在本文中,我们将详细介绍流式计算和实时计算有什么区别?的各个方面,并为您提供关于流式计算和实时计算有什么区别呢的相关解答,同时,我们也将为您带来关于CSharpFlink实时计算引擎,增加一个窗口或表
在本文中,我们将详细介绍流式计算和实时计算有什么区别?的各个方面,并为您提供关于流式计算和实时计算有什么区别呢的相关解答,同时,我们也将为您带来关于CSharpFlink 实时计算引擎,增加一个窗口或表达式计算任务支持多个算子实例、Hashtable,HashMap,TreeMap有什么区别?Vector,ArrayList,LinkedList有什么区别?int和Integer有什么区别?、Java 中的分布式计算和计算网格技术、Java非堆内存和堆栈内存有什么区别?如果不是,它们是否相同?两者之间有什么区别?的有用知识。
本文目录一览:- 流式计算和实时计算有什么区别?(流式计算和实时计算有什么区别呢)
- CSharpFlink 实时计算引擎,增加一个窗口或表达式计算任务支持多个算子实例
- Hashtable,HashMap,TreeMap有什么区别?Vector,ArrayList,LinkedList有什么区别?int和Integer有什么区别?
- Java 中的分布式计算和计算网格技术
- Java非堆内存和堆栈内存有什么区别?如果不是,它们是否相同?两者之间有什么区别?
")
流式计算和实时计算有什么区别?(流式计算和实时计算有什么区别呢)
流计算和实时计算是以不同的维度对计算任务做出的分类。
按数据处理的延迟分类
分为实时计算和离线计算。
实时计算强调尽快响应每个到达的数据记录,比如毫秒级甚至微秒级的响应延迟。以统计股市或者电商平台的日总成交金额为例,实时计算指每当市场上发生交易时,系统立刻对最新的成交记录做出响应,更新当日的总成交金额。
与之相对的,在交易发生时不做及时响应,而是等到第二日再统计前一日的总成交金额,则称为离线计算。
按数据处理的方式分类
分为流计算和批计算。
流计算强调其处理的数据是无界的数据流,无界的数据流也称为流数据,工业设备上的传感器记录、股市的逐笔成交记录都是源源不断生成的流数据。针对数据流这个特征,流计算是一个持续的计算任务,处理的数据大小为单条记录或者微批的记录;
批计算处理的是有界的数据集,且数据集通常包含大批量数据,一次批计算不管是运行几分钟还是几个小时,总是会结束的。
以统计日总成交金额为例,即使是在每笔交易发生时做出实时响应,依然有两种截然不同的计算方法:若以当日截止当前所有的成交数据作为计算输入得到结果,这种基于全量数据集的计算称为批计算;而若是将成交数据看做一个序列,总是增量地处理最新到达的数据以更新统计结果,则称为流计算,总成交额可以通过最近一次统计的总成交额与最新一条成交记录的金额相加得到。很明显,在实时统计总成交金额的这个例子中,流计算是更优的数据处理方式。
因此,严格来讲,流计算与实时计算这两个概念并不可以拿来类比。
但由于业界通常以流计算作为实现实时计算的底层技术,比如近年来流计算引擎 Flink 在实时计算领域被广泛应用,因此很可能在一些场合中,在使用实时计算和流计算这两种表述时并没有进行严格的区分。
最后,推荐一下我们的 DolphinDB。
DolphinDB 的实时流处理是一个轻量化一站式平台,在金融量化分析、物联网等领域有着大量的用户。在没有太多选择的情况下,很多用户基于Kafka + Flink + 实时数仓来构建实时数据处理平台,这种架构由多个子系统集群组成,无论是部署和运维成本都比较重。但是,与上述的开源多系统集成的实时计算解决方案相比,DolphinDB的实时流处理框架是基于轻量一体化设计的原则,内置支持流数据的发布、订阅、预处理、实时内存计算、复杂指标的滚动窗口计算等,将通道,计算,存储三大组件均纳入一套系统内完成,不仅实现轻量化的部署和运维,而且也支持高可用模式部署,规避单点故障对实时生产系统造成业务上的影响。
同时,从开发效率和计算性能上考虑,DolphinDB 设计了多个独立实时计算引擎,可以让业务人员以低代码的方式实现各种场景的复杂计算。DolphinDB 还提供了上百个实现了增量算法优化的内置算子,并支持内存交换方式输出计算结果,将整体计算链路的时延压缩到极致。此外,DolphinDB 作为时序数据库本身具有优秀的批计算能力,并且能够达到“流批一体”,即批计算和流计算可以使用同一套代码,并保证批计算与流计算的结果完全一致,在金融等领域此特性可以帮助企业实现产研一体,极大缩减从投研到投产的周期。
欢迎大家上手体验DolphinDB,更多使用教程可参考下方链接。
DolphinDB教程:dolphindb/Tutorials_CN
DolphinDB开发手册:欢迎阅读DolphinDB用户手册! — DolphinDB 1.30 文档

CSharpFlink 实时计算引擎,增加一个窗口或表达式计算任务支持多个算子实例
更新内容:
1.计算任务增加ResultId,用于保存(Sink)数据的时候标识计算结果。
2.窗口或表达式计算任务支持多个算子实例,应用场景,例如:一个窗口的数据,可以同时计算和值、均值或最大值等。
CSharpFlink
a real-time computing framework
官方网址 http://www.ineuos.net/
技术博客 https://www.cnblogs.com/lsjwq/
gitee地址:https://gitee.com/wxzz/CSharpFlink
1 项目背景
我们有一个全国性质的面向工业的公有云平台,通过专线或4G的链路方式实时向平台传输数据,每天处理1亿条左右的数据量,为现场用户提供实时的在线服务和离线数据分析服务。现在已经上线稳定运行有将近3年的时间。同时也为工业企业提供私有云建设服务。
我们计划使用Flink作为云平台后台的实时计算部分,基本实现数据点的聚合计算、表达式规则计算等业务,进一步实现机器学习或自定义复杂算法的需求。
我们经过将近一年左右时间的研究及开发,已经基本实现了聚合和逻辑等业务,但是感觉Flink比较重,并且应用和运维的水平要求比较高。
基于上述情况,我们自主使用NET 5.0开发一套CSharpFlink实时计算组件,支持自定义数据源、计算和存储的基本要求。

2 应用场景
主要面向物联网、工业互联网私有云或公有云平台建设过程中的数据点实时聚合和表达式计算。应用场景包括:
- 数据点的实时时间窗口范围内聚合计算,例如:最大值、最小值、平均值、和值、众数、方差、中位数等,可以自定义二次开发。
- 数据点的历史延迟窗口的一段时间范围内数据补充或更新的重新计算。
- 数据点的表达式计算,支持自定义C#脚本进行编辑,实时预警或数据深度加工处理。
- 主从结构的分布式部署,主节点负责计算任务分发,工作节点负责任务计算及结果存储。
3 框架特点
主要特点主要是根据我们多年的物联网、工业项目经验的提炼和总结,满足实现应用场景,特点包括:
- 使用最新的NET 5.0进行开发,完全跨平台。
- 实时数据窗口范围外的数据补发或更新的重新计算,例如:当前5秒的实时数据窗口,支持5秒以前的数据补充和更新,并且进行重新计算及更新到数据存储单元。
- 实时数据表达式计算支持定时计算或数据值改事件变触发计算,满足实时表达式或周期性计算。
- C#语言的二次开发,对接多种数据源,自定义算子和多种方式数据存储等。
- 单节点或分布式部署。

Hashtable,HashMap,TreeMap有什么区别?Vector,ArrayList,LinkedList有什么区别?int和Integer有什么区别?
接着上篇继续更新。
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/10759447.html* /
题目一:Hashtable,HashMap,TreeMap有什么区别?
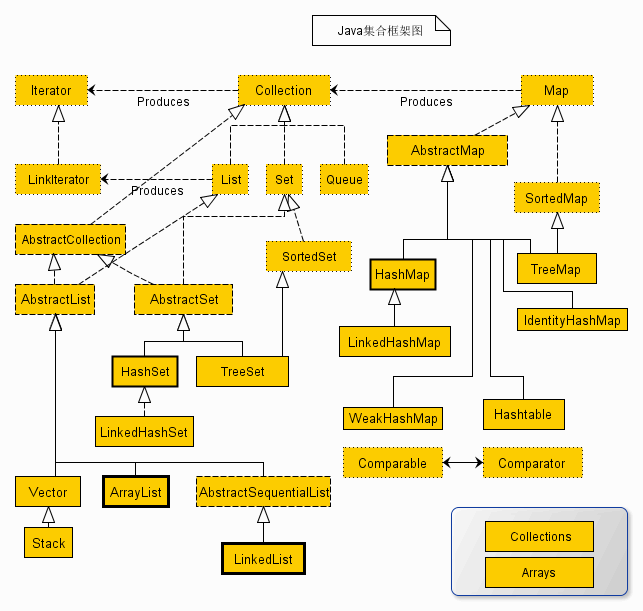
题目二:Vector,ArrayList,LinkedList有什么区别?
题目三:int和Integer有什么区别?
public class Main {
public static void main(String[] args) {
//自动装箱
Integer total = 99;
//自定拆箱
int totalprim = total;
}
}反编译class文件之后得到如下内容:

原文出处:https://www.cnblogs.com/jpcflyer/p/10759447.html

Java 中的分布式计算和计算网格技术
随着数据量和计算任务的不断增长,传统的计算方式已经无法满足大规模数据处理和高性能计算的需求。分布式计算和计算网格技术作为新兴的计算方式,已经成为解决这些问题的有效手段。特别是在 java 开发领域中,分布式计算和计算网格技术的应用得到了广泛的推广和应用。
一、分布式计算的基本原理
分布式计算采用多个计算节点协作完成一个计算任务。一个计算节点可以是一台独立的计算机或者是一个计算集群。每个计算节点都有独立的计算能力和存储能力,通过互相协作完成整个计算任务。
在分布式计算中,一个计算任务通常分为多个子任务,每个计算节点负责处理其中的一个子任务,最后将所有子任务的结果进行汇总,得到最终的计算结果。这种方式可以大大提升计算速度和处理效率,并且具备更高的可靠性和容错性。
二、分布式计算在 Java 中的应用
立即学习“Java免费学习笔记(深入)”;
Java 作为一种流行的编程语言,支持分布式计算的应用开发。Java 提供了诸如 RMI、CORBA、Web Services 等分布式计算框架和标准,方便开发人员快速实现分布式计算应用。
在 Java 中,分布式计算最常见的应用场景是数据分析和处理。比如,在大数据领域中,使用 Hadoop 开源框架进行数据处理和分析。Hadoop 采用分布式计算的方式处理海量数据,将数据分成多个数据块,每个节点处理一部分数据块,最终将结果进行整合得到最终的计算结果。
另外,分布式计算还可以应用在视频编解码和图像处理等领域。其中,视频编解码需要对每一帧图像进行处理和压缩,这些处理任务可以分配给多个节点处理,最终得到压缩后的视频流。而图像处理方面,包括人脸识别和图像识别等应用,需要对图像进行像素级别的计算处理,分布式计算可以大幅提高计算效率。
三、计算网格技术的基本原理
计算网格(Grid Computing)是一种分布式计算技术,它将多个计算节点组成一个庞大的计算机群,通过互相协作共同完成一个计算任务。与分布式计算不同,计算网格不同计算节点的计算资源进行统一调度,从而达到更高的计算效率和性能。
计算网格技术最早是在高能物理实验中应用的,用于处理庞大而复杂的实验数据。随着计算机科学和网络技术的不断发展,计算网格技术开始应用于其他领域,如天文学、材料科学、医疗诊断等。
四、计算网格技术在 Java 中的应用
计算网格技术在 Java 中的应用通常基于 Globus Toolkit 开源软件框架和标准。Globus Toolkit 提供了一套标准的接口和服务,使不同的计算节点之间可以互相通信,从而完成各种计算任务。
在计算网格应用中,通常需要将计算任务进行分解和分配,然后通过调度器将分配后的任务分配给不同的计算节点处理。Java 语言可以方便地实现这些功能,并且具备优秀的跨平台性能和高可靠性。
总之,分布式计算和计算网格技术在 Java 开发中的应用极为广泛,可以满足各种计算任务的需求。未来,随着云计算和人工智能等技术的火热发展,分布式计算和计算网格技术还将发挥更加重要的作用。
以上就是Java 中的分布式计算和计算网格技术的详细内容,更多请关注php中文网其它相关文章!

Java非堆内存和堆栈内存有什么区别?如果不是,它们是否相同?两者之间有什么区别?
我正在使用Jconsole监视Java应用程序。内存选项卡显示不同的堆和非堆内存,例如
- 堆内存使用情况
- 非堆内存使用
- 内存池“ CMS Old Gen”
- 内存池“ Par Eden Space”
- 内存池“ Par Survivor Space”
- 内存池“代码缓存”
- 内存池“ CMS Perm Gen”
这些术语之间有什么区别。还请提供一些有关-如何通过监视这些参数来发现应用程序行为异常的信息。
关于流式计算和实时计算有什么区别?和流式计算和实时计算有什么区别呢的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于CSharpFlink 实时计算引擎,增加一个窗口或表达式计算任务支持多个算子实例、Hashtable,HashMap,TreeMap有什么区别?Vector,ArrayList,LinkedList有什么区别?int和Integer有什么区别?、Java 中的分布式计算和计算网格技术、Java非堆内存和堆栈内存有什么区别?如果不是,它们是否相同?两者之间有什么区别?等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

