本文将分享sqler集成terraformv0.12生成资源部署文件的详细内容,并且还将对sqlserver集成环境进行详尽解释,此外,我们还将为大家带来关于AWSTerraform-在资源上使用动态
本文将分享sqler 集成 terraform v0.12 生成资源部署文件的详细内容,并且还将对sql server集成环境进行详尽解释,此外,我们还将为大家带来关于AWS Terraform - 在资源上使用动态块、IaC云资源编排-Terraform、py-libterraform 的使用和实现:一个 Terraform 的 Python 绑定、Terraform (2) 资源与变量的相关知识,希望对你有所帮助。
本文目录一览:- sqler 集成 terraform v0.12 生成资源部署文件(sql server集成环境)
- AWS Terraform - 在资源上使用动态块
- IaC云资源编排-Terraform
- py-libterraform 的使用和实现:一个 Terraform 的 Python 绑定
- Terraform (2) 资源与变量
")
sqler 集成 terraform v0.12 生成资源部署文件(sql server集成环境)
terraform v0.12 发布了,有好多新功能的添加,包括语法的增强,新函数的引入,更好的开发提示
只是当前对于一些老版本的 provider 暂时还不兼容,但是大部分官方的 provider 都是可以使用的
这片文章只是一个简单的 demo,使用 sqler 提供 rest api,集合 tf 0.12 的新功能,使用模版函数以及 json 解码函数
实现一个部署资源的动态生成
环境准备
tf 使用本地软件,sqler 以及数据库使用 docker-compose 运行
- 软件下载
tf 下载 https://www.terraform.io/downloads.html- 项目结构
├── main.tf├── restapi│ ├── config│ │ └── config-example.hcl│ ├── docker-compose.yaml│ └── user-app.sql├── terraform.tfstate├── tf-result└── user_apps.tmpl- sqler 环境
docker-compose 文件
version: "3"services: sqler: image: dalongrong/sqler:2.0 volumes: - "./config/config-example.hcl:/app/config.example.hcl" environment: - "DRIVER=postgres" - "DSN=postgresql://postgres:dalong@postgres:5432/postgres?sslmode=disable" ports: - "3678:3678" - "8025:8025" postgres: image: postgres:9.6.11 ports: - "5432:5432" environment: - "POSTGRES_PASSWORD:dalong"代码说明
- sqler 数据库查询 dsl
config/config-example.hcl
apps { exec = <<SQL select * from apps SQL}users { exec = <<SQL select * from users; SQL}user_apps { aggregate = ["users","apps"]}- pg sql
几个测试的数据表
CREATE TABLE apps ( id SERIAL PRIMARY KEY, appname text, appversion text, content text);CREATE TABLE users ( id SERIAL PRIMARY KEY, username text, age integer, content text);INSERT INTO "public"."apps"("appname", "appversion", "content") VALUES(''login'', ''v1.0'', ''login'') RETURNING "id", "appname", "appversion", "content";INSERT INTO "public"."apps"("appname", "appversion") VALUES(''logo'', ''v2.0'') RETURNING "id", "appname", "appversion", "content";INSERT INTO "public"."users"("username", "age", "content") VALUES(''dalong'', 22, ''demo'') RETURNING "id", "username", "age", "content";INSERT INTO "public"."users"("username", "age") VALUES(''rong'', 29) RETURNING "id", "username", "age", "content";- tf main.tf
主要是集成模版函数以及 http provider 还有 jsondecode 函数
main.tf
variable filename { type = string default = "tf-result/main.tf"}data "http" "user_apps" { url = "http://localhost:8025/user_apps"}resource "local_file" "main_tf" { content = templatefile("user_apps.tmpl", jsondecode(data.http.user_apps.body)) filename = var.filename}user_apps.tmpl
%{ for item in data.apps ~}resource "users" "${item.appname}" { appname = "${item.appname}" version = "${item.appversion}" content = "${item.content != null ? item.content : ""}"}%{ endfor ~}%{ for item in data.users ~}resource "apps" "${item.username}" { username = "${item.username}" age = "${item.age}" content = "${item.content != null ? item.content : ""}"}%{ endfor ~} 运行 && 测试
- 启动 sqler
cd restapi && docker-compose up -d- 运行 tf
init :
下载依赖的 provider
terraform init plan:
查询 tf 的任务
terraform plan效果
Refreshing Terraform state in-memory prior to plan...The refreshed state will be used to calculate this plan, but will not bepersisted to local or remote state storage.data.http.user_apps: Refreshing state...------------------------------------------------------------------------An execution plan has been generated and is shown below.Resource actions are indicated with the following symbols: + createTerraform will perform the following actions: # local_file.main_tf will be created + resource "local_file" "main_tf" { + content = "resource \"users\" \"login\" {\n appname = \"login\"\n version = \"v1.0\"\n content = \"login\"\n}\nresource \"users\" \"logo\" {\n appname = \"logo\"\n version = \"v2.0\"\n content = \"\"\n}\n\nresource \"apps\" \"dalong\" {\n username = \"dalong\"\n age = \"22\"\n content = \"demo\"\n}\nresource \"apps\" \"rong\" {\n username = \"rong\"\n age = \"29\"\n content = \"\"\n}\n" + filename = "tf-result/main.tf" + id = (known after apply) }Plan: 1 to add, 0 to change, 0 to destroy.------------------------------------------------------------------------Note: You didn''t specify an "-out" parameter to save this plan, so Terraformcan''t guarantee that exactly these actions will be performed if"terraform apply" is subsequently run. apply:
data.http.user_apps: Refreshing state...An execution plan has been generated and is shown below.Resource actions are indicated with the following symbols: + createTerraform will perform the following actions: # local_file.main_tf will be created + resource "local_file" "main_tf" { + content = "resource \"users\" \"login\" {\n appname = \"login\"\n version = \"v1.0\"\n content = \"login\"\n}\nresource \"users\" \"logo\" {\n appname = \"logo\"\n version = \"v2.0\"\n content = \"\"\n}\n\nresource \"apps\" \"dalong\" {\n username = \"dalong\"\n age = \"22\"\n content = \"demo\"\n}\nresource \"apps\" \"rong\" {\n username = \"rong\"\n age = \"29\"\n content = \"\"\n}\n" + filename = "tf-result/main.tf" + id = (known after apply) }Plan: 1 to add, 0 to change, 0 to destroy.Do you want to perform these actions? Terraform will perform the actions described above. Only ''yes'' will be accepted to approve. Enter a value: yeslocal_file.main_tf: Creating...local_file.main_tf: Creation complete after 0s [id=ee0a2ad2f12e1e21723c46248af40d5cc53e46cd]Apply complete! Resources: 1 added, 0 changed, 0 destroyed.- 生成的模版内容
resource "users" "login" { appname = "login" version = "v1.0" content = "login"}resource "users" "logo" { appname = "logo" version = "v2.0" content = ""}resource "apps" "dalong" { username = "dalong" age = "22" content = "demo"}resource "apps" "rong" { username = "rong" age = "29" content = ""} 说明
以上只是一个简单的集成,实际上我们可以集合数据库的管理,做为配置管理,同时集成安全认证,使用 slqer 快速提供数据接口
使用 tf 进行资源部署,同时可以使用 tf 的状态管理,实现技术设施资源的快速部署以及管理,还是很不错的
参考资料
https://github.com/rongfengliang/sqler-docker-compose
https://www.terraform.io/docs/cli-index.html
https://www.terraform.io/docs/configuration/functions/templatefile.html
https://www.terraform.io/docs/providers/http/index.html
https://github.com/rongfengliang/sqler-terraform-resource-demo

AWS Terraform - 在资源上使用动态块
如何解决AWS Terraform - 在资源上使用动态块?
我正在尝试使用动态块为 AWS 安全组编写 terraform 模块,但出现此错误:
│
│ on main.tf line 17,in module "security_group":
│ 17: ingress = {
│
│ The argument "ingress" was already set at main.tf:8,5-12. Each argument may be set only once.
我已按照文档进行操作,但仍有错误 我使用的是 terraform 0.15.1 和 AWS 提供商版本 3.38.0
这是我的代码
./modules/security_group/main.tf
resource "aws_security_group" "main" {
.......
dynamic "ingress" {
for_each = var.ingress
content {
description = ingress.value["description"]
from_port = ingress.value["from_port"]
to_port = ingress.value["to_port"]
protocol = ingress.value["protocol"]
cidr_blocks = ingress.value["cidr_blocks"]
ipv6_cidr_blocks = ingress.value["ipv6_cidr_blocks"]
}
}
.......
}
./modules/security_group/variables.tf
variable "ingress" {
description = ""
type = object({
description = string
from_port = number
to_port = number
protocol = string
cidr_blocks = list(string)
ipv6_cidr_blocks = list(string)
})
default = {
description = ""
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = []
ipv6_cidr_blocks = []
}
}
./main.tf
module "security_group" {
source = "./modules/security_group"
name = "${var.project}-sg"
description = "security group testing"
vpc_id = "my-vpc"
ingress = {
description = ""
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = []
ipv6_cidr_blocks = []
}
ingress = {
description = ""
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = []
ipv6_cidr_blocks = []
}
}
解决方法
您有 ingress 参数。我想你想要一个列表:
variable "ingress" {
description = ""
type = list(object({
description = string
from_port = number
to_port = number
protocol = string
cidr_blocks = list(string)
ipv6_cidr_blocks = list(string)
}))
default = [{
description = ""
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = []
ipv6_cidr_blocks = []
}
}]
module "security_group" {
source = "./modules/security_group"
name = "${var.project}-sg"
description = "security group testing"
vpc_id = "my-vpc"
ingress = [{
description = ""
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = []
ipv6_cidr_blocks = []
},{
description = ""
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = []
ipv6_cidr_blocks = []
}]
}

IaC云资源编排-Terraform
Terraform
2019/10/14 Chenxin 整理 转自: https://cloud.tencent.com/developer/article/1469162
IaC与资源编排
IaC(Infrastructure as Code)这一理念随着云技术的普及以及多云时代的到来而被广泛接受和认可,特别是众多生态工具产品的涌现使得IaC由概念逐渐成为现实。
1.与传统的“ClickOps”管理模式相比,IaC主要可以在以下3方面优势:
提高资源部署的速度和效率 所有的云服务都可以通过代码的方式进行部署、维护和管理,极大地提高了规模部署下的生产效率;
配置的一致性 由于所有的云服务管理都是通过代码的方式实现,因此相关的软件方法论也可以类似的迁移到IaC使用中来,能够提高开发、测试、运维环境的配置一致性,降低人为失误;
节约成本 IaC的引入可以更加高效的应对多云管理,既可以降低Opex,也可以通过多云部署方案降低资源使用成本;
2.目前,常见的IaC工具主要分为两类: 一类是配置管理类,如Chef,Puppet等,该类产品主要优势在于底层的单服务器、单服务的配置管理; 一类是资源编排类,如Terraform、Pulumi等,该类产品主要优势在于更高层面的资源编排,根据资源描述文件创建具有相互依赖关系的云资源或服务并进行配置。 值得注意的是,在Terraform里资源的相互依赖关系并不需要被明确指出,Terraform会根据资源之间的互相引用情况自行判断依赖关系,并据此决定资源的先后创建顺序。
terraform简介
Terraform是由HashiCorp公司在2014年左右推出, 目前几乎所有的主流云服务商都支持Terraform,包括腾讯云、AWS、Azure和GCP等。
Terraform之所以为众多云用户和云服务商青睐,主要是基于: 1.完善的开源生态。只需要一个工具即可完成对多个云厂商的服务进行资源编排; 2.使用声明型语言HCL(HashiCorp Configuration Language)。使用户只关注与自己的需求,而非如何实现; 3.采用客户端单一架构(Client Only),而非CS(Client/Server)架构。降低数据安全风险,同时提高了infrastructure配置的可靠性;
目前大多数云平台的主流产品均已支持Terraform.
部署与安装
使用Terraform前,我们需要首先现下载客户端并配置工作环境。 客户端的安装可以选择本地PC,也可以使用云服务器(CVM),详细内容可以参考terraform官方说明。https://learn.hashicorp.com/terraform/getting-started/install
使用Terraform
下面我们通过一个简单地案例来了解Terraform在资源编排上的强大功能以及优势。
使用Terraform的Scripting、Plan、Apply和Destroy四个步骤即可轻松实现基础架构资源的全生命周期管理。 下面我们以腾讯云的CVM、MySQl、VPC和Security Group服务为例,搭建一个最简单的基础架构,相关Resources的说明参考Tencentcloud Provider。链接https://www.terraform.io/docs/providers/tencentcloud/index.html
1、Scripting 资源声明 使用HashiCorp自己的声明型语言HCL编写资源编排脚本。由于是声明型语言,我们熟悉的过程型语言的一些高级特性,比如“for”循环,HCL是不支持的。
#1、Provider info
provider "tencentcloud" {
secret_id = "AsVv2va1CE5ipdx4"
secret_key = "KQdafafrtJ"
region = "ap-shanghai"
}
#2、Create a VPC resource
resource "tencentcloud_vpc" "main" {
name = "demo-VPC"
cidr_block = "10.0.0.0/16"
}
#3、Create route tables for web and DB
resource "tencentcloud_route_table" "web" {
name = "demo-rt_web"
vpc_id = "${tencentcloud_vpc.main.id}"
}
resource "tencentcloud_route_table" "db" {
name = "demo-rt_db"
vpc_id = "${tencentcloud_vpc.main.id}"
}
#4、CVM instances
resource "tencentcloud_instance" "nginx" {
instance_name = "demo-nginx"
availability_zone = "ap-shanghai-2"
image_id = "img-pi0ii46r"
instance_type = "S4.SMALL2"
security_groups = [
"${tencentcloud_security_group.web.id}"
]
vpc_id = "${tencentcloud_vpc.main.id}"
subnet_id = "${tencentcloud_subnet.web.id}"
internet_max_bandwidth_out = 10
count = 10
}
#5、Mysql instance
resource "tencentcloud_mysql_instance" "demo-mysql" {
instance_name = "demo-mysql"
mem_size = 1000
root_password = "My_demo_mysql0001"
volume_size = 50
availability_zone = "ap-shanghai-2"
engine_version = "5.7"
internet_service = 0
intranet_port = 3306
parameters = {
max_connections = "1000"
}
security_groups = [
"${tencentcloud_security_group.db.id}"
]
vpc_id = "${tencentcloud_vpc.main.id}"
subnet_id = "${tencentcloud_subnet.db.id}"
tags = {
name ="demo-project"
}
}
#6、Create subnets within the VPC
resource "tencentcloud_subnet" "web" {
name = "demo-SN_web"
cidr_block = "10.0.1.0/24"
availability_zone = "ap-shanghai-2"
vpc_id = "${tencentcloud_vpc.main.id}"
route_table_id = "${tencentcloud_route_table.web.id}"
}
resource "tencentcloud_subnet" "db" {
name = "demo-SN_db"
cidr_block = "10.0.2.0/24"
availability_zone = "ap-shanghai-2"
vpc_id = "${tencentcloud_vpc.main.id}"
route_table_id = "${tencentcloud_route_table.db.id}"
}
#7、Create security groups and rules
resource "tencentcloud_security_group" "web" {
name = "demo-sg_web"
description = "Accessible for both HTTP and SSH"
}
resource "tencentcloud_security_group" "db" {
name = "demo-sg_db"
description = "Accessible for both mysql and SSH from web"
}
resource "tencentcloud_security_group_rule" "web-from-public" {
security_group_id = "${tencentcloud_security_group.web.id}"
type = "ingress"
cidr_ip = "0.0.0.0/0"
ip_protocol = "tcp"
port_range = "80,22"
policy = "accept"
}
resource "tencentcloud_security_group_rule" "web-to-public" {
security_group_id = "${tencentcloud_security_group.web.id}"
type = "egress"
ip_protocol = "tcp"
cidr_ip = "0.0.0.0/0"
port_range = "80,22"
policy = "accept"
}
resource "tencentcloud_security_group_rule" "mysql-from-webtier" {
security_group_id = "${tencentcloud_security_group.db.id}"
type = "ingress"
cidr_ip = "10.0.1.0/24"
ip_protocol = "tcp"
port_range = "22,3306"
policy = "accept"
}
resource "tencentcloud_security_group_rule" "mysql-to-webtier" {
security_group_id = "${tencentcloud_security_group.db.id}"
type = "egress"
cidr_ip = "0.0.0.0/0"
ip_protocol = "tcp"
port_range = "22,3306"
policy = "accept"
}
2、Plan 资源确认 Terraform Plan功能可以很好的支持Terraform脚本执行前的检查确认工作。Terraform基于脚本、本地状态文件(terraform.tfstate)和云平台三者的一致性来保证执行结果的准确性。 执行命令 terraform plan, 会自动检查.
3、Apply 部署 Terraform apply功能实现基础架构的一键部署。 注意,apply前Terraform还是会强制进行资源的确认工作,即Terraform Plan工作。
Terraform的执行结果会保存在本地状态文件(terraform.tfstate)中。 执行命令 terraform apply
4、Destroy 释放 通过以上简单地三个步骤即可实现复杂的资源部署工作,同样的,仅需要一个简单地命令即可实现资源的快速高效释放。 执行命令 terraform destroy
总结
通过上面的简单案例,我们可以快速的发现相比于传统的Infrastructure管理工作,IaC具有无可比拟的优势.

py-libterraform 的使用和实现:一个 Terraform 的 Python 绑定
本文同步发表于字节话云公众号。
初衷
在某个使用 Python 开发的业务中,涉及到 Terraform 的交互,具体有两个需求:
- 需要调用 Terraform 的各种命令,以完成对资源的部署、销毁等操作
- 需要解析 Terraform 配置文件(HCL 语法)的内容,分析里面的组成
对于前者,有一个名为 python-terraform 的开源库,它封装了 Terraform 的命令,当我们在代码中调用时,背后会新启一个进程执行 Terraform 的对应命令,并能返回命令退出码和捕获的 stdout 和 stderr。python-terraform 用起来虽然方便,但最大的缺点在于要求执行环境事先安装了 Terraform,而且新启进程也带来了额外的开销。
对于后者,尚未找到 Python 开源库能满足要求。
我希望能有一个库无需用户事先安装 Terraform,能在当前进程执行 Terraform 命令,而且还能解析 Terraform 配置文件,py-libterraform 就这样诞生了。
使用
在说明 py-libterraform 的实现原理之前,不妨先看看是如何安装和使用的。
它的安装十分简单,执行 pip 命令即可,支持 Mac、Linux和Windows,并支持 Python3.6 及以上版本:
$ pip install libterraformpy-libterraform 目前提供两个功能:TerraformCommand 用于执行 Terraform CLI,TerraformConfig 用于解析 Terraform 配置文件。后文将通过示例介绍这两个功能。假定当前有一个 sleep 文件夹,里面的 main.tf 文件内容如下:
variable "time1" {
type = string
default = "1s"
}
variable "time2" {
type = string
default = "1s"
}
resource "time_sleep" "wait1" {
create_duration = var.time1
}
resource "time_sleep" "wait2" {
create_duration = var.time2
}
output "wait1_id" {
value = time_sleep.wait1.id
}
output "wait2_id" {
value = time_sleep.wait2.id
}Terraform CLI
现在进入 sleep 目录,需要对它执行 Terraform init, apply 和 show,以部署资源并查看资源属性,那么可以这么做:
>>> from libterraform import TerraformCommand
>>> cli = TerraformCommand()
>>> cli.init()
<CommandResult retcode=0 json=False>
>>> _.value
''\nInitializing the backend...\n\nInitializing provider plugins...\n- Reusing previous version of hashicorp/time from the dependency lock file\n- Using previously-installed hashicorp/time v0.7.2\n\nTerraform has been successfully initialized!\n\nYou may now begin working with Terraform. Try running "terraform plan" to see\nany changes that are required for your infrastructure. All Terraform commands\nshould now work.\n\nIf you ever set or change modules or backend configuration for Terraform,\nrerun this command to reinitialize your working directory. If you forget, other\ncommands will detect it and remind you to do so if necessary.\n''
>>> cli.apply()
<CommandResult retcode=0 json=True>
>>> _.value
[{''@level'': ''info'', ''@message'': ''Terraform 1.1.7'', ''@module'': ''terraform.ui'', ''@timestamp'': ''2022-04-08T19:16:59.984727+08:00'', ''terraform'': ''1.1.7'', ''type'': ''version'', ''ui'': ''1.0''}, ... ]
>>> cli.show()
<CommandResult retcode=0 json=True>
>>> _.value
{''format_version'': ''1.0'', ''terraform_version'': ''1.1.7'', ''values'': {''outputs'': {''wait1_id'': {''sensitive'': False, ''value'': ''2022-04-08T11:17:01Z''}, ''wait2_id'': {''sensitive'': False, ''value'': ''2022-04-08T11:17:01Z''}}, ''root_module'': {''resources'': [{''address'': ''time_sleep.wait1'', ''mode'': ''managed'', ''type'': ''time_sleep'', ''name'': ''wait1'', ''provider_name'': ''registry.terraform.io/hashicorp/time'', ''schema_version'': 0, ''values'': {''create_duration'': ''1s'', ''destroy_duration'': None, ''id'': ''2022-04-08T11:17:01Z'', ''triggers'': None}, ''sensitive_values'': {}}, {''address'': ''time_sleep.wait2'', ''mode'': ''managed'', ''type'': ''time_sleep'', ''name'': ''wait2'', ''provider_name'': ''registry.terraform.io/hashicorp/time'', ''schema_version'': 0, ''values'': {''create_duration'': ''1s'', ''destroy_duration'': None, ''id'': ''2022-04-08T11:17:01Z'', ''triggers'': None}, ''sensitive_values'': {}}]}}}从上述执行过程可以看出,不论执行什么命令,都会返回一个 CommandResult 对象,用来表示命令执行结果(包含返回码、输出、错误输出、是否为 json 结构)。
其中:
init()返回的 value 是Terraform init命令的标准输出,一个字符串apply()返回的 value 默认是Terraform apply -json命令的标准输出被视作 json 加载后的数据,一个展示日志记录的列表。如果不希望解析标准输出,则可以使用apply(json=False)show()返回的 value 默认是Terraform show -jon命令的标准输出被视作 json 加载后的数据,一个展示 Terraform state 文件数据结构的字典
所有命令的封装函数的思路是尽可能让结果方便给程序处理,因此对于支持 -json 的 Terraform 命令都会默认使用此选项并对结果进行解析。
以上是一个简单的示例,实际上 TerraformCommand 封装了所有的 Terraform 命令,具体可以调用 help(TerraformCommand) 进行查看。
Terraform 配置文件解析
如果希望拿到 Terraform 对配置文件的解析结果做进一步处理,那么 TerraformConfig 就可以满足需求,通过它可以解析指定的 Terraform 配置目录,获取其中的变量、资源、输出、行号等信息,这对分析配置组成很有帮助。可以这么做(部分输出较多使用...做了省略):
>>> from libterraform import TerraformConfig
>>> mod, _ = TerraformConfig.load_config_dir(''.'')
>>> mod
{''SourceDir'': ''.'', ''CoreVersionConstraints'': None, ''ActiveExperiments'': {}, ''Backend'': None, ''CloudConfig'': None, ''ProviderConfigs'': None, ''ProviderRequirements'': {''RequiredProviders'': {}, ''DeclRange'': ...}, ''Variables'': {''time1'': ..., ''time2'': ...}, ''Locals'': {}, ''Outputs'': {''wait1_id'': ..., ''wait2_id'': ...}, ''ModuleCalls'': {}, ''ManagedResources'': {''time_sleep.wait1'': ..., ''time_sleep.wait2'': ...}, ''DataResources'': {}, ''Moved'': None}TerraformConfig.load_config_dir 背后会调用 Terraform 源码中 internal/configs/parser_config_dir.go 中的 LoadConfigDir 方法,以加载 Terraform 配置文件目录,返回内容是原生返回结果 *Module, hcl.Diagnostics 的经序列化后分别加载为 Python 中的字典。
实现原理
由于 Terraform 是用 GoLang 编写的,Python 无法直接调用,但好在它可以编译为动态链接库,然后再被 Python 加载调用。因此,总体思路上可以这么做:
- 使用
cgo编写 Terraform 的 C 接口文件 - 将它编译为动态链接库,Linux/Unix 上以
.so结尾,在 Windows 上以.dll结尾 - 在 Python 中通过
ctypes加载此动态链接库,在此之上实现命令封装
本质上,GoLang 和 Python 之间以 C 作为媒介,完成交互。关于如何使用 cgo 和 ctypes 网上有很多文章,本文着重介绍实现过程中遇到的各种“坑”以及如何解决的。
坑 1:GoLang 的 internal packages 机制阻隔了外部调用
GoLang 从 1.4 版本开始,增加了 Internal packages 机制,只允许 internal 的父级目录及父级目录的子包导入,其它包无法导入。而 Terraform 最新版本中,几乎所有的代码都放在了 internal 中,这意味着使用 cgo 写的接口文件(本项目中叫 libterraform.go)如果作为外部包(比如包名叫 libterraform)是无法调用 Terraform 代码的,也就无法实现 Terraform 命令的封装。
一个解决方法是把 Terraform 中的 internal 改为 public,但这意味着需要修改大量的 Terraform 源码,这可不是个好主意。
那么另一个思路就是让 libterraform.go 作为整个 Terraform 项目的“一份子”,来“欺骗” Go 编译器。具体过程如下:
libterraform.go的包名和 Terraform 主包保持一致,即main- 构建前把
libterraform.go移动到 Terraform 源码根目录下,作为 Terraform 项目的成员 - 构建时,使用
go build -buildmode=c-shared -o=libterraform.so github.com/hashicorp/terraform命令进行编译,这样编译出的动态链接库就能包含libterraform.go的逻辑
坑 2:注意管理 C 运行时申请的内存空间
不论是 GoLang 还是 Python,我们都不需要担心内存管理的问题,因为它们自会被语言的垃圾回收机制在合适的时机去回收。但是涉及到 C 的逻辑就需要各位注意内存管理了。
使用 cgo 中定义的接口中可能会返回 *C.char,它实际是 C 层面上开辟的一段内存空间,需要被显式释放。例如,libterraform.go 中定义了加载 Terraform 配置目录的方法 ConfigLoadConfigDir,其实现如下:
//export ConfigLoadConfigDir
func ConfigLoadConfigDir(cPath *C.char) (cMod *C.char, cDiags *C.char, cError *C.char) {
defer func() {
recover()
}()
parser := configs.NewParser(nil)
path := C.GoString(cPath)
mod, diags := parser.LoadConfigDir(path)
modBytes, err := json.Marshal(convertModule(mod))
if err != nil {
cMod = C.CString("")
cDiags = C.CString("")
cError = C.CString(err.Error())
return cMod, cDiags, cError
}
diagsBytes, err := json.Marshal(diags)
if err != nil {
cMod = C.CString(string(modBytes))
cDiags = C.CString("")
cError = C.CString(err.Error())
return cMod, cDiags, cError
}
cMod = C.CString(string(modBytes))
cDiags = C.CString(string(diagsBytes))
cError = C.CString("")
return cMod, cDiags, cError
}上述方法实现中,使用 C.CString 会在 C 层面上申请了一段内存空间,并返回结果返回给调用者,那么调用者(Python 进程)需要在使用完返回值之后显式释放内存。
在此之前,需要先通过 cgo 暴露释放内存的方法:
//export Free
func Free(cString *int) {
C.free(unsafe.Pointer(cString))
}然后,在 Python 中就可以实现如下封装:
import os
from ctypes import cdll, c_void_p
from libterraform.common import WINDOWS
class LoadConfigDirResult(Structure):
_fields_ = [("r0", c_void_p),
("r1", c_void_p),
("r2", c_void_p)]
_load_config_dir = _lib_tf.ConfigLoadConfigDir
_load_config_dir.argtypes = [c_char_p]
_load_config_dir.restype = LoadConfigDirResult
root = os.path.dirname(os.path.abspath(__file__))
_lib_filename = ''libterraform.dll'' if WINDOWS else ''libterraform.so''
_lib_tf = cdll.LoadLibrary(os.path.join(root, _lib_filename))
_free = _lib_tf.Free
_free.argtypes = [c_void_p]
def load_config_dir(path: str) -> (dict, dict):
ret = _load_config_dir(path.encode(''utf-8''))
r_mod = cast(ret.r0, c_char_p).value
_free(ret.r0)
r_diags = cast(ret.r1, c_char_p).value
_free(ret.r1)
err = cast(ret.r2, c_char_p).value
_free(ret.r2)
...这里,在获取到返回结果后,调用 _free (也就是 libterraform.go 中的 Free)来显式释放内存,从而避免内存泄露。
坑 3:捕获输出
在 Terraform 的源码中,执行命令的输出会打印到标准输出 stdout 和标准错误输出 stderr 上,那么使用 cgo 封装出 RunCli 的接口,并被 Python 调用时,默认情况下就直接输出到 stdout 和 stderr 上了。
这会有什么问题呢?如果同时执行两个命令,输出结果会交错,没法区分这些结果是哪个命令的结果。
解决思路就是使用管道:
- 在 Python 进程中使用
os.pipe分别创建用于标准输出和标准错误输出的管道(会生成文件描述符) - 将两个文件描述符传入到
libterraform.go的RunCli方法中,在内部使用os.NewFile打开两个文件描述符,并分别替换os.Stdout和os.Stderr - 在
RunCli方法结束时关闭这两个文件,并恢复原始的os.Stdout和os.Stderr
此外,使用 os.pipe 获取到的文件描述符给 libterraform.go 使用时要注意操作系统的不同:
- 对于 Linux/Unix 来说,直接传进去使用即可
- 对于 Windows 来说,需要额外将文件描述符转换成文件句柄,这是因为在 Windows 上 GoLang 的
os.NewFile接收的是文件句柄
Python 中相关代码如下:
if WINDOWS:
import msvcrt
w_stdout_handle = msvcrt.get_osfhandle(w_stdout_fd)
w_stderr_handle = msvcrt.get_osfhandle(w_stderr_fd)
retcode = _run_cli(argc, c_argv, w_stdout_handle, w_stderr_handle)
else:
retcode = _run_cli(argc, c_argv, w_stdout_fd, w_stderr_fd)坑 4:管道 Hang
由于管道的大小有限制,如果写入超过了限制就会导致写 Hang。因此不能在调用 RunCli (即会把命令输出写入管道)之后去管道中读取输出,否则会发现在执行简单命令(如version)时正常,在执行复杂命令(如apply,因为有大量输出)时会 Hang 住。
解决思路就是在调用 RunCli 前就启动两个线程分别读取标准输出和标准错误输出的文件描述符内容,在调用 RunCli 命令之后去 join 这两个线程。Python 中相关代码如下:
r_stdout_fd, w_stdout_fd = os.pipe()
r_stderr_fd, w_stderr_fd = os.pipe()
stdout_buffer = []
stderr_buffer = []
stdout_thread = Thread(target=cls._fdread, args=(r_stdout_fd, stdout_buffer))
stdout_thread.daemon = True
stdout_thread.start()
stderr_thread = Thread(target=cls._fdread, args=(r_stderr_fd, stderr_buffer))
stderr_thread.daemon = True
stderr_thread.start()
if WINDOWS:
import msvcrt
w_stdout_handle = msvcrt.get_osfhandle(w_stdout_fd)
w_stderr_handle = msvcrt.get_osfhandle(w_stderr_fd)
retcode = _run_cli(argc, c_argv, w_stdout_handle, w_stderr_handle)
else:
retcode = _run_cli(argc, c_argv, w_stdout_fd, w_stderr_fd)
stdout_thread.join()
stderr_thread.join()
if not stdout_buffer:
raise TerraformFdReadError(fd=r_stdout_fd)
if not stderr_buffer:
raise TerraformFdReadError(fd=r_stderr_fd)
stdout = stdout_buffer[0]
stderr = stderr_buffer[0]最后
当发现现有的开源库满足不了需求时,手撸了 py-libterraform,基本实现了在单进程中调用 Terraform 命令的要求。尽管在开发过程中遇到了各种问题,并需要不断在 Python、GoLang、C 之间跳转,但好在一个个解决了,记录此过程若能让大家少“踩坑”也算值啦!
最后,https://github.com/Prodesire/... 求赞~
 资源与变量")
Terraform (2) 资源与变量
《Windows Azure Platform 系列文章目录》
熟悉Azure Template的读者都知道:Azure ARM (5) ARM Template初探 - 本地JSON Template文件(1)
Azure Template分为两种类型的文件,资源和变量
(1)Template:资源文件,表示我们需要创建的资源是什么,比如Azure VM,Azure Storage
(2)Parameter:变量文件,表示资源所使用到的参数,比如虚拟机的名字,登陆虚拟机所需要的用户名和密码。存储名称等等。
在使用Terraform时,也会有两种类型的文件。我们以Terraform例子为例:
https://github.com/terraform-providers/terraform-provider-azurerm/tree/master/examples/virtual-networks/multiple-subnets
Terraform 运行时会读取工作目录中所有的 *.tf, *.tfvars 文件,所以我们不必把所有的东西都写在单个文件中去,应按职责分列在不同的文件中,例如:
provider.tf -- provider 配置
terraform.tfvars -- 配置 provider 要用到的变量
varable.tf -- 通用变量
resource.tf -- 资源定义
data.tf -- 包文件定义
output.tf -- 输出
在这个例子里,我们先观察:https://github.com/terraform-providers/terraform-provider-azurerm/blob/master/examples/virtual-networks/multiple-subnets/main.tf
provider "azurerm" {
features {}
}
resource "azurerm_resource_group" "example" {
#这里会读取variables.tf文件
name = "${var.prefix}-resources"
location = "${var.location}"
}
上面的var.prefix和var.location,会读取到变量文件
具体的变量内容,在这里被定义:https://github.com/terraform-providers/terraform-provider-azurerm/blob/master/examples/virtual-networks/multiple-subnets/variables.tf
variable "prefix" {
description = "The prefix used for all resources in this example"
}
variable "location" {
description = "The Azure location where all resources in this example should be created"
}
好了,现在我们用两种方式执行Terraform
第一种:通过读取variable.tf中的变量值,来创建Azure资源
第二种:通过执行terraform -apply 过程中,直接设置变量值
我们开始第一种方法:通过读取variable.tf中的变量值,来创建Azure资源
1.修改varible.tf文件,设置default值。在Terraform执行过程中
我们可以在variable.tf中,设置default值,定义这些变量值。
variable "prefix" {
default="leizha"
description = "The prefix used for all resources in this example"
}
variable "location" {
default="chinaeast2"
description = "The Azure location where all resources in this example should be created"
}
2.terraform init,初始化工作目录:
terraform initTerraform init做的事情就像是git init加上npm install,执行完trraform init之后,会在当前目录中生成.terraform目录,并依照*.tf文件中的执行下载相应的插件
3.terraform plan
该命令让terraform在正式执行之前,提供了预览执行计划的机会,让我们清楚的了解将要做什么
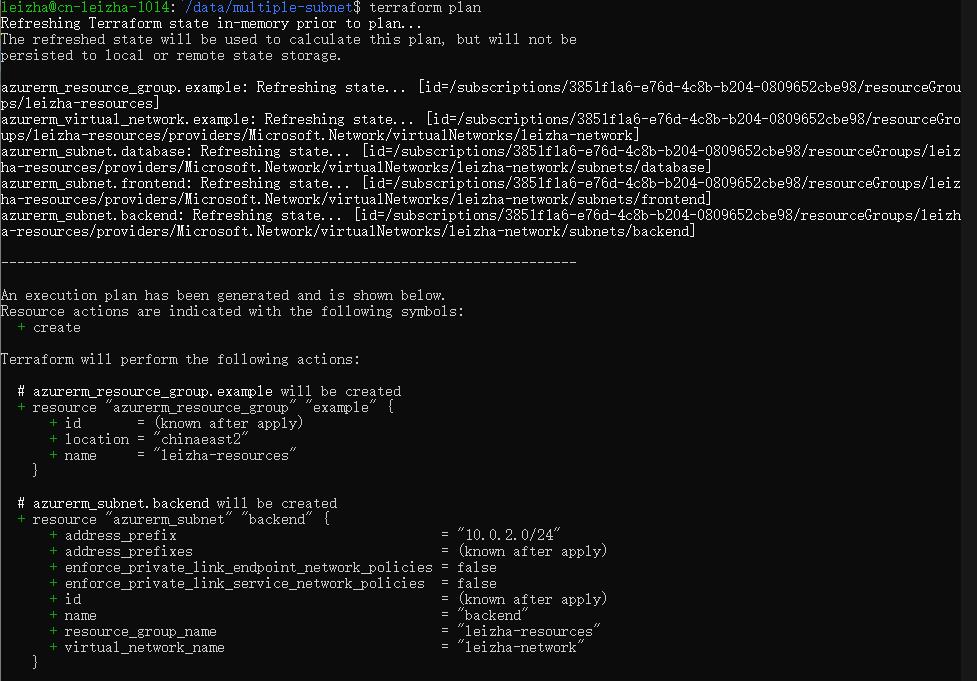
4.terraform apply
这句语句就是真正执行terraform,并显示结果。
terraform apply -auto-approve注意:上面的auto-approve是跳过交互式批准流程。
因为我们在步骤1中,设置了prefix值,则我们在terraform执行完毕后,通过读取variable.tf中prefix值,创建相应的资源。
执行的结果如下:
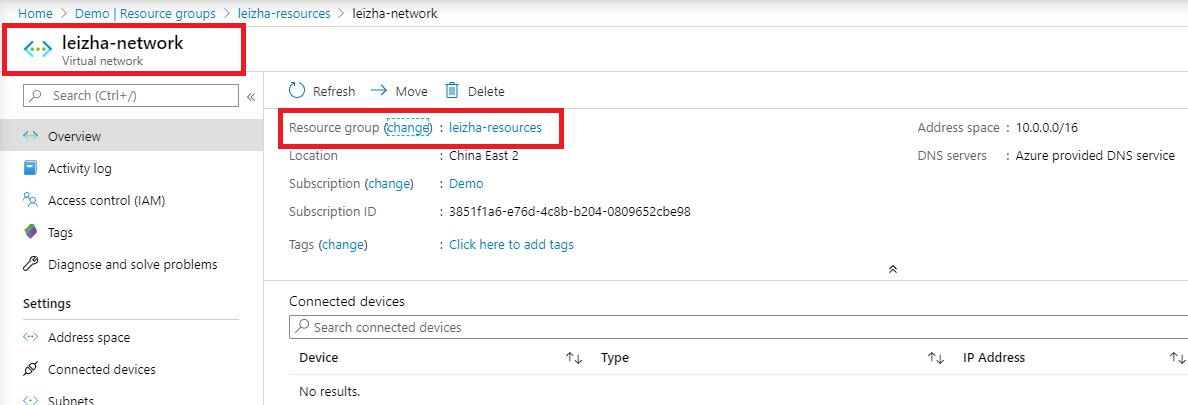
第二种:通过执行terraform apply 过程中,直接设置变量值
1.首先我们把上面已经创建的Azure资源删除。图略。
2.观察variable.tf中,设置default值,定义这些变量值。
variable "prefix" {
default="leizha"
description = "The prefix used for all resources in this example"
}
variable "location" {
default="chinaeast2"
description = "The Azure location where all resources in this example should be created"
}
3.在terraform apply中,直接设置变量值
下面的-var里面,分别设置了prefix的值和location的值
terraform apply -var ''prefix=contoso'' -var ''location=chinaeast2''
4.执行结果:
可以看到,虽然我们在variable.tf中,设置default值。但是在terraform apply中,直接设置了变量值,所以会显示不一样的结果:
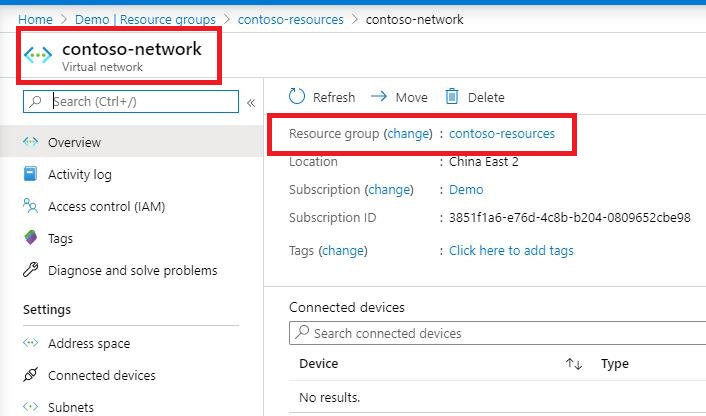
var.prefix关于sqler 集成 terraform v0.12 生成资源部署文件和sql server集成环境的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于AWS Terraform - 在资源上使用动态块、IaC云资源编排-Terraform、py-libterraform 的使用和实现:一个 Terraform 的 Python 绑定、Terraform (2) 资源与变量的相关知识,请在本站寻找。
本文标签:




