在本文中,您将会了解到关于给定无向图设计算法的新资讯,同时我们还将为您解释设无向图g,要求给出的相关在本文中,我们将带你探索给定无向图设计算法的奥秘,分析设无向图g,要求给出的特点,并给出一些关于12
在本文中,您将会了解到关于给定无向图设计算法的新资讯,同时我们还将为您解释设无向图g,要求给出的相关在本文中,我们将带你探索给定无向图设计算法的奥秘,分析设无向图g,要求给出的特点,并给出一些关于12.boost 有向图无向图 (矩阵法)、15、【图】邻接矩阵无向图和邻接表无向图、2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也、C#图表算法之无向图的实用技巧。
本文目录一览:- 给定无向图设计算法(设无向图g,要求给出)
- 12.boost 有向图无向图 (矩阵法)
- 15、【图】邻接矩阵无向图和邻接表无向图
- 2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也
- C#图表算法之无向图
")
给定无向图设计算法(设无向图g,要求给出)
有一个简单的方法可以解决此问题:
- 为
V - H运行Dijkstra,即除H中的节点以外的所有节点。令输出为dist。 - 对于
i中的每个节点H,最短路径的长度为min {dist[j] + w[i][j]},其中min应用于{{1 }}(如果我们有一个邻接列表而不是矩阵,可以提高效率。)
因此,基本上,使用Dijkstra在j中找到到节点 not 的最短路径。这样,到V-H中节点的最短路径就是从H中的节点到自身的最短扩展。 (对于H中未直接连接到V-H的节点,它们将∞作为问题状态。)
根据@jrook的评论,您提到所有边缘的长度都相同。然后,可以使用BFS代替Dijkstra。
另一个解决方案是在图形的修改版本上运行BFS:
- 同时删除
H中节点内的所有边缘。 - 使
V-H和H中的节点之间的边缘指向从V-H到H的方向。 - 通过在两个方向上添加有向边来使所有其他边(即
V-H中的节点之间的边)有向。
在此修改后的有向图中,您可以应用BFS或Dijkstra来找到所需条件的最短路径。
")
12.boost 有向图无向图 (矩阵法)
1 #include <iostream>
2 #include <boost/config.hpp>
3 //图
4 #include <boost/graph/adjacency_matrix.hpp>
5 #include <boost\graph\graph_utility.hpp>
6
7 using namespace std;
8 using namespace boost;
9
10 //顶点名称
11 enum { A, B, C, D, E, F };
12 //顶点个数
13 #define N 6
14 const char *name = "ABCDEF";
15
16 //无向图
17 void main1()
18 {
19 adjacency_matrix<undirectedS> myg(N);
20 add_edge(A, B, myg);
21 add_edge(A, C, myg);
22 add_edge(A, D, myg);
23 add_edge(A, E, myg);
24 add_edge(B, C, myg);
25 add_edge(F, C, myg);
26
27 cout << "顶点" << endl;
28 print_vertices(myg, name);
29 cout << endl;
30
31 cout << "边" << endl;
32 print_edges(myg, name);
33 cout << endl;
34
35 cout << "关联" << endl;
36 print_graph(myg, name);
37 cout << endl;
38
39 cin.get();
40 }
41
42 //有向图
43 void main2()
44 {
45 adjacency_matrix<directedS> myg(N);
46 add_edge(A, B, myg);
47 add_edge(A, C, myg);
48 add_edge(A, D, myg);
49 add_edge(A, E, myg);
50 add_edge(B, C, myg);
51 add_edge(F, C, myg);
52
53 cout << "顶点" << endl;
54 print_vertices(myg, name);
55 cout << endl;
56
57 cout << "边" << endl;
58 print_edges(myg, name);
59 cout << endl;
60
61 cout << "关联" << endl;
62 print_graph(myg, name);
63 cout << endl;
64 cin.get();
65 }

15、【图】邻接矩阵无向图和邻接表无向图
一、邻接矩阵无向图的介绍
邻接矩阵无向图是指通过邻接矩阵表示的无向图。

上面的图G1包含了"A,B,C,D,E,F,G"共7个顶点,而且包含了"(A,C),(A,D),(A,F),(B,C),(C,D),(E,G),(F,G)"共7条边。由于这是无向图,所以边(A,C)和边(C,A)是同一条边;这里列举边时,是按照字母先后顺序列举的。
上图右边的矩阵是G1在内存中的邻接矩阵示意图。A[i][j]=1表示第i个顶点与第j个顶点是邻接点,A[i][j]=0则表示它们不是邻接点;而A[i][j]表示的是第i行第j列的值;例如,A[1,2]=1,表示第1个顶点(即顶点B)和第2个顶点(C)是邻接点。
二、邻接矩阵无向图说明
1. 基本定义
1 class MatrixUDG {
2 private:
3 char mVexs[MAX]; // 顶点集合
4 int mVexNum; // 顶点数
5 int mEdgNum; // 边数
6 int mMatrix[MAX][MAX]; // 邻接矩阵
7
8 public:
9 // 创建图(自己输入数据)
10 MatrixUDG();
11 // 创建图(用已提供的矩阵)
12 MatrixUDG(char vexs[], int vlen, char edges[][2], int elen);
13 ~MatrixUDG();
14
15 // 打印矩阵队列图
16 void print();
17
18 private:
19 // 读取一个输入字符
20 char readChar();
21 // 返回ch在mMatrix矩阵中的位置
22 int getPosition(char ch);
23 };MatrixUDG是邻接矩阵对应的结构体。
mVexs用于保存顶点,mVexNum是顶点数,mEdgNum是边数;mMatrix则是用于保存矩阵信息的二维数组。例如,mMatrix[i][j]=1,则表示"顶点i(即mVexs[i])"和"顶点j(即mVexs[j])"是邻接点;mMatrix[i][j]=0,则表示它们不是邻接点。
2. 创建矩阵
这里介绍提供了两个创建矩阵的方法。一个是用已知数据,另一个则需要用户手动输入数据。
2.1 创建图(用已提供的矩阵)
1 /*
2 * 创建图(用已提供的矩阵)
3 *
4 * 参数说明:
5 * vexs -- 顶点数组
6 * vlen -- 顶点数组的长度
7 * edges -- 边数组
8 * elen -- 边数组的长度
9 */
10 MatrixUDG::MatrixUDG(char vexs[], int vlen, char edges[][2], int elen)
11 {
12 int i, p1, p2;
13
14 // 初始化"顶点数"和"边数"
15 mVexNum = vlen;
16 mEdgNum = elen;
17 // 初始化"顶点"
18 for (i = 0; i < mVexNum; i++)
19 mVexs[i] = vexs[i];
20
21 // 初始化"边"
22 for (i = 0; i < mEdgNum; i++)
23 {
24 // 读取边的起始顶点和结束顶点
25 p1 = getPosition(edges[i][0]);
26 p2 = getPosition(edges[i][1]);
27
28 mMatrix[p1][p2] = 1;
29 mMatrix[p2][p1] = 1;
30 }
31 }该函数的作用是利用已知数据来创建一个邻接矩阵无向图。 实际上,在本文的测试程序源码中,该方法创建的无向图就是上面图G1。具体的调用代码如下:
1 char vexs[] = {''A'', ''B'', ''C'', ''D'', ''E'', ''F'', ''G''};
2 char edges[][2] = {
3 {''A'', ''C''},
4 {''A'', ''D''},
5 {''A'', ''F''},
6 {''B'', ''C''},
7 {''C'', ''D''},
8 {''E'', ''G''},
9 {''F'', ''G''}};
10 int vlen = sizeof(vexs)/sizeof(vexs[0]);
11 int elen = sizeof(edges)/sizeof(edges[0]);
12 MatrixUDG* pG;
13
14 pG = new MatrixUDG(vexs, vlen, edges, elen);2.2 创建图(自己输入)
1 /*
2 * 创建图(自己输入数据)
3 */
4 MatrixUDG::MatrixUDG()
5 {
6 char c1, c2;
7 int i, p1, p2;
8
9 // 输入"顶点数"和"边数"
10 cout << "input vertex number: ";
11 cin >> mVexNum;
12 cout << "input edge number: ";
13 cin >> mEdgNum;
14 if ( mVexNum < 1 || mEdgNum < 1 || (mEdgNum > (mVexNum * (mVexNum-1))))
15 {
16 cout << "input error: invalid parameters!" << endl;
17 return ;
18 }
19
20 // 初始化"顶点"
21 for (i = 0; i < mVexNum; i++)
22 {
23 cout << "vertex(" << i << "): ";
24 mVexs[i] = readChar();
25 }
26
27 // 初始化"边"
28 for (i = 0; i < mEdgNum; i++)
29 {
30 // 读取边的起始顶点和结束顶点
31 cout << "edge(" << i << "): ";
32 c1 = readChar();
33 c2 = readChar();
34
35 p1 = getPosition(c1);
36 p2 = getPosition(c2);
37 if (p1==-1 || p2==-1)
38 {
39 cout << "input error: invalid edge!" << endl;
40 return ;
41 }
42
43 mMatrix[p1][p2] = 1;
44 mMatrix[p2][p1] = 1;
45 }
46 }三、邻接矩阵无向图的C++实现
1 /**
2 * C++: 邻接矩阵表示的"无向图(List Undirected Graph)"
3 */
4
5 #include <iomanip>
6 #include <iostream>
7 #include <vector>
8 using namespace std;
9
10 #define MAX 100
11 class MatrixUDG {
12 private:
13 char mVexs[MAX]; // 顶点集合
14 int mVexNum; // 顶点数
15 int mEdgNum; // 边数
16 int mMatrix[MAX][MAX]; // 邻接矩阵
17
18 public:
19 // 创建图(自己输入数据)
20 MatrixUDG();
21 // 创建图(用已提供的矩阵)
22 MatrixUDG(char vexs[], int vlen, char edges[][2], int elen);
23 ~MatrixUDG();
24
25 // 打印矩阵队列图
26 void print();
27
28 private:
29 // 读取一个输入字符
30 char readChar();
31 // 返回ch在mMatrix矩阵中的位置
32 int getPosition(char ch);
33 };
34
35 /*
36 * 创建图(自己输入数据)
37 */
38 MatrixUDG::MatrixUDG()
39 {
40 char c1, c2;
41 int i, p1, p2;
42
43 // 输入"顶点数"和"边数"
44 cout << "input vertex number: ";
45 cin >> mVexNum;
46 cout << "input edge number: ";
47 cin >> mEdgNum;
48 if ( mVexNum < 1 || mEdgNum < 1 || (mEdgNum > (mVexNum * (mVexNum-1))))
49 {
50 cout << "input error: invalid parameters!" << endl;
51 return ;
52 }
53
54 // 初始化"顶点"
55 for (i = 0; i < mVexNum; i++)
56 {
57 cout << "vertex(" << i << "): ";
58 mVexs[i] = readChar();
59 }
60
61 // 初始化"边"
62 for (i = 0; i < mEdgNum; i++)
63 {
64 // 读取边的起始顶点和结束顶点
65 cout << "edge(" << i << "): ";
66 c1 = readChar();
67 c2 = readChar();
68
69 p1 = getPosition(c1);
70 p2 = getPosition(c2);
71 if (p1==-1 || p2==-1)
72 {
73 cout << "input error: invalid edge!" << endl;
74 return ;
75 }
76
77 mMatrix[p1][p2] = 1;
78 mMatrix[p2][p1] = 1;
79 }
80 }
81
82 /*
83 * 创建图(用已提供的矩阵)
84 *
85 * 参数说明:
86 * vexs -- 顶点数组
87 * vlen -- 顶点数组的长度
88 * edges -- 边数组
89 * elen -- 边数组的长度
90 */
91 MatrixUDG::MatrixUDG(char vexs[], int vlen, char edges[][2], int elen)
92 {
93 int i, p1, p2;
94
95 // 初始化"顶点数"和"边数"
96 mVexNum = vlen;
97 mEdgNum = elen;
98 // 初始化"顶点"
99 for (i = 0; i < mVexNum; i++)
100 mVexs[i] = vexs[i];
101
102 // 初始化"边"
103 for (i = 0; i < mEdgNum; i++)
104 {
105 // 读取边的起始顶点和结束顶点
106 p1 = getPosition(edges[i][0]);
107 p2 = getPosition(edges[i][1]);
108
109 mMatrix[p1][p2] = 1;
110 mMatrix[p2][p1] = 1;
111 }
112 }
113
114 /*
115 * 析构函数
116 */
117 MatrixUDG::~MatrixUDG()
118 {
119 }
120
121 /*
122 * 返回ch在mMatrix矩阵中的位置
123 */
124 int MatrixUDG::getPosition(char ch)
125 {
126 int i;
127 for(i=0; i<mVexNum; i++)
128 if(mVexs[i]==ch)
129 return i;
130 return -1;
131 }
132
133 /*
134 * 读取一个输入字符
135 */
136 char MatrixUDG::readChar()
137 {
138 char ch;
139
140 do {
141 cin >> ch;
142 } while(!((ch>=''a''&&ch<=''z'') || (ch>=''A''&&ch<=''Z'')));
143
144 return ch;
145 }
146
147 /*
148 * 打印矩阵队列图
149 */
150 void MatrixUDG::print()
151 {
152 int i,j;
153
154 cout << "Martix Graph:" << endl;
155 for (i = 0; i < mVexNum; i++)
156 {
157 for (j = 0; j < mVexNum; j++)
158 cout << mMatrix[i][j] << " ";
159 cout << endl;
160 }
161 }
162
163 int main()
164 {
165 char vexs[] = {''A'', ''B'', ''C'', ''D'', ''E'', ''F'', ''G''};
166 char edges[][2] = {
167 {''A'', ''C''},
168 {''A'', ''D''},
169 {''A'', ''F''},
170 {''B'', ''C''},
171 {''C'', ''D''},
172 {''E'', ''G''},
173 {''F'', ''G''}};
174 int vlen = sizeof(vexs)/sizeof(vexs[0]);
175 int elen = sizeof(edges)/sizeof(edges[0]);
176 MatrixUDG* pG;
177
178 // 自定义"图"(输入矩阵队列)
179 //pG = new MatrixUDG();
180 // 采用已有的"图"
181 pG = new MatrixUDG(vexs, vlen, edges, elen);
182
183 pG->print(); // 打印图
184
185 return 0;
186 }四、邻接表无向图介绍
邻接表无向图是指通过邻接表表示的无向图。
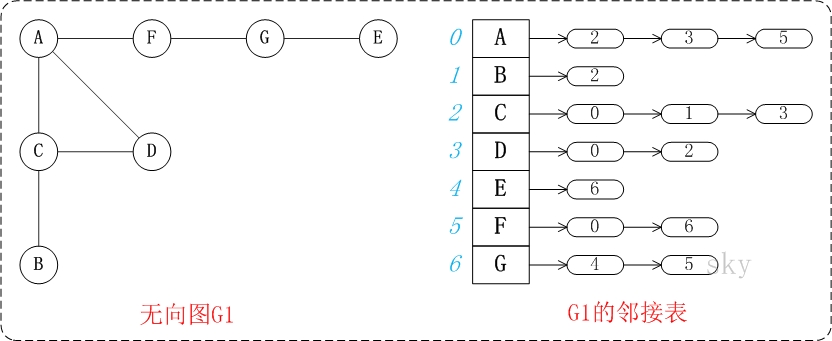
上面的图G1包含了"A,B,C,D,E,F,G"共7个顶点,而且包含了"(A,C),(A,D),(A,F),(B,C),(C,D),(E,G),(F,G)"共7条边。
上图右边的矩阵是G1在内存中的邻接表示意图。每一个顶点都包含一条链表,该链表记录了"该顶点的邻接点的序号"。例如,第2个顶点(顶点C)包含的链表所包含的节点的数据分别是"0,1,3";而这"0,1,3"分别对应"A,B,D"的序号,"A,B,D"都是C的邻接点。就是通过这种方式记录图的信息的。
五、邻接表无向图的代码说明
1. 基本定义
1 #define MAX 100
2 // 邻接表
3 class ListUDG
4 {
5 private: // 内部类
6 // 邻接表中表对应的链表的顶点
7 class ENode
8 {
9 public:
10 int ivex; // 该边所指向的顶点的位置
11 ENode *nextEdge; // 指向下一条弧的指针
12 };
13
14 // 邻接表中表的顶点
15 class VNode
16 {
17 public:
18 char data; // 顶点信息
19 ENode *firstEdge; // 指向第一条依附该顶点的弧
20 };
21
22 private: // 私有成员
23 int mVexNum; // 图的顶点的数目
24 int mEdgNum; // 图的边的数目
25 VNode mVexs[MAX];
26
27 public:
28 // 创建邻接表对应的图(自己输入)
29 ListUDG();
30 // 创建邻接表对应的图(用已提供的数据)
31 ListUDG(char vexs[], int vlen, char edges[][2], int elen);
32 ~ListUDG();
33
34 // 打印邻接表图
35 void print();
36
37 private:
38 // 读取一个输入字符
39 char readChar();
40 // 返回ch的位置
41 int getPosition(char ch);
42 // 将node节点链接到list的最后
43 void linkLast(ENode *list, ENode *node);
44 };(1) ListUDG是邻接表对应的结构体。
mVexNum是顶点数,mEdgNum是边数;mVexs则是保存顶点信息的一维数组。
(2) VNode是邻接表顶点对应的结构体。
data是顶点所包含的数据,而firstEdge是该顶点所包含链表的表头指针。
(3) ENode是邻接表顶点所包含的链表的节点对应的结构体。
ivex是该节点所对应的顶点在vexs中的索引,而nextEdge是指向下一个节点的。
2. 创建矩阵
这里介绍提供了两个创建矩阵的方法。一个是用已知数据,另一个则需要用户手动输入数据。
2.1 创建图(用已提供的矩阵)
/*
* 创建邻接表对应的图(用已提供的数据)
*/
ListUDG::ListUDG(char vexs[], int vlen, char edges[][2], int elen)
{
char c1, c2;
int i, p1, p2;
ENode *node1, *node2;
// 初始化"顶点数"和"边数"
mVexNum = vlen;
mEdgNum = elen;
// 初始化"邻接表"的顶点
for(i=0; i<mVexNum; i++)
{
mVexs[i].data = vexs[i];
mVexs[i].firstEdge = NULL;
}
// 初始化"邻接表"的边
for(i=0; i<mEdgNum; i++)
{
// 读取边的起始顶点和结束顶点
c1 = edges[i][0];
c2 = edges[i][1];
p1 = getPosition(c1);
p2 = getPosition(c2);
// 初始化node1
node1 = new ENode();
node1->ivex = p2;
// 将node1链接到"p1所在链表的末尾"
if(mVexs[p1].firstEdge == NULL)
mVexs[p1].firstEdge = node1;
else
linkLast(mVexs[p1].firstEdge, node1);
// 初始化node2
node2 = new ENode();
node2->ivex = p1;
// 将node2链接到"p2所在链表的末尾"
if(mVexs[p2].firstEdge == NULL)
mVexs[p2].firstEdge = node2;
else
linkLast(mVexs[p2].firstEdge, node2);
}
}该函数的作用是创建一个邻接表无向图。实际上,该方法创建的无向图,就是上面图G1。调用代码如下:
1 char vexs[] = {''A'', ''B'', ''C'', ''D'', ''E'', ''F'', ''G''};
2 char edges[][2] = {
3 {''A'', ''C''},
4 {''A'', ''D''},
5 {''A'', ''F''},
6 {''B'', ''C''},
7 {''C'', ''D''},
8 {''E'', ''G''},
9 {''F'', ''G''}};
10 int vlen = sizeof(vexs)/sizeof(vexs[0]);
11 int elen = sizeof(edges)/sizeof(edges[0]);
12 ListUDG* pG;
13
14 pG = new ListUDG(vexs, vlen, edges, elen);2.2 创建图(自己输入)
1 /*
2 * 创建邻接表对应的图(自己输入)
3 */
4 ListUDG::ListUDG()
5 {
6 char c1, c2;
7 int v, e;
8 int i, p1, p2;
9 ENode *node1, *node2;
10
11 // 输入"顶点数"和"边数"
12 cout << "input vertex number: ";
13 cin >> mVexNum;
14 cout << "input edge number: ";
15 cin >> mEdgNum;
16 if ( mVexNum < 1 || mEdgNum < 1 || (mEdgNum > (mVexNum * (mVexNum-1))))
17 {
18 cout << "input error: invalid parameters!" << endl;
19 return ;
20 }
21
22 // 初始化"邻接表"的顶点
23 for(i=0; i<mVexNum; i++)
24 {
25 cout << "vertex(" << i << "): ";
26 mVexs[i].data = readChar();
27 mVexs[i].firstEdge = NULL;
28 }
29
30 // 初始化"邻接表"的边
31 for(i=0; i<mEdgNum; i++)
32 {
33 // 读取边的起始顶点和结束顶点
34 cout << "edge(" << i << "): ";
35 c1 = readChar();
36 c2 = readChar();
37
38 p1 = getPosition(c1);
39 p2 = getPosition(c2);
40 // 初始化node1
41 node1 = new ENode();
42 node1->ivex = p2;
43 // 将node1链接到"p1所在链表的末尾"
44 if(mVexs[p1].firstEdge == NULL)
45 mVexs[p1].firstEdge = node1;
46 else
47 linkLast(mVexs[p1].firstEdge, node1);
48 // 初始化node2
49 node2 = new ENode();
50 node2->ivex = p1;
51 // 将node2链接到"p2所在链表的末尾"
52 if(mVexs[p2].firstEdge == NULL)
53 mVexs[p2].firstEdge = node2;
54 else
55 linkLast(mVexs[p2].firstEdge, node2);
56 }
57 }该函数是读取用户的输入,将输入的数据转换成对应的无向图。
六、邻接表无向图的C++实现
1 /**
2 * C++: 邻接表表示的"无向图(List Undirected Graph)" 6 */
7
8 #include <iomanip>
9 #include <iostream>
10 #include <vector>
11 using namespace std;
12
13 #define MAX 100
14 // 邻接表
15 class ListUDG
16 {
17 private: // 内部类
18 // 邻接表中表对应的链表的顶点
19 class ENode
20 {
21 public:
22 int ivex; // 该边所指向的顶点的位置
23 ENode *nextEdge; // 指向下一条弧的指针
24 };
25
26 // 邻接表中表的顶点
27 class VNode
28 {
29 public:
30 char data; // 顶点信息
31 ENode *firstEdge; // 指向第一条依附该顶点的弧
32 };
33
34 private: // 私有成员
35 int mVexNum; // 图的顶点的数目
36 int mEdgNum; // 图的边的数目
37 VNode mVexs[MAX];
38
39 public:
40 // 创建邻接表对应的图(自己输入)
41 ListUDG();
42 // 创建邻接表对应的图(用已提供的数据)
43 ListUDG(char vexs[], int vlen, char edges[][2], int elen);
44 ~ListUDG();
45
46 // 打印邻接表图
47 void print();
48
49 private:
50 // 读取一个输入字符
51 char readChar();
52 // 返回ch的位置
53 int getPosition(char ch);
54 // 将node节点链接到list的最后
55 void linkLast(ENode *list, ENode *node);
56 };
57
58 /*
59 * 创建邻接表对应的图(自己输入)
60 */
61 ListUDG::ListUDG()
62 {
63 char c1, c2;
64 int v, e;
65 int i, p1, p2;
66 ENode *node1, *node2;
67
68 // 输入"顶点数"和"边数"
69 cout << "input vertex number: ";
70 cin >> mVexNum;
71 cout << "input edge number: ";
72 cin >> mEdgNum;
73 if ( mVexNum < 1 || mEdgNum < 1 || (mEdgNum > (mVexNum * (mVexNum-1))))
74 {
75 cout << "input error: invalid parameters!" << endl;
76 return ;
77 }
78
79 // 初始化"邻接表"的顶点
80 for(i=0; i<mVexNum; i++)
81 {
82 cout << "vertex(" << i << "): ";
83 mVexs[i].data = readChar();
84 mVexs[i].firstEdge = NULL;
85 }
86
87 // 初始化"邻接表"的边
88 for(i=0; i<mEdgNum; i++)
89 {
90 // 读取边的起始顶点和结束顶点
91 cout << "edge(" << i << "): ";
92 c1 = readChar();
93 c2 = readChar();
94
95 p1 = getPosition(c1);
96 p2 = getPosition(c2);
97 // 初始化node1
98 node1 = new ENode();
99 node1->ivex = p2;
100 // 将node1链接到"p1所在链表的末尾"
101 if(mVexs[p1].firstEdge == NULL)
102 mVexs[p1].firstEdge = node1;
103 else
104 linkLast(mVexs[p1].firstEdge, node1);
105 // 初始化node2
106 node2 = new ENode();
107 node2->ivex = p1;
108 // 将node2链接到"p2所在链表的末尾"
109 if(mVexs[p2].firstEdge == NULL)
110 mVexs[p2].firstEdge = node2;
111 else
112 linkLast(mVexs[p2].firstEdge, node2);
113 }
114 }
115
116 /*
117 * 创建邻接表对应的图(用已提供的数据)
118 */
119 ListUDG::ListUDG(char vexs[], int vlen, char edges[][2], int elen)
120 {
121 char c1, c2;
122 int i, p1, p2;
123 ENode *node1, *node2;
124
125 // 初始化"顶点数"和"边数"
126 mVexNum = vlen;
127 mEdgNum = elen;
128 // 初始化"邻接表"的顶点
129 for(i=0; i<mVexNum; i++)
130 {
131 mVexs[i].data = vexs[i];
132 mVexs[i].firstEdge = NULL;
133 }
134
135 // 初始化"邻接表"的边
136 for(i=0; i<mEdgNum; i++)
137 {
138 // 读取边的起始顶点和结束顶点
139 c1 = edges[i][0];
140 c2 = edges[i][1];
141
142 p1 = getPosition(c1);
143 p2 = getPosition(c2);
144 // 初始化node1
145 node1 = new ENode();
146 node1->ivex = p2;
147 // 将node1链接到"p1所在链表的末尾"
148 if(mVexs[p1].firstEdge == NULL)
149 mVexs[p1].firstEdge = node1;
150 else
151 linkLast(mVexs[p1].firstEdge, node1);
152 // 初始化node2
153 node2 = new ENode();
154 node2->ivex = p1;
155 // 将node2链接到"p2所在链表的末尾"
156 if(mVexs[p2].firstEdge == NULL)
157 mVexs[p2].firstEdge = node2;
158 else
159 linkLast(mVexs[p2].firstEdge, node2);
160 }
161 }
162
163 /*
164 * 析构函数
165 */
166 ListUDG::~ListUDG()
167 {
168 }
169
170 /*
171 * 将node节点链接到list的最后
172 */
173 void ListUDG::linkLast(ENode *list, ENode *node)
174 {
175 ENode *p = list;
176
177 while(p->nextEdge)
178 p = p->nextEdge;
179 p->nextEdge = node;
180 }
181
182 /*
183 * 返回ch的位置
184 */
185 int ListUDG::getPosition(char ch)
186 {
187 int i;
188 for(i=0; i<mVexNum; i++)
189 if(mVexs[i].data==ch)
190 return i;
191 return -1;
192 }
193
194 /*
195 * 读取一个输入字符
196 */
197 char ListUDG::readChar()
198 {
199 char ch;
200
201 do {
202 cin >> ch;
203 } while(!((ch>=''a''&&ch<=''z'') || (ch>=''A''&&ch<=''Z'')));
204
205 return ch;
206 }
207
208 /*
209 * 打印邻接表图
210 */
211 void ListUDG::print()
212 {
213 int i,j;
214 ENode *node;
215
216 cout << "List Graph:" << endl;
217 for (i = 0; i < mVexNum; i++)
218 {
219 cout << i << "(" << mVexs[i].data << "): ";
220 node = mVexs[i].firstEdge;
221 while (node != NULL)
222 {
223 cout << node->ivex << "(" << mVexs[node->ivex].data << ") ";
224 node = node->nextEdge;
225 }
226 cout << endl;
227 }
228 }
229
230 int main()
231 {
232 char vexs[] = {''A'', ''B'', ''C'', ''D'', ''E'', ''F'', ''G''};
233 char edges[][2] = {
234 {''A'', ''C''},
235 {''A'', ''D''},
236 {''A'', ''F''},
237 {''B'', ''C''},
238 {''C'', ''D''},
239 {''E'', ''G''},
240 {''F'', ''G''}};
241 int vlen = sizeof(vexs)/sizeof(vexs[0]);
242 int elen = sizeof(edges)/sizeof(edges[0]);
243 ListUDG* pG;
244
245 // 自定义"图"(输入矩阵队列)
246 //pG = new ListUDG();
247 // 采用已有的"图"
248 pG = new ListUDG(vexs, vlen, edges, elen);
249
250 pG->print(); // 打印图
251
252 return 0;
253 }
![2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也](http://www.gvkun.com/zb_users/upload/2025/03/9812dacb-6dc1-4677-b6c8-42dc580267b11741861377965.jpg "2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也")
2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也
2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也就是树结构 每个节点可以染1、2、3三种颜色。 要求 : 非叶节点的相邻点一定要至少有两种和自己不同颜色的点。 返回一种达标的染色方案,也就是一个数组,表示每个节点的染色状况。 1 <= 节点数量 <= 10的5次方。 来自米哈游。
答案2022-11-04:
生成图,选一个头节点,深度优先染色。
代码用rust编写。代码如下:
use std::{iter::repeat, vec};
use rand::Rng;
fn main() {
let nn: i32 = 100;
let test_time: i32 = 1000;
println!("测试开始");
for i in 0..test_time {
let n = rand::thread_rng().gen_range(0, nn) + 1;
let mut edges = random_edges(n);
let mut ans = dye(n, &mut edges);
if !right_answer(n, &mut edges, &mut ans) {
println!("出错了!{}", i);
break;
}
}
println!("测试结束");
}
// 1 2 3 1 2 3 1 2 3
const RULE1: [i32; 3] = [1, 2, 3];
// // 1 3 2 1 3 2 1 3 2
const RULE2: [i32; 3] = [1, 3, 2];
fn dye(n: i32, edges: &mut Vec<Vec<i32>>) -> Vec<i32> {
let mut graph: Vec<Vec<i32>> = vec![];
// 0 : { 2, 1 }
// 1 : { 0 }
// 2 : { 0 }
for _i in 0..n {
graph.push(vec![]);
}
for edge in edges.iter() {
// 0 -> 2
// 1 -> 0
graph[edge[0] as usize].push(edge[1]);
graph[edge[1] as usize].push(edge[0]);
}
// 选一个头节点!
let mut head = -1;
for i in 0..n {
if graph[i as usize].len() >= 2 {
head = i;
break;
}
}
// graph
// head
let mut colors: Vec<i32> = repeat(0).take(n as usize).collect();
if head == -1 {
// 两个点,互相连一下
// 把colors,所有位置,都设置成1
colors = repeat(1).take(n as usize).collect();
} else {
// dfs 染色了!
colors[head as usize] = 1;
let h = graph[head as usize][0];
dfs(&mut graph, h, 1, &RULE1, &mut colors);
for i in 1..graph[head as usize].len() as i32 {
let h = graph[head as usize][i as usize];
dfs(&mut graph, h, 1, &RULE2, &mut colors);
}
}
return colors;
}
// 整个图结构,都在graph
// 当前来到的节点,是head号节点
// head号节点,在level层
// 染色的规则,rule {1,2,3...} {1,3,2...}
// 做的事情:以head为头的整颗树,每个节点,都染上颜色
// 填入到colors数组里去
fn dfs(graph: &mut Vec<Vec<i32>>, head: i32, level: i32, rule: &[i32; 3], colors: &mut Vec<i32>) {
colors[head as usize] = rule[(level % 3) as usize];
for next in graph[head as usize].clone().iter() {
if colors[*next as usize] == 0 {
dfs(graph, *next, level + 1, rule, colors);
}
}
}
// 为了测试
// 生成无环无向图
fn random_edges(n: i32) -> Vec<Vec<i32>> {
let mut order: Vec<i32> = repeat(0).take(n as usize).collect();
for i in 0..n {
order[i as usize] = i;
}
let mut i = n - 1;
while i >= 0 {
order.swap(i as usize, rand::thread_rng().gen_range(0, i + 1) as usize);
i -= 1;
}
let mut edges: Vec<Vec<i32>> = repeat(repeat(0).take(2).collect())
.take((n - 1) as usize)
.collect();
for i in 1..n {
edges[(i - 1) as usize][0] = order[i as usize];
edges[(i - 1) as usize][1] = order[rand::thread_rng().gen_range(0, i) as usize];
}
return edges;
}
// 为了测试
fn right_answer(n: i32, edges: &mut Vec<Vec<i32>>, colors: &mut Vec<i32>) -> bool {
let mut graph: Vec<Vec<i32>> = vec![];
for _i in 0..n {
graph.push(vec![]);
}
for edge in edges.iter() {
graph[edge[0] as usize].push(edge[1]);
graph[edge[1] as usize].push(edge[0]);
}
let mut has_colors: Vec<bool> = repeat(false).take(4).collect();
let mut i = 0;
let mut color_cnt = 1;
while i < n {
if colors[i as usize] == 0 {
return false;
}
if graph[i as usize].len() <= 1 {
// i号点是叶节点
i += 1;
color_cnt = 1;
continue;
}
has_colors[colors[i as usize] as usize] = true;
for near in graph[i as usize].iter() {
if !has_colors[colors[*near as usize] as usize] {
has_colors[colors[*near as usize] as usize] = true;
color_cnt += 1;
}
}
if color_cnt != 3 {
return false;
}
has_colors = repeat(false).take(4).collect();
i += 1;
color_cnt = 1;
}
return true;
}
执行结果如下:
左神java代码

C#图表算法之无向图
图是由一组顶点和一组能够将两个顶点相连的边组成。

顶点叫什么名字并不重要,但我们需要一个方法来指代这些顶点。一般使用 0 至 V-1 来表示一张含有 V 个顶点的图中的各个顶点。这样约定是为了方便使用数组的索引来编写能够高效访问各个顶点信息的代码。用一张符号表来为顶点的名字和 0 到 V-1 的整数值建立一一对应的关系并不困难,因此直接使用数组索引作为结点的名称更方便且不失一般性,也不会损失什么效率。
我们用 v-w 的记法来表示连接 v 和 w 的边, w-v 是这条边的另一种表示方法。
在绘制一幅图时,用圆圈表示顶点,用连接两个顶点的线段表示边,这样就能直观地看出图地结构。但这种直觉有时可能会误导我们,因为图地定义和绘制地图像是无关的,一组数据可以绘制不同形态的图像。

特殊的图
自环:即一条连接一个顶点和其自身的边;
多重图:连接同一对顶点的两条边成为平行边,含有平行边的图称为多重图。
没有平行边的图称为简单图。
1.相关术语
当两个顶点通过一条边相连时,称这两个顶点是相邻得,并称这条边依附于这两个顶点。某个顶点的度数即为依附于它的边的总数。子图是由一幅图的所有边的一个子集(以及它们所依附的所有顶点)组成的图。许多计算问题都需要识别各种类型的子图,特别是由能够顺序连接一系列顶点的边所组成的子图。
在图中,路径是由边顺序连接的一系列顶点。简单路径是一条没有重复顶点的路径。环是一条至少含有一条边且起点和终点相同的路径。简单环是一条(除了起点和终点必须相同之外)不含有重复顶点和边的环。路径或环的长度为其中所包含的边数。
当两个顶点之间存在一条连接双方的路径时,我们称一个顶点和另一个顶点是连通的。
如果从任意一个顶点都存在一条路径到达另一个任意顶点,我们称这副图是连通图。一幅非连通的图由若干连通的部分组成,它们都是其极大连通子图。
一般来说,要处理一张图需要一个个地处理它的连通分量(子图)。
树是一幅无环连通图。互不相连的树组成的集合称为森林。连通图的生成树是它的一幅子图,它含有图中的所有顶点且是一棵树。图的生成森林是它的所有连通子图的生成树的集合。



树的定义非常通用,稍作改动就可以变成用来描述程序行为(函数调用层次)模型和数据结构。当且仅当一幅含有 V 个结点的图 G 满足下列 5 个条件之一时,它就是一棵树:
- G 有 V - 1 条边且不含有环;
- G 有 V - 1 条边且是连通的;
- G 是连通的,但删除任意一条都会使它不再连通;
- G 是无环图,但添加任意一条边都会产生一条环;
- G 中的任意一对顶点之间仅存在一条简单路径;
图的密度是指已经连接的顶点对占所有可能被连接的顶点对的比例。在稀疏图中,被连接的顶点对很少;而在稠密图中,只有少部分顶点对之间没有边连接。一般来说,如果一幅图中不同的边的数量在顶点总数 v 的一个小的常数倍以内,那么我们认为这幅图是稀疏的,否则就是稠密的。
二分图是一种能够将所有结点分为两部分的图,其中图的每条边所连接的两个顶点都分别属于不同的集合。
2.表示无向图的数据结构

图的几种表示方法
接下来要面对的图处理问题就是用哪种数据结构来表示图并实现这份API,包含下面两个要求:
- 1.必须为可能在应用中碰到的各种类型图预留出足够的空间;
- 2.Graph 的实例方法的实现一定要快。
下面有三种选择:
- 1.邻接矩阵:我们可以使用一个 V 乘 V 的布尔矩阵。当顶点 v 和 w 之间有连接的边时,定义 v 行 w 列的元素值为 true,否则为 false。这种表示方法不符合第一个条件--含有上百万个顶点的图所需的空间是不能满足的。
- 2.边的数组:我们可以使用一个 Edge 类,它含有两个 int 实例变量。这种表示方法很简单但不满足第二个条件--要实现 Adj 需要检查图中的所有边。
- 3.邻接表数组:使用一个以顶点为索引的列表数组,其中每个元素都是和该顶点相连的顶点列表。

非稠密图的标准表示成为邻接表的数据结构,它将每个顶点的所有相邻顶点都保存在该顶点对应的元素所指向的一张链表中。我们使用这个数组就是为了快速访问给定顶点的邻接顶点列表。这里使用 Bag 来实现这个链表,这样我们就可以在常数时间内添加新的边或遍历任意顶点的所有相邻顶点。
要添加一条连接 v 与 w 的边,我们将 w 添加到 v 的邻接表中并把 v 添加到 w 的邻接表中。因此在这个数据结构中每条边都会出现两次。这种 Graph 的实现的性能特点:
- 1.使用的空间和 V+E 成正比;
- 2.添加一条边所需的时间为常数;
- 3.遍历顶点 v 的所有相邻顶点所需的时间和 v 的度数成正比。
对于这些操作,这样的特性已经是最优的了,而且支持平行边和自环。注意,边的插入顺序决定了Graph 的邻接表中顶点的出现顺序。多个不同的邻接表可能表示着同一幅图。因为算法在使用 Adj() 处理所有相邻的顶点时不会考虑它们在邻接表中的出现顺序,这种差异不会影响算法的正确性,但在调试或是跟踪邻接表的轨迹时需要注意这一点。
public class Graph
{
private int v;
private int e;
private List<int>[] adj; //邻接表(用List 代替 bag)
/// <summary>
/// 创建一个含有V个顶点但不含有边的图
/// </summary>
/// <param name="V"></param>
public Graph(int V)
{
v = V;
e = 0;
adj = new List<int>[V];
for (var i = 0; i < V; i++)
adj[i] = new List<int>();
}
public Graph(string[] strs)
{
foreach (var str in strs)
{
var data = str.Split('' '');
int v = Convert.ToInt32(data[0]);
int w = Convert.ToInt32(data[1]);
AddEdge(v,w);
}
}
/// <summary>
/// 顶点数
/// </summary>
/// <returns></returns>
public int V()
{
return v;
}
/// <summary>
/// 边数
/// </summary>
/// <returns></returns>
public int E()
{
return e;
}
/// <summary>
/// 向图中添加一条边 v-w
/// </summary>
/// <param name="v"></param>
/// <param name="w"></param>
public void AddEdge(int v, int w)
{
adj[v].Add(w);
adj[w].Add(v);
e++;
}
/// <summary>
/// 和v相邻的所有顶点
/// </summary>
/// <param name="v"></param>
/// <returns></returns>
public IEnumerable<int> Adj(int v)
{
return adj[v];
}
/// <summary>
/// 计算 V 的度数
/// </summary>
/// <param name="G"></param>
/// <param name="V"></param>
/// <returns></returns>
public static int Degree(Graph G, int V)
{
int degree = 0;
foreach (int w in G.Adj(V))
degree++;
return degree;
}
/// <summary>
/// 计算所有顶点的最大度数
/// </summary>
/// <param name="G"></param>
/// <returns></returns>
public static int MaxDegree(Graph G)
{
int max = 0;
for (int v = 0; v < G.V(); v++)
{
var d = Degree(G, v);
if (d > max)
max = d;
}
return max;
}
/// <summary>
/// 计算所有顶点的平均度数
/// </summary>
/// <param name="G"></param>
/// <returns></returns>
public static double AvgDegree(Graph G)
{
return 2.0 * G.E() / G.V();
}
/// <summary>
/// 计算自环的个数
/// </summary>
/// <param name="G"></param>
/// <returns></returns>
public static int NumberOfSelfLoops(Graph G)
{
int count = 0;
for (int v = 0; v < G.V(); v++)
{
foreach (int w in G.Adj(v))
{
if (v == w)
count++;
}
}
return count / 2; //每条边都被计算了两次
}
public override string ToString()
{
string s = V() + " vertices, " + E() + " edges\n";
for (int v = 0; v < V(); v++)
{
s += v + ":";
foreach (int w in Adj(v))
{
s += w + " ";
}
s += "\n";
}
return s;
}
}在实际应用中还有一些操作可能有用,例如:
- 添加一个顶点;
- 删除一个顶点。
实现这些操作的一种方法是,使用符号表 ST 来代替由顶点索引构成的数组,这样修改之后就不需要约定顶点名必须是整数了。可能还需要:
- 删除一条边;
- 检查图是否含有 v-w。
要实现这些方法,可能需要使用 SET 代替 Bag 来实现邻接表。我们称这种方法为邻接集。现在还不需要,因为:
- 不需要添加,删除顶点和边或是检查一条边是否存在;
- 上述操作使用频率很低或者相关链表很短,可以直接使用穷举法遍历;
- 某些情况下会使性能损失 logV。
3.图的处理算法的设计模式
因为我们会讨论大量关于图处理的算法,所以设计的首要目标是将图的表示和实现分离开来。为此,我们会为每个任务创建一个相应的类,用例可以创建相应的对象来完成任务。类的构造函数一般会在预处理中构造各种数据结构,以有效地响应用例的请求。典型的用例程序会构造一幅图,将图作为参数传递给某个算法类的构造函数,然后调用各种方法来获取图的各种性质。

我们用起点 s 区分作为参数传递给构造函数的顶点与图中的其他顶点。在这份 API 中,构造函数的任务就是找到图中与起点连通的其他顶点。用例可以调用 marked 方法和 count 方法来了解图的性质。方法名 marked 指的是这种基本方法使用的一种实现方式:在图中从起点开始沿着路径到达其他顶点并标记每个路过的顶点。
在 union-find算法已经见过 Search API 的实现,它的构造函数会创建一个 UF 对象,对图中的每条边进行一次 union 操作并调用 connected(s,v) 来实现 marked 方法。实现 count 方法需要一个加权的 UF 实现并扩展它的API,以便使用 count 方法返回 sz[find(v)]。
下面的一种搜索算法是基于深度优先搜索(DFS)的,它会沿着图的边寻找喝起点连通的所有顶点。
4.深度优先搜索
要搜索一幅图,只需要一个递归方法来遍历所有顶点。在访问其中一个顶点时:
- 1.将它标记为已访问;
- 2.递归地访问它所有没有被标记过地邻居顶点。
这种方法称为深度优先搜索(DFS)。
namespace Graphs
{
/// <summary>
/// 使用一个 bool 数组来记录和起点连通地所有顶点。递归方法会标记给定地顶点并调用自己来访问该顶点地相邻顶点列表中
/// 所有没有被标记过地顶点。 如果图是连通的,每个邻接链表中的元素都会被标记。
/// </summary>
public class DepthFirstSearch
{
private bool[] marked;
private int count;
public DepthFirstSearch(Graph G,int s)
{
marked = new bool[G.V()];
Dfs(G,s);
}
private void Dfs(Graph g, int V)
{
marked[V] = true;
count++;
foreach (var w in g.Adj(V))
{
if (!marked[w])
Dfs(g,w);
}
}
public bool Marked(int w)
{
return marked[w];
}
}
}深度优先搜索标记与起点连通的所有顶点所需的时间和顶点的度数之和成正比。
这种简单的递归模式只是一个开始 -- 深度优先搜索能够有效处理许多和图有关的任务。
- 1.连通性。给定一幅图,两个给定的顶点是否连通?(两个给定的顶点之间是否存在一条路径?路径检测) 图中有多少个连通子图?
- 2.单点路径。给定一幅图和一个起点 s ,从 s 到给定目的顶点 v 是否存在一条路径?如果有,找出这条路径。
5.寻找路径
单点路径的API:

构造函数接受一个起点 s 作为参数,计算 s 到与 s 连通的每个顶点之间的路径。在为起点 s 创建 Paths 对象之后,用例可以调用 PathTo 方法来遍历从 s 到任意和 s 连通的顶点的路径上的所有顶点。
实现
下面的算法基于深度优先搜索,它添加了一个 edgeTo[ ] 整型数组,这个数组可以找到从每个与 s 连通的顶点回到 s 的路径。它会记住每个顶点到起点的路径,而不是记录当前顶点到起点的路径。为了做到这一点,在由边 v-w 第一次任意访问 w 时,将edgeTo[w] = v 来记住这条路径。换句话说, v-w 是从s 到 w 的路径上最后一条已知的边。这样,搜索的结果是一棵以起点为根结点的树,edgeTo[ ] 是一棵由父链接表示的树。 PathTo 方法用变量 x 遍历整棵树,将遇到的所有顶点压入栈中。
public class DepthFirstPaths
{
private bool[] marked;
private int[] edgeTo; //从起点到一个顶点的已知路径上的最后一个顶点
private int s;//起点
public DepthFirstPaths(Graph G, int s)
{
marked = new bool[G.V()];
edgeTo = new int[G.V()];
this.s = s;
Dfs(G,s);
}
private void Dfs(Graph G, int v)
{
marked[v] = true;
foreach (int w in G.Adj(v))
{
if (!marked[w])
{
edgeTo[w] = v;
Dfs(G,w);
}
}
}
public bool HasPathTo(int v)
{
return marked[v];
}
public IEnumerable<int> PathTo(int v)
{
if (!HasPathTo(v))
return null;
Stack<int> path = new Stack<int>();
for (int x = v; x != s; x = edgeTo[x])
path.Push(x);
path.Push(s);
return path;
}
}

使用深度优先搜索得到从给定起点到任意标记顶点的路径所需的时间与路径长度成正比。
6.广度优先搜索
深度优先搜索得到的路径不仅取决于图的结构,还取决于图的表示和递归调用的性质。
单点最短路径:给定一幅图和一个起点 s ,从 s 到给定目的顶点 v 是否存在一条路径?如果有,找出其中最短的那条(所含边最少)。
解决这个问题的经典方法叫做广度优先搜索(BFS)。深度优先搜索在这个问题上没有什么作用,因为它遍历整个图的顺序和找出最短路径的目标没有任何关系。相比之下,广度又出现搜索正式为了这个目标才出现的。
要找到从 s 到 v 的最短路径,从 s 开始,在所有由一条边就可以到达的顶点中寻找 v ,如果找不到就继续在与 s 距离两条边的所有顶点中查找 v ,如此一直进行。

在程序中,在搜索一幅图时遇到有很多边需要遍历的情况时,我们会选择其中一条并将其他边留到以后再继续搜索。在深度优先搜索中,我们用了一个可以下压栈。使用LIFO (后进先出)的规则来描述下压栈和走迷宫时先探索相邻的
通道类似。从有待搜索的通道中选择最晚遇到过的那条。在广度优先搜索中,我们希望按照与起点距离的顺序来遍历所有顶点,使用(FIFO,先进先出)队列来代替栈即可。我们将从有待搜索的通道中选择最早遇到的那条。
实现
下面的算法使用了一个队列来保存所有已经被标记过但其邻接表还未被检查过的顶点。先将顶点加入队列,然后重复下面步骤知道队列为空:
- 1.取队列的下一个顶点 v 并标记它;
- 2.将与 v 相邻的所有未被标记过的顶点加入队列。
下面的 Bfs 方法不是递归。它显示地使用了一个队列。和深度优先搜索一样,它的结果也是一个数组 edgeTo[ ] ,也是一棵用父链接表示的根结点为 s 的树。它表示了 s 到每个与 s 连通的顶点的最短路径。
namespace Graphs
{
/// <summary>
/// 广度优先搜索
/// </summary>
public class BreadthFirstPaths
{
private bool[] marked;//到达该顶点的最短路径已知吗?
private int[] edgeTo;//到达该顶点的已知路径上的最后一个顶点
private int s;//起点
public BreadthFirstPaths(Graph G,int s)
{
marked = new bool[G.V()];
edgeTo = new int[G.V()];
this.s = s;
Bfs(G,s);
}
private void Bfs(Graph G, int s)
{
Queue<int> queue = new Queue<int>();
marked[s] = true;//标记起点
queue.Enqueue(s);//将它加入队列
while (queue.Count > 0)
{
int v = queue.Dequeue();//从队列中删去下一个顶点
foreach (var w in G.Adj(v))
{
if (!marked[w])//对于每个未标记的相邻顶点
{
edgeTo[w] = v;//保存最短路径的最后一条边
marked[w] = true;//标记它,因为最短路径已知
queue.Enqueue(w);//并将它添加到队列中
}
}
}
}
public bool HasPathTo(int v)
{
return marked[v];
}
}
}轨迹:

对于从 s 可达的任意顶点 v ,广度优先搜索都能找到一条从 s 到 v 的最短路径,没有其他从 s 到 v 的路径所含的边比这条路径更少。
广度优先搜索所需的时间在最坏情况下和 V+E 成正比。
我们也可以使用广度优先搜索来实现已经用深度优先搜索实现的 Search API,因为它检查所有与起点连通的顶点和边的方法只取决于查找能力。
广度优先搜索和深度优先搜索在搜索中都会先将起点存入数据结构,然后重复以下步骤直到数据结构清空:
- 1.取其中的下一个顶点并标记它;
- 2.将 v 的所有相邻而又未被标记的顶点加入数据结构。
这两个算法的不同之处在于从数据结构中获取下一个顶点的规则(对于广度优先搜索来说是最早加入的顶点,对于深度优先搜索来说是最晚加入的顶点)。这种差异得到了处理图的两种完全不同的视角,尽管无论使用哪种规则,所有与起点连通的顶点和边都会被检查到。

深度优先搜索不断深入图中并在栈中保存了所有分叉的顶点;广度优先搜索则像扇面一般扫描图,用一个队列保存访问过的最前端的顶点。深度优先搜索探索一幅图的方式是寻找离起点更远的顶点,只在碰到死胡同时才访问进出的顶点;广度优先搜索则首先覆盖起点附近的顶点,只在临近的所有顶点都被访问了之后才向前进。根据应用的不同,所需要的性质也不同。
7.连通分量
深度优先搜索的下一个直接应用就是找出一幅图的所有连通分量。在 union-find中 “与......连通” 是一种等价关系,它能够将所有顶点切分成等价类(连通分量)。

实现
CC 的实现使用了marked 数组来寻找一个顶点作为每个连通分量中深度优先搜索的起点。递归的深度优先搜索第一次调用的参数是顶点 0 -- 它会标记所有与 0 连通的顶点。然后构造函数中的 for 循环会查找每个没有被标记的顶点并递归调用 Dfs 来标记和它相邻的所有顶点。另外,还使用了一个以顶点作为索引的数组 id[ ] ,值为连通分量的标识符,将同一连通分量中的顶点和连通分量的标识符关联起来。这个数组使得 Connected 方法的实现变得非常简单。
namespace Graphs
{
public class CC
{
private bool[] marked;
private int[] id;
private int count;
public CC(Graph G)
{
marked = new bool[G.V()];
id = new int[G.V()];
for (var s = 0; s < G.V(); s++)
{
if (!marked[s])
{
Dfs(G,s);
count++;
}
}
}
private void Dfs(Graph G, int v)
{
marked[v] = true;
id[v] = count;
foreach (var w in G.Adj(v))
{
if (!marked[w])
Dfs(G,w);
}
}
public bool Connected(int v, int w)
{
return id[v] == id[w];
}
public int Id(int v)
{
return id[v];
}
public int Count()
{
return count;
}
}
}深度优先搜索的预处理使用的时间和空间与 V + E 成正比且可以在常数时间内处理关于图的连通性查询。由代码可知每个邻接表的元素都只会被检查一次,共有 2E 个元素(每条边两个)。
union-find 算法
CC 中基于深度优先搜索来解决图连通性问题的方法与 union-find算法 中的算法相比,理论上,深度优先搜索更快,因为它能保证所需的时间是常数而 union-find算法不行;但在实际应用中,这点差异微不足道。union-find算法其实更快,因为它不需要完整地构造表示一幅图。更重要的是,union-find算法是一种动态算法(我们在任何时候都能用接近常数的时间检查两个顶点是否连通,甚至是添加一条边的时候),但深度优先搜索则必须对图进行预处理。
因此,我们在只需要判断连通性或是需要完成大量连通性查询和插入操作混合等类似的任务时,更倾向使用union-find算法,而深度优先搜索则适合实现图的抽象数据类型,因为它能更有效地利用已有的数据结构。
使用深度优先搜索还可以解决 检测环 和双色问题:
检测环,给定的图是无环图吗?
namespace Graphs
{
public class Cycle
{
private bool[] marked;
private bool hasCycle;
public Cycle(Graph G)
{
marked = new bool[G.V()];
for (var s = 0; s < G.V(); s++)
{
if (!marked[s])
Dfs(G,s,s);
}
}
private void Dfs(Graph g, int v, int u)
{
marked[v] = true;
foreach (var w in g.Adj(v))
{
if (!marked[w])
Dfs(g, w, v);
else if (w != u)
hasCycle = true;
}
}
public bool HasCycle()
{
return hasCycle;
}
}
}是二分图吗?(双色问题)
namespace Graphs
{
public class TwoColor
{
private bool[] marked;
private bool[] color;
private bool isTwoColorable = true;
public TwoColor(Graph G)
{
marked = new bool[G.V()];
color = new bool[G.V()];
for(var s = 0;s<G.V();s++)
{
if (!marked[s])
Dfs(G,s);
}
}
private void Dfs(Graph g, int v)
{
marked[v] = true;
foreach (var w in g.Adj(v))
{
if (!marked[w])
{
color[w] = !color[v];
Dfs(g, w);
}
else if (color[w] == color[v])
isTwoColorable = false;
}
}
public bool IsBipartite()
{
return isTwoColorable;
}
}
}8.符号图
在典型应用中,图都是通过文件或者网页定义的,使用的是字符串而非整数来表示和指代顶点。为了适应这样的应用,我们使用符号图。符号图的API:

这份API 定义一个构造函数来读取并构造图,用 name() 和 index() 方法将输入流中的顶点名和图算法使用的顶点索引对应起来。
实现
需要用到3种数据结构:
- 1.一个符号表 st ,键的类型为 string(顶点名),值的类型 int (索引);
- 2.一个数组 keys[ ],用作反向索引,保存每个顶点索引对应的顶点名;
- 3.一个 Graph 对象 G,它使用索引来引用图中顶点。
SymbolGraph 会遍历两遍数据来构造以上数据结构,这主要是因为构造 Graph 对象需要顶点总数 V。在典型的实际应用中,在定义图的文件中指明 V 和 E 可能会有些不便,而有了 SymbolGraph,就不需要担心维护边或顶点的总数。
namespace Graphs
{
public class SymbolGraph
{
private Dictionary<string, int> st;//符号名 -> 索引
private string[] keys;//索引 -> 符号名
private Graph G;
public SymbolGraph(string fileName, string sp)
{
var strs = File.ReadAllLines(fileName);
st = new Dictionary<string, int>();
//第一遍
foreach (var str in strs)
{
var _strs = str.Split(sp);
foreach (var _str in _strs)
{
st.Add(_str,st.Count);
}
}
keys = new string[st.Count];
foreach (var name in st.Keys)
{
keys[st[name]] = name;
}
//第二遍 将每一行的第一个顶点和该行的其他顶点相连
foreach (var str in strs)
{
var _strs = str.Split(sp);
int v = st[_strs[0]];
for (var i = 1; i < _strs.Length; i++)
{
G.AddEdge(v,st[_strs[i]]);
}
}
}
public bool Contains(string s)
{
return st.ContainsKey(s);
}
public int Index(string s)
{
return st[s];
}
public string Name(int v)
{
return keys[v];
}
public Graph Gra()
{
return G;
}
}
}间隔的度数
可以使用SymbolGraph 和 BreadthFirstPaths 来查找图中的最短路径:

总结

到此这篇关于C#图表算法之无向图的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。
- C#图表算法之最小生成树
- C#图表算法之有向图
- C#图表算法之最短路径
我们今天的关于给定无向图设计算法和设无向图g,要求给出的分享就到这里,谢谢您的阅读,如果想了解更多关于12.boost 有向图无向图 (矩阵法)、15、【图】邻接矩阵无向图和邻接表无向图、2022-11-04:给定一个正数n,表示有多少个节点 给定一个二维数组edges,表示所有无向边 edges[i] = {a, b} 表示a到b有一条无向边 edges一定表示的是一个无环无向图,也、C#图表算法之无向图的相关信息,可以在本站进行搜索。
本文标签:




