这篇文章主要围绕机器学习组件Accord.NET框架功能介绍展开,旨在为您提供一份详细的参考资料。我们将全面介绍机器学习组件Accord.NET框架功能介绍,同时也会为您带来.NET开发框架(二)-框
这篇文章主要围绕机器学习组件Accord.NET框架功能介绍展开,旨在为您提供一份详细的参考资料。我们将全面介绍机器学习组件Accord.NET框架功能介绍,同时也会为您带来.NET 开发框架 (二)- 框架功能简述、.NETCore 新型 ORM 功能介绍、.NET版Word处理控件Aspose.Words功能演示:从C#.NET中的模板生成Word文档、ASP.NET Core扩展库的相关功能介绍的实用方法。
本文目录一览:- 机器学习组件Accord.NET框架功能介绍
- .NET 开发框架 (二)- 框架功能简述
- .NETCore 新型 ORM 功能介绍
- .NET版Word处理控件Aspose.Words功能演示:从C#.NET中的模板生成Word文档
- ASP.NET Core扩展库的相关功能介绍

机器学习组件Accord.NET框架功能介绍
1.基本功能与介绍
Accord.NET为.NET应用程序提供了统计分析、机器学习、图像处理、计算机视觉相关的算法。Accord.NET框架扩展了AForge.NET框架,提供了一些新功能。同时为.NET环境下的科学计算提供了一个完整的开发环境。该框架被分成了多个程序集,可以直接从官网下载安装文件或者使用NuGet得到。可以参考以下链接:https://github.com/accord-net/framework/wiki
1.1 框架的三大功能模块
Accord.NET框架主要有三个大的功能性模块。分别为科学技术,信号与图像处理,支持组件。下面将对3个模型的命名空间和功能进行简单介绍。可以让大家更快的接触和了解其功能是否是自己想要的,下面是主要的命名空间介绍。
1.1.1 科学计算
Accord.Math:包括矩阵扩展程序,以及一组矩阵数值计算和分解的方法,也包括一些约束和非约束问题的数值优化算法,还有一些特殊函数以及其他一些辅助工具。
Accord.Statistics:包含概率分布、假设检验、线性和逻辑回归等统计模型和方法,隐马尔科夫模型,(隐藏)条件随机域、主成分分析、偏最小二乘判别分析、内核方法和许多其他相关的技术。
Accord.MachineLearning: 为机器学习应用程序提供包括支持向量机,决策树,朴素贝叶斯模型,k-means聚类算法,高斯混合模型和通用算法如Ransac,交叉验证和网格搜索等算法。
Accord.Neuro:包括大量的神经网络学习算法,如Levenberg-Marquardt,Parallel Resilient Backpropagation,Nguyen-Widrow初始化算法,深层的信念网络和许多其他神经网络相关的算法。具体看参考帮助文档。
1.1.2 信号与图像处理
Accord.Imaging:包含特征点探测器(如Harris, SURF, FAST and FREAK),图像过滤器、图像匹配和图像拼接方法,还有一些特征提取器。
Accord.Audio:包含一些机器学习和统计应用程序说需要的处理、转换过滤器以及处理音频信号的方法。
Accord.Vision:实时人脸检测和跟踪,以及对人流图像中的一般的检测、跟踪和转换方法,还有动态模板匹配追踪器。
1.1.3 支持组件
主要是为上述一些组件提供数据显示,绘图的控件,分为以下几个命名空间:
Accord.Controls:包括科学计算应用程序常见的柱状图、散点图和表格数据浏览。
Accord.Controls.Imaging:包括用来显示和处理的图像的WinForm控件,包含一个方便快速显示图像的对话框。
Accord.Controls.Audio:显示波形和音频相关性信息的WinForm控件。
Accord.Controls.Vision:包括跟踪头部,脸部和手部运动以及其他计算机视觉相关的任务WinForm控件。
1.2 支持的算法介绍
下面将Accord.NET框架包括的主要功能算法按照类别进行介绍。来源主要是官网介绍,进行了简单的翻译和整理。
1.2.1 分类(Classification)
SVM(支持向量机)、Logistic Regression(逻辑回归)、Decision Trees(决策树)、 Neural Networks(神经网络)、Deep Learning(深度学习)(Deep Neural Networks深层神经网络)、Levenberg-Marquardt with Bayesian Regularization、Restricted Boltzmann Machines(限制玻耳兹曼机)、Sequence classification (序列分类),Hidden Markov Classifiers and Hidden Conditional Random Fields(隐马尔科夫分类器和隐藏条件随机域)。
1.2.2 回归(Regression)
Multiple linear regression(多元线性回归-单因变量多自变量)、Multivariate linear regression(多元线性回归-多因变量多自变量)、polynomial regression (多项式回归)、logarithmic regression(对数回归)、Logistic regression(逻辑回归)、multinomial logistic regression(多项式逻辑回归)(softmax) and generalized linear models(广义线性模型)、L2-regularized L2-loss logistic regression , L2-regularized logistic regression , L1-regularized logistic regression , L2-regularized logistic regression in the dual form and regression support vector machines。
1.2.3 聚类(Clustering)
K-Means、K-Modes、Mean-Shift(均值漂移)、Gaussian Mixture Models(高斯混合模型)、Binary Split(二元分裂)、Deep Belief Networks(深层的信念网络)、 Restricted Boltzmann Machines(限制玻耳兹曼机)。聚类算法可以应用于任意数据,包括图像、数据表、视频和音频。
1.2.4 概率分布(Distributions)
包括40多个分布的参数和非参数估计。包括一些常见的分布如正态分布、柯西分布、超几何分布、泊松分布、伯努利;也包括一些特殊的分布如Kolmogorov-Smirnov , Nakagami、Weibull、and Von-Mises distributions。也包括多元分布如多元正态分布、Multinomial 、Independent 、Joint and Mixture distributions。
1.2.5 假设检验(Hypothesis Tests)
超过35统计假设测试,包括单向和双向方差分析测试、非参数测试如Kolmogorov-Smirnov测试和媒体中的信号测试。contingency table tests such as the Kappa test,with variations for multiple tables , as well as the Bhapkar and Bowker tests; and the more traditional Chi-Square , Z , F , T and Wald tests .
1.2.6 核方法(Kernel Methods)
内核支持向量机,多类和多标签向量机、序列最小优化、最小二乘学习、概率学习。Including special methods for linear machines such as LIBLINEAR''s methods for Linear Coordinate Descent , Linear Newton Method , Probabilistic Coordinate Descent , Probabilistic Coordinate Descent in the Dual , Probabilistic Newton Method for L1 and L2 machines in both the dual and primal formulations .
1.2.7 图像(Imaging)
兴趣和特征点探测器如Harris,FREAK,SURF,FAST。灰度共生矩阵,Border following,Bag-of-Visual-Words (BoW),RANSAC-based homography estimation , integral images , haralick textural feature extraction , and dense descriptors such as histogram of oriented gradients (HOG) and Local Binary Pattern (LBP).Several image filters for image processing applications such as difference of Gaussians , Gabor , Niblack and Sauvola thresholding。还有几个图像处理中经常用到的图像过滤器。
1.2.8 音频信号(Audio and Signal)
音频信号的加载、解析、保存、过滤和转换,如在空间域和频域应用音频过滤器。WAV文件、音频捕捉、时域滤波器,高通,低通,波整流过滤器。Frequency-domain operators such as differential rectification filter and comb filter with Dirac''s delta functions . Signal generators for Cosine , Impulse , Square signals.
1.2.9 视觉(Vision)
实时人脸检测和跟踪,以及图像流中检测、跟踪、转换的一般的检测方法。Contains cascade definitions , Camshift and Dynamic Template Matching trackers . Includes pre-created classifiers for human faces and some facial features such as noses。
1.3 相关资源
从项目主页:http://accord-framework.net/下载的“Archive”压缩包中,包括了几乎所有的在线资源。如下图,介绍几个主要的资源:
Debug是一些用于调试的程序集,Docs是帮助文档,Externals是一些辅助的组件,Release是不同.NET环境的Dll程序集版本,Samples是案例源代码,Setup是安装的程序,Sources是项目的源代码,Unit Tests是单元测试代码。
Accord.NET框架源代码托管在GitHub:https://github.com/accord-net/framework/
上面有大量的入门资源和教程,例如,查看页面右边的列表栏切换:https://github.com/accord-net/framework/wiki/How-to-use
原文地址:http://www.cnblogs.com/asxinyu/p/dotnet_Opensource_project_AccordNET.html
关注我们的方法:
1.点击文章标题下的“dotNET跨平台”蓝字,或者在微信搜索“opendotnet”,加关注
2.老朋友点击点击右上角“……”标志分享到朋友圈
本文分享自微信公众号 - dotNET跨平台(opendotnet)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
- 框架功能简述")
.NET 开发框架 (二)- 框架功能简述
PC 版本演示视频,请点击 这里查看
本框架为响应式 SPA 框架,支持 PC 与手机端的屏幕自适应。手机展示效果视频在文章末尾查看。
框架入口地址:http://letyouknow.net/
1、框架登录界面,输入账号与密码,点击立即登录
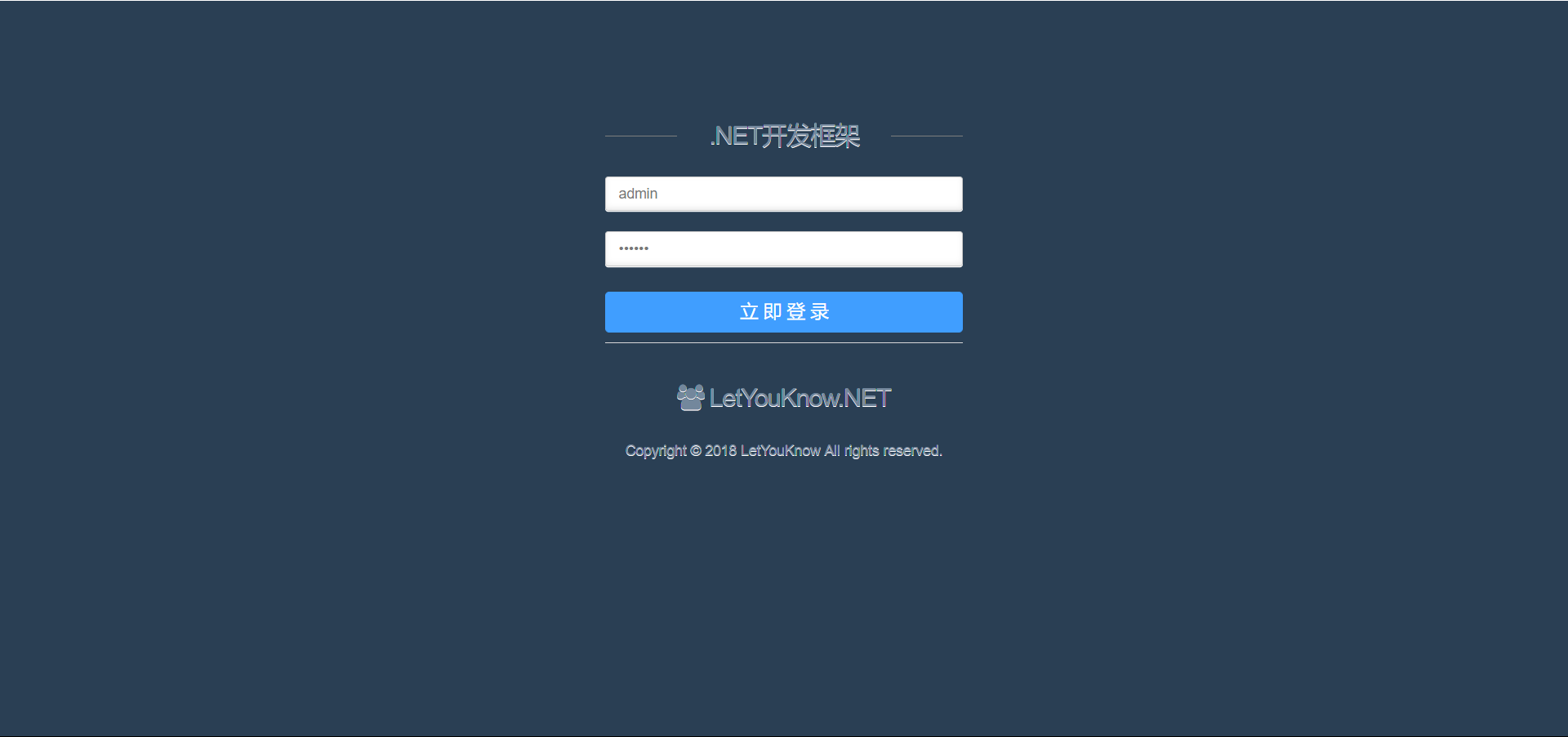
2、框架主界面,左 - 右结构,左边为手风琴式菜单(左菜单可点击三图标收缩与展开),右边内容显示
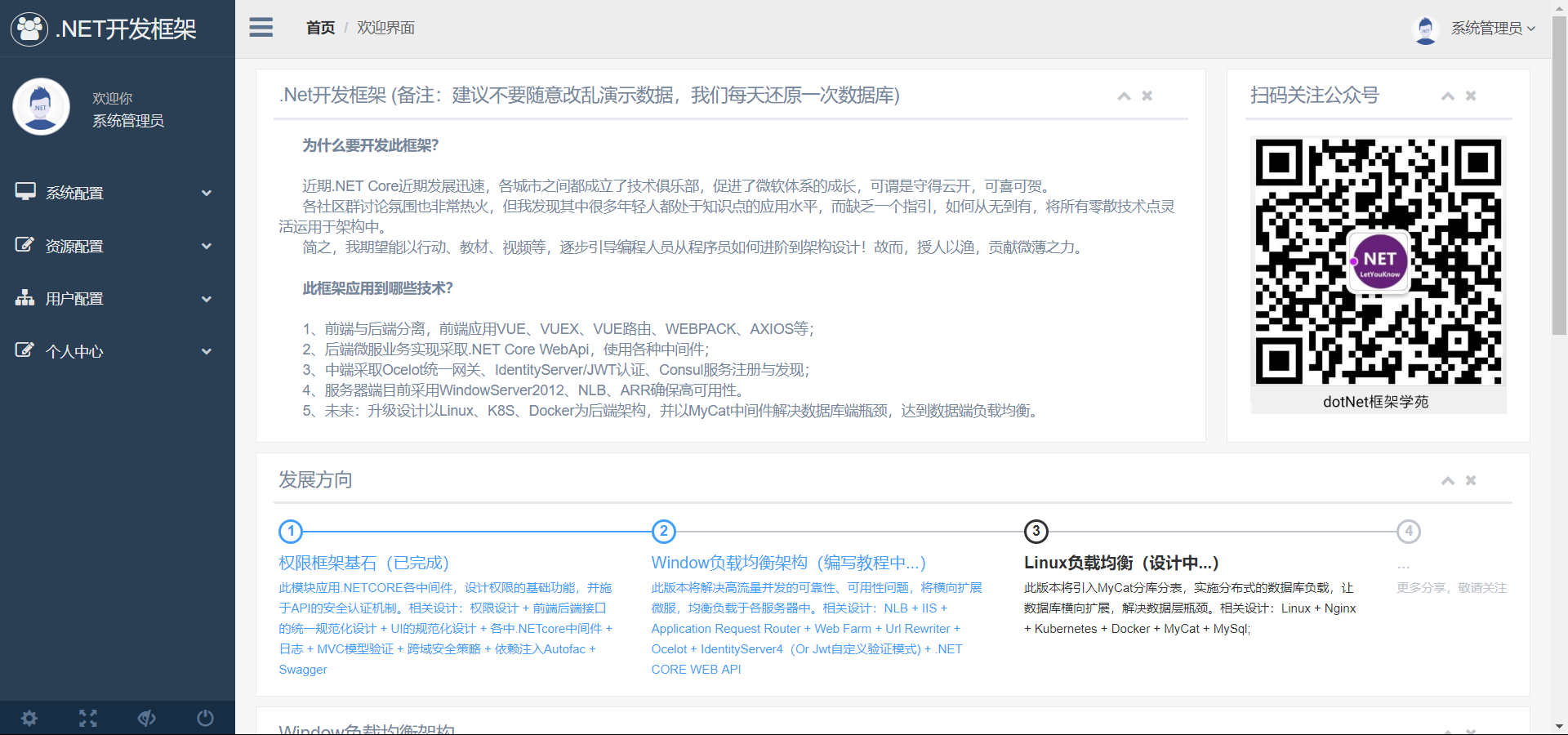
3、应用管理,所谓应用管理, 是泛指所有需要加入权限控制的服务,包括 ASP.NET CORE WEBAPI。当我们后端 API 项目有 N 个时,有时候我们需要将权限粒度控制到很细时,比如希望能控制动态控制到某个具体的方法时,我们就需要对它控制。(当然,如果您只需要针对一整个项目来作一个粒度来控制权限的话,那直接使用 IdentityServer 或 JWT 自定义认证足已)
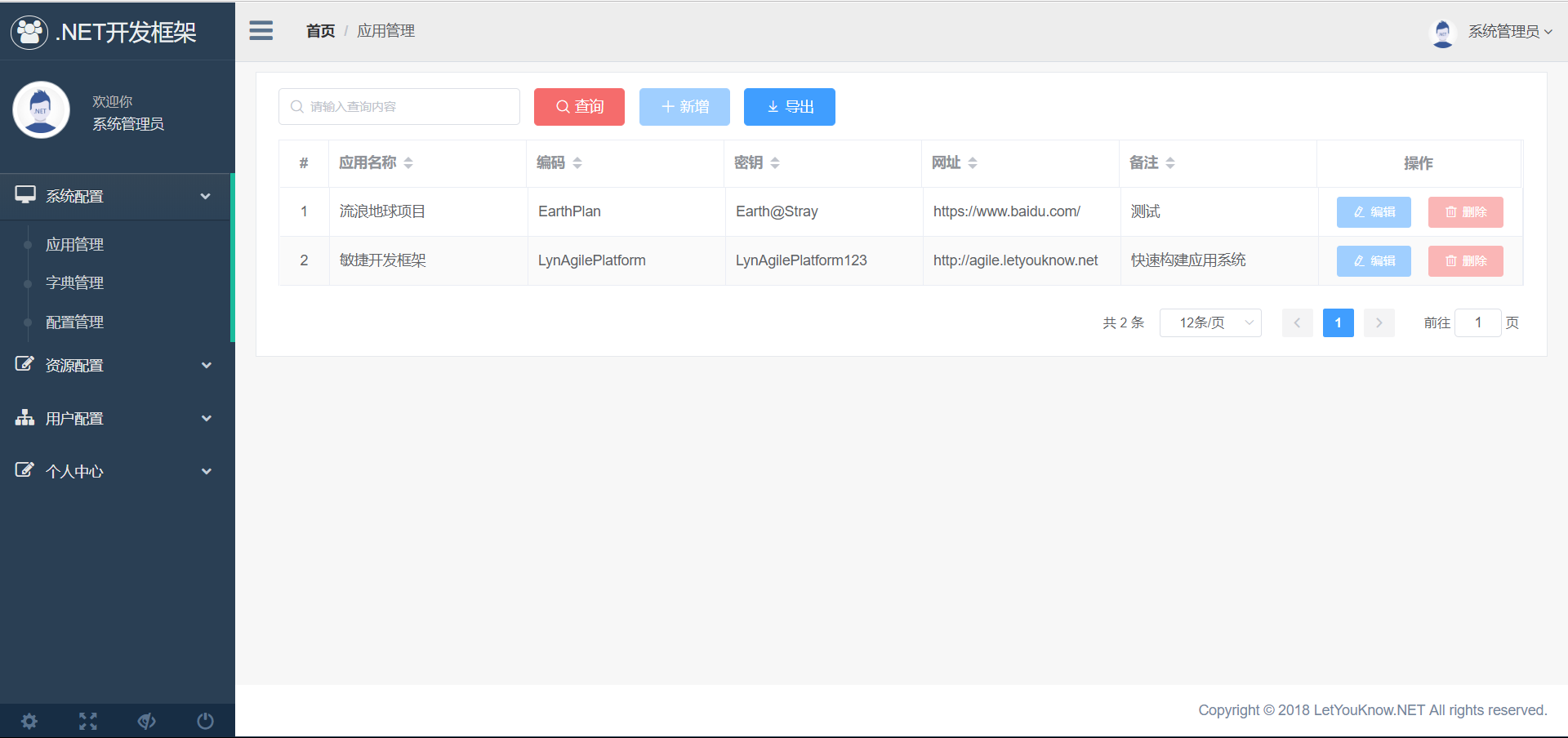
4、字典的基本管理,每个应用可能都会使用一些字典数据,双击某行可快捷显示详情内容
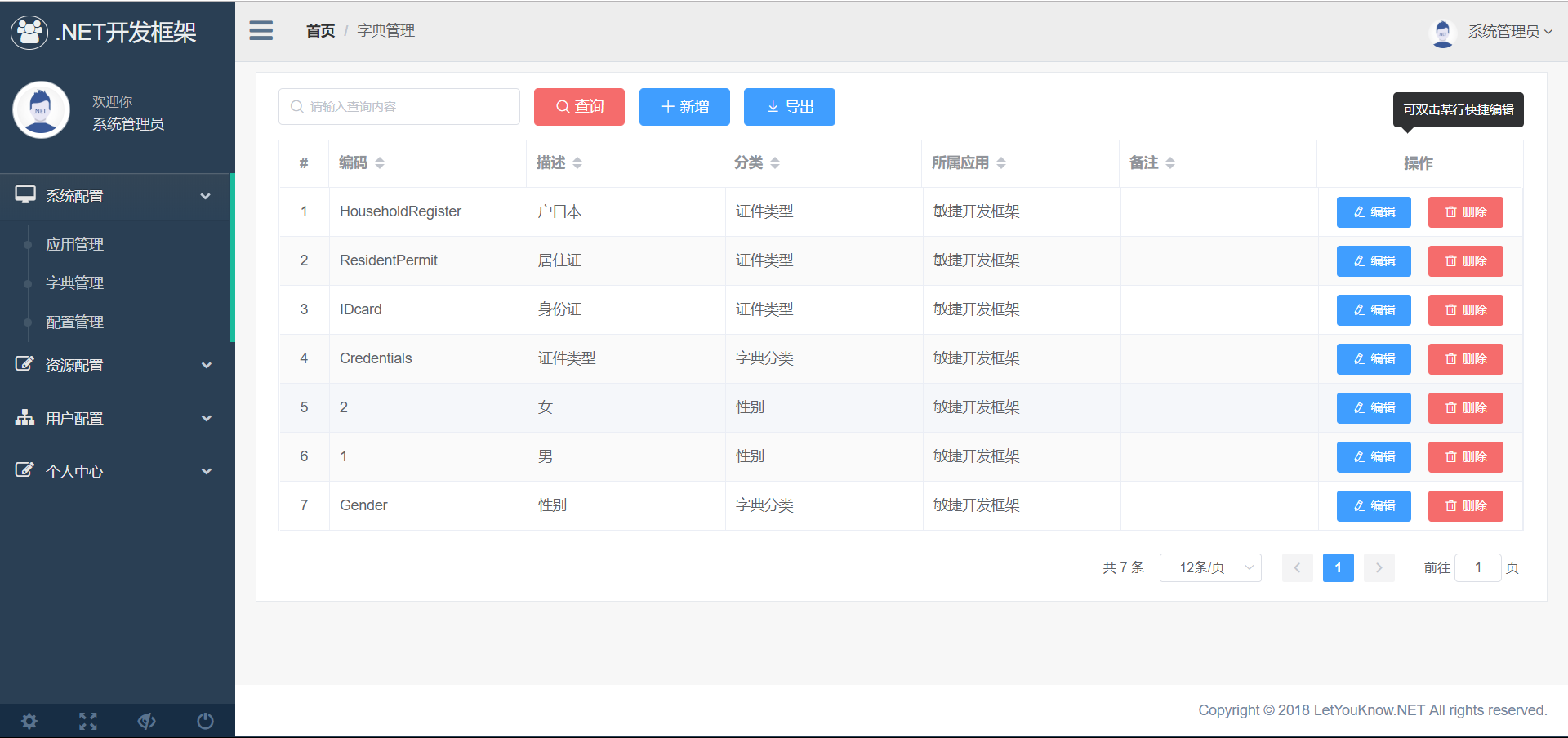
5、菜单管理,可管理每个应用的菜单,与其对应的按钮
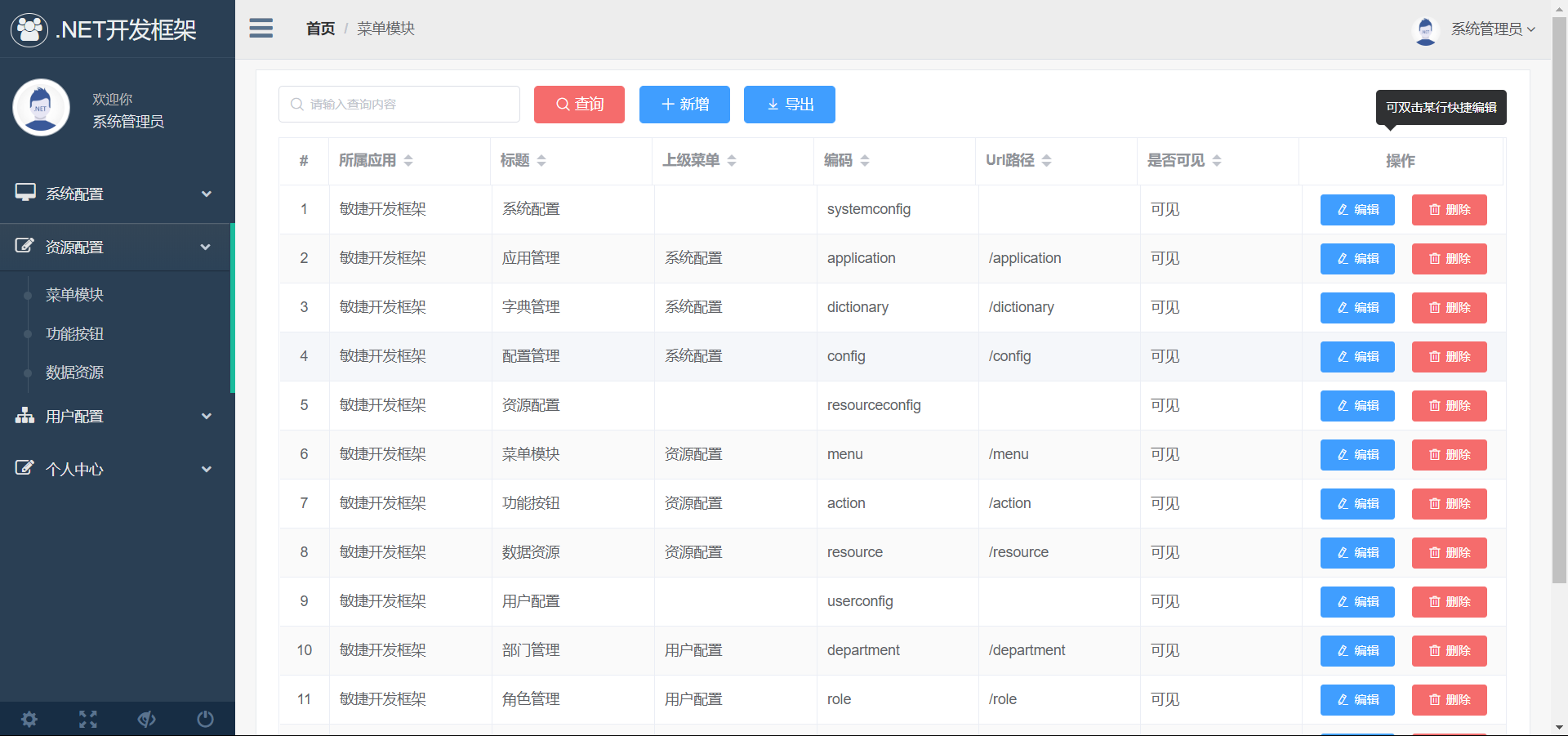
6、按钮管理,配置每个应用的菜单对应的按钮
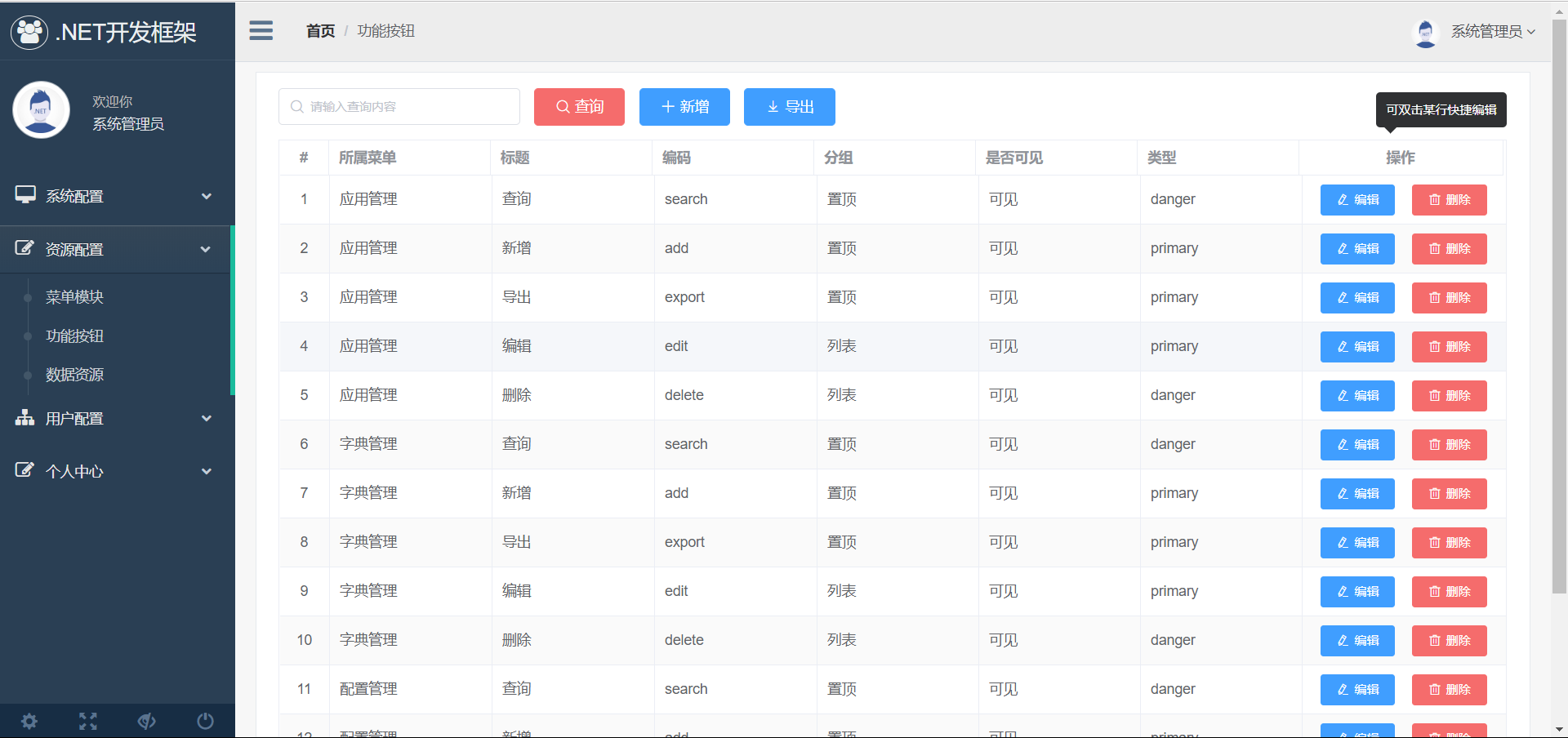
7、部门管理
8、左菜单的收缩与展开

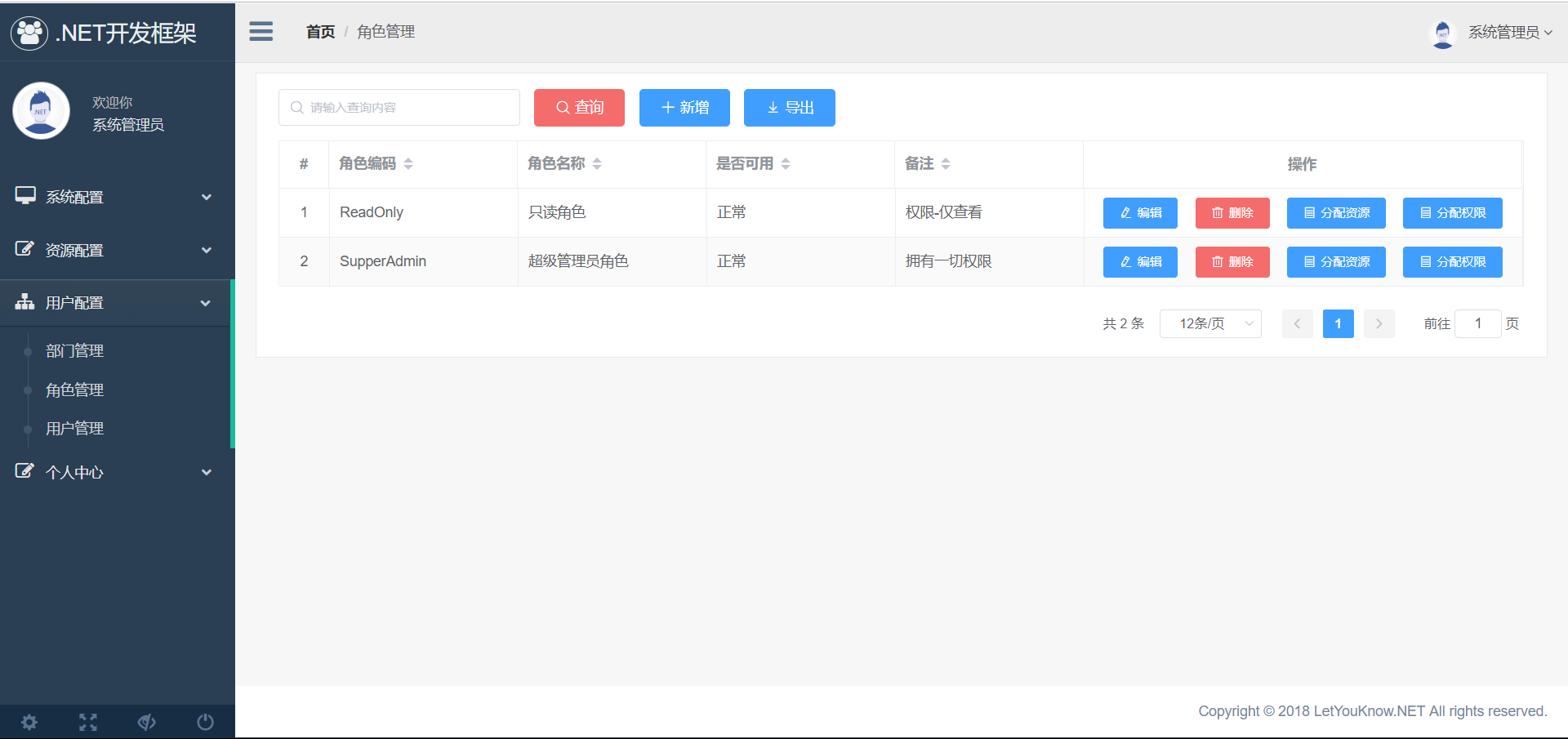
9、角色的管理,它包括配置数据资源权限与菜单权限,还有可配置按钮的权限
10、用户管理,包括分配角色,分配以穿梭框方式操作,左右穿越
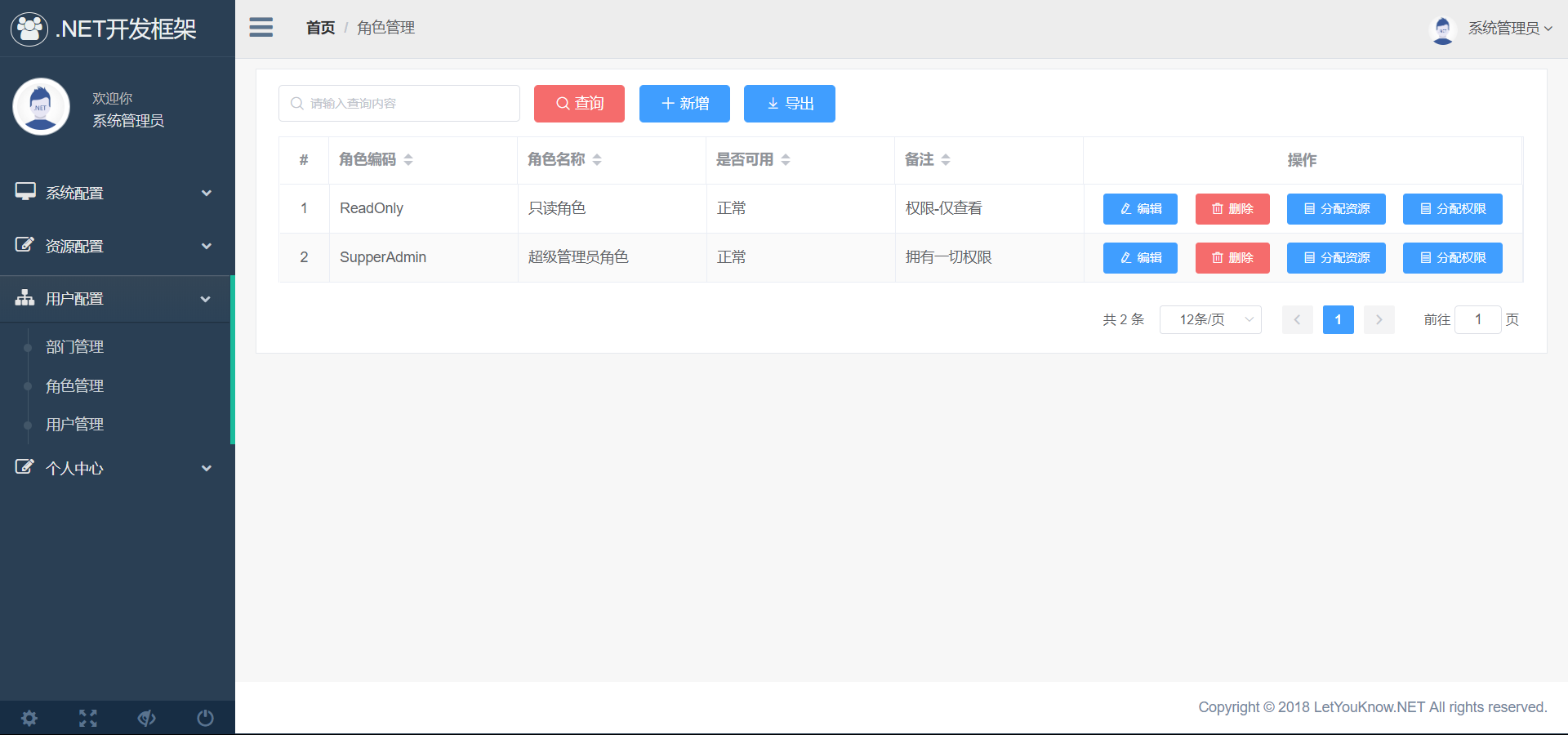
11、对角色分配菜单与按钮的权限
12、个人资料的管理,可上传头像,修改密码。上传头像使用了 VUE Upload 上传组件
VUE Upload 上传组件,支持拖放,伸缩调整图片,查看上传进度

13、左下角放置了常用功能按钮,全屏显示、临时锁屏、退出系统

14、双击列表中某行,快捷展示详情内容
15、此框架为响应式设计,适应于各种手机屏展示。支持 PC 与手机端的屏幕自适应,同时设计为 SPA 模式,可结合 AppCloud 快速生成安卓或 IOS 的 APP。

.NETCore 新型 ORM 功能介绍
简介
FreeSql 是一个功能强大的 .NETStandard 库,用于对象关系映射程序(O/RM),支持 .NETCore 2.1+ 或 .NETFramework 4.6.1+。
定义
IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.Sqlite,
@"Data Source=|DataDirectory|/test.db;Pooling=true;Max Pool Size=10")
.UseAutoSyncStructure(true) //自动同步实体结构到数据库
.Build();入门篇
查询
1、查询一条
fsql.Select<Xxx>.Where(a => a.Id == 1).First();2、分页:第1页,每页20条
fsql.Select<Xxx>.Page(1, 20).ToList();细节说明:SqlServer 2012 以前的版本,使用 row_number 分页;SqlServer 2012+ 版本,使用最新的 fetch next rows 分页;
3、IN
fsql.Select<Xxx>.Where(a => new { 1,2,3 }.Contains(a.Id)).ToList();4、联表
fsql.Select<Xxx>.LeftJoin<Yyy>((a, b) => a.YyyId == b.Id).ToList();5、Exists子表
fsql.Select<Xxx>.Where(a => fsql.Select<Yyy>(b => b.Id == a.YyyId).Any()).ToList();6、GroupBy & Having
fsql.Select<Xxx>.GroupBy(a => new { a.CategoryId }).Having(a => a.Count > 2).ToList(a => new { a.Key, a.Count() });7、指定字段查询
fsql.Select<Xxx>.Limit(10).ToList(a => a.Id);
fsql.Select<Xxx>.Limit(10).ToList(a => new { a.Id, a.Name });
fsql.Select<Xxx>.Limit(10).ToList(a => new Dto());8、执行SQL返回实体
fsql.Ado.Query<Xxx>("select * from xxx");
fsql.Ado.Query<(int, string, string)>("select * from xxx");
fsql.Ado.Query<dynamic>("select * from xxx");插入
1、单条
fsql.Insert<Xxx>().AppendData(new Xxx()).ExecuteAffrows();2、单条,返回自增值
fsql.Insert<Xxx>().AppendData(new Xxx()).ExecuteIdentity();3、单条,返回插入的行(SqlServer 的 output 特性)
fsql.Insert<Xxx>().AppendData(new Xxx()).ExecuteInserted();4、批量
fsql.Insert<Xxx>().AppendData(数组).ExecuteAffrows();5、批量,返回插入的行(SqlServer 的 output 特性)
fsql.Insert<Xxx>().AppendData(数组).ExecuteInserted();6、指定列
fsql.Insert<Xxx>().AppendData(new Xxx()).InsertColumns(a => a.Title).ExecuteAffrows();
fsql.Insert<Xxx>().AppendData(new Xxx()).InsertColumns(a => new { a.Id, a.Title}).ExecuteAffrows();7、忽略列
fsql.Insert<Xxx>().AppendData(new Xxx()).IgnoreColumns(a => a.Title).ExecuteAffrows();
fsql.Insert<Xxx>().AppendData(new Xxx()).IgnoreColumns(a => new { a.Id, a.Title}).ExecuteAffrows();8、事务
fsql.Insert<Xxx>().AppendData(new Xxx()).WithTransaction(事务对象).ExecuteAffrows();更新
1、指定列
fsql.Update<Xxx>(1).Set(a => a.CreateTime, DateTime.Now).ExecuteAffrows();2、累加,set clicks = clicks + 1
fsql.Update<Xxx>(1).Set(a => a.Clicks + 1).ExecuteAffrows();3、保存
fsql.Update<Xxx>().SetSource(单个实体).ExecuteAffrows();4、批量保存
fsql.Update<Xxx>().SetSource(数组).ExecuteAffrows();5、忽略列
fsql.Update<Xxx>().SetSource(数组).IgnoreColumns(a => new { a.Clicks, a.CreateTime }).ExecuteAffrows();6、更新条件
fsql.Update<Xxx>().SetSource(数组).Where(a => a.Clicks > 100).ExecuteAffrows();7、事务
fsql.Update<Xxx>(1).Set(a => a.Clicks + 1).WithTransaction(事务对象).ExecuteAffrows();删除
1、dywhere
- 主键值
- new[] { 主键值1, 主键值2 }
- Xxx对象
- new[] { Xxx对象1, Xxx对象2 }
- new { id = 1 }
fsql.Delete<Xxx>(new[] { 1, 2 }).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` = 1 OR `Id` = 2)
fsql.Delete<Xxx>(new Xxx { Id = 1, Title = "test" }).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` = 1)
fsql.Delete<Xxx>(new[] { new Xxx { Id = 1, Title = "test" }, new Xxx { Id = 2, Title = "test" } }).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` = 1 OR `Id` = 2)
fsql.Delete<Xxx>(new { id = 1 }).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` = 1)2、条件
fsql.Delete<Xxx>().Where(a => a.Id == 1).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` = 1)
fsql.Delete<Xxx>().Where("id = ?id", new { id = 1 }).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (id = ?id)
var item = new Xxx { Id = 1, Title = "newtitle" };
var t7 = fsql.Delete<Xxx>().Where(item).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` = 1)
var items = new List<Xxx>();
for (var a = 0; a < 10; a++) items.Add(new Xxx { Id = a + 1, Title = $"newtitle{a}", Clicks = a * 100 });
fsql.Delete<Xxx>().Where(items).ExecuteAffrows();
//DELETE FROM `xxx` WHERE (`Id` IN (1,2,3,4,5,6,7,8,9,10))3、事务
fsql.Delete<Xxx>().Where(a => a.Id == 1).WithTransaction(事务对象).ExecuteAffrows();初级篇
表达式
支持功能丰富的表达式函数解析,方便程序员在不了解数据库函数的情况下编写代码。这是 FreeSql 非常特色的功能之一,深入细化函数解析尽量做到满意,所支持的类型基本都可以使用对应的表达式函数,例如 日期、字符串、IN查询、数组(PostgreSQL的数组)、字典(PostgreSQL HStore)等等。
1、查找今天创建的数据
fsql.Delete<Xxx>().Where(a => a.CreateTime.Date == DateTime.Now.Date).ToList();2、SqlServer 下随机获取记录
fsql.Delete<Xxx>().OrderBy(a => Guid.NewGuid()).Limit(1).ToSql();4、表达式函数全览
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | 功能说明 |
|---|---|---|---|---|---|
| a ? b : c | case when a then b else c end | case when a then b else c end | case when a then b else c end | case when a then b else c end | a成立时取b值,否则取c值 |
| a ?? b | ifnull(a, b) | isnull(a, b) | coalesce(a, b) | nvl(a, b) | 当a为null时,取b值 |
| 数字 + 数字 | a + b | a + b | a + b | a + b | 数字相加 |
| 数字 + 字符串 | concat(a, b) | cast(a as varchar) + cast(b as varchar) | case(a as varchar) + b | a+b | 字符串相加,a或b任意一个为字符串时 |
| a - b | a - b | a - b | a - b | a - b | 减 |
| a * b | a * b | a * b | a * b | a * b | 乘 |
| a / b | a / b | a / b | a / b | a / b | 除 |
| a % b | a % b | a % b | a % b | mod(a,b) | 模 |
等等...
5、数组
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | 功能说明 |
|---|---|---|---|---|---|
| a.Length | - | - | case when a is null then 0 else array_length(a,1) end | - | 数组长度 |
| 常量数组.Length | - | - | array_length(array[常量数组元素逗号分割],1) | - | 数组长度 |
| a.Any() | - | - | case when a is null then 0 else array_length(a,1) end > 0 | - | 数组是否为空 |
| 常量数组.Contains(b) | b in (常量数组元素逗号分割) | b in (常量数组元素逗号分割) | b in (常量数组元素逗号分割) | b in (常量数组元素逗号分割) | IN查询 |
| a.Contains(b) | - | - | a @> array[b] | - | a数组是否包含b元素 |
| a.Concat(b) | - | - | a + b | - | 数组相连 |
| a.Count() | - | - | 同 Length | - | 数组长度 |
一个细节证明 FreeSql 匠心制作
通用的 in 查询 select.Where(a => new []{ 1,2,3 }.Contains(a.xxx))
假设 xxxs 是 pgsql 的数组字段类型,其实会与上面的 in 查询起冲突,FreeSql 解决了这个矛盾 select.Where(a => a.xxxs.Contains(1))
6、字典 Dictionary<string, string>
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | 功能说明 |
|---|---|---|---|---|---|
| a.Count | - | - | case when a is null then 0 else array_length(akeys(a),1) end | - | 字典长度 |
| a.Keys | - | - | akeys(a) | - | 返回字典所有key数组 |
| a.Values | - | - | avals(a) | - | 返回字典所有value数组 |
| a.Contains(b) | - | - | a @> b | - | 字典是否包含b |
| a.ContainsKey(b) | - | - | a? b | - | 字典是否包含key |
| a.Concat(b) | - | - | a + b | - | 字典相连 |
| a.Count() | - | - | 同 Count | - | 字典长度 |
7、JSON JToken/JObject/JArray
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | 功能说明 |
|---|---|---|---|---|---|
| a.Count | - | - | jsonb_array_length(coalesce(a, ''[])) | - | json数组类型的长度 |
| a.Any() | - | - | jsonb_array_length(coalesce(a, ''[])) > 0 | - | json数组类型,是否为空 |
| a.Contains(b) | - | - | coalesce(a, ''{}'') @> b::jsonb | - | json中是否包含b |
| a.ContainsKey(b) | - | - | coalesce(a, ''{}'') ? b | - | json中是否包含键b |
| a.Concat(b) | - | - | coalesce(a, ''{}'') + b::jsonb | - | 连接两个json |
| Parse(a) | - | - | a::jsonb | - | 转化字符串为json类型 |
8、字符串
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | Sqlite |
|---|---|---|---|---|---|
| string.Empty | '''' | '''' | '''' | '''' | |
| string.IsNullOrEmpty(a) | (a is null or a = '''') | (a is null or a = '''') | (a is null or a = '''') | (a is null or a = '''') | (a is null or a = '''') |
| a.CompareTo(b) | strcmp(a, b) | - | case when a = b then 0 when a > b then 1 else -1 end | case when a = b then 0 when a > b then 1 else -1 end | case when a = b then 0 when a > b then 1 else -1 end |
| a.Contains(''b'') | a like ''%b%'' | a like ''%b%'' | a ilike''%b%'' | a like ''%b%'' | a like ''%b%'' |
| a.EndsWith(''b'') | a like ''%b'' | a like ''%b'' | a ilike''%b'' | a like ''%b'' | a like ''%b'' |
| a.IndexOf(b) | locate(a, b) - 1 | locate(a, b) - 1 | strpos(a, b) - 1 | instr(a, b, 1, 1) - 1 | instr(a, b) - 1 |
| a.Length | char_length(a) | len(a) | char_length(a) | length(a) | length(a) |
| a.PadLeft(b, c) | lpad(a, b, c) | - | lpad(a, b, c) | lpad(a, b, c) | lpad(a, b, c) |
| a.PadRight(b, c) | rpad(a, b, c) | - | rpad(a, b, c) | rpad(a, b, c) | rpad(a, b, c) |
| a.Replace(b, c) | replace(a, b, c) | replace(a, b, c) | replace(a, b, c) | replace(a, b, c) | replace(a, b, c) |
| a.StartsWith(''b'') | a like ''b%'' | a like ''b%'' | a ilike''b%'' | a like ''b%'' | a like ''b%'' |
| a.Substring(b, c) | substr(a, b, c + 1) | substring(a, b, c + 1) | substr(a, b, c + 1) | substr(a, b, c + 1) | substr(a, b, c + 1) |
| a.ToLower | lower(a) | lower(a) | lower(a) | lower(a) | lower(a) |
| a.ToUpper | upper(a) | upper(a) | upper(a) | upper(a) | upper(a) |
| a.Trim | trim(a) | trim(a) | trim(a) | trim(a) | trim(a) |
| a.TrimEnd | rtrim(a) | rtrim(a) | rtrim(a) | rtrim(a) | rtrim(a) |
| a.TrimStart | ltrim(a) | ltrim(a) | ltrim(a) | ltrim(a) | ltrim(a) |
使用字符串函数可能会出现性能瓶颈,虽然不推荐使用,但是作为功能库这也是不可缺少的功能之一。
9、日期
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DateTime.Now | now() | getdate() | current_timestamp | systimestamp | ||||||||||||
| DateTime.UtcNow | utc_timestamp() | getutcdate() | (current_timestamp at time zone ''UTC'') | sys_extract_utc(systimestamp) | ||||||||||||
| DateTime.Today | curdate | convert(char(10),getdate(),120) | current_date | trunc(systimestamp) | ||||||||||||
| DateTime.MaxValue | cast(''9999/12/31 23:59:59'' as datetime) | ''9999/12/31 23:59:59'' | ''9999/12/31 23:59:59''::timestamp | to_timestamp(''9999-12-31 23:59:59'',''YYYY-MM-DD HH24:MI:SS.FF6'') | ||||||||||||
| DateTime.MinValue | cast(''0001/1/1 0:00:00'' as datetime) | ''1753/1/1 0:00:00'' | ''0001/1/1 0:00:00''::timestamp | to_timestamp(''0001-01-01 00:00:00'',''YYYY-MM-DD HH24:MI:SS.FF6'') | ||||||||||||
| DateTime.Compare(a, b) | a - b | a - b | extract(epoch from a::timestamp-b::timestamp) | extract(day from (a-b)) | ||||||||||||
| DateTime.DaysInMonth(a, b) | dayofmonth(last_day(concat(a, ''-'', b, ''-1''))) | datepart(day, dateadd(day, -1, dateadd(month, 1, cast(a as varchar) + ''-'' + cast(b as varchar) + ''-1''))) | extract(day from (a | ''-'' | b | ''-01'')::timestamp+''1 month''::interval-''1 day''::interval) | cast(to_char(last_day(a | ''-'' | b | ''-01''),''DD'') as number) | ||||||
| DateTime.Equals(a, b) | a = b | a = b | a = b | a = b | ||||||||||||
| DateTime.IsLeapYear(a) | a%4=0 and a%100<>0 or a%400=0 | a%4=0 and a%100<>0 or a%400=0 | a%4=0 and a%100<>0 or a%400=0 | mod(a,4)=0 AND mod(a,100)<>0 OR mod(a,400)=0 | ||||||||||||
| DateTime.Parse(a) | cast(a as datetime) | cast(a as datetime) | a::timestamp | to_timestamp(a,''YYYY-MM-DD HH24:MI:SS.FF6'') | ||||||||||||
| a.Add(b) | date_add(a, interval b microsecond) | dateadd(millisecond, b / 1000, a) | a::timestamp+(b | '' microseconds'')::interval | 增加TimeSpan值 | a + b | ||||||||||
| a.AddDays(b) | date_add(a, interval b day) | dateadd(day, b, a) | a::timestamp+(b | '' day'')::interval | a + b | |||||||||||
| a.AddHours(b) | date_add(a, interval b hour) | dateadd(hour, b, a) | a::timestamp+(b | '' hour'')::interval | a + b/24 | |||||||||||
| a.AddMilliseconds(b) | date_add(a, interval b*1000 microsecond) | dateadd(millisecond, b, a) | a::timestamp+(b | '' milliseconds'')::interval | a + b/86400000 | |||||||||||
| a.AddMinutes(b) | date_add(a, interval b minute) | dateadd(minute, b, a) | a::timestamp+(b | '' minute'')::interval | a + b/1440 | |||||||||||
| a.AddMonths(b) | date_add(a, interval b month) | dateadd(month, b, a) | a::timestamp+(b | '' month'')::interval | add_months(a,b) | |||||||||||
| a.AddSeconds(b) | date_add(a, interval b second) | dateadd(second, b, a) | a::timestamp+(b | '' second'')::interval | a + b/86400 | |||||||||||
| a.AddTicks(b) | date_add(a, interval b/10 microsecond) | dateadd(millisecond, b / 10000, a) | a::timestamp+(b | '' microseconds'')::interval | a + b/86400000000 | |||||||||||
| a.AddYears(b) | date_add(a, interval b year) | dateadd(year, b, a) | a::timestamp+(b | '' year'')::interval | add_months(a,b*12) | |||||||||||
| a.Date | cast(date_format(a, ''%Y-%m-%d'') as datetime) | convert(char(10),a,120) | a::date | trunc(a) | ||||||||||||
| a.Day | dayofmonth(a) | datepart(day, a) | extract(day from a::timestamp) | cast(to_char(a,''DD'') as number) | ||||||||||||
| a.DayOfWeek | dayofweek(a) | datepart(weekday, a) - 1 | extract(dow from a::timestamp) | case when to_char(a)=''7'' then 0 else cast(to_char(a) as number) end | ||||||||||||
| a.DayOfYear | dayofyear(a) | datepart(dayofyear, a) | extract(doy from a::timestamp) | cast(to_char(a,''DDD'') as number) | ||||||||||||
| a.Hour | hour(a) | datepart(hour, a) | extract(hour from a::timestamp) | cast(to_char(a,''HH24'') as number) | ||||||||||||
| a.Millisecond | floor(microsecond(a) / 1000) | datepart(millisecond, a) | extract(milliseconds from a::timestamp)-extract(second from a::timestamp)*1000 | cast(to_char(a,''FF3'') as number) | ||||||||||||
| a.Minute | minute(a) | datepart(minute, a) | extract(minute from a::timestamp) | cast(to_char(a,''MI'') as number) | ||||||||||||
| a.Month | month(a) | datepart(month, a) | extract(month from a::timestamp) | cast(to_char(a,''FF3'') as number) | ||||||||||||
| a.Second | second(a) | datepart(second, a) | extract(second from a::timestamp) | cast(to_char(a,''SS'') as number) | ||||||||||||
| a.Subtract(b) | timestampdiff(microsecond, b, a) | datediff(millisecond, b, a) * 1000 | (extract(epoch from a::timestamp-b::timestamp)*1000000) | a - b | ||||||||||||
| a.Ticks | timestampdiff(microsecond, ''0001-1-1'', a) * 10 | datediff(millisecond, ''1970-1-1'', a) * 10000 + 621355968000000000 | extract(epoch from a::timestamp)*10000000+621355968000000000 | cast(to_char(a,''FF7'') as number) | ||||||||||||
| a.TimeOfDay | timestampdiff(microsecond, date_format(a, ''%Y-%m-%d''), a) | ''1970-1-1 '' + convert(varchar, a, 14) | extract(epoch from a::time)*1000000 | a - trunc(a) | ||||||||||||
| a.Year | year(a) | datepart(year, a) | extract(year from a::timestamp) | 年 | cast(to_char(a,''YYYY'') as number) | |||||||||||
| a.Equals(b) | a = b | a = b | a = b | a = b | ||||||||||||
| a.CompareTo(b) | a - b | a - b | a - b | a - b | ||||||||||||
| a.ToString() | date_format(a, ''%Y-%m-%d %H:%i:%s.%f'') | convert(varchar, a, 121) | to_char(a, ''YYYY-MM-DD HH24:MI:SS.US'') | to_char(a,''YYYY-MM-DD HH24:MI:SS.FF6'') |
10、时间
| 表达式 | MySql(微秒) | SqlServer(秒) | PostgreSQL(微秒) | Oracle(Interval day(9) to second(7)) | |
|---|---|---|---|---|---|
| TimeSpan.Zero | 0 | 0 | - | 0微秒 | numtodsinterval(0,''second'') |
| TimeSpan.MaxValue | 922337203685477580 | 922337203685477580 | - | numtodsinterval(233720368.5477580,''second'') | |
| TimeSpan.MinValue | -922337203685477580 | -922337203685477580 | - | numtodsinterval(-233720368.5477580,''second'') | |
| TimeSpan.Compare(a, b) | a - b | a - b | - | extract(day from (a-b)) | |
| TimeSpan.Equals(a, b) | a = b | a = b | - | a = b | |
| TimeSpan.FromDays(a) | a 1000000 60 60 24 | a 1000000 60 60 24 | - | numtodsinterval(a*86400,''second'') | |
| TimeSpan.FromHours(a) | a 1000000 60 * 60 | a 1000000 60 * 60 | - | numtodsinterval(a*3600,''second'') | |
| TimeSpan.FromMilliseconds(a) | a * 1000 | a * 1000 | - | numtodsinterval(a/1000,''second'') | |
| TimeSpan.FromMinutes(a) | a 1000000 60 | a 1000000 60 | - | numtodsinterval(a*60,''second'') | |
| TimeSpan.FromSeconds(a) | a * 1000000 | a * 1000000 | - | numtodsinterval(a,''second'') | |
| TimeSpan.FromTicks(a) | a / 10 | a / 10 | - | numtodsinterval(a/10000000,''second'') | |
| a.Add(b) | a + b | a + b | - | a + b | |
| a.Subtract(b) | a - b | a - b | - | a - b | |
| a.CompareTo(b) | a - b | a - b | - | extract(day from (a-b)) | |
| a.Days | a div (1000000 60 60 * 24) | a div (1000000 60 60 * 24) | - | extract(day from a) | |
| a.Hours | a div (1000000 60 60) mod 24 | a div (1000000 60 60) mod 24 | - | extract(hour from a) | |
| a.Milliseconds | a div 1000 mod 1000 | a div 1000 mod 1000 | - | cast(substr(extract(second from a)-floor(extract(second from a)),2,3) as number) | |
| a.Seconds | a div 1000000 mod 60 | a div 1000000 mod 60 | - | extract(second from a) | |
| a.Ticks | a * 10 | a * 10 | - | (extract(day from a)86400+extract(hour from a)3600+extract(minute from a)60+extract(second from a))10000000 | |
| a.TotalDays | a / (1000000 60 60 * 24) | a / (1000000 60 60 * 24) | - | extract(day from a) | |
| a.TotalHours | a / (1000000 60 60) | a / (1000000 60 60) | - | (extract(day from a)*24+extract(hour from a)) | |
| a.TotalMilliseconds | a / 1000 | a / 1000 | - | (extract(day from a)86400+extract(hour from a)3600+extract(minute from a)60+extract(second from a))1000 | |
| a.TotalMinutes | a / (1000000 * 60) | a / (1000000 * 60) | - | (extract(day from a)1440+extract(hour from a)60+extract(minute from a)) | |
| a.TotalSeconds | a / 1000000 | a / 1000000 | - | (extract(day from a)86400+extract(hour from a)3600+extract(minute from a)*60+extract(second from a)) | |
| a.Equals(b) | a = b | a = b | - | a = b | |
| a.ToString() | cast(a as varchar) | cast(a as varchar) | - | to_char(a) |
11、数学函数
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle |
|---|---|---|---|---|
| Math.Abs(a) | abs(a) | abs(a) | abs(a) | |
| Math.Acos(a) | acos(a) | acos(a) | acos(a) | acos(a) |
| Math.Asin(a) | asin(a) | asin(a) | asin(a) | asin(a) |
| Math.Atan(a) | atan(a) | atan(a) | atan(a) | atan(a) |
| Math.Atan2(a, b) | atan2(a, b) | atan2(a, b) | atan2(a, b) | - |
| Math.Ceiling(a) | ceiling(a) | ceiling(a) | ceiling(a) | ceil(a) |
| Math.Cos(a) | cos(a) | cos(a) | cos(a) | cos(a) |
| Math.Exp(a) | exp(a) | exp(a) | exp(a) | exp(a) |
| Math.Floor(a) | floor(a) | floor(a) | floor(a) | floor(a) |
| Math.Log(a) | log(a) | log(a) | log(a) | log(e,a) |
| Math.Log10(a) | log10(a) | log10(a) | log10(a) | log(10,a) |
| Math.PI(a) | 3.1415926535897931 | 3.1415926535897931 | 3.1415926535897931 | 3.1415926535897931 |
| Math.Pow(a, b) | pow(a, b) | power(a, b) | pow(a, b) | power(a, b) |
| Math.Round(a, b) | round(a, b) | round(a, b) | round(a, b) | round(a, b) |
| Math.Sign(a) | sign(a) | sign(a) | sign(a) | sign(a) |
| Math.Sin(a) | sin(a) | sin(a) | sin(a) | sin(a) |
| Math.Sqrt(a) | sqrt(a) | sqrt(a) | sqrt(a) | sqrt(a) |
| Math.Tan(a) | tan(a) | tan(a) | tan(a) | tan(a) |
| Math.Truncate(a) | truncate(a, 0) | floor(a) | trunc(a, 0) | trunc(a, 0) |
12、类型转换
| 表达式 | MySql | SqlServer | PostgreSQL | Oracle | Sqlite |
|---|---|---|---|---|---|
| Convert.ToBoolean(a), bool.Parse(a) | a not in (''0'',''false'') | a not in (''0'',''false'') | a::varchar not in (''0'',''false'',''f'',''no'') | - | a not in (''0'',''false'') |
| Convert.ToByte(a), byte.Parse(a) | cast(a as unsigned) | cast(a as tinyint) | a::int2 | cast(a as number) | cast(a as int2) |
| Convert.ToChar(a) | substr(cast(a as char),1,1) | substring(cast(a as nvarchar),1,1) | substr(a::char,1,1) | substr(to_char(a),1,1) | substr(cast(a as character),1,1) |
| Convert.ToDateTime(a), DateTime.Parse(a) | cast(a as datetime) | cast(a as datetime) | a::timestamp | to_timestamp(a,''YYYY-MM-DD HH24:MI:SS.FF6'') | datetime(a) |
| Convert.ToDecimal(a), decimal.Parse(a) | cast(a as decimal(36,18)) | cast(a as decimal(36,19)) | a::numeric | cast(a as number) | cast(a as decimal(36,18)) |
| Convert.ToDouble(a), double.Parse(a) | cast(a as decimal(32,16)) | cast(a as decimal(32,16)) | a::float8 | cast(a as number) | cast(a as double) |
| Convert.ToInt16(a), short.Parse(a) | cast(a as signed) | cast(a as smallint) | a::int2 | cast(a as number) | cast(a as smallint) |
| Convert.ToInt32(a), int.Parse(a) | cast(a as signed) | cast(a as int) | a::int4 | cast(a as number) | cast(a as smallint) |
| Convert.ToInt64(a), long.Parse(a) | cast(a as signed) | cast(a as bigint) | a::int8 | cast(a as number) | cast(a as smallint) |
| Convert.ToSByte(a), sbyte.Parse(a) | cast(a as signed) | cast(a as tinyint) | a::int2 | cast(a as number) | cast(a as smallint) |
| Convert.ToString(a) | cast(a as decimal(14,7)) | cast(a as decimal(14,7)) | a::float4 | to_char(a) | cast(a as character) |
| Convert.ToSingle(a), float.Parse(a) | cast(a as char) | cast(a as nvarchar) | a::varchar | cast(a as number) | cast(a as smallint) |
| Convert.ToUInt16(a), ushort.Parse(a) | cast(a as unsigned) | cast(a as smallint) | a::int2 | cast(a as number) | cast(a as unsigned) |
| Convert.ToUInt32(a), uint.Parse(a) | cast(a as unsigned) | cast(a as int) | a::int4 | cast(a as number) | cast(a as decimal(10,0)) |
| Convert.ToUInt64(a), ulong.Parse(a) | cast(a as unsigned) | cast(a as bigint) | a::int8 | cast(a as number) | cast(a as decimal(21,0)) |
| Guid.Parse(a) | substr(cast(a as char),1,36) | cast(a as uniqueidentifier) | a::uuid | substr(to_char(a),1,36) | substr(cast(a as character),1,36) |
| Guid.NewGuid() | - | newid() | - | - | - |
| new Random().NextDouble() | rand() | rand() | random() | dbms_random.value | random() |
CodeFirst
| 参数选项 | 说明 |
|---|---|
| IsAutoSyncStructure | 【开发环境必备】自动同步实体结构到数据库,程序运行中检查实体表是否存在,然后创建或修改 |
| IsSyncStructureToLower | 转小写同步结构 |
| IsSyncStructureToUpper | 转大写同步结构,适用 Oracle |
| IsConfigEntityFromDbFirst | 使用数据库的主键和自增,适用 DbFirst 模式,无须在实体类型上设置 [Column(IsPrimary)] 或者 ConfigEntity。此功能目前可用于 mysql/sqlserver/postgresql。 |
| IsNoneCommandParameter | 不使用命令参数化执行,针对 Insert/Update,调试神器 |
| IsLazyLoading | 延时加载导航属性对象,导航属性需要声明 virtual |
1、配置实体(特性)
public class Song {
[Column(IsIdentity = true)]
public int Id { get; set; }
public string Title { get; set; }
public string Url { get; set; }
public virtual ICollection<Tag> Tags { get; set; }
[Column(IsVersion = true)]
public long versionRow { get; set; }
}2、在外部配置实体
fsql.CodeFirst
.ConfigEntity<Song>(a => {
a.Property(b => b.Id).IsIdentity(true);
a.Property(b => b.versionRow).IsVersion(true);
});DbFirst
1、获取所有数据库
fsql.DbFirst.GetDatabases();
//返回字符串数组, ["cccddd", "test"]2、获取指定数据库的表信息
fsql.DbFirst.GetTablesByDatabase(fsql.DbFirst.GetDatabases()[0]);
//返回包括表、列详情、主键、唯一键、索引、外键、备注等信息3、生成实体
new FreeSql.Generator.TemplateGenerator()
.Build(fsql.DbFirst,
@"C:\Users\28810\Desktop\github\FreeSql\Templates\MySql\simple-entity",
//模板目录(事先下载)
@"C:\Users\28810\Desktop\你的目录",
//生成后保存的目录
"cccddd"
//数据库
);高级篇
Repository 仓储实现
1、单个仓储
var curd = fsql.GetRepository<Xxx, int>();
//curd.Find(1);
var item = curd.Get(1);
curd.Update(item);
curd.Insert(item);
curd.Delete(1);
curd.Select.Limit(10).ToList();2、工作单元
using (var uow = fsql.CreateUnitOfWork()) {
var songRepos = uow.GetRepository<Song>();
var userRepos = uow.GetRepository<User>();
//上面两个仓储,由同一UnitOfWork uow 创建
//在此执行仓储操作
//这里不受异步方便影响
uow.Commit();
}3、局部过滤器 + 数据验证
var topicRepository = fsql.GetGuidRepository<Topic>(a => a.UserId == 1);之后在使用 topicRepository 操作方法时:
- 查询/修改/删除时附过滤条件,从而达到不会修改其他用户的数据;
- 添加时,使用过滤条件验证合法性,若不合法则抛出异常;如以下方法就会报错:
topicRepository.Insert(new Topic { UserId = 2 })4、乐观锁
更新实体数据,在并发情况下极容易造成旧数据将新的记录更新。FreeSql 核心部分已经支持乐观锁。
乐观锁的原理,是利用实体某字段,如:long version,更新前先查询数据,此时 version 为 1,更新时产生的 SQL 会附加 where version = 1,当修改失败时(即 Affrows == 0)抛出异常。
每个实体只支持一个乐观锁,在属性前标记特性:[Column(IsVersion = true)] 即可。
无论是使用 FreeSql/FreeSql.Repository/FreeSql.DbContext,每次更新 version 的值都会增加 1
5、DbContext
dotnet add package FreeSql.DbContext
实现类似 EFCore 使用方法,跟踪对象状态,最终通过 SaveChanges 方法以事务的方式提交整段操作。
using (var ctx = new SongContext()) {
var song = new Song { BigNumber = "1000000000000000000" };
ctx.Songs.Add(song);
song.BigNumber = (BigInteger.Parse(song.BigNumber) + 1).ToString();
ctx.Songs.Update(song);
var tag = new Tag {
Name = "testaddsublist",
Tags = new[] {
new Tag { Name = "sub1" },
new Tag { Name = "sub2" },
new Tag {
Name = "sub3",
Tags = new[] {
new Tag { Name = "sub3_01" }
}
}
}
};
ctx.Tags.Add(tag);
ctx.SaveChanges();
}
public class Song {
[Column(IsIdentity = true)]
public int Id { get; set; }
public string BigNumber { get; set; }
[Column(IsVersion = true)] //乐观锁
public long versionRow { get; set; }
}
public class Tag {
[Column(IsIdentity = true)]
public int Id { get; set; }
public int? Parent_id { get; set; }
public virtual Tag Parent { get; set; }
public string Name { get; set; }
public virtual ICollection<Tag> Tags { get; set; }
}
public class SongContext : DbContext {
public DbSet<Song> Songs { get; set; }
public DbSet<Tag> Tags { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder builder) {
builder.UseFreeSql(fsql);
}
}导航属性
支持 1对1、1对多、多对1、多对多 的约定导航属性配置,主要用于表达式内部查询;
//OneToOne、ManyToOne
var t0 = fsql.Select<Tag>().Where(a => a.Parent.Parent.Name == "粤语").ToList();
//OneToMany
var t1 = fsql.Select<Tag>().Where(a => a.Tags.AsSelect().Any(t => t.Parent.Id == 10)).ToList();
//ManyToMany
var t2 = fsql.Select<Song>().Where(s => s.Tags.AsSelect().Any(t => t.Name == "国语")).ToList();不朽篇
读写分离
数据库读写分离,本功能是客户端的读写分离行为,数据库服务器该怎么配置仍然那样配置,不受本功能影响,为了方便描术后面讲到的【读写分离】都是指客户端的功能支持。
各种数据库的读写方案不一,数据库端开启读写分离功能后,读写分离的实现大致分为以下几种:
1、nginx代理,配置繁琐且容易出错;
2、中件间,如MyCat,MySql可以其他数据库怎么办?
3、在client端支持;
FreeSql 实现了第3种方案,支持一个【主库】多个【从库】,【从库】的查询策略为随机方式。
若某【从库】发生故障,将切换到其他可用【从库】,若已全部不可用则使用【主库】查询。
出现故障【从库】被隔离起来间隔性的检查可用状态,以待恢复。
IFreeSql fsql = new FreeSql.FreeSqlBuilder()
.UseConnectionString(FreeSql.DataType.MySql, connstr)
.UseSlave("connectionString1", "connectionString2")
//使用从数据库,支持多个
.Build();
select.Where(a => a.Id == 1).ToOne();
//读【从库】(默认)
select.Master().WhereId(a => a.Id == 1).ToOne();
//强制读【主库】下面是以前某项目的测试图片,以供参考,整个过程无感切换和恢复:


分区分表
FreeSql 提供 AsTable 分表的基础方法,GuidRepository 作为分存式仓储将实现了分表与分库(不支持跨服务器分库)的封装。
var logRepository = fsql.GetGuidRepository<Log>(null, oldname => $"{oldname}_{DateTime.Now.ToString("YYYYMM")}");上面我们得到一个日志仓储按年月分表,使用它 CURD 最终会操作 Log_201903 表。
合并两个仓储,实现分表下的联表查询:
fsql.GetGuidRepository<User>().Select.FromRepository(logRepository)
.LeftJoin<Log>(b => b.UserId == a.Id)
.ToList();租户
1、按租户字段区分
FreeSql.Repository 现实了 filter(过滤与验证)功能,如:
var topicRepos = fsql.GetGuidRepository<Topic>(t => t.TerantId == 1);使用 topicRepos 对象进行 CURD 方法:
- 在查询/修改/删除时附加此条件,从而达到不会修改 TerantId != 1 的数据;
- 在添加时,使用表达式验证数据的合法性,若不合法则抛出异常;
利用这个功能,我们可以很方便的实现数据分区,达到租户的目的。
2、按租户分表
FreeSql.Repository 现实了 分表功能,如:
var tenantId = 1;
var reposTopic = orm.GetGuidRepository<Topic>(null, oldname => $"{oldname}{tenantId}");上面我们得到一个仓储按租户分表,使用它 CURD 最终会操作 Topic_1 表。
3、按租户分库
与方案二相同,只是表存储的位置不同。
4、全局设置
通过注入的方式设置仓储类的全局过滤器。
public void ConfigureServices(IServiceCollection services) {
services.AddMvc();
services.AddSingleton<IFreeSql>(Fsql);
services.AddFreeRepository(filter => {
var tenantId = 求出当前租户id;
filter
.Apply<ISoftDelete>("softdelete", a => a.IsDeleted == false)
.Apply<ITenant>("tenant", a => a.TenantId == tenantId)
}, this.GetType().Assembly
);
}结束语
这次全方位介绍 FreeSql 的功能,只抽取了重要内容发布,由于功能实在太多不方便在一篇文章介绍祥尽。
我个人是非常想展开编写,将每个功能的设计和实现放大来介绍,但还是先希望得到更多人的关注,不然就是一台独角戏了。
gayhub: https://github.com/2881099/FreeSql,肯请献上宝贵的一星,谢谢!

.NET版Word处理控件Aspose.Words功能演示:从C#.NET中的模板生成Word文档
Word文档的自动生成已被企业广泛用于创建大量报告。在某些情况下,文档是从头开始创建的。另一方面,预定义的模板用于通过填充占位符来生成Word文档。
在本文中,我将演示如何在C#中以动态方式和编程方式从模板生成Word文档。将了解如何从不同类型的数据源填充Word模板。本文将介绍以下方案以及代码示例:
- 使用C#对象的值从模板生成Word文档。
- 使用XML数据源生成Word文档。
- 使用JSON数据源生成Word文档。
- 使用CSV数据源生成Word文档。
Aspose.Words for .NET已升级至最新版本,如果你还没有用过Aspose.Words可以点击这里下载最新版 https://www.evget.com/product/564/download
https://www.evget.com/product/564/download
使用C#对象从模板生成Word文档
首先,让我们看看如何使用C#对象填充Word模板。为此,我们将创建一个Word文档(DOC / DOCX),该文档具有以下占位符作为文档的内容:
<<[sender.Name]>> says: "<<[sender.Message]>>."
在这里,发送者是以下类的对象,我们将使用该类来填充模板。
public class Sender { public string Name { get; set; } public string Message { get; set; } public Sender (string _name, string _message) { Name = _name; Message = _message; } }
现在,我们将使用Aspose.Words的报告引擎,按照以下步骤从Sender类的模板和对象生成Word文档。
- 创建Document类的对象,并使用Word模板的路径对其进行初始化。
- 创建并初始化Sender类的对象。
- 创建ReportingEngine类的对象。
- 使用ReportingEngine.BuildReport()填充模板,该模板将Document的对象,数据源和数据源的名称作为参数。
- 使用Document.Save()方法保存生成的Word文档。
下面的代码示例演示如何从C#中的模板生成Word文档。
Document doc = new Document("template.docx"); Sender sender = new Sender("LINQ Reporting Engine", "Hello World"); ReportingEngine engine = new ReportingEngine(); engine.BuildReport(doc, sender, "sender"); doc.Save("word.docx");
输出结果

从C#中的XML数据源生成Word文档
为了从XML数据源生成Word文档,我们将使用带有以下占位符的更为复杂的Word模板:
<>Name: <<[Name]>>, Age: <<[Age]>>, Date of Birth: <<[Birth]:"dd.MM.yyyy">> <> Average age: <<[persons.Average(p => p.Age)]>>
下面给出了我在此示例中使用的XML数据源。
| <Persons> | |
| <Person> | |
| <Name>John DoeName> | |
| <Age>30Age> | |
| <Birth>1989-04-01 4:00:00 pmBirth> | |
| Person> | |
| <Person> | |
| <Name>Jane DoeName> | |
| <Age>27Age> | |
| <Birth>1992-01-31 07:00:00 amBirth> | |
| Person> | |
| <Person> | |
| <Name>John SmithName> | |
| <Age>51Age> | |
| <Birth>1968-03-08 1:00:00 pmBirth> | |
| Person> | |
| Persons> |
以下是从XML数据源生成Word文档的步骤:
- 创建Document类的实例,并使用Word模板的路径对其进行初始化。
- 创建XmlDataSource类的实例,并使用XML文件的路径对其进行初始化。
- 创建ReportingEngine类的实例。
- 以与之前填充Word模板相同的方式使用ReportingEngine.BuildReport()方法。
- 使用Document.Save()方法保存生成的Word文档。
下面的代码示例演示如何从C#中的XML数据源生成Word文档。
Document doc = new Document("template.docx"); XmlDataSource dataSource = new XmlDataSource("datasource.xml"); ReportingEngine engine = new ReportingEngine(); engine.BuildReport(doc, dataSource, "persons"); doc.Save("word.docx");
输出结果

在C#中从JSON数据源生成Word文档
现在,让我们看看如何使用JSON数据源生成Word文档。在此示例中,我们将生成按其经理分组的客户列表。在这种情况下,以下为Word模板:
<>Manager: <<[Name]>> Contracts: <>- <<[Client.Name]>> ($<<[Price]>>) <> <>
以下是我们将用来填充模板的JSON数据源:
| [ | |
| { | |
| 姓名:“约翰史密斯”, | |
| 合同: | |
| [ | |
| { | |
| 客户: | |
| { | |
| 姓名:“一家公司” | |
| }, | |
| 价格:1200000 | |
| }, | |
| { | |
| 客户: | |
| { | |
| 姓名:“ B有限公司” | |
| }, | |
| 价钱:750000 | |
| }, | |
| { | |
| 客户: | |
| { | |
| 姓名:“ C&D ” | |
| }, | |
| 价钱:350000 | |
| } | |
| ] | |
| }, | |
| { | |
| 姓名:“托尼安德森”, | |
| 合同: | |
| [ | |
| { | |
| 客户: | |
| { | |
| 名称:“ E Corp. ” | |
| }, | |
| 价钱:650000 | |
| }, | |
| { | |
| 客户: | |
| { | |
| 姓名:“ F&Partners ” | |
| }, | |
| 价钱:550000 | |
| } | |
| ] | |
| }, | |
| ] |
以下是从XML数据源生成Word文档的步骤:
- 创建Document类的实例,并使用Word模板的路径对其进行初始化。
- 创建XmlDataSource类的实例,并使用XML文件的路径对其进行初始化。
- 创建ReportingEngine类的实例。
- 以与之前填充Word模板相同的方式使用ReportingEngine.BuildReport()方法。
- 使用Document.Save()方法保存生成的Word文档。
为了从JSON生成Word文档,我们将使用JsonDataSource类加载和使用JSON数据源,其余步骤将保持不变。下面的代码示例演示如何使用C#中的JSON从模板生成Word文档。
Document doc = new Document("template.docx"); JsonDataSource dataSource = new JsonDataSource("datasource.json"); ReportingEngine engine = new ReportingEngine(); engine.BuildReport(doc, dataSource, "managers"); doc.Save("word.docx");
输出结果

在C#中从CSV数据源生成Word文档
为了从CSV生成Word文档,我们将使用以下Word模板:
<>Name: <<[Column1]>>, Age: <<[Column2]>>, Date of Birth: <<[Column3]:"dd.MM.yyyy">> <> Average age: <<[persons.Average(p => p.Column2)]>>下面给出了我在此示例中使用的XML数据源。

现在,让我们来看一下C#代码。除了一个更改,我们将使用CsvDataSource类加载CSV数据,此处所有步骤都将保持不变。下面的代码示例演示如何从CSV数据源生成Word文档。
Document doc = new Document("template.docx"); CsvDataSource dataSource = new CsvDataSource("datasource.csv"); ReportingEngine engine = new ReportingEngine(); engine.BuildReport(doc, dataSource, "persons"); doc.Save("word.docx");
输出结果


ASP.NET Core扩展库的相关功能介绍
亲爱的.Neter们,在我们日复一日的编码过程中是不是会遇到一些让人烦恼的事情:
- 日志配置太过复杂,各种模板、参数也搞不清楚,每次都要去查看日志库的文档,还需要复制粘贴一些重复代码,好无赖
- 当需要类型转换时,使用AutoMapper时感觉配置又复杂,自己写人肉转换代码又冗长,又枯燥,好无聊
- 当调用其他服务时,总是不放心,于是在调用前、调用后总是不断重复地记录请求和应答日志?
- 当其他服务需要令牌时,我们不得不管理令牌的生命周期,而且不同第三方服务令牌的认证、维护过程还不一样,有时调用每一个接口时都要手动传入token,好麻烦
- 作为应用开发的你,你编写的服务和很多其他服务交互,经常因为其他服务的问题影响你的开发进度,同时你的服务由于依赖于其他服务,导致调试测试困难
- 在微服务模式下,需要请求链路跟踪,于是,你又在调用其他服务时,不断第重复传递链路跟踪的请求头
- 作为APIer的你,为了快速查找问题,不得不记录每一个接口的请求和应答内容,于是,你就在控制器里面增加了一堆的日志,你知道这不科学,但时间紧,任务重,就先这样吧
- ......
也许,以上这些问题,都有相应的库或者示例代码来解决,但这实在是太零散了,我们没有精力或不想去做这些,所以结果是常常我们采用了最“笨”的办法。
现在,解决这些问题的综合库来了,它就是Xfrogcn.AspNetCore.Extensions扩展库,它深度融合ASP.NET Core的设计模式,使用方式与ASP.NET Core完全一致。
简介
ASP.NET Core扩展库是针对.NET Core常用功能的扩展,包含日志、Token提供器、并行队列处理、HttpClient扩展、轻量级的DTO类型映射等功能。
源码地址:[GitHub] [Gitee]
包地址:[NuGet]
日志扩展
扩展库中,我们对Serilog日志库进行了简单的封装使其更加容易配置,同时也增强了本地文件日志Sink,使其支持更复杂的日志目录结构。另外,定时日志清理功能可让你无需关心本地日志管理问题。
轻量级实体映射
在分层设计模式中,各层之间的数据通常通过数据传输对象(DTO)来进行数据的传递,而大多数情况下,各层数据的定义结构大同小异,如何在这些定义结构中相互转换,之前我们通过使用AutoMapper库,但AutoMapper功能庞大,在很多场景下,可能我们只需要一些基础功能,那么此时你可以选择扩展库中的轻量级AutoMapper实现。
AspNetCore Http服务端的扩展
针对AspNetCore Http服务端,扩展库提供了以下功能:
- 请求与应答详细日志记录
- EnableBufferingAttribute特性,开启请求的Buffer(可重复读取)
HttpClient扩展
.NET Core扩展库中通过HttpFactory及HttpClient来执行HTTP请求调用,HttpClient扩展在此基础上进行了更多功能的扩展,增加易用性、可测试性。
HttpClient包含以下功能:
- 针对HttpClient的相关扩展方法
- 针对HttpRequestMessage及HttpResponseMessage的扩展方法
- 请求日志记录
- 请求头的自动传递(请求链路跟踪)
- Http请求模拟(用于测试或模拟第三方服务)
- Http受限请求中,可自动获取及管理访问令牌
令牌提供器
令牌提供器用于应用的相关访问令牌的生命周期管理,包含令牌的自动获取、缓存、失效判断、自动重试等,主要由HttpClient扩展使用。当然你也可以单独使用。
并行队列处理
并行队列处理可以将一个大的队列,拆分到多个子队列进行并行处理,以提高处理效率。同时,在每个子队列处理中实现了处理管道,可灵活扩展。
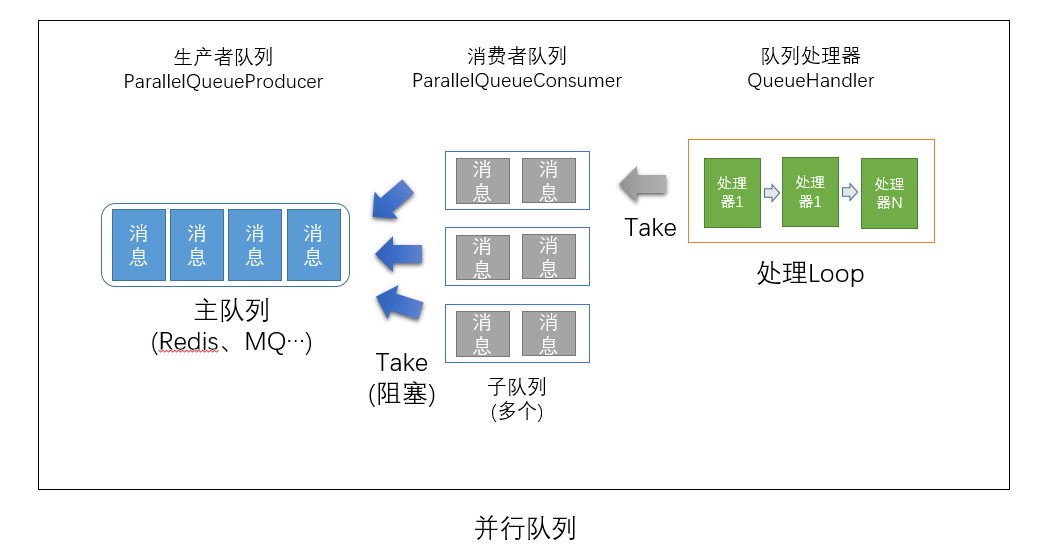
以上介绍即为扩展库所支持的功能,后面会有相关的系列文章进行详细介绍。
以上就是ASP.NET Core扩展库的相关功能介绍的详细内容,更多关于ASP.NET Core扩展库的资料请关注其它相关文章!
- ASP.NET Core Api网关Ocelot的使用初探
- ASP.NET Core扩展库之日志功能的使用详解
- 在ASP.NET Core中用HttpClient发送POST, PUT和DELETE请求
- ASP.NET Core WebApi版本控制的实现
- ASP.NET Core对不同类型的用户进行区别限流详解
- 详解如何在ASP.NET Core中编写高效的控制器
- 详解如何在ASP.NET Core中使用IHttpClientFactory
- ASP.NET Core 使用Cookie验证身份的示例代码
- 如何在ASP.Net Core使用分布式缓存的实现
- ASP.NET Core快速入门之实战篇
关于机器学习组件Accord.NET框架功能介绍的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.NET 开发框架 (二)- 框架功能简述、.NETCore 新型 ORM 功能介绍、.NET版Word处理控件Aspose.Words功能演示:从C#.NET中的模板生成Word文档、ASP.NET Core扩展库的相关功能介绍等相关知识的信息别忘了在本站进行查找喔。
本文标签:




