本文将带您了解关于重学计算机组成原理的新内容,同时我们还将为您解释九-动态链接的相关知识,另外,我们还将为您提供关于知乎热议:程序员为啥要学计算机组成原理?、计算机组成原理(二)——计算机的基本组成、
本文将带您了解关于重学计算机组成原理的新内容,同时我们还将为您解释九- 动态链接的相关知识,另外,我们还将为您提供关于知乎热议:程序员为啥要学计算机组成原理?、计算机组成原理(二)——计算机的基本组成、计算机组成原理(上)第 1 章 计算机系统概论、计算机组成原理(上)第3章 测试的实用信息。
本文目录一览:- 重学计算机组成原理(九)- 动态链接(动态链接的原理)
- 知乎热议:程序员为啥要学计算机组成原理?
- 计算机组成原理(二)——计算机的基本组成
- 计算机组成原理(上)第 1 章 计算机系统概论
- 计算机组成原理(上)第3章 测试
- 动态链接(动态链接的原理)")
重学计算机组成原理(九)- 动态链接(动态链接的原理)
把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件
链接的方式,让我们在写代码的时候做到了“复用”。
同样的功能代码只要写一次,然后提供给很多不同的程序进行链接就行了。
“链接”其实有点儿像我们日常生活中的标准化、模块化生产。
有一个可以生产标准螺帽的生产线,就可生产很多不同的螺帽。
只要需要螺帽,都可以通过链接的方式,去复制一个出来,放到需要的地方
但是,如果我们有很多个程序都要通过装载器装载到内存里面,那里面链接好的同样的功能代码,也都需要再装载一遍,再占一遍内存空间。
这就好比,假设每个人都有骑自行车的需要,那我们给每个人都生产一辆自行车带在身边,固然大家都有自行车用了,但是马路上肯定会特别拥挤。
1 链接可以分动、静,共享运行省内存
我们上一节解决程序装载到内存的时候,讲了很多方法。说起来,最根本的问题其实就是内存空间不够用。
如果能够让同样功能的代码,在不同的程序里面,不需要各占一份内存空间,那该有多好啊!
就好比,现在马路上的共享单车,我们并不需要给每个人都造一辆自行车,只要马路上有这些单车,谁需要的时候,直接通过手机扫码,都可以解锁骑行。
这个思路就引入一种新的链接方法,叫作动态链接(Dynamic Link)
相应的,我们之前说的合并代码段的方法,就是静态链接(Static Link)
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)
这个加载到内存中的共享库会被很多个程序的指令调用到。
在Windows下,这些共享库文件就是.dll文件,也就是Dynamic-Link Libary(DLL,动态链接库) 用了“动态链接”的意思
在Linux下,这些共享库文件就是.so文件,也就是Shared Object(一般我们也称之为动态链接库)。用了“共享”的意思
正好覆盖了两方面的含义。
2 地址无关很重要,相对地址解烦恼
要在程序运行的时候共享代码,这些机器码必须“地址无关”
也就是说,我们编译出来的共享库文件的指令代码,是地址无关码(Position-Independent Code)
换句话说就是,这段代码,无论加载在哪个内存地址,都能够正常执行
如果还不明白,我给你举一个生活中的例子 如果我们有一个骑自行车的程序,要“前进500米,左转进入天安门广场,再前进500米”。它在500米之后要到天安门广场了,这就是地址相关的。如果程序是“前进500米,左转,再前进500米”,无论你在哪里都可以骑车走这1000米,没有具体地点的限制,这就是地址无关的。
大部分函数库其实都可以做到地址无关,因为它们都接受特定的输入,进行确定的操作,然后给出返回结果就好了。
无论是实现一个向量加法,还是实现一个打印的函数,这些代码逻辑和输入的数据在内存里面的位置并不重要。
而常见的地址相关的代码,比如绝对地址代码(Absolute Code)、利用重定位表的代码等等,都是地址相关的代码
回想一下我们之前讲过的重定位表。在程序链接的时候,我们就把函数调用后要跳转访问的地址确定下来了,这意味着,如果这个函数加载到一个不同的内存地址,跳转就会失败。
对于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的。
没办法、也不应该要求动态链接同一个共享库的不同程序,必须把这个共享库所使用的虚拟内存地址变成一致。
如果这样的话,我们写的程序就必须明确地知道内部的内存地址分配。
那么问题来了,我们要怎么样才能做到,动态共享库编译出来的代码指令,都是地址无关码呢?
动态代码库内部的变量和函数调用都很容易解决,我们只需要使用相对地址(Relative Address)
各种指令中使用到的内存地址,给出的不是一个绝对的地址空间,而是一个相对于当前指令偏移量的内存地址
因为 整个共享库是放在一段连续的虚拟内存地址中的,无论装载到哪一段地址,不同指令之间的相对地址都是不变的。
3 动态链接的解决方案
PLT和GOT
要实现动态链接共享库,也并不困难,和前面的静态链接里的符号表和重定向表类似
拿出一小段代码来看一看。
lib.h 定义了动态链接库的一个函数 show_me_the_money
lib.c 包含了lib.h的实际实现
show_me_poor.c 调用了 lib 里面的函数
把 lib.c 编译成了一个动态链接库,也就是 .so 文件
最终生成文件集
在编译的过程中,指定了一个 -fPIC 的参数
其实就是Position Independent Code意,也就是要把这个编译成一个地址无关代码
然后,我们再通过gcc编译 show_me_poor 动态链接了 lib.so 的可执行文件
在这些操作都完成了之后,我们把 show_me_poor 这个文件通过objdump出来看一下
我们还是只关心整个可执行文件中的一小部分内容
在main函数调用show_me_the_money的函数的时候,对应的代码是这样的:
这里后面有一个@plt的关键字,代表了我们需要从PLT,也就是程序链接表(Procedure Link Table)里面找要调用的函数。对应的地址呢,则是400580这个地址。
那当我们把目光挪到上面的 400580 这个地址,你又会看到里面进行了一次跳转,
这个跳转指定的跳转地址,你可以在后面的注释里面可以看到:
在动态链接对应的共享库,我们在共享库的data section里面,保存了一张全局偏移表(GOT,Global Offset Table)
虽然共享库的代码部分的物理内存是共享的,但是数据部分是各个动态链接它的应用程序里面各加载一份的。
所有需要引用当前共享库外部的地址的指令,都会查询GOT,来找到当前运行程序的虚拟内存里的对应位置
而GOT表里的数据,则是在我们加载一个个共享库的时候写进去的。
不同的进程,调用同样的 lib.so,各自GOT里面指向最终加载的动态链接库里面的虚拟内存地址是不同的。
这样,虽然不同的程序调用的同样的动态库,各自的内存地址是独立的,调用的又都是同一个动态库,但是不需要去修改动态库里面的代码所使用的地址,
而是各个程序各自维护好自己的GOT,能够找到对应的动态库就好了
GOT表位于共享库自己的数据段里
GOT表在内存里和对应的代码段位置之间的偏移量,始终是确定的
这样,共享库就是地址无关的代码,对应的各个程序只需在物理内存里加载同一份代码
而我们又要通过各个可执行程序在加载时,生成的各不相同的GOT表,找到它需要调用到的外部变量和函数的地址
这是一个典型的、不修改代码,而是通过修改“地址数据”来进行关联的办法
它有点像我们在C语言里面用函数指针来调用对应的函数,并不是通过预先已经确定好的函数名称来调用,而是利用当时它在内存里面的动态地址来调用。
4 总结
终于在静态链接和程序装载后,利用动态链接把我们的内存利用到了极致
同样功能的代码生成的共享库,我们只要在内存里面保留一份就好了
这样
不仅能够做到代码在开发阶段的复用
也能做到代码在运行阶段的复用。
实际上,在进行Linux程序开发,一直会用到各种各样的动态链接库。
C语言的标准库就在1MB以上。
撰写任何一个程序可能都需要用到这个库,常见的Linux服务器里,/usr/bin下面就有上千个可执行文件。
如果每一个都把标准库静态链接进来的,几GB乃至几十GB的磁盘空间一下子就用出去了。如果我们服务端的多进程应用要开上千个进程,几GB的内存空间也会一下子就用出去了。这个问题在过去计算机的内存较少的时候更加显著。
通过动态链接这个方式,可以说彻底解决了这个问题。
就像共享单车一样,如果仔细经营,是一个很有社会价值的事情,但是如果粗暴地把它变成无限制地复制生产,给每个人造一辆,只会在系统内制造大量无用的垃圾。
已经把程序怎么从源代码变成指令、数据,并装载到内存里面,由CPU一条条执行下去的过程讲完了。希望你能有所收获,对于一个程序是怎么跑起来的,有了一个初步的认识。
5 推荐阅读
想要更加深入地了解动态链接,推荐你可以读一读《程序员的自我修养:链接、装载和库》的第7章
里面深入地讲解了,动态链接里程序内的数据布局和对应数据的加载关系。
参考
深入浅出计算机组成原理

本文分享自微信公众号 - JavaEdge(Java-Edge)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

知乎热议:程序员为啥要学计算机组成原理?
最近逛知乎,看到一个很有意思的帖子。我想这可能是很多人的心声。
下面的观点也挺鲜明的:这是科班与培训班的区别。
只能说,太真实了。我上学的时候,就没学好组成原理。后来到工作中就发现,增删改查还可以,遇到点底层问题就懵逼,而那些基本功好的科班生,学新东西都很快,升职加薪更是轻轻松松。
我想,这也是一个人能否去大厂的一个区别。毕竟大厂都很看重基本功,尤其想做一名优秀的工程师,如果都不了解计算机是怎么工作的,程序在计算机中怎么运作的,那怎么行得通呢?
像我经常会收到一些粉丝的反馈:说升小领导接触更多项目后,感觉自己底层原理很弱,在编程的时候总有空中楼阁的感觉;有的说工作多年,竟然看不懂科班出身同事实现的数据序列化协议,太尴尬了;还有人日常搬运代码,遇到些网络或者数据库里的乱码、强制类型转换等等大坑,就懵逼了。
说白了,就是基本功出了问题。这也是为什么,很多人在工作两年后,反而回去补组成原理这些专业课知识。
而且,计算机领域的学科渗透和交叉很厉害,学点底层的东西,有一门精通,你找工作就很占优势。
作为计算机入门和底层知识的第一课,组成原理其重要程度,就和数据结构与算法一样,都是程序员必修的“硬核内功”。
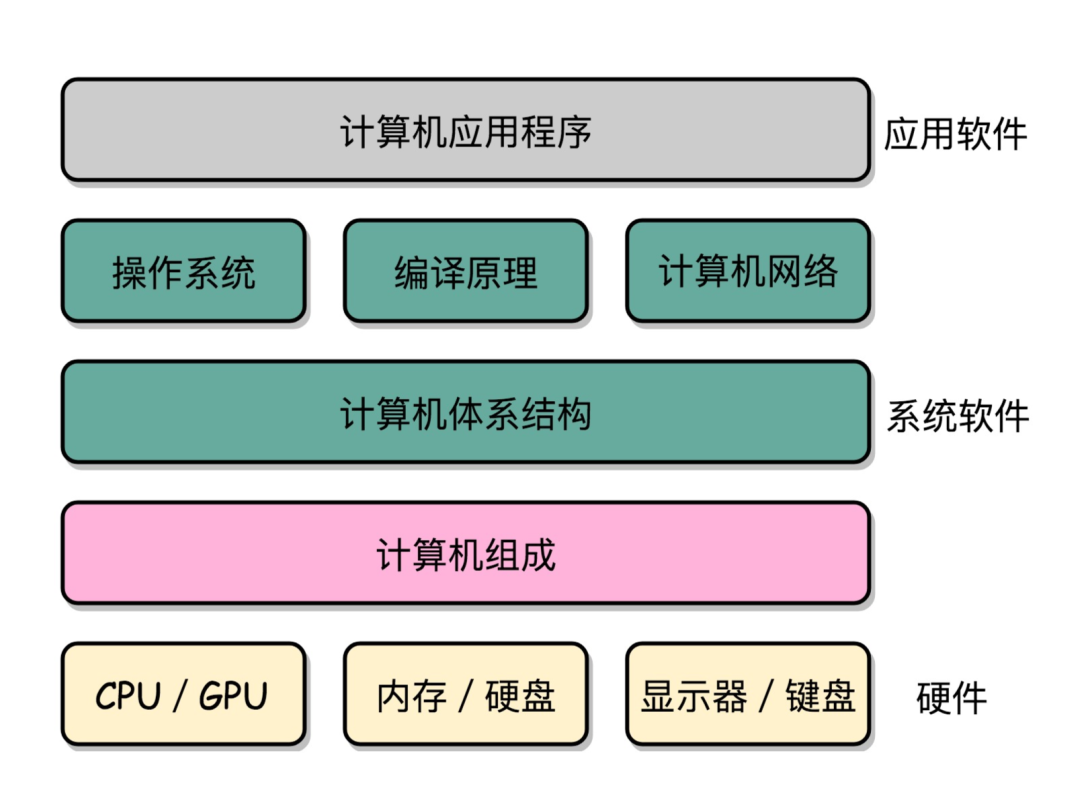
要知道,它可以直接解决你在并发编程、性能优化中经常遇到的一些困惑,比如 CPU Cache 的原理是什么,CPU 和 I/O 之间是如何通信的,虚拟内存是要解决什么问题。可以说,你基本可以掌握计算机的全貌了。
我曾经下苦功,想好好啃啃组成原理,但概念多,太抽象,难理解,不好学以致用。资料我也看过不少,说句不好意思的,我大部分买来的书,都是前面 10 页已经发黄了,后面 500 页从来没有打开过。
只啃原理不行的,还是要与实际代码工作相结合,在这我分享一份,之前收藏的学习资料 —— 「组成原理全景图」,把零散的概念系统地整理在一起,建议收藏:
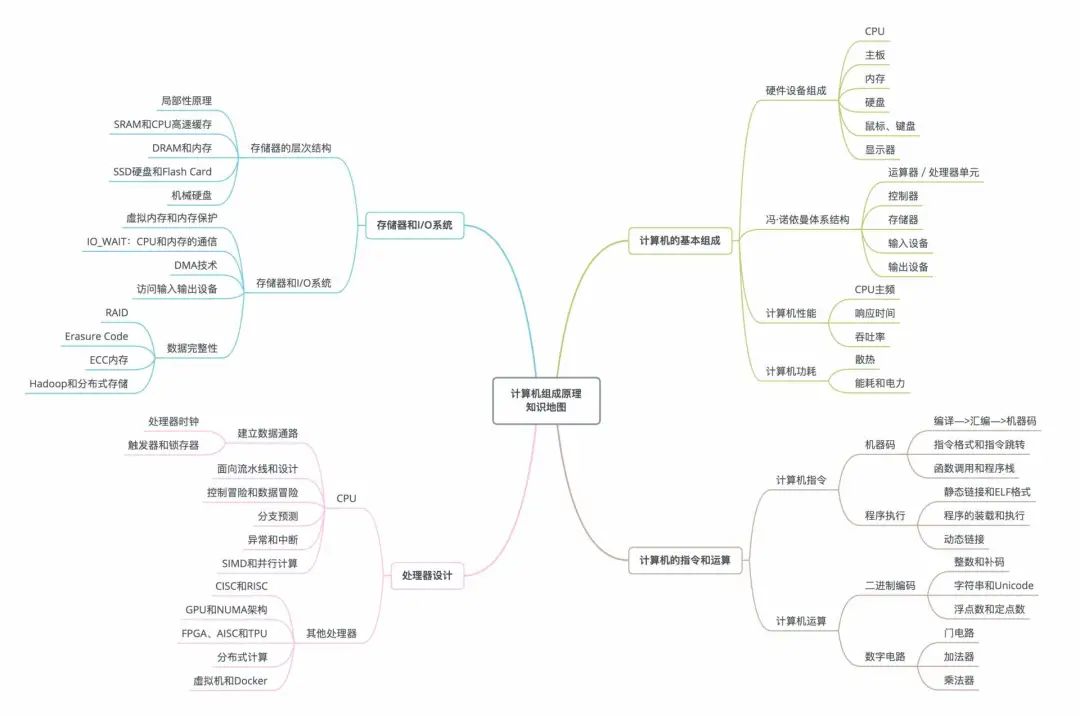
这张思维导图,出自徐文浩的专栏《深入浅出计算机组成原理》,这课可以说是我在极客时间学习,收获最大的课之一了,他用工作实际场景 + 软件开发案例,讲了 30+ 组成原理的核心知识,教你真正看懂、学会、记住,从源头理解软、硬件的共同之处,洞悉性能问题的本质。
除了理论讲的透彻,最重要的,还结合工业界的应用,要知道徐文浩老师在创业,随手就是各种实践案例,简直是一个宝藏老师,宝藏课程,口碑那么好,群众的眼睛是雪亮的,我目前 2 刷完毕,真是常看常新,时时有收获。
这个专栏已经快将近 2W 订阅了。今晚这个专栏要涨价到 ¥129 了,现在到手只需要 ¥69 。感兴趣的小伙伴可以先扫码免费试读。
我来介绍下徐文浩, BotHub.AI 创始人,从 7 岁开始接触代码,近 30 年的码龄。写过各种大型企业软件,从零开始搭建支撑每天百亿流量的广告算法系统,提升了十倍以上的广告收入和 ROI,工业界的牛人了。
现在专栏已经更新完毕,一共 62 讲。跟着读下来,最大的感触是,这个老师太会讲了,要知道越是底层的东西,越不好讲透,能把这么枯燥无聊的原理,讲得明明白白,讲述中还充满了魔力,又吸引着我去深挖下去。
比如,特色之一:图文并茂,配合给大家讲解复杂问题,简洁又清晰。
一图胜千言,理论看不懂,拆开了揉碎了,总能明白吧。
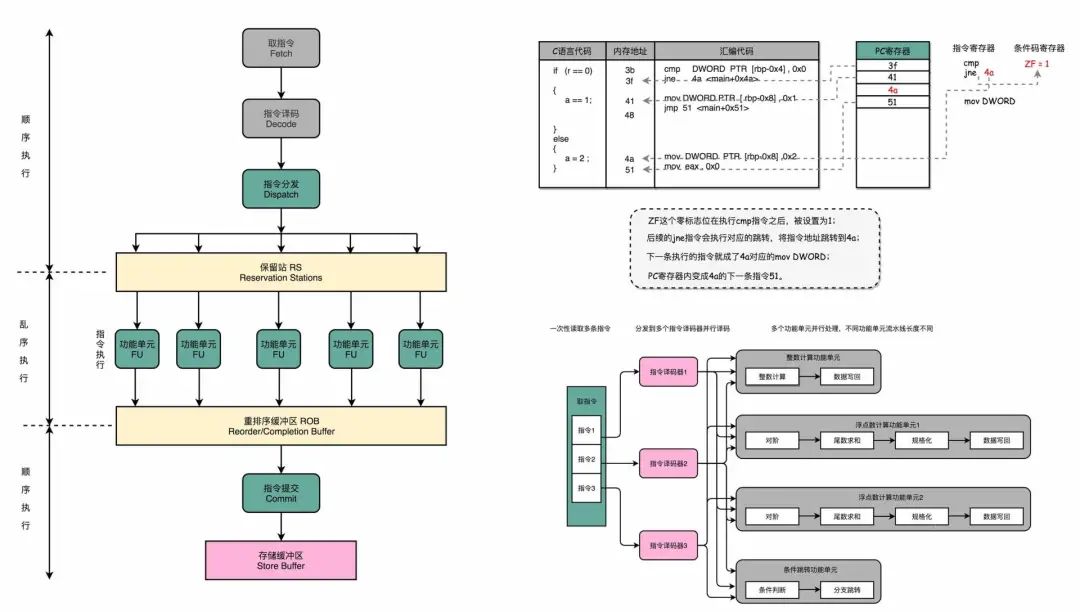
比如,专栏特色之二:每个章节都会留个符合内容的思考题,徐文浩老师经常在评论里解答,这种耐心、负责的分享精神,真的很难得了。
我的建议,光读文章可不够,还得多看看下面的思考题,更精彩,而且往往能有新的启发。

关于组成原理对程序员的作用,我再来引用一下 Rust 大神张汉东在知乎上的回答:

大家都知道,计算机考研统考有 4 门核心基础课程:数据结构与算法、操作系统,计算机网络,以及组成原理,等你做了多年研发以后,会发现,原来这么多年就是围绕这 4 门课程打转。
关于基本功的重要性,我觉得怎么强调都不过分,记得《倚天屠龙记》里,张无忌几个时辰,就把别人几十年没有练成的乾坤大挪移学会了,最根本的原因,是他有“九阳神功”练就的内功底子。
同样的,深入学习这门“底层知识”,就是在练扎马步、核心肌肉力量,提升你自己的“根骨”和“资质”,从而拔高你发展的上限。
下面是专栏的目录,看着感觉很不错,理论和实践相结合。
都说大学玩游戏,工作来补课,出来混迟早要还的。
所以还是那句话:种一棵树最好的时间是十年前,其次是现在,抓住机会。
我同样也给大家争取到了福利优惠
原价 ¥99,秒杀 ¥79
叠加优惠口令「yuanli666」
到手 ¥69,相当于半价了
今晚 24:00 涨到 ¥129 啦
扫码查看详情
点击「阅读全文」,2 杯奶茶的价格,补补基本功。今晚24:00就涨价了。
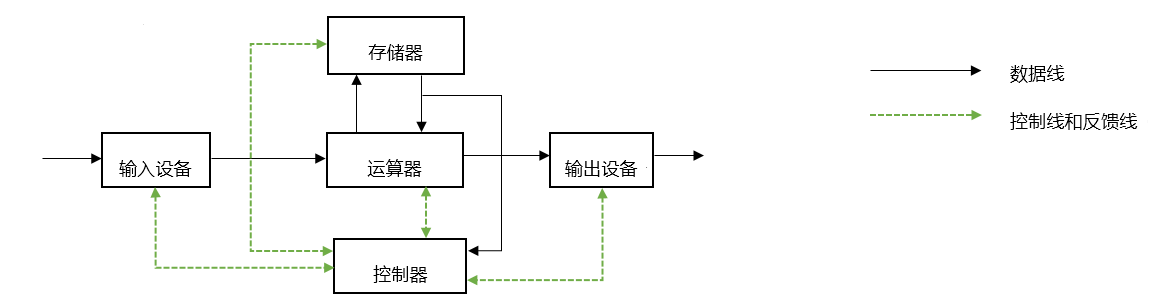
——计算机的基本组成")
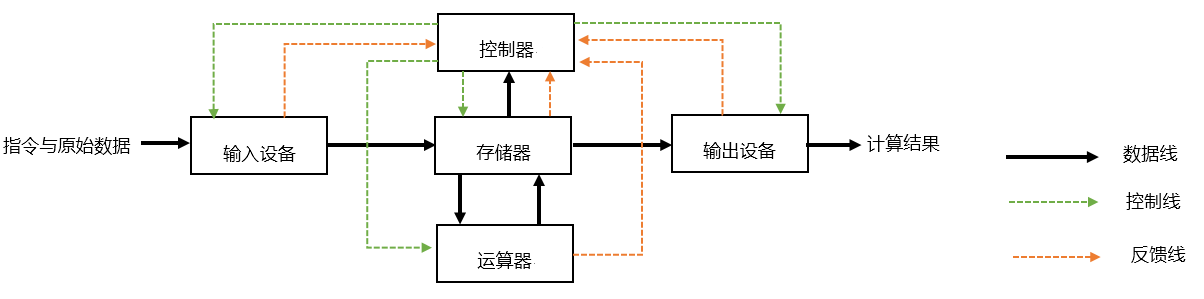



第 1 章 计算机系统概论")

第3章 测试")