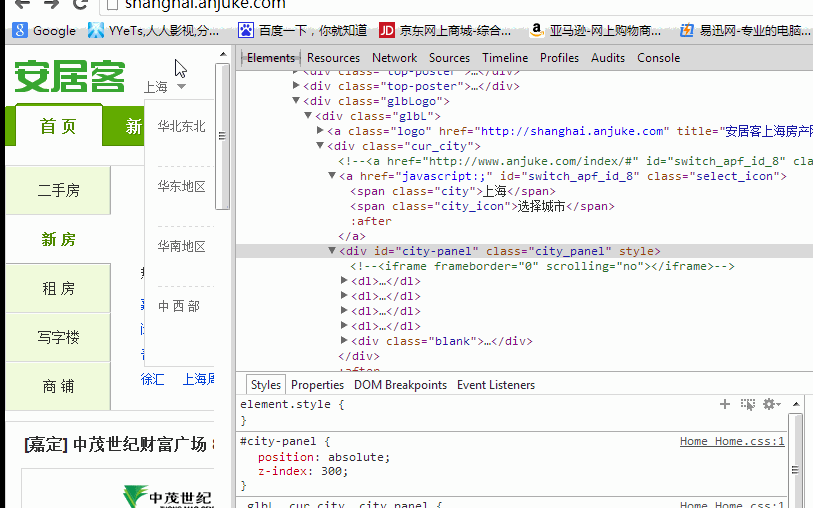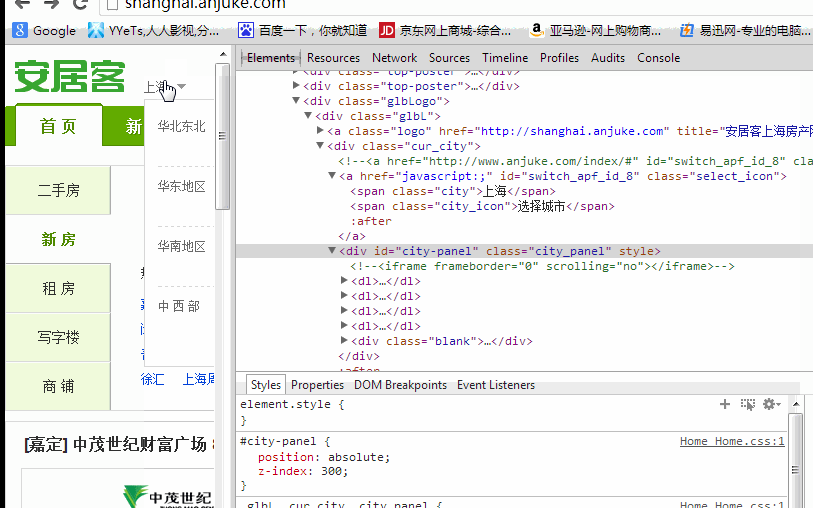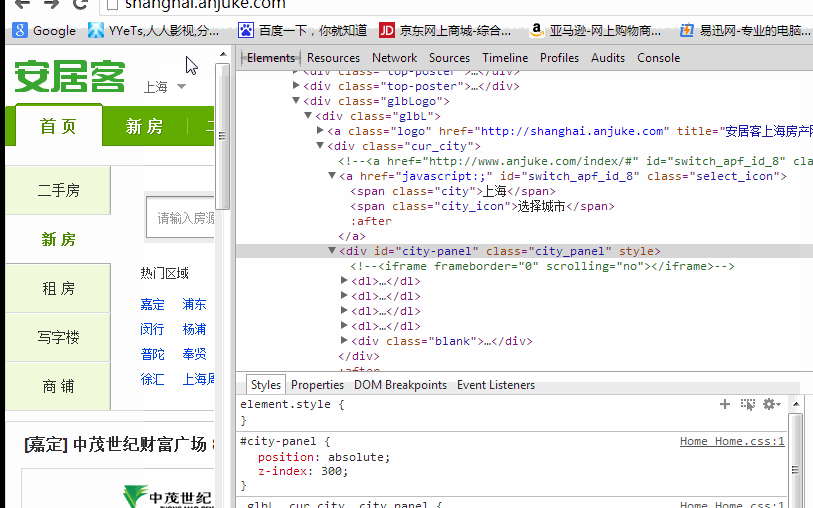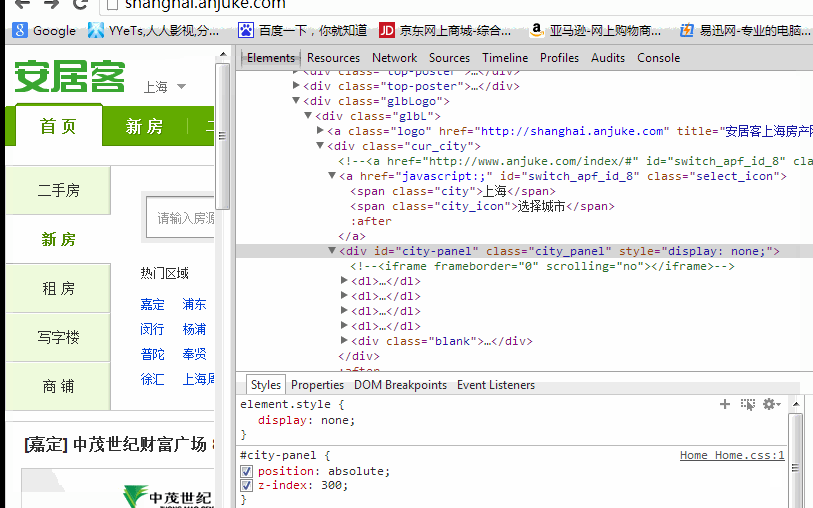
import java.util.concurrent.TimeUnit; import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver; import
org.openqa.selenium.chrome.ChromeDriver; import
org.openqa.selenium.WebElement; import
org.openqa.selenium.interactions.Actions;
public class NewTest{
public static void main(String[] args) throws InterruptedException {
System.setProperty ( "webdriver.chrome.driver" ,"C:\\Program Files(x86)\\Google\\Chrome\\Application\\chromedriver.exe" );
WebDriver driver = new ChromeDriver();
try{
//设置超时时间为3S
driver.manage().timeouts().pageLoadTimeout(3,TimeUnit.SECONDS);
driver.get("http://shanghai.anjuke.com");
}catch(Exception e){
}finally{
WebElement city=driver.findElement(By.xpath("//a[@id=''switch_apf_id_8'']"));
WebElement citys=driver.findElement(By.xpath("//div[@id=''city-panel'']"));
Actions actions=new Actions(driver);
actions.clickAndHold(city).perform();
while(citys.isDisplayed()){
System.out.println("sleep");
Thread.sleep(3000);
}
Thread.sleep(3000);
driver.quit();
}
}import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.interactions.Actions;
public class NewTest{
public static void main(String[] args) throws InterruptedException {
System.setProperty ( "webdriver.chrome.driver" ,
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe" );
WebDriver driver = new ChromeDriver();
try{
//设置超时时间为3S
driver.manage().timeouts().pageLoadTimeout(3, TimeUnit.SECONDS);
driver.get("http://shanghai.anjuke.com");
}catch(Exception e){
}finally{
WebElement city=driver.findElement(By.xpath("//a[@id=''switch_apf_id_8'']"));
WebElement citys=driver.findElement(By.xpath("//div[@id=''city-panel'']"));
Actions actions=new Actions(driver);
actions.clickAndHold(city).perform();
while(citys.isDisplayed()){
System.out.println("sleep");
Thread.sleep(3000);
}
Thread.sleep(3000);
driver.quit();
}
}执行后会每过 3S 就会输出一次 sleep, 但是这样的代码显然不够高大上,而且没有限制会一直无限的等待下去,下面介绍一种高大上的方法,就是 until,先看代码
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.interactions.Actions;
import org.openqa.selenium.support.ui.WebDriverWait;
import org.openqa.selenium.support.ui.ExpectedCondition;
public class NewTest{
public static void main(String[] args) throws InterruptedException {
System.setProperty ( "webdriver.chrome.driver" ,
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe" );
WebDriver driver = new ChromeDriver();
try{
//设置超时时间为3S
driver.manage().timeouts().pageLoadTimeout(3, TimeUnit.SECONDS);
driver.get("http://shanghai.anjuke.com");
}catch(Exception e){
}finally{
WebElement city=driver.findElement(By.xpath("//a[@id=''switch_apf_id_8'']"));
Actions actions=new Actions(driver);
actions.clickAndHold(city).perform();
//最多等待10S,每2S检查一次
WebDriverWait wait=new WebDriverWait(driver,10,2000);
wait.until(new ExpectedCondition<Boolean>() {
public Boolean apply(WebDriver driver) {
System.out.println("sleep");
return !driver.findElement(By.xpath("//div[@id=''city-panel'']")).isDisplayed();
}
});
Thread.sleep(3000);
driver.quit();
}
}
Selenium Webdriver Chromedriver在无头模式下启动时超时
我正在使用Selenium Webdriver,Ruby 32位1.9.3,Chromedriver v2.9.248315,Chrome
38.0.2125.111 m和Jenkins 1.588的本地实例
Gems: cucumber (1.3.17),selenium-webdriver (2.43.0), watir-webdriver (0.6.11)(如果您认为有必要,可以提供所有其他文件的列表)
Windows 7 Professional 64位版本。
运行Jenkins作业时,该作业使用chromedriver启动Chrome,然后尝试与其进行交互,但出现超时错误。通过命令提示符窗口在桌面上执行相同操作时,它可以完美运行。运行相同的Jenkins作业,启动Firefox而不是Chrome,效果很好。
简单示例(C:\ test.rb):
require ''watir-webdriver''require ''selenium-webdriver''client = Selenium::WebDriver::Remote::Http::Default.new$browser = Watir::Browser.new :chrome, :http_client => client$browser.driver.manage.window.maximize$browser.close配置为运行Windows批处理命令的Jenkins作业:
cd \ruby test.rb运行作业时的输出:
Started by user anonymousBuilding in workspace C:\Program Files (x86)\Jenkins\jobs\test chromedriver\workspace[workspace] $ cmd /c call C:\Windows\TEMP\hudson3963234995624341455.batC:\Program Files (x86)\Jenkins\jobs\test chromedriver\workspace>cd \C:\>ruby test.rb C:/Ruby193/lib/ruby/1.9.1/net/protocol.rb:146:in `rescue in rbuf_fill'': Timeout::Error (Timeout::Error) from C:/Ruby193/lib/ruby/1.9.1/net/protocol.rb:140:in `rbuf_fill'' from C:/Ruby193/lib/ruby/1.9.1/net/protocol.rb:122:in `readuntil'' from C:/Ruby193/lib/ruby/1.9.1/net/protocol.rb:132:in `readline'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:2563:in `read_status_line'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:2552:in `read_new'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:1320:in `block in transport_request'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:1317:in `catch'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:1317:in `transport_request'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:1294:in `request'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:1287:in `block in request'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:746:in `start'' from C:/Ruby193/lib/ruby/1.9.1/net/http.rb:1285:in `request'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/remote/http/default.rb:83:in `response_for'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/remote/http/default.rb:39:in `request'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/remote/http/common.rb:40:in `call'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/remote/bridge.rb:638:in `raw_execute'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/remote/bridge.rb:616:in `execute'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/remote/bridge.rb:236:in `maximizeWindow'' from C:/Ruby193/lib/ruby/gems/1.9.1/gems/selenium-webdriver-2.43.0/lib/selenium/webdriver/common/window.rb:98:in `maximize'' from test.rb:5:in `<main>''C:\>exit 1 Build step ''Execute Windows batch command'' marked build as failureFinished: FAILURE我尝试在Jenkins服务中启用“允许服务与桌面进行交互”,然后观察窗口(在更复杂的情况下),然后Chrome窗口打开,但是什么也不做。我最初遇到了“$browser.cookies.clear”问题,并且在注释掉该行之后,我现在在$browser.driver.manage.window.maximize行中也遇到了同样的问题
我正在运行复杂的黄瓜方案,而使用Chromedriver却没有问题。然后,我重建了PC,并安装了Jenkins,Ruby,Chromedriver(将它们都添加到PATH)并将旧作业复制到新的Jenkins安装中后,出现了上述问题。然后,我创建了上面的简单示例,对其进行了测试并创建了这篇文章。
如果有人对我如何使Chromedriver重新工作有任何想法,那就太好了。
答案1
小编典典在会话0中以系统用户身份运行时,Chrome38不起作用。通常是因为Chrome是由Windows服务(在您的情况下是作为服务运行的Jenkins)启动,因此会发生这种情况。这是一个已知的问题。请在此处和此处查看硒问题。
两种解决方案:
- 将Chrome降级到38以下的版本。
- 下载并安装AlwaysUp并将其配置为以默认系统用户以外的用户身份运行Jenkins服务
AlwaysUp解决方案绝对可以使用,但许可费用较低,如果您不担心Chrome版本,可以将其降级。

Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效
如何解决Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效?
我正在尝试抓取一些 LinkedIn 个人资料,但是,使用下面的代码,给了我一个错误:
错误:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-b6cfafdd5b52> in <module>
25 #sending our driver as the driver to be used by srape_linkedin
26 #you can also create driver options and pass it as an argument
---> 27 ps = ProfileScraper(cookie=myLI_AT_Key,scroll_increment=random.randint(10,50),scroll_pause=0.8 + random.uniform(0.8,1),driver=my_driver) #changed name,default driver and scroll_pause time and scroll_increment made a little random
28 print(''Currently scraping: '',link,''Time: '',datetime.Now())
29 profile = ps.scrape(url=link) #changed name
~\Anaconda3\lib\site-packages\scrape_linkedin\Scraper.py in __init__(self,cookie,scraperInstance,driver,driver_options,scroll_pause,scroll_increment,timeout)
37
38 self.was_passed_instance = False
---> 39 self.driver = driver(**driver_options)
40 self.scroll_pause = scroll_pause
41 self.scroll_increment = scroll_increment
TypeError: ''WebDriver'' object is not callable
代码:
from datetime import datetime
from scrape_linkedin import ProfileScraper
import random #new import made
from selenium import webdriver #new import made
import pandas as pd
import json
import os
import re
import time
os.chdir("C:\\Users\\MyUser\\DropBox\\linkedInScrapper\\")
my_profile_list = [''https://www.linkedin.com/in/williamhgates/'',''https://www.linkedin.com/in/christinelagarde/'',''https://www.linkedin.com/in/ursula-von-der-leyen/'']
myLI_AT_Key = MyKey # you need to obtain one from Linkedin using these steps:
# To get LI_AT key
# Navigate to www.linkedin.com and log in
# Open browser developer tools (Ctrl-Shift-I or right click -> inspect element)
# Select the appropriate tab for your browser (Application on Chrome,Storage on Firefox)
# Click the Cookies dropdown on the left-hand menu,and select the www.linkedin.com option
# Find and copy the li_at value
for link in my_profile_list:
#my_driver = webdriver.Chrome() #if you don''t have Chromedrive in the environment path then use the next line instead of this
#my_driver = webdriver.Chrome()
my_driver = webdriver.Firefox(executable_path=r''C:\Users\MyUser\DropBox\linkedInScrapper\geckodriver.exe'')
#my_driver = webdriver.Chrome(executable_path=r''C:\Users\MyUser\DropBox\linkedInScrapper\chromedriver.exe'')
#sending our driver as the driver to be used by srape_linkedin
#you can also create driver options and pass it as an argument
ps = ProfileScraper(cookie=myLI_AT_Key,default driver and scroll_pause time and scroll_increment made a little random
print(''Currently scraping: '',datetime.Now())
profile = ps.scrape(url=link) #changed name
dataJSON = profile.to_dict()
profileName = re.sub(''https://www.linkedin.com/in/'','''',link)
profileName = profileName.replace("?originalSubdomain=es","")
profileName = profileName.replace("?originalSubdomain=pe","")
profileName = profileName.replace("?locale=en_US","")
profileName = profileName.replace("?locale=es_ES","")
profileName = profileName.replace("?originalSubdomain=uk","")
profileName = profileName.replace("/","")
with open(os.path.join(os.getcwd(),''ScrapedLinkedInprofiles'',profileName + ''.json''),''w'') as json_file:
json.dump(dataJSON,json_file)
time.sleep(10 + random.randint(0,5)) #added randomness to the sleep time
#this will close your browser at the end of every iteration
my_driver.quit()
print(''The first observation scraped was:'',my_profile_list[0:])
print(''The last observation scraped was:'',my_profile_list[-1:])
print(''END'')
我尝试了许多不同的方法来尝试让 webdriver.Chrome() 工作,但没有任何运气。我曾尝试使用 Chrome (chromedriver) 和 Firefox (geckodriver),尝试以多种不同的方式加载 selenium 包,但我一直收到错误 TypeError: ''WebDriver'' object is not callable。
我下面的原始代码仍然有效。 (即它会打开 Google Chrome 浏览器并转到 my_profiles_list 中的每个配置文件,但我想使用上面的代码。
from datetime import datetime
from scrape_linkedin import ProfileScraper
import pandas as pd
import json
import os
import re
import time
my_profile_list = [''https://www.linkedin.com/in/williamhgates/'',''https://www.linkedin.com/in/ursula-von-der-leyen/'']
# To get LI_AT key
# Navigate to www.linkedin.com and log in
# Open browser developer tools (Ctrl-Shift-I or right click -> inspect element)
# Select the appropriate tab for your browser (Application on Chrome,Storage on Firefox)
# Click the Cookies dropdown on the left-hand menu,and select the www.linkedin.com option
# Find and copy the li_at value
myLI_AT_Key = ''INSERT LI_AT Key''
with ProfileScraper(cookie=myLI_AT_Key,scroll_increment = 50,scroll_pause = 0.8) as scraper:
for link in my_profile_list:
print(''Currently scraping: '',datetime.Now())
profile = scraper.scrape(url=link)
dataJSON = profile.to_dict()
profileName = re.sub(''https://www.linkedin.com/in/'',link)
profileName = profileName.replace("?originalSubdomain=es","")
profileName = profileName.replace("?originalSubdomain=pe","")
profileName = profileName.replace("?locale=en_US","")
profileName = profileName.replace("?locale=es_ES","")
profileName = profileName.replace("?originalSubdomain=uk","")
profileName = profileName.replace("/","")
with open(os.path.join(os.getcwd(),''w'') as json_file:
json.dump(dataJSON,json_file)
time.sleep(10)
print(''The first observation scraped was:'',my_profile_list[0:])
print(''The last observation scraped was:'',my_profile_list[-1:])
print(''END'')
注意事项:
代码略有不同,因为我在 SO here 上提出了一个问题,@Ananth 帮助我给出了解决方案。
我也知道在线和 SO 存在与 selenium 和 chromedriver 相关的“类似”问题,但在尝试了每个建议的解决方案后,我仍然无法使其正常工作。 (即常见的解决方案是 webdriver.Chrome() 中的拼写错误)。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
关于在Selenium Webdriver上设置超时和selenium设置超时时间的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于JavaSelenium Webdriver:修改navigator.webdriver标志以防止selenium检测、selenium webdriver (5)— 超时设置、Selenium Webdriver Chromedriver在无头模式下启动时超时、Selenium WebDriver 在导入 selenium 时不可调用错误但在不导入 selenium 时有效等相关内容,可以在本站寻找。
本文标签:




