对于基于案例讲解Storm实时流计算感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解storm流计算,并且为您提供关于DStream实时流数据处理、Golang中使用缓存提高大数据实时流计算
对于基于案例讲解Storm实时流计算感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解storm 流计算,并且为您提供关于DStream实时流数据处理、Golang中使用缓存提高大数据实时流计算的实践。、Java之String.format()方法案例讲解、JStorm-Alibaba —— Storm 的实时流式计算框架的宝贵知识。
本文目录一览:- 基于案例讲解Storm实时流计算(storm 流计算)
- DStream实时流数据处理
- Golang中使用缓存提高大数据实时流计算的实践。
- Java之String.format()方法案例讲解
- JStorm-Alibaba —— Storm 的实时流式计算框架
")
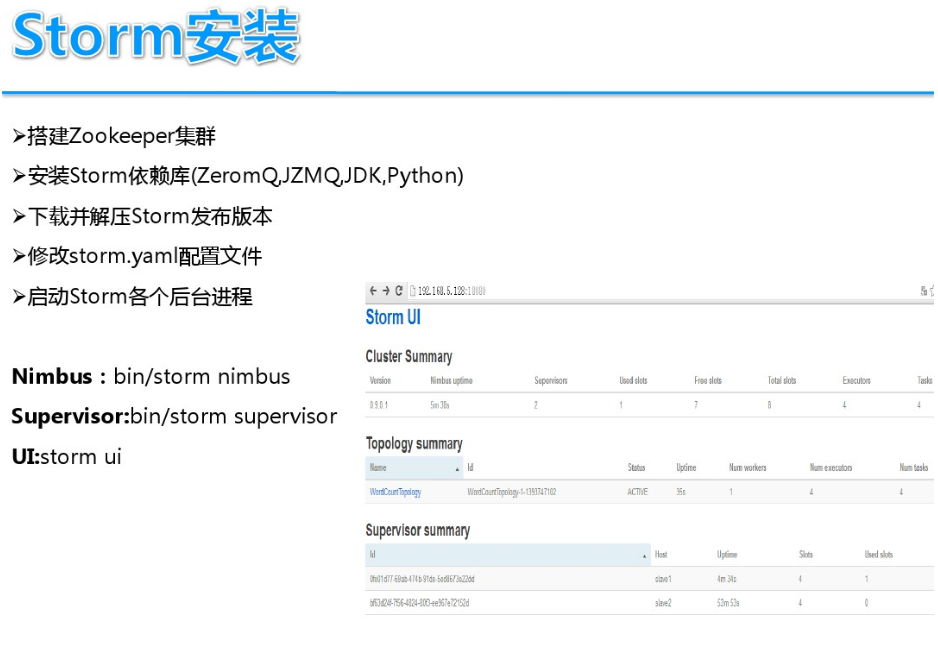
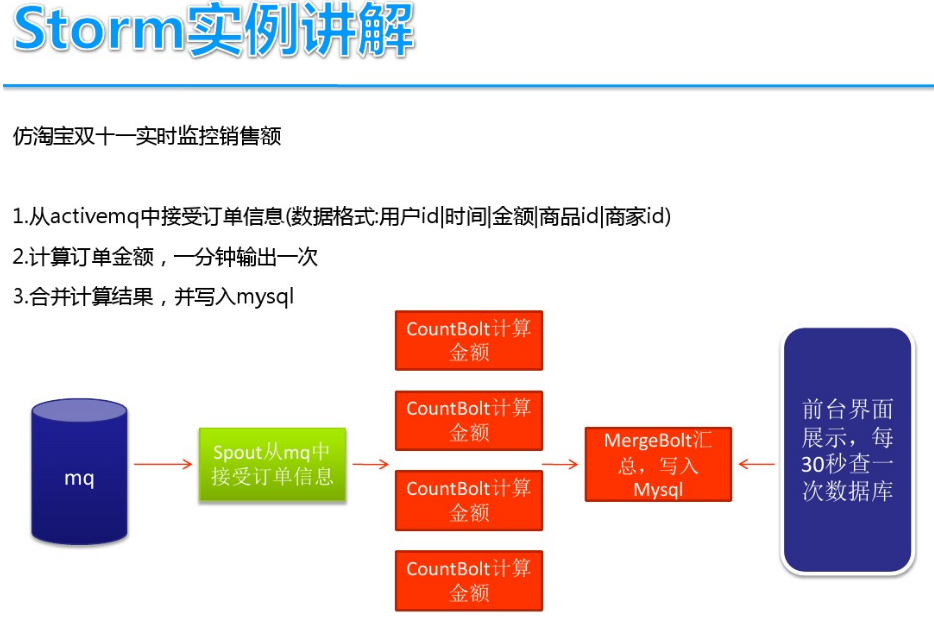
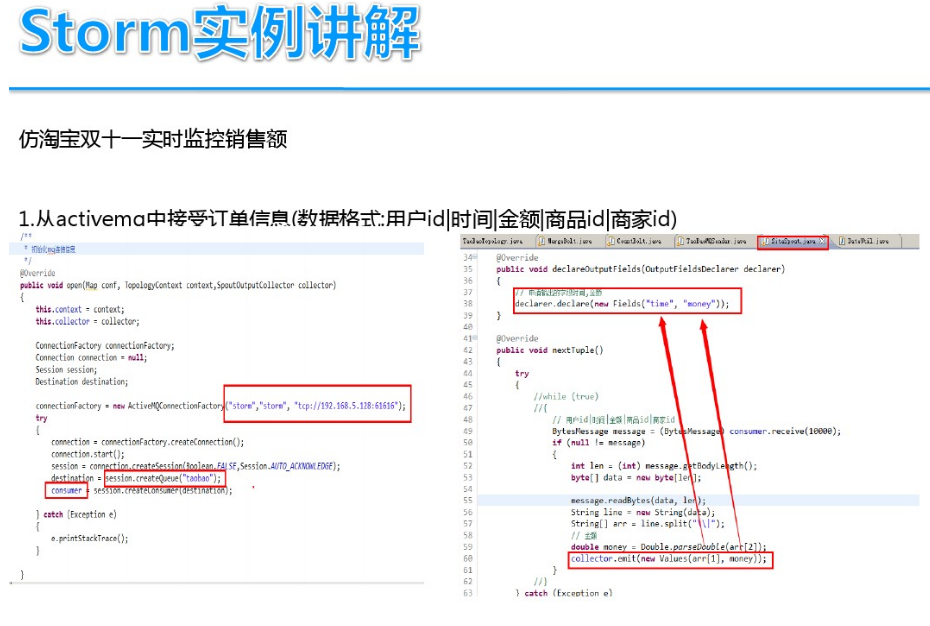
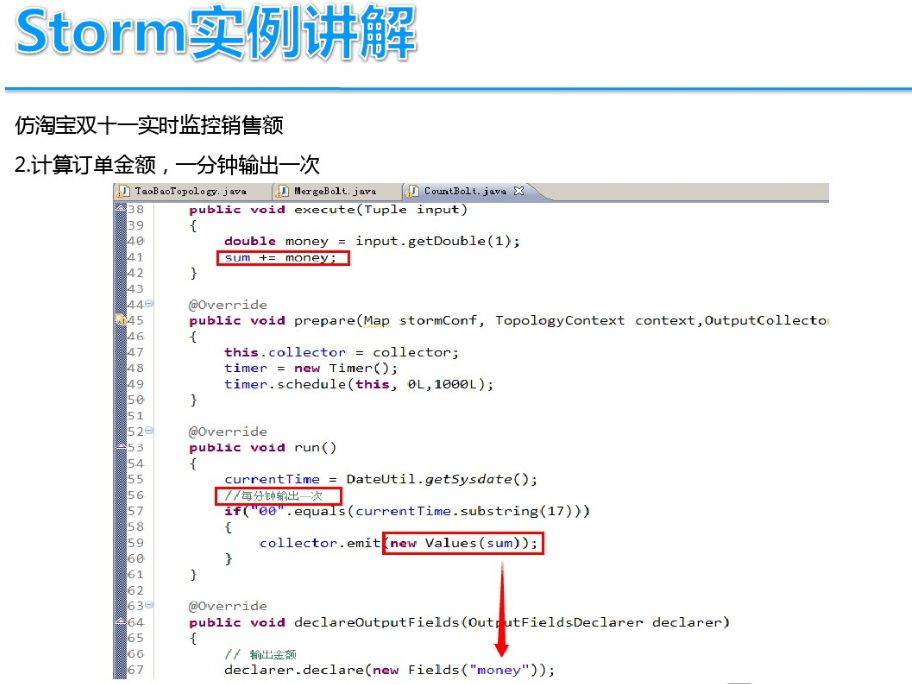
基于案例讲解Storm实时流计算(storm 流计算)
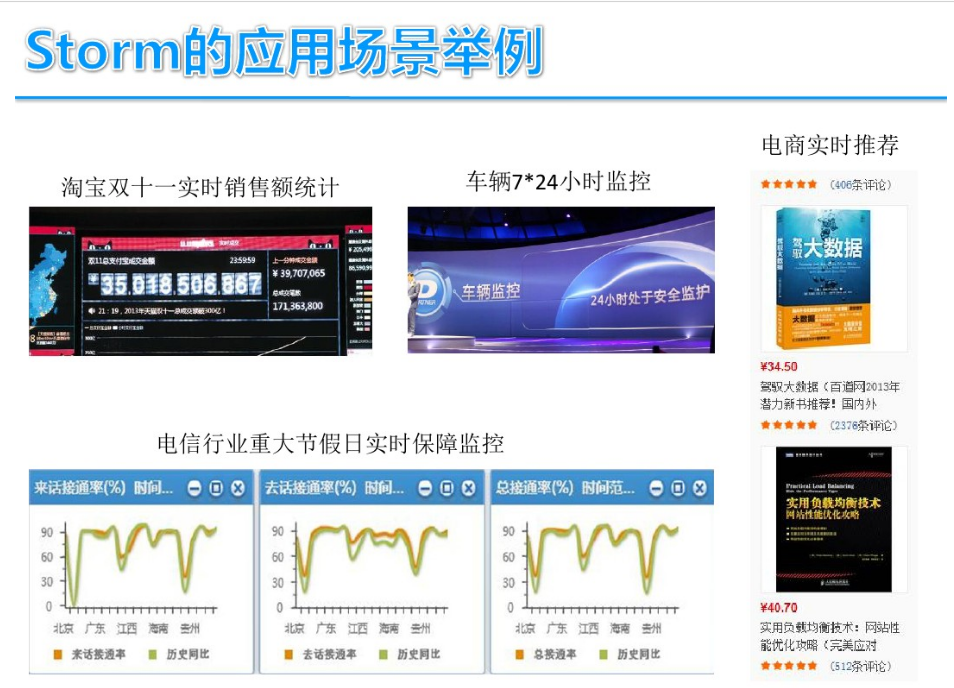



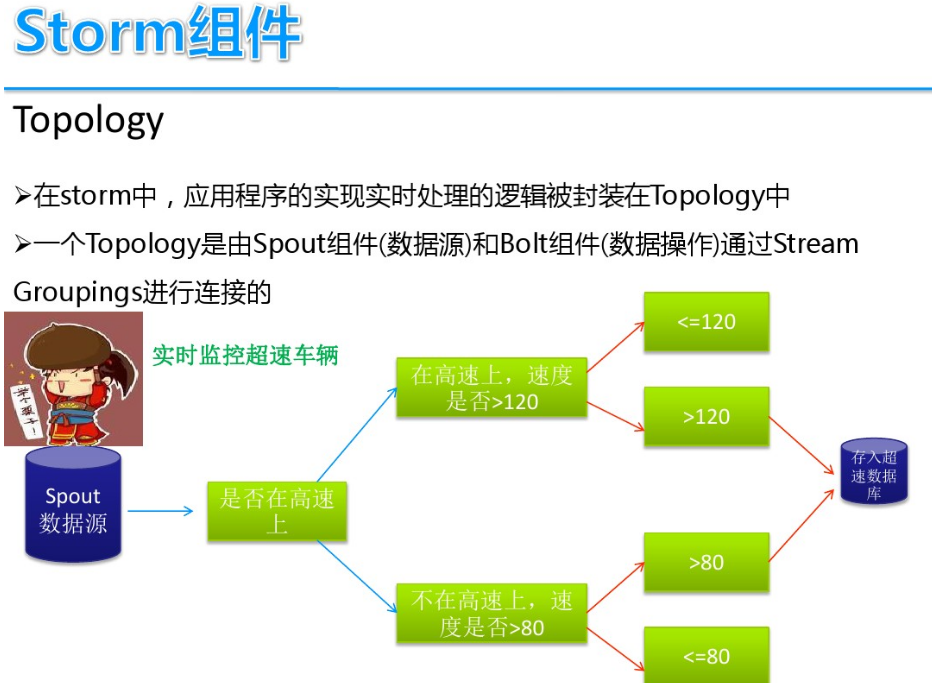


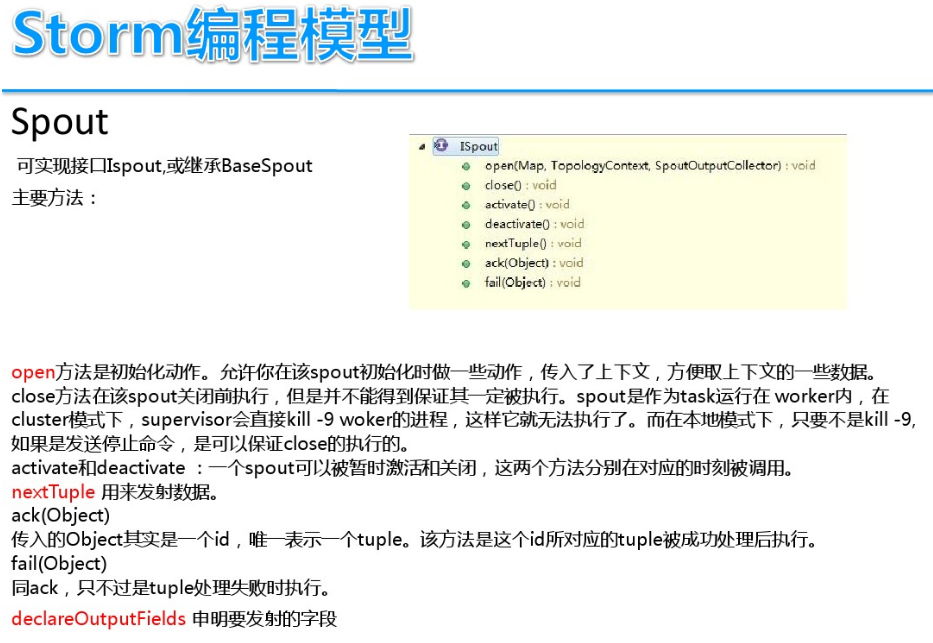
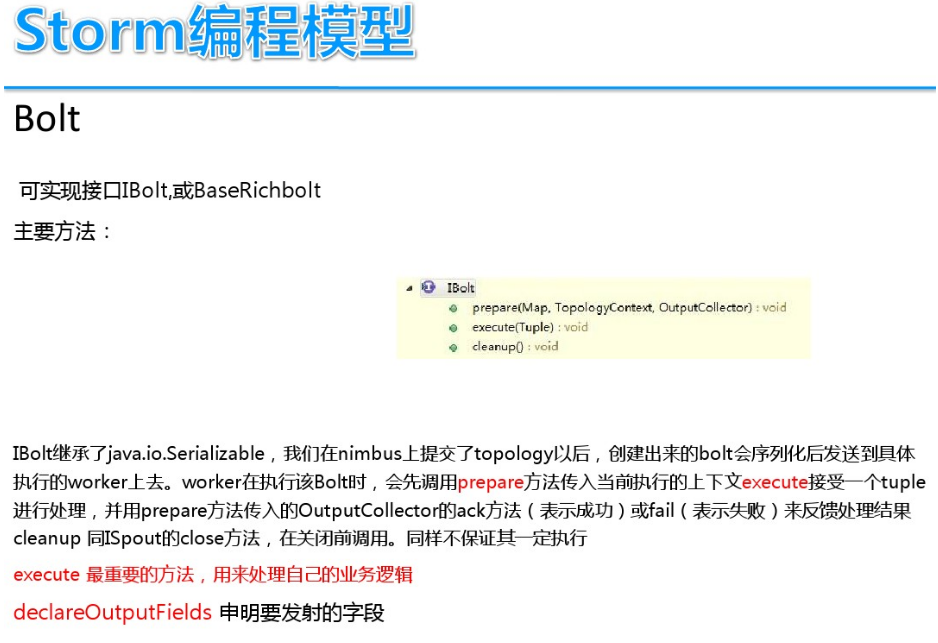
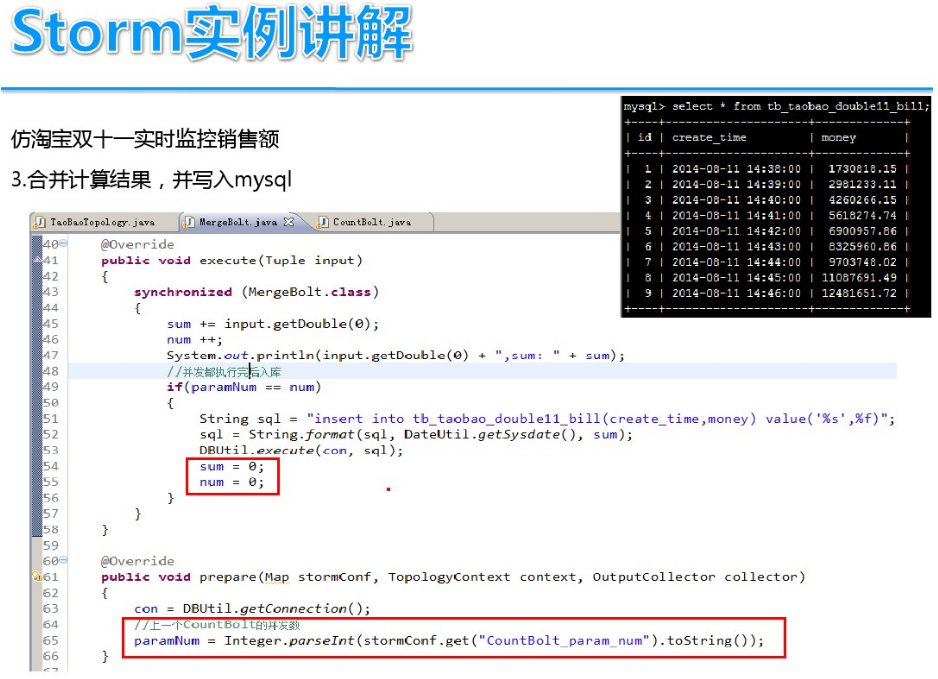

DStream实时流数据处理

更多精彩内容请关注:http://bbs.superwu.cn
关注超人学院微信二维码:@H_301_146@

Golang中使用缓存提高大数据实时流计算的实践。
随着大数据时代的到来,数据的实时处理变得越来越重要。在实时流计算中,性能是一个关键因素。而对于
在本文中,我们将探讨如何在Golang中使用缓存来提高大数据实时流计算的性能。我们将先介绍什么是缓存及其优势,然后介绍如何在Golang中实现缓存,并结合实例说明如何在大数据实时流计算中使用缓存。
什么是缓存及其优势
缓存是数据存储的一种技术,用于提高数据的访问速度。缓存通常使用高速的存储设备来存储最近或最频繁使用的数据,以避免重复计算或IO操作。使用缓存的主要优点是提高了程序的性能和响应速度。
在实时流计算中,需要对大量数据进行分析和计算。将数据存储在缓存中可以大大提高程序的性能和响应速度。在缓存中,可以将经常使用的数据存储在高速的内存中,从而避免了每次访问都需要从磁盘或网络中获取数据的开销。同时,使用缓存还可以减轻网络和IO负担,从而提高整个系统的性能和响应速度。
立即学习“go语言免费学习笔记(深入)”;
使用缓存的主要风险是缓存数据的不一致性。因为缓存中的数据可能会被修改或删除,这会导致缓存不一致。为了避免这种情况,开发人员需要使用一些技术和策略来确保缓存数据的一致性。
在Golang中实现缓存
在Golang中,可以使用标准库中的内置缓存机制来实现缓存。标准库提供了两种常见的缓存实现方式:map和sync.Pool。
map是一种无序的键值对集合,可以通过键来访问值。在Golang中,可以使用map来实现缓存。使用map可以快速存储和检索数据,同时也可以方便地访问数据。下面是一个使用map实现缓存的示例代码:
package main
import (
"fmt"
"sync"
"time"
)
var cache = make(map[string]string)
var mu sync.Mutex
func main() {
go dataReader()
go dataReader()
time.Sleep(2 * time.Second)
}
func dataReader() {
for {
getData("key")
time.Sleep(100 * time.Millisecond)
}
}
func getData(key string) string {
mu.Lock()
defer mu.Unlock()
if val, ok := cache[key]; ok {
fmt.Println("Cached: ", val)
return val
}
time.Sleep(500 * time.Millisecond)
data := "Data " + time.Now().Format(time.StampMilli)
fmt.Println("Loaded: ", data)
cache[key] = data
return data
}在这个例子中,我们使用map实现了一个简单的缓存功能。我们使用sync.Mutex来保护map的读写,并在getData方法中判断数据是否已经缓存在map中。如果存在,则直接从map中获取数据;如果不存在,则从数据源中读取数据。获取数据后,我们将其存储在map中,以便下一次访问时能够快速获取。
另一种常见的缓存实现方式是sync.Pool。Pool是一个对象池,可以用于存储和重用临时对象,以避免频繁地创建和销毁对象。使用Pool可以提高程序的性能和响应速度。下面是一个使用sync.Pool实现缓存的示例代码:
package main
import (
"bytes"
"fmt"
"sync"
)
var bufPool = sync.Pool{
New: func() interface{} {
return bytes.NewBuffer([]byte{})
},
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
b := bufPool.Get().(*bytes.Buffer)
defer bufPool.Put(b)
b.WriteString("Hello World!")
fmt.Println(b.String())
}()
}
wg.Wait()
}在这个例子中,我们使用sync.Pool来实现一个缓存池,用于存储和重用临时的字节缓冲区。我们定义了一个函数来创建新的字节缓冲区,并使用Put和Get方法来存储和获取字节缓冲区。在使用字节缓冲区之后,我们将其放回到缓存池中以便下次使用。
使用缓存来提高大数据实时流计算性能的实例
在实际的应用中,使用缓存来提高大数据实时流计算的性能是非常常见的。下面是一个使用缓存来提高大数据实时流计算性能的示例代码:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Data struct {
Key string
Value int
Time time.Time
}
var cache = make(map[string]*Data)
var mu sync.Mutex
func main() {
go producer()
go consumer()
time.Sleep(10 * time.Second)
}
func producer() {
for {
key := randString(10)
value := rand.Intn(100)
data := &Data{Key: key, Value: value, Time: time.Now()}
mu.Lock()
cache[key] = data
mu.Unlock()
time.Sleep(500 * time.Millisecond)
}
}
func consumer() {
for {
mu.Lock()
for key, data := range cache {
if time.Since(data.Time) >= 2*time.Second {
delete(cache, key)
} else {
fmt.Println(data.Key, data.Value)
}
}
mu.Unlock()
time.Sleep(100 * time.Millisecond)
}
}
func randString(length int) string {
const charset = "abcdefghijklmnopqrstuvwxyz0123456789"
b := make([]byte, length)
for i := range b {
b[i] = charset[rand.Intn(len(charset))]
}
return string(b)
}在这个例子中,我们使用map来实现缓存,并通过加锁(mutex)来保护map的并发读写。我们使用producer函数每隔500ms生成一个长度为10的随机字符串作为键,随机生成一个0~100之间的值,以及当前时间作为值。我们将生成的数据存储在map中。在consumer函数中,我们每隔100ms遍历map中的数据,并检查它们的时间戳,如果数据的时间戳已经超过2s,则从map中删除。否则,我们输出数据的键和值。
使用缓存可以显著提高程序的性能和响应速度。在上面的示例中,我们可以看到程序不断地产生数据并写入缓存,同时另一个线程不断地从缓存中读取数据。如果没有使用缓存,程序的性能和响应速度将受到很大影响。
结论
在本文中,我们介绍了什么是缓存及其优势。我们还介绍了如何在Golang中使用标准库实现缓存,并通过一个实例说明了如何在大数据实时流计算中使用缓存。使用缓存可以大大提高程序的性能和响应速度,减轻网络和IO负担。在实际的应用中,我们应该考虑使用缓存来优化程序的性能和响应速度。
以上就是Golang中使用缓存提高大数据实时流计算的实践。的详细内容,更多请关注php中文网其它相关文章!
方法案例讲解")
Java之String.format()方法案例讲解
这篇文章主要介绍了Java之String.format()方法案例讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下
前言:
String.format()作为文本处理工具,为我们提供强大而丰富的字符串格式化功能,这里根据查阅的资料做个学习笔记,整理成如下文章,供后续复习查阅。
一. format()方法的两种重载形式:
1. format(String format, Object ... args)
该方法使用指定的格式字符串和参数返回一个格式化的字符串,格式化后的新字符串使用本地默认的语言环境。
2. format(Local l, String format, Pbject ... args)
其中,参数l为格式化过程中要应用的语言环境。如果l为null,则不进行本地化。
二. 占位符:
1.对整数进行格式化:%[index$][标识][最小宽度]转换方式
格式化字符串由4部分组成,特殊的格式常以%index$开头,index从1开始取值,表示将第index个参数拿进来进行格式化,[最小宽度]的含义也很好理解,就是最终该整数转化的字符串最少包含多少位数字。剩下2个部分的含义:
标识:
'-' 在最小宽度内左对齐,不可以与"用0填充"同时使用
'#' 只适用于8进制和16进制,8进制时在结果前面增加一个0,16进制时在结果前面增加0x
'+' 结果总是包括一个符号(一般情况下只适用于10进制,若对象为BigInteger才可以用于8进制和16进制)
' ' 正值前加空格,负值前加负号(一般情况下只适用于10进制,若对象为BigInteger才可以用于8进制和16进制)
'0' 结果将用零来填充
',' 只适用于10进制,每3位数字之间用","分隔
'(' 若参数是负数,则结果中不添加负号而是用圆括号把数字括起来(同'+'具有同样的限制)
转换方式:
d-十进制 o-八进制 x或X-十六进制
举个例子,如下:
System.out.println(String.format("%1$-9d", 312356)); System.out.println(String.format("%1$#9x", 312356)); System.out.println(String.format("%1$-#9o", 312356)); System.out.println(String.format("%1$+9d", 312356)); System.out.println(String.format("%1$ 9d", 312356)); System.out.println(String.format("%1$ 9d", -312356)); System.out.println(String.format("%1$09d", 312356)); System.out.println(String.format("%1$,9d", 312356)); System.out.println(String.format("%1$(9d", 312356));
输出结果:
312356 0x4c424 01142044 +312356 312356 -312356 000312356 312,356 312356
2.对浮点数进行格式化:%[index$][标识][最少宽度][.精度]转换方式
我们可以看到,浮点数的转换多了一个"精度"选项,可以控制小数点后面的位数。
标识:
'-' 在最小宽度内左对齐,不可以与"用0填充"同时使用
'+' 结果总是包括一个符号
' ' 正值前加空格,负值前加负号
'0' 结果将用零来填充
',' 每3位数字之间用","分隔(只适用于fgG的转换)
'(' 若参数是负数,则结果中不添加负号而是用圆括号把数字括起来(只适用于eEfgG的转换)
转换方式:
'e', 'E' -- 结果被格式化为用计算机科学记数法表示的十进制数
'f' -- 结果被格式化为十进制普通表示方式
'g', 'G' -- 根据具体情况,自动选择用普通表示方式还是科学计数法方式
'a', 'A' -- 结果被格式化为带有效位数和指数的十六进制浮点数
System.out.println(String.format("%1$-9.2f", 3123.32)); System.out.println(String.format("%1$+9.2f", 3123.32)); System.out.println(String.format("%1$ 9.2f", -3123.32)); System.out.println(String.format("%1$ 9.2f", 3123.32)); System.out.println(String.format("%1$09.2f", 3123.32)); System.out.println(String.format("%1$,9.2f", 3123.32)); System.out.println(String.format("%1$(9.2f", -3123.32)); System.out.println(String.format("%1$9.2e", -3123.32)); System.out.println(String.format("%1$9.2f", -3123.32)); System.out.println(String.format("%1$9.2g", -3123.32)); System.out.println(String.format("%1$9.2a", -3123.32));
输出结果:
3123.32 +3123.32 -3123.32 3123.32 003123.32 3,123.32 (3123.32) -3.12e+03 -3123.32 -3.1e+03 -0x1.86p11
3.对字符进行格式化:
对字符进行格式化是非常简单的,c表示字符,标识中'-'表示左对齐,其他就没什么了。
三. 对日期进行格式化:
常用的日期格式转换符如下表所示:
转换符
说明
示例
%te
一个月中的某一天(1~31)
2
%tb
指定语言环境的月份简称
Feb(英文)、二月(中文)
%tB
指定语言环境的月份全称
February(英文)、二月(中文)
%tA
指定语言环境的星期几全称
Monday(英文)、星期一(中文)
%ta
指定语言环境的星期几简称
Mon(英文)、星期一(中文)
%tc
包括全部日期和时间信息
星期二 三月 25 13:37:22 CST 2008
%tY
4位年份
2019
%tj
一年中的第几天(001~366)
085
%tm
月份
03
%td
一个月中的第几天(01~31)
02
%ty
2位年份
19
举个例子,如下:
public class Eval { public static void main(String[] args) { Date date = new Date(); String day = String.format("%te", date); System.out.println("今天是2019年8月:" + day + "号"); String month = String.format("%tb", date); System.out.println("现在是2019年:" + month); String xingqi = String.format("%tA", date); System.out.println("今天是:" + xingqi); String year = String.format("%tY", date); System.out.println("现在是:" + year + "年"); } }
输出结果:
1 今天是2019年8月:20号
2 现在是2019年:八月
3 今天是:星期二
4 现在是:2019年
常用的时间格式转换符如下表所示:
转换符
说明
示例
%tH
2位数字的24时制的小时(00~23)
14
%tI
2位数字的12时制的小时(01~12)
05
%tk
2位数字的24时制的小时(0~23)
5
%tl
2位数字的12时制的小时(1~12)
10
%tM
2位数字的分钟(00~59)
05
%tS
2位数字的秒数(00~60)
12
%tL
3位数字的毫秒数(000~999)
920
%tN
9位数字的微秒数(000000000~999999999)
062000000
%tp
指定语言环境下上午或下午标记
下午(中文)、pm(英文)
%tz
相对于GMT RFC 82格式的数字时区偏移量
+0800
%tZ
时区缩写形式的字符串
CST
%ts
1970-01-01 00:00:00至现在经过的秒数
1206345534
%tQ
1970-01-01 00:00:00至现在经过的毫秒数
12923409349034
举个例子,如下:
public class GetDate { public static void main(String[] args) { Date date = new Date(); String hour = String.format("%tH", date); String minute = String.format("%tM", date); String second = String.format("%tS", date); System.out.println("现在是:" + hour + "点" + minute + "分" + second + "秒"); System.out.println("##################################"); String hour2 = String.format("%tI", date); String pm = String.format("%tp", date); System.out.println("现在是:" + pm + hour2 + "点" + minute + "分" + second + "秒"); } }
输出结果:
1 现在是:15点06分37秒
2 ##################################
3 现在是:下午03点06分37秒
常见的日期和时间组合的格式如下表所示:
转换符
说明
示例
%tF
“年-月-日”格式(4位年份)
2019-08-20
%tD
“年/月/日”格式(2位年份)
08/20/19
%tc
全部日期和时间信息
星期二 三月 25 15:20:00 CST 2019
%tr
“时:分:秒 PM(AM)”格式(12时制)
03:22:06 下午
%tT
“时:分:秒”格式(24时制)
15:23:50
%tR
“时:分”格式(24时制)
15:25
举个例子,如下:
public class DateAndTime { public static void main(String[] args) { Date date = new Date(); String time = String.format("%tc", date); String form = String.format("%tF", date); String form2 = String.format("%tD", date); String form3 = String.format("%tr", date); String form4 = String.format("%tT", date); String form5 = String.format("%tR", date); System.out.println("全部的时间信息是:" + time); System.out.println("年-月-日格式:" + form); System.out.println("年/月/日格式:" + form2); System.out.println("时:分:秒 PM(AM)格式:" + form3); System.out.println("时:分:秒格式:" + form4); System.out.println("时:分格式:" + form5); } }
输出结果:
全部的时间信息是:星期二 八月 20 15:14:20 CST 2019 年-月-日格式:2019-08-20 年/月/日格式:08/20/19 时:分:秒 PM(AM)格式:03:14:20 下午 时:分:秒格式:15:14:20 时:分格式:15:14
结尾:
以上内容为format()方法的一些常用功能,也是本人在工作场景中经常用到的。整理归纳方便后续学习查阅,如果后面还有遇到相关方法的其他用法,后期再对该篇文章进行补充。

JStorm-Alibaba —— Storm 的实时流式计算框架
JStorm是参考storm的实时流式计算框架,在网络IO、线程模型、资源调度、可用性及稳定性上做了持续改进,已被越来越多企业使用。经过4年发展,阿里巴巴JStorm集群已经成为世界上最大的集群之一,基于JStorm的应用数量超过1000个。数据显示,JStorm集群每天处理的消息数量达到1.5PB。 在2015年,JStorm正式成为Apache Storm里的子项目。JStorm将在 Apache Storm里孵化,孵化成功后会成为Apache Storm主干。
关于基于案例讲解Storm实时流计算和storm 流计算的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于DStream实时流数据处理、Golang中使用缓存提高大数据实时流计算的实践。、Java之String.format()方法案例讲解、JStorm-Alibaba —— Storm 的实时流式计算框架的相关知识,请在本站寻找。
本文标签:




