如果您想了解Java中的HashMap实现。桶索引计算如何工作?和javahashmapsort的知识,那么本篇文章将是您的不二之选。我们将深入剖析Java中的HashMap实现。桶索引计算如何工作?
如果您想了解Java中的HashMap实现。桶索引计算如何工作?和java hashmap sort的知识,那么本篇文章将是您的不二之选。我们将深入剖析Java中的HashMap实现。桶索引计算如何工作?的各个方面,并为您解答java hashmap sort的疑在这篇文章中,我们将为您介绍Java中的HashMap实现。桶索引计算如何工作?的相关知识,同时也会详细的解释java hashmap sort的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- Java中的HashMap实现。桶索引计算如何工作?(java hashmap sort)
- HashMap 索引计算
- HashMap如何在Java中工作?
- Hashset,Treeset和LinkedHashset,Hashmap之间的主要区别是什么?它在Java中如何工作?
- java – weakhashmap如何工作?
")
Java中的HashMap实现。桶索引计算如何工作?(java hashmap sort)
我正在研究HashMapJava 的实现,只停留在一点。
该indexFor函数如何计算?
static int indexFor(int h, int length) { return h & (length-1);}谢谢
答案1
小编典典它不是在计算 哈希 ,而是在计算 存储桶 。
表达h &(length-1)确实逐位AND上h使用length-1,这是像一个位掩码,以便仅返回的低位比特h,从而使得对于一个超高速变体h %length。

HashMap 索引计算
从HashMap源码中,可以看到求容器下标值的方法,有两步,首先通过key值计算hash,然后用hash计算下标:
计算hash:
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
计算下标,其下标值为:(n-1) & hash
n = (tab = resize()).length;
p = tab[i = (n - 1) & hash]
即,是通过key的hash值和容器的大小减1,两者进行与运算,获取容器数组下标。这里使用与运算,其实蕴含了一个隐藏条件,即数组的大小n,必须是2的n次方,否则,计算出来的下标值i是无法覆盖这个范围[0, n-1]的。
举个例子,假设两种情况,一种容器大小为10,不是2的幂,另外一种容器大小为16,刚好是2的4次方。
则,对于第一种,n-1= 9, 二进制表示为 1001,任何值与该值进行与运算,都无法改变中间的两个0,只能改变首尾的两个1,因此结果范围就缩小了一倍
而,对于第二种,n-1=15,二进制表示为 1111,该值与其他值与运算后,可以覆盖范围[0, 15],而这个范围刚好是数组的大小,因此只要hash值均匀分布,结果也是均匀的。
实际上,只要数组大小是2的幂,则 (n-1) & hash 的结果等效于: hash % (n-1);即与运算、求余运算通过这个前提,实现了等效。
而计算机中,与运算和求余运算,两个计算的效率肯定是前者更好。因为与运算,是直接对位进行逻辑与操作,属于cpu的底层支持的基础逻辑操作,但是求余运算可不是,应该是需要额外的算术运算单元支持的。可能这就是把数组大小规定为2的幂的原因之一,提高运算效率。
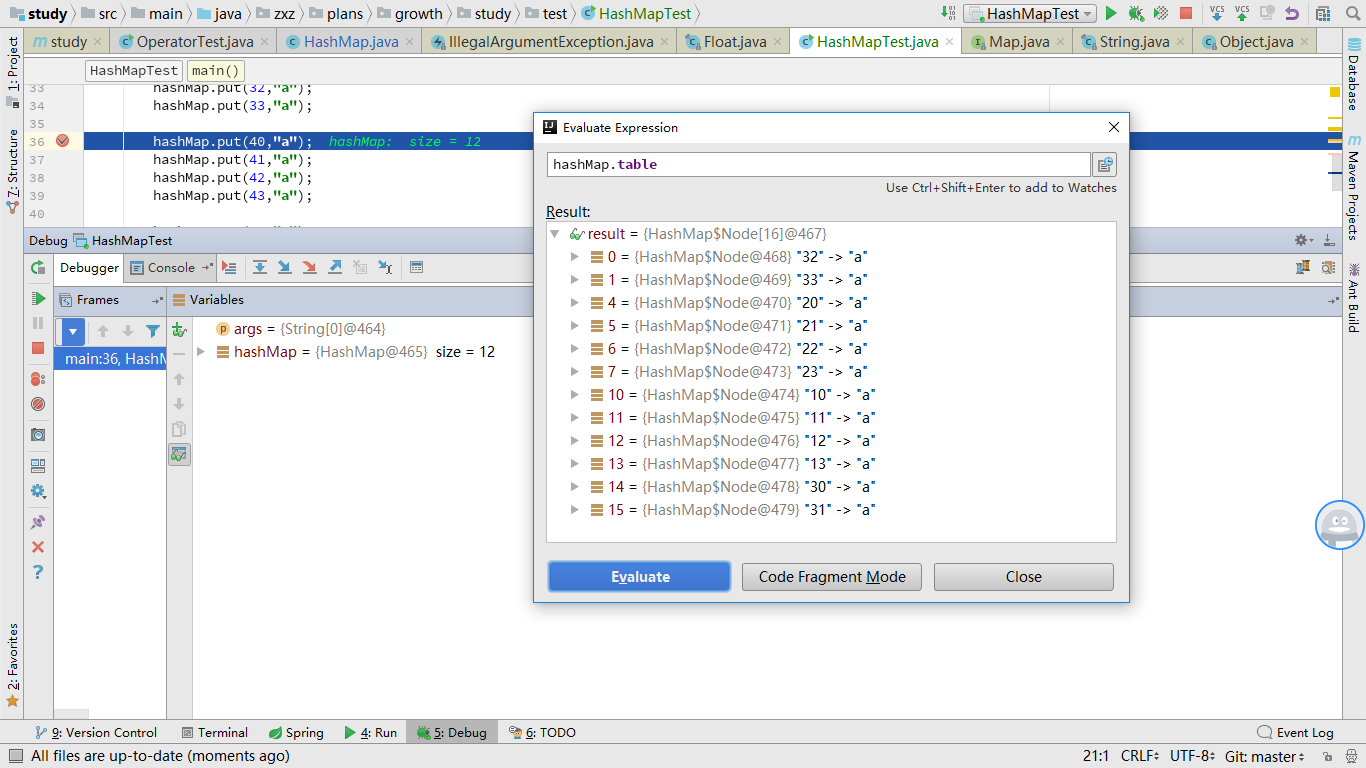
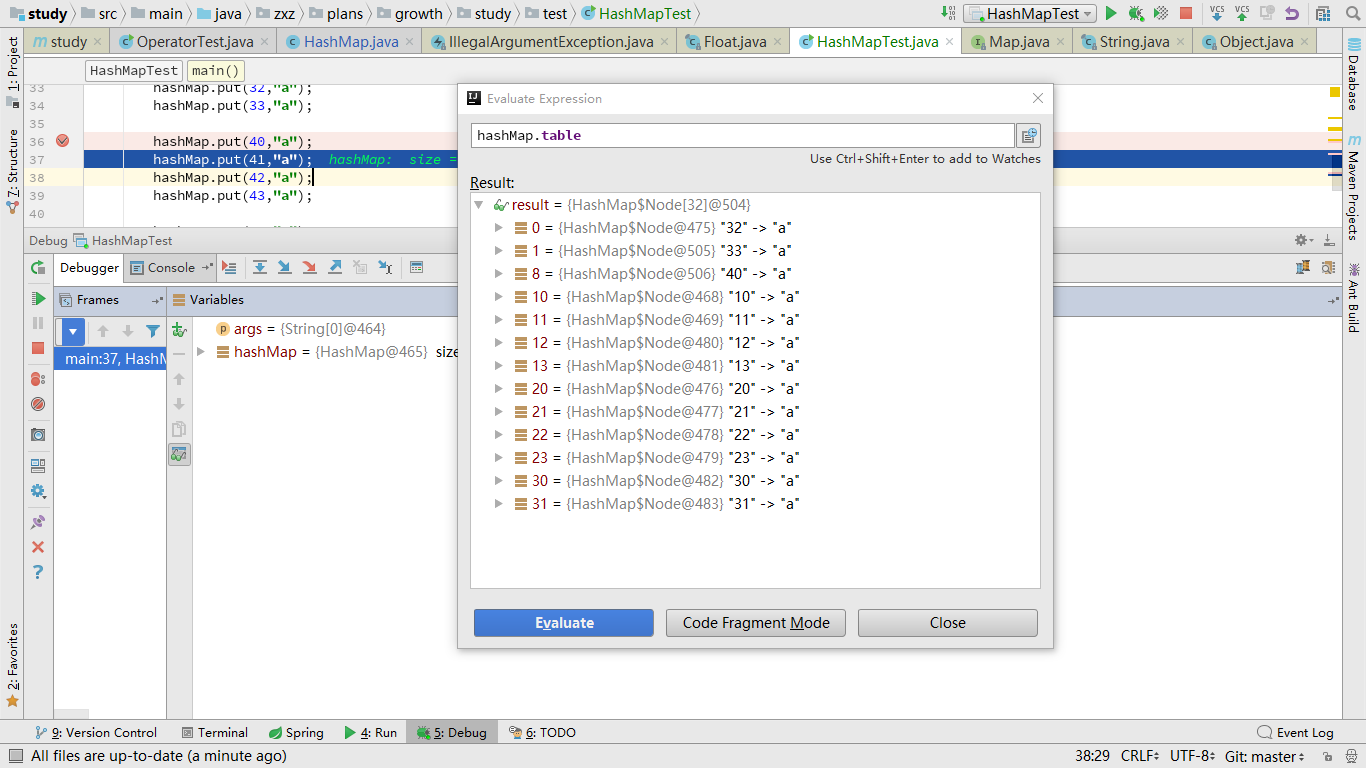
附注:这里额外补充一点,即HashMap的扩容机制,涉及到的参数有容器大小,负载因子,当实际数据的数量,超过两者的乘积时,就触发扩容,直接放大一倍。比如原本容器大小为16,负载因子为0.75(默认的),当放入的数据个数从12变为13时,则容器大小扩大为32. 扩容时,原本元素的位置也会发生改变,但是这种改变是有规律的,有一些是不变,而发生改变的,则刚好都是在原来数组索引的基础上,加上扩大的数量值(在该例子中就是加上16)。
这个我没有看源码,是直接根据上面的索引计算方式推断出来的,试验结果也证明确实如此。
扩容前:
扩容后:

HashMap如何在Java中工作?
通过优锐课学习笔记分享,我们可以看到HashMap问题在工作面试中很常见。 这也是HashMaps在Java内部如何工作的一些深入说明,分享给大家参考学习。
HashMap在内部如何工作已成为几乎所有访谈中的一个普遍问题。 几乎每个人都知道如何使用HashMap或HashMap与Hashtable之间的区别。 但是,当问题为“ HashMap如何在内部工作?”时,许多人会失败。
这个问题的答案是,它基于哈希原理工作,但听起来并不那么简单。 哈希是一种使用算法将唯一代码分配给变量或属性的机制,从而可以轻松进行检索。 真正的哈希机制在应用于同一对象时应始终返回相同的hashCode()。
然后是一个问题:“哈希如何帮助存储和检索HashMap中的值?” 许多人会说该值将存储在存储桶中,并使用键进行检索。 如果你认为这是有效的,那么你绝对是错误的。 为了证明这一点,让我们看一下HashMap类:
1 /**
2
3 * The table, resized as necessary. Length MUST Always be a power of two.
4
5 */
6
7 transient Entry[] table;
那么HashMap中Entry []的用途是什么? HashMap将对象存储为Entry实例,而不是键和值。
什么是入门班?
HashMap有一个称为Entry Class的内部类,其中包含键和值。 还有一个叫做next的东西,稍后您将了解。
1 static class Entry<K,V> implements Map.Entry<K,V>
2
3 {
4
5 final K key;
6
7 V value;
8
9 Entry<K,V> next;
10
11 final int hash;
12
13 ........
14
15 }
你知道HashMap将Entry实例存储在数组中,而不是作为键值对存储。 为了存储值,你将使用HashMap的put()方法。 让我们深入研究一下,看看它是如何工作的。
Put()方法如何在内部工作?
该代码将如下所示:
1 public V put(K key, V value)
2
3 {
4
5 if (key == null)
6
7 return putForNullKey(value);
8
9 int hash = hash(key.hashCode());
10
11 int i = indexFor(hash, table.length);
12
13 for (Entry<K,V> e = table[i]; e != null; e = e.next)
14
15 {
16
17 Object k;
18
19 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
20
21 {
22
23 V oldValue = e.value;
24
25 e.value = value;
26
27 e.recordAccess(this);
28
29 return oldValue;
30
31 }
32
33 }
34
35 modCount++;
36
37 addEntry(hash, key, value, i);
38
39 return null;
40
41 }
首先,它检查给定的密钥是否为null。如果给定键为null,则它将存储在零位置,因为null的哈希码将为零。
然后通过调用hashcode方法将哈希码应用于键.hashCode()。为了在数组范围内获得值,调用了hash(key.hashCode()),它对哈希码执行一些移位操作。
indexFor()方法用于获取存储Entry对象的确切位置。
接下来是最重要的部分-如果两个不同的对象具有相同的哈希码(例如Aa和BB将具有相同的哈希码),它将存储在同一存储桶中吗?为了解决这个问题,让我们考虑一下数据结构中的LinkedList。它将具有“下一个”属性,该属性将始终指向下一个对象,与Entry类中的下一个属性指向下一个对象的方式相同。使用这种方法,具有相同哈希码的不同对象将彼此相邻放置。
对于Collision,HashMap检查下一个属性的值。如果为null,则将Entry对象插入该位置。如果下一个属性不为null,则它将保持循环运行,直到下一个属性为null,然后将Entry对象存储在那里。
如何在HashMap中防止重复密钥?
众所周知,HashMap不允许重复键,即使当我们插入具有不同值的相同键时,也仅返回最新值。
1 import java.util.HashMap;
2
3 import java.util.Map;
4
5 public class HashMapEg {
6
7 public static void main(String[] args) {
8
9 Map map = new HashMap();
10
11 map.put(1, "sam");
12
13 map.put(1, "Ian");
14
15 map.put(1, "Scott");
16
17 map.put(null, "asdf");
18
19 System.out.println(map);
20
21 }
22
23 }
对于上面的代码,您将获得输出{null = asdf,1 = Scott},因为值sam和Ian将被替换为Scott。 那么,这是怎么发生的呢?
LinkedList中的所有Entry对象将具有相同的哈希码,但是HashMap使用equals()。 此方法检查相等性,因此如果key.equals(k)为true,它将替换Entry类中的值对象而不是键。 这样,可以防止插入重复密钥。
Get()方法如何在内部工作?
将使用put()方法中几乎相同的逻辑来检索值。
1 public V get(Object key)
2
3 {
4
5 if (key == null)
6
7 return getForNullKey();
8
9 int hash = hash(key.hashCode());
10
11 for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next)
12
13 {
14
15 Object k;
16
17 if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
18
19 return e.value;
20
21 }
22
23 return null;
24
25 }
26
27 1,First, it gets the hash code of the key object, which is passed, and finds the bucket location.
28
29 2,If the correct bucket is found, it returns the value.
30
31 3,If no match is found, it returns null.
32
33
如果两个键具有相同的Hashcode会发生什么?
此处将使用相同的冲突解决机制。 key.equals(k)将一直检查到它为true,如果为true,则返回它的值。
我希望本文能阐明麻烦的HashMap内部机制。 祝大家学习愉快!如有不足之处,欢迎补充评论。
抽丝剥茧,细说架构那些事--优锐课

Hashset,Treeset和LinkedHashset,Hashmap之间的主要区别是什么?它在Java中如何工作?
我只知道LinkedHashSet插入时不允许重复的元素。但是,我不了解Hashset在Hava中如何工作?我知道哈希表中使用了哈希表,因此哈希表用于存储元素,这里也不允许重复的元素。然后,Treeset也类似于Hashset,它也不允许重复的条目,因此将看到唯一的元素,并且遵循升序。
关于HashMap,我还有一个疑问-
Hashmap不维护顺序。它可能具有一个null键和多个null值。我只是不明白这一点,这实际上意味着什么?有什么实际的例子吗?
我知道一点,Hashmap曾经基于此工作-
用于存储桶的键和值也具有唯一编号。这样就可以识别并从存储桶中获取键和值。当我将键/值对放在标识符为键的哈希码的存储桶中时。
例如:密钥的哈希码为101,因此将其存储在存储桶101中。一个存储桶可以存储多于键和值对。假设举个例子,对象1是“ A”,对象2是“ A”,对象3是“
B”,那么它具有相同的哈希码。因此,它通过在同一存储桶中共享相同的哈希码来存储不同的对象。我的疑问是,具有相同哈希码的对象应该相等,而不同对象应该具有不同的哈希码?
这是使用HashSet的程序:
import java.util.*; public class Simple{ public static void main(String[] args){ HashSet hh=new HashSet(); hh.add("D"); hh.add("A"); hh.add("B"); hh.add("C"); hh.add("a"); System.out.println("Checking the size is:"+hh.size()+""); System.out.println(hh); Iterator i=hh.iterator(); while(i.hasNext()){ System.out.println(i.next()); } } }输出是
Checking the size is:5[D, A, B, a, C]DABaC我的疑问是,为什么在“ B”和“ C”之间插入“ a”。
现在,我正在使用LinkedHashSet,
public class Simple{public static void main(String[] args){ LinkedHashSet hh=new LinkedHashSet(); hh.add("D"); hh.add("A"); hh.add("B"); hh.add("C"); hh.add("a"); System.out.println("Checking the size is:"+hh.size()+""); System.out.println(hh); Iterator i=hh.iterator(); while(i.hasNext()){ System.out.println(i.next()); } }}我只是理解,它遵循插入顺序,并且避免了重复的元素。所以输出是
Checking the size is:5[D, A, B, C, a]DABCa现在,使用树集:
import java.util.*;public class Simple{public static void main(String[] args){ TreeSet hh=new TreeSet(); hh.add("1"); hh.add("5"); hh.add("3"); hh.add("5"); hh.add("2"); hh.add("7");System.out.println("Checking the size is:"+hh.size()+"");System.out.println(hh); Iterator i=hh.iterator(); while(i.hasNext()){ System.out.println(i.next()); } }}在这里,我只知道-树集遵循升序。
The output is,Checking the size is:5[1, 2, 3, 5, 7]12357然后我的疑问是,哈希集如何在Java中工作?而且我知道LinkedHashset遵循双重链表。如果它使用双向链表,那么它将如何存储元素?双向链表是什么意思,它是如何工作的?那么在Java中将使用这三个Hashset,Treeset,LinkedHashset的哪一个在Java中具有更好的性能呢?
答案1
小编典典我的疑问是,为什么在“ B”和“ C”之间插入“ a”。
TreeSet对条目进行排序。
LinkedHashSet保留插入顺序。
HashSet不保留插入顺序,也不对条目进行排序/排序。这意味着,当您遍历集合时,将按难以理解的顺序返回条目,并且没有实际意义。此时没有"a"插入任何特定的“原因”
。事实就是如此……给定了一组输入键及其插入顺序。
我唯一的疑问是,哈希集如何在Java中工作。
它实现了一个哈希表。阅读哈希表上的Wikipedia页面,以获取一般概述以及的源代码java.util.HashMap和java.util.HashSet详细信息。
简短的回答是,HashSet和HashMap均作为哈希链阵列实现的哈希表。
而且我知道,LinkedHashset遵循双重链表。如果它使用双向链表,那么它将如何存储元素?
LinkedHashSet本质上是一个带有附加链表的哈希表,该链表记录了插入顺序。元素存储在主哈希表中……这就是提供快速查找的功能。同样,请参阅源代码以获取详细信息。
双向链表是什么意思,它是如何工作的?
阅读Wikipedia中的双向链接列表中的文章。
那么在Java中将使用这三个Hashset,Treeset,Linkedhashset的情况,哪个在Java中具有更好的性能呢?
在这三个类别(和其他类别)之间进行选择时,有很多事情要考虑:
他们是否提供所需的功能。例如,我们已经看到它们在迭代顺序方面有 不同的 行为。
它们是否具有必需的并发属性?例如,它们是线程安全的吗?他们处理争执吗?他们允许并发修改吗?
他们需要多少空间?
性能(时间)特征是什么?
关于最后两点?
A
TreeSet使用最少的空间,而ALinkedHashSet使用最多的空间。甲
HashSet趋于为最快的查找,插入和删除较大套,以及TreeSet往往是最慢的。

java – weakhashmap如何工作?
就像weakhashmap如何理解对其中一个键的引用现在已经过时,特别是如果键是一个汇集的String?
解决方法
String myKey = "somekey";
相反,你必须使用:
String myKey = new String("somekey");
在后一种情况下,String不会被合并.
关于Java中的HashMap实现。桶索引计算如何工作?和java hashmap sort的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于HashMap 索引计算、HashMap如何在Java中工作?、Hashset,Treeset和LinkedHashset,Hashmap之间的主要区别是什么?它在Java中如何工作?、java – weakhashmap如何工作?的相关知识,请在本站寻找。
本文标签:




