在本文中,我们将给您介绍关于计算数组中数字的出现的详细内容,并且为您解答计算数组中数字的出现次序的相关问题,此外,我们还将为您提供关于(力扣)面试题56-I.数组中数字出现的次数、c–计算整数区间(或
在本文中,我们将给您介绍关于计算数组中数字的出现的详细内容,并且为您解答计算数组中数字的出现次序的相关问题,此外,我们还将为您提供关于(力扣) 面试题 56 - I. 数组中数字出现的次数、c – 计算整数区间(或int数组)中每个数字的出现次数、Java中数组中所有数字的LCM、Jquery计算数组中的出现次数的知识。
本文目录一览:- 计算数组中数字的出现(计算数组中数字的出现次序)
- (力扣) 面试题 56 - I. 数组中数字出现的次数
- c – 计算整数区间(或int数组)中每个数字的出现次数
- Java中数组中所有数字的LCM
- Jquery计算数组中的出现次数
")
计算数组中数字的出现(计算数组中数字的出现次序)
我堆了一会儿。我尝试调试,但找不到解决方案。我正在尝试计算数字的出现。所以我的问题是当我打印输出时
3 occurs 1 times1 occurs 1 times0 occurs 1 times2 occurs 1 times1 occurs 2 times3 occurs 2 times2 occurs 2 times0 occurs 2 times10 occurs 1 times4 occurs 1 times代替
1 occurs 2 times0 occurs 2 times2 occurs 2 times3 occurs 2 time10 occurs 1 times4 occurs 1 times因此,如果数字出现的次数超过1,则应该只说一次,而不是出现的次数。欢呼这是代码
import java.util.*;public class CountingOccuranceOfNumbers{ public static void main(String[] args) { countNumbers(); } public static void countNumbers() { Scanner input = new Scanner(System.in); Random generator = new Random(); int[] list = new int[11]; int[] counts = new int[150]; int counter = 0; int number = 1; while(counter <= 10) { number = generator.nextInt(11); list[counter] = number; counter++; } for(int i=0; i<list.length - 1; i++) { counts[list[i]]++;// System.out.print(list[i] + " "); System.out.println(list[i] +" occurs " + counts[list[i]] + " times"); } }}答案1
小编典典另一个选项是番石榴的Multiset类,它将为您跟踪计数:
int values[] = ...;Multiset<Integer> ms = HashMultiset.create();ms.addAll(Ints.asList(list));int count0 = ms.count(Integer.valueOf(0));int count1 = ms.count(Integer.valueOf(1));在这里,Multiset,HashMultiset和Ints都是番石榴类。
请注意,Multiset通过使用Map和counter来跟踪计数器,几乎可以完成上面提到的某些事情。它只是从您身上抽象出来,以使您的代码更简单。
 面试题 56 - I. 数组中数字出现的次数")
(力扣) 面试题 56 - I. 数组中数字出现的次数
(力扣) 面试题 56 - I. 数组中数字出现的次数
一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是 O (n),空间复杂度是 O (1)。
示例 1:
输入:nums = [4,1,4,6]
输出:[1,6] 或 [6,1]
示例 2:
输入:nums = [1,2,10,4,1,4,3,3]
输出:[2,10] 或 [10,2]
限制:
2 <= nums <= 10000
解题代码
时间不理想
class Solution {
public int[] singleNumbers(int[] nums) {
Map<Integer,Integer> maps = new HashMap<>();
for (int k:nums) {
maps.put(k,maps.containsKey(k)?maps.get(k)+1:1);
}
int [] in = new int[2];
int i = 0;
for (Integer key:maps.keySet()) {
if(maps.get(key)==1){
in[i] = key;
i++;
}
}
return in;
}
}
解题思路
时间不理想
1、使用 HashMap 的性质,来找出重复的
2、把不重复的给提取出来
3、返回
本文分享 CSDN - TrueDei。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
中每个数字的出现次数")
c – 计算整数区间(或int数组)中每个数字的出现次数
例如:
> INPUT n,m = [19,23] = 19,20,21,22,23
>输出应该是:
0次出现:1次
1次出现:2次
2次出现:5次
3次出现:1次等
#include <iostream>
using namespace std;
int main()
{
int i,j,z,count,n,m;
cin >>n >>m;
for(int i=0; i<10; i++) // LOOP FOR DIGITS
{
cout << i <<"occurences: ";
count=0;
for(int j=n; j<m; j++) // LOOP INTEGER INTERVAL
{
while (z!=0)
{
z = j % 10; // LAST DIGIT OF FirsT NUMBER IN INTERVAL
if (z == i) count++;
z /= 10;
}
}
cout << count <<" times"<< endl;
}
}
我的代码每个数字返回0次,错误在哪里?
解决方法
int n,m;
cin >> n >> m;
counts = int[10];
for(int i = 0; i < 10; ++i) {
counts[i] = 0;
}
for(int j = n; j <= m; j++) {
int z = j;
do {
int digit = z % 10; // LAST DIGIT OF FirsT NUMBER IN INTERVAL
counts[digit]++;
z /= 10;
} while (z != 0);
}
for(int i = 0; i < 10; ++i) {
cout << i << " occurrences " << counts[i] << " times";
}

Java中数组中所有数字的LCM
我有一个整数数组,我试图找到该数组中所有值的LCM(最小公倍数)。我已经lcm单独写了一个方法;它接受两个值作为输入,并返回lcm。我的lcm方法工作得很好,但是当我用它来查找所有值的LCM时,我得到了错误的答案。
这是我gcd和的lcm方法:
public static int gcd(int a, int b){ if (a<b) return gcd(b,a); if (a%b==0) return b; else return gcd(a, a%b);}public static int lcm(int a, int b){ return ((a*b)/gcd(a,b));}这是我对数组值的lcm的要求:
public static int lcmofarray(int[] arr, int start, int end){ if ((end-start)==1) return lcm(arr[start],arr[end-1]); else return (lcm (arr[start], lcmofarray(arr, start+1, end)));}当我放入一个数字1到5为arr,0为asstart且数组的长度为的数组时end,得到30作为答案,而我想要60。当我放入一个包含从1到1的所有数字的数组时10,我得到840,而不是2520。我真的无法解释。
该算法应该有效-我已经脑力激荡了。无法弄清楚我的代码出了什么问题。
任何帮助将不胜感激。
答案1
小编典典如果您将gcd函数更改为
public static int gcd(int a, int b){ if (a<b) return gcd(b,a); if (a%b==0) return b; else return gcd(b, a%b);}它应该工作正常。

Jquery计算数组中的出现次数
我想计算数组中每个元素的数量
例:
var basketItems = ['1','3','1','4','4'];
jQuery.each(basketItems,function(key,value) {
// Go through each element and tell me how many times it occurs,output this and remove duplicates
}
然后我想输出
Item | Occurances -------------------- 1 | 2 3 | 1 4 | 2
提前致谢
解决方法
var basketItems = ['1','4'],counts = {};
jQuery.each(basketItems,value) {
if (!counts.hasOwnProperty(value)) {
counts[value] = 1;
} else {
counts[value]++;
}
});
结果:
Object {1: 2,3: 1,4: 2}
我们今天的关于计算数组中数字的出现和计算数组中数字的出现次序的分享就到这里,谢谢您的阅读,如果想了解更多关于(力扣) 面试题 56 - I. 数组中数字出现的次数、c – 计算整数区间(或int数组)中每个数字的出现次数、Java中数组中所有数字的LCM、Jquery计算数组中的出现次数的相关信息,可以在本站进行搜索。
在本文中,我们将详细介绍焦点改变后自动计算年龄的各个方面,并为您提供关于焦点时间的相关解答,同时,我们也将为您带来关于C#实现计算年龄的简单方法汇总、Calendar 计算年龄、days360函数计算年龄、delphi使用回车设置焦点改变的有用知识。
本文目录一览:")
焦点改变后自动计算年龄(焦点时间)
从日期选择器中选择日期之后,以及当焦点从日期选择器更改为年龄文本文件时,可以自动计算年龄吗?
样品表在这里
答案1
小编典典FocusListener例如,A 会有所帮助…
JXDatePicker dp = new JXDatePicker(); dp.getEditor().addFocusListener(new FocusAdapter() { @Override public void focusLost(FocusEvent e) { // Calculate age Date date = dp.getDate(); } });有关更多详细信息,请参见如何编写焦点侦听器。
最好使用JodaTime或Java 8的新Time API完成年龄计算
Java 8
Date date = // Date from date pickerLocalDate ld = date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate();//LocalDate ld = LocalDate.of(1972, Month.MARCH, 8);Period p = Period.between(ld, LocalDate.now());System.out.println(p.getYears());System.out.println(p.getMonths());System.out.println(p.getDays());输出类似…
421118乔达时代
Date date = // Date from date pickerLocalDate ld = LocalDate.fromDateFields(date);Period p = Period.fieldDifference(ld, LocalDate.now());System.out.println(p.getYears());System.out.println(p.getMonths());System.out.println(p.getDays());
C#实现计算年龄的简单方法汇总
vs2010测试通过,主要思想是由出生日期和当前日期,两个日期计算出年龄(岁、月、天)
using System;
using System.Collections.Generic;
using System.Text;
namespace Publicclass
{
public static class CalculationDate
{
/// <summary>
/// 由两个日期计算出年龄(岁、月、天)
/// </summary>
public static void calculationDate(DateTime beginDateTime,DateTime endDateTime)
{
if (beginDateTime > endDateTime)
throw new Exception("开始时间应小于或等与结束时间!");
/*计算出生日期到当前日期总月数*/
int Months = endDateTime.Month - beginDateTime.Month + 12 * (endDateTime.Year - beginDateTime.Year);
/*出生日期加总月数后,如果大于当前日期则减一个月*/
int totalMonth = (beginDateTime.AddMonths(Months) > endDateTime) ? Months - 1 : Months;
/*计算整年*/
int fullYear = totalMonth / 12;
/*计算整月*/
int fullMonth = totalMonth % 12;
/*计算天数*/
DateTime changeDate = beginDateTime.AddMonths(totalMonth);
double days = (endDateTime - changeDate).TotalDays;
}
}
}
再简单一些:
public int CalculateAgeCorrect(DateTime birthDate,DateTime Now)
{
int age = Now.Year - birthDate.Year;
if (Now.Month < birthDate.Month || (Now.Month == birthDate.Month && Now.Day < birthDate.Day)) age--;
return age;
}
下面我们来看看常规方法:
方法1:
string m_Str = "1984-04-04";
int m_Y1 = DateTime.Parse(m_Str).Year;
int m_Y2 = DateTime.Now.Year;
int m_Age = m_Y2 - m_Y1;
Response.Write(m_Age);
方法2:
如果你将日期格式化为yyyymmdd,并且从当前日子减去生日,最后去除4个数字,就得到年龄了:)
我相信这样的方法可以用任何语言实现:
20080814-19800703=280111
去除最后4位 = 28.
int Now =int.Parse(DateTime.Today.ToString("yyyyMMdd"));
int dob =int.Parse(datedob.ToString("yyyyMMdd"));
string dif =(Now - dob).ToString();
string age ="0";
if(dif.Length>4)
age = dif.Substring(0,dif.Length-4);
方法3:
DateTime Now =DateTime.Today; int age = Now.Year- bday.Year; if(bday > Now.AddYears(-age)) age--;
以上所述就是本文的全部内容了,希望能对大家学习C#有所帮助。

Calendar 计算年龄
//由出生日期获取年龄
public static int getAge(Date birthday){
if (birthday == null) {
return 0;
}
Calendar cal = Calendar.getInstance();
if (cal.before(birthday)) {
return 0;
}
//获取当前的年月日
int yearNow = cal.get(Calendar.YEAR);
int monthNow = cal.get(Calendar.MONTH);
int dayOfMonthNow = cal.get(Calendar.DAY_OF_MONTH);
//获取出生年月日
cal.setTime(birthday);
int yearBirth = cal.get(Calendar.YEAR);
int monthBirth = cal.get(Calendar.MONTH);
int dayOfMonthBirth = cal.get(Calendar.DAY_OF_MONTH);
int age = yearNow - yearBirth;
if (monthNow <= monthBirth) { if (monthNow == monthBirth) { if (dayOfMonthNow < dayOfMonthBirth) age--; } else { age--; } } return age; }

days360函数计算年龄

days360函数计算年龄
excel中计算年龄的方式有很多种,这里为大家介绍days360函数来计算年龄的方法。
推荐教程:excel教程
days360函数格式:
days360(开始时间, 结束时间)
1、首先在C2单元格输入公式
=DAYS360(B2,TODAY())
today()也是一个函数,用于计算当前时间。

2、这是年龄显示的是天数,我们将它除以365
c3单元格输入
=DAYS360(B3,TODAY())/365

3、这是年龄显示有小数,我们可以进行单元格格式设置



c4单元格为最终效果,这样年龄就计算出来了。
以上就是days360函数计算年龄的详细内容,更多请关注php中文网其它相关文章!

delphi使用回车设置焦点改变
总结
以上是小编为你收集整理的delphi使用回车设置焦点改变全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
今天的关于焦点改变后自动计算年龄和焦点时间的分享已经结束,谢谢您的关注,如果想了解更多关于C#实现计算年龄的简单方法汇总、Calendar 计算年龄、days360函数计算年龄、delphi使用回车设置焦点改变的相关知识,请在本站进行查询。
以上就是给各位分享如何在编译时驱动C#,C ++或Java编译器来计算1 + 2 + 3 +…+ 1000?,其中也会对c编译器实现进行解释,同时本文还将给你拓展c – 如何在编译时建立有向图?、c – 如何在编译时替换元组元素?、c – 编译器在编译时如何检测编号溢出?、delphi – 如何在每次编译时强制使用资源编译器?等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- 如何在编译时驱动C#,C ++或Java编译器来计算1 + 2 + 3 +…+ 1000?(c编译器实现)
- c – 如何在编译时建立有向图?
- c – 如何在编译时替换元组元素?
- c – 编译器在编译时如何检测编号溢出?
- delphi – 如何在每次编译时强制使用资源编译器?
")
如何在编译时驱动C#,C ++或Java编译器来计算1 + 2 + 3 +…+ 1000?(c编译器实现)
在最近的一次采访中,有人问我一个非常奇怪的问题。面试官问我如何仅使用编译器功能来计算1 + 2 + 3 + … +
1000。这意味着我不允许编写程序并执行它,但我只应该编写一个程序,该程序可以驱动编译器在编译时计算此和,并在编译完成时打印结果。作为提示,他告诉我,我可能会使用编译器的泛型和预处理器功能。可以使用C
++,C#或Java编译器。有任何想法吗???
此问题与此处未询问任何循环的求和无关。另外,应该注意,总和应该在编译期间计算。使用C
++编译器指令仅打印结果是不可接受的。
阅读有关发布的答案的更多信息后,我发现在使用C 模板进行编译期间解决问题称为 metaprogramming 。这是Erwin
Unruh博士在标准化C 语言的过程中偶然发现的一项技术。您可以在meta-
programming的Wiki页面上阅读有关此主题的更多信息。似乎可以使用Java注释用Java编写程序。您可以在下面查看
maress的 答案。
关于用C元编程++一个很好的书是这一个。如果有兴趣的话值得一看。
Boost的MPL
这个链接是有用的C
++元编程库。
答案1
小编典典*立即 *更新, 具有改进的递归深度!无需增加深度即可在MSVC10和GCC上运行。:)
简单的编译时递归+加法:
template<unsigned Cur, unsigned Goal>struct adder{ static unsigned const sub_goal = (Cur + Goal) / 2; static unsigned const tmp = adder<Cur, sub_goal>::value; static unsigned const value = tmp + adder<sub_goal+1, Goal>::value;};template<unsigned Goal>struct adder<Goal, Goal>{ static unsigned const value = Goal;};测试码:
template<unsigned Start>struct sum_from{ template<unsigned Goal> struct to{ template<unsigned N> struct equals; typedef equals<adder<Start, Goal>::value> result; };};int main(){ sum_from<1>::to<1000>::result();}GCC的输出:
错误:声明’struct sum_from <1u> :: to <1000u> :: equals <500500u>’
有关Ideone的现场示例。
MSVC10的输出:
error C2514: ''sum_from<Start>::to<Goal>::equals<Result>'' : class has no constructors with [ Start=1, Goal=1000, Result=500500 ]
c – 如何在编译时建立有向图?
示例:我有一些线程和队列,并希望建立:
+-------+ +---------+ +-------+
| f_gen | -> QGen -> | f_check | -> QOut -> | f_out |
+-------+ +---------+ ^ +-------+
| |
\|/ |
| |
QProc |
| |
\|/ |
| |
+-----------+ |
| f_process | /
+-----------+
请注意,这只是一个例子:解决方案应该处理
每个节点/边缘类型的有向图.
我想写它可能像:
make_directed_graph<Queue,Thread>(
// Queues
{
// ID,Type of Queue,queue size
{ 0,std::string,100 },// QGen
{ 1,int,250 },// QProc
{ 2,500 } // QOut
},// Threads
{
// Fn,thread cnt,in queues,out queues
{ f_gen,5,{},{ qref(0) } },// ID 1: QGen
{ f_check,30,{ qref(0) },{ qref(1),qref(2) }},// IDs of queues
{ f_process,75,{ qref(1) },{ qref(2) }},{ f_out,12,{ qref(2) },{} }
});
请注意,这只是一个想法 – 任何其他可能性
写这个对我来说很好.
我设法实现了make_tree函数.
它可以像
make_tree< arexp,int >(
{ '+',{ 1,2,{ '*',{ 3,4,5 } } } } )
这里有一个很大的区别:可以创建节点和边缘
苍蝇’ – 没有必要参考任何现有的.
有向图的最大问题是如何引用一个对象/
前面定义的结构/部分.喜欢:如何参考一个
定义线程时的队列(或反之).
我的问题:
>是否可以在编译时定义有向图?
>如果是的话,请你给我一个提示如何实施它?
解决方法
Queue<std::string> QGen(100); // No need for an ID,we have &QGen. // We *do* need to pass the Queue type to figure out the type of &QGen. Thread<void,nullptr,&QGen> f_gen(5);
当然,您无法以这种方式定义循环图.

c – 如何在编译时替换元组元素?
例如,
using a_t = std::tuple<std::string,unsigned>; // start with some n-tupleusing b_t = element_replace<a_t,1,double>; // std::tuple<std::string,double>using c_t = element_replace<b_t,char>; // std::tuple<char,double>
解决方法
// the usual helpers (BTW: I wish these would be standardized!!)template< std::size_t... Ns >struct indices{ typedef indices< Ns...,sizeof...( Ns ) > next;};template< std::size_t N >struct make_indices{ typedef typename make_indices< N - 1 >::type::next type;};template<>struct make_indices< 0 >{ typedef indices<> type;};// and Now we use themtemplate< typename Tuple,std::size_t N,typename T,typename Indices = typename make_indices< std::tuple_size< Tuple >::value >::type >struct element_replace;template< typename... Ts,std::size_t... Ns >struct element_replace< std::tuple< Ts... >,N,T,indices< Ns... > >{ typedef std::tuple< typename std::conditional< Ns == N,Ts >::type... > type;}; 然后使用它:
using a_t = std::tuple<std::string,unsigned>; // start with some n-tupleusing b_t = element_replace<a_t,double>::type; // std::tuple<std::string,char>::type; // std::tuple<char,double>

c – 编译器在编译时如何检测编号溢出?
我的问题是数字150仍然是字符串,编译器使用什么算法来比较数字序列 – 在这种情况下为150 – 对类型限制?
我为一个十进制,八进制,十六进制和小端二进制的类型’int’做了一个简单的算法,但我不认为编译器会这样做以检测数字溢出.
我所做的算法用C编码:
typedef signed char int8;
typedef signed int int32;
#define DEC 0
#define HEX 1
#define OCT 2
#define BIN 3
bool isOverflow(const char* value,int32 base)
{
// left-most digit for maximum and minimum number
static const char* max_numbers[4][2] =
{
// INT_MAX INT_MIN
{ "2147483647","2147483648" },// decimal
{ "7fffffff","80000000" },// hexadecimal
{ "17777777777","20000000000" },// octal
{ "01111111111111111111111111111111","10000000000000000000000000000000" } // binary
};
// size of strings in max_numbers array
static const int32 number_sizes[] = { 10,8,11,32 };
// input string size
int32 str_len = strlen(value);
// is sign mark exist in input string
int32 signExist = ((base == DEC || base == OCT) && *value == '-');
// first non zero digit in input number
int32 non_zero_index = signExist;
// locate first non zero index
while(non_zero_index < str_len && value[non_zero_index] == 0) non_zero_index++;
// if non_zero_index equal length then all digits are zero
if (non_zero_index == str_len) return false;
// get number of digits that actually represent the number
int32 diff = str_len - non_zero_index;
// if difference less than 10 digits then no overflow will happened
if (diff < number_sizes[base]) return false;
// if difference greater than 10 digits then overflow will happened
if (diff > number_sizes[base]) return true;
// left digit in input and search strings
int8 left1 = 0,left2 = 0;
// if digits equal to 10 then loop over digits from left to right and compare
for (int32 i = 0; non_zero_index < str_len; non_zero_index++,i++)
{
// get input digit
left1 = value[non_zero_index];
// get match digit
left2 = max_numbers[signExist][i];
// if digits not equal then if left1 is greater overflow will occurred,false otherwise
if (left1 != left2) return left1 > left2;
}
// overflow won't happened
return false;
}
可以优化该算法以适用于所有整数类型,但是使用浮点数我必须使用新的算法来处理IEEE浮点表示.
我认为编译器使用有效的算法来检测除了我的溢出,不是吗?
解决方法
但现在,考虑一下你原来的问题;如果你把数字和刚构建的例程视为数字呢?比方说,一个可以采取的算法
6+5
并将总和计算为两位数的字符串11?将其扩展到其他操作,您可以直接计算32769是否大于32768.

delphi – 如何在每次编译时强制使用资源编译器?
更新:受到接受的答案的启发,我写道:https://gist.github.com/2868141
解决方法
今天关于如何在编译时驱动C#,C ++或Java编译器来计算1 + 2 + 3 +…+ 1000?和c编译器实现的介绍到此结束,谢谢您的阅读,有关c – 如何在编译时建立有向图?、c – 如何在编译时替换元组元素?、c – 编译器在编译时如何检测编号溢出?、delphi – 如何在每次编译时强制使用资源编译器?等更多相关知识的信息可以在本站进行查询。
针对当多个Java程序在同一台计算机上运行时和一个java多线程的程序在不同计算机上运行这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展angular-cli在同一台计算机上的不同版本、Cupy添加在同一台计算机上的不同环境中的不同工作方式、delphi – 如何在同一台计算机上部署两个或多个使用Firebird嵌入式数据库的应用程序?、java – 在一台计算机上模拟p2p网络流量等相关知识,希望可以帮助到你。
本文目录一览:- 当多个Java程序在同一台计算机上运行时(一个java多线程的程序在不同计算机上运行)
- angular-cli在同一台计算机上的不同版本
- Cupy添加在同一台计算机上的不同环境中的不同工作方式
- delphi – 如何在同一台计算机上部署两个或多个使用Firebird嵌入式数据库的应用程序?
- java – 在一台计算机上模拟p2p网络流量
")
当多个Java程序在同一台计算机上运行时(一个java多线程的程序在不同计算机上运行)
每个Java应用程序都将在特定的Java虚拟机实例中运行。我真的在以下方面感到困惑,而Google搜索使我更加困惑。不同网站上的不同文章。
如果我有一个用Java编写的Web服务,它将需要一个JVM实例来运行,那么JVM可以成为守护进程吗?
如果是,当我们运行任何其他Java应用程序时,它将使用该JVM实例还是创建一个新的JVM?
任何机器上可用的主内存是恒定的。当我们同时启动n个Java进程而不提供任何初始堆大小时,堆大小如何在进程之间分配?
是否有管理n个JVM实例的进程,或者由OS本身管理?
当GC发生世界末日时,是否会影响其他JVM实例(我认为是不同的线程)?
答案1
小编典典1)如果我有一个用Java编写的Web服务,它将需要一个JVM实例来运行。那么可以将JVM设为守护进程吗?
是的,它可以。如何完成取决于O / S和Web服务器容器本身。
2)如果是,当我们运行任何其他Java应用程序时,它将使用此JVM实例还是创建一个新的JVM?
否。每个Java应用程序都使用一个独立的JVM。
每个JVM是一个单独的进程,这意味着不会共享堆栈,堆等。(通常,唯一可以共享的内容是保存核心JVM和本机库代码的只读段,就像普通进程可以共享代码段一样。)
3)在任何机器上可用的主存储器是恒定的。当我们同时启动n个Java进程而不提供任何初始堆大小时,堆大小如何在进程之间分配?
如果不指定大小,则决定堆大小的机制取决于所使用的JVM /平台/版本,以及是否使用“客户端”或“服务器”模型(对于Hotspot
JVM)。启发式算法没有考虑其他JVM的数量或大小。
参考:https :
//stackoverflow.com/a/4667635/139985
实际上,最好直接指定堆大小。
4)是否有管理n个JVM实例的进程,或者由OS本身管理?
都不行
JVM实例的数量取决于可以启动进程的各种事物的动作。例如守护程序脚本,命令脚本,用户在命令行中键入命令等。最终,如果操作系统用尽了资源,则OS可能会拒绝启动更多进程,但是JVM与其他进程没有任何区别。
5)当GC期间发生世界末日时,是否会影响其他JVM实例(我认为是不同的线程)?
否。JVM是独立的进程。他们没有任何可变状态。垃圾收集在每个JVM上独立运行。

angular-cli在同一台计算机上的不同版本
请向任何指向正确方向的人表示非常感谢.
提前致谢…
在我的例子中,我在一个项目中使用Node 6.9.5和Angular2,在另一个项目中使用Node 10和Angular6.
您只需注意哪个版本就位,并像平常一样正常工作.

Cupy添加在同一台计算机上的不同环境中的不同工作方式
您可能同时安装了cupy和cupy-cudaXXX,这将导致各种奇怪的问题。如果是这样,请移开杯子,并坚持使用车轮版本。

delphi – 如何在同一台计算机上部署两个或多个使用Firebird嵌入式数据库的应用程序?
如果客户购买我的所有三个应用程序并将其安装在他/她的计算机上.我的客户同时运行所有三个应用程序,会发生什么?
Firebird dll会有冲突吗?你在这种情况下做了什么?
解决方法
如果要使用不同版本的dll,则必须确保每个应用程序都安装到自己的文件夹中.

java – 在一台计算机上模拟p2p网络流量
我处于网络对等项目的早期阶段,并确定客户端的一些必要特性,我希望能够在我的PC上同时模拟100个实例.
理想情况下,我想创建一个套接字的“模拟”版本,它们有自己的输入和输出流.最后,我将使用这些流进行数据传输,而不是仅仅在java对象之间移动数据,因此我想要模拟的是延迟,数据丢失和您在实际网络中可能遇到的其他错误.
理想情况下,这些模拟方法将非常接近java.net.*的实际流标准,因此我不需要进行大量重写以便从模拟转移到实际客户端.
谁能指出我正确的方向?
解决方法
这是一个示例项目:
https://github.com/adelbertc/scalanet
关于当多个Java程序在同一台计算机上运行时和一个java多线程的程序在不同计算机上运行的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于angular-cli在同一台计算机上的不同版本、Cupy添加在同一台计算机上的不同环境中的不同工作方式、delphi – 如何在同一台计算机上部署两个或多个使用Firebird嵌入式数据库的应用程序?、java – 在一台计算机上模拟p2p网络流量等相关知识的信息别忘了在本站进行查找喔。
如果您想了解如何使用IntelliJ IDEA计算Java代码行数?的相关知识,那么本文是一篇不可错过的文章,我们将对idea统计java代码行数进行全面详尽的解释,并且为您提供关于android – 如何使用IntelliJ IDEA正确配置AdMob?、IntelliJ IDEA 常用快捷键 及 技巧(Java代码)、Intellij IDEA中一次性折叠所有Java代码的快捷键设置、Intellij IDEA中常用的编写Java代码快的快捷方式总结的有价值的信息。
本文目录一览:- 如何使用IntelliJ IDEA计算Java代码行数?(idea统计java代码行数)
- android – 如何使用IntelliJ IDEA正确配置AdMob?
- IntelliJ IDEA 常用快捷键 及 技巧(Java代码)
- Intellij IDEA中一次性折叠所有Java代码的快捷键设置
- Intellij IDEA中常用的编写Java代码快的快捷方式总结
")
如何使用IntelliJ IDEA计算Java代码行数?(idea统计java代码行数)
如何使用IntelliJ IDEA计算Java代码行数?
答案1
小编典典该统计插件为我工作。
要从Intellij安装它:
文件-设置-插件-浏览存储库…在列表中找到它,然后双击它。
从以下位置打开统计信息窗口:
查看->工具窗口->统计

android – 如何使用IntelliJ IDEA正确配置AdMob?
>是否需要下载AdMob SDK所需的所有初步步骤.
>按照指示here,试图为IntelliJ IDEA增加它们.我已将AdMob SDK的单入口模块库依赖项添加到我的项目中.
如果我尝试在代码中使用它,IDE看起来像是没有问题识别SDK中的类.但是,它无法在XML中解析它们.我有以下两个错误:
>当我在AndroidManifest.xml中设置广告活动时,无法解析符号’AdActivity’.
>当我尝试以文档here的方式向广告添加广告视图时,不允许使用元素com.google.ads.AdView.
非常感谢您的帮助.我希望我已经清楚了.
编辑
根据Cristian的回答进行澄清.确实,第一个错误似乎并不重要.但是,第二个错误导致项目构建中断以下消息:
… / res / layout / main.xml:7:错误:解析XML时出错:未绑定的前缀
有问题的XML是以下布局:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:orientation="vertical"
android:layout_width="fill_parent"
android:layout_height="fill_parent">
<com.google.ads.AdView android:id="@+id/adView"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
ads:adUnitId="MY_AD_UNIT_ID"
ads:adSize="BANNER"
ads:loadAdOnCreate="true"/>
<ImageView android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentTop="true"
android:layout_marginLeft="123dp"
android:src="@drawable/logo"/>
<ImageView android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_alignParentRight="true"
android:src="@drawable/cart"/>
<Button android:id="@+id/new_shopping_list"
android:layout_width="223dp"
android:layout_height="wrap_content"
android:layout_marginTop="90dp"
android:text="@string/new_shopping_list_btn"/>
<Button android:id="@+id/view_all_shopping_lists"
android:layout_width="223dp"
android:layout_height="wrap_content"
android:layout_below="@id/new_shopping_list"
android:text="@string/saved_shopping_lists_btn"/>
<ImageView android:id="@+id/copyright_notice"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_alignParentRight="true"
android:layout_marginBottom="7dp"
android:layout_marginRight="5dp"
android:src="@drawable/copyright"/>
<ImageView android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_above="@id/copyright_notice"
android:layout_alignParentRight="true"
android:layout_marginBottom="5dp"
android:layout_marginRight="4dp"
android:src="@drawable/techsmart_logo"/>
<ImageButton android:id="@+id/user_guide"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_alignParentLeft="true"
android:layout_marginBottom="7dp"
android:layout_marginLeft="5dp"
android:src="@drawable/user_guide"/>
</RelativeLayout>
解决方法
正如您所看到的,还有像Pontiflex或AirPush这样的其他库存在同样的问题.
关于你的第二个问题,你似乎忘了添加XML NameSpace. This回答说你必须添加这个:
xmlns:ads="http://schemas.android.com/apk/lib/com.google.ads"
")
IntelliJ IDEA 常用快捷键 及 技巧(Java代码)
查看当前类的所有方法:alt + 7
补全单词:alt + /
左补全:Ctrl + alt + v
format格式化:Ctrl + alt + L
import导包:alt + enter
快速生成System.out.println();使用:sout
快速生成for循环:fori + enter
快速生成main方法:main + enter
快速遍历list:list.for + enter List<Object> list = new LinkedList<>(); for (Object o : list) { }
快速循环list:list.fori + enter List<Object> list = new LinkedList<>(); for (int i = 0; i < list.size(); i++) { }
快速倒循环list:list.forr + enter List<Object> list = new LinkedList<>(); for (int i = list.size() - 1; i >= 0; i--) { }
快速遍历数组a: a.for + enter int [] a = {5,5,6,8,8,9,2}; for (int i : a) { }
快速循环数据a: a.fori + enter int [] a = {5,5,6,8,8,9,2}; for (int i = 0; i < a.length; i++) { }
快速倒循环数组a:a.forr + enter int [] a = {5,5,6,8,8,9,2}; for (int i = a.length - 1; i >= 0; i--) { }
生成方法体的大括号:Ctrl + shift + enter
复制光标所在的行或选中的行:Ctrl + d
删除光标所在的行或选中的行:Ctrl + y
上移光标所在的行或选中的行:Ctrl + shift + 向上箭头
下移光标所在的行或选中的行:Ctrl + shift + 向下箭头
查看当前类的所有方法:alt + 7
查看当前类或接口的父类或实现的接口:Ctrl + alt + u
例如下图中的LinkedList:蓝色实线(表示类与类之间继承关系),绿色实线(表示接口与接口之间的继承关系),绿色虚线(表示类与接口之间的实现关系)

查看当前类下面的所有子类或实现类:Ctrl + alt + b
例如下图中的List接口:
打开当前选中项目所在的文件夹:
idea开启自动提示,如下:
idea开启Java自动导包,如下:
更新maven项目,如下:
编译maven项目,使用package或者install都可以,如下:
单独编译一个Java类,如下:
安装mybatis plus插件及使用,如下:


Intellij IDEA中一次性折叠所有Java代码的快捷键设置
这篇文章主要介绍了Intellij IDEA中一次性折叠所有Java代码的快捷键设置,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
问题:在Java文件中,想把所有的Java方法代码都一次性给折叠起来,用哪个点开哪个。
问题来源:在新建model bean的时候,要是属性很多,那么对应的getter和setter就会很多,要是所有的方法代码都是展开状态,那么这个文件看着也不甚美观,所以,可以把方法都折叠起来。
下面看怎么设置快捷键:看法宝。。。



要是看不懂,系统自带的快捷键配置,大可以,自己再修改个,就像这个折叠代码的这个快件,折叠一个方法的快捷键是: ctrl + 减号。
我就把折叠所有的快捷键设置成:ctrl+shift+减号。
这样也好记忆,
到此这篇关于Intellij IDEA中一次性折叠所有Java代码的快捷键设置的文章就介绍到这了,更多相关IDEA折叠所有Java代码内容请搜索小编以前的文章或继续浏览下面的相关文章希望大家以后多多支持小编!

Intellij IDEA中常用的编写Java代码快的快捷方式总结
1. main函数快捷键 —— psvm
特别好记:public static void main的缩写
2. System.out.println();输出快捷键 —— sout
3. for(int i=0;i<;i++)for循环遍历快捷键 —— fori
一般用来写算法题,各种循环遍历中特别快捷
4. foreach循环遍历快捷键 —— iter
5. itli
6. itit
7.try...catch(对于Mac来说是option+command+T)
我们今天的关于如何使用IntelliJ IDEA计算Java代码行数?和idea统计java代码行数的分享已经告一段落,感谢您的关注,如果您想了解更多关于android – 如何使用IntelliJ IDEA正确配置AdMob?、IntelliJ IDEA 常用快捷键 及 技巧(Java代码)、Intellij IDEA中一次性折叠所有Java代码的快捷键设置、Intellij IDEA中常用的编写Java代码快的快捷方式总结的相关信息,请在本站查询。
本文将带您了解关于将异步计算包装为同步的新内容,同时我们还将为您解释阻塞计算的相关知识,另外,我们还将为您提供关于ajax怎么将异步请求改为同步、c# – 将异步操作转换为异步函数委托,保留同步异常传递、GIL 与多线程(线程池与进程池,同步异步阻塞非阻塞)、IO 模式和 IO 多路复用(阻塞 IO、非阻塞 IO、同步 IO、异步 IO 等概念)的实用信息。
本文目录一览:- 将异步计算包装为同步(阻塞)计算(如何将异步变为同步)
- ajax怎么将异步请求改为同步
- c# – 将异步操作转换为异步函数委托,保留同步异常传递
- GIL 与多线程(线程池与进程池,同步异步阻塞非阻塞)
- IO 模式和 IO 多路复用(阻塞 IO、非阻塞 IO、同步 IO、异步 IO 等概念)
计算(如何将异步变为同步)")
将异步计算包装为同步(阻塞)计算(如何将异步变为同步)
我有一个对象,该对象带有一种方法,希望以类似以下方式向库客户端(尤其是脚本客户端)公开:
interface MyNiceInterface{ public Baz doSomethingAndBlock(Foo fooArg, Bar barArg); public Future<Baz> doSomething(Foo fooArg, Bar barArg); // doSomethingAndBlock is the straightforward way; // doSomething has more control but deals with // a Future and that might be too much hassle for // scripting clients}但是我可以使用的原始“东西”是一组事件驱动的类:
interface BazComputationSink{ public void onBazResult(Baz result);}class ImplementingThing{ public void doSomethingAsync(Foo fooArg, Bar barArg, BazComputationSink sink);}在其中,ImplementingThing接受输入,执行一些不可思议的工作,例如将任务排队入队列,然后稍后在发生结果时,sink.onBazResult()在可能与调用ImplementingThing.doSomethingAsync()相同的线程上调用该线程。
有没有一种方法可以使用我拥有的事件驱动功能以及并发原语来实现MyNiceInterface,以便脚本客户端可以愉快地等待阻塞线程?
编辑:
我可以为此使用FutureTask吗?
答案1
小编典典使用您自己的Future实现:
public class BazComputationFuture implements Future<Baz>, BazComputationSink { private volatile Baz result = null; private volatile boolean cancelled = false; private final CountDownLatch countDownLatch; public BazComputationFuture() { countDownLatch = new CountDownLatch(1); } @Override public boolean cancel(final boolean mayInterruptIfRunning) { if (isDone()) { return false; } else { countDownLatch.countDown(); cancelled = true; return !isDone(); } } @Override public Baz get() throws InterruptedException, ExecutionException { countDownLatch.await(); return result; } @Override public Baz get(final long timeout, final TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { countDownLatch.await(timeout, unit); return result; } @Override public boolean isCancelled() { return cancelled; } @Override public boolean isDone() { return countDownLatch.getCount() == 0; } public void onBazResult(final Baz result) { this.result = result; countDownLatch.countDown(); }}public Future<Baz> doSomething(Foo fooArg, Bar barArg) { BazComputationFuture future = new BazComputationFuture(); doSomethingAsync(fooArg, barArg, future); return future;}public Baz doSomethingAndBlock(Foo fooArg, Bar barArg) { return doSomething(fooArg, barArg).get();}该解决方案在内部创建一个CountDownLatch,一旦收到回调,该计数器将被清除。如果用户调用get,则使用CountDownLatch阻止调用线程,直到计算完成并调用onBazResult回调。CountDownLatch将确保如果回调在调用get()之前发生,则get()方法将立即返回结果。

ajax怎么将异步请求改为同步
ajax中根据async值的不同可分为同步和异步,默认情况下async值是true(异步提交);而想将异步改为同步,只需要将async的值设置为false即可。

本教程操作环境:windows7系统、javascript1.8.5版、Dell G3电脑。
AJAX中根据async的值不同分为同步(async = false)和异步(async = true)
默认情况下async是true(异步提交)。
如果想同步 async设置为false就可以。
示例:
使用AJAX时,偶尔会遇上需要从一个接口中得到一个数组和数据对应的id,在另一个接口上再得到数据,最初写法如下:
$.get(url_1, function (data) {
var dom = [];
for (var i = 0; i < data.length; i++) {
var item = data[i];
//两个url不一致,根据id查找另一个表
$.get(url_2, function (data) {
var item_result = data;
dom.push("<div> item_result.id</div>");
});
}
$("#id").empty().append(dom.join(''));
});但是此时经常会出现数组清空后并没有写入数据的问题,初学时常误以为时接口错误的问题,其实不然
这是由于$get()等Ajax方法在调用接口时需要时间,导致push还未完成已经发生了append的行为,即此时数组清空,但是dom数组中此时并没有join读取的数据
故此处需要将循环中的Ajax修改为同步,代码修改如下:
$.get(url_1, function (data) {
var dom = [];
for (var i = 0; i < data.length; i++) {
var item = data[i];
//在第二次的Ajax前将异步改同步
$.ajaxSettings.async = false;
//两个url不一致,根据id查找另一个表
$.get(url_2, function (data) {
var item_result = data;
dom.push("<div> item_result.id</div>");
});
//注意在ajax中的push完成后,将其改回异步
$.ajaxSettings.async = true;
}
$("#id").empty().append(dom.join(''));
});【相关教程推荐:AJAX视频教程】
以上就是ajax怎么将异步请求改为同步的详细内容,更多请关注php中文网其它相关文章!

c# – 将异步操作转换为异步函数委托,保留同步异常传递
public static Func<Task<TResult>> Return<TResult>(this Func<Task> asyncAction,TResult result)
{
ArgumentValidate.NotNull(asyncAction,nameof(asyncAction));
return async () =>
{
await asyncAction();
return result;
};
}
但是,我的扩展方法是错误的,因为从操作委托同步传递的异常现在从函数委托异步传递.具体来说:
Func<Task> asyncAction = () => { throw new InvalidOperationException(); };
var asyncFunc = asyncAction.Return(42);
var task = asyncFunc(); // exception should be thrown here
await task; // but instead gets thrown here
有没有办法以同步异常继续同步传递的方式创建此包装器?继续继续前进的道路吗?
更新:同步抛出异常的异步操作的具体示例:
public static Task WriteallBytesAsync(string filePath,byte[] bytes)
{
if (filePath == null)
throw new ArgumentNullException(filePath,nameof(filePath));
if (bytes == null)
throw new ArgumentNullException(filePath,nameof(bytes));
return WriteallBytesAsyncInner(filePath,bytes);
}
private static async Task WriteallBytesAsyncInner(string filePath,byte[] bytes)
{
using (var fileStream = File.OpenWrite(filePath))
await fileStream.WriteAsync(bytes,bytes.Length);
}
测试:
Func<Task> asyncAction = () => WriteallBytesAsync(null,null); var asyncFunc = asyncAction.Return(42); var task = asyncFunc(); // ArgumentNullException should be thrown here await task; // but instead gets thrown here
解决方法
public static Func<Task<TResult>> Return<TResult>(this Func<Task> asyncAction,nameof(asyncAction));
return () =>
{
// Call this synchronously
var task = asyncAction();
// Now create an async delegate for the rest
Func<Task<TResult>> intermediate = async () =>
{
await task;
return result;
};
return intermediate();
};
}
或者,将它重构为两个方法,基本上将异步lambda表达式提取为异步方法:
public static Func<Task<TResult>> Return<TResult>(
this Func<Task> asyncAction,nameof(asyncAction));
return () =>
{
var task = asyncAction();
return AwaitAndReturn(task,result);
};
}
public static async Func<Task<TResult>> AwaitAndReturn<TResult>(
this Task asyncAction,TResult result)
{
await task;
return result;
}
")
GIL 与多线程(线程池与进程池,同步异步阻塞非阻塞)
一:什么是 GIL?
GIL 是 Global Interpreter Lock 的缩写,全局解释器锁,是加在解释器上的互斥锁。
''''''
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
''''''
释义:
在CPython中,这个全局解释器锁,也称为GIL,是一个互斥锁,防止多个线程在同一时间执行Python字节码,这个锁是非常重要的,因为CPython的内存管理非线程安全的,很多其他的特性依赖于GIL,所以即使它影响了程序效率也无法将其直接去除
结论:在Cpython解释器中,同一个进程中下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
需要申明一点的是 GIL 并不是 Python 的特性,它是在实现 Python 解释器(Cpython)时引入的概念。python 中一段代码可以通过 Cpython,PyPy,Psyco 等不同的 Python 执行环境来执行。然而因为 Cpython 是大部分环境下默认的 Python 执行环境。所以在很多人的概念里 Cpython 就是 Python。所以需要明确的一点是,GIL 仅存在于 Cpython 中,这不是 Python 这门语言的缺陷,而是 Cpython 解释器的问题。
二:GIL 介绍及为什么需要 GIL
GIL 本质就是一把互斥锁,所有互斥锁的本质都是一样的,都是将并发变成并行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据的安全。
可以肯定的一点是:保护不同的数据安全,就应该加不同的锁。
首先明确执行一个 py 文件,分为三个步骤:
1. 从硬盘加载 python 解释器到内存
2. 从硬盘加载 py 文件到内存
3. 解释器解析 py 文件内容,交给 CPU 执行
每当执行一个 py 文件,就会立即启动一个 Python 解释器,产生一个独立的进程。
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问:
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
#2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。也就是说:如果多个线程的 target=work,执行流程如下:
多个线程先访问到解释器的代码,即拿到执行权限,然后将 target 的代码交给解释器的代码去执行解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据 100,可能线程 1 执行 x=100 的同时,而垃圾回收执行的是回收 100 的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的 GIL,保证 python 解释器同一时间只能执行一个任务的代码。
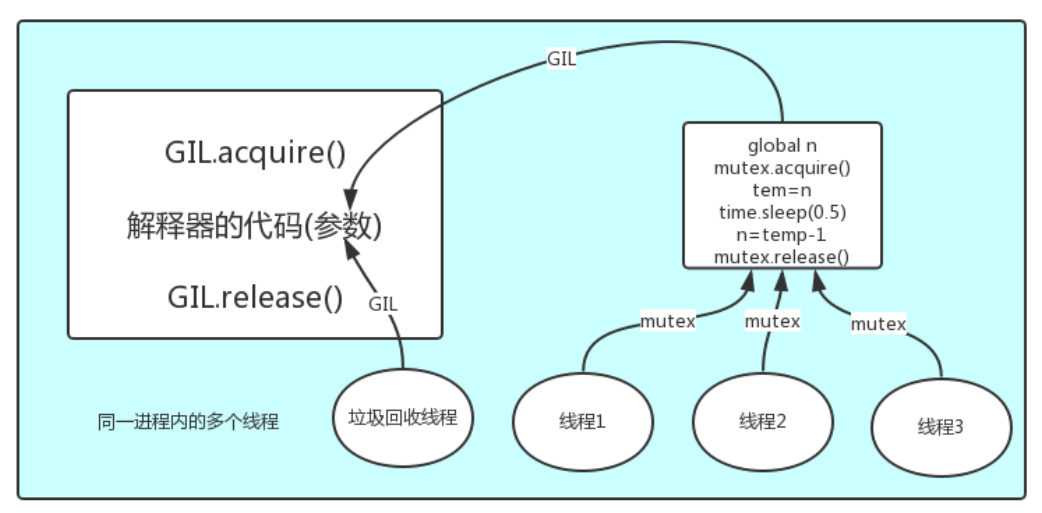
GIL 保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如图:
Python 中内存管理使用的是引用计数,每个数会被加上一个整型的计数器,表示这个数据被引用的次数,当这个整数变为 0 时则表示该数据已经没有人使用,成了垃圾数据。当内存占用达到某个阈值时,GC(内存管理机制)会将其他线程挂起,然后执行垃圾清理操作,垃圾清理也是一串代码,也就需要一条线程来执行。


from threading import Thread
def task():
a = 10
print(a)
# 开启三个子线程执行task函数
Thread(target=task).start()
Thread(target=task).start()
Thread(target=task).start()
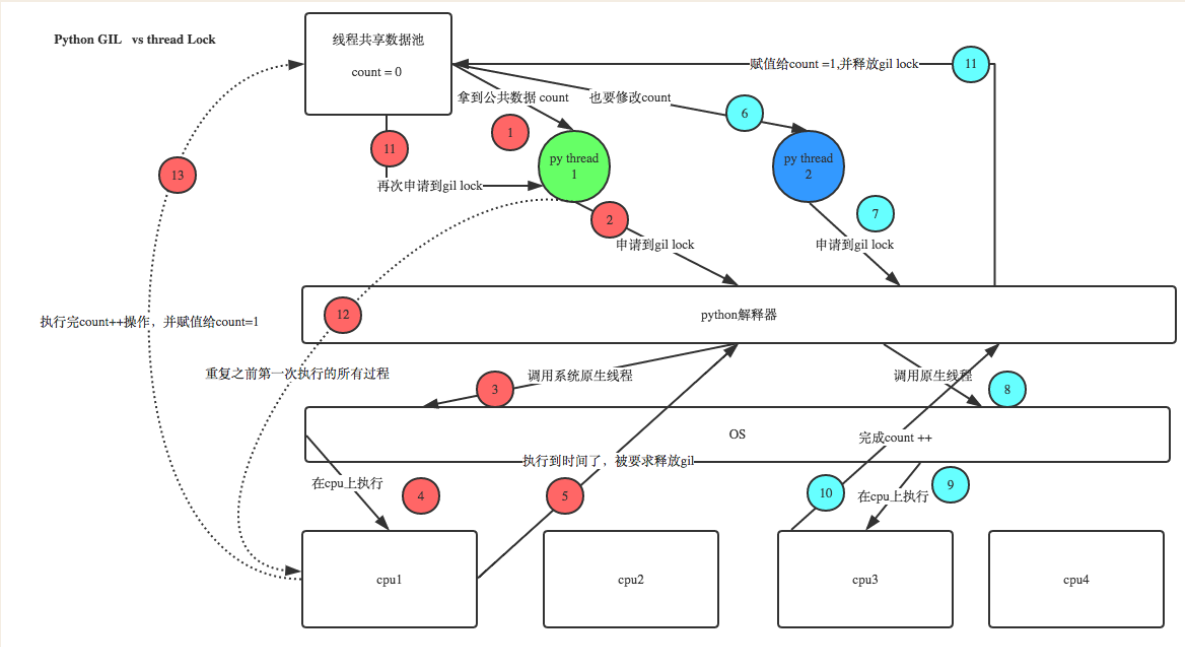
GC与其他线程都在竞争解释器的执行权,而CPU何时切换,以及切换到哪个线程都是无法预支的,这样一来就造成了竞争问题,假设线程1正在定义变量a=10,而定义变量第一步会先到到内存中申请空间把10存进去,第二步将10的内存地址与变量名a进行绑定,如果在执行完第一步后,CPU切换到了GC线程,GC线程发现10的地址引用计数为0则将其当成垃圾进行了清理,等CPU再次切换到线程1时,刚刚保存的数据10已经被清理掉了,导致无法正常定义变量。
为了避免 GC 与其他线程竞争带来的问题,Cpython 给解释器加了锁。
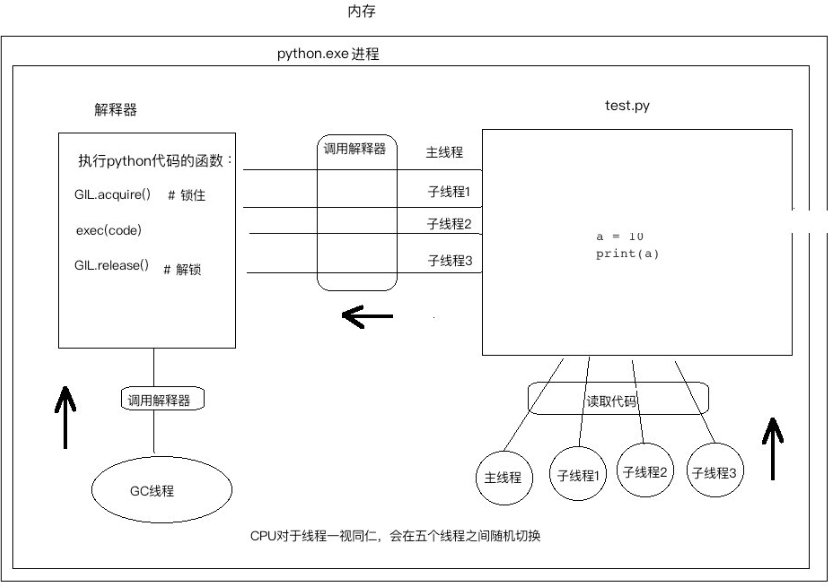
由于互斥锁的特性,程序串行,保证数据的安全,降低执行效率,GIL 将使得程序整体效率降低。
示例二:当进程中只有一条线程时,GIL 锁不会有任何的影响,但是如果进程中有多个线程时,GIL 锁就开始发挥作用。(代码要执行则必须交由解释器,即多个线程之间就需要共享解释器,为了避免共享带来的数据竞争问题,就要给解释器加互斥锁)
三:GIL 加锁与解锁时机
加锁:在调用解释器时立即加锁
解锁:1. 当前线程遇到了 IO 时释放
2. 当前线程执行时间超过设定值时释放,解释器会检测线程的执行时间,一旦到达某个阈值,就会通知线程保存状态切换线程,一次来保存数据安全。
四:关于 GIL 的性能讨论
GIL 优点:保证了 Cpython 中的内存管理是安全的
GIL 缺点:互斥锁的特性使得多线程无法并行
但是,在单核处理器下,多线程之间本来就无法真正的并行执行。在多核处理下,运算效率的确比单核处理器高,但是在现代应用程序多数是基于网络的(QQ,微信,爬虫等),CPU 的运行效率是无法决定网络速度的,而网络速度远远比不上处理器的运算速度,则意味着每次处理器在执行运算前都需要等待网络 IO,这样一来多核优势也就没有那么明显了。


1. 任务1 从网络上下载一个网页,等待网络IO的时间为1分钟,解析网页数据花费,1秒钟
任务2 将用户输入数据并将其转换为大写,等待用户输入时间为1分钟,转换为大写花费,1秒钟
**单核CPU下:**1.开启第一个任务后进入等待。2.切换到第二个任务也进入了等待。一分钟后解析网页数据花费1秒解析完成切换到第二个任务,转换为大写花费1秒,那么总耗时为:1分+1秒+1秒 = 1分钟2秒
**多核CPU下:**1.CPU1处理第一个任务等待1分钟,解析花费1秒钟。1.CPU2处理第二个任务等待1分钟,转换大写花费1秒钟。由于两个任务是并行执行的所以总的执行时间为1分钟+1秒钟 = 1分钟1秒
可以发现,多核CPU对于总的执行时间提升只有1秒,但是这边的1秒实际上是夸张了,转换大写操作不可能需要1秒,时间非常短!
上面的两个任务都是需要大量IO时间的,这样的任务称之为IO密集型,与之对应的是计算密集型即没有IO操作全都是计算任务。
对于计算密集型任务,Python多线程的确比不上其他语言!为了解决这个弊端,Python推出了多进程技术,可以良好的利用多核处理器来完成计算密集任务。总结:1. 单核下无论是 IO 密集还是计算密集 GIL 都不会产生任何影响
2. 多核下对于 IO 密集任务,GIL 对它的影响可以忽略、
3.Cpython 中 IO 密集任务采用多线程,计算密集任务采用多进程
另外:之所以大量采用 Cpython 解释器,就是因为大量的应用程序都是 IO 密集型的,还有另一个很重要的原因是 Cpython 可以无缝对接各种 C 语言实现的库,这对于一些数学相关的应用程序而言就可以直接使用现成的算法。


from multiprocessing import Process
from threading import Thread
import time
def task():
for i in range(10000000):
i += 1
if __name__ == ''__main__'':
start_time = time.time()
# 多进程
# p1 = Process(target=task)
# p2 = Process(target=task)
# p3 = Process(target=task)
# p4 = Process(target=task)
# 多线程
p1 = Thread(target=task)
p2 = Thread(target=task)
p3 = Thread(target=task)
p4 = Thread(target=task)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(time.time()-start_time)
===========================================
多进程测试结果:
1.8134608268737793
多线程测试结果:
2.144787311553955

from multiprocessing import Process
from threading import Thread
import time
def task():
with open("test.txt",encoding="utf-8") as f:
f.read()
if __name__ == ''__main__'':
start_time = time.time()
# 多进程
# p1 = Process(target=task)
# p2 = Process(target=task)
# p3 = Process(target=task)
# p4 = Process(target=task)
# 多线程
p1 = Thread(target=task)
p2 = Thread(target=task)
p3 = Thread(target=task)
p4 = Thread(target=task)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(time.time()-start_time)
============================================
多线程测试结果:
0.0010006427764892578
多进程测试结果:
0.3288099765777588五:自定义的线程锁与 GIL 的区别
GIL 保护的是解释器级别的数据安全,比如对象的引用计数,垃圾分代数据等等,具体参考垃圾回收机制。而对于程序中自己定义的数据则没有任何的保护效果,所以当程序中出现了共享自定义的数据时就要自己加锁。
未加锁之前:


from threading import Thread,Lock
import time
a = 0
def task():
global a
temp = a
time.sleep(0.01)
a = temp + 1
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)过程分析:
1. 线程 1 获得 CPU 执行权,并获取 GIL 锁执行代码 ,得到 a 的值为 0 后进入睡眠,释放 CPU 并释放 GIL
2. 线程 2 获得 CPU 执行权,并获取 GIL 锁执行代码 ,得到 a 的值为 0 后进入睡眠,释放 CPU 并释放 GIL
3. 线程 1 睡醒后获得 CPU 执行权,并获取 GIL 执行代码 ,将 temp 的值 0+1 后赋给 a,执行完毕释放 CPU 并释放 GIL
4. 线程 2 睡醒后获得 CPU 执行权,并获取 GIL 执行代码 ,将 temp 的值 0+1 后赋给 a,执行完毕释放 CPU 并释放 GIL,最后 a 的值也就是 1
之所以出现问题是因为两个线程子啊并发的执行同一段代码,解决方案就是加锁。


from threading import Thread,Lock
import time
lock = Lock()
a = 0
def task():
global a
lock.acquire()
temp = a
time.sleep(0.01)
a = temp + 1
lock.release()
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)加锁后分析:
1. 线程 1 获得 CPU 执行权,并获取 GIL 锁执行代码 ,得到 a 的值为 0 后进入睡眠,释放 CPU 并释放 GIL,不释放 lock
2. 线程 2 获得 CPU 执行权,并获取 GIL 锁,尝试获取 lock 失败,无法执行,释放 CPU 并释放 GIL
3. 线程 1 睡醒后获得 CPU 执行权,并获取 GIL 继续执行代码 ,将 temp 的值 0+1 后赋给 a,执行完毕释放 CPU 释放 GIL,释放 lock,此时 a 的值为 1
4. 线程 2 获得 CPU 执行权,获取 GIL 锁,尝试获取 lock 成功,执行代码,得到 a 的值为 1 后进入睡眠,释放 CPU 并释放 GIL,不释放 lock
5. 线程 2 睡醒后获得 CPU 执行权,获取 GIL 继续执行代码 ,将 temp 的值 1+1 后赋给 a,执行完毕释放 CPU 释放 GIL,释放 lock,此时 a 的值为 2
六:进程池与线程池
本质上就是一个存储进程或线程的列表。如果是 IO 密集型任务使用线程池,计算密集型任务则使用进程池。
在很多情况下需要控制进程或者线程的数量在一个合理的范围,例如 CPU 程序中,一个客户端对于一个线程,虽然线程开销小,但是不能无限开,否则会耗尽系统资源,所以要控制线程数量。进程池 / 线程池不仅帮我们控制进程 / 线程的数量,还可以帮我们完成进程 / 线程的创建,销毁,以及任务的分配。(TCP 是 IO 密集型,一个使用线程池)


from concurrent.futures import ThreadPoolExecutor
from threading import active_count,current_thread
import os,time
# 创建线程池 指定最大线程数为3 如果不指定 默认为CPU核心数 * 5
pool = ThreadPoolExecutor(3)# 不会立即开启子线程
print(active_count())
def task():
print("%s running.." % current_thread().name)
time.sleep(1)
#提交任务到线程池
for i in range(10):
pool.submit(task)

from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import active_count,current_thread
import os,time
# 创建进程池 最大进程数为3 默认为cpu个数
pool = ProcessPoolExecutor(3)# 不会立即开启子进程
# time.sleep(10)
def task():
print("%s running.." % os.getpid())
time.sleep(1)
if __name__ == ''__main__'':
# #提交任务到进程池
for i in range(10):
pool.submit(task) # 第一次提交任务时会创建进程 ,后续再提交任务,直接交给以及存在的进程来完成,如果没有空闲进程就等待七:同步异步与阻塞非阻塞
阻塞:当程序执行过程中遇到了 IO 操作,在执行 IO 操作时,程序无法继续执行其他代码。
非阻塞:程序正常运行没有遇到 IO 操作,或者通过某种方式是程序即使遇到了也不会停在原地,还可以执行其他操作,以提高 CPU 占用率
阻塞与非阻塞指的是程序的运行状态。
同步指调用:发起任务后必须在原地等待任务执行完成,才能继续执行
异步指调用:发起任务后不用等待任务执行,可以立即执行其他操作
同步会有等待的效果但是这和阻塞完全不同,阻塞时程序会被剥夺 CPU 执行权,而异步调用则不会。异步效率高于同步,到那时并不是所有任务都可以异步执行,判断一个任务是否可以异步的条件是,任务发起方是否立即需要执行结果。


from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(3)
def task(i):
time.sleep(0.01)
print(current_thread().name,"working..")
return i ** i
if __name__ == ''__main__'':
objs = []
for i in range(3):
res_obj = pool.submit(task,i) # 异步方式提交任务# 会返回一个对象用于表示任务结果
objs.append(res_obj)
# 该函数默认是阻塞的 会等待池子中所有任务执行结束后执行
pool.shutdown(wait=True)
# 从结果对象中取出执行结果
for res_obj in objs:
print(res_obj.result())
print("over")

from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(3)
def task(i):
time.sleep(0.01)
print(current_thread().name,"working..")
return i ** i
if __name__ == ''__main__'':
objs = []
for i in range(3):
res_obj = pool.submit(task,i) # 会返回一个对象用于表示任务结果
print(res_obj.result()) #result是同步的一旦调用就必须等待 任务执行完成拿到结果
print("over")
")
IO 模式和 IO 多路复用(阻塞 IO、非阻塞 IO、同步 IO、异步 IO 等概念)
网络编程里常听到阻塞 IO、非阻塞 IO、同步 IO、异步 IO 等概念,总听别人装 13 不如自己下来钻研一下。不过,搞清楚这些概念之前,还得先回顾一些基础的概念。
1 基础知识回顾
注意:咱们下面说的都是 Linux 环境下,跟 Windows 不一样哈~~~
1.1 用户空间和内核空间
现在操作系统都采用虚拟寻址,处理器先产生一个虚拟地址,通过地址翻译成物理地址(内存的地址),再通过总线的传递,最后处理器拿到某个物理地址返回的字节。
对 32 位操作系统而言,它的寻址空间(虚拟存储空间)为 4G(2 的 32 次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对 linux 操作系统而言,将最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF),供内核使用,称为内核空间,而将较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个进程使用,称为用户空间。
补充:地址空间就是一个非负整数地址的有序集合。如 {0,1,2...}。
1.2 进程上下文切换(进程切换)
为了控制进程的执行,内核必须有能力挂起正在 CPU 上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换(也叫调度)。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存当前进程 A 的上下文。
上下文就是内核再次唤醒当前进程时所需要的状态,由一些对象(程序计数器、状态寄存器、用户栈等各种内核数据结构)的值组成。
这些值包括描绘地址空间的页表、包含进程相关信息的进程表、文件表等。
2. 切换页全局目录以安装一个新的地址空间。
...
3. 恢复进程 B 的上下文。
可以理解成一个比较耗资源的过程。
1.3 进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语 (Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得 CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用 CPU 资源的。
1.4 文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于 UNIX、Linux 这样的操作系统。
1.5 直接 I/O 和缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,以 write 为例,数据会先被拷贝进程缓冲区,在拷贝到操作系统内核的缓冲区中,然后才会写到存储设备中。
缓存 I/O 的 write:
直接 I/O 的 write:(少了拷贝到进程缓冲区这一步)
write 过程中会有很多次拷贝,知道数据全部写到磁盘。好了,准备知识概略复习了一下,开始探讨 IO 模式。
回到顶部
2 I/O 模式
对于一次 IO 访问(这回以 read 举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的缓冲区,最后交给进程。所以说,当一个 read 操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux 系统产生了下面五种网络模式的方案:
-- 阻塞 I/O(blocking IO)
-- 非阻塞 I/O(nonblocking IO)
-- I/O 多路复用( IO multiplexing)
-- 信号驱动 I/O( signal driven IO)
-- 异步 I/O(asynchronous IO)
注:由于 signal driven IO 在实际中并不常用,所以我这只提及剩下的四种 IO 模型。
2.1 block I/O 模型(阻塞 I/O)
阻塞 I/O 模型示意图:
read 为例:
(1)进程发起 read,进行 recvfrom 系统调用;
(2)内核开始第一阶段,准备数据(从磁盘拷贝到缓冲区),进程请求的数据并不是一下就能准备好;准备数据是要消耗时间的;
(3)与此同时,进程阻塞(进程是自己选择阻塞与否),等待数据 ing;
(4)直到数据从内核拷贝到了用户空间,内核返回结果,进程解除阻塞。
也就是说,内核准备数据和数据从内核拷贝到进程内存地址这两个过程都是阻塞的。
2.2 non-block(非阻塞 I/O 模型)
可以通过设置 socket 使其变为 non-blocking。当对一个 non-blocking socket 执行读操作时,流程是这个样子:
(1)当用户进程发出 read 操作时,如果 kernel 中的数据还没有准备好;
(2)那么它并不会 block 用户进程,而是立刻返回一个 error,从用户进程角度讲 ,它发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果;
(3)用户进程判断结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦 kernel 中的数据准备好了,并且又再次收到了用户进程的 system call;
(4)那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO 的特点是用户进程在内核准备数据的阶段需要不断的主动询问数据好了没有。
2.3 I/O 多路复用
I/O 多路复用实际上就是用 select, poll, epoll 监听多个 io 对象,当 io 对象有变化(有数据)的时候就通知用户进程。好处就是单个进程可以处理多个 socket。当然具体区别我们后面再讨论,现在先来看下 I/O 多路复用的流程:
(1)当用户进程调用了 select,那么整个进程会被 block;
(2)而同时,kernel 会 “监视” 所有 select 负责的 socket;
(3)当任何一个 socket 中的数据准备好了,select 就会返回;
(4)这个时候用户进程再调用 read 操作,将数据从 kernel 拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select () 函数就可以返回。
这个图和 blocking IO 的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个 system call (select 和 recvfrom),而 blocking IO 只调用了一个 system call (recvfrom)。但是,用 select 的优势在于它可以同时处理多个 connection。
所以,如果处理的连接数不是很高的话,使用 select/epoll 的 web server 不一定比使用多线程 + 阻塞 IO 的 web server 性能更好,可能延迟还更大。
select/epoll 的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在 IO multiplexing Model 中,实际中,对于每一个 socket,一般都设置成为 non-blocking,但是,如上图所示,整个用户的 process 其实是一直被 block 的。只不过 process 是被 select 这个函数 block,而不是被 socket IO 给 block。
2.4 asynchronous I/O(异步 I/O)
真正的异步 I/O 很牛逼,流程大概如下:
(1)用户进程发起 read 操作之后,立刻就可以开始去做其它的事。
(2)而另一方面,从 kernel 的角度,当它受到一个 asynchronous read 之后,首先它会立刻返回,所以不会对用户进程产生任何 block。
(3)然后,kernel 会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel 会给用户进程发送一个 signal,告诉它 read 操作完成了。
2.5 小结
(1)blocking 和 non-blocking 的区别
调用 blocking IO 会一直 block 住对应的进程直到操作完成,而 non-blocking IO 在 kernel 还准备数据的情况下会立刻返回。
(2)synchronous IO 和 asynchronous IO 的区别
在说明 synchronous IO 和 asynchronous IO 的区别之前,需要先给出两者的定义。POSIX 的定义是这样子的:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于 synchronous IO 做”IO operation” 的时候会将 process 阻塞。按照这个定义,之前所述的 blocking IO,non-blocking IO,IO multiplexing 都属于 synchronous IO。
有人会说,non-blocking IO 并没有被 block 啊。这里有个非常 “狡猾” 的地方,定义中所指的”IO operation” 是指真实的 IO 操作,就是例子中的 recvfrom 这个 system call。non-blocking IO 在执行 recvfrom 这个 system call 的时候,如果 kernel 的数据没有准备好,这时候不会 block 进程。但是,当 kernel 中数据准备好的时候,recvfrom 会将数据从 kernel 拷贝到用户内存中,这个时候进程是被 block 了,在这段时间内,进程是被 block 的。
而 asynchronous IO 则不一样,当进程发起 IO 操作之后,就直接返回再也不理睬了,直到 kernel 发送一个信号,告诉进程说 IO 完成。在这整个过程中,进程完全没有被 block。
(3)non-blocking IO 和 asynchronous IO 的区别
可以发现 non-blocking IO 和 asynchronous IO 的区别还是很明显的。
-- 在 non-blocking IO 中,虽然进程大部分时间都不会被 block,但是它仍然要求进程去主动的 check,并且当数据准备完成以后,也需要进程主动的再次调用 recvfrom 来将数据拷贝到用户内存。
-- 而 asynchronous IO 则完全不同。它就像是用户进程将整个 IO 操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查 IO 操作的状态,也不需要主动的去拷贝数据。
回到顶部
3 事件驱动编程模型
3.1 论事件驱动
通常,我们写服务器处理模型的程序时,有以下几种模型:
(1)每收到一个请求,创建一个新的进程,来处理该请求;
(2)每收到一个请求,创建一个新的线程,来处理该请求;
(3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞 I/O 方式来处理请求
上面的几种方式,各有千秋:
第(1)中方法,由于创建新的进程:实现比较简单,但开销比较大,导致服务器性能比较差。
第(2)种方式,由于要涉及到线程的同步,有可能会面临死锁等问题。
第(3)种方式,在写应用程序代码时,逻辑比前面两种都复杂。
综合考虑各方面因素,一般普遍认为第(3)种方式是大多数网络服务器采用的方式。
3.2 看图说话讲事件驱动模型
在 UI 编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU 资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的 CPU 资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的 UI 编程都是事件驱动模型,如很多 UI 平台都会提供 onClick () 事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如 onClick ()、onKeyDown () 等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
事件驱动编程是一种网络编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有 3 个任务需要完成,每个任务都在等待 I/O 操作时阻塞自身。阻塞在 I/O 操作上所花费的时间已经用灰色框标示出来了。
在单线程同步模型中,任务按照顺序执行。如果某个任务因为 I/O 而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这 3 个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的 bug。
在事件驱动版本的程序中,3 个任务交错执行,但仍然在一个单独的线程控制中。当处理 I/O 或者其他昂贵的操作时,注册一个回调到事件循环中,然后当 I/O 操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
回到顶部
4 select/poll/epoll 的区别及其 Python 示例
4.1 select/poll/epoll 的区别
首先前文已述 I/O 多路复用的本质就是用 select/poll/epoll,去监听多个 socket 对象,如果其中的 socket 对象有变化,只要有变化,用户进程就知道了。
select 是不断轮询去监听的 socket,socket 个数有限制,一般为 1024 个;
poll 还是采用轮询方式监听,只不过没有个数限制;
epoll 并不是采用轮询方式去监听了,而是当 socket 有变化时通过回调的方式主动告知用户进程。
4.2 Python select 示例
Python 的 select () 方法直接调用操作系统的 IO 接口,它监控 sockets,open files, and pipes (所有带 fileno () 方法的文件句柄) 何时变成 readable 和 writeable, 或者通信错误,select () 使得同时监控多个连接变的简单,并且这比写一个长循环来等待和监控多客户端连接要高效,因为 select 直接通过操作系统提供的 C 的网络接口进行操作,而不是通过 Python 的解释器。
注意:Using Python’s file objects with select () works for Unix, but is not supported under Windows.
接下来通过 echo server 例子要以了解 select 是如何通过单进程实现同时处理多个非阻塞的 socket 连接的:
import select
import socket
import sys
import Queue
# Create a TCP/IP socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setblocking(0)
# Bind the socket to the port
server_address = (''localhost'', 10000)
print >>sys.stderr, ''starting up on %s port %s'' % server_address
server.bind(server_address)
# Listen for incoming connections
server.listen(5)
select()方法接收并监控3个通信列表, 第一个是所有的输入的data,就是指外部发过来的数据,第2个是监控和接收所有要发出去的data(outgoing data),第3个监控错误信息,接下来我们需要创建2个列表来包含输入和输出信息来传给select().
# Sockets from which we expect to read
inputs = [ server ]
# Sockets to which we expect to write
outputs = [ ]
所有客户端的进来的连接和数据将会被 server 的主循环程序放在上面的 list 中处理,我们现在的 server 端需要等待连接可写(writable) 之后才能过来,然后接收数据并返回 (因此不是在接收到数据之后就立刻返回),因为每个连接要把输入或输出的数据先缓存到 queue 里,然后再由 select 取出来再发出去。
Connections are added to and removed from these lists by the server main loop. Since this version of the server is going to wait for a socket to become writable before sending any data (instead of immediately sending the reply), each output connection needs a queue to act as a buffer for the data to be sent through it.
# Outgoing message queues (socket:Queue)
message_queues = {}
The main portion of the server program loops, calling select() to block and wait for network activity.
下面是此程序的主循环,调用 select () 时会阻塞和等待直到新的连接和数据进来:
while inputs:
# Wait for at least one of the sockets to be ready for processing
print >>sys.stderr, ''\nwaiting for the next event''
readable, writable, exceptional = select.select(inputs, outputs, inputs)
当你把 inputs,outputs,exceptional (这里跟 inputs 共用) 传给 select () 后,它返回 3 个新的 list,我们上面将他们分别赋值为 readable,writable,exceptional, 所有在 readable list 中的 socket 连接代表有数据可接收 (recv), 所有在 writable list 中的存放着你可以对其进行发送 (send) 操作的 socket 连接,当连接通信出现 error 时会把 error 写到 exceptional 列表中。
select() returns three new lists, containing subsets of the contents of the lists passed in. All of the sockets in the readable list have incoming data buffered and available to be read. All of the sockets in the writable list have free space in their buffer and can be written to. The sockets returned in exceptional have had an error (the actual definition of “exceptional condition” depends on the platform).
Readable list 中的 socket 可以有 3 种可能状态,第一种是如果这个 socket 是 main "server" socket, 它负责监听客户端的连接,如果这个 main server socket 出现在 readable 里,那代表这是 server 端已经 ready 来接收一个新的连接进来了,为了让这个 main server 能同时处理多个连接,在下面的代码里,我们把这个 main server 的 socket 设置为非阻塞模式。
The “readable” sockets represent three possible cases. If the socket is the main “server” socket, the one being used to listen for connections, then the “readable” condition means it is ready to accept another incoming connection. In addition to adding the new connection to the list of inputs to monitor, this section sets the client socket to not block.
# Handle inputs
for s in readable:
if s is server:
# A "readable" server socket is ready to accept a connection
connection, client_address = s.accept()
print >>sys.stderr, ''new connection from'', client_address
connection.setblocking(0)
inputs.append(connection)
# Give the connection a queue for data we want to send
message_queues[connection] = Queue.Queue()
第二种情况是这个 socket 是已经建立了的连接,它把数据发了过来,这个时候你就可以通过 recv () 来接收它发过来的数据,然后把接收到的数据放到 queue 里,这样你就可以把接收到的数据再传回给客户端了。
The next case is an established connection with a client that has sent data. The data is read with recv(), then placed on the queue so it can be sent through the socket and back to the client.
else:
data = s.recv(1024)
if data:
# A readable client socket has data
print >>sys.stderr, ''received "%s" from %s'' % (data, s.getpeername())
message_queues[s].put(data)
# Add output channel for response
if s not in outputs:
outputs.append(s)第三种情况就是这个客户端已经断开了,所以你再通过 recv () 接收到的数据就为空了,所以这个时候你就可以把这个跟客户端的连接关闭了。
A readable socket without data available is from a client that has disconnected, and the stream is ready to be closed.
else:
# Interpret empty result as closed connection
print >>sys.stderr, ''closing'', client_address, ''after reading no data''
# Stop listening for input on the connection
if s in outputs:
outputs.remove(s) #既然客户端都断开了,我就不用再给它返回数据了,所以这时候如果这个客户端的连接对象还在outputs列表中,就把它删掉
inputs.remove(s) #inputs中也删除掉
s.close() #把这个连接关闭掉
# Remove message queue
del message_queues[s]对于 writable list 中的 socket,也有几种状态,如果这个客户端连接在跟它对应的 queue 里有数据,就把这个数据取出来再发回给这个客户端,否则就把这个连接从 output list 中移除,这样下一次循环 select () 调用时检测到 outputs list 中没有这个连接,那就会认为这个连接还处于非活动状态
There are fewer cases for the writable connections. If there is data in the queue for a connection, the next message is sent. Otherwise, the connection is removed from the list of output connections so that the next time through the loop select() does not indicate that the socket is ready to send data.
A readable socket without data available is from a client that has disconnected, and the stream is ready to be closed.
else:
# Interpret empty result as closed connection
print >>sys.stderr, ''closing'', client_address, ''after reading no data''
# Stop listening for input on the connection
if s in outputs:
outputs.remove(s) #既然客户端都断开了,我就不用再给它返回数据了,所以这时候如果这个客户端的连接对象还在outputs列表中,就把它删掉
inputs.remove(s) #inputs中也删除掉
s.close() #把这个连接关闭掉
# Remove message queue
del message_queues[s]
最后,如果在跟某个 socket 连接通信过程中出了错误,就把这个连接对象在 inputs\outputs\message_queue 中都删除,再把连接关闭掉。
# Handle "exceptional conditions"
for s in exceptional:
print >>sys.stderr, ''handling exceptional condition for'', s.getpeername()
# Stop listening for input on the connection
inputs.remove(s)
if s in outputs:
outputs.remove(s)
s.close()
# Remove message queue
del message_queues[s]4.3 完整的 server 端和 client 端示例
这里实现了一个 server,其功能就是可以和多个 client 建立连接,每个 client 的发过来的数据加上一个 response 字符串返回给 client 端~~~
erver端:
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
import socket
import select
sk = socket.socket()
sk.bind((''127.0.0.1'', 9000),)
sk.listen(5)
inputs = [sk, ]
outputs = []
message = {} # 实现读写分离
print("start...")
while True:
# 监听的inputs中的socket对象内部如果有变化,那么这个对象就会在rlist
# outputs里有什么对象,wlist中就有什么对象
# []如果这里的对象内部出错,那会把这些对象加到elist中
# 1 是超时时间
rlist, wlist, elist = select.select(inputs, outputs, [], 1)
print(len(inputs), len(outputs))
for r in rlist:
if r == sk:
conn, addr = sk.accept()
conn.sendall(b"ok")
# 这里记住是吧conn添加到inputs中去监听,千万别写成r了
inputs.append(conn)
message[conn] = []
else:
try:
data = r.recv(1024)
print(data)
if not data:
raise Exception(''连接断开'')
message[r].append(data)
outputs.append(r)
except Exception as e:
inputs.remove(r)
del message[r]
for r in wlist:
data = str(message[r].pop(), encoding=''utf-8'')
res = data + "response"
r.sendall(bytes(res, encoding=''utf-8''))
outputs.remove(r)
# 实现读写分离
# IO多路复用的本质是用select、poll、epoll(系统底层提供的)来监听socket对象内部是否有变化
# select 是在Win和Linux中都支持额,相当于系统内部维护了一个for循环,缺点是监听个数有上限(1024),效率不高
# poll的监听个数没有限制,但仍然用循环,效率不高。
# epoll的机制是socket对象变化,主动告诉epoll。而不是轮询,相当于有个回调函数,效率比前两者高
# Nginx就是用epoll。只要IO操作都支持,除开文件操作
# 列表删除指定元素用remove
client端:
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
import socket
sc = socket.socket()
sc.connect(("127.0.0.1", 9000,))
data = sc.recv(1024)
print(data)
while True:
msg = input(">>>:")
if msg == ''q'':
break
if len(msg) == 0:
continue
send_msg = bytes(msg, encoding="utf-8")
sc.send(send_msg)
res = sc.recv(1024)
print(str(res, encoding="utf-8"))
sc.close()
今天的关于将异步计算包装为同步和阻塞计算的分享已经结束,谢谢您的关注,如果想了解更多关于ajax怎么将异步请求改为同步、c# – 将异步操作转换为异步函数委托,保留同步异常传递、GIL 与多线程(线程池与进程池,同步异步阻塞非阻塞)、IO 模式和 IO 多路复用(阻塞 IO、非阻塞 IO、同步 IO、异步 IO 等概念)的相关知识,请在本站进行查询。
对于如何计算两个向量的余弦相似度?感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍如何计算两个向量的余弦相似度公式,并为您提供关于C# Net 比较2个字符串的相似度(使用余弦相似度)、java – 如何有效地计算数百万字符串之间的余弦相似度、java 如何计算两个汉字的相似度?如何获得一个汉字的相似汉字?、java算法之余弦相似度计算字符串相似率的有用信息。
本文目录一览:- 如何计算两个向量的余弦相似度?(如何计算两个向量的余弦相似度公式)
- C# Net 比较2个字符串的相似度(使用余弦相似度)
- java – 如何有效地计算数百万字符串之间的余弦相似度
- java 如何计算两个汉字的相似度?如何获得一个汉字的相似汉字?
- java算法之余弦相似度计算字符串相似率
")
如何计算两个向量的余弦相似度?(如何计算两个向量的余弦相似度公式)
如何找到向量之间的余弦相似度?
我需要找到相似性来衡量两行文本之间的相关性。
例如,我有两个句子:
用户界面系统
用户界面机
…及其在tF-idf之后的向量,然后使用LSI进行标准化,例如 [1,0.5]和[0.5,1]。
如何测量这些向量之间的相似性?
答案1
小编典典public class CosineSimilarity extends AbstractSimilarity { @Override protected double computeSimilarity(Matrix sourceDoc, Matrix targetDoc) { double dotProduct = sourceDoc.arrayTimes(targetDoc).norm1(); double eucledianDist = sourceDoc.normF() * targetDoc.normF(); return dotProduct / eucledianDist; }}我最近在大学的信息检索部门做了一些tf-idf的工作。我使用了这种余弦相似度方法,该方法使用Jama:Java Matrix
Package。
有关完整的源代码,请参阅《IR Math with
Java:相似性度量》,这是一个非常好的资源,涵盖了许多不同的相似性度量。
")
C# Net 比较2个字符串的相似度(使用余弦相似度)
C# Net 比较2个字符串的相似度(使用余弦相似度)
复制代码使用:
/// <summary>
/// 比较2个字符串的相似度(使用余弦相似度)
/// </summary>
/// <param name="str1"></param>
/// <param name="str2"></param>
/// <returns>0-1之间的数</returns>
public static double SimilarityCos(string str1, string str2)
{
str1 = str1.Trim();
str2 = str2.Trim();
if (string.IsNullOrEmpty(str1) || string.IsNullOrEmpty(str2))
return 0;
List<string> lstr1 = SimpParticiple(str1);
List<string> lstr2 = SimpParticiple(str2);
//求并集
var strUnion = lstr1.Union(lstr2);
//求向量
List<int> int1 = new List<int>();
List<int> int2 = new List<int>();
foreach (var item in strUnion)
{
int1.Add(lstr1.Count(o => o == item));
int2.Add(lstr2.Count(o => o == item));
}
double s = 0;
double den1 = 0;
double den2 = 0;
for (int i = 0; i < int1.Count(); i++)
{
//求分子
s += int1[i] * int2[i];
//求分母(1)
den1 += Math.Pow(int1[i], 2);
//求分母(2)
den2 += Math.Pow(int2[i], 2);
}
return s / (Math.Sqrt(den1) * Math.Sqrt(den2));
}
/// <summary>
/// 简单分词(需要更好的效果,需要这里优化,比如把:【今天天气很好】,分成【今天,天气,很好】,同时可以做同义词优化,【今天】=【今日】效果更好)
/// </summary>
public static List<string> SimpParticiple(string str)
{
List<string> vs = new List<string>();
foreach (var item in str)
{
vs.Add(item.ToString());
}
return vs;
}

java – 如何有效地计算数百万字符串之间的余弦相似度
编辑
我想确定哪些字符串与给定字符串最相似,并且能够获得与相似性相关的度量/分数.我认为我想做的事情与群集相符合,群集的数量最初并不为人所知.
解决方法
从本质上讲,计算余弦相似性的天真方式是不好的.因为你最终计算了很多0 *的东西.相反,你最好在列中工作,并在那里留下所有0.

java 如何计算两个汉字的相似度?如何获得一个汉字的相似汉字?
计算汉字相似度
情景
有时候我们希望计算两个汉字的相似度,比如文本的 OCR 等场景。用于识别纠正。
实现
引入 maven
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>nlp-hanzi-similar</artifactId>
<version>1.3.0</version>
</dependency>java 实现
double rate1 = HanziSimilarHelper.similar(''末'', ''未'');返回对应的相似度:
0.9629629629629629返回一个汉字的相似列表
情景
找到相似的汉字,有很多有趣的场景。
实现
List<String> list = HanziSimilarHelper.similarList(''爱'');
Assert.assertEquals("[爰, 爯, 受, 爭, 妥, 憂, 李, 爳, 叐, 雙]", list.toString());开源地址
为了便于大家学习,上述代码已开源
https://github.com/houbb/nlp-hanzi-similar
在线体验
在线体验
拓展阅读
NLP 中文形近字相似度计算思路
中文形近字相似度算法实现,为汉字 NLP 尽一点绵薄之力
当代中国最贵的汉字是什么?
NLP 开源形近字算法补完计划(完结篇)
NLP 开源形近字算法之形近字列表(番外篇)
开源项目在线化 中文繁简体转换/敏感词/拼音/分词/汉字相似度/markdown 目录

java算法之余弦相似度计算字符串相似率
这篇文章主要介绍了java算法之余弦相似度计算字符串相似率,对算法感兴趣的同学,可以参考下
目录
概述
一、理论知识
1、说重点
2、案例理论知识
二、实际开发案例
1、pom.xml
2、main方法
3、Tokenizer(分词工具类)
4、Word(封装分词结果)
5、Cosinesimilarity(相似率具体实现工具类)
6、AtomicFloat原子类
三、总结
概述
功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中。这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻
或者一样的新闻,那就不存储到数据库中。(因为有网站会去引用其它网站新闻,或者把其它网站新闻拿过来稍微改下内容就发布到自己网站中)。
解析方案:最终就是采用余弦相似度算法,来计算两个新闻正文的相似度。现在自己写一篇博客总结下。
一、理论知识
先推荐一篇博客,对于余弦相似度算法的理论讲的比较清晰,我们也是按照这个方式来计算相似度的。网址:相似度算法之余弦相似度。
1、说重点
我这边先把计算两个字符串的相似度理论知识再梳理一遍。
(1)首先是要明白通过向量来计算相识度公式。

(2)明白:余弦值越接近1,也就是两个向量越相似,这就叫"余弦相似性",
余弦值越接近0,也就是两个向量越不相似,也就是这两个字符串越不相似。
2、案例理论知识
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,计算词频。(也就是每个词语出现的频率)
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第三步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
第四步:运用上面的公式:计算如下:

计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
二、实际开发案例
我把我们实际开发过程中字符串相似率计算代码分享出来。
1、pom.xml
展示一些主要jar包
org.apache.commonscommons-lang33.5org.projectlomboklombokcom.hankcshanlpportable-1.6.5
2、main方法
/** * 计算两个字符串的相识度 */ public class Similarity { public static final String content1="今天小小和爸爸一起去摘草莓,小小说今天的草莓特别的酸,而且特别的小,关键价格还贵"; public static final String content2="今天小小和妈妈一起去草原里采草莓,今天的草莓味道特别好,而且价格还挺实惠的"; public static void main(String[] args) { double score=Cosinesimilarity.getSimilarity(content1,content2); System.out.println("相似度:"+score); score=Cosinesimilarity.getSimilarity(content1,content1); System.out.println("相似度:"+score); } }
先看运行结果:

通过运行结果得出:
(1)第一次比较相似率为:0.772853 (说明这两条句子还是挺相似的),第二次比较相似率为:1.0 (说明一模一样)。
(2)我们可以看到这个句子的分词效果,后面是词性。
3、Tokenizer(分词工具类)
import com.hankcs.hanlp.HanLP; import com.hankcs.hanlp.seg.common.Term; import java.util.List; import java.util.stream.Collectors; /** * 中文分词工具类*/ public class Tokenizer { /** * 分词*/ public static List segment(String sentence) { //1、 采用HanLP中文自然语言处理中标准分词进行分词 List termlist = HanLP.segment(sentence); //上面控制台打印信息就是这里输出的 System.out.println(termlist.toString()); //2、重新封装到Word对象中(term.word代表分词后的词语,term.nature代表改词的词性) return termlist.stream().map(term -> new Word(term.word, term.nature.toString())).collect(Collectors.toList()); } }
4、Word(封装分词结果)
这里面真正用到的其实就词名和权重。
import lombok.Data; import java.util.Objects; /** * 封装分词结果*/ @Data public class Word implements Comparable { // 词名 private String name; // 词性 private String pos; // 权重,用于词向量分析 private Float weight; public Word(String name, String pos) { this.name = name; this.pos = pos; } @Override public int hashCode() { return Objects.hashCode(this.name); } @Override public boolean equals(Object obj) { if (obj == null) { return false; } if (getClass() != obj.getClass()) { return false; } final Word other = (Word) obj; return Objects.equals(this.name, other.name); } @Override public String toString() { StringBuilder str = new StringBuilder(); if (name != null) { str.append(name); } if (pos != null) { str.append("/").append(pos); } return str.toString(); } @Override public int compareto(Object o) { if (this == o) { return 0; } if (this.name == null) { return -1; } if (o == null) { return 1; } if (!(o instanceof Word)) { return 1; } String t = ((Word) o).getName(); if (t == null) { return 1; } return this.name.compareto(t); } }
5、Cosinesimilarity(相似率具体实现工具类)
import com.jincou.algorithm.tokenizer.Tokenizer; import com.jincou.algorithm.tokenizer.Word; import org.apache.commons.lang3.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.util.CollectionUtils; import java.math.BigDecimal; import java.util.*; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.atomic.AtomicInteger; /** * 判定方式:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度 余弦夹角原理: 向量a=(x1,y1),向量b=(x2,y2) similarity=a.b/|a|*|b| a.b=x1x2+y1y2 * |a|=根号[(x1)^2+(y1)^2],|b|=根号[(x2)^2+(y2)^2]*/ public class Cosinesimilarity { protected static final Logger LOGGER = LoggerFactory.getLogger(Cosinesimilarity.class); /** * 1、计算两个字符串的相似度 */ public static double getSimilarity(String text1, String text2) { //如果wei空,或者字符长度为0,则代表完全相同 if (StringUtils.isBlank(text1) && StringUtils.isBlank(text2)) { return 1.0; } //如果一个为0或者空,一个不为,那说明完全不相似 if (StringUtils.isBlank(text1) || StringUtils.isBlank(text2)) { return 0.0; } //这个代表如果两个字符串相等那当然返回1了(这个我为了让它也分词计算一下,所以注释掉了) // if (text1.equalsIgnoreCase(text2)) { // return 1.0; // } //第一步:进行分词 List words1 = Tokenizer.segment(text1); List words2 = Tokenizer.segment(text2); return getSimilarity(words1, words2); } /** * 2、对于计算出的相似度保留小数点后六位 */ public static double getSimilarity(List words1, List words2) { double score = getSimilarityImpl(words1, words2); //(int) (score * 1000000 + 0.5)其实代表保留小数点后六位 ,因为1034234.213强制转换不就是1034234。对于强制转换添加0.5就等于四舍五入 score = (int) (score * 1000000 + 0.5) / (double) 1000000; return score; } /** * 文本相似度计算 判定方式:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度 余弦夹角原理: 向量a=(x1,y1),向量b=(x2,y2) similarity=a.b/|a|*|b| a.b=x1x2+y1y2 * |a|=根号[(x1)^2+(y1)^2],|b|=根号[(x2)^2+(y2)^2] */ public static double getSimilarityImpl(List words1, List words2) { // 向每一个Word对象的属性都注入weight(权重)属性值 taggingWeightByFrequency(words1, words2); //第二步:计算词频 //通过上一步让每个Word对象都有权重值,那么在封装到map中(key是词,value是该词出现的次数(即权重)) Map weightMap1 = getFastSearchMap(words1); Map weightMap2 = getFastSearchMap(words2); //将所有词都装入set容器中 Set words = new HashSet(); words.addAll(words1); words.addAll(words2); AtomicFloat ab = new AtomicFloat();// a.b AtomicFloat aa = new AtomicFloat();// |a|的平方 AtomicFloat bb = new AtomicFloat();// |b|的平方 // 第三步:写出词频向量,后进行计算 words.parallelStream().forEach(word -> { //看同一词在a、b两个集合出现的此次 Float x1 = weightMap1.get(word.getName()); Float x2 = weightMap2.get(word.getName()); if (x1 != null && x2 != null) { //x1x2 float oneOfTheDimension = x1 * x2; //+ ab.addAndGet(oneOfTheDimension); } if (x1 != null) { //(x1)^2 float oneOfTheDimension = x1 * x1; //+ aa.addAndGet(oneOfTheDimension); } if (x2 != null) { //(x2)^2 float oneOfTheDimension = x2 * x2; //+ bb.addAndGet(oneOfTheDimension); } }); //|a| 对aa开方 double aaa = Math.sqrt(aa.doubleValue()); //|b| 对bb开方 double bbb = Math.sqrt(bb.doubleValue()); //使用BigDecimal保证精确计算浮点数 //double aabb = aaa * bbb; BigDecimal aabb = BigDecimal.valueOf(aaa).multiply(BigDecimal.valueOf(bbb)); //similarity=a.b/|a|*|b| //divide参数说明:aabb被除数,9表示小数点后保留9位,最后一个表示用标准的四舍五入法 double cos = BigDecimal.valueOf(ab.get()).divide(aabb, 9, BigDecimal.ROUND_HALF_UP).doubleValue(); return cos; } /** * 向每一个Word对象的属性都注入weight(权重)属性值 */ protected static void taggingWeightByFrequency(List words1, List words2) { if (words1.get(0).getWeight() != null && words2.get(0).getWeight() != null) { return; } //词频统计(key是词,value是该词在这段句子中出现的次数) Map frequency1 = getFrequency(words1); Map frequency2 = getFrequency(words2); //如果是DEBUG模式输出词频统计信息 // if (LOGGER.isDebugEnabled()) { // LOGGER.debug("词频统计1:n{}", getWordsFrequencyString(frequency1)); // LOGGER.debug("词频统计2:n{}", getWordsFrequencyString(frequency2)); // } // 标注权重(该词出现的次数) words1.parallelStream().forEach(word -> word.setWeight(frequency1.get(word.getName()).floatValue())); words2.parallelStream().forEach(word -> word.setWeight(frequency2.get(word.getName()).floatValue())); } /** * 统计词频 * @return 词频统计图 */ private static Map getFrequency(List words) { Map freq = new HashMap(); //这步很帅哦 words.forEach(i -> freq.computeIfAbsent(i.getName(), k -> new AtomicInteger()).incrementAndGet()); return freq; } /** * 输出:词频统计信息 */ private static String getWordsFrequencyString(Map frequency) { StringBuilder str = new StringBuilder(); if (frequency != null && !frequency.isEmpty()) { AtomicInteger integer = new AtomicInteger(); frequency.entrySet().stream().sorted((a, b) -> b.getValue().get() - a.getValue().get()).forEach( i -> str.append("t").append(integer.incrementAndGet()).append("、").append(i.getKey()).append("=") .append(i.getValue()).append("n")); } str.setLength(str.length() - 1); return str.toString(); } /** * 构造权重快速搜索容器 */ protected static Map getFastSearchMap(List words) { if (CollectionUtils.isEmpty(words)) { return Collections.emptyMap(); } Map weightMap = new ConcurrentHashMap(words.size()); words.parallelStream().forEach(i -> { if (i.getWeight() != null) { weightMap.put(i.getName(), i.getWeight()); } else { LOGGER.error("no word weight info:" + i.getName()); } }); return weightMap; } }
这个具体实现代码因为思维很紧密所以有些地方写的比较绕,同时还手写了AtomicFloat原子类。
6、AtomicFloat原子类
import java.util.concurrent.atomic.AtomicInteger; /** * jdk没有AtomicFloat,写一个 */ public class AtomicFloat extends Number { private AtomicInteger bits; public AtomicFloat() { this(0f); } public AtomicFloat(float initialValue) { bits = new AtomicInteger(Float.floatToIntBits(initialValue)); } //叠加 public final float addAndGet(float delta) { float expect; float update; do { expect = get(); update = expect + delta; } while (!this.compareAndSet(expect, update)); return update; } public final float getAndAdd(float delta) { float expect; float update; do { expect = get(); update = expect + delta; } while (!this.compareAndSet(expect, update)); return expect; } public final float getAndDecrement() { return getAndAdd(-1); } public final float decrementAndGet() { return addAndGet(-1); } public final float getAndIncrement() { return getAndAdd(1); } public final float incrementAndGet() { return addAndGet(1); } public final float getAndSet(float newValue) { float expect; do { expect = get(); } while (!this.compareAndSet(expect, newValue)); return expect; } public final boolean compareAndSet(float expect, float update) { return bits.compareAndSet(Float.floatToIntBits(expect), Float.floatToIntBits(update)); } public final void set(float newValue) { bits.set(Float.floatToIntBits(newValue)); } public final float get() { return Float.intBitsToFloat(bits.get()); } @Override public float floatValue() { return get(); } @Override public double doubleValue() { return (double) floatValue(); } @Override public int intValue() { return (int) get(); } @Override public long longValue() { return (long) get(); } @Override public String toString() { return Float.toString(get()); } }
三、总结
把大致思路再捋一下:
(1)先分词:分词当然要按一定规则,不然随便分那也没有意义,那这里通过采用HanLP中文自然语言处理中标准分词进行分词。
(2)统计词频:就统计上面词出现的次数。
(3)通过每一个词出现的次数,变成一个向量,通过向量公式计算相似率。
关于如何计算两个向量的余弦相似度?和如何计算两个向量的余弦相似度公式的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于C# Net 比较2个字符串的相似度(使用余弦相似度)、java – 如何有效地计算数百万字符串之间的余弦相似度、java 如何计算两个汉字的相似度?如何获得一个汉字的相似汉字?、java算法之余弦相似度计算字符串相似率的相关信息,请在本站寻找。
对于想了解计算整数的幂的读者,本文将提供新的信息,我们将详细介绍计算整数幂python,并且为您提供关于2021-11-06:3的幂。给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。整数 n 是 3 的幂次方需满足:存在整数 x 使得 n ==、c – 计算整数区间(或int数组)中每个数字的出现次数、java – 我需要编写只返回整数的幂的方法、JAVA计算整数的位数的有价值信息。
本文目录一览:- 计算整数的幂(计算整数幂python)
- 2021-11-06:3的幂。给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。整数 n 是 3 的幂次方需满足:存在整数 x 使得 n ==
- c – 计算整数区间(或int数组)中每个数字的出现次数
- java – 我需要编写只返回整数的幂的方法
- JAVA计算整数的位数
")
计算整数的幂(计算整数幂python)
Java中还有其他方法可以计算整数的幂吗?
我Math.pow(a, b)现在使用,但是它返回一个double,这通常是很多工作,并且在您只想使用ints
时看起来不太干净(那么幂也会总是产生int)。
有没有a**b像Python 一样简单的东西?
答案1
小编典典整数只有32位。这意味着其最大值为2^31-1。如您所见,对于非常小的数字,您很快就会得到不能再用整数表示的结果。这就是Math.pow使用的原因double。
如果要任意整数精度,请使用BigInteger.pow。但这当然效率较低。

2021-11-06:3的幂。给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。整数 n 是 3 的幂次方需满足:存在整数 x 使得 n ==
2021-11-06:3的幂。给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。整数 n 是 3 的幂次方需满足:存在整数 x 使得 n == 3**x。力扣326。
答案2021-11-06:
如果一个数字是3的某次幂,那么这个数一定只含有3这个质数因子。
4052555153018976267是int型范围内,最大的3的幂,它是3的38次方。
这个4052555153018976267只含有3这个质数因子,如果n也是只含有3这个质数因子,那么4052555153018976267% n == 0;反之如果4052555153018976267% n != 0 说明n一定含有其他因子。
时间复杂度:O(1)。
空间复杂度:O(1)。
代码用golang编写。代码如下:
package main
import "fmt"
func main() {
ret := isPowerOfThree(81)
fmt.Println(ret)
}
func isPowerOfThree(n int) bool {
//3的38次方
return (n > 0 && 4052555153018976267%n == 0)
}执行结果如下:
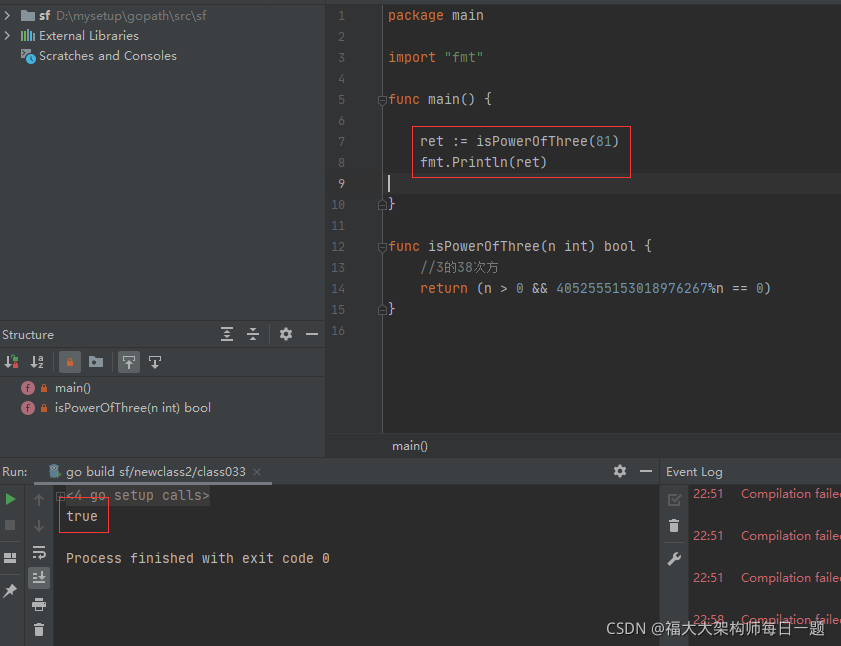
左神java代码
中每个数字的出现次数")
c – 计算整数区间(或int数组)中每个数字的出现次数
例如:
> INPUT n,m = [19,23] = 19,20,21,22,23
>输出应该是:
0次出现:1次
1次出现:2次
2次出现:5次
3次出现:1次等
#include <iostream>
using namespace std;
int main()
{
int i,j,z,count,n,m;
cin >>n >>m;
for(int i=0; i<10; i++) // LOOP FOR DIGITS
{
cout << i <<"occurences: ";
count=0;
for(int j=n; j<m; j++) // LOOP INTEGER INTERVAL
{
while (z!=0)
{
z = j % 10; // LAST DIGIT OF FirsT NUMBER IN INTERVAL
if (z == i) count++;
z /= 10;
}
}
cout << count <<" times"<< endl;
}
}
我的代码每个数字返回0次,错误在哪里?
解决方法
int n,m;
cin >> n >> m;
counts = int[10];
for(int i = 0; i < 10; ++i) {
counts[i] = 0;
}
for(int j = n; j <= m; j++) {
int z = j;
do {
int digit = z % 10; // LAST DIGIT OF FirsT NUMBER IN INTERVAL
counts[digit]++;
z /= 10;
} while (z != 0);
}
for(int i = 0; i < 10; ++i) {
cout << i << " occurrences " << counts[i] << " times";
}

java – 我需要编写只返回整数的幂的方法
我尝试了第一个简单的步骤:
public static int GetPower(int base,int power)
{
int result = 1;
for(int i = 1; i<=power; i++)
{
result *= base;
if (result < 0 ) {
break; // not very acurate
}
}
if (result < 0 ) {
return -1;
}
return result;
}
上面的方法是否准确,因为在调试后我发现当结果超过Integer.MAX_VALUE时它会转到负数,还是有另一种方法来处理这个?
解决方法
处理这种情况的一种简单但不是最佳的方法是使用长数据类型来存储输出并比较输出以检查它是否在Integer.MAX_VALUE和Integer.MIN_VALUE之间.
public static int GetPower(int base,int power){
long result = 1;
for(int i = 1; i <= power; i++)
{
result *= base;
if (result > Integer.MAX_VALUE || result < Integer.MIN_VALUE) {
return -1;
}
}
return result;
}

JAVA计算整数的位数
/**
* 计算整数的位数
* @param x
* @return
*/
public static int countIntegerLength(int x){
final int [] sizeTable = { 9, 99, 999, 9999, 99999, 999999, 9999999,
99999999, 999999999, Integer.MAX_VALUE };
for (int i=0; ; i++)
if (x <= sizeTable[i]){
return i+1;
}
}
我们今天的关于计算整数的幂和计算整数幂python的分享就到这里,谢谢您的阅读,如果想了解更多关于2021-11-06:3的幂。给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。整数 n 是 3 的幂次方需满足:存在整数 x 使得 n ==、c – 计算整数区间(或int数组)中每个数字的出现次数、java – 我需要编写只返回整数的幂的方法、JAVA计算整数的位数的相关信息,可以在本站进行搜索。
对于游戏循环中最佳睡眠时间计算的研究感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍游戏深度睡眠,并为您提供关于autosleep睡眠时间如何修改 autosleep睡眠时间修改方法、C#使用TimeSpan时间计算的简单实现、java – android游戏循环中的同步、java – 在没有冻结UI线程的情况下实现游戏循环的最佳方式的有用信息。
本文目录一览:- 游戏循环中最佳睡眠时间计算的研究(游戏深度睡眠)
- autosleep睡眠时间如何修改 autosleep睡眠时间修改方法
- C#使用TimeSpan时间计算的简单实现
- java – android游戏循环中的同步
- java – 在没有冻结UI线程的情况下实现游戏循环的最佳方式
")
游戏循环中最佳睡眠时间计算的研究(游戏深度睡眠)
在编写动画和小游戏时,我已经知道Thread.sleep(n);我依靠这种方法告诉操作系统什么时候我的应用程序不需要任何CPU,并以此来使程序以可预测的速度前进,这具有不可思议的重要性。
我的问题是JRE在不同的操作系统上使用了不同的方法来实现此功能。在基于UNIX(或受影响的)的OS:例如Ubuntu和OS
X上,底层的JRE实现使用功能良好且精确的系统将CPU时间分配给不同的应用程序,从而使我的2D游戏流畅无延迟。但是,在Windows
7和较旧的Microsoft系统上,CPU时间分配似乎工作方式不同,通常在给定的睡眠量后,您的CPU时间会恢复,与目标睡眠之间的差约为1-2
ms。但是,偶尔会出现额外的10-20毫秒的睡眠时间。这会导致我的游戏每隔几秒钟出现一次延迟。我注意到我在Windows上尝试过的大多数Java游戏中都存在此问题,Minecraft是一个明显的例子。
现在,我一直在Internet上四处寻找解决此问题的方法。我见过很多人只使用Thread.yield();而不是代替Thread.sleep(n);,无论您的游戏实际需要多少CPU,它都可以完美工作,而当前使用的CPU内核却要满负荷运行。这对于在笔记本电脑或高能耗工作站上玩游戏并不理想,并且在Mac和Linux系统上是不必要的折衷。
进一步环顾四周,我发现了一种纠正睡眠时间不一致的常用方法,称为“旋转睡眠”,您一次只能订购1
ms的睡眠,并使用该System.nanoTime();方法检查一致性,即使在Microsoft系统上,该方法也非常准确。这有助于正常的1-2
ms的睡眠不一致,但对于偶尔出现+ 10-20 ms的睡眠不一致的突发情况却无济于事,因为这通常导致花费的时间超过循环的一个周期应占用的全部时间一起。
经过无数次查找,我发现了Andy Malakov的这篇神秘文章,这对改善我的循环非常有帮助:http : //andy-
malakov.blogspot.com/2010/06/alternative-to-threadsleep.html
根据他的文章,我写了这个睡眠方法:
// Variables for calculating optimal sleep time. In nanoseconds (1s = 10^-9ms).private long timeBefore = 0L;private long timeSleepEnd, timeLeft;// The estimated game update rate.private double timeUpdateRate;// The time one game loop cycle should take in order to reach the max FPS.private long timeLoop;private void sleep() throws InterruptedException { // Skip first game loop cycle. if (timeBefore != 0L) { // Calculate optimal game loop sleep time. timeLeft = timeLoop - (System.nanoTime() - timeBefore); // If all necessary calculations took LESS time than given by the sleepTimeBuffer. Max update rate was reached. if (timeLeft > 0 && isUpdateRateLimited) { // Determine when to stop sleeping. timeSleepEnd = System.nanoTime() + timeLeft; // Sleep, yield or keep the thread busy until there is not time left to sleep. do { if (timeLeft > SLEEP_PRECISION) { Thread.sleep(1); // Sleep for approximately 1 millisecond. } else if (timeLeft > SPIN_YIELD_PRECISION) { Thread.yield(); // Yield the thread. } if (Thread.interrupted()) { throw new InterruptedException(); } timeLeft = timeSleepEnd - System.nanoTime(); } while (timeLeft > 0); } // Save the calculated update rate. timeUpdateRate = 1000000000D / (double) (System.nanoTime() - timeBefore); } // Starting point for time measurement. timeBefore = System.nanoTime();}SLEEP_PRECISION``SPIN_YIELD_PRECISION为了使Windows 7机器获得最佳性能,我通常花费大约2毫秒和10000
ns。
经过大量的努力,这是我能想到的最好的选择。因此,由于我仍然很想提高这种睡眠方法的准确性,并且对性能仍然不满意,因此我想呼吁所有Java游戏黑客和动画制作者为该解决方案提供更好的解决方案的建议。
Windows平台。我可以在Windows上使用特定于平台的方式来使其更好吗?只要大多数代码与操作系统无关,我都不会在乎我的应用程序中只包含一些平台特定的代码。
我还想知道是否有人对Microsoft和Oracle知道如何更好地实现该Thread.sleep(n);方法,或者Oracle未来的计划是改善环境,将其作为要求高定时精度的应用程序的基础,例如音乐软件和软件。游戏?
谢谢大家阅读我冗长的问题/文章。我希望有人可能对我的研究有所帮助!
答案1
小编典典您可以使用与互斥锁关联的
循环计时器。这是IHMO做您想要的事的最有效方法。但是,然后您应该考虑跳过帧以防计算机延迟(您可以使用计时器代码中的另一个非阻塞互斥锁来做到这一点。)
编辑:一些伪代码来澄清
计时器代码:
While(true): if acquireIfPossible(mutexSkipRender): release(mutexSkipRender) release(mutexRender)睡眠代码:
acquire(mutexSkipRender)acquire(mutexRender)release(mutexSkipRender)起始值:
mutexSkipRender = 1mutexRender = 0编辑 :更正了初始化值。
以下代码在Windows上运行良好(以50 fps的精度精确到毫秒地循环)
import java.util.Date;import java.util.Timer;import java.util.TimerTask;import java.util.concurrent.Semaphore;public class Main { public static void main(String[] args) throws InterruptedException { final Semaphore mutexRefresh = new Semaphore(0); final Semaphore mutexRefreshing = new Semaphore(1); int refresh = 0; Timer timRefresh = new Timer(); timRefresh.scheduleAtFixedRate(new TimerTask() { @Override public void run() { if(mutexRefreshing.tryAcquire()) { mutexRefreshing.release(); mutexRefresh.release(); } } }, 0, 1000/50); // The timer is started and configured for 50fps Date startDate = new Date(); while(true) { // Refreshing loop mutexRefresh.acquire(); mutexRefreshing.acquire(); // Refresh refresh += 1; if(refresh % 50 == 0) { Date endDate = new Date(); System.out.println(String.valueOf(50.0*1000/(endDate.getTime() - startDate.getTime())) + " fps."); startDate = new Date(); } mutexRefreshing.release(); } }}
autosleep睡眠时间如何修改 autosleep睡眠时间修改方法
很多小伙伴不知道autosleep睡眠时间怎么修改,对此php小编小新为大家整理了autosleep睡眠时间的修改方法。面对autosleep睡眠时间修改的问题,我们该如何解决呢?下面php小编小新就来为大家详细介绍一下修改方法,希望对大家有所帮助。
autosleep睡眠时间如何修改?autosleep睡眠时间修改方法
第一步:首先打开app

第二步:然后点击右下角的设置

第三步:在配置中找到向导

第四步:根据指示操作就能看到睡眠时间的设置选项,选择一个对你合适的入睡时间点即可

以上就是autosleep睡眠时间如何修改 autosleep睡眠时间修改方法的详细内容,更多请关注php中文网其它相关文章!

C#使用TimeSpan时间计算的简单实现
本文告诉大家简单的方法进行时间计算。
实际上使用 TimeSpan 可以做到让代码比较好懂,而代码很简单。
例如我使用下面的代码表示 5 秒
const int needCount = 5 * 1000;
因为后面使用的是延迟,延迟的代码很简单
Task.Delay(needCount)
这时传入的是一个毫秒,但是很多小伙伴问,为什么是 5*1000 表示 5秒,他不知道我使用的是毫秒。
所以建议使用 TimeSpan 来写时间,下面的需求是在判断在开机 20 秒内的延迟,如果在开机 20 秒内启动应用,那么就需要延迟时间
var needTime = TimeSpan.FromSeconds(20); //开机20秒左右 USB 已经加载完成
计算时间的减法或加法可以使用重载+和-,请看下面代码,就是把两个 TimeSpan 相减,返回的值也是一个 TimeSpan ,下面的代码是编译不通过的。
var chikesereHearpawwirboo = needTime - maxDelay; Console.WriteLine(chikesereHearpawwirboo);
如果需要从毫秒转 TimeSpan ,请看下面代码
// 毫秒转 TimeSpan var milliseconds = 5 * 1000; var time = TimeSpan.FromMilliseconds(milliseconds); // TimeSpan 转 毫秒 milliseconds =(int) time.TotalMilliseconds;
因为从秒转毫秒的值是 double 需要进行转换,如果使用 int 转换有时会越界,建议使用下面代码
// 毫秒转 TimeSpan long milliseconds = 5 * 1000; var time = TimeSpan.FromMilliseconds(milliseconds); // TimeSpan 转 毫秒 milliseconds = (long) Math.Ceiling(time.TotalMilliseconds);
这个计算适合在有天数和小时等的计算,如计算 1天 减去 3h10m 有多少毫秒,如果不使用 TimeSpan 自己重写,还是需要写很多代码
var time = TimeSpan.FromDays(1); var cut = new TimeSpan(0, 3, 10, 0); var milliseconds = (long)(time - cut).TotalMilliseconds;
尝试不使用 TimeSpan 想想需要怎么写
C#使用timespan和timer完成一个简单的倒计时器
首先利用timespan数据类型这样构造:
TimeSpan ts = new TimeSpan(0, 45, 0);
这样就声明了一个长度为45分钟的时间段,其中构造函数参数的含义:
TimeSpan(hour,minute,second);
然后拖进去一个timer,叫timer1
timer1.Interval=1000;
设置一秒一个周期
在timer的tick事件里面这样写:
private
void timer1_Tick(object
sender, EventArgs e)
{
String str = ts.Hours.ToString() + ":"
+ ts.Minutes.ToString() + ":"
+ ts.Seconds.ToString();
label17.Text = str;//label17用来显示剩余的时间
ts = ts.Subtract(new
TimeSpan(0, 0, 1));//每隔一秒减去一秒
if
(ts.TotalSeconds < 0.0)//当倒计时完毕
{
timer1.Enabled = false;
MessageBox.Show("考试时间到,系统将强行交卷");//提示时间到,下面可以加你想要的操作
}
}
一个简单的倒计时器就这样完成了,嘿嘿,不看不知道,一看很简单呀
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
- 详解C# TimeSpan 计算时间差(时间间隔)
- C#基于TimeSpan实现倒计时效果的方法
- C#的TimeSpan案例详解

java – android游戏循环中的同步
我正在阅读一些用于学习目的的基本Android游戏技术.
我遇到了一些同步访问游戏循环线程上使用的SurfaceHolder对象的代码,为什么这是必要的?
在sdk / samples / android-18 / legacy / LunarLander,LunarView.LunarThread类中找到示例代码:
public void run() {
while (mRun) {
Canvas c = null;
try {
c = mSurfaceHolder.lockCanvas(null);
synchronized (mSurfaceHolder) {
if (mMode == STATE_RUNNING) updatePhysics();
synchronized (mRunLock) {
if (mRun) doDraw(c);
}
}
} finally {
if (c != null) {
mSurfaceHolder.unlockCanvasAndPost(c);
}
}
}
}
因此,这段代码可以从mSurfaceHolder对象访问画布,然后在绘制画布时锁定该对象.
为什么需要同步?
我认为不是,因为请求画布和绘图的唯一线程是游戏循环运行的线程.
另外the documnetation of SurfaceHolder.lockCanvas()说它将获取一个内部锁,直到调用unlockCanvasAndPost(),然后为什么额外同步?
解决方法:
如果你查看你给出的参考,完整的报价是:
If null is not returned, this function internally holds a lock until the corresponding unlockCanvasAndPost(Canvas) call, preventing SurfaceView from creating, destroying, or modifying the surface while it is being drawn.
我的重点 – 请注意,阅读不在列表中.
所以lockCanvas不会阻止它被读取.我猜想额外的同步是为了确保其他线程当时不会从中读取 – 这是有道理的,因为你正在调用updatePhysics,这可能会让其他读者感到不安.

java – 在没有冻结UI线程的情况下实现游戏循环的最佳方式
到目前为止,我有一个JFrame,一个菜单栏,一个扩展JPanel并覆盖它的paint方法的类.现在,我需要一个游戏循环,在那里我将更新图像的位置等等.不过,我被困在如何最好地实现这一点.我应该使用多线程,因为肯定的是,如果在主线程上放置无限循环,那么UI(因此我的菜单栏)会冻结?
这是我的代码到目前为止
import java.awt.Color;
import java.awt.Graphics;
import javax.swing.JPanel;
@SuppressWarnings("serial")
public class GameCanvas extends JPanel {
public void paint(Graphics g) {
while (true) {
g.setColor(Color.DARK_GRAY);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printstacktrace();
}
}
}
}
import javax.swing.JFrame;
import javax.swing.JMenu;
import javax.swing.JMenuBar;
import javax.swing.JMenuItem;
@SuppressWarnings("serial")
public class Main extends JFrame {
GameCanvas canvas = new GameCanvas();
final int FRAME_HEIGHT = 400;
final int FRAME_WIDTH = 400;
public static void main(String args[]) {
new Main();
}
public Main() {
super("Game");
JMenuBar menuBar = new JMenuBar();
JMenu fileMenu = new JMenu("File");
JMenuItem startmenuItem = new JMenuItem("Pause");
menuBar.add(fileMenu);
fileMenu.add(startmenuItem);
super.add(canvas);
super.setVisible(true);
super.setSize(FRAME_WIDTH,FRAME_WIDTH);
super.setDefaultCloSEOperation(JFrame.EXIT_ON_CLOSE);
super.setJMenuBar(menuBar);
}
}
任何指针或提示?我应该把我的循环放在哪里?在我的主课,或我的GameCanvas类?
解决方法
当您使用Swing API时,会自动为您的UI自动获取一个名为事件调度线程的线程.您的回调在此线程上执行,而不是主线程.
如果您希望游戏在程序运行时自动启动,您的主线程对您的游戏循环是好的.如果要使用Swing GUI启动和停止游戏,那么主线程将启动GUI,然后当用户想要开始游戏时,GUI可以为游戏循环创建一个新的线程.
不,如果你的游戏循环在主线程中,你的菜单栏不会冻结.如果您的Swing回调需要很长时间才能完成,您的菜单栏会冻结.
线程之间共享的数据需要使用锁来保护.
我建议你将你的Swing代码考虑进自己的类中,并把你的游戏循环放在你的主类中.如果您正在使用主线程进行游戏循环,这是您如何设计它的一个粗略概念.
import javax.swing.JFrame;
import javax.swing.JMenu;
import javax.swing.JMenuBar;
import javax.swing.JMenuItem;
class GUI extends JFrame {
GameCanvas canvas = new GameCanvas();
final int FRAME_HEIGHT = 400;
final int FRAME_WIDTH = 400;
public GUI() {
// build and display your GUI
super("Game");
JMenuBar menuBar = new JMenuBar();
JMenu fileMenu = new JMenu("File");
JMenuItem startmenuItem = new JMenuItem("Pause");
menuBar.add(fileMenu);
fileMenu.add(startmenuItem);
super.add(canvas);
super.setVisible(true);
super.setSize(FRAME_WIDTH,FRAME_WIDTH);
super.setDefaultCloSEOperation(JFrame.EXIT_ON_CLOSE);
super.setJMenuBar(menuBar);
}
}
public class Main {
public static void main(String args[]) {
GUI ui = new GUI(); // create and display GUI
gameLoop(); // start the game loop
}
static void gameLoop() {
// game loop
}
}
今天的关于游戏循环中最佳睡眠时间计算的研究和游戏深度睡眠的分享已经结束,谢谢您的关注,如果想了解更多关于autosleep睡眠时间如何修改 autosleep睡眠时间修改方法、C#使用TimeSpan时间计算的简单实现、java – android游戏循环中的同步、java – 在没有冻结UI线程的情况下实现游戏循环的最佳方式的相关知识,请在本站进行查询。
此处将为大家介绍关于以编程方式计算Java对象的详细内容,并且为您解答有关包括其引用的对象占用的内存的相关问题,此外,我们还将为您介绍关于java – GAE数据存储:持久引用的对象、java – 以编程方式检查SD卡上是否有足够的内存、java – 以编程方式检查可用的heapSize?、java – 如何以编程方式找到所有未使用的导入?的有用信息。
本文目录一览:- 以编程方式计算Java对象(包括其引用的对象)占用的内存(用java编写一个计算器,实现算法)
- java – GAE数据存储:持久引用的对象
- java – 以编程方式检查SD卡上是否有足够的内存
- java – 以编程方式检查可用的heapSize?
- java – 如何以编程方式找到所有未使用的导入?
占用的内存(用java编写一个计算器,实现算法)")
以编程方式计算Java对象(包括其引用的对象)占用的内存(用java编写一个计算器,实现算法)
我需要以编程方式确切地找出给定的Java对象正在占用多少内存,包括它所引用的对象所占用的内存。
我可以生成内存堆转储,并使用工具分析结果。但是,生成堆转储以及使用这种工具读取转储以生成报告需要花费大量时间。考虑到我可能需要多次执行此操作,如果我可以在项目中添加一些代码来赋予我“运行时”价值,那么我的工作就会更加敏捷。
我怎样才能最好地做到这一点?
ps:具体地说,我有一个javax.xml.transform.Templates类型的对象的集合
答案1
小编典典您将需要使用 反射 。对于我来说,生成的代码段太复杂了,无法在此处发布(尽管它将很快作为我正在构建的GPL工具包的一部分提供),但是主要思想是:
- 对象标头使用8个字节(用于类指针和引用计数)
- 每个原始字段使用1、2、4或8个字节,具体取决于实际类型
- 每个对象引用(即非原始对象)字段使用4个字节(引用以及所引用对象使用的所有内容)
您需要分别处理数组(8个字节的标头,4个字节的length字段,4 *length个表的字节,以及内部使用的任何对象)。您需要使用反射来处理遍历字段(及其父字段)的其他类型的对象。
您还需要在递归过程中保留一组“可见”对象,以免多次计数在多个位置引用的对象。

java – GAE数据存储:持久引用的对象
我不确定如何持久化具有(“非平凡”)引用对象的对象.
也就是说,假设我有以下内容.
public class Father {
String name;
int age;
Vector<Child> offsprings; //this is what I call "non-trivial" reference
//ctor,getters,setters...
}
public class Child {
String name;
int age;
Father father; //this is what I call "non-trivial" reference
//ctor,setters...
}
名称字段在每个类型域中都是唯一的,并且被视为主键.
为了保持“普通”(String,int)字段,我只需要添加正确的注释.到现在为止还挺好.
但是,我不明白我应该如何坚持参考的自酿(儿童,父亲)类型.
我是不是该:
>转换每个此类引用以保存主键(在此示例中为名称字符串)而不是“实际”对象,因此Vector< Child>后代;变为Vector< String> offspringsNames ;?如果是这种情况,我如何在运行时处理对象?我只是从Class.getName查询主键,以检索refrenced对象?
>转换每个这样的引用以保存数据存储在正确的put()操作时提供给我的实际密钥?即,Vector< Child>后代;变为Vector< Key> offspringsHashKeys ;?
我已经阅读了所有官方相关的GAE文档/示例.在整个过程中,它们始终保持“琐碎”引用,这些引用由数据存储区本地支持(例如,在留言簿示例中,仅限字符串和长整数).
解决方法
>另请阅读JDO中可分离的对象
>要查询选择性列(或字段),请阅读JDO中的fetchgroups
对于您的问题您有几个选择:
>拥有一对多关系(对象将在同一个实体组中)在这里,您可以在父级(父级)中拥有一个Child列表.这会将所有对象放在同一个实体组中.如果您不想在每次获取父级时获取子项,则可以从“默认获取组”中删除子项
@PersistenceCapable(identityType = IdentityType.APPLICATION,detachable = "true")
public class Father {
@PrimaryKey
@Persistent
private String name;
@Persistent
private int age;
@Persistent(mappedBy = "father",defaultFetchGroup = "false")
private List childern;
}
@PersistenceCapable(identityType = IdentityType.APPLICATION,detachable = "true")
public class Child {
@Persistent
@PrimaryKey
private String name;
@Persistent
private Father dad;
}
>存储密钥而不是引用的无关关系:
@PersistenceCapable(identityType = IdentityType.APPLICATION,detachable = "true")
public class Father {
@PrimaryKey
@Persistent
private String name;
@Persistent
private int age;
@Persistent
private List childern;
}
@PersistenceCapable(identityType = IdentityType.APPLICATION,detachable = "true")
public class Child {
@Persistent
@PrimaryKey
private String name;
@Persistent
private Key dad;
}
在这种情况下,您必须管理参照完整性,并确保它们在同一个实体组中,如果您必须在单个事务中更新/添加它们
国际海事组织,如果我在建模一个现实世界(父亲 – 孩子)的场景,我会选择“拥有相关关系”的路线,因为,真的,一个人可以拥有多少个孩子;).当然还有一个问题,即你一次要更新多少父亲?
希望这会有所帮助,欢呼!

java – 以编程方式检查SD卡上是否有足够的内存
就像是:
if(MemoryCard.getFreeMemory()>20Mb)
{
saveFiles();
}
else
{
Toast.makeText(this,"Not enough memory",100).show();
}
解决方法
StatFs stat = new StatFs(Environment.getExternalStorageDirectory().getPath()); long bytesAvailable = (long)stat.getBlockSize() * (long)stat.getBlockCount(); long megAvailable = bytesAvailable / 1048576;

java – 以编程方式检查可用的heapSize?
例如,我知道我们可以检查可用的JVM堆大小:
long heapSize = Runtime.getRuntime().totalMemory();
System.out.println("Heap Size = " + heapSize);
问题是,这给出了JVM堆大小.即使增加它也无法使用Eclipse.在Eclipse中,如果我更改VM参数,那么它可以工作.但是,上述声明的打印输出始终相同.有没有命令我可以准确地知道我为特定应用程序分配了多少内存?
解决方法
代码示例:
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryPoolMXBean;
import java.lang.management.MemoryType;
import java.lang.management.MemoryUsage;
for (MemoryPoolMXBean mpBean: ManagementFactory.getMemoryPoolMXBeans()) {
if (mpBean.getType() == MemoryType.HEAP) {
System.out.printf(
"Name: %s: %s\n",mpBean.getName(),mpBean.getUsage()
);
}
}
输出示例:
Name: Eden Space: init = 6619136(6464K) used = 3754304(3666K) committed = 6619136(6464K) max = 186253312(181888K) Name: Survivor Space: init = 786432(768K) used = 0(0K) committed = 786432(768K) max = 23265280(22720K) Name: Tenured Gen: init = 16449536(16064K) used = 0(0K) committed = 16449536(16064K) max = 465567744(454656K)
如果您对“伊甸园空间”或“幸存者空间”有疑问,请查看How is the java memory pool divided

java – 如何以编程方式找到所有未使用的导入?
>有时人们会错误地导入存在于macbook JDK中但在Linux中不存在的类.这导致在基于Linux的盒子的ci服务器上构建失败.我不经常发生,但是当它确实发生时,我认为应该有一些更聪明的方法来更早地找到它.
>未使用的导入会在IDE /代码分析中触发警告.有时候有人需要花时间清理这些东西.即使只在IDE中单击右键,您仍然需要提交更改并确保所有内容都可以正常构建.
我很好奇是否有任何方法可以通过编程方式找到未使用的导入(比如单元测试),如果有的话就在本地失败.
也许由于未使用的导入声音失败,但是如果它为团队整体节省时间,那么这样做很有意义(也希望听到对此的意见).
更新:
我遵循了yegor256的建议,并将checkstyle任务与Sun Code Conventions的最初小部分(未使用的导入就是其中之一)结合起来,如果发现违规,它就会破坏构建.
经过一周的试用,我们的代码库中没有未使用的导入,并且令人惊讶的是没有关于此规则的抱怨(顺便说一下,checkstyle非常快 – 分析~100KLoc只需不到一秒钟)
至于使用IDE进行此类分析 – 是的,这是一个很好的选择,但是作为自动构建的一部分运行这种检查更好.
解决方法
你也可以看看qulice.com(我是它的开发人员之一),它集成了一些静态分析工具并预先配置它们(包括Checkstyle,PMD,FindBugs).
今天关于以编程方式计算Java对象和包括其引用的对象占用的内存的讲解已经结束,谢谢您的阅读,如果想了解更多关于java – GAE数据存储:持久引用的对象、java – 以编程方式检查SD卡上是否有足够的内存、java – 以编程方式检查可用的heapSize?、java – 如何以编程方式找到所有未使用的导入?的相关知识,请在本站搜索。
本文标签:




