对于什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍学习资料中的
对于什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍学习资料中的文档材料,并为您提供关于1.1大数据平台架构及Hadoop生态圈、Hadoop - 企业级大数据管理平台 CDH (安装 Hadoop 组件)、Hadoop 入门进阶课程 12--Flume 介绍、安装与应用案例、Hadoop 学习系列之 Hadoop、Spark 学习路线(很值得推荐)的有用信息。
本文目录一览:- 什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介(学习资料中的文档材料)
- 1.1大数据平台架构及Hadoop生态圈
- Hadoop - 企业级大数据管理平台 CDH (安装 Hadoop 组件)
- Hadoop 入门进阶课程 12--Flume 介绍、安装与应用案例
- Hadoop 学习系列之 Hadoop、Spark 学习路线(很值得推荐)
")
什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介(学习资料中的文档材料)
一. HADOOP背景介绍
1. 1.1 什么是HADOOP
1. HADOOP是apache旗下的一套开源软件平台
2. HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3. HADOOP的核心组件有
A. HDFS(分布式文件系统)
B. YARN(运算资源调度系统)
C. MAPREDUCE(分布式运算编程框架)
4. 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
2. 1.2 HADOOP产生背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3. Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
3. 1.3 HADOOP在大数据、云计算中的位置和关系
1. 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2. 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3. 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
4. 1.4 国内外HADOOP应用案例介绍
1、HADOOP应用于数据服务基础平台建设
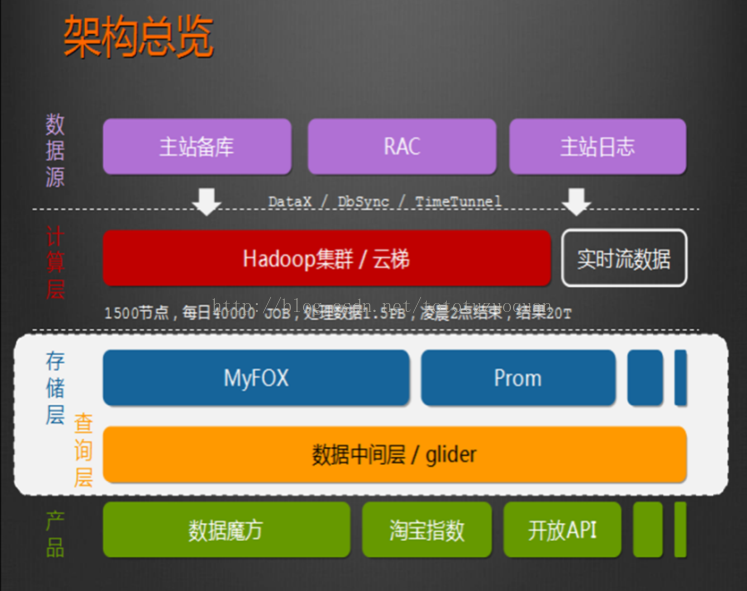
2/HADOOP用于用户画像

3、HADOOP用于网站点击流日志数据挖掘
金融行业:个人征信分析
证券行业:投资模型分析
交通行业:车辆、路况监控分析
电信行业:用户上网行为分析
......
总之:hadoop并不会跟某种具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具
5. 1.5 国内HADOOP的就业情况分析
1、 HADOOP就业整体情况
A. 大数据产业已纳入国家十三五规划
B. 各大城市都在进行智慧城市项目建设,而智慧城市的根基就是大数据综合平台
C. 互联网时代数据的种类,增长都呈现爆发式增长,各行业对数据的价值日益重视
D. 相对于传统JAVAEE技术领域来说,大数据领域的人才相对稀缺
E. 随着现代社会的发展,数据处理和数据挖掘的重要性只会增不会减,因此,大数据技术是一个尚在蓬勃发展且具有长远前景的领域
2、 HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
A. HADOOP分布式集群的平台搭建
B. HADOOP分布式文件系统HDFS的原理理解及使用
C. HADOOP分布式运算框架MAPREDUCE的原理理解及编程
D. Hive数据仓库工具的熟练应用
E. Flume、sqoop、oozie等辅助工具的熟练使用
F. Shell/python等脚本语言的开发能力
6. 1.6 HADOOP生态圈以及各组成部分的简介
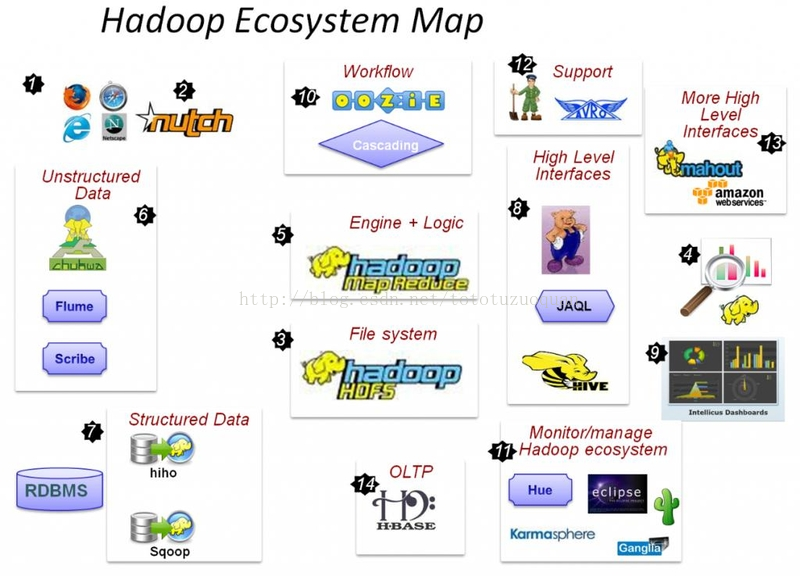
各组件简介[M1]
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
HADOOP(hdfs、MAPREDUCE、yarn) 元老级大数据处理技术框架,擅长离线数据分析
Zookeeper 分布式协调服务基础组件
Hbase 分布式海量数据库,离线分析和在线业务通吃
Hive sql 数据仓库工具,使用方便,功能丰富,基于MR延迟大
Sqoop数据导入导出工具
Flume数据采集框架

1.1大数据平台架构及Hadoop生态圈
1.硬件架构实例
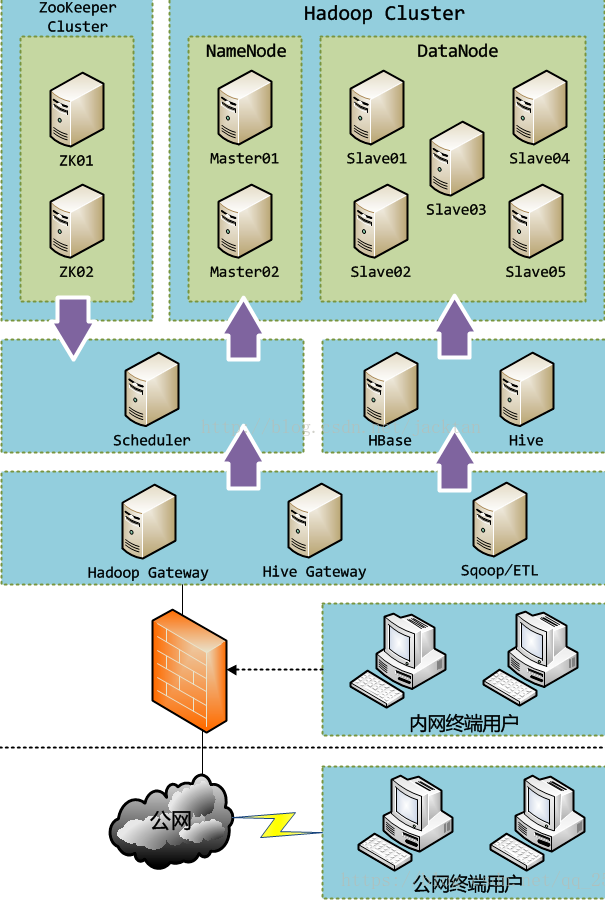
2.软件架构实例
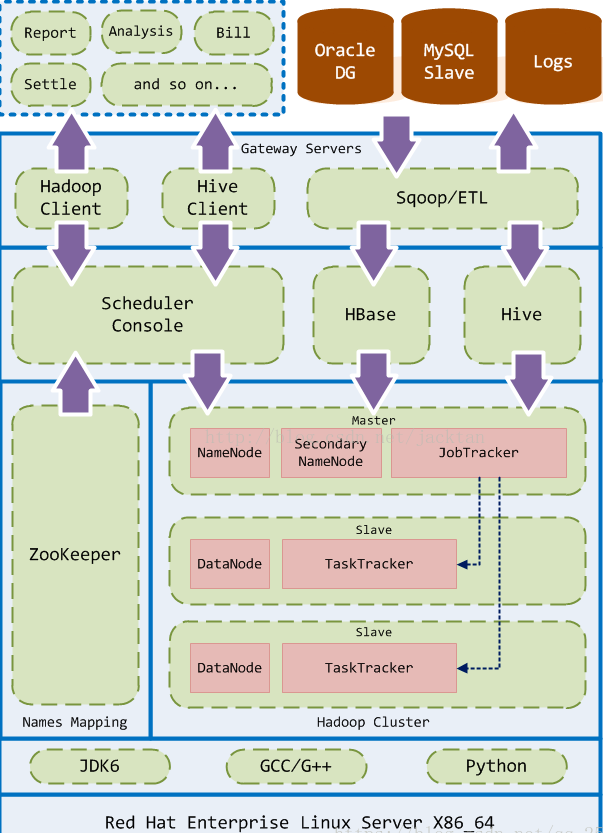
3.数据流通用概念模型
a.数据源(互联网、物联网、企业数据):App、Device、Site
b.数据收集(ETL、提取、转换、加载):Flume、Kafka、Sqoop
c.数据存储:HDFS、Hive/HBase
d.资源管理:Yarn、Mesos
e.批处理:MapReduce、Spark core
流处理:Storm、Spark streaming
f.数据挖掘(OLAP、BI):Mahout、MLlib
g.数据可视化(report)
4.Hadoop生态圈

")
Hadoop - 企业级大数据管理平台 CDH (安装 Hadoop 组件)

当我们已经把 cm-service 和 cm-agent 安装完成之后,接下来我们就要到最重要的部分了,安装 Hadoop 组件
附上:
喵了个咪的博客:w-blog.cn
cloudera 官网: https://www.cloudera.com/
官方文档地址: https://www.cloudera.com/documentation/enterprise/latest.html
一,主机 agent 安装配置
接着上篇文章的页面点击下一步:

填入主机的名称或在已托管主机选择一下主机
cm
master-1
master-2
slave-1
slave-2
slave-3

下一步选择我们之前下载好的 parcel

等待系统自动分发


完成之后在进行下一步

检查集群正确性

以上的几个提示不解决也可以,为了美观我们还是处理掉上面的问题
用户和用户组
useradd cloudera-scm
swappiness
echo 10 > /proc/sys/vm/swappiness
透明页面
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
点击页面头部的重新运行,我们就得到一个干净的主机检查了

二,大数据组件安装
主要组件分布
cm cloudManageService oozie HUE
master-1 Zookeeper NameNode HbaseMaster YARN HiveMetastore
master-2 Zookeeper NameNode HbaseMaster YARN HiveMetastore
slave-1 Zookeeper DataNode HbaseRegion NodeManger
slave-2 Zookeeper DataNode HbaseRegion NodeManger
slave-3 Zookeeper DataNode HbaseRegion NodeManger
选择创建集群:

勾选我们需要的组件

对组件中的各个实例修改安装的主机实例


PS: 如果大家发现安装完成之后有组件挂掉,并且不能解决可以尝试减少安装的组件数量,比如 oozie 和 hue 可以在后面安装,先安装好核心组件
数据库配置 (先去 MYSQL 创建好对应的数据库)

配置修改 (先使用默认配置)

开始安装运行组件


愉快的开始使用了


三,HUE load balancer 启动失败问题解决
需要先安装一下下面两个包之后在重启
yum install httpd mod_ssl


Hadoop 入门进阶课程 12--Flume 介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan 。该系列课程是应邀实验楼整理编写的,这里需要赞一下实验楼提供了学习的新方式,可以边看博客边上机实验,课程地址为 https://www.shiyanlou.com/courses/237
【注】该系列所使用到安装包、测试数据和代码均可在百度网盘下载,具体地址为 http://pan.baidu.com/s/10PnDs,下载该 PDF 文件
1、搭建环境
部署节点操作系统为 CentOS,防火墙和 SElinux 禁用,创建了一个 shiyanlou 用户并在系统根目录下创建 /app 目录,用于存放 Hadoop 等组件运行包。因为该目录用于安装 hadoop 等组件程序,用户对 shiyanlou 必须赋予 rwx 权限(一般做法是 root 用户在根目录下创建 /app 目录,并修改该目录拥有者为 shiyanlou (chown –R shiyanlou:shiyanlou /app)。
Hadoop 搭建环境:
l 虚拟机操作系统: CentOS6.6 64 位,单核,1G 内存
l JDK:1.7.0_55 64 位
l Hadoop:1.1.2
2、Flume 介绍
Flume 是 Cloudera 提供的日志收集系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 Flume 是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。
Flume 具有 Reliability、Scalability、Manageability 和 Extensibility 特点:
1.Reliability:Flume 提供 3 中数据可靠性选项,包括 End-to-end、Store on failure 和 Best effort。其中 End-to-end 使用了磁盘日志和接受端 Ack 的方式,保证 Flume 接受到的数据会最终到达目的。Store on failure 在目的不可用的时候,数据会保持在本地硬盘。和 End-to-end 不同的是,如果是进程出现问题,Store on failure 可能会丢失部分数据。Best effort 不做任何 QoS 保证。
2.Scalability:Flume 的 3 大组件:collector、master 和 storage tier 都是可伸缩的。需要注意的是,Flume 中对事件的处理不需要带状态,它的 Scalability 可以很容易实现。
3.Manageability:Flume 利用 ZooKeeper 和 gossip,保证配置数据的一致性、高可用。同时,多 Master,保证 Master 可以管理大量的节点。
4.Extensibility:基于 Java,用户可以为 Flume 添加各种新的功能,如通过继承 Source,用户可以实现自己的数据接入方式,实现 Sink 的子类,用户可以将数据写往特定目标,同时,通过 SinkDecorator,用户可以对数据进行一定的预处理。
2.1 Flume 架构
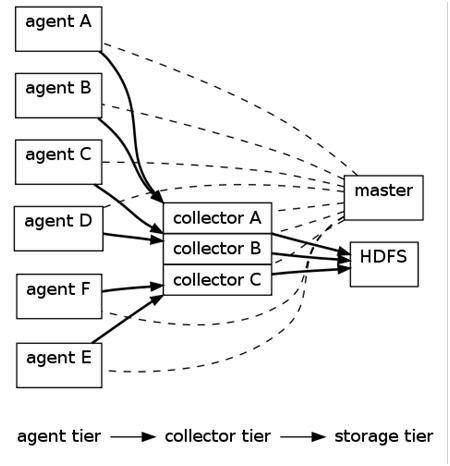
上图的 Flume 的架构中最重要的抽象是 data flow(数据流),data flow 描述了数据从产生,传输、处理并最终写入目标的一条路径(在上图中,实线描述了 data flow)。 Agent 用于采集数据,agent 是 flume 中产生数据流的地方,同时,agent 会将产生的数据流传输到 collector。对应的,collector 用于对数据进行聚
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan 。该系列课程是应邀实验楼整理编写的,这里需要赞一下实验楼提供了学习的新方式,可以边看博客边上机实验,课程地址为 https://www.shiyanlou.com/courses/237
【注】该系列所使用到安装包、测试数据和代码均可在百度网盘下载,具体地址为 http://pan.baidu.com/s/10PnDs,下载该 PDF 文件
1、搭建环境
部署节点操作系统为 CentOS,防火墙和 SElinux 禁用,创建了一个 shiyanlou 用户并在系统根目录下创建 /app 目录,用于存放 Hadoop 等组件运行包。因为该目录用于安装 hadoop 等组件程序,用户对 shiyanlou 必须赋予 rwx 权限(一般做法是 root 用户在根目录下创建 /app 目录,并修改该目录拥有者为 shiyanlou (chown –R shiyanlou:shiyanlou /app)。
Hadoop 搭建环境:
l 虚拟机操作系统: CentOS6.6 64 位,单核,1G 内存
l JDK:1.7.0_55 64 位
l Hadoop:1.1.2
2、Flume 介绍
Flume 是 Cloudera 提供的日志收集系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 Flume 是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。
Flume 具有 Reliability、Scalability、Manageability 和 Extensibility 特点:
1.Reliability:Flume 提供 3 中数据可靠性选项,包括 End-to-end、Store on failure 和 Best effort。其中 End-to-end 使用了磁盘日志和接受端 Ack 的方式,保证 Flume 接受到的数据会最终到达目的。Store on failure 在目的不可用的时候,数据会保持在本地硬盘。和 End-to-end 不同的是,如果是进程出现问题,Store on failure 可能会丢失部分数据。Best effort 不做任何 QoS 保证。
2.Scalability:Flume 的 3 大组件:collector、master 和 storage tier 都是可伸缩的。需要注意的是,Flume 中对事件的处理不需要带状态,它的 Scalability 可以很容易实现。
3.Manageability:Flume 利用 ZooKeeper 和 gossip,保证配置数据的一致性、高可用。同时,多 Master,保证 Master 可以管理大量的节点。
4.Extensibility:基于 Java,用户可以为 Flume 添加各种新的功能,如通过继承 Source,用户可以实现自己的数据接入方式,实现 Sink 的子类,用户可以将数据写往特定目标,同时,通过 SinkDecorator,用户可以对数据进行一定的预处理。
2.1 Flume 架构
上图的 Flume 的架构中最重要的抽象是 data flow(数据流),data flow 描述了数据从产生,传输、处理并最终写入目标的一条路径(在上图中,实线描述了 data flow)。 Agent 用于采集数据,agent 是 flume 中产生数据流的地方,同时,agent 会将产生的数据流传输到 collector。对应的,collector 用于对数据进行聚合,往往会产生一个更大的流。
Flume 提供了从 console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog 日志系统,支持 TCP 和 UDP 等 2 种模式),exec(命令执行)等数据源上收集数据的能力。同时,Flume 的数据接受方,可以是 console(控制台)、text(文件)、dfs(HDFS 文件)、RPC(Thrift-RPC)和 syslogTCP(TCP syslog 日志系统)等。
其中,收集数据有 2 种主要工作模式,如下:
1. Push Sources:外部系统会主动地将数据推送到 Flume 中,如 RPC、syslog。
2. Polling Sources:Flume 到外部系统中获取数据,一般使用轮询的方式,如 text 和 exec。
注意,在 Flume 中,agent 和 collector 对应,而 source 和 sink 对应。Source 和 sink 强调发送、接受方的特性(如数据格式、编码等),而 agent 和 collector 关注功能。
2.2 Flume 管理方式
Flume Master 用于管理数据流的配置,如下图。
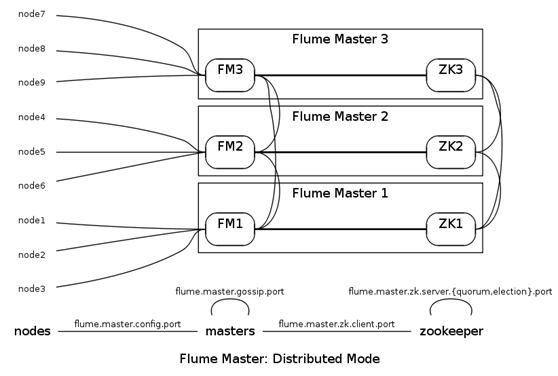
为了保证可扩展性,Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper,用于保存配置数据,ZooKeeper 本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper 可以通知 Flume Master 节点。
Flume Master 间使用 gossip 协议同步数据。
3、安装部署 Flume
3.1 Flume 部署过程
3.1.1 下载 Flume
可以到 apache 基金 flume 官网 http://flume.apache.org/download.html,选择镜像下载地址 http://mirrors.hust.edu.cn/apache/flume/ 下载一个稳定版本,如下图所示下载 flume-1.5.2-bin.tar.gz:
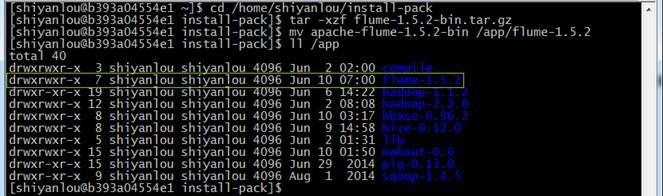
也可以在 /home/shiyanlou/install-pack 目录中找到该安装包,解压该安装包并把该安装包复制到 /app 目录中
cd /home/shiyanlou/install-pack
tar -xzf flume-1.5.2-bin.tar.gz
mv apache-flume-1.5.2-bin /app/flume-1.5.2
3.1.2 设置 /etc/profile 参数
编辑 /etc/profile 文件,声明 flume 的 home 路径和在 path 加入 bin 的路径:
export FLUME_HOME=/app/flume-1.5.2
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin

编译配置文件 /etc/profile,并确认生效
source /etc/profile
echo $PATH
3.1.3 设置 flume-env.sh 配置文件
在 $FLUME_HOME/conf 下复制改名 flume-env.sh.template 为 flume-env.sh,修改 conf/flume-env.sh 配置文件
cd /app/flume-1.5.2/conf
cp flume-env.sh.template flume-env.sh
sudo vi flume-env.sh
修改配置文件内容 :
JAVA_HOME=/app/lib/jdk1.7.0_55
JAVA_OPTS="-Xms100m -Xmx200m -Dcom.sun.management.jmxremote"

3.2 部署验证
3.2.1 验证安装
1. 修改 flume-conf 配置文件
在 $FLUME_HOME/conf 目录下修改 flume-conf.properties.template 文件,复制并改名为 flume-conf,
cd /app/flume-1.5.2/conf
cp flume-conf.properties.template flume-conf.properties
sudo vi flume-conf.properties
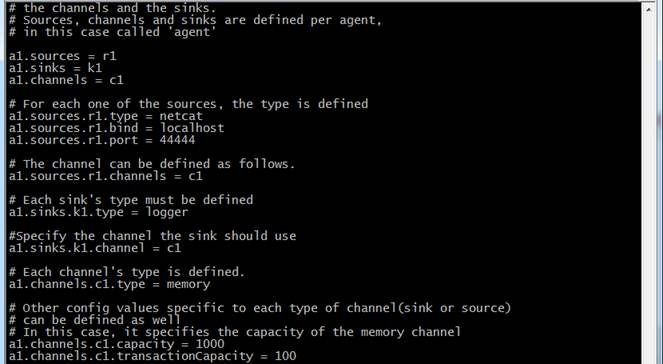
修改 flume-conf 配置文件内容
# The configuration file needs to define the sources, the channels and the sinks.
# Sources, channels and sinks are defined per agent, in this case called ''a1''
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# For each one of the sources, the type is defined
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#The channel can be defined as follows.
a1.sources.r1.channels = c1
# Each sink''s type must be defined
a1.sinks.k1.type = logger
#Specify the channel the sink should use
a1.sinks.k1.channel = c1
# Each channel''s type is defined.
a1.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
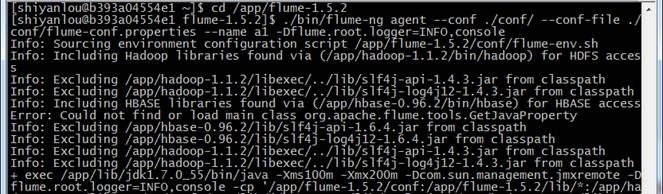
2. 在 flume 的安装目录 /flume-1.5.2 下运行
cd /app/flume-1.5.2
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
3. 再打开一个终端,输入如下命令:
telnet localhost 44444
hello world

注:在 CentOS6.5 运行 telnet 提示 "command not found",使用 sudo yum install telnet 进行安装
4. 在原来的终端上查看,可以收到来自于 telnet 发出的消息

3.2.2 测试收集日志到 HDFS
1. 在 $FLUME_HOME/conf 目录下修改 flume-conf.properties.template 文件,复制并改名为 flume-conf2.properties
cd /app/flume-1.5.2/conf
cp flume-conf.properties.template flume-conf2.properties
sudo vi flume-conf2.properties
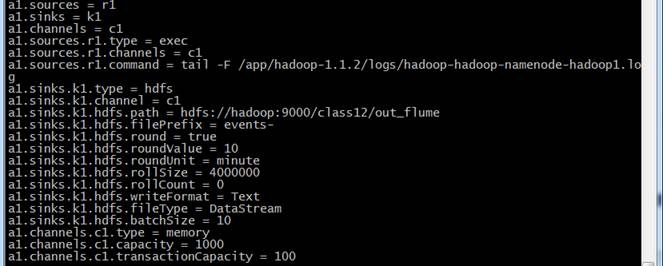
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
a1.sources.r1.command = tail -F /app/hadoop-1.1.2/logs/hadoop-shiyanlou-namenode-b393a04554e1.log
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://hadoop:9000/class12/out_flume
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollSize = 4000000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.batchSize = 10
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
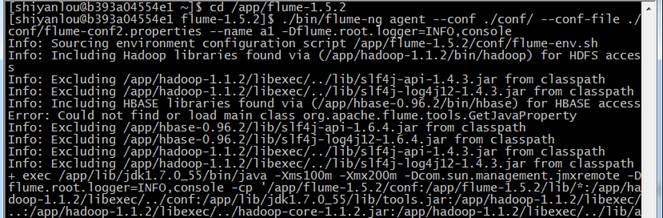
2. 在 flume 的安装目录 /flume-1.5.2 下运行
cd /app/flume-1.5.2
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/flume-conf2.properties --name a1 -Dflume.root.logger=INFO,console
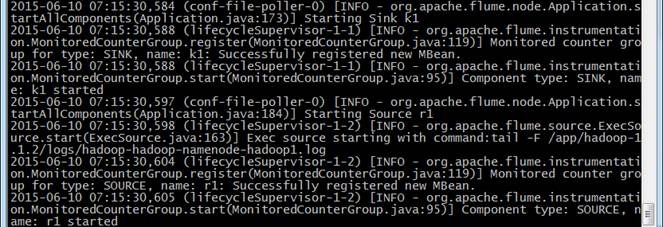
3. 不断收集 hadoop-hadoop-namenode-hadoop1.log 的数据写入 HDFS 中
4. 查看 hdfs 中 /class12/out_flume 中的文件
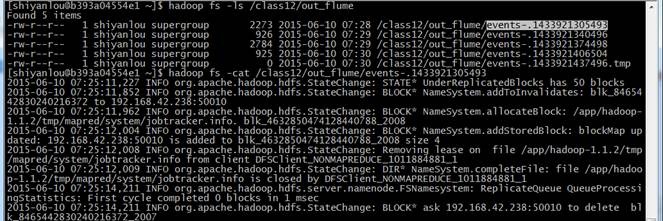
hadoop fs -ls /class12/out_flume
hadoop fs -cat /class12/out_flume/events-.1433921305493
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。
")
Hadoop 学习系列之 Hadoop、Spark 学习路线(很值得推荐)
1 Java 基础:
视频方面:推荐高淇老师《Java300 集视频教程》。
学习 hadoop 不需要过度的深入,java 学习到 javase,在多线程和并行化多多理解实践即可。
2 Linux 基础:
视频方面:(1)北京尚学堂 - Linux 入门、
(2)鸟哥 Linux 基础 + 私房菜、
看的过程中,不可只看不同步操作,这是最危险的一件事!不需全部看完。如:基本的 Linux 操作系统官网下载、安装(命令行界面和图形界面)、基本命 令、网络配置、快照、VMtools 工具安装、虚拟机的菜单熟悉等等。这是必须要首先完成的。之后,可回过来再根据需要使用到哪些,再来学习即可。当作工具书!
书籍方面:
(1)《鸟哥的 linux 私房菜》,
系统学习只要多多实践,学习 linux 并不枯燥。
3 hadoop 书籍:
(1)《Hadoop 实战 (第 1 版) 陆嘉恒》、《Hadoop 实战 (第 2 版) 陆嘉恒》
(2)《hadoop definitive guide 》,中文书名是《Hadoop 权威指南(第 1 版)曾大聃译》,《Hadoop 权威指南 (第 2 版) 周敏奇译》,《Hadoop 权威指南 (第 3 版 ) 华东师范大学数据科学与工程学院译》
(3)Hadoop 技术内幕:《深入解析 Hadoop common 和 HDFS 架构设计与实现原理》 蔡斌
4)hadoop 技术内幕:《深入解析 YARN 架构设计与实现原理》董西成
(5)Hadoop 技术内幕:《深入理解 MapReduce 架构设计与实现原理》 董西成
(5)《Hadoop in Action》中文书名是《Hadoop 实战》,
(6)《Hadoop 应用开发技术详解 刘刚》
(7)《Hadoop 核心技术》翟周伟
平常多看看 hadoop 的官网,虽然是官网,但尽量多学习计算机方面的单词,对后续学习帮助极大。
4 Maven 书籍:
强烈推荐书籍:Maven 实战 许晓斌著。目前是第一版
5、spark 书籍:
(1)《Spark 大数据处理 技术、应用与性能优化 高彦杰》
(2)《深入理解 Spark 核心思想与源码分析 耿嘉安》
摘要:致目前想要学习大数据,但是却不了解大数据,也不知道该从哪开始学起的同学,希望这篇文章能够帮到你们。
最近群里有很多朋友问我,"初学大数据,不知道怎么开始学","不知道大数据具体是什么东西,只是听说很厉害的样子","学习大数据,需要学习 哪些框架,只学习 spark 可以吗?" 等等... 类似的问题,针对这些问题,一两句话解释不清楚,所以,就在这里写一些我自己的看法吧,希望可以帮助到初学者的你。
大数据初学者,总结下来,大致有这么几种情况:
[if !supportLists]・ [endif] 跨行业转过来的 (这一种是最难的,之前可能都没接触过编程,这种属于真正的 0 基础)
[if !supportLists]・ [endif] 即将毕业的大四学员 (包含计算机专业或者其他专业,这一种稍微好点,最起码大学的时候多少会接触一点编程)
[if !supportLists]・ [endif] 有软件开发经验的老司机 (包含,javaweb,.net,c 等)
上面这几种情况的同学都有一个共性,对大数据都是 0 基础,相对而言,有软件开发经验的老司机学习起来不会很吃力,其余的刚开始学起来会比较吃力,但只要肯比别人多花点时间,多下点功夫,其实并没有你想象的那么难。有付出,才会有回报!
好了,废话不多说了,下面就直接说一下,针对所有大数据初学者的一些学习建议吧【适用于上面三种基础的同学】
今天关于什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介和学习资料中的文档材料的讲解已经结束,谢谢您的阅读,如果想了解更多关于1.1大数据平台架构及Hadoop生态圈、Hadoop - 企业级大数据管理平台 CDH (安装 Hadoop 组件)、Hadoop 入门进阶课程 12--Flume 介绍、安装与应用案例、Hadoop 学习系列之 Hadoop、Spark 学习路线(很值得推荐)的相关知识,请在本站搜索。
本文标签:




