对于Docker简介与shell操作使用感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解shelldocker命令,并且为您提供关于100行shell写个Docker、bash–使用shel
对于Docker 简介与 shell 操作使用感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解shell docker命令,并且为您提供关于100 行 shell 写个 Docker、bash – 使用shell脚本在Docker容器内运行脚本、Bocker —— Shell 实现的 Docker、Docker 17.03系列教程(一)Docker EE/Docker CE简介与版本规划的宝贵知识。
本文目录一览:- Docker 简介与 shell 操作使用(shell docker命令)
- 100 行 shell 写个 Docker
- bash – 使用shell脚本在Docker容器内运行脚本
- Bocker —— Shell 实现的 Docker
- Docker 17.03系列教程(一)Docker EE/Docker CE简介与版本规划
")
Docker 简介与 shell 操作使用(shell docker命令)
一.Docker 概述
1.Docker 简介
Docker 是一个开源的应用容器引擎;是一个轻量级容器技术;Docker 支持将软件编译成一个镜像;然后在镜像中各种软件做好配置,将镜像发布出去,其他使用者可以直接使 用这个镜像;运行中的这个镜像称为容器,容器启动是非常快速的。
对比传统虚拟机总结:

2.Docker 术语
- docker 主机 (Host):安装了 Docker 程序的机器(Docker 直接安装在操作系统之上);
- docker 客户端 (Client):连接 docker 主机进行操作; docker 仓库 (Registry):用来保存各种打包好的软件镜像;
- docker 镜像 (Images):软件打包好的镜像;放在 docker 仓库中;
- docker 容器 (Container):镜像启动后的实例称为一个容器;容器是独立运行的一个或一组应用。
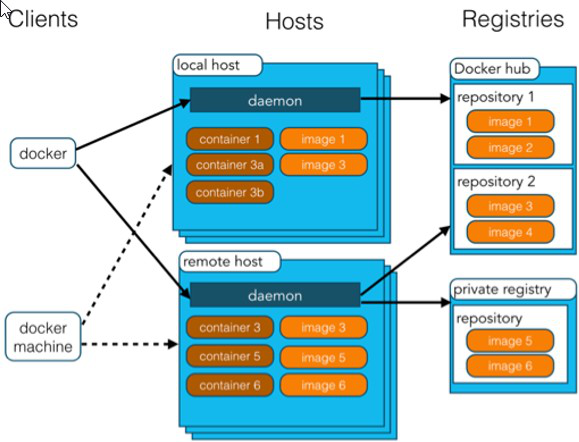
使用 Docker 的步骤:
1)、安装 Docker
2)、去 Docker 仓库找到这个软件对应的镜像;
3)、使用 Docker 运行这个镜像,这个镜像就会生成一个 Docker 容器;
4)、对容器的启动停止就是对软件的启动停止;
二.Docker 安装
1. 安装 linux 虚拟机
1)、VMWare、VirtualBox(安装); VirtualBox 下载地址: https://www.virtualbox.org/wiki/Downloads
2)、安装 linux 系统 CentOS7;
3)、双击启动 linux 虚拟机;使用 root/ 123456 登陆
4)、使用客户端连接 linux 服务器进行命令操作;
5)、设置虚拟机网络;桥接网络 = 选好网卡 == 接入网线;
6)、设置好网络以后使用命令重启虚拟机的网络 service network restart ip addr
2.linux 上安装 docker
1、检查内核版本,必须是 3.10 及以上 uname ‐r ,如果不是需要 yum update 升级软件包及内核

2、安装 docker ,输入 y 确认安装
[root@localhost ~]# yum install docker
yum 方式安装的 docker 不是最新版的,通过下面方式安装最新版的 docker
[root@localhost ~]# curl -sSL https://get.daocloud.io/docker | sh
3、启动 docker 查看 docker 版本号
[root@localhost ~]# systemctl start docker4、设置开机启动 docker
[root@localhost ~]# systemctl enable docker
5、停止 docker
[root@localhost ~]# systemctl stop docker6、查看 docker 帮助
[root@localhost ~]# docker --help帮助命令如下:


[root@localhost ~]# docker --help
Usage: docker COMMAND
A self-sufficient runtime for containers
Options:
--config string Location of client config files (default "/root/.docker")
-D, --debug Enable debug mode
--help Print usage
-H, --host list Daemon socket(s) to connect to (default [])
-l, --log-level string Set the logging level ("debug", "info", "warn", "error", "fatal") (default "info")
--tls Use TLS; implied by --tlsverify
--tlscacert string Trust certs signed only by this CA (default "/root/.docker/ca.pem")
--tlscert string Path to TLS certificate file (default "/root/.docker/cert.pem")
--tlskey string Path to TLS key file (default "/root/.docker/key.pem")
--tlsverify Use TLS and verify the remote
-v, --version Print version information and quit
Management Commands:
container Manage containers
image Manage images
network Manage networks
node Manage Swarm nodes
plugin Manage plugins
secret Manage Docker secrets
service Manage services
stack Manage Docker stacks
swarm Manage Swarm
system Manage Docker
volume Manage volumes
Commands:
attach Attach to a running container
build Build an image from a Dockerfile
commit Create a new image from a container''s changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
diff Inspect changes on a container''s filesystem
events Get real time events from the server
exec Run a command in a running container
export Export a container''s filesystem as a tar archive
history Show the history of an image
images List images
import Import the contents from a tarball to create a filesystem image
info Display system-wide information
inspect Return low-level information on Docker objects
kill Kill one or more running containers
load Load an image from a tar archive or STDIN
login Log in to a Docker registry
logout Log out from a Docker registry
logs Fetch the logs of a container
pause Pause all processes within one or more containers
port List port mappings or a specific mapping for the container
ps List containers
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rename Rename a container
restart Restart one or more containers
rm Remove one or more containers
rmi Remove one or more images
run Run a command in a new container
save Save one or more images to a tar archive (streamed to STDOUT by default)
search Search the Docker Hub for images
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop one or more running containers
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
top Display the running processes of a container
unpause Unpause all processes within one or more containers
update Update configuration of one or more containers
version Show the Docker version information
wait Block until one or more containers stop, then print their exit codes
Run ''docker COMMAND --help'' for more information on a command.三.Docker 镜像操作
操作
命令
说明
检索
docker search 关键字
eg:docker search mysql
我们经常去 docker hub 上检索镜像的详细信息,如镜像的 TAG
拉取
docker pull 镜像名:tag
:tag 是可选的,tag 表示标签,多为软件的版本,默认是 latest(最新的)
列表
docker images
查看所有本地镜像
删除
docker rmi image-id
删除指定的本地镜像
1. 检索镜像
[root@localhost ~]# docker search centos默认会去 https://hub.docker.com/ 搜索,搜过结果如下
[root@localhost ~]# docker search centos
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 4709 [OK]
ansible/centos7-ansible Ansible on Centos7 118 [OK]
jdeathe/centos-ssh CentOS-6 6.10 x86_64 / CentOS-7 7.5.1804 x86… 99 [OK]
consol/centos-xfce-vnc Centos container with "headless" VNC session… 63 [OK]
imagine10255/centos6-lnmp-php56 centos6-lnmp-php56 45 [OK]
tutum/centos Simple CentOS docker image with SSH access 43
centos/mysql-57-centos7 MySQL 5.7 SQL database server 39
gluster/gluster-centos Official GlusterFS Image [ CentOS-7 + Glust… 34 [OK]
openshift/base-centos7 A Centos7 derived base image for Source-To-I… 33
centos/python-35-centos7 Platform for building and running Python 3.5… 30
centos/postgresql-96-centos7 PostgreSQL is an advanced Object-Relational … 29
kinogmt/centos-ssh CentOS with SSH 22 [OK]
openshift/jenkins-2-centos7 A Centos7 based Jenkins v2.x image for use w… 15
pivotaldata/centos-gpdb-dev CentOS image for GPDB development. Tag names… 7
openshift/wildfly-101-centos7 A Centos7 based WildFly v10.1 image for use … 5
openshift/jenkins-1-centos7 DEPRECATED: A Centos7 based Jenkins v1.x ima… 4
darksheer/centos Base Centos Image -- Updated hourly 3 [OK]
pivotaldata/centos-mingw Using the mingw toolchain to cross-compile t… 2
pivotaldata/centos Base centos, freshened up a little with a Do… 2
blacklabelops/centos CentOS Base Image! Built and Updates Daily! 1 [OK]
pivotaldata/centos-gcc-toolchain CentOS with a toolchain, but unaffiliated wi… 0
pivotaldata/centos7-test CentosOS 7 image for GPDB testing 0
pivotaldata/centos7-build CentosOS 7 image for GPDB compilation 0
smartentry/centos centos with smartentry 0 [OK]
jameseckersall/sonarr-centos Sonarr on CentOS 7 0 [OK]- NAME:仓库名称
- DESCRIPTION:镜像描述
- STARS:用户评价,反应一个镜像的受欢迎程度
- OFFICIAL:是否官方
- AUTOMATED:自动构建,表示该镜像由 Docker Hub 自动构建流程创建的
2. 拉取镜像
拉取镜像默认是从 docker hub 拉取,这是 docker 默认的公用仓库,不过缺点是国内下载会比较慢。这里设置从 ustc 拉取镜像(建议使用)。
在宿主机器编辑文件:vi /etc/docker/daemon.json,在该配置文件中加入(没有该文件的话,请先建一个):
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
最后,需要重启 docker 服务 systemctl restart docker.service 执行拉取镜像命令
[root@localhost ~]# docker pull centos
Using default tag: latest
latest: Pulling from library/centos
256b176beaff: Pull complete
Digest: sha256:6f6d986d425aeabdc3a02cb61c02abb2e78e57357e92417d6d58332856024faf
Status: Downloaded newer image for centos:latest
3. 列表镜像
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/tomcat latest 41a54fe1f79d 3 days ago 463 MB
docker.io/centos latest 5182e96772bf 5 weeks ago 200 MB- REPOSITORY:镜像所在的仓库名称
- TAG:镜像标签
- lMAGE ID:镜像 ID
- CREATED:镜像的创建日期(不是获取该镜像的日期)
- SIZE:镜像大小
这些镜像都是存储在 Docker 宿主机的 /var/lib/docker 目录下
4. 删除镜像
[root@localhost ~]# docker rmi 41a54fe1f79d四.Docker 容器操作
操作
命令
说明
运行
docker run --name container-name -d image-name
eg:docker run –name myredis –d redis
--name:自定义容器名
-d:后台运行
image-name: 指定镜像模板
列表
docker ps(查看正在运行中的容器);
docker ps -a:查看历史运行过的容器
docker ps -l:查看最近运行过的容器
停止
docker stop container-name/container-id
停止当前你运行的容器
启动
docker start container-name/container-id
启动容器
删除
docker rm container-id
删除指定容器
端口映射
-p 6379:6379
eg:docker run -d -p 6379:6379 --name myredis docker.io/redis
-p: 主机端口 (映射到) 容器内部的端口
容器日志
docker logs container-name/container-id
更多命令
https://docs.docker.com/engine/reference/commandline/docker/
1. 启动容器
1)以交互方式启动容器:docker run -it --name 容器名称 镜像 /bin/bash;
- -i:表示以 “交互模式” 运行容器
- -t:表示容器启动后会进入其命令行。加入这两个参数后,容器创建就能登录进去。即分配一个伪终端。
- --name : 为创建的容器命名。
- -v:表示目录映射关系(前者是宿主机目录,后者是映射到宿主机上的目录),可以使用多个-v 做多个目录或文件映射。注意:最好做目录映射,在宿主机上做修改,然后共享到容器上。
- -d:在 run 后面加上 -d 参数 , 则会创建一个守护式容器在后台运行(这样创建容器后不会自动登录容器,如果只加 -i -t 两个参数,创建后就会自动进去容器)。
- -p:表示端口映射,前者是宿主机端口,后者是容器内的映射端口。可以使用多个-p 做多个端口映射
创建一个交互式容器并取名为 mycentos
[root@localhost docker]# docker run -i -t --name=mycentos centos /bin/bash
2)以守护进程后台方式启动容器:docker run -d --name 容器名称 镜像
[root@localhost ~]# docker search tomcat #搜索tomcat
[root@localhost ~]# docker pull tomcat #拉取tomcat镜像
[root@localhost ~]# docker run -d --name mytomcat -p 8888:8080 tomcat:latest #启动tomcat容器,并做端口映射
[root@localhost ~]# docker ps #查看容器运行列表
2. 停止容器
docker stop 容器名称或者容器 ID
[root@localhost ~]# docker stop 62a021b1c0fd
3. 重启容器
docker start 容器名称或者容器 ID
[root@localhost ~]# docker start 62a021b1c0fd4. 删除容器
删除容器必须是已经停止的容器,删除指定容器:docker rm 容器名称或者容器 ID;删除所有容器:docker rm ‘docker ps -a -q’
[root@localhost ~]# docker rm 62a021b1c0fd
五.Docker 下部署应用程序
1. 构建镜像方案
- 方案一:直接通过 docker pull 拉取别人提交好的 tomcat、nginx 等应用程序镜像,然后基于这些镜像去创建容器。
- 方案二:通过 dockerfile 制作自己的应用程序镜像
- 方案三:根据系统镜像创建 Docker 容器,这个时候 Docker 就相当于一个虚拟机,然后进入容器部署对应的应用。具体步骤如下:
- 启动 Centos 系统镜像的容器 my_container;
- 在该容器中部署应用程序,例如:Tomcat、Nginx 等;
- 将部署完的 my_container 提交为新的镜像;
- 然后根据新的镜像去创建容器;
- 这个镜像可以打包,导入到其他的 Docker 服务器上
2. 构建 MySQL 镜像
1、 获取基础镜像 CentOS
[root@localhost ~]# docker pull centos
2、 启动容器并且在容器内部安装 MySQL
docker run -i -t --name mycentos-mysql centos /bin/bash(通过下面的命令运行 centos 容器。否则安装后的 mysql 无法启动。)
[root@localhost ~]# docker run -it --privileged --name=mycentos-mysql centos /usr/sbin/init
另起一个窗口进入容器:[root@localhost ~]# docker exec -it mycentos-mysql /bin/bash
[root@53ee11bff386 /]# yum install -y wget net-tools
[root@53ee11bff386 /]# wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
[root@53ee11bff386 /]# rpm -ivh mysql-community-release-el7-5.noarch.rpm
[root@53ee11bff386 /]# yum install mysql-community-server
3、 启动 mysql,并设置密码
[root@53ee11bff386 /]# systemctl start mysqld
[root@53ee11bff386 /]# mysql -uroot -p 回车
mysql> SET PASSWORD = PASSWORD(''123456'');
mysql> GRANT ALL PRIVILEGES ON *.* TO ''root''@''%'' IDENTIFIED BY ''123456'' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
mysql> exit;
4、 提交为新镜像
[root@localhost ~]# docker commit mycentos-mysql mysql5.6
[root@localhost ~]# docker images

5、 启动 mysql 容器
[root@localhost ~]# docker run -d -e "container=docker" --privileged=true --name mysql5.6 -p 3306:3306 mysql5.6
6、 进入容器启动 MySQL 服务
[root@localhost ~]# docker exec -it mysql5.6 /bin/bash
[root@6dda80c75bfc /]# systemctl start mysql
7、 Navicat 连接
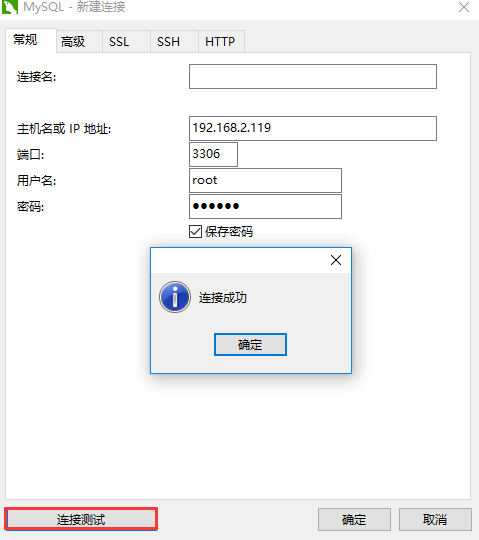
8、 上传镜像到 Docker hub
- 注册 Docker hub 账号,在 Docker Hub 注册后创建 private/public 的 Repository。
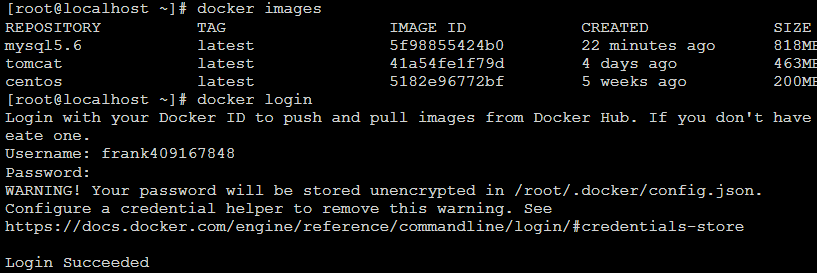
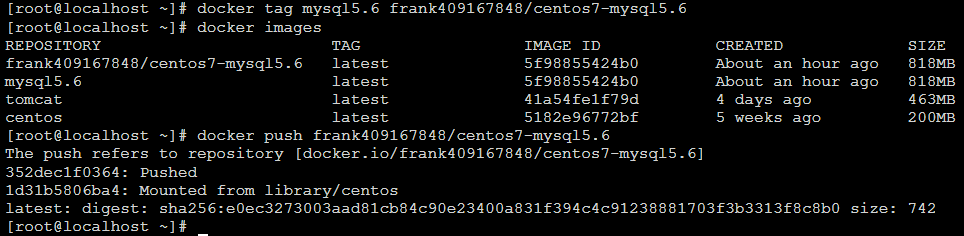
- 登录 docker login [root@localhost ~]# docker login
- tag 修改镜像名称 [root@localhost ~]# docker tag mysql5.6 frank409167848/centos7-mysql5.6
- 推送 docker push [root@localhost ~]# docker push frank409167848/centos7-mysql5.6
- Docker hub 查看
- 下载

六。报错问题
1. 启动 docker 报错
[root@localhost ~]# systemctl start docker
Job for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xe" for details.查看 docker 状态
[root@localhost ~]# systemctl status docker.service
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Sun 2018-09-16 04:13:30 EDT; 8min ago
Docs: http://docs.docker.com
Process: 2124 ExecStart=/usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=dock
er-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current --init-path=/usr/libexec/dock
er/docker-init-current --seccomp-profile=/etc/docker/seccomp.json $OPTIONS $DOCKER_STORAGE_OPTIONS $DOCKER_NETWORK_OPTIONS $ADD_REGISTRY $B
LOCK_REGISTRY $INSECURE_REGISTRY $REGISTRIES (code=exited, status=1/FAILURE)
Main PID: 2124 (code=exited, status=1/FAILURE)
Sep 16 04:13:27 localhost.localdomain systemd[1]: Starting Docker Application Container Engine...
Sep 16 04:13:29 localhost.localdomain dockerd-current[2124]: time="2018-09-16T04:13:29.348086797-04:00" level=warning msg="could no...ound"
Sep 16 04:13:29 localhost.localdomain dockerd-current[2124]: time="2018-09-16T04:13:29.365854628-04:00" level=info msg="libcontaine...2128"
Sep 16 04:13:30 localhost.localdomain dockerd-current[2124]: time="2018-09-16T04:13:30.457340010-04:00" level=warning msg="overlay2: the...
Sep 16 04:13:30 localhost.localdomain dockerd-current[2124]: Error starting daemon: SELinux is not supported with the overlay2 grap...alse)
Sep 16 04:13:30 localhost.localdomain systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE
Sep 16 04:13:30 localhost.localdomain systemd[1]: Failed to start Docker Application Container Engine.
Sep 16 04:13:30 localhost.localdomain systemd[1]: Unit docker.service entered failed state.
Sep 16 04:13:30 localhost.localdomain systemd[1]: docker.service failed.
Hint: Some lines were ellipsized, use -l to show in full.Solutions: 根据高亮的错误日志得知,此 linux 的内核中的 SELinux 不支持 overlay2 graph driver ,解决方法有两个,要么启动一个新内核,要么就在 docker 里禁用 selinux,--selinux-enabled=false
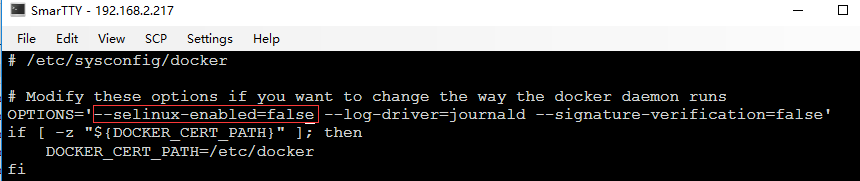
如上改为 --selinux-enabled=false 后保存,重启 docker,搞定!
2. 启动 mysql 报错
[root@dfb1cc594f9b /]# systemctl start mysql
Failed to get D-Bus connection: Operation not permitted
解决办法:
生成容器: # docker run -d -e "container=docker" --privileged=true --name mysql5.6 -p 3306:3306 mysql5.6
进入容器: # docker exec -it mysql /bin/bash
这样可以使用 systemctl 启动服务了。

100 行 shell 写个 Docker
作者:vivo 互联网运维团队- Hou Dengfeng
本文主要介绍使用shell实现一个简易的Docker。
一、目的
在初接触Docker的时候,我们必须要了解的几个概念就是Cgroup、Namespace、RootFs,如果本身对虚拟化的发展没有深入的了解,那么很难对这几个概念有深入的理解,本文的目的就是通过在操作系统中以交互式的方式去理解,Cgroup/Namespace/Rootfs到底实现了什么,能做到哪些事情,然后通过shell这种直观的命令行方式把我们的理解组合起来,去模仿Docker实现一个缩减的版本。
二、技术拆解
2.1 Namespace
2.1.1 简介
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。学习过Linux的同学应该对chroot命令比较熟悉(通过修改根目录把用户限制在一个特定目录下),chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等的隔离机制。Namespace是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace里的进程,对其他namespace中的进程没有影响。
Linux Namespace有如下种类:

2.1.2 Namespace相关系统调用
amespace相关的系统调用有3个,分别是clone(),setns(),unshare()。
- clone: 创建一个新的进程并把这个新进程放到新的namespace中
- setns: 将当前进程加入到已有的namespace中
- unshare: 使当前进程退出指定类型的namespace,并加入到新创建的namespace中
2.1.3 查看进程所属Namespace
上面的概念都比较抽象,我们来看看在Linux系统中怎么样去get namespace。
系统中的每个进程都有/proc/[pid]/ns/这样一个目录,里面包含了这个进程所属namespace的信息,里面每个文件的描述符都可以用来作为setns函数(2.1.2)的fd参数。
#查看当前bash进程关联的Namespace
# ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Jan 17 21:43 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 uts -> uts:[4026531838]
#这些 namespace 文件都是链接文件。链接文件的内容的格式为 xxx:[inode number]。
其中的 xxx 为 namespace 的类型,inode number 则用来标识一个 namespace,我们也可以把它理解为 namespace 的 ID。
如果两个进程的某个 namespace 文件指向同一个链接文件,说明其相关资源在同一个 namespace 中。以ipc:[4026531839]例,
ipc是namespace的类型,4026531839是inode number,如果两个进程的ipc namespace的inode number一样,说明他们属于同一个namespace。
这条规则对其他类型的namespace也同样适用。
#从上面的输出可以看出,对于每种类型的namespace,进程都会与一个namespace ID关联。
#当一个namespace中的所有进程都退出时,该namespace将会被销毁。在 /proc/[pid]/ns 里放置这些链接文件的作用就是,一旦这些链接文件被打开,
只要打开的文件描述符(fd)存在,那么就算该 namespace 下的所有进程都结束了,但这个 namespace 也会一直存在,后续的进程还可以再加入进来。2.1.4 相关命令及操作示例
本节会用UTS/IPC/NET 3个Namespace作为示例演示如何在linux系统中创建Namespace,并介绍相关命令。
2.1.4.1 IPC Namespace
IPC namespace用来隔离System V IPC objects和POSIX message queues。其中System V IPC objects包含消息列表Message queues、信号量Semaphore sets和共享内存Shared memory segments。为了展现区分IPC Namespace我们这里会使用到ipc相关命令:
# nsenter: 加入指定进程的指定类型的namespace中,然后执行参数中指定的命令。
# 命令格式:nsenter [options] [program [arguments]]
# 示例:nsenter –t 27668 –u –I /bin/bash
#
# unshare: 离开当前指定类型的namespace,创建且加入新的namesapce,然后执行参数中执行的命令。
# 命令格式:unshare [options] program [arguments]
# 示例:unshare --fork --pid --mount-proc readlink /proc/self
#
# ipcmk:创建shared memory segments, message queues, 和semaphore arrays
# 参数-Q:创建message queues
# ipcs:查看shared memory segments, message queues, 和semaphore arrays的相关信息
# 参数-a:显示全部可显示的信息
# 参数-q:显示活动的消息队列信息下面将以消息队列为例,演示一下隔离效果,为了使演示更直观,我们在创建新的ipc namespace的时候,同时也创建新的uts namespace,然后为新的uts namespace设置新hostname,这样就能通过shell提示符一眼看出这是属于新的namespace的bash。示例中我们用两个shell来展示:
shell A
#查看当前shell的uts / ipc namespace number
# readlink /proc/$$/ns/uts /proc/$$/ns/ipc
uts:[4026531838]
ipc:[4026531839]
#查看当前主机名
# hostname
myCentos
#查看ipc message queues,默认情况下没有message queue
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
#创建一个message queue
# ipcmk -Q
Message queue id: 131072
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x82a1d963 131072 root 644 0 0
-----> 切换至shell B执行
------------------------------------------------------------------
#回到shell A之后我们可以看下hostname、ipc等有没有收到影响
# hostname
myCentos
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x82a1d963 131072 root 644 0 0
#接下来我们尝试加入shell B中新的Namespace
# nsenter -t 30372 -u -i /bin/bash
[root@shell-B:/root]
# hostname
shell-B
# readlink /proc/$$/ns/uts /proc/$$/ns/ipc
uts:[4026532382]
ipc:[4026532383]
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
#可以看到我们已经成功的加入到了新的Namespace中shell B
#确认当前shell和shell A属于相同Namespace
# readlink /proc/$$/ns/uts /proc/$$/ns/ipc
uts:[4026531838]
ipc:[4026531839]
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x82a1d963 131072 root 644 0 0
#使用unshare创建新的uts和ipc Namespace,并在新的Namespace中启动bash
# unshare -iu /bin/bash
#确认新的bash uts/ipc Namespace Number
# readlink /proc/$$/ns/uts /proc/$$/ns/ipc
uts:[4026532382]
ipc:[4026532383]
#设置新的hostname与shell A做区分
# hostname shell-B
# hostname
shell-B
#查看之前的ipc message queue
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
#查看当前bash进程的PID
# echo $$
30372
切换回shell A <-----2.1.4.2 Net Namespace
Network namespace用来隔离网络设备, IP地址, 端口等. 每个namespace将会有自己独立的网络栈,路由表,防火墙规则,socket等。每个新的network namespace默认有一个本地环回接口,除了lo接口外,所有的其他网络设备(物理/虚拟网络接口,网桥等)只能属于一个network namespace。每个socket也只能属于一个network namespace。当新的network namespace被创建时,lo接口默认是关闭的,需要自己手动启动起。标记为"local devices"的设备不能从一个namespace移动到另一个namespace,比如loopback, bridge, ppp等,我们可以通过ethtool -k命令来查看设备的netns-local属性。
我们使用以下命令来创建net namespace。
相关命令:
ip netns: 管理网络namespace
用法:
ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]下面使用ip netns来演示创建net Namespace。
shell A
#创建一对网卡,分别命名为veth0_11/veth1_11
# ip link add veth0_11 type veth peer name veth1_11
#查看已经创建的网卡
#ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 5e:75:97:0d:54:17 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
3: br1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/24 scope global br1
valid_lft forever preferred_lft forever
96: veth1_11@veth0_11: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff
97: veth0_11@veth1_11: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff
#使用ip netns创建两个net namespace
# ip netns add r1
# ip netns add r2
# ip netns list
r2
r1 (id: 0)
#将两个网卡分别加入到对应的netns中
# ip link set veth0_11 netns r1
# ip link set veth1_11 netns r2
#再次查看网卡,在bash当前的namespace中已经看不到veth0_11和veth1_11了
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 5e:75:97:0d:54:17 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
3: br1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/24 scope global br1
valid_lft forever preferred_lft forever
#接下来我们切换到对应的netns中对网卡进行配置
#通过nsenter --net可以切换到对应的netns中,ip a展示了我们上面加入到r1中的网卡
# nsenter --net=/var/run/netns/r1 /bin/bash
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
97: veth0_11@if96: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
#对网卡配置ip并启动
# ip addr add 172.18.0.11/24 dev veth0_11
# ip link set veth0_11 up
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
97: veth0_11@if96: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 172.18.0.11/24 scope global veth0_11
valid_lft forever preferred_lft forever
-----> 切换至shell B执行
------------------------------------------------------------------
#在r1中ping veth1_11
# ping 172.18.0.12
PING 172.18.0.12 (172.18.0.12) 56(84) bytes of data.
64 bytes from 172.18.0.12: icmp_seq=1 ttl=64 time=0.033 ms
64 bytes from 172.18.0.12: icmp_seq=2 ttl=64 time=0.049 ms
...
#至此我们通过netns完成了创建net Namespace的小实验shell B
#在shell B中我们同样切换到netns r2中进行配置
#通过nsenter --net可以切换到r2,ip a展示了我们上面加入到r2中的网卡
# nsenter --net=/var/run/netns/r2 /bin/bash
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
96: veth1_11@if97: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff link-netnsid 0
#对网卡配置ip并启动
# ip addr add 172.18.0.12/24 dev veth1_11
# ip link set veth1_11 up
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
96: veth1_11@if97: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.12/24 scope global veth1_11
valid_lft forever preferred_lft forever
inet6 fe80::5c75:97ff:fe0d:540e/64 scope link
valid_lft forever preferred_lft forever
#尝试ping r1中的网卡
# ping 172.18.0.11
PING 172.18.0.11 (172.18.0.11) 56(84) bytes of data.
64 bytes from 172.18.0.11: icmp_seq=1 ttl=64 time=0.046 ms
64 bytes from 172.18.0.11: icmp_seq=2 ttl=64 time=0.040 ms
...
#可以完成通信
切换至shell A执行 <-----示意图

2.2 Cgroup
2.2.1 简介
Cgroup和namespace类似,也是将进程进行分组,但它的目的和namespace不一样,namespace是为了隔离进程组之间的资源,而cgroup是为了对一组进程进行统一的资源监控和限制。
Cgroup作用:
- 资源限制(Resource limiting): Cgroups可以对进程组使用的资源总额进行限制。如对特定的进程进行内存使用上限限制,当超出上限时,会触发OOM。
- 优先级分配(Prioritization): 通过分配的CPU时间片数量及硬盘IO带宽大小,实际上就相当于控制了进程运行的优先级。
- 资源统计(Accounting): Cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等等,这个功能非常适用于计费。
- 进程控制(Control):Cgroups可以对进程组执行挂起、恢复等操作。
Cgroups的组成:
- task: 在Cgroups中,task就是系统的一个进程。
- cgroup: Cgroups中的资源控制都以cgroup为单位实现的。cgroup表示按照某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。
- subsystem: 一个subsystem就是一个内核模块,被关联到一颗cgroup树之后,就会在树的每个节点(进程组)上做具体的操作。subsystem经常被称作"resource controller",因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如perf_event subsystem。到目前为止,Linux支持13种subsystem(Cgroup v1),比如限制CPU的使用时间,限制使用的内存,统计CPU的使用情况,冻结和恢复一组进程等。
- hierarchy: 一个hierarchy可以理解为一棵cgroup树,树的每个节点就是一个进程组,每棵树都会与零到多个subsystem关联。在一颗树里面,会包含Linux系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗cgroup树,每棵树都和不同的subsystem关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的subsystem关联。如果不考虑不与任何subsystem关联的情况(systemd就属于这种情况),Linux里面最多可以建13颗cgroup树,每棵树关联一个subsystem,当然也可以只建一棵树,然后让这棵树关联所有的subsystem。当一颗cgroup树不和任何subsystem关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd就是一个这样的例子。
2.2.2 查看Cgroup信息
查看当前系统支持的subsystem
#通过/proc/cgroups查看当前系统支持哪些subsystem
# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 11 1 1
cpu 4 67 1
cpuacct 4 67 1
memory 5 69 1
devices 7 62 1
freezer 8 1 1
net_cls 6 1 1
blkio 9 62 1
perf_event 3 1 1
hugetlb 2 1 1
pids 10 62 1
net_prio 6 1 1
#字段含义
#subsys_name: subsystem的名称
#hierarchy:subsystem所关联到的cgroup树的ID,如果多个subsystem关联到同一颗cgroup树,那么他们的这个字段将一样,比如这里的cpu和cpuacct就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为0:
当前subsystem没有和任何cgroup树绑定
当前subsystem已经和cgroup v2的树绑定
当前subsystem没有被内核开启
#num_cgroups: subsystem所关联的cgroup树中进程组的个数,也即树上节点的个数
#enabled: 1表示开启,0表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制subsystem的开启).查看进程所属cgroup
#查看当前shell进程所属的cgroup
# cat /proc/$$/cgroup
11:cpuset:/
10:pids:/system.slice/sshd.service
9:blkio:/system.slice/sshd.service
8:freezer:/
7:devices:/system.slice/sshd.service
6:net_prio,net_cls:/
5:memory:/system.slice/sshd.service
4:cpuacct,cpu:/system.slice/sshd.service
3:perf_event:/
2:hugetlb:/
1:name=systemd:/system.slice/sshd.service
#字段含义(以冒号分为3列):
# 1. cgroup树ID,对应/proc/cgroups中的hierachy
# 2. cgroup所绑定的subsystem,多个subsystem使用逗号分隔。name=systemd表示没有和任何subsystem绑定,只是给他起了个名字叫systemd。
# 3. 进程在cgroup树中的路径,即进程所属的cgroup,这个路径是相对于挂载点的相对路径。2.2.3 相关命令
使用cgroup
cgroup相关的所有操作都是基于内核中的cgroup virtual filesystem,使用cgroup很简单,挂载这个文件系统就可以了。一般情况下都是挂载到/sys/fs/cgroup目录下,当然挂载到其它任何目录都没关系。
查看下当前系统cgroup挂载情况。
#过滤系统挂载可以查看cgroup
# mount |grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
#如果系统中没有挂载cgroup,可以使用mount命令创建cgroup
#挂载根cgroup
# mkdir /sys/fs/cgroup
# mount -t tmpfs cgroup_root /sys/fs/cgroup
#将cpuset subsystem关联到/sys/fs/cgroup/cpu_memory
# mkdir /sys/fs/cgroup/cpuset
# sudo mount -t cgroup cpuset -o cgroup /sys/fs/cgroup/cpuset/
#将cpu和memory subsystem关联到/sys/fs/cgroup/cpu_memory
# mkdir /sys/fs/cgroup/cpu_memory
# sudo mount -n -t cgroup -o cpu,memory cgroup /sys/fs/cgroup/cpu_memory除了mount命令之外我们还可以使用以下命令对cgroup进行创建、属性设置等操作,这也是我们后面脚本中用于创建和管理cgroup的命令。
# Centos操作系统可以通过yum install cgroup-tools 来安装以下命令
cgcreate: 在层级中创建新cgroup。
用法: cgcreate [-h] [-t <tuid>:<tgid>] [-a <agid>:<auid>] [-f mode] [-d mode] [-s mode]
-g <controllers>:<path> [-g ...]
示例: cgcreate -g *:student -g devices:teacher //在所有的挂载hierarchy中创建student cgroup,在devices
hierarchy挂载点创建teacher cgroup
cgset: 设置指定cgroup(s)的参数
用法: cgset [-r <name=value>] <cgroup_path> ...
示例: cgset -r cpuset.cpus=0-1 student //将student cgroup的cpuset控制器中的cpus限制为0-1
cgexec: 在指定的cgroup中运行任务
用法: cgexec [-h] [-g <controllers>:<path>] [--sticky] command [arguments]
示例: cgexec -g cpu,memory:test1 ls -l //在cpu和memory控制器下的test1 cgroup中运行ls -l命令
2.3 Rootfs
2.3.1 简介
Rootfs 是 Docker 容器在启动时内部进程可见的文件系统,即 Docker容器的根目录。rootfs 通常包含一个操作系统运行所需的文件系统,例如可能包含典型的类 Unix 操作系统中的目录系统,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及运行 Docker 容器所需的配置文件、工具等。
就像Linux启动会先用只读模式挂载rootfs,运行完完整性检查之后,再切换成读写模式一样。Docker deamon为container挂载rootfs时,也会先挂载为只读模式,但是与Linux做法不同的是,在挂载完只读的rootfs之后,Docker deamon会利用联合挂载技术(Union Mount)在已有的rootfs上再挂一个读写层。container在运行过程中文件系统发生的变化只会写到读写层,并通过whiteout技术隐藏只读层中的旧版本文件。
Docker支持不同的存储驱动,包括 aufs、devicemapper、overlay2、zfs 和 vfs 等,目前在 Docker 中,overlay2 取代了 aufs 成为了推荐的存储驱动。
2.3.2 overlayfs
overlayFS是联合挂载技术的一种实现。除了overlayFS以外还有aufs,VFS,Brtfs,device mapper等技术。虽然实现细节不同,但是他们做的事情都是相同的。Linux内核为Docker提供的overalyFS驱动有2种:overlay2和overlay,overlay2是相对于overlay的一种改进,在inode利用率方面比overlay更有效。
overlayfs通过三个目录来实现:lower目录、upper目录、以及work目录。三种目录合并出来的目录称为merged目录。
- lower:可以是多个,是处于最底层的目录,作为只读层。
- upper:只有一个,作为读写层。
- work:为工作基础目录,挂载后内容会被清空,且在使用过程中其内容用户不可见。
- merged:为最后联合挂载完成给用户呈现的统一视图,也就是说merged目录里面本身并没有任何实体文件,给我们展示的只是参与联合挂载的目录里面文件而已,真正的文件还是在lower和upper中。所以,在merged目录下编辑文件,或者直接编辑lower或upper目录里面的文件都会影响到merged里面的视图展示。

2.3.3 文件规则
merged层目录会显示离它最近层的文件。层级关系中upperdir比lowerdir更靠近merged层,而多个lowerdir的情况下,写的越靠前的目录离merged层目录越近。相同文件名的文件会依照层级规则进行“覆盖”。
2.3.4 overlayFS如何工作
读:
- 如果文件在容器层(upperdir),直接读取文件;
- 如果文件不在容器层(upperdir),则从镜像层(lowerdir)读取;
写:
- ①首次写入: 如果在upperdir中不存在,overlay执行cow操作,把文件从lowdir拷贝到upperdir,由于overlayfs是文件级别的(即使文件只有很少的一点修改,也会产生的cow的行为),后续对同一文件的在此写入操作将对已经复制到容器的文件的副本进行操作。值得注意的是,cow操作只发生在文件首次写入,以后都是只修改副本。
- ②删除文件和目录: 当文件在容器被删除时,在容器层(upperdir)创建whiteout文件,镜像层(lowerdir)的文件是不会被删除的,因为他们是只读的,但whiteout文件会阻止他们显示。
2.3.5 在系统里创建overlayfs
shell
# 创建所需的目录
# mkdir upper lower merged work
# echo "lower" > lower/in_lower.txt
# echo "upper" > upper/in_upper.txt
# 在lower和upper中都创建 in_both文件
# echo "lower" > lower/in_both.txt
# echo "upper" > upper/in_both.txt
#查看下我们当前的目录及文件结构
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
|-- upper
| |-- in_both.txt
| `-- in_upper.txt
`-- work
#使用mount命令将创建的目录联合挂载起来
# mount -t overlay overlay -o lowerdir=lower,upperdir=upper,workdir=work merged
#查看mount结果可以看到已经成功挂载了
# mount |grep overlay
overlay on /data/overlay_demo/merged type overlay (rw,relatime,lowerdir=lower,upperdir=upper,workdir=work)
#此时再查看文件目录结构
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
| |-- in_both.txt
| |-- in_lower.txt
| `-- in_upper.txt
|-- upper
| |-- in_both.txt
| `-- in_upper.txt
`-- work
`-- work
#可以看到merged中包含了lower和upper中的文件
#然后我查看merge中的in_both文件,验证了上层目录覆盖下层的结论
# cat merged/in_both.txt
upper
#上面我们验证了挂载后overlayfs的读,接下来我们去验证下写
#我们在merged中创建一个新文件,并查看
# touch merged/new_file
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
| |-- in_both.txt
| |-- in_lower.txt
| |-- in_upper.txt
| `-- new_file
|-- upper
| |-- in_both.txt
| |-- in_upper.txt
| `-- new_file
`-- work
`-- work
#可以看到新文件实际是放在了upper目录中
#下面我们看下如果删除了lower和upper中都有的文件会怎样
# rm -f merged/in_both.txt
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
| |-- in_lower.txt
| |-- in_upper.txt
| `-- new_file
|-- upper
| |-- in_both.txt
| |-- in_upper.txt
| `-- new_file
`-- work
`-- work
#从文件目录上看只有merge中没有了in_both文件,但是upper中的文件已经发生了变化
# ll upper/in_both.txt
c--------- 1 root root 0, 0 Jan 21 19:33 upper/in_both.txt
#upper/in_both.txt已经变成了一个空的字符文件,且覆盖了lower层的内容三 、Bocker
3.1 功能演示
第二部分中我们对Namespace,cgroup,overlayfs有了一定的了解,接下来我们通过一个脚本来实现个建议的Docker。脚本源自于https://github.com/p8952/bocker,我做了image/pull/存储驱动的部分修改,下面先看下脚本完成后的示例:

3.2 完整脚本
脚本一共用130行代码,完成了上面的功能,也算符合我们此次的标题了。为了大家可以更深入的理解脚本内容,这里就不再对脚本进行拆分讲解,以下是完整脚本。
#!/usr/bin/env bash
set -o errexit -o nounset -o pipefail; shopt -s nullglob
overlay_path=''/var/lib/bocker/overlay'' && container_path=''/var/lib/bocker/containers'' && cgroups=''cpu,cpuacct,memory'';
[[ $# -gt 0 ]] && while [ "${1:0:2}" == ''--'' ]; do OPTION=${1:2}; [[ $OPTION =~ = ]] && declare "BOCKER_${OPTION/=*/}=${OPTION/*=/}" || declare "BOCKER_${OPTION}=x"; shift; done
function bocker_check() {
case ${1:0:3} in
img) ls "$overlay_path" | grep -qw "$1" && echo 0 || echo 1;;
ps_) ls "$container_path" | grep -qw "$1" && echo 2 || echo 3;;
esac
}
function bocker_init() { #HELP Create an image from a directory:\nBOCKER init <directory>
uuid="img_$(shuf -i 42002-42254 -n 1)"
if [[ -d "$1" ]]; then
[[ "$(bocker_check "$uuid")" == 0 ]] && bocker_run "$@"
mkdir "$overlay_path/$uuid" > /dev/null
cp -rf --reflink=auto "$1"/* "$overlay_path/$uuid" > /dev/null
[[ ! -f "$overlay_path/$uuid"/img.source ]] && echo "$1" > "$overlay_path/$uuid"/img.source
[[ ! -d "$overlay_path/$uuid"/proc ]] && mkdir "$overlay_path/$uuid"/proc
echo "Created: $uuid"
else
echo "No directory named ''$1'' exists"
fi
}
function bocker_pull() { #HELP Pull an image from Docker Hub:\nBOCKER pull <name> <tag>
tmp_uuid="$(uuidgen)" && mkdir /tmp/"$tmp_uuid"
download-frozen-image-v2 /tmp/"$tmp_uuid" "$1:$2" > /dev/null
rm -rf /tmp/"$tmp_uuid"/repositories
for tar in $(jq ''.[].Layers[]'' --raw-output < /tmp/$tmp_uuid/manifest.json); do
tar xf /tmp/$tmp_uuid/$tar -C /tmp/$tmp_uuid && rm -rf /tmp/$tmp_uuid/$tar
done
for config in $(jq ''.[].Config'' --raw-output < /tmp/$tmp_uuid/manifest.json); do
rm -f /tmp/$tmp_uuid/$config
done
echo "$1:$2" > /tmp/$tmp_uuid/img.source
bocker_init /tmp/$tmp_uuid && rm -rf /tmp/$tmp_uuid
}
function bocker_rm() { #HELP Delete an image or container:\nBOCKER rm <image_id or container_id>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named ''$1'' exists" && exit 1
[[ "$(bocker_check "$1")" == 1 ]] && echo "No image named ''$1'' exists" && exit 1
if [[ -d "$overlay_path/$1" ]];then
rm -rf "$overlay_path/$1" && echo "Removed: $1"
else
umount "$container_path/$1"/merged && rm -rf "$container_path/$1" && ip netns del netns_"$1" && ip link del dev veth0_"$1" && echo "Removed: $1"
cgdelete -g "$cgroups:/$1" &> /dev/null
fi
}
function bocker_images() { #HELP List images:\nBOCKER images
echo -e "IMAGE_ID\t\tSOURCE"
for img in "$overlay_path"/img_*; do
img=$(basename "$img")
echo -e "$img\t\t$(cat "$overlay_path/$img/img.source")"
done
}
function bocker_ps() { #HELP List containers:\nBOCKER ps
echo -e "CONTAINER_ID\t\tCOMMAND"
for ps in "$container_path"/ps_*; do
ps=$(basename "$ps")
echo -e "$ps\t\t$(cat "$container_path/$ps/$ps.cmd")"
done
}
function bocker_run() { #HELP Create a container:\nBOCKER run <image_id> <command>
uuid="ps_$(shuf -i 42002-42254 -n 1)"
[[ "$(bocker_check "$1")" == 1 ]] && echo "No image named ''$1'' exists" && exit 1
[[ "$(bocker_check "$uuid")" == 2 ]] && echo "UUID conflict, retrying..." && bocker_run "$@" && return
cmd="${@:2}" && ip="$(echo "${uuid: -3}" | sed ''s/0//g'')" && mac="${uuid: -3:1}:${uuid: -2}"
ip link add dev veth0_"$uuid" type veth peer name veth1_"$uuid"
ip link set dev veth0_"$uuid" up
ip link set veth0_"$uuid" master br1
ip netns add netns_"$uuid"
ip link set veth1_"$uuid" netns netns_"$uuid"
ip netns exec netns_"$uuid" ip link set dev lo up
ip netns exec netns_"$uuid" ip link set veth1_"$uuid" address 02:42:ac:11:00"$mac"
ip netns exec netns_"$uuid" ip addr add 172.18.0."$ip"/24 dev veth1_"$uuid"
ip netns exec netns_"$uuid" ip link set dev veth1_"$uuid" up
ip netns exec netns_"$uuid" ip route add default via 172.18.0.1
mkdir -p "$container_path/$uuid"/{lower,upper,work,merged} && cp -rf --reflink=auto "$overlay_path/$1"/* "$container_path/$uuid"/lower > /dev/null && \
mount -t overlay overlay \
-o lowerdir="$container_path/$uuid"/lower,upperdir="$container_path/$uuid"/upper,workdir="$container_path/$uuid"/work \
"$container_path/$uuid"/merged
echo ''nameserver 114.114.114.114'' > "$container_path/$uuid"/merged/etc/resolv.conf
echo "$cmd" > "$container_path/$uuid/$uuid.cmd"
cgcreate -g "$cgroups:/$uuid"
: "${BOCKER_CPU_SHARE:=512}" && cgset -r cpu.shares="$BOCKER_CPU_SHARE" "$uuid"
: "${BOCKER_MEM_LIMIT:=512}" && cgset -r memory.limit_in_bytes="$((BOCKER_MEM_LIMIT * 1000000))" "$uuid"
cgexec -g "$cgroups:$uuid" \
ip netns exec netns_"$uuid" \
unshare -fmuip --mount-proc \
chroot "$container_path/$uuid"/merged \
/bin/sh -c "/bin/mount -t proc proc /proc && $cmd" \
2>&1 | tee "$container_path/$uuid/$uuid.log" || true
ip link del dev veth0_"$uuid"
ip netns del netns_"$uuid"
}
function bocker_exec() { #HELP Execute a command in a running container:\nBOCKER exec <container_id> <command>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named ''$1'' exists" && exit 1
cid="$(ps o ppid,pid | grep "^$(ps o pid,cmd | grep -E "^\ *[0-9]+ unshare.*$1" | awk ''{print $1}'')" | awk ''{print $2}'')"
[[ ! "$cid" =~ ^\ *[0-9]+$ ]] && echo "Container ''$1'' exists but is not running" && exit 1
nsenter -t "$cid" -m -u -i -n -p chroot "$container_path/$1"/merged "${@:2}"
}
function bocker_logs() { #HELP View logs from a container:\nBOCKER logs <container_id>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named ''$1'' exists" && exit 1
cat "$container_path/$1/$1.log"
}
function bocker_commit() { #HELP Commit a container to an image:\nBOCKER commit <container_id> <image_id>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named ''$1'' exists" && exit 1
[[ "$(bocker_check "$2")" == 0 ]] && echo "Image named ''$2'' exists" && exit 1
mkdir "$overlay_path/$2" && cp -rf --reflink=auto "$container_path/$1"/merged/* "$overlay_path/$2" && sed -i "s/:.*$/:$(date +%Y%m%d-%H%M%S)/g" "$overlay_path/$2"/img.source
echo "Created: $2"
}
function bocker_help() { #HELP Display this message:\nBOCKER help
sed -n "s/^.*#HELP\\s//p;" < "$1" | sed "s/\\\\n/\n\t/g;s/$/\n/;s!BOCKER!${1/!/\\!}!g"
}
[[ -z "${1-}" ]] && bocker_help "$0" && exit 1
case $1 in
pull|init|rm|images|ps|run|exec|logs|commit) bocker_"$1" "${@:2}" ;;
*) bocker_help "$0" ;;
esacREADMEBocker
- 使用100行bash实现一个docker,本脚本是依据bocker实现,更换了存储驱动,完善了pull等功能。
前置条件
为了脚本能够正常运行,机器上需要具备以下组件:
- overlayfs
- iproute2
- iptables
- libcgroup-tools
- util-linux >= 2.25.2
- coreutils >= 7.5
大部分功能在centos7上都是满足的,overlayfs可以通过modprobe overlay挂载。
另外你可能还要做以下设置:
- 创建bocker运行目录 /var/lib/bocker/overlay,/var/lib/bocker/containers
- 创建一个IP地址为 172.18.0.1/24 的桥接网卡 br1
- 确认开启IP转发 /proc/sys/net/ipv4/ip_forward = 1
- 创建iptables规则将桥接网络流量转发至物理网卡,示例:iptables -t nat -A POSTROUTING -s 172.18.0.0/24 -o eth0 -j MASQUERADE
实现的功能
- docker build +
- docker pull
- docker images
- docker ps
- docker run
- docker exec
- docker logs
- docker commit
- docker rm / docker rmi
- Networking
- Quota Support / CGroups
- +bocker init 提供了有限的 bocker build 能力
四、总结
到此本文要介绍的内容就结束了,正如开篇我们提到的,写出最终的脚本实现这样一个小玩意并没有什么实用价值,真正的价值是我们通过100行左右的脚本,以交互式的方式去理解Docker的核心技术点。在工作中与容器打交道时能有更多的思路去排查、解决问题。

bash – 使用shell脚本在Docker容器内运行脚本
#!bin/bash docker run -t -i -p 5902:5902 --name "mycontainer" --privileged myImage:new /bin/bash
运行此脚本文件将在新调用的bash中运行该容器。
现在我需要运行一个脚本文件(test.sh),它已经在上面给出的shell脚本里面的容器内(例如:cd /path/to/test.sh&& ./test.sh)
如何做到这一点,请随时询问这个情况是否不清楚。
docker exec mycontainer /path/to/test.sh
并从bash会话运行:
docker exec -it mycontainer /bin/bash
从那里你可以运行你的脚本或任何东西。

Bocker —— Shell 实现的 Docker

Bocker 是一个用大约 100 行代码实现的 Docker。
Docker EE/Docker CE简介与版本规划")
Docker 17.03系列教程(一)Docker EE/Docker CE简介与版本规划
近日,Docker发布了Docker 17.03。进入Docker 17时代后,Docker分成了两个版本:Docker EE和Docker CE,即:企业版(EE)和社区版(CE)。那么这两个版本有什么区别呢?不仅如此,Docker进入17.03后,版本命名方式跟之前完全不同,以后Docker又会有怎样的版本迭代计划呢?本文将为您一一解答。
版本区别
Docker EE
Docker EE由公司支持,可在经过认证的操作系统和云提供商中使用,并可运行来自Docker Store的、经过认证的容器和插件。
Docker EE提供三个服务层次:
| 服务层级 | 功能 |
|---|---|
| Basic | 包含用于认证基础设施的Docker平台 Docker公司的支持 经过认证的、来自Docker Store的容器与插件 |
| Standard | 添加高级镜像与容器管理 LDAP/AD用户集成 基于角色的访问控制(Docker Datacenter) |
| Advanced | 添加Docker安全扫描 连续漏洞监控 |
大家可在该页查看各个服务层次的价目:https://www.docker.com/pricing 。
Docker CE
Docker CE是免费的Docker产品的新名称,Docker CE包含了完整的Docker平台,非常适合开发人员和运维团队构建容器APP。事实上,Docker CE 17.03,可理解为Docker 1.13.1的Bug修复版本。因此,从Docker 1.13升级到Docker CE 17.03风险相对是较小的。
大家可前往Docker的RELEASE log查看详情https://github.com/docker/docker/releases 。
Docker公司认为,Docker CE和EE版本的推出为Docker的生命周期、可维护性以及可升级性带来了巨大的改进。
版本迭代计划
Docker从17.03开始,转向基于时间的YY.MM 形式的版本控制方案,类似于Canonical为Ubuntu所使用的版本控制方案。
Docker CE有两种版本:
edge版本每月发布一次,主要面向那些喜欢尝试新功能的用户。
stable版本每季度发布一次,适用于希望更加容易维护的用户(稳定版)。
edge版本只能在当前月份获得安全和错误修复。而stable版本在初始发布后四个月内接收关键错误修复和安全问题的修补程序。这样,Docker CE用户就有一个月的窗口期来切换版本到更新的版本。举个例子,Docker CE 17.03会维护到17年07月;而Docker CE 17.03的下个稳定版本是CE 17.06,这样,6-7月这个时间窗口,用户就可以用来切换版本了。
Docker EE和stable版本的版本号保持一致,每个Docker EE版本都享受为期一年的支持与维护期,在此期间接受安全与关键修正。

总结
- Docker从17.03开始分为企业版与社区版,社区版并非阉割版,而是改了个名称;企业版则提供了一些收费的高级特性。
- EE版本维护期1年;CE的stable版本三个月发布一次,维护期四个月;另外CE还有edge版,一个月发布一次。
参考文档
- https://blog.docker.com/2017/03/docker-enterprise-edition/
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
关注我
博客:http://www.itmuch.com
微信公众号:

关于Docker 简介与 shell 操作使用和shell docker命令的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于100 行 shell 写个 Docker、bash – 使用shell脚本在Docker容器内运行脚本、Bocker —— Shell 实现的 Docker、Docker 17.03系列教程(一)Docker EE/Docker CE简介与版本规划等相关内容,可以在本站寻找。
本文标签:




