如果您想了解实现报表数据外置计算和实现报表数据外置计算的方法的知识,那么本篇文章将是您的不二之选。我们将深入剖析实现报表数据外置计算的各个方面,并为您解答实现报表数据外置计算的方法的疑在这篇文章中,我
如果您想了解实现报表数据外置计算和实现报表数据外置计算的方法的知识,那么本篇文章将是您的不二之选。我们将深入剖析实现报表数据外置计算的各个方面,并为您解答实现报表数据外置计算的方法的疑在这篇文章中,我们将为您介绍实现报表数据外置计算的相关知识,同时也会详细的解释实现报表数据外置计算的方法的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- 实现报表数据外置计算(实现报表数据外置计算的方法)
- FineReport实现报表数据根据点击次数奇偶性排序的方法
- flex 实现报表中的斜线表头
- Hive应用:数据外置内部表
- MISP8: 细化迭代6:实现报表
")
实现报表数据外置计算(实现报表数据外置计算的方法)
在报表应用中,针对历史数据查询的报表占比很大,这类报表的特点是:第一,数据变化小,查询的历史数据几乎不会发生变化;第二,数据量大,而且还会随时间不断增加。如果这些历史数据始终存放在数据库中,由于大多数数据库的 JDBC 性能都很低下(取数过程的数据对象转换比从文件中读取数据慢一个数量级),当涉及数据量较大或并发较多的时候,报表的性能会急剧下降。显然,如果能将这些变化不大的历史数据移出数据库,采用文件系统存储,就可以获得比数据库高得多的 IO 性能,从而提高报表的整体性能。
但是,报表并不能直接使用原始数据,都需要运算(比如查询汇总)之后再进行呈现,而文件本身没有计算能力,因此无法提供报表需要的结果。此外,使用文件存储的数据量一般都很大,仅靠报表呈现端很难实现高效的计算。
对于润乾报表来说,这种需求完全可以在内置集算引擎的帮助下做到,称为库外文件计算,或数据外置计算。所支持的文件类型包括:文本、Excel、JSON 格式文件等,还支持效率更高的二进制文件。
通过数据外置计算,将较大数据量的历史数据从数据库中剥离,除了可以满足历史查询类报表的性能需求外,还可以实现混合数据源(文件 + 数据库)的计算,进而实现大数据量的实时数据查询,比如从文件系统中读取往期大量的历史数据,从数据库中读取当期较小量的实时数据进行混合计算。由此,一方面可以避免数据库的 IO 瓶颈,快速提升报表性能,增大数据查询范围;另一方面,将历史数据移出,数据库可以专注于保证业务系统数据的一致性,而不是耗费资源在大量的历史查询任务上,这也是一种数据库优化的手段。
下面用一个例子说明润乾报表实现数据外置计算(结合集算器实现)的步骤:
1、 将数据库中历史数据导出到文件
用户可以自行选择适当的方法将历史数据导出到文件,当然这个过程也可以使用集算器来做,比如将数据导出到文本。如果希望更高的性能,还可以使用比文本能快 2-5 倍的二进制文件格式。在集算器中使用以下代码可将文本文件转换成二进制格式。
file("E:/订单明细.b").export@b(file(“E:/订单明细.txt”.cursor())
file("E:/订单明细.b").export@b(file(“E:/订单明细.txt”.cursor())
2、 使用润乾报表内置的集算引擎读取数据文件
当数据外置后,润乾报表可将文件作为数据源来设计报表,比如根据订单明细按客户统计订单数量和订单金额,由于原始订单数据非常大,所以读入文件时采用流式(文件游标)的方式逐步读入。
脚本中使用的参数及其含义如下:

脚本:
| A | |
|---|---|
| 1 | =file(“E:/ 订单明细.txt”).cursor@t() |
| 2 | =A1.select(货主国家 ==county && 货主地区 ==area && 货主城市 ==city && 订购日期 >=begin && 订购日期 <=end) |
| 3 | =A2.groups(客户 ID;count( 订单 ID): 订单数量,sum(订单金额): 订单总额 ) |
| 4 | return A3 |
代码说明:
A1:通过文件游标采用流式处理的方式读入大文本;
A2:按照指定的多个维度进行数据过滤,结果仍然是游标;
A3:根据选出的结果,按照客户 ID 汇总订单数量和订单金额;
A4:为报表返回结果集。
前面提到,润乾报表既可以针对单独的文件(导出的历史数据)进行查询计算,还可以进行文件 + 数据库的混合运算,进行大数据量实时查询。
| A | |
|---|---|
| 1 | =file(“E:/ 订单明细.txt”).cursor@t() |
| 2 | =A1.select(订购日期 >=begin && 订购日期 <=end) |
| 3 | =A2.groups(客户 ID;count( 订单 ID): 订单数量,sum(订单金额): 订单金额 ) |
| 4 | =connect(“cmos”) |
| 5 | =A4.cursor(“select 客户 ID,count( 订单 ID) 订单数量,sum(订单金额) 订单金额 from 订单明细 where 货主国家 =? and 货主地区 =? and 货主城市 =? and 订购日期 >? and 订购日期 <? group by 客户 ID”,county,area,city,begin,end) |
| 6 | =[A3,A5.fetch()].conj() |
| 7 | >A4.close() |
| 8 | =A6.groups(客户 ID;sum( 订单数量): 订单总量,sum(订单金额): 订单总额 ) |
| 9 | return A7 |
代码说明:
A1-A3:与上一个脚本一样,汇总历史数据;
A5:根据指定参数执行 sql,汇总当期数据;
A6:将两部分汇总数据合并(纵向拼接);
A8:根据合并后的历史和当期汇总数据再次汇总,得到各客户的订单数量和订单金额。
3 在润乾报表中调用集算脚本,编辑报表表达式完成报表制作
数据集配置如下:

报表配置如下:

通过以上过程可以清晰的看到,润乾报表可以通过数据外置提升报表性能,解决对往期历史 + 当期数据进行查询时性能不高的问题。

FineReport实现报表数据根据点击次数奇偶性排序的方法
使用FineReport报表软在进行排序的时,很多时候您可能想实现根据点击的次数进行升降序排序,也就是说点击第一次点击标题升序排序,再次点击就降序,以此类推,而不是通过选择升序进行升序排列,选择降序进行降序排列。
由扩展后排序可知,可以根据参数值的不同来决定升序还是降序,这里也可以此思路进行实现,定义一个参数,如果参数值为1的时候,就升序,参数值为0的时候,按照数据列的负数进行升序排序,即数据列降序。
本文所提供的方法,只适用于排序数据列数据类型为数字型的字段。数据类型为字符型,我们下节再介绍。
下面以一个简单示例进行介绍,模板根据订单ID进行升序降序排列,第一次点击订单ID的时候升序,再次点击时降序,以此类推。
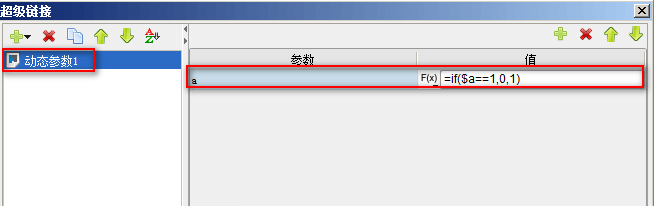
1、设置超链接
选中A1单元格,右键选择超级链接,添加一个动态参数,增加一个动态参数a,参数值为公式if($a==1,0,1),如下图:
2、排序设置
排序设置有两种设置方式,高级排序和扩展后排序,下面分别介绍着两种方式的设置方式。
(1)高级排序
双击A2单元格,选择高级,在排序顺序处选择升序,公式值为if($a==1,$,?$),如下图:

注:公式的意义是,如果动态参数值为1,那么就将订单ID按照订单ID升序排序,如果不为1,就按照订单ID的负数进行升序排序,即按照订单ID进行降序排序,由于只有数值型数据才有负数,字符型数据没有负数,故该方法只适用于数值型字段排序。
另:如果是将订单ID按照运货费进行升序降序排序,那么公式应为:if($a==1,运货费,-运货费),由于此处排序是设置数据列的排序,则公式中输入的是数据列的名称。
(2)扩展后排序
选中A2单元格,在单元格属性表>扩展属性中的扩展后选择升序,值为公式=if($a==1,A2,-A2),如下图:

注:公式意义同上,此处是根据单元格进行排序,所以公式中输入的是单元格,不是数据列名字。
另:如果需要将订单ID按照运货费进行升序降序排序,那么公式应为:if($a==1,F2,-F2)
3、效果查看
不论是根据高级排序设置,还是扩展后排序设置,设置的效果如下:

flex 实现报表中的斜线表头



图1 图2 图3
<com:ObliqueLine width="500" height="300" label="时间|产品|产量|地区|...|...|..."/>
制作这样的表头,需要了解以下知识:
1 ) 使用graphics绘制斜线
2 ) Math函数中的tan sin 等几何函数,以及(角度 = 弧度*180/PI)
例如图一的(时间)角度计算为Math.atan2(this.height,this.width) * 180.0 / Math.PI
3 ) 使用BitmapData的方式将TextField 旋转指定度数
public function getBiasText(text:String):Shape
{
var s:Shape=new Shape;
var t:TextField=new TextField;
t.text=text;
var f:textformat=new textformat;
f.size=20;
t.settextformat(f);
var b:BitmapData=new BitmapData(t.width,t.height,true,null);
b.draw(t);
s.graphics.clear();
s.graphics.beginBitmapFill(b);
s.graphics.drawRect(0,t.textWidth,t.textHeight);
s.graphics.endFill();
textWidth = s.width;
textHeight = s.height;
//s.rotation=20;
return s;
}
备注:如何解决文字的位置不会压在斜线上呢?基本原理就是通过几何运算,计算出x坐标,y坐标以及旋转的角度
/** * 设置倾斜的文本 * @param index 文本的下标 * @param firstAngle 当前扇形区域的角度 * @param secendAngle 当前扇形区域以及之前的区域的角度和 * @param zoneType 区域的类型 * @param isCenter 是否旋转居中 */ private function biasText(index:int,firstAngle:Number,secondAngle:Number,zoneType:int,isCenter:Boolean):void { var d5:Number=(firstAngle + secondAngle) / 2.0; var d1:Number; var d2:Number var label:Shape=labelObjects[index] as Shape; switch(zoneType){ case 1:{ d1 = textHeight/Math.tan(secondAngle/ 180.0 * Math.PI); d2 = 0; break; } case 2:{ if(isCenter){ var t:Number = textHeight/2/Math.sin((secondAngle-firstAngle)/2/180.0 * Math.PI); var d1 = t*Math.cos((firstAngle)/180.0 * Math.PI); var d2 = t * Math.sin((firstAngle)/180.0 * Math.PI); }else{ d2 = this.height-label.height; d1 = 0; } break; } case 3:{ var t:Number = textHeight/2/Math.sin((secondAngle-firstAngle)/2/180.0 * Math.PI); var d1 = t*Math.cos(firstAngle/180.0 * Math.PI); var d2 = t * Math.sin(firstAngle/180.0 * Math.PI); } } if(isCenter && redraw){ label.rotation+=d5; } label.x=d1; label.y=d2; }
依然存在的问题:旋转后的文体不是很平滑
Hive应用:数据外置内部表
Hive应用:数据外置内部表
介绍
个人认为这种表就体现了Hive的无节操无底线。会颠覆你对外部表和内部表的传统认知。
当你在创建内部表的时候,加上了location和目录,那么你的数据就存放在你指定的目录中,这个目录可以是在HDFS的任意目录,所以如果你的Hive库中存在这样的表,那么你就不能随意地删除你Hive中的任何表,因为使用show tables;命令查看Hive中的表的列表时,没有明确标识哪个表是外部表,哪个表是内部表,不小心删除之后,数据就彻底没了。
示例
先创建HDFS目录/data/person,将数据文件上传到此目录之下。数据内容如下:
1.0|张三|20.0|男|未知|0
2.0|李四|25.0|男|河北|0
3.0|张飞|30.0|男|河北|0
4.0|关羽|35.0|男|山东|0
5.0|小乔|38.0|女|浙江|0
6.0|刘备|40.0|男|成都|0
7.0|小李|29.0|男|江南|0创建Hive内部表:
hive> create table person(id string,name string,age string,gender string,address string,test int) row format delimited fields terminated by ''|'' location ''hdfs://192.168.75.150:9000/data/person'';
OK
Time taken: 0.148 seconds
hive> select * from person;
OK
1.0 张三 20.0 男 未知 0
2.0 李四 25.0 男 河北 0
3.0 张飞 30.0 男 河北 0
4.0 关羽 35.0 男 山东 0
5.0 小乔 38.0 女 浙江 0
6.0 刘备 40.0 男 成都 0
7.0 小李 29.0 男 江南 0
Time taken: 0.141 seconds, Fetched: 7 row(s)
hive> 此时就创建了一个数据外置的内部表,这个表也允许先有数据,上面展示的数据,就是证明了这一点,完美展示了数据外置的内部表。
然而如果删除Hive中的这个表的话,数据也会跟着被删除。
下图是数据存放的目录:
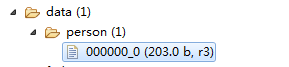
在看一下test数据库目录:

没有person表的目录。
接下来将删除person表看看目录的变化:
hive> drop table preson;
OK
Time taken: 0.184 seconds
hive> show tables;
OK
person
promo
tab
Time taken: 0.222 seconds, Fetched: 3 row(s)
hive> drop table person;
OK
Time taken: 0.189 seconds
hive> show tables;
OK
promo
tab
Time taken: 0.076 seconds, Fetched: 2 row(s)
hive> 第一遍删除竟然没有成功,不知道闹哪样,第二次删除成功,下面是目录结构:

data目录空了,person文件夹也不存在了。
总结
所以综上所述,这种内部表有普通外部表的先有数据的特性,还具有普通内部表删除表数据也同时删除的特性。那么如果这个表也是内部表的话,那么内部表和外部表的区别在哪里?只剩下一个external关键字了,其他的没有区别了,而且Hive中表的列表中没有明确标识表的种类,稀里糊涂一顿删除,有可能删除的就是这种表!
这种表出现有两种可能:一种是创建外部表的时候手误忘记写external关键字,另外一种就是真的需要这样一种表,但是好像在我的职业生涯中,还暂时没有遇到这种需求,而本人只是手误忘记写external关键字,才产生的这种表,然后删除,重新创建,发现存放数据的目录以及数据都没有了,才进一步做了以上的实验来证明这个事情。
上一篇:Hive应用:外部分区表
下一篇:Hive应用:设置字段自增

MISP8: 细化迭代6:实现报表
一、任务:实现报表
任务A:实现POS系统报表功能。
基本需求及逻辑如下:
(1) 统计每月销售总金额 (数字或图形报表)
(2) 按“产品类别”统计“起止时间”内销售金额,有小计和总计(数字报表)。
任务B:按“课程设计文档模板”要求编写文档:
(1) 撰写文档4.2.2 报表设计 (架构师完成)
(2) 撰写文档5.1 功能实现,5.2 系统测试(测试员),5.3系统部署(架构师完成)
(3) 撰写文档6 项目总结(项目经理)
二、要求:
(1)可根据技术能力和学习情况自行选择报表实现工具(建议JasperReport)。
(2)优先实现数字报表,有精力可实现图形报表(建议JFreeChart实现)。
三、制品交付:
(1) 程序提交的项目git。
(2) 文档发表在项目经理blog。
(3) 为方便指导老师评价程序,程序运行界面截图和测试报告发表在项目经理blog(另写一篇,测试员完成)。
交付时间:细化迭代5时间为2周(第13、14周),截止日期6月13日(第14周星期五) 24:00。
制品反馈见blog评论和git的issue。
关于实现报表数据外置计算和实现报表数据外置计算的方法的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于FineReport实现报表数据根据点击次数奇偶性排序的方法、flex 实现报表中的斜线表头、Hive应用:数据外置内部表、MISP8: 细化迭代6:实现报表的相关信息,请在本站寻找。
本文标签:




