关于计算乔达时间的月差和计算乔达时间的月差怎么算的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.net–计算2个日期之间的月数、c#–计算从到达时间和旅行时间开始的时间、CPU调度中到达
关于计算乔达时间的月差和计算乔达时间的月差怎么算的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.net – 计算2个日期之间的月数、c# – 计算从到达时间和旅行时间开始的时间、CPU调度中到达时间和突发时间的区别、GTFS查询以列出两个站点名称之间的所有出发和到达时间等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- 计算乔达时间的月差(计算乔达时间的月差怎么算)
- .net – 计算2个日期之间的月数
- c# – 计算从到达时间和旅行时间开始的时间
- CPU调度中到达时间和突发时间的区别
- GTFS查询以列出两个站点名称之间的所有出发和到达时间
")
计算乔达时间的月差(计算乔达时间的月差怎么算)
在代码的第四行(忽略空格和注释),然后我计算两个日期之间的月份差。这行得通,但看起来有些古怪。有没有更好的办法?
int handleAllowance(LocalDate today) { int allowance = membership.allowance(); if (allowance == 0) return 0; // if update was last month (or earlier) int months = today.monthOfYear().getMaximumValue() - today.monthOfYear().getMinimumValue(); // yeah, 12, but just to be 100% correct :-) int curMonth = (today.getYear() * months) + today. getMonthOfYear(); int updMonth = (lastAllowanceUpdate.getYear() * months) + lastAllowanceUpdate.getMonthOfYear(); if (curMonth > updMonth) { // ...and if today is on or past update day int updateDay = Math.min(allowanceDay, today.dayOfMonth().getMaximumValue()); if (today.getDayOfMonth() >= updateDay) { // number of months to give allowance (in the rare case this process fails to run for 2 months or more) int allowanceMonths = curMonth - updMonth; // give credits final int totalAllowance = allowance * allowanceMonths; giveCredits(totalAllowance); // update day lastAllowanceUpdate = lastAllowanceUpdate.plusMonths(allowanceMonths); // return the allowance given return totalAllowance; } } return 0;}答案1
小编典典Months.monthsBetween( start.withDayOfMonth(1), end.withDayOfMonth(1)).getMonths()
.net – 计算2个日期之间的月数
Dim Date1 As New DateTime(2010,5,6) Dim Date2 As New DateTime(2009,10,12) Dim NumOfMonths = 0 '' This is where I am stumped
我想要做的是找出两个日期之间有多少个月.任何帮助,将不胜感激.
解决方法
Public Shared Function MonthDifference(ByVal first As DateTime,ByVal second As DateTime) As Integer
Return Math.Abs((first.Month - second.Month) + 12 * (first.Year - second.Year))
End Function
像这样:
Dim Date1 As New DateTime(2010,12) Dim NumOfMonths = MonthDifference(Date1,Date2)

c# – 计算从到达时间和旅行时间开始的时间
Example: Arrival_time = 20/03/2013 09:00:00 Travel_time = 00:30:00 Launch_time = Arrival_time - Travel_time Launch_time should equal: 20/03/2013 08:30:00
有人能告诉我一个简单的方法来实现这一点.非常感谢.
解决方法
using System;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
Console.Title = "Datetime checker";
Console.Write("Enter the date and time to launch from: ");
DateTime time1 = DateTime.Parse(Console.ReadLine());
Console.WriteLine();
Console.Write("Enter the time to take off: ");
TimeSpan time2 = TimeSpan.Parse(Console.ReadLine());
DateTime launch = time1.Subtract(time2);
Console.WriteLine("The launch time is: {0}",launch.ToString());
Console.ReadLine();
}
}
}
我使用您的示例输入并获得了预期的输出,这应该满足您的需求.
我希望这有助于加快你的发展速度:)

CPU调度中到达时间和突发时间的区别
cpu 调度算法需要其执行所需的 cpu 时间和 IO 时间。cpu时间是cpu执行进程所花费的时间,而I/O时间说明了进程进行I/O操作所需的时间。
以优化方式执行多个进程是基于不同类型的算法,如 FCFS、最短作业优先等,这些算法取决于时间帧值,如到达时间、突发时间、等待时间等。
1. 到达时间(AT):
到达时间是进程到达就绪队列开始执行的时间点(以毫秒为单位)。它仅与 cpu 或 I/O 时间无关,仅描述进程可用于完成其指定作业的时间范围。进程与处于运行状态的进程无关。到达时间可以计算为过程的完成时间和周转时间之差。
到达时间 (A.T.)
= 完成时间 (C.T.) - 周转时间 (T.A.T.)
2. 爆发时间(BT):
突发时间是指进程执行所需的时间(以毫秒为单位)。Burst Time 考虑了进程的 cpu 时间。不考虑 I/O 时间。它被称为进程的执行时间或运行时间。该过程在此时间范围内从运行状态转换到完成状态。Burst time 可以计算为进程的 Completion Time 和 Waiting Time 之差,即
突发时间 (B.T.)
= 完成时间 (C.T.) - 等待时间 (W.T.)
下表说明了三个进程 P1、P2 和 P3 的到达和突发时间。为执行这些进程分配了一个 cpu。

如果计算甘特图,则基于 FCFS 调度,其中首先执行就绪队列中的第一个进程。进程的到达决定了进程的执行顺序,时间等于它的突发时间。

由于进程 P2 4ms 到达,进程 P1 需要 3ms 执行(=Burst Time),cpu 等待 1ms,即 cpu 的空闲时间,此时它不执行任何进程执行。最后执行的进程是 P3。
下表分别说明了到达时间和突发时间的主要区别:
| 到达时间 | 突发时间 |
|---|---|
| 标记队列中进程的入口点。 | 标记队列中进程的退出点。 |
| 在进程执行之前计算。 | 在进程执行后计算。 |
| 与 cpu 的就绪状态有关。 | 与 cpu 的运行状态有关。 |

GTFS查询以列出两个站点名称之间的所有出发和到达时间
我是第一次使用GTFS结构,但在查询时遇到了麻烦。我已经将运输数据存储到mysql表中,可以自由查询它们,但是我感觉我在进行太多的查询和for循环以获取最简单的信息。
我想在一个查询中得到的是两个已知站点之间的所有出发时间和到达时间,可能用名称来标识。
这是我到目前为止所涉及的内容,其中涉及一个查询,然后遍历每个trip_id以查找出发和到达站的信息+时间。
查询1 :
显示在特定方向上从特定始发站出发的所有出发时间。结果将给出出发时间和trip_ids。
SELECT t.trip_id, trip_headsign, departure_time, direction_id, s.stop_name FROM stops s, routes r, stop_times st, calendar c, trips t WHERE departure_time > "00:00:00" and departure_time < "23:59:59" AND r.route_id=1 and s.stop_id = 42 AND s.stop_id = st.stop_id AND st.trip_id = t.trip_id AND c.service_id = t.service_id AND c.monday=1 and direction_id=1;结果
+---------+---------------+----------------+--------------+-----------+| trip_id | trip_headsign | departure_time | direction_id | stop_name |+---------+---------------+----------------+--------------+-----------+| 5671498 | Grand Central | 04:43:00 | 1 | Garrison || 5671501 | Grand Central | 05:13:00 | 1 | Garrison || 5671504 | Grand Central | 05:43:00 | 1 | Garrison || 5671506 | Grand Central | 06:08:00 | 1 | Garrison || 5671507 | Grand Central | 06:32:00 | 1 | Garrison || 5671513 | Grand Central | 06:53:00 | 1 | Garrison || 5671516 | Grand Central | 07:18:00 | 1 | Garrison || 5671519 | Grand Central | 07:40:00 | 1 | Garrison || 5671521 | Grand Central | 08:03:00 | 1 | Garrison || 5671523 | Grand Central | 08:32:00 | 1 | Garrison || 5671525 | Grand Central | 08:58:00 | 1 | Garrison || 5671526 | Grand Central | 09:27:00 | 1 | Garrison || 5671529 | Grand Central | 10:24:00 | 1 | Garrison || 5671532 | Grand Central | 11:24:00 | 1 | Garrison || 5671535 | Grand Central | 12:24:00 | 1 | Garrison || 5671537 | Grand Central | 13:24:00 | 1 | Garrison || 5671540 | Grand Central | 14:24:00 | 1 | Garrison || 5671542 | Grand Central | 15:24:00 | 1 | Garrison || 5671543 | Grand Central | 16:22:00 | 1 | Garrison || 5671547 | Grand Central | 17:24:00 | 1 | Garrison || 5671550 | Grand Central | 18:24:00 | 1 | Garrison || 5671552 | Grand Central | 19:26:00 | 1 | Garrison || 5671554 | Grand Central | 20:24:00 | 1 | Garrison || 5671556 | Grand Central | 21:24:00 | 1 | Garrison || 5671557 | Grand Central | 22:24:00 | 1 | Garrison || 5671559 | Croton-Harmon | 23:24:00 | 1 | Garrison |+---------+---------------+----------------+--------------+-----------+查询2 :
给我所有特定行程的停靠点以及到达时间,请使用上一个查询中的trip_id:
SELECT s.stop_id,stop_lat, stop_lon, stop_name, arrival_time, stop_sequence FROM stop_times st JOIN stops s ON s.stop_id=st.stop_id WHERE trip_id=5671521;结果
+---------+-----------+------------+------------------+--------------+---------------+| stop_id | stop_lat | stop_lon | stop_name | arrival_time | stop_sequence |+---------+-----------+------------+------------------+--------------+---------------+| 51 | 41.705839 | -73.937946 | Poughkeepsie | 07:31:00 | 1 || 49 | 41.587448 | -73.947226 | New Hamburg | 07:41:00 | 2 || 46 | 41.504007 | -73.984528 | Beacon | 07:50:00 | 3 || 43 | 41.415283 | -73.958090 | Cold Spring | 07:58:00 | 4 || 42 | 41.381780 | -73.947202 | Garrison | 08:03:00 | 5 || 40 | 41.332601 | -73.970426 | Manitou | 08:08:00 | 6 || 39 | 41.285962 | -73.930420 | Peekskill | 08:17:00 | 7 || 37 | 41.246259 | -73.921884 | Cortlandt | 08:22:00 | 8 || 33 | 41.189903 | -73.882394 | Croton-Harmon | 08:32:00 | 9 || 4 | 40.805157 | -73.939149 | Harlem-125th St. | 09:09:00 | 10 || 1 | 40.752998 | -73.977056 | Grand Central | 09:22:00 | 11 |+---------+-----------+------------+------------------+--------------+---------------+我真正想要的是两个站点之间的出发时间和到达时间的列表,例如理论上的结果:
+---------+----------------+----------------+-----------+---------------+--------------+| trip_id | departure_stop | departure_time | direction | arrival_stop | arrival_time |+---------+----------------+----------------+-----------+---------------+--------------+| 5671521 | Garrison | 08:03:00 | 1 | Grand Central | 09:22:00 || 5671522 | Garrison | 08:32:00 | 1 | Grand Central | 09:51:00 | ...etc...答案1
小编典典只需将数据连接在一起,stops两次连接就可以开始和结束停止,stop_times两次连接就可以开始和结束stop_times, 我唯一不确定的是它direction_id来自哪里。
请尝试以下查询。 在查询的最后,您可以指定start_s.stop_id和end_s.stop_id,代表要查询数据的两个停靠点。
SELECT t.trip_id, start_s.stop_name as departure_stop, start_st.departure_time, direction_id as direction, end_s.stop_name as arrival_stop, end_st.arrival_timeFROMtrips t INNER JOIN calendar c ON t.service_id = c.service_id INNER JOIN routes r ON t.route_id = r.route_id INNER JOIN stop_times start_st ON t.trip_id = start_st.trip_id INNER JOIN stops start_s ON start_st.stop_id = start_s.stop_id INNER JOIN stop_times end_st ON t.trip_id = end_st.trip_id INNER JOIN stops end_s ON end_st.stop_id = end_s.stop_idWHERE c.monday = 1 AND direction_id = 1 AND start_st.departure_time > "00:00:00" AND start_st.departure_time < "23:59:59" AND r.route_id = 1 AND start_s.stop_id = 42 AND end_s.stop_id = 1我尝试从此链接查找GTFS结构示例,但找不到任何内容direction_id
指定停止名称而不是AND start_s.stop_id = 42 AND end_s.stop_id = 1
仅使用AND start_s.stop_name = ''Garrison'' AND end_s.stop_name = ''Grand Central''
关于计算乔达时间的月差和计算乔达时间的月差怎么算的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于.net – 计算2个日期之间的月数、c# – 计算从到达时间和旅行时间开始的时间、CPU调度中到达时间和突发时间的区别、GTFS查询以列出两个站点名称之间的所有出发和到达时间的相关信息,请在本站寻找。
在这篇文章中,我们将带领您了解是否可以为字符串比较计算布尔表达式?的全貌,包括对字符串进行布尔运算的相关情况。同时,我们还将为您介绍有关1106. 解析布尔表达式 : 双栈求解表达式问题、2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (t、2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。、2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR...的知识,以帮助您更好地理解这个主题。
本文目录一览:- 是否可以为字符串比较计算布尔表达式?(对字符串进行布尔运算)
- 1106. 解析布尔表达式 : 双栈求解表达式问题
- 2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (t
- 2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。
- 2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR...
")
是否可以为字符串比较计算布尔表达式?(对字符串进行布尔运算)
我将有一个像
(''abc'' != ''xyz'' AND ''thy'' = ''thy'') OR (''ujy'' = ''ujy'')该字符串将能够具有所需的任意多个“ AND”组。AND组内将没有任何嵌套组。所有组将始终由OR分隔。
我可以只切换AND &&和AND ||。
我想要将此字符串传递到某种类型的eval方法中,并输出TRUE或FALSE。
有什么可以做到的吗?
答案1
小编典典您可以使用JDK1.6随附的内置Javascript引擎来评估包含数学表达式的字符串。
您可以在这里查找:ScriptEngine
这里是一个例子:
import javax.script.ScriptEngine;import javax.script.ScriptEngineManager;import javax.script.ScriptException;public class Myclass { public static void main(String[] args) { try { ScriptEngineManager sem = new ScriptEngineManager(); ScriptEngine se = sem.getEngineByName("JavaScript"); String myExpression = "(''abc'' == ''xyz'' && ''thy'' == ''thy'') || (''ujy'' == ''ujy'')"; System.out.println(se.eval(myExpression)); } catch (ScriptException e) { System.out.println("Invalid Expression"); e.printStackTrace(); } }}只要记住要替换以下内容:
“&”和“ &&”,
“ OR”和“ ||”,
“ =”必须为“ ==”
否则它将不接受您的表情,并会引发 javax.script.ScriptException

1106. 解析布尔表达式 : 双栈求解表达式问题
题目描述
这是 LeetCode 上的 1106. 解析布尔表达式 ,难度为困难。
Tag : 「栈」、「表达式计算」
给你一个以字符串形式表述的 布尔表达式 (boolean) expression,返回该式的运算结果。
有效的表达式需遵循以下约定:
"t",运算结果为True"f",运算结果为False"!(expr)",运算过程为对内部表达式expr进行逻辑 非的运算(NOT)"&(expr1,expr2,...)",运算过程为对2个或以上内部表达式expr1, expr2, ...进行逻辑 与的运算(AND)"|(expr1,expr2,...)",运算过程为对2个或以上内部表达式expr1, expr2, ...进行逻辑 或的运算(OR)
示例 1:
输入:expression = "!(f)"
输出:true示例 2:
输入:expression = "|(f,t)"
输出:true示例 3:
输入:expression = "&(t,f)"
输出:false示例 4:
输入:expression = "|(&(t,f,t),!(t))"
输出:false提示:
- $1 <= expression.length <= 20000$
expression[i]由{''('', '')'', ''&'', ''|'', ''!'', ''t'', ''f'', '',''}中的字符组成。expression是以上述形式给出的有效表达式,表示一个布尔值。
双栈
为了方便,我们令 expression 为 s。
我们可以将 t 和 f 看做操作数,而 |、& 和 ! 看做操作符,创建两个栈 nums 和 ops 分别对其进行存储。
剩余的 () 和 , 则只是优先级和分隔符,无须额外关注。
从前往后处理 s,根据当前处理的字符为何值进行分情况讨论:
,:分隔符,直接跳过;t或f:操作数,添加到nums栈中;|、&或!:操作符,添加到ops栈中;(:子表达式的左端点,为了在我们从「双栈」中取出数值和符号计算时,可以知道某个子表达式计算完成,需要记录一下。往nums追加一个占位符号-来代指;):子表达式的右端点,代表一个子表达式的结束。可从「双栈」中取出符号和数组进行计算(在ops中仅取栈顶元素,代表当前子表达式的操作符;而在nums中则取到代表左端点的占位元素-为止),并将结果重新放入nums中。
最后考虑如何计算最简表达式,考虑实现一个 char calc(char a, char b, char op) 函数,代表对操作数 a 和 b 执行 op 操作并进行结果返回。
实际上,在 calc 函数我们只区分 | 操作和其他操作即可。也就是说 & 和 ! 均当做 & 来做,! 操作在计算完整个表达式后再翻转。
Java 代码:
class Solution {
public boolean parseBoolExpr(String s) {
Deque<Character> nums = new ArrayDeque<>(), ops = new ArrayDeque<>();
for (char c : s.toCharArray()) {
if (c == '','') continue;
if (c == ''t'' || c == ''f'') nums.addLast(c);
if (c == ''|'' || c == ''&'' || c == ''!'') ops.addLast(c);
if (c == ''('') nums.addLast(''-'');
if (c == '')'') {
char op = ops.pollLast(), cur = '' '';
while (!nums.isEmpty() && nums.peekLast() != ''-'') {
char top = nums.pollLast();
cur = cur == '' '' ? top : calc(top, cur, op);
}
if (op == ''!'') cur = cur == ''t'' ? ''f'' : ''t'';
nums.pollLast(); nums.addLast(cur);
}
}
return nums.peekLast() == ''t'';
}
char calc(char a, char b, char op) {
boolean x = a == ''t'', y = b == ''t'';
boolean ans = op == ''|'' ? x | y : x & y;
return ans ? ''t'' : ''f'';
}
}TypeScript 代码:
function parseBoolExpr(s: string): boolean {
function calc(a: string, b: string, op: string): string {
const x = a == ''t'', y = b == ''t''
const ans = op == ''|'' ? x || y : x && y
return ans ? ''t'' : ''f''
}
const nums = new Array<string>(s.length).fill(''''), ops = new Array<string>(s.length).fill('''')
let idx1 = 0, idx2 = 0
for (const c of s) {
if (c == '','') continue
if (c == ''t'' || c == ''f'') nums[idx1++] = c
if (c == ''|'' || c == ''&'' || c == ''!'') ops[idx2++] = c
if (c == ''('') nums[idx1++] = ''-''
if (c == '')'') {
let op = ops[--idx2], cur = '' ''
while (idx1 > 0 && nums[idx1 - 1] != ''-'') {
const top = nums[--idx1]
cur = cur == '' '' ? top : calc(top, cur, op)
}
if (op == ''!'') cur = cur == ''t'' ? ''f'' : ''t''
idx1--; nums[idx1++] = cur
}
}
return nums[idx1 - 1] == ''t''
}Python 代码:
class Solution:
def parseBoolExpr(self, s: str) -> bool:
def calc(a, b, op):
x, y = a == ''t'', b == ''t''
ans = x | y if op == ''|'' else x & y
return ''t'' if ans else ''f''
nums, ops = [], []
for c in s:
if c == '','':
continue
if c == ''t'' or c == ''f'':
nums.append(c)
if c == ''|'' or c == ''&'' or c == ''!'':
ops.append(c)
if c == ''('':
nums.append(''-'')
if c == '')'':
op, cur = ops.pop(), '' ''
while nums and nums[-1] != ''-'':
top = nums.pop()
cur = top if cur == '' '' else calc(cur, top, op)
if op == ''!'':
cur = ''t'' if cur == ''f'' else ''f''
nums.pop()
nums.append(cur)
return nums[-1] == ''t''- 时间复杂度:$O(n)$
- 空间复杂度:$O(n)$
最后
这是我们「刷穿 LeetCode」系列文章的第 No.1106 篇,系列开始于 2021/01/01,截止于起始日 LeetCode 上共有 1916 道题目,部分是有锁题,我们将先把所有不带锁的题目刷完。
在这个系列文章里面,除了讲解解题思路以外,还会尽可能给出最为简洁的代码。如果涉及通解还会相应的代码模板。
为了方便各位同学能够电脑上进行调试和提交代码,我建立了相关的仓库:https://github.com/SharingSou... 。
在仓库地址里,你可以看到系列文章的题解链接、系列文章的相应代码、LeetCode 原题链接和其他优选题解。
更多更全更热门的「笔试/面试」相关资料可访问排版精美的 合集新基地
本文由mdnice多平台发布
、1 (t")
2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (t
2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。实现一个函数,算出有几种可使该表达式得出 result 值的括号方法。
福大大 答案 2021-06-03:
方法一:递归。
方法二:动态规划。
代码用 golang 编写。代码如下:
package main
import "fmt"
func main() {
express := "1&1&1" desired := 1 ret0 := countEval0(express, desired) ret1 := countEval1(express, desired) ret2 := countEval2(express, desired) fmt.Println(ret0, ret1, ret2)
}
func countEval0(express string, desired int) int { if express == "" { return 0 } N := len(express) dp := make([][]*Info, N) for i := 0; i < N; i++ { dp[i] = make([]*Info, N) } allInfo := ff(express, 0, len(express)-1, dp) return twoSelectOne(desired == 1, allInfo.t, allInfo.f)}
type Info struct { t int f int}
func twoSelectOne(c bool, a int, b int) int { if c { return a } else { return b }}
// 限制:// L...R上,一定有奇数个字符// L位置的字符和R位置的字符,非0即1,不能是逻辑符号!// 返回str[L...R]这一段,为true的方法数,和false的方法数func ff(str string, L int, R int, dp [][]*Info) *Info { if dp[L][R] != nil { return dp[L][R] } t := 0 f := 0 if L == R { t = twoSelectOne(str[L] == ''1'', 1, 0) f = twoSelectOne(str[L] == ''0'', 1, 0) } else { // L..R >=3 // 每一个种逻辑符号,split枚举的东西 // 都去试试最后结合 for split := L + 1; split < R; split += 2 { leftInfo := ff(str, L, split-1, dp) rightInfo := ff(str, split+1, R, dp) a := leftInfo.t b := leftInfo.f c := rightInfo.t d := rightInfo.f switch str[split] { case ''&'': t += a * c f += b*c + b*d + a*d break case ''|'': t += a*c + a*d + b*c f += b * d break case ''^'': t += a*d + b*c f += a*c + b*d break } }
} dp[L][R] = &Info{t, f} return dp[L][R]}
func countEval1(express string, desired int) int { if express == "" { return 0 } return f(express, desired, 0, len(express)-1)}
func f(str string, desired int, L int, R int) int { if L == R { if str[L] == ''1'' { return desired } else { return desired ^ 1 } } res := 0 if desired == 1 { for i := L + 1; i < R; i += 2 { switch str[i] { case ''&'': res += f(str, 1, L, i-1) * f(str, 1, i+1, R) break case ''|'': res += f(str, 1, L, i-1) * f(str, 0, i+1, R) res += f(str, 0, L, i-1) * f(str, 1, i+1, R) res += f(str, 1, L, i-1) * f(str, 1, i+1, R) break case ''^'': res += f(str, 1, L, i-1) * f(str, 0, i+1, R) res += f(str, 0, L, i-1) * f(str, 1, i+1, R) break } } } else { for i := L + 1; i < R; i += 2 { switch str[i] { case ''&'': res += f(str, 0, L, i-1) * f(str, 1, i+1, R) res += f(str, 1, L, i-1) * f(str, 0, i+1, R) res += f(str, 0, L, i-1) * f(str, 0, i+1, R) break case ''|'': res += f(str, 0, L, i-1) * f(str, 0, i+1, R) break case ''^'': res += f(str, 1, L, i-1) * f(str, 1, i+1, R) res += f(str, 0, L, i-1) * f(str, 0, i+1, R) break } } } return res}
func countEval2(express string, desired int) int { if express == "" { return 0 } N := len(express) dp := make([][][]int, 2) for i := 0; i < 2; i++ { dp[i] = make([][]int, N) for j := 0; j < N; j++ { dp[i][j] = make([]int, N) } } dp[0][0][0] = twoSelectOne(express[0] == ''0'', 1, 0) dp[1][0][0] = dp[0][0][0] ^ 1 for i := 2; i < len(express); i += 2 { dp[0][i][i] = twoSelectOne(express[i] == ''1'', 0, 1) dp[1][i][i] = twoSelectOne(express[i] == ''0'', 0, 1) for j := i - 2; j >= 0; j -= 2 { for k := j; k < i; k += 2 { if express[k+1] == ''&'' { dp[1][j][i] += dp[1][j][k] * dp[1][k+2][i] dp[0][j][i] += (dp[0][j][k]+dp[1][j][k])*dp[0][k+2][i] + dp[0][j][k]*dp[1][k+2][i] } else if express[k+1] == ''|'' { dp[1][j][i] += (dp[0][j][k]+dp[1][j][k])*dp[1][k+2][i] + dp[1][j][k]*dp[0][k+2][i] dp[0][j][i] += dp[0][j][k] * dp[0][k+2][i] } else { dp[1][j][i] += dp[0][j][k]*dp[1][k+2][i] + dp[1][j][k]*dp[0][k+2][i] dp[0][j][i] += dp[0][j][k]*dp[0][k+2][i] + dp[1][j][k]*dp[1][k+2][i] } } } } return dp[desired][0][N-1]}
执行结果如下:
***
[左神 java 代码](https://gitee.com/moonfdd/coding-for-great-offer/blob/main/src/class10/Code05_BooleanEvaluation.java)
本文分享自微信公众号 - 福大大架构师每日一题(gh_bbe96e5def84)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。")
2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。
2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。实现一个函数,算出有几种可使该表达式得出 result 值的括号方法。
福大大 答案2021-06-03:
方法一:递归。
方法二:动态规划。
代码用golang编写。代码如下:
package main
import "fmt"
func main() {
express := "1&1&1"
desired := 1
ret0 := countEval0(express, desired)
ret1 := countEval1(express, desired)
ret2 := countEval2(express, desired)
fmt.Println(ret0, ret1, ret2)
}
func countEval0(express string, desired int) int {
if express == "" {
return 0
}
N := len(express)
dp := make([][]*Info, N)
for i := 0; i < N; i++ {
dp[i] = make([]*Info, N)
}
allInfo := ff(express, 0, len(express)-1, dp)
return twoSelectOne(desired == 1, allInfo.t, allInfo.f)
}
type Info struct {
t int
f int
}
func twoSelectOne(c bool, a int, b int) int {
if c {
return a
} else {
return b
}
}
// 限制:
// L...R上,一定有奇数个字符
// L位置的字符和R位置的字符,非0即1,不能是逻辑符号!
// 返回str[L...R]这一段,为true的方法数,和false的方法数
func ff(str string, L int, R int, dp [][]*Info) *Info {
if dp[L][R] != nil {
return dp[L][R]
}
t := 0
f := 0
if L == R {
t = twoSelectOne(str[L] == ''1'', 1, 0)
f = twoSelectOne(str[L] == ''0'', 1, 0)
} else { // L..R >=3
// 每一个种逻辑符号,split枚举的东西
// 都去试试最后结合
for split := L + 1; split < R; split += 2 {
leftInfo := ff(str, L, split-1, dp)
rightInfo := ff(str, split+1, R, dp)
a := leftInfo.t
b := leftInfo.f
c := rightInfo.t
d := rightInfo.f
switch str[split] {
case ''&'':
t += a * c
f += b*c + b*d + a*d
break
case ''|'':
t += a*c + a*d + b*c
f += b * d
break
case ''^'':
t += a*d + b*c
f += a*c + b*d
break
}
}
}
dp[L][R] = &Info{t, f}
return dp[L][R]
}
func countEval1(express string, desired int) int {
if express == "" {
return 0
}
return f(express, desired, 0, len(express)-1)
}
func f(str string, desired int, L int, R int) int {
if L == R {
if str[L] == ''1'' {
return desired
} else {
return desired ^ 1
}
}
res := 0
if desired == 1 {
for i := L + 1; i < R; i += 2 {
switch str[i] {
case ''&'':
res += f(str, 1, L, i-1) * f(str, 1, i+1, R)
break
case ''|'':
res += f(str, 1, L, i-1) * f(str, 0, i+1, R)
res += f(str, 0, L, i-1) * f(str, 1, i+1, R)
res += f(str, 1, L, i-1) * f(str, 1, i+1, R)
break
case ''^'':
res += f(str, 1, L, i-1) * f(str, 0, i+1, R)
res += f(str, 0, L, i-1) * f(str, 1, i+1, R)
break
}
}
} else {
for i := L + 1; i < R; i += 2 {
switch str[i] {
case ''&'':
res += f(str, 0, L, i-1) * f(str, 1, i+1, R)
res += f(str, 1, L, i-1) * f(str, 0, i+1, R)
res += f(str, 0, L, i-1) * f(str, 0, i+1, R)
break
case ''|'':
res += f(str, 0, L, i-1) * f(str, 0, i+1, R)
break
case ''^'':
res += f(str, 1, L, i-1) * f(str, 1, i+1, R)
res += f(str, 0, L, i-1) * f(str, 0, i+1, R)
break
}
}
}
return res
}
func countEval2(express string, desired int) int {
if express == "" {
return 0
}
N := len(express)
dp := make([][][]int, 2)
for i := 0; i < 2; i++ {
dp[i] = make([][]int, N)
for j := 0; j < N; j++ {
dp[i][j] = make([]int, N)
}
}
dp[0][0][0] = twoSelectOne(express[0] == ''0'', 1, 0)
dp[1][0][0] = dp[0][0][0] ^ 1
for i := 2; i < len(express); i += 2 {
dp[0][i][i] = twoSelectOne(express[i] == ''1'', 0, 1)
dp[1][i][i] = twoSelectOne(express[i] == ''0'', 0, 1)
for j := i - 2; j >= 0; j -= 2 {
for k := j; k < i; k += 2 {
if express[k+1] == ''&'' {
dp[1][j][i] += dp[1][j][k] * dp[1][k+2][i]
dp[0][j][i] += (dp[0][j][k]+dp[1][j][k])*dp[0][k+2][i] + dp[0][j][k]*dp[1][k+2][i]
} else if express[k+1] == ''|'' {
dp[1][j][i] += (dp[0][j][k]+dp[1][j][k])*dp[1][k+2][i] + dp[1][j][k]*dp[0][k+2][i]
dp[0][j][i] += dp[0][j][k] * dp[0][k+2][i]
} else {
dp[1][j][i] += dp[0][j][k]*dp[1][k+2][i] + dp[1][j][k]*dp[0][k+2][i]
dp[0][j][i] += dp[0][j][k]*dp[0][k+2][i] + dp[1][j][k]*dp[1][k+2][i]
}
}
}
}
return dp[desired][0][N-1]
}
执行结果如下:

左神java代码
总结
以上是小编为你收集整理的2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
原文地址:https://blog.csdn.net/weixin_48502062/article/details/117537426
、1 (true)、& (AND)、 | (OR) 和 ^ (XOR...")
2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR...
2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。实现一个函数,算出有几种可使该表达式得出 result 值的括号方法。
福大大 答案2021-06-03:
方法一:递归。
方法二:动态规划。
代码用golang编写。代码如下:
package main
import "fmt"
func main() {
express := "1&1&1"
desired := 1
ret0 := countEval0(express, desired)
ret1 := countEval1(express, desired)
ret2 := countEval2(express, desired)
fmt.Println(ret0, ret1, ret2)
}
func countEval0(express string, desired int) int {
if express == "" {
return 0
}
N := len(express)
dp := make([][]*Info, N)
for i := 0; i < N; i++ {
dp[i] = make([]*Info, N)
}
allInfo := ff(express, 0, len(express)-1, dp)
return twoSelectOne(desired == 1, allInfo.t, allInfo.f)
}
type Info struct {
t int
f int
}
func twoSelectOne(c bool, a int, b int) int {
if c {
return a
} else {
return b
}
}
// 限制:
// L...R上,一定有奇数个字符
// L位置的字符和R位置的字符,非0即1,不能是逻辑符号!
// 返回str[L...R]这一段,为true的方法数,和false的方法数
func ff(str string, L int, R int, dp [][]*Info) *Info {
if dp[L][R] != nil {
return dp[L][R]
}
t := 0
f := 0
if L == R {
t = twoSelectOne(str[L] == ''1'', 1, 0)
f = twoSelectOne(str[L] == ''0'', 1, 0)
} else {
// L..R >=3
// 每一个种逻辑符号,split枚举的东西
// 都去试试最后结合
for split := L + 1; split < R; split += 2 {
leftInfo := ff(str, L, split-1, dp)
rightInfo := ff(str, split+1, R, dp)
a := leftInfo.t
b := leftInfo.f
c := rightInfo.t
d := rightInfo.f
switch str[split] {
case ''&'':
t += a * c
f += b*c + b*d + a*d
break
case ''|'':
t += a*c + a*d + b*c
f += b * d
break
case ''^'':
t += a*d + b*c
f += a*c + b*d
break
}
}
}
dp[L][R] = &Info{
t, f}
return dp[L][R]
}
func countEval1(express string, desired int) int {
if express == "" {
return 0
}
return f(express, desired, 0, len(express)-1)
}
func f(str string, desired int, L int, R int) int {
if L == R {
if str[L] == ''1'' {
return desired
} else {
return desired ^ 1
}
}
res := 0
if desired == 1 {
for i := L + 1; i < R; i += 2 {
switch str[i] {
case ''&'':
res += f(str, 1, L, i-1) * f(str, 1, i+1, R)
break
case ''|'':
res += f(str, 1, L, i-1) * f(str, 0, i+1, R)
res += f(str, 0, L, i-1) * f(str, 1, i+1, R)
res += f(str, 1, L, i-1) * f(str, 1, i+1, R)
break
case ''^'':
res += f(str, 1, L, i-1) * f(str, 0, i+1, R)
res += f(str, 0, L, i-1) * f(str, 1, i+1, R)
break
}
}
} else {
for i := L + 1; i < R; i += 2 {
switch str[i] {
case ''&'':
res += f(str, 0, L, i-1) * f(str, 1, i+1, R)
res += f(str, 1, L, i-1) * f(str, 0, i+1, R)
res += f(str, 0, L, i-1) * f(str, 0, i+1, R)
break
case ''|'':
res += f(str, 0, L, i-1) * f(str, 0, i+1, R)
break
case ''^'':
res += f(str, 1, L, i-1) * f(str, 1, i+1, R)
res += f(str, 0, L, i-1) * f(str, 0, i+1, R)
break
}
}
}
return res
}
func countEval2(express string, desired int) int {
if express == "" {
return 0
}
N := len(express)
dp := make([][][]int, 2)
for i := 0; i < 2; i++ {
dp[i] = make([][]int, N)
for j := 0; j < N; j++ {
dp[i][j] = make([]int, N)
}
}
dp[0][0][0] = twoSelectOne(express[0] == ''0'', 1, 0)
dp[1][0][0] = dp[0][0][0] ^ 1
for i := 2; i < len(express); i += 2 {
dp[0][i][i] = twoSelectOne(express[i] == ''1'', 0, 1)
dp[1][i][i] = twoSelectOne(express[i] == ''0'', 0, 1)
for j := i - 2; j >= 0; j -= 2 {
for k := j; k < i; k += 2 {
if express[k+1] == ''&'' {
dp[1][j][i] += dp[1][j][k] * dp[1][k+2][i]
dp[0][j][i] += (dp[0][j][k]+dp[1][j][k])*dp[0][k+2][i] + dp[0][j][k]*dp[1][k+2][i]
} else if express[k+1] == ''|'' {
dp[1][j][i] += (dp[0][j][k]+dp[1][j][k])*dp[1][k+2][i] + dp[1][j][k]*dp[0][k+2][i]
dp[0][j][i] += dp[0][j][k] * dp[0][k+2][i]
} else {
dp[1][j][i] += dp[0][j][k]*dp[1][k+2][i] + dp[1][j][k]*dp[0][k+2][i]
dp[0][j][i] += dp[0][j][k]*dp[0][k+2][i] + dp[1][j][k]*dp[1][k+2][i]
}
}
}
}
return dp[desired][0][N-1]
}执行结果如下:
左神java代码
关于是否可以为字符串比较计算布尔表达式?和对字符串进行布尔运算的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于1106. 解析布尔表达式 : 双栈求解表达式问题、2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (t、2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR) 符号组成。、2021-06-03:布尔运算。给定一个布尔表达式和一个期望的布尔结果 result,布尔表达式由 0 (false)、1 (true)、& (AND)、 | (OR) 和 ^ (XOR...等相关知识的信息别忘了在本站进行查找喔。
这篇文章主要围绕用Java计算平均值和java计算平均值和标准差展开,旨在为您提供一份详细的参考资料。我们将全面介绍用Java计算平均值的优缺点,解答java计算平均值和标准差的相关问题,同时也会为您带来bash – awk计算平均值或零、C 语言实例 - 计算平均值、Excel怎么算平均值 Excel表格计算平均值操作方法、excel怎么计算平均值的实用方法。
本文目录一览:")
用Java计算平均值(java计算平均值和标准差)
编辑:我已经写了平均的代码,但我不知道如何使它也使用从我的args.length而不是数组的整数
我需要编写一个Java程序,该程序可以计算:1.读入的整数数2.平均值-不必是整数!
注意!我不想从数组中计算平均值,但是要在args中计算整数。
目前我已经写了这个:
int count = 0; for (int i = 0; i<args.length -1; ++i) count++; System.out.println(count); }int nums[] = new int[] { 23, 1, 5, 78, 22, 4};double result = 0; //average will have decimal point { for(int i=0; i < nums.length; i++){ result += nums[i]; } System.out.println(result/count) }谁能指导我正确的方向?还是举个例子,以书面形式指导我塑造这段代码?
提前致谢
答案1
小编典典只需对您的代码进行一些小的修改即可(为了清楚起见,使用了一些var重命名):
double sum = 0; //average will have decimal pointfor(int i=0; i < args.length; i++){ //parse string to double, note that this might fail if you encounter a non-numeric string //Note that we could also do Integer.valueOf( args[i] ) but this is more flexible sum += Double.valueOf( args[i] ); }double average = sum/args.length;System.out.println(average );注意,循环也可以简化:
for(String arg : args){ sum += Double.valueOf( arg );}编辑:OP似乎要使用args数组。这似乎是一个String数组,因此相应地更新了答案。
更新 :
正如zoxqoj正确指出的那样,上面的代码未考虑整数/双精度溢出。尽管我假设输入值将足够小而不会出现问题,但以下代码段可用于非常大的输入值:
BigDecimal sum = BigDecimal.ZERO;for(String arg : args){ sum = sum.add( new BigDecimal( arg ) );}这种方法有几个优点(尽管速度较慢,所以不要将其用于时间紧迫的操作):
- 保持精度,将精度加倍,您将逐渐降低数学运算数量的精度(或完全不获得精确的精度,具体取决于数字)
- 实际上消除了溢出的可能性。但是请注意,a
BigDecimal可能大于adouble或的大小long。

bash – awk计算平均值或零
grep '^num' file.$i | awk '{ sum += $2 } END { print sum / NR }'
但有时文件不包含模式,其中cas我希望脚本返回零.这个略有修改的单线的任何想法?
awk '/^num/ {n++;sum+=$2} END {print n?sum/n:0}' file

C 语言实例 - 计算平均值
C 语言实例 - 计算平均值
C 语言实例 C 语言实例
使用数组来计算几个数的平均值。
实例
#include <stdio.h>
int main()
{
int n, i;
float num[100], sum = 0.0, average;
printf("输入元素个数: ");
scanf("%d", &n);
while (n > 100 || n <= 0)
{
printf("Error! 数字需要在1 到 100 之间。\n");
printf("再次输入: ");
scanf("%d", &n);
}
for(i = 0; i < n; ++i)
{
printf("%d. 输入数字: ", i+1);
scanf("%f", &num[i]);
sum += num[i];
}
average = sum / n;
printf("平均值 = %.2f", average);
return 0;
}
输出结果为:
输入元素个数: 4
1. 输入数字: 1
2. 输入数字: 2
3. 输入数字: 4
4. 输入数字: 8
平均值 = 3.75

Excel怎么算平均值 Excel表格计算平均值操作方法
我们在使用excel表格的时候,可以通过一些公式来计算数值,平均值也是比较常看的数值,虽然用手动选中单元格就可以查看,但是当我们的数据多的时候就不适用了,那么应该怎么通过公式来快速计算,本期的软件教程就来和大伙分享具体的操作步骤,希望能够给更多小伙伴带来帮助。excel怎么算平均值:1、首先打开excel,然后输入相对应的数值。
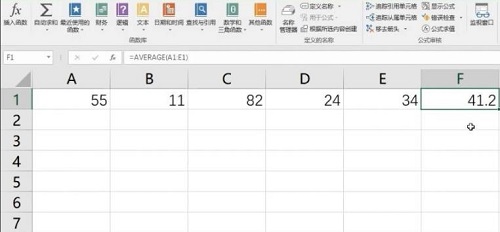
以上就是Excel怎么算平均值 Excel表格计算平均值操作方法的详细内容,更多请关注php中文网其它相关文章!

excel怎么计算平均值
在 excel 中计算平均值需要遵循以下步骤:1. 选择要计算平均值的数据范围;2. 插入“average”函数;3. 输入数据范围作为函数参数;4. 按下回车键。

如何使用 Excel 计算平均值
在 Excel 中,计算平均值非常简单快捷。下面是详细步骤:
第一步:选择要计算平均值的数据
- 选中包含数字数据的单元格区域。
第二步:插入平均值函数
- 单击公式选项卡。
- 在“函数库”组中,选择“统计”类别。
- 单击“AVERAGE”函数。
第三步:输入函数参数
- 在函数参数框中,输入要计算平均值的单元格区域。例如,如果您的数据位于 A1:A10,则输入“A1:A10”。
第四步:按回车键
- 按下回车键,Excel 将计算并显示平均值。
提示:
- 您还可以使用快捷键 Alt + H,U,A 计算平均值。
- 要计算加权平均值,请使用“AVERAGEWEIGHTED”函数。
- 如果您的数据包含空单元格或文本值,Excel 将忽略这些值。
以上就是excel怎么计算平均值的详细内容,更多请关注php中文网其它相关文章!
关于用Java计算平均值和java计算平均值和标准差的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于bash – awk计算平均值或零、C 语言实例 - 计算平均值、Excel怎么算平均值 Excel表格计算平均值操作方法、excel怎么计算平均值的相关信息,请在本站寻找。
以上就是给各位分享如何使用JAVA计算标准差,其中也会对如何使用java计算标准差值进行解释,同时本文还将给你拓展excel如何计算标准差、excel怎么算标准差、excel怎么算标准差?excel计算标准差方法介绍、excel标准差函数是什么 excel怎么计算标准差等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- 如何使用JAVA计算标准差(如何使用java计算标准差值)
- excel如何计算标准差
- excel怎么算标准差
- excel怎么算标准差?excel计算标准差方法介绍
- excel标准差函数是什么 excel怎么计算标准差
")
如何使用JAVA计算标准差(如何使用java计算标准差值)
我在这里很新,目前正在尝试使用Java计算标准偏差(我已经用谷歌搜索了哈哈),但是在使其正常工作方面存在很多问题
我有一个由用户输入的十个值,然后我必须计算到目前为止我所理解的标准偏差,这要归功于已经回答过的人们,我找到了数组的均值然后完成了计算
double two = total[2]; double three = total[3]; double four = total[3]; double five = total[4]; double six = total[6]; double seven = total[7]; double eight = total[8]; double nine = total[9]; double ten = total[10]; double eleven = average_total;mean = one + two + three + four + five + six + seven + eight + nine + ten + eleven;mean = mean/11;//one = one - mean;//System.out.println("I really hope this prints out a value:" +one);*/ //eleven = average_total - mean; //eleven = Math.pow(average_total,average_total); //stand_dev = (one + two + three + four + five + six + seven + eight + nine + ten + eleven); //stand_dev = stand_dev - mean;// stand_dev = (stand_dev - mean) * (stand_dev - mean);// stand_dev = (stand_dev/11);// stand_dev = Math.sqrt(stand_dev);我已经将数据存储在10个值的数组中,但是我不太确定如何从数组中打印数据,然后进行计算而不必将输入代码存储在这里数据中,而这些数据我已经处理过
谢谢您的宝贵时间,非常感谢:)
答案1
小编典典calculate mean of array.
loop through values array value = (indexed value - mean)^2 calculate sum of the new array. divide the sum by the array length square root it编辑:
我将向您展示如何遍历数组,所有步骤几乎都是同一步骤,只是计算方式不同。
// calculating mean.int total = 0;for(int i = 0; i < array.length; i++){ total += array[i]; // this is the calculation for summing up all the values}double mean = total / array.length;编辑2:
阅读代码后,您做错的部分是您没有遍历这些值并没有正确地用平均值减去它。
又名这部分。
十一= average_total-平均值;
十一= Math.pow(average_total,average_total);
您需要这样做。
for(int i = 0; i < array.length; i++){ array[i] = Math.pow((array[i]-mean),2)}本质上,您需要使用newvalue = oldvalue-mean(average)更改数组中的每个值。
然后计算总和…然后求平方根。

excel如何计算标准差
excel标准差函数是什? excel怎么计算标准差呢?其实在生活中标准差是经常使用到的,它表示一组数据的离散程度,数值越大,预示着离散程度越大;数值越小,预示着离散程度越小,接下来给大家详细介绍excel标准差函数的计算方法。

excel标准差计算的方法如下:
1、首先选中最后标准差要出现的单元格;
2、点击【开始】-【自动求和】旁边的三角,出现下拉菜单,点击【其他函数】;
3、出现【插入函数】的窗口,点击【选择类别】,选择【全部】,找到标准差的函数【STDEVP】;
4、点击确定后,点击箭头所指的位置,选择数据;
5、选择完成后,再次点击箭头所指的图标,回到设置窗口,点击【确定】;
6、就可以看到计算好的标准差了;
以上所述是excel标准差计算的方法,希望对大家有所帮助。

excel怎么算标准差
excel 中计算标准差的步骤:选择数据范围。插入 stdev 函数并输入数据范围。选择“样本”(用于估计总体标准差)或“总体”(当拥有所有数据时)。单击“确定”以获得标准差结果。

如何使用 Excel 计算标准差
标准差是衡量数据集离散程度的一个统计量,它可以反映数据点的分布情况。在 Excel 中,计算标准差非常简单。
步骤:
- 选择数据范围:首先,选择包含您要计算标准差的数据范围。
- 插入函数:在公式栏中,单击“插入函数”按钮(希腊字母 sigma)。
- 选择“STDEV”函数:在弹出的“插入函数”对话框中,搜索并选择“STDEV”函数。
- 输入数据范围:在“数字”字段中,输入要计算标准差的数据范围。
-
确定样本或总体标准差:在“函数”字段中选择“样本”或“总体”选项。
- 样本(STDEV):用于计算样本数据的标准差,代表总体数据的良好估计。
- 总体(STDEVP):用于计算总体数据的标准差,当您拥有所有总体数据时使用。
- 单击“确定”:完成所有字段后,单击“确定”按钮。
- 获得标准差结果:选定的单元格将显示所选数据范围的标准差结果。
示例:
假设您有一个包含销售额数据的列 A,从 A2 到 A10。要计算这些销售额的标准差,请按照以下步骤操作:
- 选择 A2:A10 范围。
- 插入 STDEV 函数并输入数据范围 A2:A10。
- 选择“样本”选项。
- 单击“确定”。
结果将显示在所选单元格中,表示数据集中销售额的标准差。
以上就是excel怎么算标准差的详细内容,更多请关注php中文网其它相关文章!

excel怎么算标准差?excel计算标准差方法介绍
怎样才能计算Excel中的标准差呢?标准差能够表示一组数据的离散程度,数值越大离散程度越大,如何计算一组数据的标准差呢?现在就为大家简单介绍一下
方法/步骤
1、首先选中最后标准差要出现的单元格
2、点击【开始】-【自动求和】旁边的三角,出现下拉菜单,点击【其他函数
3、出现【插入函数】的窗口,点击【选择类别】,选择【全部】,找到标准差的函数【STDEVP】
4、点击确定后,点击箭头所指的位置,选择数据
5、选择完成后,再次点击箭头所指的图标,回到设置窗口,点击【确定】
6、就可以看到计算好的标准差了
以上就是excel计算标准差方法介绍,希望能对大家有所帮助!

excel标准差函数是什么 excel怎么计算标准差
怎样才能计算Excel中的标准差呢?标准差能够表示一组数据的离散程度,数值越大离散程度越大,如何计算一组数据的标准差呢?现在就为大家简单介绍一下
excel标准差函数是什? excel怎么计算标准差呢?其实在生活中标准差是经常使用到的,它表示一组数据的离散程度,数值越大,预示着离散程度越大;数值越小,预示着离散程度越小,接下来小编给大家详细介绍excel标准差函数的计算方法。

excel标准差计算的方法如下:
1、首先选中最后标准差要出现的单元格;

2、点击【开始】-【自动求和】旁边的三角,出现下拉菜单,点击【其他函数】;

3、出现【插入函数】的窗口,点击【选择类别】,选择【全部】,找到标准差的函数【STDEVP】;

4、点击确定后,点击箭头所指的位置,选择数据;

5、选择完成后,再次点击箭头所指的图标,回到设置窗口,点击【确定】;

6、就可以看到计算好的标准差了;

以上所述是小编给大家介绍的excel标准差计算的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小编网站的支持!
总结
以上是小编为你收集整理的excel标准差函数是什么 excel怎么计算标准差全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
今天关于如何使用JAVA计算标准差和如何使用java计算标准差值的讲解已经结束,谢谢您的阅读,如果想了解更多关于excel如何计算标准差、excel怎么算标准差、excel怎么算标准差?excel计算标准差方法介绍、excel标准差函数是什么 excel怎么计算标准差的相关知识,请在本站搜索。
关于Python-给定2个句子字符串,计算余弦相似度和python两个字符串匹配的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于C# Net 比较2个字符串的相似度(使用余弦相似度)、java – 如何有效地计算数百万字符串之间的余弦相似度、java算法之余弦相似度计算字符串相似率、KNN cosine 余弦相似度计算等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- Python-给定2个句子字符串,计算余弦相似度(python两个字符串匹配)
- C# Net 比较2个字符串的相似度(使用余弦相似度)
- java – 如何有效地计算数百万字符串之间的余弦相似度
- java算法之余弦相似度计算字符串相似率
- KNN cosine 余弦相似度计算
")
Python-给定2个句子字符串,计算余弦相似度(python两个字符串匹配)
从Python:tf-idf-cosine:查找文档相似度,可以使用tf-idf余弦计算文档相似度。如果不导入外部库,是否有任何方法可以计算2个字符串之间的余弦相似度?
s1 = "This is a foo bar sentence ."s2 = "This sentence is similar to a foo bar sentence ."s3 = "What is this string ? Totally not related to the other two lines ."cosine_sim(s1, s2) # Should give high cosine similaritycosine_sim(s1, s3) # Shouldn''t give high cosine similarity valuecosine_sim(s2, s3) # Shouldn''t give high cosine similarity value答案1
小编典典一个简单的纯Python实现是:
import re, mathfrom collections import CounterWORD = re.compile(r''\w+'')def get_cosine(vec1, vec2): intersection = set(vec1.keys()) & set(vec2.keys()) numerator = sum([vec1[x] * vec2[x] for x in intersection]) sum1 = sum([vec1[x]**2 for x in vec1.keys()]) sum2 = sum([vec2[x]**2 for x in vec2.keys()]) denominator = math.sqrt(sum1) * math.sqrt(sum2) if not denominator: return 0.0 else: return float(numerator) / denominatordef text_to_vector(text): words = WORD.findall(text) return Counter(words)text1 = ''This is a foo bar sentence .''text2 = ''This sentence is similar to a foo bar sentence .''vector1 = text_to_vector(text1)vector2 = text_to_vector(text2)cosine = get_cosine(vector1, vector2)print ''Cosine:'', cosine印刷品:
Cosine: 0.861640436855这里所用的余弦公式描述这里。
这不包括通过tf-idf对单词进行加权,但是为了使用tf-idf,你需要具有一个相当大的语料库才能从中估计tfidf的权重。
你还可以通过使用更复杂的方法从一段文本中提取单词,对其进行词干或词义化等来进一步开发它。
")
C# Net 比较2个字符串的相似度(使用余弦相似度)
C# Net 比较2个字符串的相似度(使用余弦相似度)
复制代码使用:
/// <summary>
/// 比较2个字符串的相似度(使用余弦相似度)
/// </summary>
/// <param name="str1"></param>
/// <param name="str2"></param>
/// <returns>0-1之间的数</returns>
public static double SimilarityCos(string str1, string str2)
{
str1 = str1.Trim();
str2 = str2.Trim();
if (string.IsNullOrEmpty(str1) || string.IsNullOrEmpty(str2))
return 0;
List<string> lstr1 = SimpParticiple(str1);
List<string> lstr2 = SimpParticiple(str2);
//求并集
var strUnion = lstr1.Union(lstr2);
//求向量
List<int> int1 = new List<int>();
List<int> int2 = new List<int>();
foreach (var item in strUnion)
{
int1.Add(lstr1.Count(o => o == item));
int2.Add(lstr2.Count(o => o == item));
}
double s = 0;
double den1 = 0;
double den2 = 0;
for (int i = 0; i < int1.Count(); i++)
{
//求分子
s += int1[i] * int2[i];
//求分母(1)
den1 += Math.Pow(int1[i], 2);
//求分母(2)
den2 += Math.Pow(int2[i], 2);
}
return s / (Math.Sqrt(den1) * Math.Sqrt(den2));
}
/// <summary>
/// 简单分词(需要更好的效果,需要这里优化,比如把:【今天天气很好】,分成【今天,天气,很好】,同时可以做同义词优化,【今天】=【今日】效果更好)
/// </summary>
public static List<string> SimpParticiple(string str)
{
List<string> vs = new List<string>();
foreach (var item in str)
{
vs.Add(item.ToString());
}
return vs;
}

java – 如何有效地计算数百万字符串之间的余弦相似度
编辑
我想确定哪些字符串与给定字符串最相似,并且能够获得与相似性相关的度量/分数.我认为我想做的事情与群集相符合,群集的数量最初并不为人所知.
解决方法
从本质上讲,计算余弦相似性的天真方式是不好的.因为你最终计算了很多0 *的东西.相反,你最好在列中工作,并在那里留下所有0.

java算法之余弦相似度计算字符串相似率
这篇文章主要介绍了java算法之余弦相似度计算字符串相似率,对算法感兴趣的同学,可以参考下
目录
概述
一、理论知识
1、说重点
2、案例理论知识
二、实际开发案例
1、pom.xml
2、main方法
3、Tokenizer(分词工具类)
4、Word(封装分词结果)
5、Cosinesimilarity(相似率具体实现工具类)
6、AtomicFloat原子类
三、总结
概述
功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中。这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻
或者一样的新闻,那就不存储到数据库中。(因为有网站会去引用其它网站新闻,或者把其它网站新闻拿过来稍微改下内容就发布到自己网站中)。
解析方案:最终就是采用余弦相似度算法,来计算两个新闻正文的相似度。现在自己写一篇博客总结下。
一、理论知识
先推荐一篇博客,对于余弦相似度算法的理论讲的比较清晰,我们也是按照这个方式来计算相似度的。网址:相似度算法之余弦相似度。
1、说重点
我这边先把计算两个字符串的相似度理论知识再梳理一遍。
(1)首先是要明白通过向量来计算相识度公式。

(2)明白:余弦值越接近1,也就是两个向量越相似,这就叫"余弦相似性",
余弦值越接近0,也就是两个向量越不相似,也就是这两个字符串越不相似。
2、案例理论知识
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,计算词频。(也就是每个词语出现的频率)
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第三步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
第四步:运用上面的公式:计算如下:

计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
二、实际开发案例
我把我们实际开发过程中字符串相似率计算代码分享出来。
1、pom.xml
展示一些主要jar包
org.apache.commonscommons-lang33.5org.projectlomboklombokcom.hankcshanlpportable-1.6.5
2、main方法
/** * 计算两个字符串的相识度 */ public class Similarity { public static final String content1="今天小小和爸爸一起去摘草莓,小小说今天的草莓特别的酸,而且特别的小,关键价格还贵"; public static final String content2="今天小小和妈妈一起去草原里采草莓,今天的草莓味道特别好,而且价格还挺实惠的"; public static void main(String[] args) { double score=Cosinesimilarity.getSimilarity(content1,content2); System.out.println("相似度:"+score); score=Cosinesimilarity.getSimilarity(content1,content1); System.out.println("相似度:"+score); } }
先看运行结果:

通过运行结果得出:
(1)第一次比较相似率为:0.772853 (说明这两条句子还是挺相似的),第二次比较相似率为:1.0 (说明一模一样)。
(2)我们可以看到这个句子的分词效果,后面是词性。
3、Tokenizer(分词工具类)
import com.hankcs.hanlp.HanLP; import com.hankcs.hanlp.seg.common.Term; import java.util.List; import java.util.stream.Collectors; /** * 中文分词工具类*/ public class Tokenizer { /** * 分词*/ public static List segment(String sentence) { //1、 采用HanLP中文自然语言处理中标准分词进行分词 List termlist = HanLP.segment(sentence); //上面控制台打印信息就是这里输出的 System.out.println(termlist.toString()); //2、重新封装到Word对象中(term.word代表分词后的词语,term.nature代表改词的词性) return termlist.stream().map(term -> new Word(term.word, term.nature.toString())).collect(Collectors.toList()); } }
4、Word(封装分词结果)
这里面真正用到的其实就词名和权重。
import lombok.Data; import java.util.Objects; /** * 封装分词结果*/ @Data public class Word implements Comparable { // 词名 private String name; // 词性 private String pos; // 权重,用于词向量分析 private Float weight; public Word(String name, String pos) { this.name = name; this.pos = pos; } @Override public int hashCode() { return Objects.hashCode(this.name); } @Override public boolean equals(Object obj) { if (obj == null) { return false; } if (getClass() != obj.getClass()) { return false; } final Word other = (Word) obj; return Objects.equals(this.name, other.name); } @Override public String toString() { StringBuilder str = new StringBuilder(); if (name != null) { str.append(name); } if (pos != null) { str.append("/").append(pos); } return str.toString(); } @Override public int compareto(Object o) { if (this == o) { return 0; } if (this.name == null) { return -1; } if (o == null) { return 1; } if (!(o instanceof Word)) { return 1; } String t = ((Word) o).getName(); if (t == null) { return 1; } return this.name.compareto(t); } }
5、Cosinesimilarity(相似率具体实现工具类)
import com.jincou.algorithm.tokenizer.Tokenizer; import com.jincou.algorithm.tokenizer.Word; import org.apache.commons.lang3.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.util.CollectionUtils; import java.math.BigDecimal; import java.util.*; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.atomic.AtomicInteger; /** * 判定方式:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度 余弦夹角原理: 向量a=(x1,y1),向量b=(x2,y2) similarity=a.b/|a|*|b| a.b=x1x2+y1y2 * |a|=根号[(x1)^2+(y1)^2],|b|=根号[(x2)^2+(y2)^2]*/ public class Cosinesimilarity { protected static final Logger LOGGER = LoggerFactory.getLogger(Cosinesimilarity.class); /** * 1、计算两个字符串的相似度 */ public static double getSimilarity(String text1, String text2) { //如果wei空,或者字符长度为0,则代表完全相同 if (StringUtils.isBlank(text1) && StringUtils.isBlank(text2)) { return 1.0; } //如果一个为0或者空,一个不为,那说明完全不相似 if (StringUtils.isBlank(text1) || StringUtils.isBlank(text2)) { return 0.0; } //这个代表如果两个字符串相等那当然返回1了(这个我为了让它也分词计算一下,所以注释掉了) // if (text1.equalsIgnoreCase(text2)) { // return 1.0; // } //第一步:进行分词 List words1 = Tokenizer.segment(text1); List words2 = Tokenizer.segment(text2); return getSimilarity(words1, words2); } /** * 2、对于计算出的相似度保留小数点后六位 */ public static double getSimilarity(List words1, List words2) { double score = getSimilarityImpl(words1, words2); //(int) (score * 1000000 + 0.5)其实代表保留小数点后六位 ,因为1034234.213强制转换不就是1034234。对于强制转换添加0.5就等于四舍五入 score = (int) (score * 1000000 + 0.5) / (double) 1000000; return score; } /** * 文本相似度计算 判定方式:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度 余弦夹角原理: 向量a=(x1,y1),向量b=(x2,y2) similarity=a.b/|a|*|b| a.b=x1x2+y1y2 * |a|=根号[(x1)^2+(y1)^2],|b|=根号[(x2)^2+(y2)^2] */ public static double getSimilarityImpl(List words1, List words2) { // 向每一个Word对象的属性都注入weight(权重)属性值 taggingWeightByFrequency(words1, words2); //第二步:计算词频 //通过上一步让每个Word对象都有权重值,那么在封装到map中(key是词,value是该词出现的次数(即权重)) Map weightMap1 = getFastSearchMap(words1); Map weightMap2 = getFastSearchMap(words2); //将所有词都装入set容器中 Set words = new HashSet(); words.addAll(words1); words.addAll(words2); AtomicFloat ab = new AtomicFloat();// a.b AtomicFloat aa = new AtomicFloat();// |a|的平方 AtomicFloat bb = new AtomicFloat();// |b|的平方 // 第三步:写出词频向量,后进行计算 words.parallelStream().forEach(word -> { //看同一词在a、b两个集合出现的此次 Float x1 = weightMap1.get(word.getName()); Float x2 = weightMap2.get(word.getName()); if (x1 != null && x2 != null) { //x1x2 float oneOfTheDimension = x1 * x2; //+ ab.addAndGet(oneOfTheDimension); } if (x1 != null) { //(x1)^2 float oneOfTheDimension = x1 * x1; //+ aa.addAndGet(oneOfTheDimension); } if (x2 != null) { //(x2)^2 float oneOfTheDimension = x2 * x2; //+ bb.addAndGet(oneOfTheDimension); } }); //|a| 对aa开方 double aaa = Math.sqrt(aa.doubleValue()); //|b| 对bb开方 double bbb = Math.sqrt(bb.doubleValue()); //使用BigDecimal保证精确计算浮点数 //double aabb = aaa * bbb; BigDecimal aabb = BigDecimal.valueOf(aaa).multiply(BigDecimal.valueOf(bbb)); //similarity=a.b/|a|*|b| //divide参数说明:aabb被除数,9表示小数点后保留9位,最后一个表示用标准的四舍五入法 double cos = BigDecimal.valueOf(ab.get()).divide(aabb, 9, BigDecimal.ROUND_HALF_UP).doubleValue(); return cos; } /** * 向每一个Word对象的属性都注入weight(权重)属性值 */ protected static void taggingWeightByFrequency(List words1, List words2) { if (words1.get(0).getWeight() != null && words2.get(0).getWeight() != null) { return; } //词频统计(key是词,value是该词在这段句子中出现的次数) Map frequency1 = getFrequency(words1); Map frequency2 = getFrequency(words2); //如果是DEBUG模式输出词频统计信息 // if (LOGGER.isDebugEnabled()) { // LOGGER.debug("词频统计1:n{}", getWordsFrequencyString(frequency1)); // LOGGER.debug("词频统计2:n{}", getWordsFrequencyString(frequency2)); // } // 标注权重(该词出现的次数) words1.parallelStream().forEach(word -> word.setWeight(frequency1.get(word.getName()).floatValue())); words2.parallelStream().forEach(word -> word.setWeight(frequency2.get(word.getName()).floatValue())); } /** * 统计词频 * @return 词频统计图 */ private static Map getFrequency(List words) { Map freq = new HashMap(); //这步很帅哦 words.forEach(i -> freq.computeIfAbsent(i.getName(), k -> new AtomicInteger()).incrementAndGet()); return freq; } /** * 输出:词频统计信息 */ private static String getWordsFrequencyString(Map frequency) { StringBuilder str = new StringBuilder(); if (frequency != null && !frequency.isEmpty()) { AtomicInteger integer = new AtomicInteger(); frequency.entrySet().stream().sorted((a, b) -> b.getValue().get() - a.getValue().get()).forEach( i -> str.append("t").append(integer.incrementAndGet()).append("、").append(i.getKey()).append("=") .append(i.getValue()).append("n")); } str.setLength(str.length() - 1); return str.toString(); } /** * 构造权重快速搜索容器 */ protected static Map getFastSearchMap(List words) { if (CollectionUtils.isEmpty(words)) { return Collections.emptyMap(); } Map weightMap = new ConcurrentHashMap(words.size()); words.parallelStream().forEach(i -> { if (i.getWeight() != null) { weightMap.put(i.getName(), i.getWeight()); } else { LOGGER.error("no word weight info:" + i.getName()); } }); return weightMap; } }
这个具体实现代码因为思维很紧密所以有些地方写的比较绕,同时还手写了AtomicFloat原子类。
6、AtomicFloat原子类
import java.util.concurrent.atomic.AtomicInteger; /** * jdk没有AtomicFloat,写一个 */ public class AtomicFloat extends Number { private AtomicInteger bits; public AtomicFloat() { this(0f); } public AtomicFloat(float initialValue) { bits = new AtomicInteger(Float.floatToIntBits(initialValue)); } //叠加 public final float addAndGet(float delta) { float expect; float update; do { expect = get(); update = expect + delta; } while (!this.compareAndSet(expect, update)); return update; } public final float getAndAdd(float delta) { float expect; float update; do { expect = get(); update = expect + delta; } while (!this.compareAndSet(expect, update)); return expect; } public final float getAndDecrement() { return getAndAdd(-1); } public final float decrementAndGet() { return addAndGet(-1); } public final float getAndIncrement() { return getAndAdd(1); } public final float incrementAndGet() { return addAndGet(1); } public final float getAndSet(float newValue) { float expect; do { expect = get(); } while (!this.compareAndSet(expect, newValue)); return expect; } public final boolean compareAndSet(float expect, float update) { return bits.compareAndSet(Float.floatToIntBits(expect), Float.floatToIntBits(update)); } public final void set(float newValue) { bits.set(Float.floatToIntBits(newValue)); } public final float get() { return Float.intBitsToFloat(bits.get()); } @Override public float floatValue() { return get(); } @Override public double doubleValue() { return (double) floatValue(); } @Override public int intValue() { return (int) get(); } @Override public long longValue() { return (long) get(); } @Override public String toString() { return Float.toString(get()); } }
三、总结
把大致思路再捋一下:
(1)先分词:分词当然要按一定规则,不然随便分那也没有意义,那这里通过采用HanLP中文自然语言处理中标准分词进行分词。
(2)统计词频:就统计上面词出现的次数。
(3)通过每一个词出现的次数,变成一个向量,通过向量公式计算相似率。

KNN cosine 余弦相似度计算
# coding: utf-8
import collections
import numpy as np
import os
from sklearn.neighbors import NearestNeighbors
def cos(vector1,vector2):
dot_product = 0.0;
normA = 0.0;
normB = 0.0;
for a,b in zip(vector1,vector2):
dot_product += a*b
normA += a**2
normB += b**2
if normA == 0.0 or normB==0.0:
return None
else:
return dot_product / ((normA*normB)**0.5)
def iterbrowse(path):
for home, dirs, files in os.walk(path):
for filename in files:
yield os.path.join(home, filename)
def get_data(filename):
white_verify = []
with open(filename) as f:
lines = f.readlines()
for line in lines:
a = line.split("\t")
if len(a) != 78:
print(line)
raise Exception("fuck")
white_verify.append([float(n) for n in a[3:]])
return white_verify
unwanted_features = {6, 7, 8, 41,42,43,67,68,69,70,71,72,73,74,75}
def get_wanted_data(x):
return x
"""
ans = []
for item in x:
#row = [data for i, data in enumerate(item) if i+6 in wanted_feature]
row = [data for i, data in enumerate(item) if i+6 not in unwanted_features]
ans.append(row)
#assert len(row) == len(wanted_feature)
assert len(row) == len(x[0])-len(unwanted_features)
return ans
"""
if __name__ == "__main__":
neg_file = "cc_data/black/black_all.txt"
pos_file = "cc_data/white/white_all.txt"
X = []
y = []
# if os.path.isfile(pos_file):
# if pos_file.endswith(''.txt''):
# pos_set = np.genfromtxt(pos_file)
# elif pos_file.endswith(''.npy''):
# pos_set = np.load(pos_file)
# X.extend(pos_set)
# y += [0] * len(pos_set)
# print("len of X(white):", len(X))
if os.path.isfile(neg_file):
if neg_file.endswith(''.txt''):
neg_set = np.genfromtxt(neg_file)
elif neg_file.endswith(''.npy''):
neg_set = np.load(neg_file)
X.extend(list(neg_set) * 1)
y += [1] * (1 * len(neg_set))
print("len of X:", len(X))
# print("X sample:", X[:3])
# print("len of y:", len(y))
# print("y sample:", y[:3])
X = [x[3:] for x in X]
X = get_wanted_data(X)
# print("filtered X sample:", X[:3])
black_verify = []
for f in iterbrowse("todo/top"):
print(f)
black_verify += get_data(f)
# print(black_verify)
black_verify = get_wanted_data(black_verify)
black_verify_labels = [1] * len(black_verify)
white_verify = get_data("todo/white_verify.txt")
# print(white_verify)
white_verify = get_wanted_data(white_verify)
white_verify_labels = [0] * len(white_verify)
unknown_verify = get_data("todo/pek_feature74.txt")
unknown_verify = get_wanted_data(unknown_verify)
bd_verify = get_data("guzhaoshen_pek_out.txt")
# print(unknown_verify)
# samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]]
#neigh = NearestNeighbors(n_neighbors=3)
neigh = NearestNeighbors(n_neighbors=1, metric=''cosine'')
neigh.fit(X)
print("neigh.kneighbors(black_verify)")
nearest_points = (neigh.kneighbors(black_verify))
print(nearest_points)
for i, x in enumerate(black_verify):
print(i, nearest_points[1][i], "cosine:", cos(x, nearest_points[1][i]))
#print(neigh.predict(black_verify))
print("neigh.kneighbors(white_verify)")
nearest_points = (neigh.kneighbors(white_verify))
print(nearest_points)
for i, x in enumerate(white_verify):
print(i, nearest_points[1][i], "cosine:", cos(x, nearest_points[1][i]))
#print(neigh.predict(white_verify))
print("neigh.kneighbors(unknown_verify)")
nearest_points = (neigh.kneighbors(unknown_verify))
print(nearest_points)
for i, x in enumerate(unknown_verify):
print(i, nearest_points[1][i], "cosine:", cos(x, nearest_points[1][i]))
#print(neigh.predict(unknown_verify))
print("neigh.kneighbors(self)")
print(neigh.kneighbors(X[:3]))
#print(neigh.predict(X[:3]))
print("neigh.kneighbors(bd pek)")
print(neigh.kneighbors(bd_verify))
nearest_points = (neigh.kneighbors(bd_verify))
print(nearest_points)
for i, x in enumerate(bd_verify):
print(i, nearest_points[1][i], "cosine:", cos(x, nearest_points[1][i]))输出示例:
neigh.kneighbors(white_verify)
(array([[ 0.01140831],
[ 0.0067373 ],
[ 0.00198682],
[ 0.00686728],
[ 0.00210445],
[ 0.00061413],
[ 0.00453888]]), array([[11032],
[ 967],
[11091],
[13149],
[11091],
[19041],
[13068]]))
(0, array([11032]), ''cosine:'', 1.0)
(1, array([967]), ''cosine:'', 1.0)
(2, array([11091]), ''cosine:'', 1.0)
(3, array([13149]), ''cosine:'', 1.0)
(4, array([11091]), ''cosine:'', 1.0)
(5, array([19041]), ''cosine:'', 1.0)
(6, array([13068]), ''cosine:'', 1.0)
样本质量堪忧啊!!!
注意:如果是常规knn,计算距离时候记得标准化。如果各个维度的数据属性衡量单位不一样:
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X)
X = scaler.transform(X)
print("standard X sample:", X[:3])
black_verify = scaler.transform(black_verify)
print(black_verify)
white_verify = scaler.transform(white_verify)
print(white_verify)
unknown_verify = scaler.transform(unknown_verify)
print(unknown_verify)
关于Python-给定2个句子字符串,计算余弦相似度和python两个字符串匹配的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于C# Net 比较2个字符串的相似度(使用余弦相似度)、java – 如何有效地计算数百万字符串之间的余弦相似度、java算法之余弦相似度计算字符串相似率、KNN cosine 余弦相似度计算等相关内容,可以在本站寻找。
以上就是给各位分享如何计算java.awt.geom.Area的面积?,其中也会对java怎么算面积进行解释,同时本文还将给你拓展CAD2007如何计算面积?CAD2007计算面积方法、CAD如何计算图形面积?cad计算图纸面积方法、Java AWT / SWT / Swing:如何计划GUI?、java – 如何计算JTextArea中的行数,包括由包装引起的行数?等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- 如何计算java.awt.geom.Area的面积?(java怎么算面积)
- CAD2007如何计算面积?CAD2007计算面积方法
- CAD如何计算图形面积?cad计算图纸面积方法
- Java AWT / SWT / Swing:如何计划GUI?
- java – 如何计算JTextArea中的行数,包括由包装引起的行数?
")
如何计算java.awt.geom.Area的面积?(java怎么算面积)
我正在寻找一种方法来计算的任意实例的面积(以像素为单位)java.awt.geom.Area。
背景:我Shape的应用程序中可能存在可能重叠的。我想知道一个Shape重叠的部分。的ShapeS可以是歪斜的,旋转,等等。如果我有一个函数area(Shape)(或Area),我可以使用的两个交叉点Shape就像这样:
double fractionObscured(Shape bottom, Shape top) { Area intersection = new Area(bottom); intersection.intersect(new Area(top)); return area(intersection) / area(bottom);}答案1
小编典典一种方法是使用合适的方法fill()分别缩放和变换Shape为不同的颜色,AlphaComposite并计算基础像素中的重叠像素Raster。
附录1:使用此计算器查看效果,AlphaComposite.Xor表明任意两种不透明颜色的间隔为零。
附录2:计数像素可能会导致性能问题;采样可能会有所帮助。如果每个Shape都是合理凸的,则有可能根据intersect()面积与Shapes’
的面积之和的比率来估计重叠getBounds2D()。例如,
Shape s1, s2 ...Rectangle2D r1 = s1.getBounds2D();Rectangle2D r2 = s2.getBounds2D();Rectangle2D r3 = new Rectangle2D.Double();Rectangle2D.intersect(r1, r2, r3);double overlap = area(r3) / (area(r1) + area(r2));...private double area(Rectangle2D r) { return r.getWidth() * r.getHeight();}您可能需要凭经验验证结果。

CAD2007如何计算面积?CAD2007计算面积方法
大家都知道AutoCAD2007是一款非常专业的绘图软件,为经常跟工程打交道的同事们,肯定每天必须接触到CAD,现在CAD版本很多,而大多数的工程师们还是喜欢用2007版本的,当然是它最经典,最兼容,最好用了。计算面积是一个特别常见的做法。图形若是规则就不必费很多力气,不规则的话很多人就不知道怎么下手了。那么如何在cad2007中计算不规则图形面积?下面为大家详细介绍CAD2007计算面积方法,一起来看看吧!

方法/步骤
1、打开CAD2007软件,选择CAD经典模式。

2、在菜单栏里选择打开,或者直接快捷键“ctrl+o”,选择图纸。以我的图纸为例。

3、如果你的图形有图层,并且图层可以选中的话,你可以直接单击图层,然后点击菜单栏里的“工具”——“查询”——“列表显示”,就可以看到面积了。

4、如果没有图层,但是图形是比较规则的,那我们可以通过公式来查询面积。在命令框输入“aa”,回车,然后依次点击图形的端点,使之封闭,最后鼠标右键确定就会显示面积。

5、如果图形不规则,那我们可以用合成多段线和画多段线来解决。合成多段线的命令是“pe”,之后再输入“m”,然后选择图形的边,右键确定,接着Y——J——0,这样多段线合成了,再通过第二种方法查询面积即可。

6、绘制多段线是另一种办法。点左侧菜单栏的“多段线”,然后依次单击图形端点,使之封闭,最后依旧是利用第二种办法查询面积。

以上就是CAD2007计算面积方法介绍,希望对大家有所帮助!

CAD如何计算图形面积?cad计算图纸面积方法
众所周知,CAD是一款实用的制图工具,常用于建筑图纸设计,室内设计,很多工程相关职业都要会使用CAD制图,要会看懂CAD图片。那么给你一张室内设计图,你会用AutoCAD工具来测量面积吗?CAD怎么算面积?下面,我们就一起来看看CAD计算面积图文教程详解。
一、查询命令
1、CAD各个版本操作基本一致,这里以CAD2014为例。对于简单图形,使用简单的查询就能搞定。具体方法是,打开cad图形,在菜单栏,点击“ 工具 ”。
2、调出工具选项,用鼠标指着“ 查询Q ”,激活查询命令。
3、弹出查询的更多功能选项,点击“ 面积 ”。
4、这时候使用鼠标拾取需要查询的围成面积的各个关键点。
5、拾取各个点,围成一个 封闭图形。
6、点击“ 回车键 ”,这时候就直接弹出面积信息,这里的面积一般是以mm为单位的,所以要转化成自己习惯的平方米,小数点向左移动6位即可看出面积。
二、复杂图形的面积查询
1、对于简单图形,按照刚才的方式查询感觉差不多,但是对于不规则的多边形,拾取点将会花费很多时间,这样效率低下,这时候如果觉得费时间,可以创建面域,然后点击“ 工具 ”——“ 查询”——“ 面积 ”中进行查看。

Java AWT / SWT / Swing:如何计划GUI?
我已经实现了一些带有小型图形用户界面的应用程序。没什么复杂的,但是我遇到了一些问题,这些问题导致组件无法显示或无法正常运行。
现在我的问题是:
您如何计划这些用户界面?当您需要进行更改时该怎么办?您如何调试奇怪的行为?
这几乎适用于所有类型的GUI设计。当然,使用Microsoft Visual Studio具有很大的优势,因为您几乎获得了在设计器中看到的东西。
是否存在 优秀 的AWT开源设计器?已经环顾四周,没有发现任何真正聪明的东西。
编辑: 到目前为止,我还手动创建了所有GUI。当然,这是更简洁的代码,但有时很难找到布局错误。如果Visual Studio by
MS能够创建近似干净的代码,那么其他人为什么不呢?
我听说过一些Eclipse Visual设计器。那个已经准备好生产了吗?
答案1
小编典典我不是GUI建设者的忠实拥护者:他们通常会自动生成大量的代码,然后将您的整个开发团队锁定为使用一个IDE。而且,此代码通常不可读(请检查在Netbeans下使用Matisse时生成的代码)。
我对GUI设计/调试的建议是:
main在每个面板(或“顶级”组件)实现中添加一个方法,使其他开发人员可以轻松确定组件的外观。- 赞成使用
Actions overActionListeners并在每个JComponents中注册这些动作ActionMap。这允许它们被“提取”并添加到UI的其他部分(例如JToolBar),同时它们的状态仍由“所有权”JComponent(即松散耦合)控制。 - 使用assert来确保所有UI组件修改都在Event Dispatch线程上进行;例如
assert SwingUtilities.isEventDispatchThread()。 - 要调试奇怪的布局行为,请考虑将组件的背景涂成红色!
- 集中捕获和报告工作流事件和异常。例如,我通常实现一个
TaskManager在UI的状态栏中注册的类。任何后台处理(在SwingWorkers 内执行)都会通过传递给Task创建的句柄TaskManager。与工作Interracting(通过调用setDescription(String),setThrowable(Throwable),cancel())导致要更新的状态栏。这也将导致玻璃窗格显示为“全局”任务…但是,所有窗格都与单个SwingWorkers分离/隐藏了。 - 不要使用
Observer/Observable班,而是青睐ChangeListener,PropertyChangeListener或传播事件自己定制的监听器实现。Observer传递一个Objectas事件,迫使客户端代码使用instanceof检查类型并执行向下转换,使代码不可读并且使类之间的关系不那么清楚。 - 即使在表只有一列的情况下,也建议使用
JTableoverJList。JList它的API中有一些讨厌的功能,包括您需要为其提供原型值以正确计算其大小这一事实。 - 永远不要使用
DefaultTableModel它,因为它通常会导致您将“模型”数据存储在两个位置:在实际的业务对象中以及位于2D数组中DefaultTableModel。相反,只需子类AbstractTableModel-这 很容易 做到,并且意味着您的实现可以简单地委派给List存储您的数据的数据结构(例如)。

java – 如何计算JTextArea中的行数,包括由包装引起的行数?
为了做到这一点,我计划使用…来计算字体的高度
Font font = jTextArea.getFont(); FontMetrics fontMetrics = jTextArea.getFontMetrics(font); int lineHeight = fontMetrics.getAscent() + fontMetrics.getDescent();
…然后将其乘以JTextArea中使用的行数.问题是JTextArea.getLineCount()计算忽略包装线的行返回数.
如何计算JTextArea中使用的行数,包括由word wrap引起的行数?
这里有一些演示代码让这个问题变得更容易.我有一个监听器,每次窗口调整大小时打印出行数.目前,它总是打印1,但是我想要补偿单词包装,并打印出实际使用了多少行.
编辑:我在下面的代码中包含了问题的解决方案.静态countLines方法给出了解决方案.
package components;
import java.awt.*;
import java.awt.event.*;
import java.awt.font.*;
import java.text.*;
import javax.swing.*;
public class JTextAreaLineCountDemo extends JPanel {
JTextArea textArea;
public JTextAreaLineCountDemo() {
super(new GridBagLayout());
String inputStr = "Lorem ipsum dolor sit amet,consectetur adipisicing elit,sed do eiusmo";
textArea = new JTextArea(inputStr);
textArea.setEditable(false);
textArea.setLineWrap(true);
textArea.setWrapStyleWord(true);
// Add Components to this panel.
GridBagConstraints c = new GridBagConstraints();
c.gridwidth = GridBagConstraints.REMAINDER;
c.fill = GridBagConstraints.BOTH;
c.weightx = 1.0;
c.weighty = 1.0;
add(textArea,c);
addComponentListener(new ComponentAdapter() {
@Override
public void componentResized(ComponentEvent ce) {
System.out.println("Line count: " + countLines(textArea));
}
});
}
private static int countLines(JTextArea textArea) {
AttributedString text = new AttributedString(textArea.getText());
FontRenderContext frc = textArea.getFontMetrics(textArea.getFont())
.getFontRenderContext();
AttributedCharacterIterator charIt = text.getIterator();
LineBreakMeasurer lineMeasurer = new LineBreakMeasurer(charIt,frc);
float formatWidth = (float) textArea.getSize().width;
lineMeasurer.setPosition(charIt.getBeginIndex());
int noLines = 0;
while (lineMeasurer.getPosition() < charIt.getEndindex()) {
lineMeasurer.nextLayout(formatWidth);
noLines++;
}
return noLines;
}
private static void createAndShowGUI() {
JFrame frame = new JFrame("JTextAreaLineCountDemo");
frame.setDefaultCloSEOperation(JFrame.EXIT_ON_CLOSE);
frame.add(new JTextAreaLineCountDemo());
frame.pack();
frame.setVisible(true);
}
public static void main(String[] args) {
javax.swing.SwingUtilities.invokelater(new Runnable() {
public void run() {
createAndShowGUI();
}
});
}
}
解决方法
LineBreakMeasurer类.
The LineBreakMeasurer class allows styled text to be broken into lines (or segments) that fit within a particular visual advance. This is useful for clients who wish to display a paragraph of text that fits within a specific width,called the wrapping width.LineBreakMeasurer implements the most commonly used line-breaking policy: Every word that fits within the wrapping width is placed on the line. If the first word does not fit,then all of the characters that fit within the wrapping width are placed on the line. At least one character is placed on each line.
关于如何计算java.awt.geom.Area的面积?和java怎么算面积的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于CAD2007如何计算面积?CAD2007计算面积方法、CAD如何计算图形面积?cad计算图纸面积方法、Java AWT / SWT / Swing:如何计划GUI?、java – 如何计算JTextArea中的行数,包括由包装引起的行数?的相关知识,请在本站寻找。
本文将分享计算复活节星期天的日期的详细内容,并且还将对计算复活节星期天的日期怎么算进行详尽解释,此外,我们还将为大家带来关于AngularJS:明天的日期和昨天的某个ng组件的日期、iOS 获取本周星期一至星期日的日期、iOS:获取一周7天的日期(年-月-日-星期)、java 计算当前日期所在周的星期一及星期日的日期的相关知识,希望对你有所帮助。
本文目录一览:- 计算复活节星期天的日期(计算复活节星期天的日期怎么算)
- AngularJS:明天的日期和昨天的某个ng组件的日期
- iOS 获取本周星期一至星期日的日期
- iOS:获取一周7天的日期(年-月-日-星期)
- java 计算当前日期所在周的星期一及星期日的日期
")
计算复活节星期天的日期(计算复活节星期天的日期怎么算)
编写一个程序来计算复活节星期天的日期。复活节星期日是春天的第一个满月之后的第一个星期日。使用数学家卡尔·弗里德里希·高斯(Carl Friedrich
Gauss)在1800年发明的算法:
- 让
y是年份(如1800年或2001年) - 除以
y通过19并调用剩余a。忽略商。 - 除以
y通过100获得商b和余数c。 - 除以
b通过4获得商d和余数e。 - 除以
8 * b + 13通过25获得商g。忽略其余部分。 - 除以
19 * a + b - d - g + 15通过30得到的余数h。忽略商。 - 除以
c通过4获得商j和余数k。 - 除以
a + 11 * h通过319获得商m。忽略其余部分。 - 除以
2 * e + 2 * j - k - h + m + 32通过7得到的余数r。忽略商。 - 除以
h - m + r + 90通过25获得商n。忽略其余部分。 - 除以
h - m + r + n + 19通过32获得的剩余部分p。忽略商。
然后复活节p是一个月的一天n。
例如,如果y为2001:
a = 6b = 20c = 1d = 5e = 0g = 6h = 18j = 0k = 1m = 0r = 6n = 4p = 15因此,在2001年,复活节星期日是4月15日。
确保提示用户输入年份并让用户输入年份。另外,请确保输出p和n的值以及描述输出值的适当消息。
将其放入Java代码时遇到了一些麻烦。这是我尝试过的:
import java.util.Scanner;public class Easter { public static void main(String[] args) { Scanner input = new Scanner(System.in); int y = 2014; int a = y % 19; int b = y / 100; int c = y % 100; int d = b / 4; int e = b % 4; int g = (8 * b + 13) / 25; int h = (19 * a + b - d - g + 15) % 30; int j = c / 4; int k = c % 4; int m = (a + 11 * h) / 319; int r = (2 * e + 2 * j - k - h + m + 32) % 7; int n = (h - m + r + 90) / 25; int p = (h - m + r + n + 19) % 32; getEasterSundayMonth = n; System.out.println("Month: " + Easter.getEasterSundayMonth()); }}这就是我所拥有的。我不知道如何分配内容,就像我试图使getEasterSundayMonth的值相等一样n,很确定它是不正确的。我从这里去哪里?
答案1
小编典典试试这个:
import java.util.Scanner;class Easter{ public static void main(String[] args) { System.out.print("Please enter a year to calculate Easter Sunday\n>"); Scanner s = new Scanner(System.in); int inputted = getResult(s); while(inputted <= 0) { System.out.print("Expected a positive year. Please try again:\n>"); inputted = getResult(s); } System.out.println(getEasterSundayDate(inputted)); } private static int getResult(Scanner s) { while(!s.hasNextInt()) { System.out.print("Expected a valid year. Please try again:\n>"); s.nextLine(); } return s.nextInt(); } public static String getEasterSundayDate(int year) { int a = year % 19, b = year / 100, c = year % 100, d = b / 4, e = b % 4, g = (8 * b + 13) / 25, h = (19 * a + b - d - g + 15) % 30, j = c / 4, k = c % 4, m = (a + 11 * h) / 319, r = (2 * e + 2 * j - k - h + m + 32) % 7, n = (h - m + r + 90) / 25, p = (h - m + r + n + 19) % 32; String result; switch(n) { case 1: result = "January "; break; case 2: result = "February "; break; case 3: result = "March "; break; case 4: result = "April "; break; case 5: result = "May "; break; case 6: result = "June "; break; case 7: result = "July "; break; case 8: result = "August "; break; case 9: result = "September "; break; case 10: result = "October "; break; case 11: result = "November "; break; case 12: result = "December "; break; default: result = "error"; } return result + p; }}2001结果的输入April 15作为输出。

AngularJS:明天的日期和昨天的某个ng组件的日期
$scope.date = new Date(); var tomorrow = new Date(); tomorrow.setDate(tomorrow.getDate() + 1);
我写过这样的东西,我知道它不正确.请更正我以这种格式显示{{date |日期:’EEE,dd MMM yyyy’}}
编辑1:我希望明天的日期显示在点击右箭头按钮上,昨天在左箭头按钮点击2014年9月3日星期三的相同位置.隐藏/显示功能,如何编码,我不明白如何用角度来获得它.参考图片
https://www.google.co.in/search?q=full+calendar+day+view&source=lnms&tbm=isch&sa=X&ei=PIqjVbP4FIijugS3qYOgBg&ved=0CAcQ_AUoAQ&biw=1360&bih=595#imgrc=2E7vtXzvWMYS0M%3A
解决方法
JSFiddle
HTML:
<div ng-app="myApp" ng-controller="myCtrl">
<p><a href="" ng-click="showToday = true; showTomorrow = false">Left arrow</a></p>
<p><a href="" ng-click="showTomorrow = true; showToday = false">Right arrow</a></p>
<span ng-show="showToday">Today: {{date | date:'EEE,dd MMM yyyy'}}</span>
<span ng-show="showTomorrow">Tomorrow: {{tomorrow | date:'EEE,dd MMM yyyy'}}</span>
</div>
JS:
angular.module('myApp',[])
.controller('myCtrl',function ($scope) {
$scope.showToday = false;
$scope.showTomorrow = false;
$scope.date = new Date();
$scope.tomorrow = new Date();
$scope.tomorrow.setDate($scope.tomorrow.getDate() + 1);
});

iOS 获取本周星期一至星期日的日期
NSDate *now = [NSDate date];
NSCalendar *calendar = [NSCalendar currentCalendar];
NSDateComponents *comp = [calendar components:NSYearCalendarUnit|NSMonthCalendarUnit|NSDayCalendarUnit|NSWeekdayCalendarUnit|NSDayCalendarUnit
fromDate:now];
// 得到星期几// 1(星期天) 2(星期二) 3(星期三) 4(星期四) 5(星期五) 6(星期六) 7(星期天)NSInteger weekDay = [comp weekday];// 得到几号NSInteger day = [comp day];
NSLog(@"weekDay:%ld day:%ld",weekDay,day);
// 计算当前日期和这周的星期一和星期天差的天数long firstDiff,lastDiff;if (weekDay == 1) {
firstDiff = 1;
lastDiff = 0;
}else{
firstDiff = [calendar firstWeekday] - weekDay;
lastDiff = 9 - weekDay;
}
NSLog(@"firstDiff:%ld lastDiff:%ld",firstDiff,lastDiff);
// 在当前日期(去掉了时分秒)基础上加上差的天数NSDateComponents *firstDayComp = [calendar components:NSYearCalendarUnit|NSMonthCalendarUnit|NSDayCalendarUnit fromDate:now];
[firstDayComp setDay:day + firstDiff];
NSDate *firstDayOfWeek= [calendar dateFromComponents:firstDayComp];
NSDateComponents *lastDayComp = [calendar components:NSYearCalendarUnit|NSMonthCalendarUnit|NSDayCalendarUnit fromDate:now];
[lastDayComp setDay:day + lastDiff];
NSDate *lastDayOfWeek= [calendar dateFromComponents:lastDayComp];
NSDateFormatter *formater = [[NSDateFormatter alloc] init];
[formater setDateFormat:@"yyyy-MM-dd HH:mm:ss"];
NSLog(@"星期一开始 %@",[formater stringFromDate:firstDayOfWeek]);
NSLog(@"当前 %@",[formater stringFromDate:now]);
NSLog(@"星期天结束 %@",[formater stringFromDate:lastDayOfWeek]);")
iOS:获取一周7天的日期(年-月-日-星期)
一、介绍
在开发中,日期的使用绝对是离不了的,跟业务的关联性太强了,例如课程表。有的时候我们不需要课程表,但是需要获取一周7天的日期,这一周内的日期,我觉得有两种理解:
1、获取当天开始的一周日期,当天作为起点往后顺延的一周(红色的为当天),实现方法见如下代码:方式一:

2、获取一周内的日期,当天在这一周内,所在一周的第一天和最后一天, 不是作为起点往后顺延(红色的为当天),实现方法见如下代码:方式二:

二、代码(放在单例工具类HYWeekCalendarUitility实现)
1、工具类声明和实现
@interface HYWeekCalendarUitility : NSObject
@property (nonatomic, strong) NSArray *weeks;
@property (nonatomic, copy) NSString *firstDayDeteOfWeek;
@property (nonatomic, copy) NSString *nowDayDeteOfWeek;
@property (nonatomic, copy) NSString *lastDayDeteOfWeek;
+ (instancetype)shareInstance;
@end+ (instancetype)shareInstance {
static HYWeekCalendarUitility *weekCalendarUitility = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
weekCalendarUitility = [[HYWeekCalendarUitility alloc] init];
//[weekCalendarUitility getDateWeeksDuraingToday];
[weekCalendarUitility getDateWeeksFromToday];
});
return weekCalendarUitility;
}-(NSString *)transWeekName:(NSString *)orrignWeekName
{
NSString *targetWeekName = @"";
//转换文案
if ([orrignWeekName isEqualToString:@"星期日"]) {
targetWeekName = @"周日";
}
else if ([orrignWeekName isEqualToString:@"星期一"]) {
targetWeekName = @"周一";
}
else if ([orrignWeekName isEqualToString:@"星期二"]) {
targetWeekName = @"周二";
}
else if ([orrignWeekName isEqualToString:@"星期三"]) {
targetWeekName = @"周三";
}
else if ([orrignWeekName isEqualToString:@"星期四"]) {
targetWeekName = @"周四";
}
else if ([orrignWeekName isEqualToString:@"星期五"]) {
targetWeekName = @"周五";
}else{
targetWeekName = @"周六";
}
return targetWeekName;
}2、方法实现
---方式一---
/**
* 模式一
* 获取当前时间开始的一周日期
* 注意:当天作为起点往后顺延的一周
*/
-(void)getDateWeeksFromToday{
//日历格式
NSCalendar *calendar = [NSCalendar currentCalendar];
NSDateFormatter *formater = [[NSDateFormatter alloc] init];
[formater setDateFormat:@"yyyy-MM-dd"];
NSMutableArray *dateWeeks = [NSMutableArray array];
for (int i=0; i<7; i++) {
//这一天
NSDateComponents *components = [calendar components:NSCalendarUnitYear | NSCalendarUnitMonth | NSCalendarUnitDay | NSCalendarUnitWeekday fromDate:[NSDate dateWithTimeIntervalSinceNow:60 * 60 * 24 * i]];
NSDate *date = [calendar dateFromComponents:components];
//年月日
NSDateFormatter *dateFormatter = [[NSDateFormatter alloc] init];
[dateFormatter setDateFormat:@"yyyy-MM-dd"];
NSString *dateString = [dateFormatter stringFromDate:date];//几月几号
//星期
NSDateFormatter *weekFormatter = [[NSDateFormatter alloc] init];
[weekFormatter setDateFormat:@"EEEE"];
NSString *weekString = [self transWeekName:[weekFormatter stringFromDate:date]];//周几
NSString *date_weekStr = [NSString stringWithFormat:@"%@-%@",dateString,weekString];
[dateWeeks addObject:date_weekStr];
//赋值
if (i==0) {
self.firstDayDeteOfWeek = [formater stringFromDate:date];
self.nowDayDeteOfWeek = [formater stringFromDate:date];
}else if (i==6) {
self.lastDayDeteOfWeek = [formater stringFromDate:date];
}
}
self.weeks = dateWeeks;
NSLog(@"----dateWeeks:%@------",dateWeeks);
}---方式二---
/**
* 模式二
* 获取当前时间所在一周的第一天和最后一天, 也即一周的日期
* 注意:当天在这一周内,不是作为起点往后顺延
*/
- (void)getDateWeeksDuraingToday
{
//日历格式
NSDate *now = [NSDate date];
NSCalendar *calendar = [NSCalendar currentCalendar];
NSDateComponents *comp = [calendar components:NSCalendarUnitYear|NSCalendarUnitMonth|NSCalendarUnitDay|NSCalendarUnitWeekday
fromDate:now];
// 得到:今天是星期几
// 1(星期天) 2(星期二) 3(星期三) 4(星期四) 5(星期五) 6(星期六) 7(星期天)
NSInteger weekDay = [comp weekday];
// 得到:今天是几号
NSInteger day = [comp day];
NSLog(@"weekDay:%ld day:%ld",weekDay,day);
// 计算当前日期和这周的星期一和星期天差的天数
long firstDiff,lastDiff;
if (weekDay == 1) {
firstDiff = 1;
lastDiff = 0;
}else{
firstDiff = [calendar firstWeekday] - weekDay;
lastDiff = 7 - weekDay;
}
NSLog(@"firstDiff:%ld lastDiff:%ld",firstDiff,lastDiff);
// 一周日期
NSArray *dateWeeks = [self getCurrentWeeksWithFirstDiff:firstDiff lastDiff:lastDiff];
// 在当前日期(去掉了时分秒)基础上加上差的天数
NSDateComponents *firstDayComp = [calendar components:NSCalendarUnitYear|NSCalendarUnitMonth|NSCalendarUnitDay fromDate:now];
[firstDayComp setDay:day + firstDiff];
NSDate *firstDayOfWeek= [calendar dateFromComponents:firstDayComp];
NSDateComponents *lastDayComp = [calendar components:NSCalendarUnitYear|NSCalendarUnitMonth|NSCalendarUnitDay fromDate:now];
[lastDayComp setDay:day + lastDiff];
NSDate *lastDayOfWeek= [calendar dateFromComponents:lastDayComp];
NSDateFormatter *formater = [[NSDateFormatter alloc] init];
[formater setDateFormat:@"yyyy-MM-dd"];
NSLog(@"一周开始 %@",[formater stringFromDate:firstDayOfWeek]);
NSLog(@"当前 %@",[formater stringFromDate:now]);
NSLog(@"一周结束 %@",[formater stringFromDate:lastDayOfWeek]);
NSLog(@"%@",dateWeeks);
self.firstDayDeteOfWeek = [formater stringFromDate:firstDayOfWeek];
self.nowDayDeteOfWeek = [formater stringFromDate:now];
self.lastDayDeteOfWeek = [formater stringFromDate:lastDayOfWeek];
self.weeks = dateWeeks;
}
//获取一周时间 数组
- (NSMutableArray *)getCurrentWeeksWithFirstDiff:(NSInteger)first lastDiff:(NSInteger)last{
NSMutableArray *eightArr = [[NSMutableArray alloc] init];
for (NSInteger i = first; i < last + 1; i ++) {
//从现在开始的24小时
NSTimeInterval secondsPerDay = i * 24*60*60;
NSDate *curDate = [NSDate dateWithTimeIntervalSinceNow:secondsPerDay]; NSDateFormatter *dateFormatter = [[NSDateFormatter alloc] init];
[dateFormatter setDateFormat:@"yyyy-MM-dd"];
NSString *dateStr = [dateFormatter stringFromDate:curDate];//几月几号
//NSString *dateStr = @"5月31日";
NSDateFormatter *weekFormatter = [[NSDateFormatter alloc] init];
[weekFormatter setDateFormat:@"EEEE"];//星期几 @"HH:mm ''on'' EEEE MMMM d"];
NSString *weekStr = [weekFormatter stringFromDate:curDate];
//转换文案
weekStr = [self transWeekName:weekStr];
//组合时间
NSString *strTime = [NSString stringWithFormat:@"%@-%@",dateStr,weekStr];
[eightArr addObject:strTime];
}
return eightArr;
}

java 计算当前日期所在周的星期一及星期日的日期
public static void mondayToSunday() {
Date now = new Date();
Date time = new Date(now.getYear(), now.getMonth(), now.getDate());
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); // 设置时间格式
Calendar cal = Calendar.getInstance();
cal.setTime(time);
// 判断要计算的日期是否是周日,如果是则减一天计算周六的,否则会出问题,计算到下一周去了
int dayWeek = cal.get(Calendar.DAY_OF_WEEK);// 获得当前日期是一个星期的第几天
if (1 == dayWeek) {
cal.add(Calendar.DAY_OF_MONTH, -1);
}
System.out.println("要计算日期为:" + sdf.format(cal.getTime())); // 输出要计算日期
// 设置一个星期的第一天,按中国的习惯一个星期的第一天是星期一
cal.setFirstDayOfWeek(Calendar.MONDAY);
// 获得当前日期是一个星期的第几天
int day = cal.get(Calendar.DAY_OF_WEEK);
// 根据日历的规则,给当前日期减去星期几与一个星期第一天的差值
cal.add(Calendar.DATE, cal.getFirstDayOfWeek() - day);
cal.set(Calendar.HOUR, 0);
cal.set(Calendar.MINUTE, 0);
cal.set(Calendar.SECOND, 0);
String imptimeBegin = sdf.format(cal.getTime());
Date mondayDate = cal.getTime();
System.out.println("所在周星期一的日期:" + imptimeBegin);
cal.add(Calendar.DATE, 6);
cal.set(Calendar.HOUR, 23);
cal.set(Calendar.MINUTE, 59);
cal.set(Calendar.SECOND, 59);
String imptimeEnd = sdf.format(cal.getTime());
Date sundayDate = cal.getTime();
System.out.println("所在周星期日的日期:" + imptimeEnd);
DateFormat datetimeDf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("星期一的开始:" + datetimeDf.format(mondayDate));
System.out.println("星期天的结束:" + datetimeDf.format(sundayDate));
}关于计算复活节星期天的日期和计算复活节星期天的日期怎么算的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于AngularJS:明天的日期和昨天的某个ng组件的日期、iOS 获取本周星期一至星期日的日期、iOS:获取一周7天的日期(年-月-日-星期)、java 计算当前日期所在周的星期一及星期日的日期等相关知识的信息别忘了在本站进行查找喔。
本文标签:




