在本文中,您将会了解到关于计算python字典中每个键的出现次数的新资讯,同时我们还将为您解释计算python字典中每个键的出现次数的方法的相关在本文中,我们将带你探索计算python字典中每个键的出
在本文中,您将会了解到关于计算python字典中每个键的出现次数的新资讯,同时我们还将为您解释计算python字典中每个键的出现次数的方法的相关在本文中,我们将带你探索计算python字典中每个键的出现次数的奥秘,分析计算python字典中每个键的出现次数的方法的特点,并给出一些关于c – 计算大数据流中每个元素的出现次数、c – 计算整数区间(或int数组)中每个数字的出现次数、C#计算每个字符的出现次数、JAVA 练习:计算一个字符串中每个字符的出现次数的实用技巧。
本文目录一览:- 计算python字典中每个键的出现次数(计算python字典中每个键的出现次数的方法)
- c – 计算大数据流中每个元素的出现次数
- c – 计算整数区间(或int数组)中每个数字的出现次数
- C#计算每个字符的出现次数
- JAVA 练习:计算一个字符串中每个字符的出现次数
")
计算python字典中每个键的出现次数(计算python字典中每个键的出现次数的方法)
我有一个看起来像这样的python字典对象:
[{"house": 4, "sign": "Aquarius"}, {"house": 2, "sign": "Sagittarius"}, {"house": 8, "sign": "Gemini"}, {"house": 3, "sign": "Capricorn"}, {"house": 2, "sign": "Sagittarius"}, {"house": 3, "sign": "Capricorn"}, {"house": 10, "sign": "Leo"}, {"house": 4, "sign": "Aquarius"}, {"house": 10, "sign": "Leo"}, {"house": 1, "sign": "Scorpio"}]现在,对于每个“符号”键,我想计算每个值出现多少次。
def predominant_sign(data): signs = [k[''sign''] for k in data if k.get(''sign'')] print len(signs)但是,这会打印出“ sign”出现在字典中的次数,而不是获取的值sign并计算特定值出现的次数。
例如,我想看到的输出是:
Aquarius: 2Sagittarius: 2Gemini: 1...等等。我应该改变什么以获得期望的输出?
答案1
小编典典用途collections.Counter及其most_common方法:
from collections import Counterdef predominant_sign(data): signs = Counter(k[''sign''] for k in data if k.get(''sign'')) for sign, count in signs.most_common(): print(sign, count)
c – 计算大数据流中每个元素的出现次数
我需要计算每个状态字符串出现的次数,以形成直方图.我尝试过使用Google的Sparse Hash Map,但是内存开销很疯狂.
我已经运行了一些减少的测试(附加)超过100,000个时间步,500粒子.这导致50mil可能的状态字符串中仅有超过18.2mil的唯一状态字符串,这与需要完成的实际工作一致.
它最终在空间中使用323 MB作为每个唯一条目的char *和int以及实际的状态字符串本身.但是,任务管理器报告使用了870M.这是547M的开销,或大约251.87比特/条目,超过谷歌宣传的大约4-5比特.
所以我认为我必须做错事.但后来我发现了site,它显示了类似的结果,但是,我不确定他的图表是仅显示哈希表大小,还是包括实际数据的大小.此外,他的代码不会释放任何已插入到已存在的散列图中的字符串(意味着如果他的图表确实包含实际数据的大小,它将会结束).
以下是一些显示输出问题的代码:
#include <google/sparse_hash_map>
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <stdlib.h>
//String equality
struct eqstrc
{
bool operator()(const char* s1,const char* s2) const
{
return (s1 == s2) || (s1 && s2 && !strcmp(s1,s2));
}
};
//Hashing function
template <class T>
class fnv1Hash
{
public:
size_t operator()(const T& c) const {
unsigned int hash = 2166136261;
const unsigned char *key = (const unsigned char*)(c);
size_t L = strlen((const char*)c);
size_t i = 0;
for(const unsigned char *s = key; i < L; ++s,++i)
hash = (16777619 * hash) ^ (*s);
return (size_t)hash;
}
};
//Function to form new string
char * new_string_from_integer(int num)
{
int ndigits = num == 0 ? 1 : (int)log10((float)num) + 1;
char * str = (char *)malloc(ndigits + 1);
sprintf(str,"%d",num);
return str;
}
typedef google::sparse_hash_map<const char*,int,fnv1Hash<const char*>,eqstrc> HashCharMap;
int main()
{
HashCharMap hashMapChar;
int N = 500;
int T = 100000;
//Fill hash table with strings
for(int k = 0; k < T; ++k)
{
for(int i = 0; i < N; ++i)
{
char * newString = new_string_from_integer(i*k);
std::pair<HashCharMap::iterator,bool> res = hashMapChar.insert(HashCharMap::value_type(newString,HashCharMap::data_type()));
(res.first)->second++;
if(res.second == false) //If the string already in hash map,don't need this memory
free(newString);
}
}
//Count memory used by key
size_t dataCount = 0;
for(HashCharMap::iterator hashCharItr = hashMapChar.begin(); hashCharItr != hashMapChar.end(); ++hashCharItr)
{
dataCount += sizeof(char*) + sizeof(unsigned int); //Size of data to store entries
dataCount += (((strlen(hashCharItr->first) + 1) + 3) & ~0x03); //Size of entries,padded to 4 byte boundaries
}
printf("Hash Map Size: %lu\n",(unsigned long)hashMapChar.size());
printf("Bytes written: %lu\n",(unsigned long)dataCount);
system("pause");
}
产量
Hash Map Size: 18218975 Bytes written: 339018772 Peak Working Set (Reported by TaskManager): 891,228 K Overhead: 560,155 K,or 251.87 bits/entry
我已经尝试了Google Sparse Hash Map v1.10和v2.0.2.
我在使用哈希映射时做错了什么.或者有更好的方法来解决这个问题,因为使用这些字符串,我几乎可以只存储字符串列表,排序,然后计算连续的条目.
谢谢你的帮助
编辑
因为我被问到,这里是实际数据的格式:
每个组件是2个字节,分为两个子部分. 12位,4位.
>前两个字节(短):[当前粒子的id(12位)|的角度
当前粒子(4位)]
>第二短:[相互作用的数量
粒子(12位)(N)|以前的当前粒子角度(4位)]
>对于下一个N短裤:[粒子i的id(12位)|粒子的前一个角度i(4位)]
角度近似(除以16),以4位存储.
这有点罗嗦,所以我会写一个例子:
0x120A 0x001B 0x136F =粒子288(0x120),角度为10(0xA).在前一个时间步长有11(0xB)角.与1(0x001)其他粒子交互.这个其他粒子是粒子310(0x136)并且在之前的时间步长中具有角度15(0xF).
粒子与0到9个其他粒子相互作用,因此我上面提到的4-22个字节(尽管很少,可以与多达12个或更多的其他粒子相互作用.没有限制.如果所有500个粒子都在半径范围内,那么该字符串将是1004字节长)
附加信息:哈希函数和比较函数在我的实际代码中使用存储在第二个short的最重要的12位中的大小来进行处理,因为非终端0x0000可以出现在我的状态字符串中.一切正常.
解决方法
这意味着您对18218975字符串(“0”..“50000000”)的实验需要在堆上使用291503600个字节,其长度(加上尾随0)的总和为156681483.
因此,由于malloc,您的开销为135MB.
(峰值工作集大小是否可靠?)
中每个数字的出现次数")
c – 计算整数区间(或int数组)中每个数字的出现次数
例如:
> INPUT n,m = [19,23] = 19,20,21,22,23
>输出应该是:
0次出现:1次
1次出现:2次
2次出现:5次
3次出现:1次等
#include <iostream>
using namespace std;
int main()
{
int i,j,z,count,n,m;
cin >>n >>m;
for(int i=0; i<10; i++) // LOOP FOR DIGITS
{
cout << i <<"occurences: ";
count=0;
for(int j=n; j<m; j++) // LOOP INTEGER INTERVAL
{
while (z!=0)
{
z = j % 10; // LAST DIGIT OF FirsT NUMBER IN INTERVAL
if (z == i) count++;
z /= 10;
}
}
cout << count <<" times"<< endl;
}
}
我的代码每个数字返回0次,错误在哪里?
解决方法
int n,m;
cin >> n >> m;
counts = int[10];
for(int i = 0; i < 10; ++i) {
counts[i] = 0;
}
for(int j = n; j <= m; j++) {
int z = j;
do {
int digit = z % 10; // LAST DIGIT OF FirsT NUMBER IN INTERVAL
counts[digit]++;
z /= 10;
} while (z != 0);
}
for(int i = 0; i < 10; ++i) {
cout << i << " occurrences " << counts[i] << " times";
}

C#计算每个字符的出现次数
using System;
public class Demo {
public static void Main() {
string str = Website;
Console.WriteLine(String: +str);
while (str.Length > 0) {
Console.Write(str[0] + = );
int cal = 0;
for (int j = 0; j < str.Length; j++) {
if (str[0] == str[j]) {
caL++;
}
}
Console.WriteLine(cal);
str = str.Replace(str[0].ToString(), string.Empty);
}
Console.ReadLine();
}
}

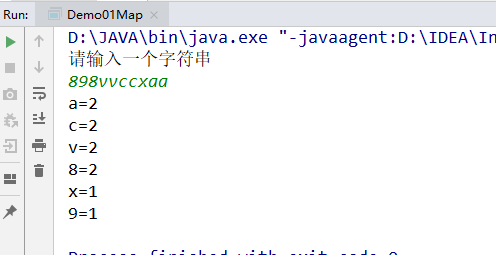
JAVA 练习:计算一个字符串中每个字符的出现次数
/*
练习:
计算一个字符串中每个字符的出现次数
分析:
1,使用Scanner获得用户输入的字符串
2,创建Map集合,kep是字符串的字符,value是字符的个数
3,遍历字符串,获取每一个字符
4,使用获取到在字符,去Map集合判断key是否存在
key存在:
通过字符(key),获取value(字符个数)
value++
put(key,value)把新的value存储 在Map集合中
key不存在 :
put(key,1)
5,遍历Map集合,输出结果
*/
import java.util.HashMap;
import java.util.Scanner;
public class Demo01Map {
public static void main(String[] args) {
//1,使用Scanner获得用户输入的字符串
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个字符串");
String str = scanner.next();
//2,创建Map集合,kep是字符串的字符,value是字符的个数
HashMap<Character,Integer> map =new HashMap<>();
//3,4
for(char c :str.toCharArray()){
if(map.containsKey(c)){
Integer value =map.get(c);
value++;
map.put(c,value);
}else{
map.put(c,1);
}
}
for(Character key :map.keySet()){
Integer value = map.get(key);
System.out.println(key+"="+value);
}
}
关于计算python字典中每个键的出现次数和计算python字典中每个键的出现次数的方法的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于c – 计算大数据流中每个元素的出现次数、c – 计算整数区间(或int数组)中每个数字的出现次数、C#计算每个字符的出现次数、JAVA 练习:计算一个字符串中每个字符的出现次数等相关内容,可以在本站寻找。
本文标签:




