本文将带您了解关于ThinkPython:Howtothinklikeacomputerscien...的新内容,另外,我们还将为您提供关于(30)3waystomakebetterdecisions
本文将带您了解关于ThinkPython:How to think like a computer scien...的新内容,另外,我们还将为您提供关于(30)3 ways to make better decisions — by thinking like a computer、A Self-Organized Computer Virus Demo in C、Chapter 1: A Tour of Computer Systems、computer network的实用信息。
本文目录一览:- ThinkPython:How to think like a computer scien...
- (30)3 ways to make better decisions — by thinking like a computer
- A Self-Organized Computer Virus Demo in C
- Chapter 1: A Tour of Computer Systems
- computer network

ThinkPython:How to think like a computer scien...
I recommended fresher to read this book, because this is so easy to learn and only have 200 pages, not everything in detail but almost the main theory has been explained well.
Just like a vonderful javascript book <<the good parts>>.
---------------------------------------------------------------------------
Allen Downey :
In January 1999 I was preparing to teach an introductory programming class in Java. I had taught it three times and I was getting frustrated. The failure rate in the class was too high and, even for students who succeeded, the overall level of achievement was too low.
One of the problems I saw was the books. They were too big, with too much unnecessary detail about Java, and not enough high-level guidance about how to program. And they all suffered from the trap door effect: they would start out easy, proceed gradually, and then somewhere around Chapter 5 the bottom would fall out. The students would get too much new material, too fast, and I would spend the rest of the semester picking up the pieces.
Two weeks before the first day of classes, I decided to write my own book. My goals were:
- Keep it short. It is better for students to read 10 pages than not read 50 pages.
- Be careful with vocabulary. I tried to minimize the jargon and define each term at first use.
- Build gradually. To avoid trap doors, I took the most difficult topics and split them into a series of small steps.
- Focus on programming, not the programming language. I included the minimum useful subset of Java and left out the rest.
I needed a title, so on a whim I chose How to Think Like a Computer Scientist.
3 ways to make better decisions — by thinking like a computer")
(30)3 ways to make better decisions — by thinking like a computer
https://www.ted.com/talks/tom_griffiths_3_ways_to_make_better_decisions_by_thinking_like_a_computer
00:12
If there''s one city in the world where it''s hard to find a place to buy or rent, it''s Sydney. And if you''ve tried to find a home here recently, you''re familiar with the problem. Every time you walk into an open house, you get some information about what''s out there and what''s on the market, but every time you walk out, you''re running the risk of the very best place passing you by. So how do you know when to switch from looking to being ready to make an offer?
00:27
This is such a cruel and familiar problem that it might come as a surprise that it has a simple solution. 37 percent.
(这个如此残酷和熟悉的问题却可能有个让人惊讶的简单解决方案。37%。)
00:34
(Laughter)
00:36
If you want to maximize the probability that you find the very best place, you should look at 37 percent of what''s on the market, and then make an offer on the next place you see, which is better than anything that you''ve seen so far. Or if you''re looking for a month, take 37 percent of that time -- 11 days, to set a standard -- and then you''re ready to act.
00:57
We know this because trying to find a place to live is an example of an optimal stopping problem. A class of problems that has been studied extensively by mathematicians and computer scientists.
01:09
I''m a computational cognitive scientist. I spend my time trying to understand how it is that human minds work, from our amazing successes to our dismal[ˈdɪzməl] failures. To do that, I think about the computational structure of the problems that arise in everyday life, and compare the ideal solutions to those problems to the way that we actually behave. As a side effect, I get to see how applying a little bit of computer science can make human decision-making easier.
01:37
I have a personal motivation for this. Growing up in Perth as an overly cerebral[səˈriːbrəl] 理智的 kid ...
(对此,我有一个私人动机。 作为在珀斯长大的一个过度理智的孩子…)
01:43
(Laughter)
01:48
I would always try and act in the way that I thought was rational, reasoning through every decision, trying to figure out the very best action to take. But this is an approach that doesn''t scale up when you start to run into the sorts of problems that arise in adult life. At one point, I even tried to break up with my girlfriend because trying to take into account her preferences as well as my own and then find perfect solutions --
02:09
(Laughter)
02:12
was just leaving me exhausted.
02:13
(Laughter)
02:16
She pointed out that I was taking the wrong approach to solving this problem -- and she later became my wife.
02:21
(Laughter)
02:24
(Applause)
02:28
Whether it''s as basic as trying to decide what restaurant to go to or as important as trying to decide who to spend the rest of your life with, human lives are filled with computational problems that are just too hard to solve by applying sheer effort. For those problems, it''s worth consulting the experts: computer scientists.
02:48
(Laughter)
02:49
When you''re looking for life advice, computer scientists probably aren''t the first people you think to talk to. Living life like a computer -- stereotypically deterministic[dɪˌtɜːrmɪˈnɪstɪk] 一成不变的确定性 , exhaustive[ɪgˈzɔːstɪv] 详尽的 and exact -- doesn''t sound like a lot of fun. But thinking about the computer science of human decisions reveals that in fact, we''ve got this backwards. When applied to the sorts of difficult problems that arise in human lives, the way that computers actually solve those problems looks a lot more like the way that people really act.
03:17
Take the example of trying to decide what restaurant to go to. This is a problem that has a particular computational structure. You''ve got a set of options, you''re going to choose one of those options, and you''re going to face exactly the same decision tomorrow. In that situation, you run up against what computer scientists call the "explore-exploit trade-off 探索与利用的权衡." You have to make a decision about whether you''re going to try something new -- exploring, gathering some information that you might be able to use in the future -- or whether you''re going to go to a place that you already know is pretty good -- exploiting the information that you''ve already gathered so far. The explore/exploit trade-off shows up any time you have to choose between trying something new and going with something that you already know is pretty good, whether it''s listening to music or trying to decide who you''re going to spend time with. It''s also the problem that technology companies face when they''re trying to do something like decide what ad to show on a web page. Should they show a new ad and learn something about it, or should they show you an ad that they already know there''s a good chance you''re going to click on?
04:18
Over the last 60 years, computer scientists have made a lot of progress understanding the explore/exploit trade-off, and their results offer some surprising insights. When you''re trying to decide what restaurant to go to, the first question you should ask yourself is how much longer you''re going to be in town. If you''re just going to be there for a short time, then you should exploit. There''s no point gathering information. Just go to a place you already know is good. But if you''re going to be there for a longer time, explore. Try something new, because the information you get is something that can improve your choices in the future. The value of information increases the more opportunities you''re going to have to use it.
04:56
This principle can give us insight into the structure of a human life as well. Babies don''t have a reputation for being particularly rational. They''re always trying new things, and you know, trying to stick them in their mouths. But in fact, this is exactly what they should be doing. They''re in the explore phase of their lives, and some of those things could turn out to be delicious. At the other end of the spectrum[ˈspektrəm], the old guy who always goes to the same restaurant and always eats the same thing isn''t boring -- he''s optimal.
05:28
(Laughter)
05:32
He''s exploiting the knowledge that he''s earned through a lifetime''s experience. More generally, knowing about the explore/exploit trade-off can make it a little easier for you to sort of relax and go easier on yourself when you''re trying to make a decision. You don''t have to go to the best restaurant every night. Take a chance, try something new, explore. You might learn something. And the information that you gain is going to be worth more than one pretty good dinner.
06:00
Computer science can also help to make it easier on us in other places at home and in the office. If you''ve ever had to tidy up your wardrobe, you''ve run into a particularly agonizing[ˈægənaɪzɪŋ] 使人十分痛苦的 decision: you have to decide what things you''re going to keep and what things you''re going to give away. Martha Stewart turns out to have thought very hard about this --
06:18
(Laughter)
06:20
and she has some good advice. She says, "Ask yourself four questions: How long have I had it? Does it still function? Is it a duplicate of something that I already own? And when was the last time I wore it or used it?" But there''s another group of experts who perhaps thought even harder about this problem, and they would say one of these questions is more important than the others. Those experts? The people who design the memory systems of computers. Most computers have two kinds of memory systems: a fast memory system, like a set of memory chips that has limited capacity, because those chips are expensive, and a slow memory system, which is much larger. In order for the computer to operate as efficiently as possible, you want to make sure that the pieces of information you want to access are in the fast memory system, so that you can get to them quickly. Each time you access a piece of information, it''s loaded into the fast memory and the computer has to decide which item it has to remove from that memory, because it has limited capacity.
07:21
Over the years, computer scientists have tried a few different strategies for deciding what to remove from the fast memory. They''ve tried things like choosing something at random or applying what''s called the "first-in, first-out principle," which means removing the item which has been in the memory for the longest. But the strategy that''s most effective focuses on the items which have been least recently used. This says if you''re going to decide to remove something from memory, you should take out the thing which was last accessed the furthest in the past. And there''s a certain kind of logic to this. If it''s been a long time since you last accessed that piece of information, it''s probably going to be a long time before you''re going to need to access it again. Your wardrobe is just like the computer''s memory. You have limited capacity, and you need to try and get in there the things that you''re most likely to need so that you can get to them as quickly as possible. Recognizing that, maybe it''s worth applying the least recently used principle to organizing your wardrobe as well. So if we go back to Martha''s four questions, the computer scientists would say that of these, the last one is the most important.
08:31
This idea of organizing things so that the things you are most likely to need are most accessible can also be applied in your office. The Japanese economist Yukio Noguchi actually invented a filing system that has exactly this property. He started with a cardboard[ˈkaːrdbɔːrd] 卡纸板 box, and he put his documents into the box from the left-hand side. Each time he''d add a document, he''d move what was in there along and he''d add that document to the left-hand side of the box. And each time he accessed a document, he''d take it out, consult it and put it back in on the left-hand side. As a result, the documents would be ordered from left to right by how recently they had been used. And he found he could quickly find what he was looking for by starting at the left-hand side of the box and working his way to the right.
09:13
Before you dash[dæʃ] 急奔 home and implement this filing system --
09:15
(Laughter)
09:17
it''s worth recognizing that you probably already have.
09:20
(Laughter)
09:24
That pile of papers on your desk ... typically maligned[məˈlaɪnd] as messy and disorganized, a pile of papers is, in fact, perfectly organized --
(就是你桌上的那堆文件… 通常被认为是凌乱无序的 这堆文件,实际上已经经过了完美的整理 --)
09:32
(Laughter)
09:33
as long as you, when you take a paper out, put it back on the top of the pile, then those papers are going to be ordered from top to bottom by how recently they were used, and you can probably quickly find what you''re looking for by starting at the top of the pile.
09:47
Organizing your wardrobe or your desk are probably not the most pressing problems in your life. Sometimes the problems we have to solve are simply very, very hard. But even in those cases, computer science can offer some strategies and perhaps some solace[ˈsaːləs] 安慰. The best algorithms are about doing what makes the most sense in the least amount of time. When computers face hard problems, they deal with them by making them into simpler problems -- by making use of randomness, by removing constraints or by allowing approximations. Solving those simpler problems can give you insight into the harder problems, and sometimes produces pretty good solutions in their own right.
10:29
Knowing all of this has helped me to relax when I have to make decisions. You could take the 37 percent rule for finding a home as an example. There''s no way that you can consider all of the options, so you have to take a chance. And even if you follow the optimal strategy, you''re not guaranteed a perfect outcome. If you follow the 37 percent rule, the probability that you find the very best place is -- funnily enough ...
10:54
(Laughter)
10:55
37 percent. You fail most of the time. But that''s the best that you can do.
(37%。 你大部分时间都未能如愿。 但是你已经尽力了。)
11:02
Ultimately, computer science can help to make us more forgiving[fərˈgɪvɪŋ] 宽容的 of our own limitations. You can''t control outcomes, just processes. And as long as you''ve used the best process, you''ve done the best that you can. Sometimes those best processes involve taking a chance -- not considering all of your options, or being willing to settle for a pretty good solution. These aren''t the concessions[kənˈsɛʃənz] 让步 that we make when we can''t be rational -- they''re what being rational means.
11:28
Thank you.
11:30
(Applause)

A Self-Organized Computer Virus Demo in C
A Program that can modify herself and copy herself to somewhere else and execute it. Just like gene-transformable virus.
Here''s the sample code.
#include "stdio.h"
#include "windows.h"
#define MAX_LOOP 10000
int main(int argc, const char** argv)
{
/*** THE VIRUS LOGIC PART ***/
//GENE_MARK
int a = 0;
printf("GENE PRINT:%d\n", a);
/*** THE VIRUS LOGIC PART ***/
// FILE NAME
char file_name[30] = "test";
// MAKE A COPY OF HERSELF
FILE* source = fopen("test.c", "r");
FILE* descendant = fopen("descendant.c", "w+");
printf("SOURCE FILE OPEN RESULT IS : %d \n", (int)source);
printf("DESCENDANT FILE CREATED: %d \n", (int)descendant);
if(descendant==NULL)
{
printf("ERROR ON CREATING DESCENDANT.\n");
return -1;
}
char buff[100] = {0};
// REPLACE GENE MARK PROGRAM
char letter = 0;
// GENE LINE
int idx = 0;
int loop = 0;
int buff_idx = 0;
while(!feof(source))
{
// ALARM
if(loop>MAX_LOOP)
break;
loop ++;
fread(&letter, sizeof(char), 1, source);
buff[buff_idx] = letter;
buff_idx ++;
if(letter==''\n'')
{
if(idx==9)
{
// TRANSFORM GENE
memset(buff, 0, 100);
buff_idx = 0;
strcat(buff, "int a = 1;\n");
}
fwrite(buff, sizeof(char), strlen(buff), descendant);
// CLEAR BUFFER
memset(buff, 0, 100);
buff_idx = 0;
idx ++;
}
}
// DEAL WITH LEFT LETTERS IN BUFFER
if(strlen(buff)>0)
{
strcat(buff, "\n");
fwrite(buff, sizeof(char), strlen(buff)+1, descendant);
}
// CLOSE ALL FILES
fclose(source);
fclose(descendant);
// until the descendant file is written over
/*** COMPILE HERSELF ***/
char* source_file = "descendant.c";
char* dest_file = "descendant.exe";
char command[100] = {0};
strcat(command, "gcc -o ");
strcat(command, dest_file);
strcat(command, " ");
strcat(command, source_file);
// COMPILATION
system(command);
/***********************/
printf("COPYING MYSELF DONE.\n");
printf("WAITING FOR NEXT INSTRUCTION...\n");
char cmd = getchar();
if(cmd==''Y'')
{
printf("BEGIN EXECUTE THE COPYFILE EXECUTION...\n");
//GENE_MARK
system("descendant.exe");
printf("EXECUTION PROCESS IS ACTIVATED, TASK DONE. EXIT SYSTEM.");
}
else
printf("YOU CHOOSE TO EXIT SYSTEM. BYE!");
return 0;
}If you have any suggestions or ideas, please feel free comment below, thanks!

Chapter 1: A Tour of Computer Systems
A computer system consists of hardware and systems software that work together to run application programs.
We begin our study of systems by tracing the lifetime of the hello program, from the time it is created by a programmer, until it runs on a system, prints its simple message, and terminates.
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
}
1.1 Information Is Bits + Context
The hello.c program is stored in a file as a sequence of bytes, we shows the ASCII representation of the hello.c program:

Files such as hello.c that consist exclusively of ASCII characters are known as text files.All other files are known as binary files.
The representation of hello.c illustrates a fundamental idea: All information in a system--including disk files, programs stored in memory, user data stored in memory, and data transferred across a network--is represented as a bunch of bits.The only thing that distinguishes different data objects is the context in which we view them.
1.2 Programs Are Translated by Other Programs into Different Forms
in order to run hello.c on the system, the individual C statements must be translated by other programs into a sequence of low-level machine-language instructions.These instructions are then packaged in a form called an executable object program and stored as a binary disk file.Object programs are also referred to as executable object files.
we run hello.c in unix system:
lgtdeMacBook-Pro:~ lgt$ gcc -o hello hello.c
lgtdeMacBook-Pro:~ lgt$ ls hello*
hello hello.c
lgtdeMacBook-Pro:~ lgt$ ./hello
hello, world
Preprocessing phase:The preprocessor(cpp) modifies the original C program according to directives that begin with the # character.For example, the #include<stdio.h> command in line 1 of hello.c tells the preprocessor to read the contents of the system header file stdio.h and insert it directly into the program text. The result is another C program, typically with the .i suffix.
Compilation phase:The compiler(cc1) translates the text file hello.i into the text file hello.s, which contains an assembly-language program.Each statement in an assembly-language program exactly describes one low-level machine-language instruction in a standard text form.Assembly language is useful because it provides a common output language for different compilers for different high-level languages.
Assembly phase: The assembler(as) translates hello.s into machine-language instructions, packages then in a form known as a relocatable object program, and stores the result in the object file hello.o.The hello.o file is a binary file whose bytes encode machine language instructions rather than characters.
Linking phase:The printf function resides in a separate precompiled object file called print.o, which must somehow be merged with our hello.o program. The linker(ld) handles this merging.The result is the hello file, which is an executable object file(or simply executable) that is ready to be loaded into memory and executed by the system.
1.3 It Pays to Understand How Compilation Systems Work
how compilation system work: Optimizing program performance, Understanding link-time errors and Avoiding security holes.
1.4 Processors Read and Interpret Instructions Stored in Memory
1.4.1 Hardware Organization of a System
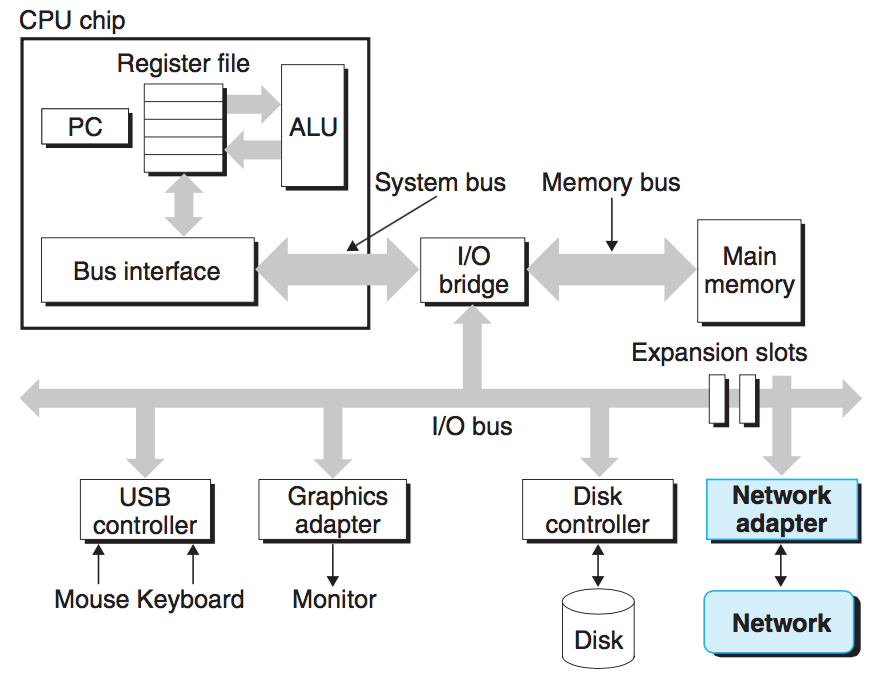
To understand what happens to our hello program when we run it, we need to understand the hardware organization of a typical system:
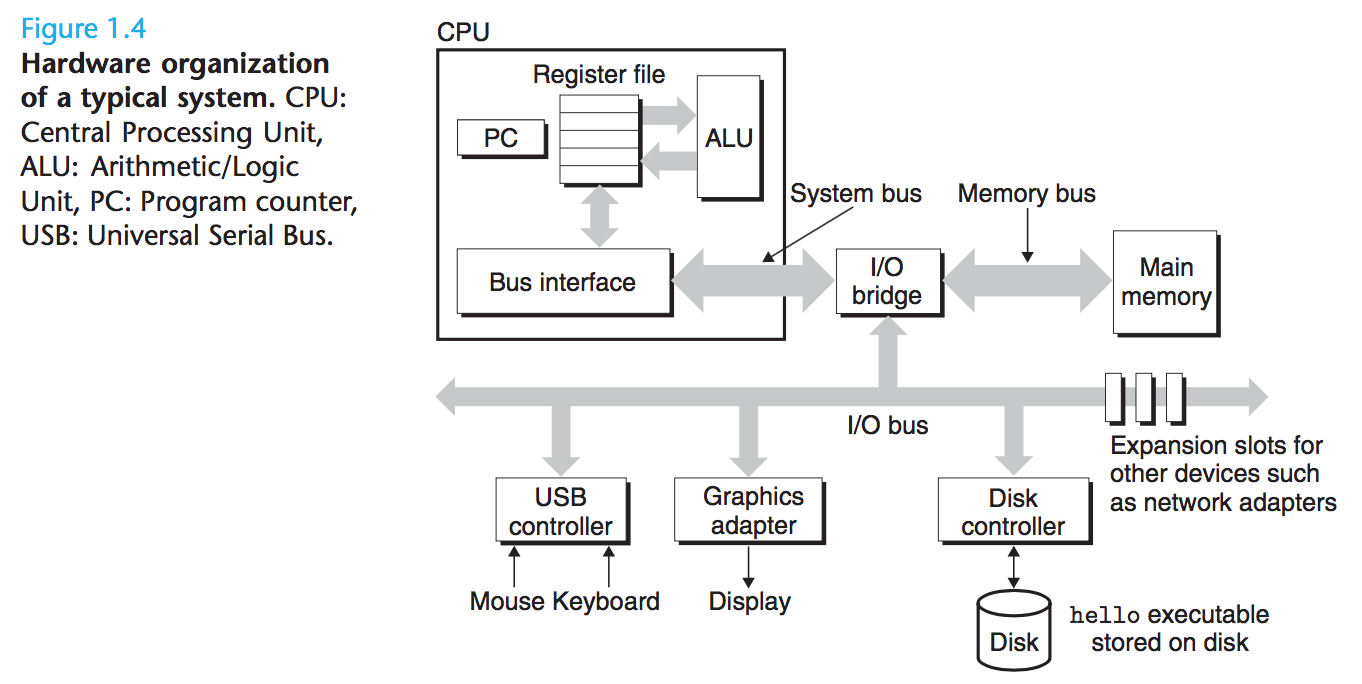
Buses
Running throughout the system is a collection of electrical conduits called buses that carry bytes of information back and forth between the components. Buses are typically designed to transfer fixed-sized chunks of bytes known as words.The number of bytes in a word(the word size) is a fundamental system parameter that varies across systems.
I/O Devices
Input/output(I/O) devices are the system''s connection to the external world.
Each I/O device is connected to the I/O bus by either a controller or an adapter. Controllers are chip sets in the device itself or on the system''s main printed circuit board(often called the mother board). An adapter is a card that plugs into a slot on the motherboard. Regardless, the purpose of each is to transfer information back and forth between the I/O bus and an I/O device.
Main Memory
The main memory is a temporary storage device that holds both a program and the data it manipulates while the processor is executing the program. Physically, main memory consists of a collection of dynamic random access memory(DRAM) chips. Logically, memory is organized as a linear array of bytes, each with its own unique address(array index) starting at zero. In general, each of the machine instructions that constitute a program can consist of a variable number of bytes. The sizes of data items that correspond to C program variables vary according to type.
Processor
The central processing unit(CPU) or simply processor, is the engine that interprets(or executes) instructions stored in main memory.At its core is a word-sized storage device(or register) called the program counter(PC). At any point in time, the PC points at (contains the address of) some machine-language instruction in main memory.
From the time that power is applied to the system, until the time that the power is shut off, a processor repeatedly executes the instruction pointed at by the program counter and updates the program counter to point to the next instruction. A processor appears to operate according to a very simple instruction execution model, defined by its instruction set architecture. In this model, instructions execute in strict sequence, and executing a single instruction involves performing a series of steps. The processor reads the instruction from memory pointed at by the program counter(PC), interprets the bits in the instruction, performs some simple operation dictated by the instruction, and then updates the PC to point to the next instruction, which may or may not be contiguous in memory to the instruction that was just executed.
There are only a few of these simple operations, and they revolve around main memory, the register file, and the arithmetic/logic unit(ALU). The register file is a small storage device that consists of a collection of word-sized registers, each with its own unique name. The ALU computes new data and address values. Here has some example:
Load: Copy a byte or a word from main memory into a register, overwriting the previous contents of the register.
Store: Copy a byte or a word from a register to a location in main memory, overwriting the previous contents of that location.
Operate: Copy the contents of two registers to the ALU, perform an arithmetic operation on the two words, and store the result in a register, overwriting the previous contents of that register.
Jump: Extract a word from the instruction itself and copy that word into the program counter(PC), overwriting the previous value of the PC.
1.4.2 Running the hello Program
When we type the characters "./hello" at the keyboard, the shell program reads each one into a register, and then stores it in memory:
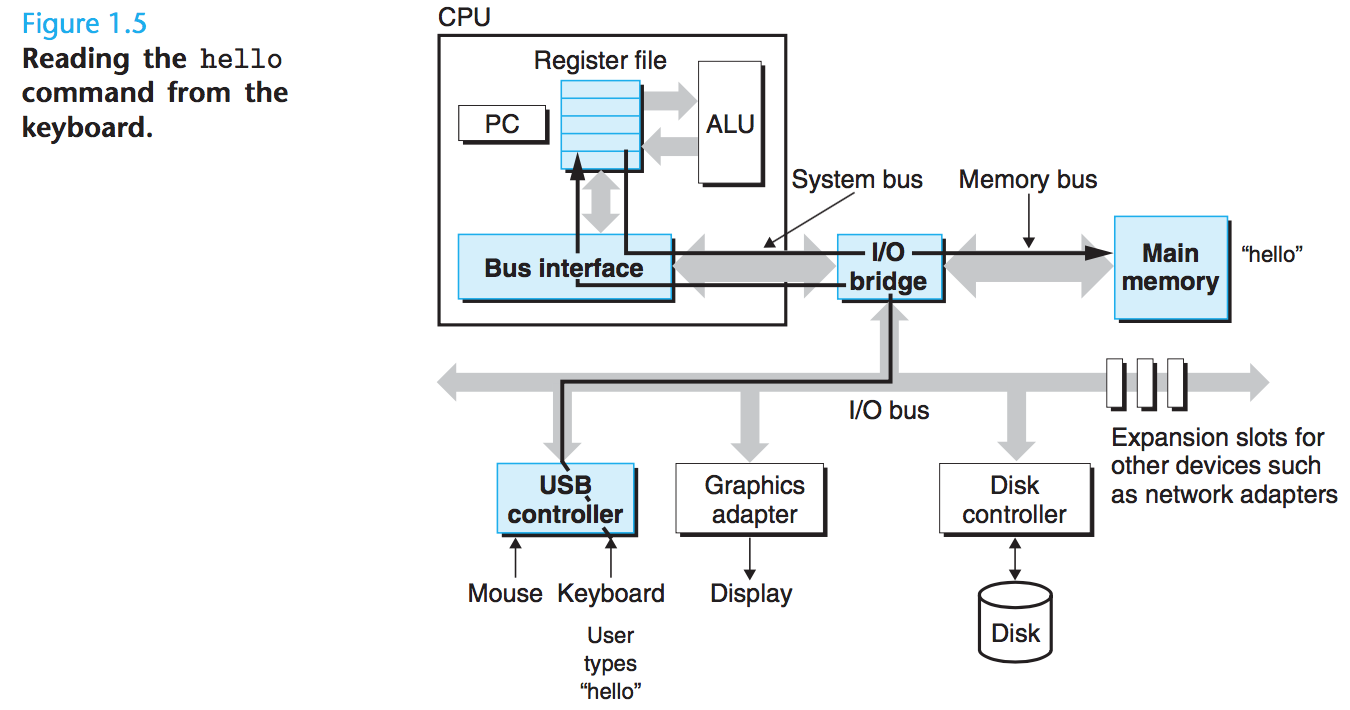
When we hit the enter, the shell then loads the executable hello file by executing a sequence of instructions that copies the code and data in the hello object file from disk to main memory. The data include the string of characters "hello, world\n" that will eventually be printed out:

Once the code and data in the hello object file are loaded into memory, the processor begins executing the machine-language instructions in the hello program''s main routine.

1.5 Caches Matter
We know that processor is faster than main memory, and main memory is faster than disk when moving information from one place to another.
To deal with the processor-memory gap, system designers include smaller faster storage devices called cache memories(or simply caches) that serve as temporary staging areas for information that the processor is likely to need in the near future.

An L1 cache on the processor chip holds tens of thousands of bytes and can be accessed nearly as fast as the register file. A larger L2 cache with hundreds of thousands to millions of bytes is connected to the processor by a special bus. It might take 5 times longer for the process to access the L2 cache than the L1 cache, but this is still faster than accessing the main memory. The L1 and L2 caches are implemented with a hardware technology known as static random access memory(SRAM).
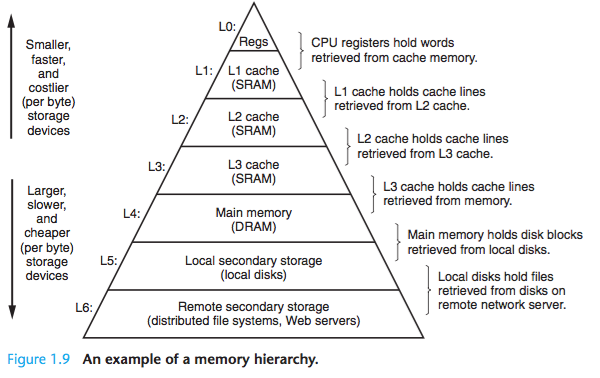
1.6 Storage Devices Form a Hierarchy
memory hierarchy:
1.7 The Operating System Manages the Hardware
Back to our hello example. When the shell loaded and ran the hello program, and when the hello program printed its message, neither program accessed the keyboard, display, disk, or main memory directly. Rather, they relied on the services provided by the operating system. We can think of the operating system as a layer of software interposed between the application program and the hardware. All attempts by an application program to manipulate the hardware must go through the operating system.

The operating system has two primary purposes:(1) to protect the hardware from misuse by runaway applications, and (2) to provide applications with simple and uniform mechanisms for manipulating complicated and often wildly different low-level hardware devices.

files are abstractions for I/O devices, virtual memory is an abstraction for both the main memory and disk I/O devices, and processes are abstractions for the processor, main memory, and I/O devices.
1.7.1 Processes
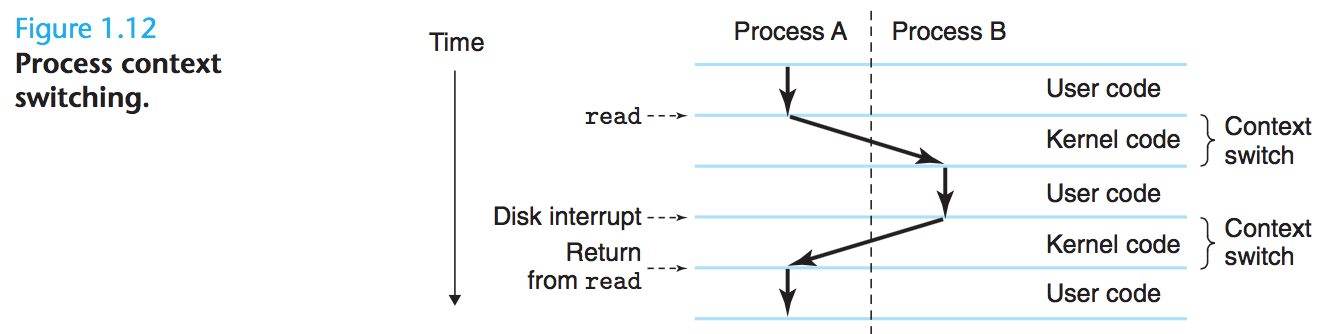
A process is the operating system''s abstraction for a running program.
The operating system keeps track of all the state information that the process needs in order to run. This state, which is known as the context, includes information such as the current values of the PC, the register file, and the contents of main memory. At any point in time, a uniprocessor system can only execute the code for a single process. When the operating system decides to transfer control from the current process to some new process, it performs a context switch by saving the context of the current process, restoring the context of the new process, and then passing control to the new process.
1.7.2 Threads
threads running in the context of the process and sharing the same code and global data.
1.7.3 Virtual Memory
Virtual memory is an abstraction that provides each process with the illusion that it has exclusive use of the main memory. Each process has the same uniform view of memory, which is known as its virtual address space.
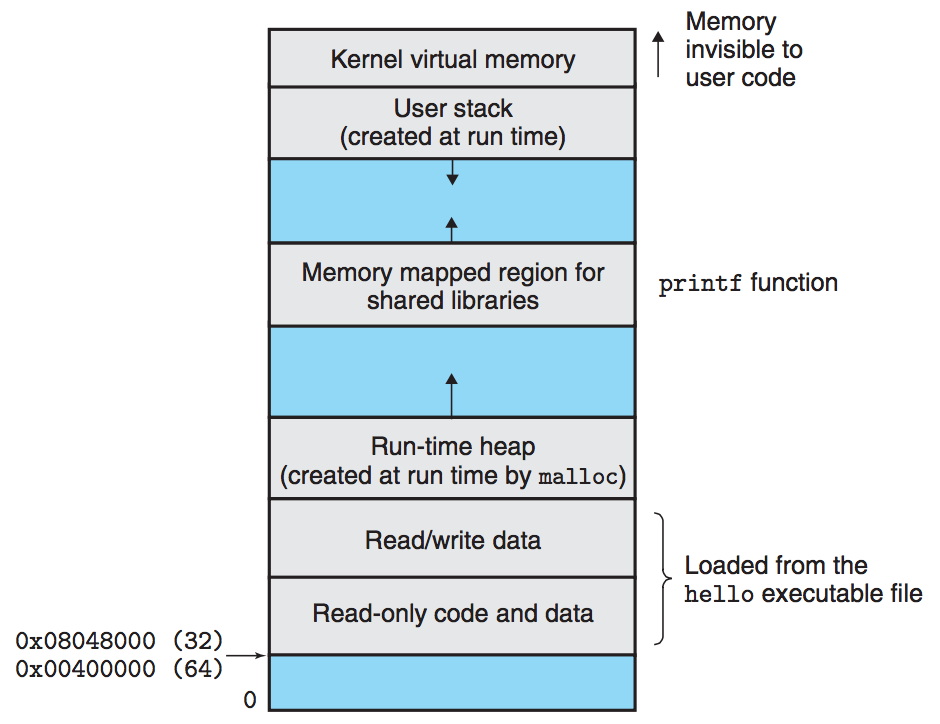
1.7.4 Files
A file is a sequence of bytes.
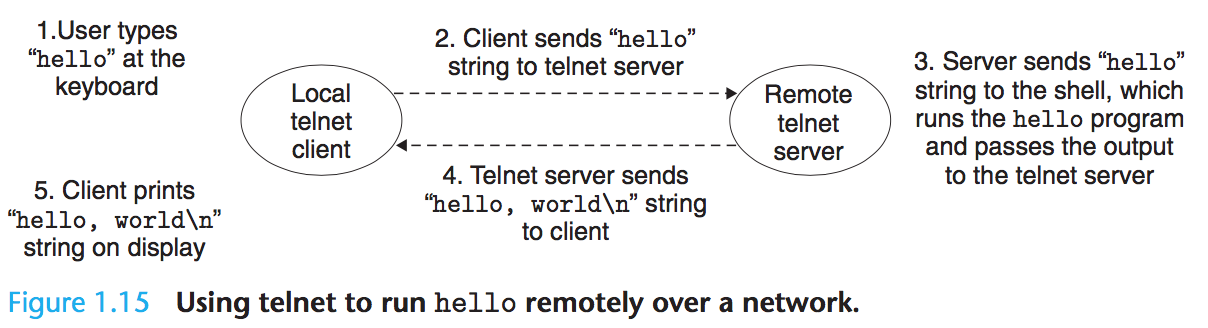
1.8 Systems Communicate with Other Systems Using Networks
The network can be viewed as just another I/O device. With the advent of global networks such as the Internet, copying information from one machine to another has become one of the most important uses of computer systems:
Returning to our hello example, we could use the familiar telnet application to run hello on a remote machine:
1.9 Important Themes
1.9.1 Concurrency and Parallelism
we want computer to do more, and we want them to run faster. Both of these factors improve when the processor does more things at once. We use the term concurrency to refer to the general concept of a system with multiple, simultaneous activities, and the term parallelism to refer to the use of concurrency to make a system run faster.Parallelism can be exploited at multiple levels of abstraction in a computer system.
Thread-Level Concurrency
We use multi-core processors and hyper threading to make a system to consist of multiple processors.
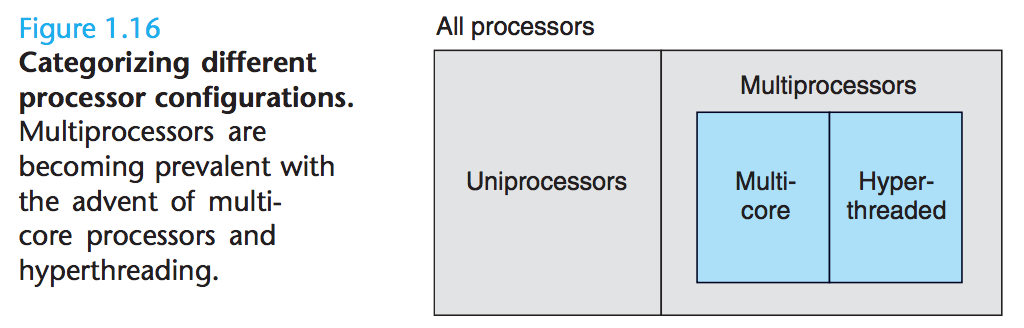
Multi-core processors have several CPUs integrated onto a single integrated-circuit chip:
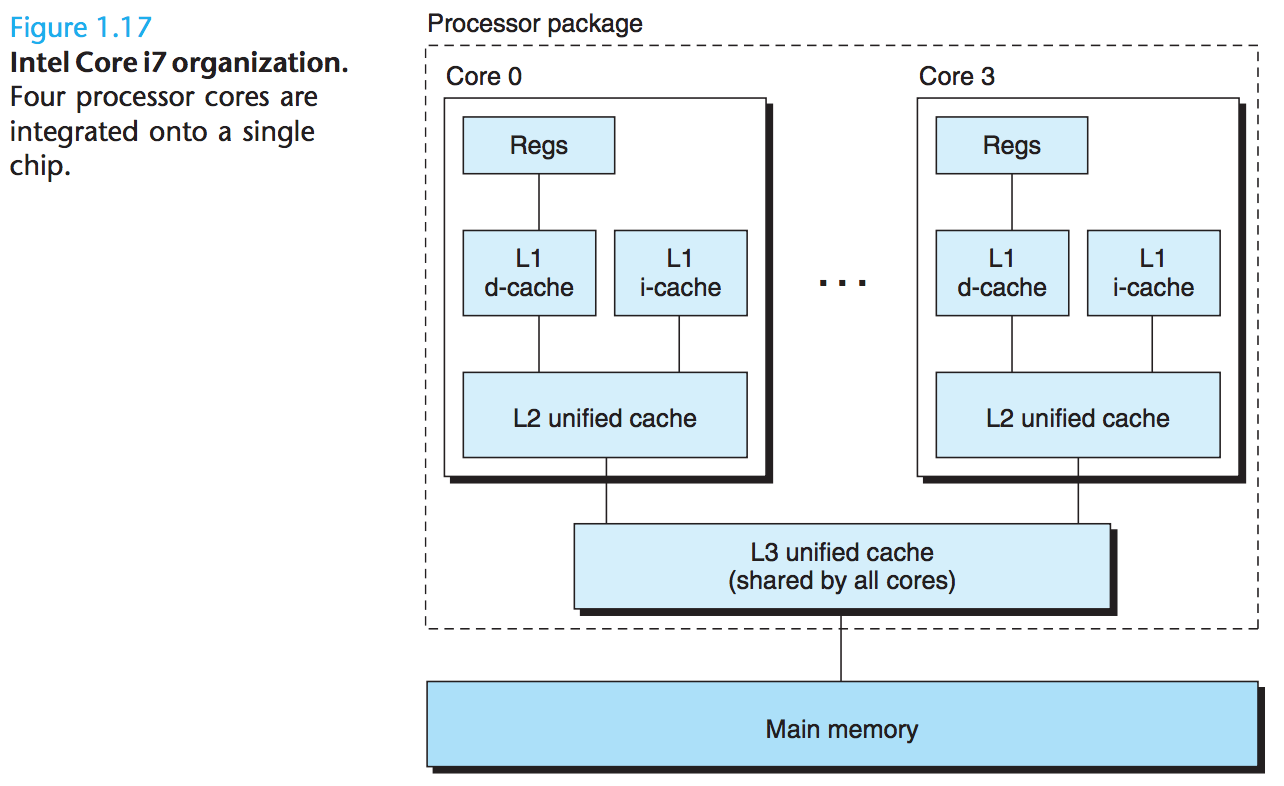
Hyperthreading, sometimes called simultaneous multi-threading, is a technique that allows a single CPU to execute multiple flows of control.It involves having multiple copies of some of the CPU hardware, such as program counters and register files, while having only single copies of other parts of the hardware, such as the units that perform floating-point arithmetic.

computer network
Internet,计算机网和分组交换
什么是协议(protocol)?为计算机网络中进行数据交换而建立的规则、标准或约定的集合。
面向终端的网络:
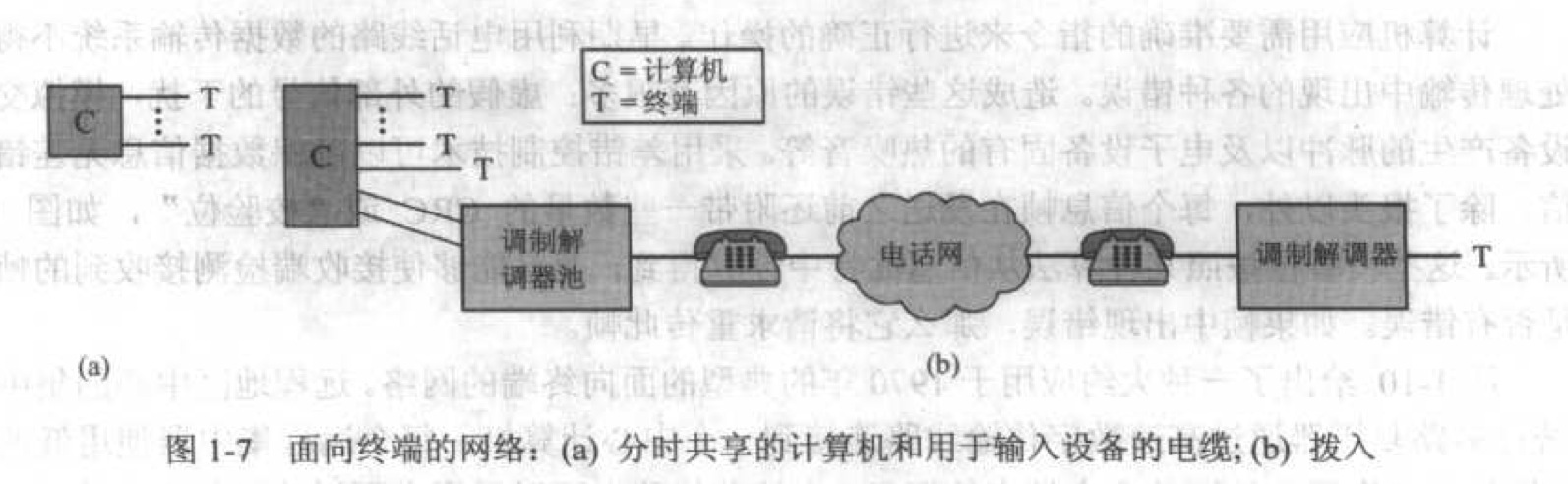
多个终端共享一台主机,每个终端通过电缆可以对主机进行远距离访问。通过引入用于传输数字信息的调制解调器(modem) 设备,终端可以通过电话网访问主机。
以下是几种不同的终端与主机间的通讯方式。
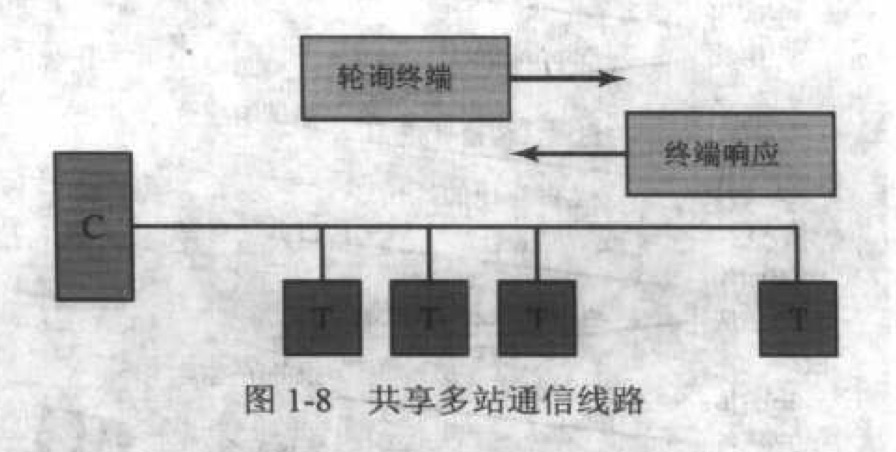
单线多点通信线路:中心计算机在输出线路上向某个特定的终端发送一个轮询消息,所有的终端都在监听此输出线路,但是只有 被轮询的终端进行响应。
统计多路复用器 / 集中器:来自多个终端的消息被多路复用器缓存,并排序在一个队列里,然后每次通过通信线路发送一个消息 到中心计算机。中心计算机分类出来各个终端的消息,进行必要的处理并在帧中返回结果。统计多路复用器利用帧中的地址来确 定目标终端。
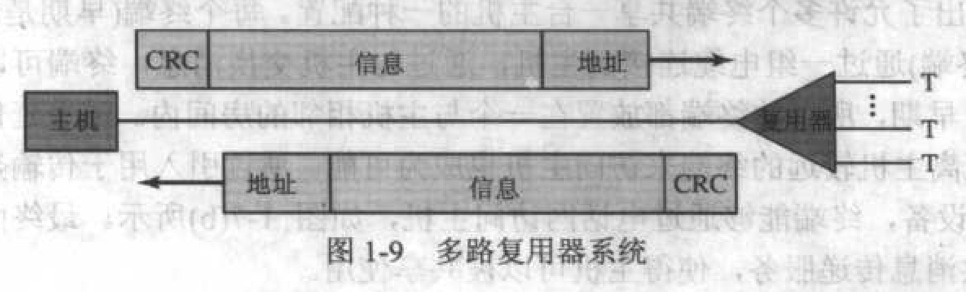
(CRC 是校验位,是按照某种算法从信息比特流中计算得到,并且能够使接收端检测接收到的帧中是否有错误,如果帧中出现 错误,那么它将请求重传此帧。)

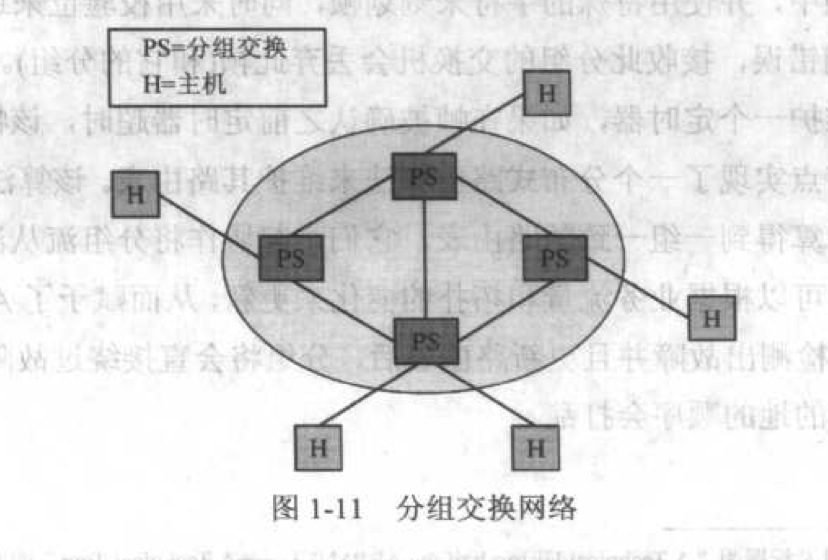
计算机到计算机的网络:
packet switching 解决了不同大小的消息进入网络带来的过长等待时间的问题。不能作为一个单独分组的消息将被分段, 然后使用多个分组进行传输。到达目标后再进行组装。
今天关于ThinkPython:How to think like a computer scien...的介绍到此结束,谢谢您的阅读,有关(30)3 ways to make better decisions — by thinking like a computer、A Self-Organized Computer Virus Demo in C、Chapter 1: A Tour of Computer Systems、computer network等更多相关知识的信息可以在本站进行查询。
本文标签:




