如果您想了解Pytorch入门到进阶和实战计算机视觉与自然语言处理项目的知识,那么本篇文章将是您的不二之选。我们将深入剖析Pytorch入门到进阶的各个方面,并为您解答实战计算机视觉与自然语言处理项目
如果您想了解Pytorch入门到进阶和实战计算机视觉与自然语言处理项目的知识,那么本篇文章将是您的不二之选。我们将深入剖析Pytorch入门到进阶的各个方面,并为您解答实战计算机视觉与自然语言处理项目的疑在这篇文章中,我们将为您介绍Pytorch入门到进阶的相关知识,同时也会详细的解释实战计算机视觉与自然语言处理项目的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- Pytorch入门到进阶(实战计算机视觉与自然语言处理项目)(pytorch机器视觉)
- 2020 新书速递: 计算机视觉 PyTorch 秘籍
- NLTK 与自然语言处理基础
- Pytext:Facebook 基于 PyTorch 的自然语言处理(NLP)开源框架
- Python NLTK 自然语言处理入门与例程(转)
(pytorch机器视觉)")
Pytorch入门到进阶(实战计算机视觉与自然语言处理项目)(pytorch机器视觉)
PyTorch是目前深度学习的主流框架之一,它有着成熟的生态、大量开源的源码以及最新的模型,无论学术研究还是工程落地,PyTorch都是主流选择。同时,PyTorch比其他深度学习框架更易学,也是新手入门的好选择。
本课程将算法、模型和基础理论知识进行有机结合,结合多个不同的CV与NLP实战项目,帮助大家掌握PyTorch框架的基础知识和使用方法,并学会利用PyTorch框架解决实际问题。通过本课程,可以较平稳地快速入门深度学习领域,初步掌握解决深度学习基础问题的关键性技能。
PyTorch是一个非常有可能改变深度学习领域前景的Python库。我尝试使用了几星期PyTorch,然后被它的易用性所震惊,在我使用过的各种深度学习库中,PyTorch是最灵活、最容易掌握的。
PyTorch的概述
PyTorch的创始人说过他们创作的一个准则——他们想成为当务之急。这意味着我们可以立即执行计算。这正好符合Python的编程方法,不需要完成全部代码才能运行,可以轻松的运行部分代码并实时检查。对于我来说把它作为一个神经网络调试器是一件非常幸福的事。
PyTorch是一个基于Python的库,用来提供一个具有灵活性的深度学习开发平台。PyTorch的工作流程非常接近Python的科学计算库——numpy。
现在你可能会问,为什么我们要用PyTorch来建立深度学习模型呢?我可以列出三件有助于回答的事情:
·易于使用的API—它就像Python一样简单。
·Python的支持—如上所述,PyTorch可以顺利地与Python数据科学栈集成。它非常类似于numpy,甚至注意不到它们的差别。
·动态计算图—取代了具有特定功能的预定义图形,PyTorch为我们提供了一个框架,以便可以在运行时构建计算图,甚至在运行时更改它们。在不知道创建神经网络需要多少内存的情况下这非常有价值。
PyTorch的其他一些优点还包括:多gpu支持,自定义数据加载器和简化的预处理器。
自从2016年1月发布以来,许多研究人员将其作为一种“go-to”库,因为它可以轻松地构建新颖的甚至是极其复杂的图形。虽说如此,PyTorch仍有一段时间没有被大多数数据科学实践者采用,因为它是新的而且处于“正在建设”的状态。

2020 新书速递: 计算机视觉 PyTorch 秘籍
由于公众号修改了推送规则,请加星标,多点在看,以便第一时间收到推送。
〄机器学习与数学

1内容简介
计算机视觉技术在帮助开发人员获得对数字图像和视频的高级理解中扮演着不可或缺的角色。本书内容包括,
-
从快速概述 PyTorch 库和关键的深度学习概念开始,本书将介绍在执行图像识别、图像分割、对象检测、图像生成和视频处理等任务时面临的常见和不常见的挑战。
-
接下来,你将了解如何使用各种深度学习架构来实现这些任务,例如卷积神经网络(CNN),递归神经网络(RNN),长短期记忆(LSTM)和生成对抗网络(GAN)等。使用问题解决方法,你将学习如何优化模型的性能或将其集成到应用程序中,从而解决可能遇到的任何实际问题。
-
最后,你将掌握如何扩展模型以处理更大的工作量,并实现最佳实践以有效地训练模型。
2学以至用
-
使用 PyTorch 1.x 开发、训练和部署深度学习算法 -
了解如何微调和更改超参数以训练深度学习算法 -
执行各种简历任务,例如分类、检测和分割 -
基于 CNN 和预训练的模型实现神经风格传递网络 -
生成新图像并使用 GAN 实施对抗性攻击 -
实施基于 RNN、LSTM 和 3D-CNN 的视频分类模型 -
训练和部署基于深度学习的 CV 应用程序的最佳实践
3目录
4速览
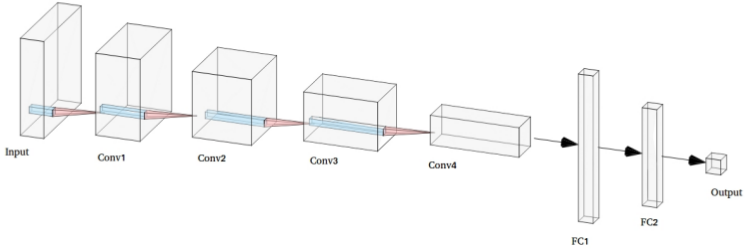
〄图像分类

〄多分类

〄单目标检测

〄多目标检测

〄多目标分割

〄风格迁移

〄视频处理

⟳参考资料⟲
代码: https://github.com/PacktPublishing/PyTorch-Computer-Vision-Cookbook
关注公众号,回复 cvbook 获得本书链接。
本文分享自微信公众号 - 机器学习与数学(Mathinside2016)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

NLTK 与自然语言处理基础
NLTK (Natural Language Toolkit)
NTLK 是著名的 Python 自然语言处理工具包,但是主要针对的是英文处理。NLTK 配套有文档,有语料库,有书籍。
- NLP 领域中最常用的一个 Python 库
- 开源项目
- 自带分类、分词等功能
- 强大的社区支持
- 语料库,语言的实际使用中真是出现过的语言材料
- http://www.nltk.org/py-modindex.html
在 NLTK 的主页详细介绍了如何在 Mac、Linux 和 Windows 下安装 NLTK:http://nltk.org/install.html ,建议直接下载 Anaconda,省去了大部分包的安装,安装 NLTK 完毕,可以 import nltk 测试一下,如果没有问题,还有下载 NLTK 官方提供的相关语料。
安装步骤:
-
下载 NLTK 包
pip install nltk -
运行 Python,并输入下面的指令
import nltk nltk.download() -
弹出下面的窗口,建议安装所有的包 ,即
all -
测试使用:
语料库
nltk.corpus
import nltk
from nltk.corpus import brown # 需要下载brown语料库
# 引用布朗大学的语料库
# 查看语料库包含的类别
print(brown.categories())
# 查看brown语料库
print(''共有{}个句子''.format(len(brown.sents())))
print(''共有{}个单词''.format(len(brown.words())))
执行结果:
[''adventure'', ''belles_lettres'', ''editorial'', ''fiction'', ''government'', ''hobbies'', ''humor'', ''learned'', ''lore'', ''mystery'', ''news'', ''religion'', ''reviews'', ''romance'', ''science_fiction'']
共有57340个句子
共有1161192个单词
分词 (tokenize)
- 将句子拆分成具有语言语义学上意义的词
- 中、英文分词区别:
- 英文中,单词之间是以空格作为自然分界符的
- 中文中没有一个形式上的分界符,分词比英文复杂的多
- 中文分词工具,如:结巴分词
pip install jieba - 得到分词结果后,中英文的后续处理没有太大区别
# 导入jieba分词
import jieba
seg_list = jieba.cut("欢迎来到黑马程序员Python学科", cut_all=True)
print("全模式: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("欢迎来到黑马程序员Python学科", cut_all=False)
print("精确模式: " + "/ ".join(seg_list)) # 精确模式
运行结果:
全模式: 欢迎/ 迎来/ 来到/ 黑马/ 程序/ 程序员/ Python/ 学科
精确模式: 欢迎/ 来到/ 黑马/ 程序员/ Python/ 学科
词形问题
- look, looked, looking
- 影响语料学习的准确度
- 词形归一化
1. 词干提取 (stemming)
示例:
# PorterStemmer
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem(''looked''))
print(porter_stemmer.stem(''looking''))
# 运行结果:
# look
# look
示例:
# SnowballStemmer
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer(''english'')
print(snowball_stemmer.stem(''looked''))
print(snowball_stemmer.stem(''looking''))
# 运行结果:
# look
# look
示例:
# LancasterStemmer
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem(''looked''))
print(lancaster_stemmer.stem(''looking''))
# 运行结果:
# look
# look
2. 词形归并 (lemmatization)
-
stemming,词干提取,如将 ing, ed 去掉,只保留单词主干
-
lemmatization,词形归并,将单词的各种词形归并成一种形式,如 am, is, are -> be, went->go
-
NLTK 中的 stemmer
PorterStemmer, SnowballStemmer, LancasterStemmer
-
NLTK 中的 lemma
WordNetLemmatizer
-
问题
went 动词 -> go, 走 Went 名词 -> Went,文特
-
指明词性可以更准确地进行 lemma
示例:
from nltk.stem import WordNetLemmatizer
# 需要下载wordnet语料库
wordnet_lematizer = WordNetLemmatizer()
print(wordnet_lematizer.lemmatize(''cats''))
print(wordnet_lematizer.lemmatize(''boxes''))
print(wordnet_lematizer.lemmatize(''are''))
print(wordnet_lematizer.lemmatize(''went''))
# 运行结果:
# cat
# box
# are
# went
示例:
# 指明词性可以更准确地进行lemma
# lemmatize 默认为名词
print(wordnet_lematizer.lemmatize(''are'', pos=''v''))
print(wordnet_lematizer.lemmatize(''went'', pos=''v''))
# 运行结果:
# be
# go
3. 词性标注 (Part-Of-Speech)
-
NLTK 中的词性标注
nltk.word_tokenize()
示例:
import nltk
words = nltk.word_tokenize(''Python is a widely used programming language.'')
print(nltk.pos_tag(words)) # 需要下载 averaged_perceptron_tagger
# 运行结果:
# [(''Python'', ''NNP''), (''is'', ''VBZ''), (''a'', ''DT''), (''widely'', ''RB''), (''used'', ''VBN''), (''programming'', ''NN''), (''language'', ''NN''), (''.'', ''.'')]
4. 去除停用词
- 为节省存储空间和提高搜索效率,NLP 中会自动过滤掉某些字或词
- 停用词都是人工输入、非自动化生成的,形成停用词表
-
分类
语言中的功能词,如 the, is…
词汇词,通常是使用广泛的词,如 want
-
中文停用词表
中文停用词库
哈工大停用词表
四川大学机器智能实验室停用词库
百度停用词列表
-
其他语言停用词表
http://www.ranks.nl/stopwords
-
使用 NLTK 去除停用词
stopwords.words()
示例:
from nltk.corpus import stopwords # 需要下载stopwords
filtered_words = [word for word in words if word not in stopwords.words(''english'')]
print(''原始词:'', words)
print(''去除停用词后:'', filtered_words)
# 运行结果:
# 原始词: [''Python'', ''is'', ''a'', ''widely'', ''used'', ''programming'', ''language'', ''.'']
# 去除停用词后: [''Python'', ''widely'', ''used'', ''programming'', ''language'', ''.'']
5. 典型的文本预处理流程
示例:
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
# 原始文本
raw_text = ''Life is like a box of chocolates. You never know what you\''re gonna get.''
# 分词
raw_words = nltk.word_tokenize(raw_text)
# 词形归一化
wordnet_lematizer = WordNetLemmatizer()
words = [wordnet_lematizer.lemmatize(raw_word) for raw_word in raw_words]
# 去除停用词
filtered_words = [word for word in words if word not in stopwords.words(''english'')]
print(''原始文本:'', raw_text)
print(''预处理结果:'', filtered_words)
运行结果:
原始文本: Life is like a box of chocolates. You never know what you''re gonna get.
预处理结果: [''Life'', ''like'', ''box'', ''chocolate'', ''.'', ''You'', ''never'', ''know'', "''re", ''gon'', ''na'', ''get'', ''.'']
使用案例:
import nltk
from nltk.tokenize import WordPunctTokenizer
sent_tokenizer = nltk.data.load(''tokenizers/punkt/english.pickle'')
paragraph = "The first time I heard that song was in Hawaii on radio. I was just a kid, and loved it very much! What a fantastic song!"
# 分句
sentences = sent_tokenizer.tokenize(paragraph)
print(sentences)
sentence = "Are you old enough to remember Michael Jackson attending. the Grammys with Brooke Shields and Webster sat on his lap during the show?"
# 分词
words = WordPunctTokenizer().tokenize(sentence.lower())
print(words)
输出结果:
[''The first time I heard that song was in Hawaii on radio.'', ''I was just a kid, and loved it very much!'', ''What a fantastic song!'']
[''are'', ''you'', ''old'', ''enough'', ''to'', ''remember'', ''michael'', ''jackson'', ''attending'', ''.'', ''the'', ''grammys'', ''with'', ''brooke'', ''shields'', ''and'', ''webster'', ''sat'', ''on'', ''his'', ''lap'', ''during'', ''the'', ''show'', ''?'']
开源框架")
Pytext:Facebook 基于 PyTorch 的自然语言处理(NLP)开源框架
自然语言处理 (NLP) 在现代深度学习生态中越来越常见。从流行的深度学习框架到云端 API 的支持,例如 Google 云、Azure、AWS 或 Bluemix,NLP 是深度学习平台不可或缺的部分。尽管已经取得了令人难以置信的进步,但构建大规模的 NLP 应用依然还有极大的挑战,在学习研究和生产部署之间还存在很多摩擦。作为当前市场上最大的会话环境之一,Facebook 已经面对构建大规模 NLP 应用的挑战有一些年头了,最近,Facebook 的工程团队开源了第一个版本的 Pytext,一个基于 PyTorch 的 NLP 框架,可以用来构建高效的 NLP 解决方案。
PyText 的最终目标是简化端对端的 NLP 工作流实现。为了实现这一目标,PyText 需要解决当前 NLP 流程中的一些问题,其中最令人头疼的就是 NLP 应用在实验环境和生产环境的不匹配问题。
更好地平衡 NLP 实验和生产部署
现代 NLP 解决方案通常包含非常重的实验环节,在这个阶段数据科学家们将借鉴研究文件快速测试新的想法和模型,以便达成一定的性能指标。在实验阶段,数据科学家倾向于使用容易上手、界面简单的框架,以便快速实现高级、动态的模型,例如 PyTorch 或 TensorFlow Eager。当需要部署到生产环境时,动态图模型的固有局限性就带了新的挑战,这一阶段的深度学习技术需要使用静态计算图,并且需要为大规模计算进行优化。TensorFlow、Caffe2 或 MxNet 都属于这一类型的技术栈。结果是大型数据科学团队不得不为实验和生产部署使用不同的技术栈。

PyTorch 是最早解决了快速实验与规模化部署之间冲突的深度学习框架之一。基于 PyTorch 构建的 PyText 为 NLP 领域应用了这些解决实验环境与生产部署之间冲突的优化原则。
理解 PyText
从概念角度触发,PyText 被设计为实现以下四个基本目标:
-
尽可能简单、快速的实现新模型
-
简化将预构建模型应用于新数据的工作量
-
同时为研究者和工程师定义清晰的工作流,以便构建和评估模型,并以最小的代价上线模型
-
确保部署的模型在推理时具有高性能:低延迟、高吞吐量
PyText 的处理容量最终打造的建模框架,可供研究者和工程师构建端到端的训练或推理流水线。当前的 PyText 实现涵盖了 NLP 工作流声明周期中的基本环节,为快速实验、原始数据处理、指标统计、训练和模型推理提供了必要的接口。一个高层级的 PyText 架构图可以清晰地展示这些环节如何封装了框架的原生组件:

如上图所示,PyText 的架构包含以下组成部分:
- Task:将多个用于训练或推理的组件拼装为一个流水线
- Data Handler:处理原始输入数据,贮备张量批数据,以便送入模型
- Model:定义神经网络的架构
- Optimizer:封装模型参数优化过程,基于模型的前馈损失进行优化
- Metric Reporter:实现模型相关指标的计算和报表提供
- Trainer: 使用数据处理器、模型、损失和优化器来训练和筛选模型
- Predictor:使用数据处理器和模型对给定的数据集进行推理
- Exporter: ONNX8 导出训练好的 PyTorch 模型到 Caffe2 图
你可以看到,PyText 利用 ONNX (Open Neural Network Exchange Format) 将模型从实验环境的 PyTorch 格式转换为生产环境的 Caffe2 运行模型。
PyText 预置了众多 NLP 任务组件,例如文本分类、单词标注、语义分析和语言模型等,可以快速实现 NLP 工作流。类似的,PyText 使用上下文模型介入语言理解领域,例如使用 SeqNN 模型用于意图标注任务,或者使用一个上下文相关的意图槽模型用于多个任务的联合训练。
从 NLP 工作流的角度来说,PyText 可以快速将一个思路从实验阶段转换为生产阶段。一个 PyText 应用的典型工作流包含如下的步骤:

- 用 PyText 实现模型,确保测试集上的离线指标正确
- 将模型发布到打包的基于 PyTorch 的推理服务,在实时样本上执行小规模评估
- 自动导出到 Caffe2 网络,不过在有些情况下,例如当使用复杂的流程控制逻辑时,或者使用自定义数据结构式,PyTorch 1.0 还不支持
- 如果第 3 步不支持,那么使用 Py-Torch C++ API9 重写模型,并封装为一个 Caffe2 操作符
- 将模型发布为生产就绪的 Caffe2 预测服务并启动
使用 PyText
上手 PyText 非常简单,按标准 python 包的方法安装框架:
$ pip install pytext-nlp
然后,我们就可以使用一个任务配置来训练 NLP 模型了:
(pytext) $ cat demo/configs/docnn.json
{
"task": {
"DocClassificationTask": {
"data_handler": {
"train_path": "tests/data/train_data_tiny.tsv",
"eval_path": "tests/data/test_data_tiny.tsv",
"test_path": "tests/data/test_data_tiny.tsv"
}
}
}
}
$ pytext train < demo/configs/docnn.json
Task 是 PyText 应用中的用来定义模型的核心部件。每一个任务都有一个嵌入的配置,它定义了不同组件之间的关系,如下面代码所示:
from word_tagging import ModelInputConfig, TargetConfig
class WordTaggingTask(Task):
class Config(Task.Config):
features: ModelInputConfig = ModelInputConfig()
targets: TargetConfig = TargetConfig()
data_handler: WordTaggingDataHandler.Config = WordTaggingDataHandler.Config()
model: WordTaggingModel.Config = WordTaggingModel.Config()
trainer: Trainer.Config = Trainer.Config()
optimizer: OptimizerParams = OptimizerParams()
scheduler: Optional[SchedulerParams] = SchedulerParams()
metric_reporter: WordTaggingMetricReporter.Config = WordTaggingMetricReporter.Config()
exporter: Optional[TextModelExporter.Config] = TextModelExporter.Config()
一旦模型训练完毕,我们就可以对模型进行评估,也可以导出为 Caffe2 格式:
(pytext) $ pytext test < "$CONFIG"
(pytext) $ pytext export --output-path exported_model.c2 < "$CONFIG"
需要指出的是,PyText 提供了可扩展的架构,可以定制、扩展其中任何一个构建模块。
PyText 代表了 NLP 开发的一个重要里程碑,它是最早解决实验与生产匹配问题的框架之一。基于 Facebook 和 PyTorch 社区的支持,PyText 可能有机会称为深度学习生态中最重要的 NLP 技术栈之一。
原文:Pytext 简介 ,转载请标明出处。
原文出处:https://www.cnblogs.com/mailer/p/10177665.html
")
Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720
Python NLTK 自然语言处理入门与例程
- 在这篇文章中,我们将基于 Python 讨论自然语言处理(NLP)。本教程将会使用 Python NLTK 库。NLTK 是一个当下流行的,用于自然语言处理的 Python 库。
那么 NLP 到底是什么?学习 NLP 能带来什么好处?
简单的说,自然语言处理( NLP )就是开发能够理解人类语言的应用程序和服务。
我们生活中经常会接触的自然语言处理的应用,包括语音识别,语音翻译,理解句意,理解特定词语的同义词,以及写出语法正确,句意通畅的句子和段落。
NLP的作用
正如大家所知,每天博客,社交网站和网页会产生数亿字节的海量数据。
有很多公司热衷收集所有这些数据,以便更好地了解他们的用户和用户对产品的热情,并对他们的产品或者服务进行合适的调整。
这些海量数据可以揭示很多现象,打个比方说,巴西人对产品 A 感到满意,而美国人却对产品 B 更感兴趣。通过NLP,这类的信息可以即时获得(即实时结果)。例如,搜索引擎正是一种 NLP,可以在正确的时间给合适的人提供适当的结果。
但是搜索引擎并不是自然语言处理(NLP)的唯一应用。还有更好更加精彩的应用。
NLP的应用
以下都是自然语言处理(NLP)的一些成功应用:
- 搜索引擎,比如谷歌,雅虎等等。谷歌等搜索引擎会通过NLP了解到你是一个科技发烧友,所以它会返回科技相关的结果。
- 社交网站信息流,比如 Facebook 的信息流。新闻馈送算法通过自然语言处理了解到你的兴趣,并向你展示相关的广告以及消息,而不是一些无关的信息。
- 语音助手,诸如苹果 Siri。
- 垃圾邮件程序,比如 Google 的垃圾邮件过滤程序 ,这不仅仅是通常会用到的普通的垃圾邮件过滤,现在,垃圾邮件过滤器会对电子邮件的内容进行分析,看看该邮件是否是垃圾邮件。
NLP库
现在有许多开源的自然语言处理(NLP)库。比如:
- Natural language toolkit (NLTK)
- Apache OpenNLP
- Stanford NLP suite
- Gate NLP library
自然语言工具包(NLTK)是最受欢迎的自然语言处理(NLP)库。它是用 Python 语言编写的,背后有强大的社区支持。
NLTK 也很容易入门,实际上,它将是你用到的最简单的自然语言处理(NLP)库。
在这个 NLP 教程中,我们将使用 Python NLTK 库。在开始安装 NLTK 之前,我假设你知道一些 Python入门知识。
安装 NLTK
如果你使用的是 Windows , Linux 或 Mac,你可以 使用PIP 安装NLTK: # pip install nltk。
在本文撰写之时,你可以在 Python 2.7 , 3.4 和 3.5 上都可以使用NLTK。或者可以通过获取tar 进行源码安装。
要检查 NLTK 是否正确地安装完成,可以打开你的Python终端并输入以下内容:Import nltk。如果一切顺利,这意味着你已经成功安装了 NLTK 库。
一旦你安装了 NLTK,你可以运行下面的代码来安装 NLTK 包:
import nltk
nltk.download()这将打开 NLTK 下载器来选择需要安装的软件包。
你可以选择安装所有的软件包,因为它们的容量不大,所以没有什么问题。现在,我们开始学习吧!
使用原生 Python 来对文本进行分词
首先,我们将抓取一些网页内容。然后来分析网页文本,看看爬下来的网页的主题是关于什么。我们将使用 urllib模块来抓取网页:
import urllib.request
response = urllib.request.urlopen(''http://php.net/'') html = response.read() print (html)从打印输出中可以看到,结果中包含许多需要清理的HTML标记。我们可以用这个 BeautifulSoup 库来对抓取的文本进行处理:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen(''http://php.net/'') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) print (text)现在,我们能将抓取的网页转换为干净的文本。这很棒,不是么?
最后,让我们通过以下方法将文本分词:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen(''http://php.net/'') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = [t for t in text.split()] print (tokens)词频统计
现在的文本相比之前的 html 文本好多了。我们再使用 Python NLTK 来计算每个词的出现频率。NLTK 中的FreqDist( ) 函数可以实现词频统计的功能 :
from bs4 import BeautifulSoup
import urllib.request
import nltk response = urllib.request.urlopen(''http://php.net/'') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = [t for t in text.split()] freq = nltk.FreqDist(tokens) for key,val in freq.items(): print (str(key) + '':'' + str(val))如果你查看输出结果,会发现最常用的词语是PHP。
你可以用绘图函数为这些词频绘制一个图形: freq.plot(20, cumulative=False)。
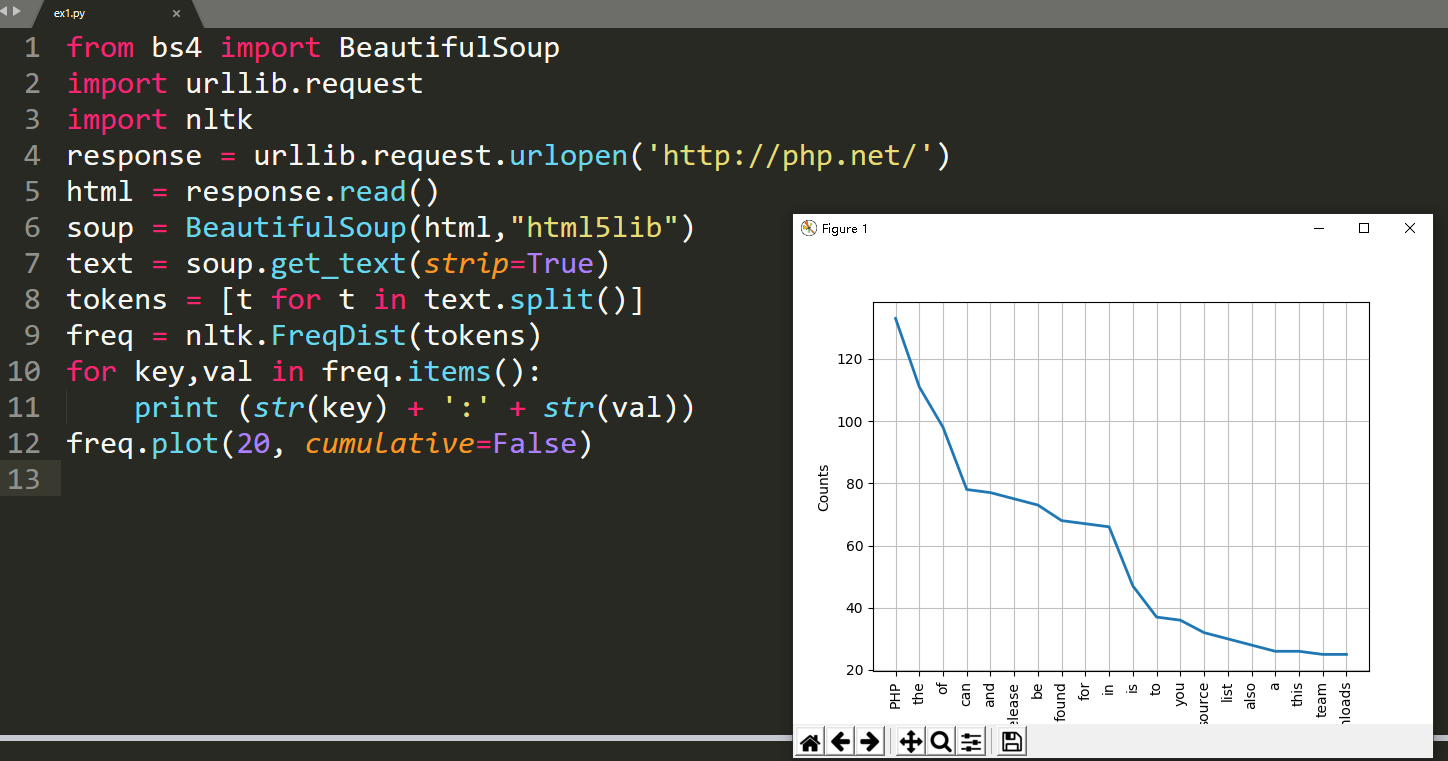
从图中,你可以肯定这篇文章正在谈论 PHP。这很棒!有一些词,如"the," "of," "a," "an," 等等。这些词是停止词。一般来说,停止词语应该被删除,以防止它们影响我们的结果。
使用 NLTK 删除停止词
NLTK 具有大多数语言的停止词表。要获得英文停止词,你可以使用以下代码:
from nltk.corpus import stopwords
stopwords.words(''english'')现在,让我们修改我们的代码,并在绘制图形之前清理标记。首先,我们复制一个列表。然后,我们通过对列表中的标记进行遍历并删除其中的停止词:
clean_tokens = tokens[:]
sr = stopwords.words(''english'') for token in tokens: if token in stopwords.words(''english''): clean_tokens.remove(token)你可以在这里查看Python List 函数, 了解如何处理列表。
最终的代码应该是这样的:
from bs4 import BeautifulSoup
import urllib.request
import nltk from nltk.corpus import stopwords response = urllib.request.urlopen(''http://php.net/'') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = [t for t in text.split()] clean_tokens = tokens[:] sr = stopwords.words(''english'') for token in tokens: if token in stopwords.words(''english''): clean_tokens.remove(token) freq = nltk.FreqDist(clean_tokens) for key,val in freq.items(): print (str(key) + '':'' + str(val))如果你现在检查图表,会感觉比之前那张图标更加清晰,因为没有了停止词的干扰。
freq.plot(20,cumulative=False)使用 NLTK 对文本分词
我们刚刚了解了如何使用 split( ) 函数将文本分割为标记 。现在,我们将看到如何使用 NLTK 对文本进行标记化。对文本进行标记化是很重要的,因为文本无法在没有进行标记化的情况下被处理。标记化意味着将较大的部分分隔成更小的单元。
你可以将段落分割为句子,并根据你的需要将句子分割为单词。NLTK 具有内置的句子标记器和词语标记器。
假设我们有如下的示例文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.为了将这个文本标记化为句子,我们可以使用句子标记器:
from nltk.tokenize import sent_tokenize
mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))输出如下:
[''Hello Adam, how are you?'', ''I hope everything is going well.'', ''Today is a good day, see you dude.'']你可能会说,这是一件容易的事情。我不需要使用 NLTK 标记器,并且我可以使用正则表达式来分割句子,因为每个句子前后都有标点符号或者空格。
那么,看看下面的文字:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.呃!Mr. 是一个词,虽然带有一个符号。让我们来试试使用 NLTK 进行分词:
from nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))输出如下所示:
[''Hello Mr. Adam, how are you?'', ''I hope everything is going well.'', ''Today is a good day, see you dude.'']Great!结果棒极了。然后我们尝试使用词语标记器来看看它是如何工作的:
from nltk.tokenize import word_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(word_tokenize(mytext))输出如下:
[''Hello'', ''Mr.'', ''Adam'', '','', ''how'', ''are'', ''you'', ''?'', ''I'', ''hope'', ''everything'', ''is'', ''going'', ''well'', ''.'', ''Today'', ''is'', ''a'', ''good'', ''day'', '','', ''see'', ''you'', ''dude'', ''.'']正如所料,Mr. 是一个词,也确实被 NLTK 当做一个词。NLTK使用 nltk.tokenize.punkt module 中的 PunktSentenceTokenizer 进行文本分词。这个标记器经过了良好的训练,可以对多种语言进行分词 。
标记非英语语言文本
为了标记其他语言,可以像这样指定语言:
from nltk.tokenize import sent_tokenize
mytext = "Bonjour M. Adam, comment allez-vous? J''espère que tout va bien. Aujourd''hui est un bon jour." print(sent_tokenize(mytext,"french"))结果将是这样的:
[''Bonjour M. Adam, comment allez-vous?'', "J''espère que tout va bien.", "Aujourd''hui est un bon jour."]NLTk 对其他非英语语言的支持也非常好!
从 WordNet 获取同义词
如果你还记得我们使用 nltk.download( ) 安装 NLTK 的扩展包时。其中一个扩展包名为 WordNet。WordNet 是为自然语言处理构建的数据库。它包括部分词语的一个同义词组和一个简短的定义。
通过 NLTK 你可以得到给定词的定义和例句:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain") print(syn[0].definition()) print(syn[0].examples())结果是:
a symptom of some physical hurt or disorder
[''the patient developed severe pain and distension'']WordNet 包含了很多词的定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP") print(syn[0].definition()) syn = wordnet.synsets("Python") print(syn[0].definition())结果是:
the branch of information science that deals with natural language information
large Old World boas您可以使用 WordNet 来获得同义词:
from nltk.corpus import wordnet
synonyms = [] for syn in wordnet.synsets(''Computer''): for lemma in syn.lemmas(): synonyms.append(lemma.name()) print(synonyms)输出是:
[''computer'', ''computing_machine'', ''computing_device'', ''data_processor'', ''electronic_computer'', ''information_processing_system'', ''calculator'', ''reckoner'', ''figurer'', ''estimator'', ''computer'']Cool!
从 WordNet 获取反义词
你可以用同样的方法得到单词的反义词。你唯一要做的是在将 lemmas 的结果加入数组之前,检查结果是否确实是一个正确的反义词。
from nltk.corpus import wordnet
antonyms = [] for syn in wordnet.synsets("small"): for l in syn.lemmas(): if l.antonyms(): antonyms.append(l.antonyms()[0].name()) print(antonyms)输出是:
[''large'', ''big'', ''big'']这就是 NLTK 在自然语言处理中的力量。
NLTK词干提取
单词词干提取就是从单词中去除词缀并返回词根。(比方说 working 的词干是 work。)搜索引擎在索引页面的时候使用这种技术,所以很多人通过同一个单词的不同形式进行搜索,返回的都是相同的,有关这个词干的页面。
词干提取的算法有很多,但最常用的算法是 Porter 提取算法。NLTK 有一个 PorterStemmer 类,使用的就是 Porter 提取算法。
from nltk.stem import PorterStemmer
stemmer = PorterStemmer() print(stemmer.stem(''working''))结果是: work
结果很清楚。
还有其他一些提取算法,如 Lancaster 提取算法。这个算法的输出同 Porter 算法的结果在几个单词上不同。你可以尝试他们两个算法来查看有哪些不同结果。
提取非英语单词词干
SnowballStemmer 类,除了英语外,还可以适用于其他 13 种语言。支持的语言如下:
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages) ''danish'', ''dutch'', ''english'', ''finnish'', ''french'', ''german'', ''hungarian'', ''italian'', ''norwegian'', ''porter'', ''portuguese'', ''romanian'', ''russian'', ''spanish'', ''swedish''你可以使用 SnowballStemmer 类的 stem( )函数来提取非英语单词,如下所示:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer(''french'') print(french_stemmer.stem("French word"))来自法国的朋友欢迎在评论区 poll 出你们测试的结果!
使用 WordNet 引入词汇
词汇的词汇化与提取词干类似,但不同之处在于词汇化的结果是一个真正的词汇。与词干提取不同,当你试图提取一些词干时,有可能会导致这样的情况:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer() print(stemmer.stem(''increases''))结果是:increas。
现在,如果我们试图用NLTK WordNet来还原同一个词,结果会是正确的:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize(''increases''))结果是 increase。
结果可能是同义词或具有相同含义的不同词语。有时,如果你试图还原一个词,比如 playing,还原的结果还是 playing。这是因为默认还原的结果是名词,如果你想得到动词,可以通过以下的方式指定。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize(''playing'', pos="v"))结果是: play。
实际上,这是一个非常好的文本压缩水平。最终压缩到原文本的 50% 到 60% 左右。结果可能是动词,名词,形容词或副词:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize(''playing'', pos="v")) print(lemmatizer.lemmatize(''playing'', pos="n")) print(lemmatizer.lemmatize(''playing'', pos="a")) print(lemmatizer.lemmatize(''playing'', pos="r"))结果是:
play
playing
playing
playing词干化和词化差异
好吧,让我们分别尝试一些单词的词干提取和词形还原:
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer stemmer = PorterStemmer() lemmatizer = WordNetLemmatizer() print(stemmer.stem(''stones'')) print(stemmer.stem(''speaking'')) print(stemmer.stem(''bedroom'')) print(stemmer.stem(''jokes'')) print(stemmer.stem(''lisa'')) print(stemmer.stem(''purple'')) print(''----------------------'') print(lemmatizer.lemmatize(''stones'')) print(lemmatizer.lemmatize(''speaking'')) print(lemmatizer.lemmatize(''bedroom'')) print(lemmatizer.lemmatize(''jokes'')) print(lemmatizer.lemmatize(''lisa'')) print(lemmatizer.lemmatize(''purple''))结果是:
stone
speak
bedroom
joke
lisa
purpl
---------------------- stone speaking bedroom joke lisa purple词干提取的方法可以在不知道语境的情况下对词汇使用,这就是为什么它相较词形还原方法速度更快但准确率更低。
在我看来,词形还原比提取词干的方法更好。词形还原,如果实在无法返回这个词的变形,也会返回另一个真正的单词;这个单词可能是一个同义词,但不管怎样这是一个真正的单词。当有时候,你不关心准确度,需要的只是速度。在这种情况下,词干提取的方法更好。
我们在本 NLP 教程中讨论的所有步骤都涉及到文本预处理。在以后的文章中,我们将讨论使用Python NLTK进行文本分析。
python机器学习——NLTK及分析文本数据(自然语言处理基础)
自然语言处理—文本情感分析
关于Pytorch入门到进阶和实战计算机视觉与自然语言处理项目的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于2020 新书速递: 计算机视觉 PyTorch 秘籍、NLTK 与自然语言处理基础、Pytext:Facebook 基于 PyTorch 的自然语言处理(NLP)开源框架、Python NLTK 自然语言处理入门与例程(转)等相关知识的信息别忘了在本站进行查找喔。
本文标签:




