如果您对单词接龙最长——6.6——计算最长英语单词链和单词接龙算法题感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解单词接龙最长——6.6——计算最长英语单词链的各种细节,并对单词接龙算法题进行
如果您对单词接龙最长——6.6——计算最长英语单词链和单词接龙算法题感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解单词接龙最长——6.6——计算最长英语单词链的各种细节,并对单词接龙算法题进行深入的分析,此外还有关于#023单词接龙1(字符串)(女友)、(Java) LeetCode 127. Word Ladder —— 单词接龙、120. 单词接龙 (BFS)、2021-09-07:单词接龙 II。按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一的实用技巧。
本文目录一览:- 单词接龙最长——6.6——计算最长英语单词链(单词接龙算法题)
- #023单词接龙1(字符串)(女友)
- (Java) LeetCode 127. Word Ladder —— 单词接龙
- 120. 单词接龙 (BFS)
- 2021-09-07:单词接龙 II。按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一
")
单词接龙最长——6.6——计算最长英语单词链(单词接龙算法题)
题目要求:
大家经常玩成语接龙游戏,我们试一试英语的接龙吧:一个文本文件中有N 个不同的英语单词, 我们能否写一个程序,快速找出最长的能首尾相连的英语单词链,每个单词最多只能用一次。最长的定义是:最多单词数量,和单词中字母的数量无关。
例如, 文件里有:
Apple
Zoo
Elephant
Under
Fox
Dog
Moon
Leaf
Tree
Pseudopseudohypoparathyroidism
最长的相连英语单词串为: apple - elephant – tree, 输出到文件里面,是这样的:
Apple
Elephant
Tree
要求程序 (WordList.exe)能处理命令行参数,知道什么是输入文件, 输出文件应该放在哪里。 这样,当助教拿到学生的源程序后,就能编译,并运行一系列的测试。
Wordlist.exe /i input1.txt /o output1.txt
Wordlist.exe /i input2.txt /o output2.txt
…
既然是测试,就会有很多边角情况,例如,文件不存在,你的程序会崩溃么,还是能优雅地退出并给用户提示信息?如果文件没有任何单词、只有一个单词、没有可以首尾相连的单词,程序应该如何输出?
程序的正确性验证完毕后, 就可以用一些命令行计时工具来测试程序的效率。 当然,同学们也可以参考《构建之法》的介绍,自己先测试并改进程序的效率, 最好是先写一个朴素的算法,看看用时如何,再分析效率,改进,分析...
如果输入文件有一万个单词,你的程序能多快输出结果?课程助教会在同一个电脑上用一个大文件来测试所有同学的作业,请做好准备。自我想法:
1.读取文件
2.读取第一个单词
3.读取第一个单词的最后一个字母b
4.读取下一个首字母为刚才最后一个字母的单词并记录其为第n个
5.循环至没有重复
6.从第一个单词到第n个单词循环2-5的步骤
以下是我从各种途径收集整合的代码,如有相似的,就当是我抄的他的
package text6_6;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Onebyone {
public static void main(String[] args) throws IOException
{
// TODO 自动生成的方法存根
String filename ="input1.txt";
File a=new File(filename);
File file=new File("output1.txt");
long startTime = System.currentTimeMillis();
//judeFileExists(a);
if(judeFileExists(a))
{
danci(filename);
}
else
{
try {
FileWriter fw =new FileWriter(file);
fw.write("文件不存在");
fw.flush();
fw.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis(); //获取结束时间
}
public static void danci(String s) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(s));
StringBuffer sb = new StringBuffer();
String text = null;
while ((text = br.readLine()) != null) {
sb.append(text); // 将读取出的字符追加到stringbuffer中
}
br.close(); // 关闭读入流
String str = sb.toString().toLowerCase(); // 将stringBuffer转为字符并转换为小写
String[] words = str.split("[^(a-zA-Z)]+"); // 非单词的字符来分割,得到所有单词
StringBuffer yao = new StringBuffer();
String b1=words[0];
yao.append(b1);
yao.append(" ");
if(b1.equals(""))
{
System.out.println("文件为空");
yao.append("文件为空");
}
else
{
if(words.length==1)
{
System.out.println("该文件只有一个单词");
}
String end=b1.substring(b1.length()-1,b1.length());
// System.out.println(end);
for(int i=1;i<words.length;i++)
{
String start=words[i].substring(0,1);
if(end.equals(start))
{
if(judechong(yao,words[i]))
{}
else
{
end=words[i].substring(words[i].length()-1,words[i].length());
yao.append(words[i]);
yao.append(" ");
}
}
}
if(yao.toString().equals(words[0]+" "))
{
yao.append("无互联语句");
System.out.println("无互联词");
}
}
File file =new File("output2.txt");
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
try {
FileWriter fw =new FileWriter(file);
fw.write(yao.toString());
fw.flush();
fw.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
public static boolean judechong(StringBuffer yao,String word)
{
String a=yao.toString();
boolean flag=false;
String[] words = a.split("[^(a-zA-Z)]+"); // 非单词的字符来分割,得到所有单词
for(int i=0;i<words.length;i++)
{
if(word.equals(words[i]))
{
flag=true;
}
}
return flag;
}
// 判断文件是否存在
public static boolean judeFileExists(File file) {
if (file.exists()) {
System.out.println("文件存在");
return true;
} else {
System.out.println("文件不存在");
return false;
}
}
// 判断文件夹是否存在(未修改)
public static void judeDirExists(File file) {
if (file.exists()) {
if (file.isDirectory()) {
System.out.println("dir exists");
} else {
System.out.println("the same name file exists, can not create dir");
}
} else {
System.out.println("dir not exists, create it ...");
file.mkdir();
}
}
}这个代码需要我长时间的复写,仔细思索,加油。
(女友)")
#023单词接龙1(字符串)(女友)
单词接龙
阿泰和女友小菲用英语短信玩单词接龙游戏。一人先写一个英文单词,然后另一个人回复一个英文单词,要求回复单词的开头有若干个字母和上一个人所写单词的结尾若干个字母相同,重合部分的长度不限。(如阿泰输入happy,小菲可以回复python,重合部分为py。)现在,小菲刚刚回复了阿泰一个单词,阿泰想知道这个单词与自己发过去的单词的重合部分是什么。他们两人都是喜欢写长单词的英语大神,阿泰觉得用肉眼找重合部分实在是太难了,所以请你编写程序来帮他找出重合部分。
程序运行结果示例1:
happy↙
pythen↙
py
程序运行结果示例2:
sun↙
unknown↙
un
输入格式: "%s%s"
输出格式: "%s\n" 1 #include <stdio.h>
2 #include <string.h>
3 #define N 20
4 int main()
5 {
6 char str1[N], str2[N], str3[N];
7 int i, r=0, lenth1, lenth2;
8 scanf("%s%s", str1, str2);
9 lenth1 = strlen(str1);
10 lenth2 = strlen(str2);
11 for(i=0;i<lenth1;i++)
12 {
13 if(str1[i] == str2[0])
14 {
15 for(r=0;r<lenth2;r++)
16 {
17 if(str1[i+r] == str2[r])
18 {
19 str3[r] = str2[r];
20 }
21 else if(str1[i+r] != ''\0'')
22 {
23 break;
24 }
25 else
26 {
27 str3[r] = ''\0'';
28 }
29 }
30 }
31 }
32 printf("%s\n", str3);
33 return 0;
34 }
 LeetCode 127. Word Ladder —— 单词接龙")
(Java) LeetCode 127. Word Ladder —— 单词接龙
Given two words (beginWord and endWord), and a dictionary''s word list, find the length of shortest transformation sequence from beginWord to endWord, such that:
- Only one letter can be changed at a time.
- Each transformed word must exist in the word list. Note that beginWord is not a transformed word.
Note:
- Return 0 if there is no such transformation sequence.
- All words have the same length.
- All words contain only lowercase alphabetic characters.
- You may assume no duplicates in the word list.
- You may assume beginWord and endWord are non-empty and are not the same.
Example 1:
Input:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
Output: 5
Explanation: As one shortest transformation is "hit" -> "hot" -> "dot" -> "dog" -> "cog",
return its length 5.Example 2:
Input:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
Output: 0
Explanation: The endWord "cog" is not in wordList, therefore no possible transformation.
这是很典型的单源头广度优先搜索最短路径的问题,只要想到这里,结合图的知识就很好做了。怎么构建图呢?首先图的顶点显而易见,就是每一个单词。那么顶点之间的边呢?就是如果顶点的单词互相只差一个字母,顶点间就会形成边。用第一个例子绘制的图如下:
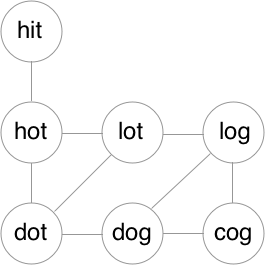
那么根据广度优先搜索的步骤,构建一个队列,之后先把源顶点加入队列,以队列是否为空作为条件开始循环:如果队列不为空,逐个取出队列中的顶点,并把它们标记为“已访问”。对于每个取出的顶点,依次把它未访问的顶点加入队列,直到找到目标顶点或者所有顶点都访问完毕。因为此题只是求最短路径的长度,而不是路径上都有哪些顶点,所以只需要存储每访问一个顶点时该顶点处在路径的位置即可。这里我用了HashMap<String, Integer>。如果是需要存储最短路径本身,那么需要建立数据结构依次存储每个顶点的前驱,并在最后追溯前驱获得路径上的所有顶点。
这里我用一个HashSet替换掉题目中存储单词的List数据结构,只是为了搜索的时候能够快一点。至于如何获取某个节点的邻接节点,即和它只差一个字母的单词,这里用了最暴力的办法,就是把顶点单词的每一位换成其他的25个字母,看看它在不在题目提供的字典里。详细的标注都已经标注在代码中,见下。
Java
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
HashSet<String> wordSet = new HashSet<>(wordList); //替换掉题目中List结构,加速查找
if (!wordSet.contains(endWord)) return 0; //如果目标顶点不在图中,直接返回0
HashMap<String, Integer> map = new HashMap<>(); //用来存储已访问的节点,并存储其在路径上的位置,相当于BFS算法中的isVisted功能
Queue<String> q = new LinkedList<>(); //构建队列,实现广度优先遍历
q.add(beginWord); //加入源顶点
map.put(beginWord, 1); //添加源顶点为“已访问”,并记录它在路径的位置
while (!q.isEmpty()) { //开始遍历队列中的顶点
String word = q.poll(); //记录现在正在处理的顶点
int level = map.get(word); //记录现在路径的长度
for (int i = 0; i < word.length(); i++) {
char[] wordLetter = word.toCharArray();
for (char j = ''a''; j <= ''z''; j++) {
if (wordLetter[i] == j) continue;
wordLetter[i] = j; //对于每一位字母,分别替换成另外25个字母
String check = new String(wordLetter);
if (check.equals(endWord)) return map.get(word) + 1; //如果已经抵达目标节点,返回当前路径长度+1
if (wordSet.contains(check) && !map.containsKey(check)) { //如果字典中存在邻接节点,且这个邻接节点还未被访问
map.put(check, level + 1); //标记这个邻接节点为已访问,记录其在路径上的位置
q.add(check); //加入队列,以供广度搜索
}
}
}
}
return 0;
}
}
")
120. 单词接龙 (BFS)
###描述 给出两个单词(start和end)和一个字典,找到从start到end的最短转换序列
比如:
每次只能改变一个字母。 变换过程中的中间单词必须在字典中出现。 如果没有转换序列则返回0。 所有单词具有相同的长度。 所有单词都只包含小写字母。
###样例 给出数据如下:
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
一个最短的变换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度 5
import collections
class Solution:
# @param start, a string
# @param end, a string
# @param dict, a set of string
# @return an integer
def ladderLength(self, start, end, dict):
# write your code here
dict.add(end)
wordLen = len(start)
queue = collections.deque([(start, 1)])
while queue:
curr = queue.popleft()
currWord = curr[0]; currLen = curr[1]
if currWord == end: return currLen
for i in range(wordLen):
part1 = currWord[:i]; part2 = currWord[i+1:]
for j in ''abcdefghijklmnopqrstuvwxyz'':
if currWord[i] != j:
nextWord = part1 + j + part2
if nextWord in dict:
queue.append((nextWord, currLen + 1))
dict.remove(nextWord)
return 0

2021-09-07:单词接龙 II。按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一
2021-09-07:单词接龙 II。按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:每对相邻的单词之间仅有单个字母不同。转换过程中的每个单词 si(1 <= i <= k)必须是字典 wordList 中的单词。注意,beginWord 不必是字典 wordList 中的单词。sk == endWord,给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。力扣 126。
福大大 答案 2021-09-07:
递归。遍历找邻居。
时间复杂度:O (k*N) 和 O (26*k*k)。
代码用 golang 编写。代码如下:
package main
import "fmt"
func main() {
beginWord := "hit" endWord := "cog" wordList := []string{"hot", "dot", "dog", "lot", "log", "cog"} ret := findLadders(beginWord, endWord, wordList) fmt.Println(ret)
}
func findLadders(start string, end string, list0 []string) [][]string { list0 = append(list0, start) nexts := getNexts(&list0) distances := getDistances(start, nexts) pathList := make([]string, 0) res := make([][]string, 0) getShortestPaths(start, end, nexts, distances, &pathList, &res) return res}
//func getNexts(words *[]string) map[string][]string { dict := make(map[string]struct{}) for _, word := range *words { dict[word] = struct{}{} } nexts := make(map[string][]string) for i := 0; i < len(*words); i++ { nexts[(*words)[i]] = getNext((*words)[i], dict) } return nexts}
// word, 在表中,有哪些邻居,把邻居们,生成list返回func getNext(word string, dict map[string]struct{}) []string { res := make([]string, 0) chs := []byte(word) for cur := byte(''a''); cur <= ''z''; cur++ { for i := 0; i < len(chs); i++ { if chs[i] != cur { tmp := chs[i] chs[i] = cur if _, ok := dict[fmt.Sprintf("%s", chs)]; ok { res = append(res, fmt.Sprintf("%s", chs)) } chs[i] = tmp } } } return res}
// 生成距离表,从start开始,根据邻居表,宽度优先遍历,对于能够遇到的所有字符串,生成(字符串,距离)这条记录,放入距离表中func getDistances(start string, nexts map[string][]string) map[string]int {
distances := make(map[string]int) distances[start] = 0 queue := make([]string, 0) queue = append(queue, start) set := make(map[string]struct{}) set[start] = struct{}{} for len(queue) > 0 { //cur := queue[len(queue)-1] //queue = queue[0 : len(queue)-1] cur := queue[0] queue = queue[1:] for _, next := range nexts[cur] { if _, ok := set[next]; !ok { distances[next] = distances[cur] + 1 queue = append(queue, next) set[next] = struct{}{} } } } return distances}
// cur 当前来到的字符串 可变// to 目标,固定参数// nexts 每一个字符串的邻居表// cur 到开头距离5 -> 到开头距离是6的支路 distances距离表// path : 来到cur之前,深度优先遍历之前的历史是什么// res : 当遇到cur,把历史,放入res,作为一个结果func getShortestPaths(cur string, to string, nexts map[string][]string, distances map[string]int, path *[]string, res *[][]string) { *path = append(*path, cur) if to == cur { //res.add(new LinkedList<String>(path)); pathcopy := make([]string, len(*path)) copy(pathcopy, *path) *res = append(*res, pathcopy) } else { for _, next := range nexts[cur] { if distances[next] == distances[cur]+1 { getShortestPaths(next, to, nexts, distances, path, res) } } } //path.pollLast(); *path = (*path)[0 : len(*path)-1]}
执行结果如下:
***
[左神 java 代码](https://github.com/algorithmzuo/coding-for-great-offer/blob/main/src/class26/Code04_WordLadderII.java)
本文分享自微信公众号 - 福大大架构师每日一题(gh_bbe96e5def84)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。
关于单词接龙最长——6.6——计算最长英语单词链和单词接龙算法题的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于#023单词接龙1(字符串)(女友)、(Java) LeetCode 127. Word Ladder —— 单词接龙、120. 单词接龙 (BFS)、2021-09-07:单词接龙 II。按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一的相关信息,请在本站寻找。
本文标签:




