此处将为大家介绍关于本科阶段,一门计算机相关课结束后,应该留下些什么?的详细内容,并且为您解答有关计算机专业一节课多长时间的相关问题,此外,我们还将为您介绍关于1.计算机发展阶段计算机发展历史机械式计
此处将为大家介绍关于本科阶段,一门计算机相关课结束后,应该留下些什么?的详细内容,并且为您解答有关计算机专业一节课多长时间的相关问题,此外,我们还将为您介绍关于1.计算机发展阶段 计算机发展历史 机械式计算机 机电式计算机 电子计算机 逻辑电路与计算机 二极管 电子管 晶体管 硅 门电路 计算机 电磁学计算机二进制、2020 年,哪一门计算机技能最当红?、8个深度学习/计算机视觉错误,应该如何避免它们、C# 获取计算机相关信息的有用信息。
本文目录一览:- 本科阶段,一门计算机相关课结束后,应该留下些什么?(计算机专业一节课多长时间)
- 1.计算机发展阶段 计算机发展历史 机械式计算机 机电式计算机 电子计算机 逻辑电路与计算机 二极管 电子管 晶体管 硅 门电路 计算机 电磁学计算机二进制
- 2020 年,哪一门计算机技能最当红?
- 8个深度学习/计算机视觉错误,应该如何避免它们
- C# 获取计算机相关信息
")
本科阶段,一门计算机相关课结束后,应该留下些什么?(计算机专业一节课多长时间)
全文2000字,阅读时间6min
1、概述
这个是大二下的课程表,计算机相关的课程有「面向对象技术」(实际上就是MFC),「数据结构」、移动终端软件开发技术(实际上是Android开发)
下面对其分别简称为,MFC、数据结构、Android,以方便进行接下来的总结和吐槽。
这三门课,其实都只是学了点皮毛,原因有很多,其中一个重要的便是持续学习一门课的时间段太短了。大二下一共有9门课,其中马克思主义、信号与系统、概率论、英语翻译等占据太多时间,而那三门计算机相关的课本身的一个理论框架熟悉需要时间,动手时间也需要时间,并且是需要周期长一点的反复的时间。
第一门MFC
这是我们的教科书,就是那个传说中最经典98年的vc6.0的教程。
课程设计视频


MFC老师他上课时的思绪逻辑总是有点像4g时代拿着3g手机看视频似的,卡片卡片的,还有一种照本宣科、读PPT的感觉。我们知道学一些基础的东西可能有助于打好基础,但是老师那种只谈MFC,其他一点有趣的课外延伸一点都没有,这有点像一位被老技术捆绑住、停滞不前的老师在坐井观天地教学生。
MFC老师给我留下最深刻的一句话绝对是那句“代码我就不写了,写代码太费时间了,你们自己回去看书,书上都有”。记得有一次,老师有敲过一次代码,有错误,老师在他那个没有行数显示的VC6.0上找了好久,最终发现是函数没有加括号。我不是想嘲笑老师,这节课我反而觉得很真实,学的东西反而更多。如果每一个老师都说,代码书上有,回去自己看书,那哪个老师来当第一个教学生从0敲完整一点的程序,这就有点像,每个数学老师都讲理论,却没有一个老师能真正带学生从头到尾算一道习题。
01
那这门课我学到了什么?
1、首先是了解到了MFC的一些历史
2、如何new一个MFC工程,了解一个MFC工程的框架、消息映射机制,在哪个地方添加代码,如何使用控价。但是一些复杂一点的控件嵌套关系就不太懂了。
3、其实学习MFC时大部分时间都是在学习一些UI组件的规范,组件的继承关系。真正涉及到算法的、数据库的几乎是没有。这也是我所担心的。
02
那这门课过后留下给我们的应该是什么?
1、MFC的笔记以及学过MFC后可以大胆追求其他技术的自信
或许在最近的一段时间、甚至未来我都不会用到MFC开发,因此那些方法我会忘掉,但是我又不敢保证不会用到。万一我需要用到,我可以通过笔记以新学时间的1/10,迅速把它捡起来。从新建MFC工程的结构、到消息映射在哪个地方添加代码,再到可使用的各种控件,以及控件的消息。不是说一定要学完MFC这种最初的UI编程,才可以去学新一点的UI编程如QT,但是既然学校安排了,我们也可以接受,因为现在的我不是急需熟练地掌握哪一门编程,而是需要不惧怕学习任何一种编程的自信心与能力。
第二门Android

这本书基于Android5.0
大概就是以2015年的Android5.0为基础
涉及到2016年的Android6.0和2017年的Android7.0。
课程设计视频·
https://www.bilibili.com/video/BV1JD4y1D7FQ/
源码地址
:https://pan.baidu.com/s/1PF5wfuhHn8Lek5Qxu_STZg 提取码:8lah
这本书也确实有点旧,没办法,因为Android迭代太快了,如今Android11正式版也即将发行。这本是很基础,但是快速迭代的Android也会因此改进很多,课本的一小部分例子的方法都是Google不推荐的了deprecate。此外,Google也给出了许多新的、书上没有的组件,就比如我们课程设计用到的Viewpager2。
我们Android全程录播课,但是老师讲话生动有趣。他和MFC老师不一样,他不局限于应该讲的Android界面,带我们看了更广阔的世界,但也教我们要把基础打好,先把方法用起来,把效果实现,再去探讨底层细节和其他各种高级的东西。
01
那这门课我们学到了什么?
1、Android studio 入门了
2、了解到Android界面开发的一些框架。
如Activity要装载xml,了解到一些控件的使用,比如要implements哪个接口,以及其方法。但是这也是我所担心的,学习Android只是学到了一些基本界面,没有掌握到一些更底层一点的东西,比如Handle,ContenProvider,网络编程等等。
3、有点体会到面向XX编程,如面向百度编程,面向bing编程。
因为在学习Android时喜欢用网上的一些教程,如viewpager2的使用教程,recyclerview的使用教程。认识到网上水文多,但完整的教程也有。
4、当有许多人在讨论一门技术时,那种学习氛围真好。
Android 一直都在更新,有问题就会有新的进展,不像MFC,找个帖子,都是08年的,网上交流的人都很少。
02
那这门课过后留下给我们的应该是什么?
1、Android的笔记以及深知技术无限后积极探索的好奇心
如果不去参加一些项目,或者去实习,大概率我是不常用Android studio,一些必须的方法我会忘掉。但是希望我的Android笔记可以在我需要Android的时候,让我快速捡起这些记忆。很多技术可以学的东西都太多了,但这次只有Android真正让我看到,前面就有许许多多的东西可以学,如上面提到的Handle、contentprovider,网络编程,这些都是老师快速带过的。以及一些新的控件,都是都没有教的。我困惑的是本人也没有找到一个很好地学习方法,继续深入学习。
第三门数据结构
我理想中的数据结构课程:比如讲到快速排序,先来个理论分析,接着老师solo敲代码
实际上的数据结构课程:比如讲到快速排序,先来个理论分析,然后下课
01
那这门课我们学到了什么?
1、简单可以分为树、图、查找、排序等等的理论
02
那这门课过后留下给我们的应该是什么?
1、数据结构应当作为一个开发人员一生的课程。
上理论课,做习题没错,但这只算是离散数学的升级版,并不算真正的数据结构
我们需要上机训练。并且以后仍然要保持对数据结构的敏感。
总结
1、既然是学校安排好的课程,可以讨论它是否值得学习,但是这要建立在60分万岁的基础上,才可以从容地对外人做出课程的评价。
2、做好“规矩按照学校课程,从入门到入土”的思想准备。
3、做好“局限于学校课程,毕业后代码能力为0”的思想准备
4、生态学习依然是我们的指导思想,附上大三上的课表

1.计算机发展阶段 计算机发展历史 机械式计算机 机电式计算机 电子计算机 逻辑电路与计算机 二极管 电子管 晶体管 硅 门电路 计算机 电磁学计算机二进制
引言
任何事物的创造发明都来源于需求和欲望
而科学技术的发展则推动实现了目标
正是因为人类对于计算能力孜孜不倦的追求,才创造了如今规模的计算机.
计算机,字如其名,用于计算的机器.这就是最初计算机的发展动力.
在漫长的历史长河中,随着社会的发展和科技的进步,人类始终有计算的需求
进行运算时所运用的工具,也经历了由简单到复杂,由低级向高级的发展变化。
本文尽可能的仅仅描述逻辑本质,不去追究实现细节
计算(机|器)的发展与数学/电磁学/电路理论等自然科学的发展息息相关
计算(机|器)的发展有四个阶段
手动阶段
机械阶段
机电阶段
电子阶段
手动阶段
顾名思义,就是用手指进行计算,或者操作一些简易工具进行计算
最开始的时候人们主要是借助简单的工具比如手指/石头/打绳结/纳皮尔棒/计算尺等,
我想大家都用手指数过数;
有人用一堆石子表示一些数目;
也有人曾经用打绳结来计数;
再后来有了一些数学理论的发展,纳皮尔棒/计算尺则是借助了一定的数学理论,可以理解为是一种查表计算法.
你会发现,这里还不能说是计算(机|器),只是计算而已,更多的靠的是心算以及逻辑思维的运算,工具只是一个简简单单的辅助.
机械阶段
我想不用做什么解释,你看到机械两个字,肯定就有了一定的理解了,没错,就是你理解的这种普通的意思,
一个齿轮,一个杠杆,一个凹槽,一个转盘这都是一个机械部件.
人们当然不满足于简简单单的计算,自然想制造计算能力更大的机器
机械阶段的主题思想其实也很简单,就是通过机械的装置部件比如齿轮旋转,动力传送等来表示数据记录,进行运算,也即是机械式计算机,这样说有些抽象.
我们举例说明:
契克卡德是现今公认的机械式计算第一人,他发明了契克卡德计算钟
我们不去纠结这个东西到底是如何实现的,只描述事情逻辑本质
其中他有一个进位装置是这样子的

可以看到采用十进制,转一圈之后,轴上面的一个突出齿,就会把更高一位(比如十位)进行加一
这就是机械阶段的精髓,不管他有多复杂,他都是通过机械装置进行传动运算的
还有帕斯卡的加法器
他是使用长齿轮进行进位

再有后来的莱布尼茨轴,设计的更为精巧
我觉得对于机械阶段来说,如果要用一个词语来形容,应该是精巧,就好似钟表里面的齿轮似的
不管形态究竟如何,终究也还是一样,他也只是一个精巧了再精巧的仪器,一个精密设计的机关装置
首先要把运算进行分解,然后就是机械性的依靠齿轮等部件传动运转来完成进位等运算.
说计算机的发展,就不得不提一个人,那就是巴贝奇
他发明了史上著名的差分机,之所以叫差分机这个名字,是因为它计算所使用的是帕斯卡在1654年提出的差分思想

我们仍旧不去纠结他的原理细节
此时的差分机,你可以清晰地看得到,仍旧是一个齿轮又一个齿轮,一个轴又一个轴的更加精巧的仪器
很显然他仍旧又仅仅是一个计算的机器,只能做差分运算
再后来1834年巴贝奇提出来了分析机的概念 一种通用计算机的概念模型
正式成为现代计算机史上的第一位伟大先驱。
之所以这样说,是因为他在那个年代,已经把计算机器的概念上升到了通用计算机的概念,这比现代计算的理论思想提前了一个世纪
它不局限于特定功能,而且是可编程的,可以用来计算任意函数——不过这个想法是构思在一坨齿轮之上的.
巴贝奇设计的分析机主要包括三大部分
1、用于存储数据的计数装置,巴贝奇称之为“仓库”(store),相当于现在CPU中的存储器
2、专门负责四则运算的装置,巴贝奇称之为“工厂”(mill),相当于现在CPU中的运算器
3、控制操作顺序、选择所需处理的数据和输出结果的装置
而且,巴贝奇并没有忽略输入输出设备的概念
此时你回想一下冯诺依曼计算机的结构的几大部件,而这些思想是在十九世纪提出来的,是不是不寒而栗!!!
巴贝奇另一大了不起的创举就是将穿孔卡片(punched card)引入了计算机器领域,用于控制数据输入和计算
你还记得所谓的第一台计算机"ENIAC"使用的是什么吗?就是纸带!!
ps:其实ENIAC真的不是第一台~
所以说你应该可以理解为什么他被称为"通用计算机之父"了.
他提出的分析机的架构设想与现代冯诺依曼计算机的五大要素,存储器 运算器 控制器 输入 输出是吻合的
也是他将穿孔卡片应用到计算机领域
ps:穿孔卡片本身并不是巴贝奇的发明,而是来自于改进后的提花机,最早的提花机来自于中国,也就是一种纺织机
只是可惜,分析机并没有真正的被构建出来,但是他的思维理念是超前的,也是正确的
巴贝奇的思想超前了整整一个世纪,不得不提的就是女程序员艾达,有兴趣的可以google一下,Augusta Ada King
机电阶段与电子阶段使用到的硬件技术原理,有不少是相同的
主要差别就在于计算机理论的成熟发展以及电子管晶体管的应用
为了接下来更好的说明,我们自然不可避免的要说一下当时出现的自然科学了
自然科学的发展与近现代计算的发展是一路相伴而来的
文艺复兴运动使人们从传统的封建神学的束缚中慢慢解放,文艺复兴促进了近代自然科学的产生和发展
你要是实在没事情做,可以探究一下"欧洲文艺复兴革命对近代自然科学发展史有何重要影响"这一议题
电磁学
据传是1752年,富兰克林做了实验,在近代发现了电
随后,围绕着电,出现了很多旷世的发现.比如电磁学,电能生磁,磁能生电
这就是电磁铁的基本原型
根据电能生磁的原理,发明了继电器,继电器可以用于电路转换,以及控制电路
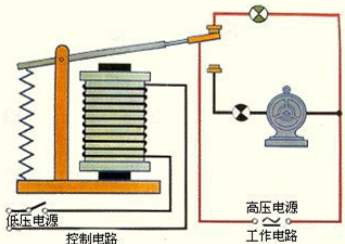
电报就是在这个技术背景下被发明了,下图是基本原理
但是,如果线路太长,电阻就会很大,怎么办?
可以用人进行接收转发到下一站,存储转发这是一个很好的词汇
所以继电器又被作为转换电路应用其中
二进制
而且,一个很重要的事情是,德国人莱布尼茨大约在1672-1676发明了二进制
用0和1两个数码来表示的数
逻辑学
更准确的说是数理逻辑,乔治布尔开创了用数学方法研究逻辑或形式逻辑的学科
既是数学的一个分支,也是逻辑学的一个分支
简单地说就是与或非的逻辑运算
逻辑电路
香农在1936年发表了一篇论文<继电器和开关电路的符号化分析>
我们知道在布尔代数里面
X表示一个命题,X=0表示命题为假;X=1表示命题为真;
如果用X代表一个继电器和普通开关组成的电路
那么,X=0就表示开关闭合 X=1就表示开关打开
不过他当时0表示闭合的理念跟现代正好相反,难道觉得0是看起来就是闭合的吗
解释起来有些别扭,我们用现代的看法解释下他的观点
也就是:
(a) 开关的闭合与打开对应命题的真假,0表示电路的断开,命题的假 1表示电路的连通,命题的真
(b)X与Y的交集,交集相当于电路的串联,只有两个都联通,电路才是联通的,两个都为真,命题才为真
(c)X与Y的并集,并集相当于电路的并联,有一个联通,电路就是联通的,两个有一个为真,命题即为真
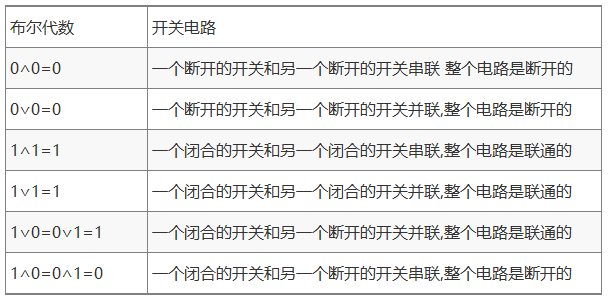
这样逻辑代数上的逻辑真假就与电路的连通断开,完美的完全映射
而且,所有的布尔代数基本规则,都非常完美的适合开关电路
基本单元-门电路
有了数理逻辑和逻辑电路的基础理论,不难得出电路中的几个基础单元
Vcc表示电源 比较粗的短横线表示的是接地
与门
串联电路,AB两个电路都联通时,右侧开关才会同时闭合,电路才会联通
符号
另外还有多输入的与门
或门
并联电路,A或者B电路只要有任何一个联通,那么右侧开关就会有一个闭合,右侧电路就会联通
符号
非门
右侧开关常闭,当A电路联通的时候,则右侧电路断开,A电路断开时,右侧电路联通
符号:
所以你只需要记住:
与是串联/或是并联/取反用非门
机电阶段
接下来我们说一个机电式计算机器的优秀典范
机电式的制表机
霍尔瑞斯的制表机,主要是为了解决美国人口普查的问题.
人口普查,你可以想象得到自然是用于统计信息,性别年龄姓名等
如果纯粹的人工手动统计,可想而知,这是多么复杂的一个工程量
制表机首次将穿孔技术应用到了数据存储上,你可以想象到,使用打孔和不打孔来识别数据
不过当时设计还不是很成熟,比如如果现代,我们肯定是一个位置表示性别,可能打孔是女,不打孔是男
当时是卡片上用了两个位置,表示男性就在标M的地方打孔,女性就在标F的地方打孔,不过在当时也是很先进了
然后,专门的打孔员使用穿孔机将居民信息戳到卡片上
紧接着自然是要统计信息
利用电流的通断来识别数据
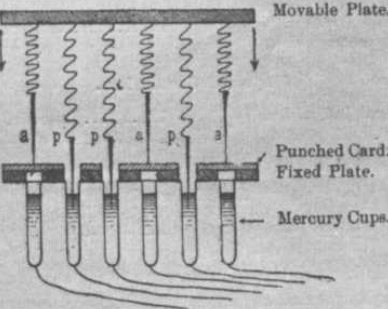
对应着这个卡片上的每个数据孔位,上面有着金属针,下面有着容器,容器装着水银
按下压板时,卡片有孔的地方,针可以通过,与水银接触,电路接通,没孔的地方,针就被挡住。
如何将电路通断对应到所需要的统计信息?
这就用到了数理逻辑与逻辑电路了
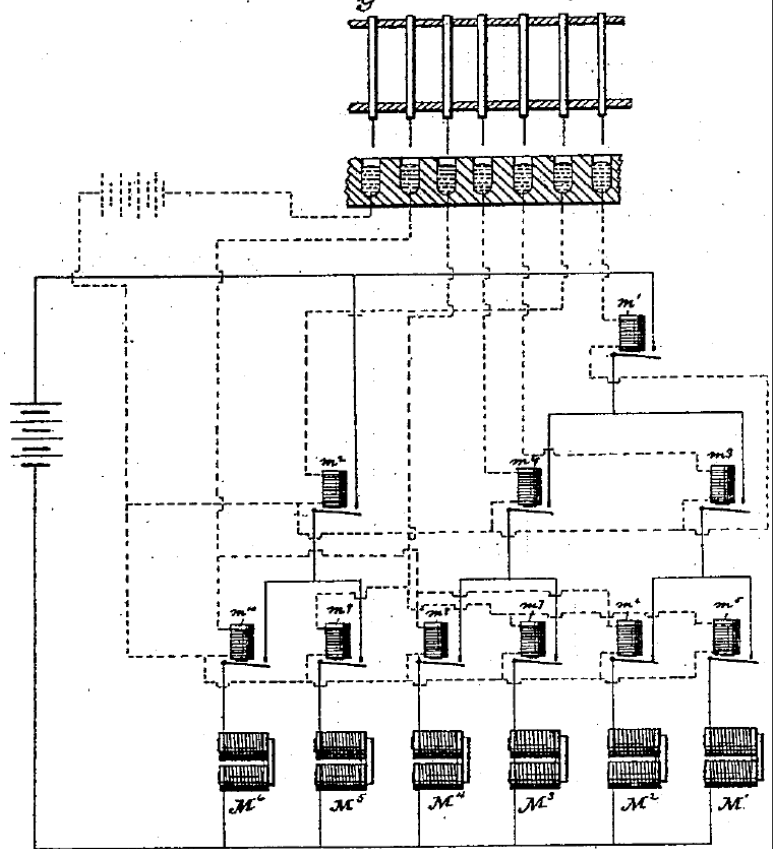
最上面的引脚是输入,通过打孔卡片的输入
下面的继电器是输出,根据结果 通电的M将产生磁场, 牵引特定的杠杆,拨动齿轮完成计数。
看到没,此时已经可以根据打孔卡片作为输入,继电器组成的逻辑电路作为运算器,齿轮进行计数的输出了
制表机中的涉及到的主要部件包括: 输入/输出/运算
1896年,霍尔瑞斯创立了制表机公司,他是IBM的前身.....
有一点要说明
并不能笼统的说谁发明了什么技术,下一个使用这种技术的人,就是借鉴使用了发明者或者说发现者的理论技术
在计算机领域,很多时候,同样的技术原理可能被好几个人在同一时期发现,这很正常
还有一位大神,不得不介绍,他就是康拉德·楚泽 Konrad Zuse 德国
http://zuse.zib.de/
因为他发明了世界上第一台可编程计算机——Z1

图为复制品,复制品其实机械工艺上比37年的要现代化一些
尽管zuse生于1910,Z1也是大约1938建造完成,但是他其实跟机械阶段的计算器并没有什么太大区别
要说和机电的关系,那就是它使用电动马达驱动,而不是手摇,所以本质还是机械式
不过他的牛逼之处在于在也设想出来了现代计算机一些的理论雏形
将机器严格划分为处理器和内存两大部分
采用了二进制
引入浮点数,发明了浮点数的二进制规格化表示
靠机械零件实现与、或、非等基础的逻辑门
虽然作为机械设备,但是却是一台时钟控制的机器。其时钟被细分为4个子周期
处理器是微代码结构的操作被分解成一系列微指令,一个机器周期一条微指令。
微指令在运算器单元之间产生具体的数据流,运算器不停地运作,每个周期都将两个输入寄存器里的数加一遍。
可编程 从穿孔带读入8比特长的指令 指令已经有了操作码 内存地址的概念
这些全都是机械式的实现
而且这些具体的实现细节的理念思维,很多也是跟现代计算机类似的
可想而知,zuse真的是个天才
后续还研究出来更多的Z系列
虽然这些天才式的人物并没有一起坐下来一边烧烤一边讨论,但是却总是"英雄所见略同"
几乎在相同时期,美国科学家斯蒂比兹(George Stibitz)与德国工程师楚泽独立研制出二进制数字计算机,就是Model k
Model I不但是第一台多终端的计算机,还是第一台可以远程操控的计算机。
贝尔实验室利用自身的技术优势,于1940年9月9日,在达特茅斯学院(Dartmouth College)和纽约的本部之间搭起线路.
贝尔实验室后续又推出了更多的Model系列机型
再后来又有Harvard Mark系列,哈佛与IBM的合作
哈佛这边是艾肯IBM是其他三位

Mark I也通过穿孔带获得指令,和Z1是不是相同?
穿孔带每行有24个空位
前8位标识用于存放结果的寄存器地址,中间8位标识操作数的寄存器地址,后8位标识所要进行的操作
——结构已经非常类似后来的汇编语言
内部还有累加寄存器,常数寄存器
机电式的计算机中,我们可以看到,有些伟大的天才已经构思设想出来了很多被应用于现代计算机的理论
机电时期的计算机可以说是有不少机器的理论模型已经算是比较接近现代计算机了
而且,有不少机电式的型号一直发展到电子式的年代,部件使用电子管来实现
这为后续计算机的发展提供了不可磨灭的贡献
电子管
我们现在再转到电学史上的1904年
一个叫做弗莱明的英国人发明了一种特殊的灯泡-----电子二极管
先说一下爱迪生效应:
在研究白炽灯的寿命时,在灯泡的碳丝附近焊上一小块金属片。
结果,他发现了一个奇怪的现象:金属片虽然没有与灯丝接触,但如果在它们之间加上电压,灯丝就会产生一股电流,趋向附近的金属片。
这股神秘的电流是从哪里来的?爱迪生也无法解释,但他不失时机地将这一发明注册了专利,并称之为“爱迪生效应”。
此处完全可以看得出来,爱迪生是多么的有商业头脑,这就拿去申请专利去了~此处省略一万字....
金属片虽然没有与灯丝接触,但是如果他们之间加上电压,灯丝就会产生一股电流,趋向附近的金属片
就是图中的这样子
而且这种装置有一个神奇的功能:单向导电性,会根据电源的正负极连通或者断开
其实上面的形式和下图是一样的,要记住的是左边靠近灯丝的是阴极 阴极电子放出
用现在的术语解释就是:
阴极是用来放射电子的部件, 分为氧化物阴极和碳化钍钨阴极。
一般来说氧化物阴极是旁热式的, 它是利用专门的灯丝对涂有氧化钡等阴极体加热, 进行热电子放射。
碳化钍钨阴极一般都是直热式的,通过加热即可产生热电子放射, 所以它既是灯丝又是阴极。
然后又有个叫做福雷斯特的人在阴极和阳极之间,加入了金属网,现在就叫做控制栅极
通过改变栅极上电压的大小和极性,可以改变阳极上电流的强弱,甚至切断
电子三极管的原理大致就是这样子的
既然可以改变电流的大小,他就有了放大的作用
不过显然,是电源驱动了他,没有电他本身不能放大
因为多了一条腿,所以就叫做电子三极管
我们知道,计算机应用的其实只是逻辑电路,逻辑电路是与或非门组成,他并不是真的在乎到底是谁有这个本事
之前继电器能实现逻辑门的功能,所以继电器被应用到了计算机上
比如我们上面提到过的与门
之所以继电器可以实现逻辑门的功能,就是因为它具有"控制电路"的功能,就是说可以根据一侧的输入情况,决定另一侧的情况
那新发明的电子管,根据它的特性,也可以应用于逻辑电路
因为你可以控制栅极上电压的大小和极性,可以改变阳极上电流的强弱,甚至切断
也达到了根据输入,控制另外一个电路的功能,只不过从继电器换成电子管,内部的电路需要变化下而已
电子阶段
现在应该说一下电子阶段的计算机了,可能你早就听过了ENIAC
我想说你更应该了解下ABC机.他才是真正的世界上第一台电子数字计算设备
阿塔纳索夫-贝瑞计算机(Atanasoff–Berry Computer,通常简称ABC计算机)
1937年设计,不可编程,仅仅设计用于求解线性方程组
但是很显然,没有通用性,也不可编程,也没有存储程序机制,他完全不是现代意义的计算机

上面这段话来源于:http://www4.ncsu.edu/~belail/The_Introduction_of_Electronic_Computing/Atanasoff-Berry_Computer.html
主要陈述了设计理念,大家可以上面的这四点
如果你想要知道你和天才的距离,请仔细看下这句话
he jotted down on a napkin in a tavern
世界上第一台现代电子计算机埃尼阿克(ENIAC),也是继ABC之后的第二台电子计算机.
ENIAC是参照阿塔纳索夫的思想完整地制造出了真正意义上的电子计算机
奇葩的是为啥不用二进制...
建造于二战期间,最初的目的是为了计算弹道
ENIAC具有通用的可编程能力
更详细的可以参看维基百科:
https://zh.wikipedia.org/zh-cn/%E9%9B%BB%E5%AD%90%E6%95%B8%E5%80%BC%E7%A9%8D%E5%88%86%E8%A8%88%E7%AE%97%E6%A9%9F
不过ENIAC程序和计算是分开的,也就意味着你需要手动输入程序!
并不是你理解的键盘上敲一敲就好了,是需要手工插接线的方式进行的,这对使用来说是一个巨大的问题.
有一个人叫做冯·诺伊曼,美籍匈牙利数学家
有意思的是斯蒂比兹演示Model I的时候,他是在场的
而且他也参与了美国第一颗原子弹的研制工作,任弹道研究所顾问,而且其中涉及到的计算自然是极为困难的
我们说过ENIAC是为了计算弹道的,所以他早晚会接触到ENIAC,也算是比较顺理成章的他也加入了计算机的研制
冯诺依曼结构
1945年,冯·诺依曼和他的研制小组在共同讨论的基础上
发表了一个全新的“存储程序通用电子计算机方案”——EDVAC(Electronic Discrete Variable Automatic Computer)
一篇长达101页纸洋洋万言的报告,即计算机史上著名的“101页报告”。这份报告奠定了现代电脑体系结构坚实的根基.
报告广泛而具体地介绍了制造电子计算机和程序设计的新思想。
这份报告是计算机发展史上一个划时代的文献,它向世界宣告:电子计算机的时代开始了。
最主要是两点:
其一是电子计算机应该以二进制为运算基础
其二是电子计算机应采用存储程序方式工作
并且进一步明确指出了整个计算机的结构应由五个部分组成:
运算器、控制器、存储器、输入装置和输出装置,并描述了这五部分的职能和相互关系
其他的点还有,
指令由操作码和地址码组成,操作码表示操作的性质,地址表示操作数的存储位置
指令在存储器内按照顺序存放
机器以运算器为中心,输入输出设备与存储器间的数据传送通过运算器完成
人们后来把根据这一方案思想设计的机器统称为“冯诺依曼机”,这也是你现在(2018年)在使用的计算机的模型
我们刚才说到,ENIAC并不是现代计算机,为什么?
因为不可编程,不通用等,到底怎么描述:什么是通用计算机?
1936年,艾伦·图灵(1912-1954)提出了一种抽象的计算模型 —— 图灵机 (Turing Machine)
又称图灵计算、图灵计算机
图灵的一生是难以评价的~
我们此处仅仅说他对计算机的贡献
下面这段话来自于百度百科:
图灵的基本思想是用机器来模拟人们进行数学运算的过程
所谓的图灵机就是指一个抽象的机器
图灵机更多的是计算机的科学思想,图灵被称为 计算机科学之父
它证明了通用计算理论,肯定了计算机实现的可能性
图灵机模型引入了读写与算法与程序语言的概念
图灵机的思想为现代计算机的设计指明了方向
冯诺依曼体系结构可以认为是图灵机的一个简单实现
冯诺依曼提出把指令放到存储器然后加以执行,据说这也来源于图灵的思想
至此计算机的硬件结构(冯诺依曼)以及计算机的自然科学理论(图灵)
已经比较完全了
计算机经过了第一代电子管计算机的时代
随后出现了晶体管
晶体管
肖克利1947年发明了晶体管,被称为20世纪最重要的发明
硅元素1822年被发现,纯净的硅叫做本征硅
硅的导电性很差,被称为半导体
一块纯净的本征硅的半导体
如果一边掺上硼一边掺上磷 然后分别引出来两根导线
这块半导体的导电性获得了很大的改善,而且,像二极管一样,具有单向导电性
因为是晶体,所以叫做晶体二极管
而且,后来还发现加入砷 镓等原子还能发光,称为发光二极管 LED
还能特殊处理下控制光的颜色,被大量应用
如同电子二极管的发明过程一样
晶体二极管不具有放大作用
又发明了在本征半导体的两边掺上硼,中间掺上磷
这就是晶体三极管
只要电流I1 发生一点点变化 电流I2就会大幅度变化
也就是说这种新的半导体材料就像电子三极管一样具有放大作
所以被称为晶体三极管
晶体管的特性完全适合逻辑门以及触发器
世界上第一台晶体管计算机诞生于肖克利获得诺贝尔奖的那年,1956年,此时进入了第二代晶体管计算机时代
再后来人们意识到:晶体管的工作原理和一块硅的大小实际没有关系
可以将晶体管做的很小,但是丝毫不影响他的单向导电性,照样可以方法信号
所以去掉各种连接线,这就进入到了第三代集成电路时代
随着技术的发展,集成的晶体管的数量千百倍的增加,进入到第四代超大规模集成电路时代

2020 年,哪一门计算机技能最当红?
2020 年,哪一门计算机技能最当红?为了研究这件事,美国招聘网站 Indeed 做了一项调查,统计了 2014 年到 2019 年五年间发布在自己网站上的数百万个美国地区的岗位数据,这些岗位共包含了 571 项计算机技能的关键词。

结论很有参考意义,比如说:
- 根据数据显示,sql 和 Java 是雇主想要的前两项技术技能。;
- Python 是第三大最常见的技能,其强劲增长部分归功于数据科学工作;
- 排名第六的亚马逊网络服务(AWS)的增长更为惊人。
近两年来 Python 的爆火我们都能感受到,但 AWS 为什么大幅增长 418%?Java 和 C 分别排在什么位置、变化趋势如何?
通过这份 Indeed.com 发布的数百万美国技术工作,可以找到一些答案。
技术能力社会需求量 TOP 20

如上表所示,在雇主想要的所有技术技能中,sql 虽然逐年下降,但仍然排名第一,大概占比 22%。
Java 老当益壮,位列第二,并保持着缓慢的增长。
Python 位居第三,但五年间取得了 123% 的增长。Python 受欢迎程度的上升也反映了工作的新组合,其中包括数据科学家和数据工程师等强劲增长的职位。Linux 排名第四,JavaScript 排名第五。

从折线图中我们可以更清楚的看到发展变化。
除了黑色的 Python 外,还有一条橘色的线在迅猛攀升,就是 AWS。从 2014 年到 2019 年,AWS 取得了 418% 的增长。整体占比从 2.7% 涨到了 14.2%。
纵观整体数据,排在前十位的技术技能是几种历史悠久的编程语言,其增长幅度适中或持平:C ++,C 和 C#。
.NET 位居第十,在五年中份额下降了 15%。被挤出前十名的 Oracle、Unix 和 HTML 在技术职位上的份额分别下降了 38%,33% 和 17%。
Python 和 AWS 增长的背后
2014 年,Python 在 Indeed.com 上排名第 15。五年后,Python 跃居到了第三位,并且份额增加了 123%。AWS 的崛起更是令人惊叹 —— 同期增长了 418%,从第 39 位上升到第六位。
这两个数据飙升的背后,可能是同样的原因。
首先,随着技术的发展和工作性质的演变,软件工程师和全栈开发人员越来越多地开始使用 Python,同样,这一批人也更多的开始使用 AWS。但是,Python 和 AWS 的飞速增长背后的一个重要原因是,底层技术工作组合正在以有利于这些编程语言的方式发生变化。
其实可以这样想,技术技能的上升或下降一般有两个原因:
1. 更多的技术工作需要该技能;2. 技术工作对某个技能的使用需求增加或增长,而这种需求变化与职位数量的变化不成比例。
第二个因素驱动了 Python 和 AWS 的迅猛增长。特别是,数据科学家和数据工程师等不成比例地使用 Python 的技术工作正在蓬勃发展。
AWS 的爆炸性增长与数据科学家职位的上升并不紧密相关。另一方面,诸如全栈开发人员和开发运营(“ DevOps”)工程师之类的技术工作助长了它的兴起。不断变化的工作结构(以数据科学家和全栈开发人员职位的增长为例)推动了 Python 和 AWS 等技能的崛起。
虽然 Python 近几年才取得突破性的发展,但 Python 其实是一门「古老」的语言,其概念首次出现于 1991 年。
Python 的历史积淀赋予了它一些优势。Python 的使用者众多,这表示这门语言稳定,且具备大量编写完备的文档。对于开发者和企业来说,这意味着使用 Python 伴随而来的是大量经验和代码,只需要评估即可。
资料来源:
Indeed hiring lab:《Today's Top Tech Skills》https://www.hiringlab.org/2019/11/19/todays-top-tech-skills/
结论
从这份数据报告中我们可以看到,最受企业关注的技术技能是 sql,其次是 Java,紧随其后的是 Python。JavaScript,尤其是 AWS 也发展迅速。
从这些趋势中来预测编程语言的发展十分简单,但如果面临选择一门语言去学习的时候,其实就不只是看趋势这么简单的事情了,还需要考虑个人的职业规划和喜好。
比如 Python 虽然大热,但主要应用于数据科学领域,如果想从事一些底层开发相关的工作,C 和 C++ 可能仍是较好的选择;如果想从事 iOS 开发,那么又需要关注 Swift;随着 Flutter 的普及,Dart 最近也经常上头条。
所以,我们还是要基于项目的属性和规模以及所需技能组合,合理地选择编程语言,而不是一味地迷信其中的某一种编程语言。
扩展阅读:
2020 编程语言盘点展望2020 全球开发者调查报告
- END -


8个深度学习/计算机视觉错误,应该如何避免它们
人是不完美的,我们经常在程序中犯错误。有时这些错误很容易发现:你的代码根本不能工作,你的应用程序崩溃等等。但是有些bug是隐藏的,这使得它们更加危险。
在解决深度学习问题时,由于一些不确定性,很容易出现这种类型的bug:很容易看到web应用端点路由请求是否正确,而不容易检查你的梯度下降步骤是否正确。然而,在DL从业者生涯中有很多错误是可以避免的。
我想分享一些我的经验,关于我在过去两年的计算机视觉工作中看到或制造的错误。我在会议上谈到过这个话题,很多人在会后告诉我:“是的,伙计,我也有很多这样的错误。”我希望我的文章可以帮助你至少避免其中的一些问题。
1.翻转图像和关键点
假设一个关键点检测问题的工作。它们的数据看起来像图像和一系列关键点元组,例如[(0,1),(2,2)],其中每个关键点是一对x和y坐标。
让我们对这个数据实现一个基本的数据增强:
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):
img = np.fliplr(img)
h, w, *_ = img.shape
kpts = [(y, w - x) for y, x in kpts]
return img, kpts看起来好像是正确的,嗯,让我们把结果可视化一下:
mage = np.ones((10, 10), dtype=np.float32)
kpts = [(0, 1), (2, 2)]
image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)
img1 = image.copy()
for y, x in kpts:
img1[y, x] = 0
img2 = image_flipped.copy()
for y, x in kpts_flipped:
img2[y, x] = 0
_ = plt.imshow(np.hstack((img1, img2)))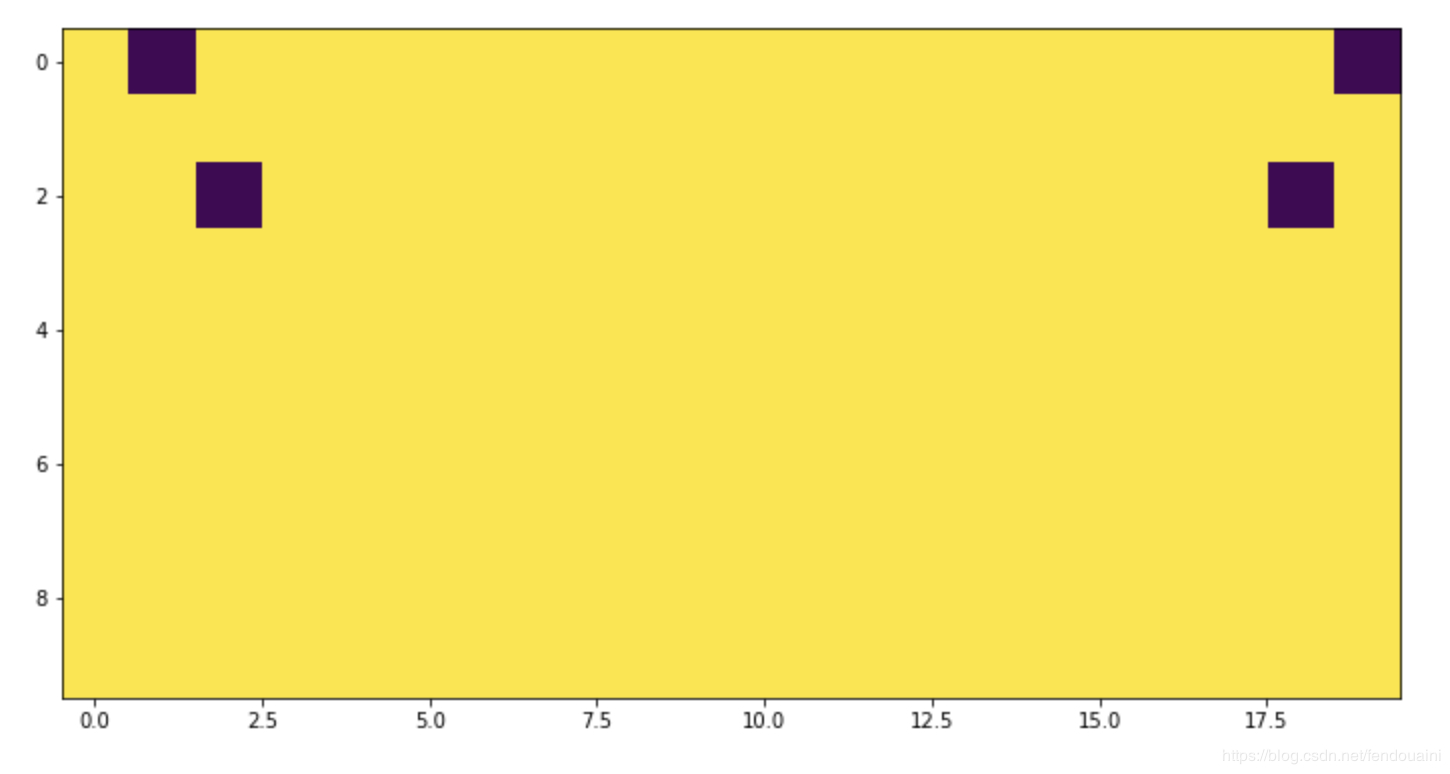
不对称看起来很奇怪!如果我们检查极值的情况呢?
image = np.ones((10, 10), dtype=np.float32)
kpts = [(0, 0), (1, 1)]
image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)
img1 = image.copy()
for y, x in kpts:
img1[y, x] = 0
img2 = image_flipped.copy()
for y, x in kpts_flipped:
img2[y, x] = 0out:
IndexError
Traceback (most recent call last)
<ipython-input-5-997162463eae> in <module>
8 img2 = image_flipped.copy()
9 for y, x in kpts_flipped:
---> 10 img2[y, x] = 0
IndexError: index 10 is out of bounds for axis 1 with size 10程序报错了!这是一个典型的差一误差。正确的代码是这样的:
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):
img = np.fliplr(img)
h, w, *_ = img.shape
kpts = [(y, w - x - 1) for y, x in kpts]
return img, kpts我们可以通过可视化来检测这个问题,而在x = 0点的单元测试也会有帮助。
2.还是关键点问题
即使在上述错误被修复之后,仍然存在问题。现在更多的是语义上的问题,而不仅仅是代码上的问题。
假设需要增强具有两只手掌的图像。看起来好像没问题-左右翻转后手还是手。
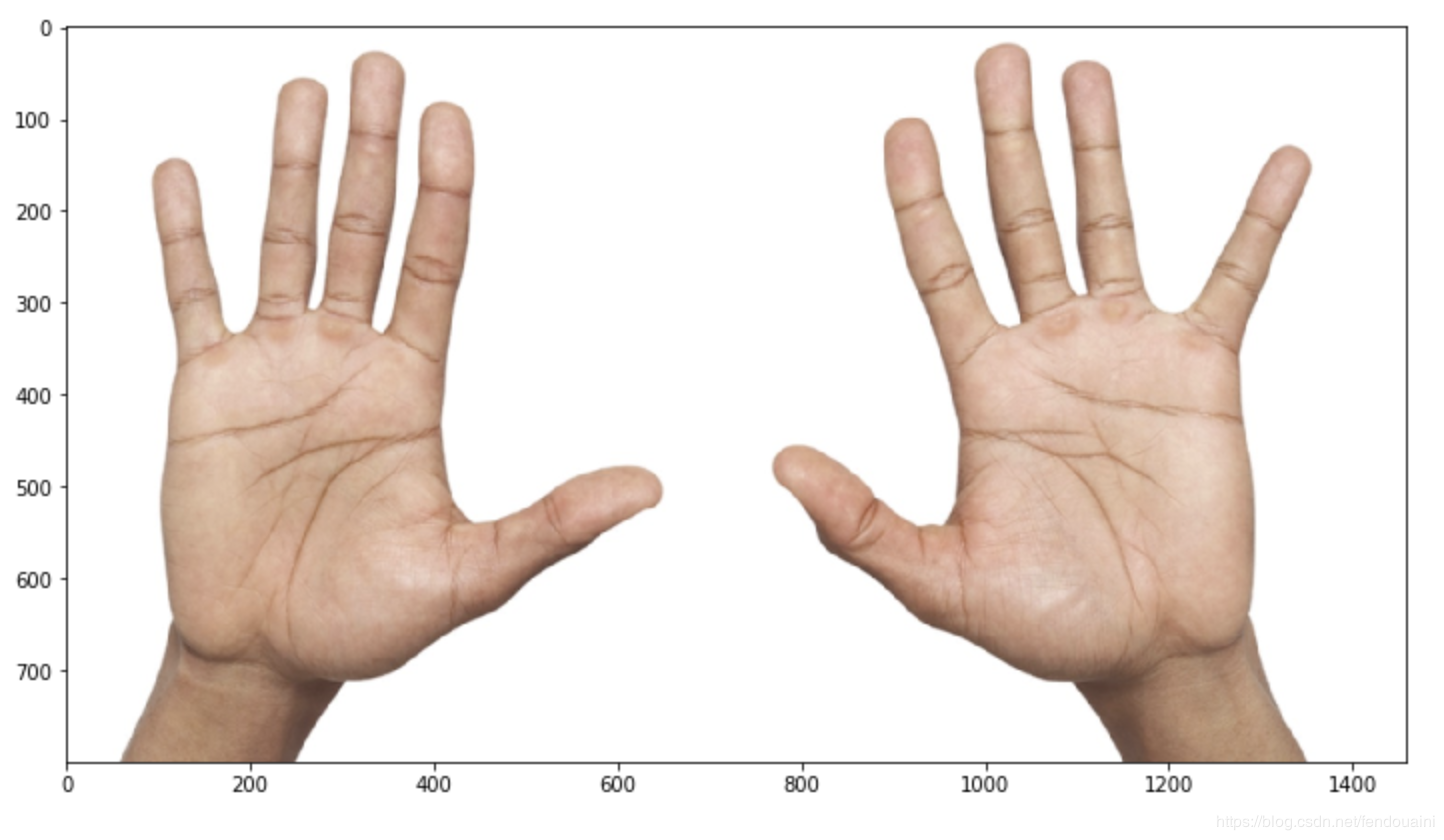
但是等等!我们对我们拥有的关键点语义一无所知。如果这个关键点的意思是这样的:
kpts = [
(20, 20), # 左小指
(20, 200), # 右小指
...
]
这意味着增强实际上改变了语义:左变成右,右变成左,但我们不交换数组中的关键点索引。它会给训练带来大量的噪音和更糟糕的度量。
我们应该吸取教训:
- 在应用增强或其他特性之前,要了解和考虑数据结构和语义;
- 保持你的实验原子性:添加一个小的变化(例如一个新的变换),如果分数已经提高,检查它如何进行和合并。
3.编码自定义损失函数
熟悉语义分割问题的人可能知道IoU度量。不幸的是,我们不能直接用SGD来优化它,所以常用的方法是用可微损失函数来近似它。让我们编码实现一个!
def iou_continuous_loss(y_pred, y_true):
eps = 1e-6
def _sum(x):
return x.sum(-1).sum(-1)
numerator = (_sum(y_true * y_pred) eps)
denominator = (_sum(y_true ** 2) _sum(y_pred ** 2)
- _sum(y_true * y_pred) eps)
return (numerator / denominator).mean()看起来不错,让我们测试一下:
In [3]: ones = np.ones((1, 3, 10, 10))
...: x1 = iou_continuous_loss(ones * 0.01, ones)
...: x2 = iou_continuous_loss(ones * 0.99, ones)
In [4]: x1, x2
Out[4]: (0.010099999897990103, 0.9998990001020204)在x1中,我们计算了与正确数据完全不同的数据的损失,而x2则是非常接近正确数据的数据损失结果。我们期望x1很大因为预测很糟糕,x2应该接近0。但是结果与我期望的有差别,哪里出现错误了呢?
上面的函数是度量的一个很好的近似。度量不是一种损失:它通常(包括这种情况)越高越好。当我们使用SGD最小化损失时,我们应该做一些改变:
def iou_continuous(y_pred, y_true):
eps = 1e-6
def _sum(x):
return x.sum(-1).sum(-1)
numerator = (_sum(y_true * y_pred) eps)
denominator = (_sum(y_true ** 2) _sum(y_pred ** 2)
- _sum(y_true * y_pred) eps)
return (numerator / denominator).mean()
def iou_continuous_loss(y_pred, y_true):
return 1 - iou_continuous(y_pred, y_true)这些问题可以从两个方面来确定:
- 编写一个单元测试来检查损失的方向
- 运行健全性检查
4.当我们遇到Pytorch的时候
假设有一个预先训练好的模型。编写基于ceevee API的Predictor 类。
from ceevee.base import AbstractPredictor
class MySuperPredictor(AbstractPredictor):
def __init__(self,
weights_path: str,
):
super().__init__()
self.model = self._load_model(weights_path=weights_path)
def process(self, x, *kw):
with torch.no_grad():
res = self.model(x)
return res
@staticmethod
def _load_model(weights_path):
model = ModelClass()
weights = torch.load(weights_path, map_location=''cpu'')
model.load_state_dict(weights)
return model这个代码正确吗?也许!对于某些模型来说确实是正确的。例如,当模型没有dropout或norm 层,如torch.nn.BatchNorm2d。
但是对于大多数计算机视觉应用来说,代码忽略了一些重要的东西:转换到评估模式。
如果试图将动态PyTorch图转换为静态PyTorch图,这个问题很容易意识到。torch.jit模块用于这种转换。
In [3]: model = nn.Sequential(
...: nn.Linear(10, 10),
...: nn.Dropout(.5)
...: )
...:
...: traced_model = torch.jit.trace(model, torch.rand(10))
/Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/jit/__init__.py:914: TracerWarning: Trace had nondeterministic nodes. Did you forget call .eval() on your model? Nodes:
: Float(10) = aten::dropout(%input, , ), scope: Sequential/Dropout[1] # /Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/nn/functional.py:806:0
This may cause errors in trace checking. To disable trace checking, pass check_trace=False to torch.jit.trace()
check_tolerance, _force_outplace, True, _module_class)
/Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/jit/__init__.py:914: TracerWarning: Output nr 1. of the traced function does not match the corresponding output of the Python function. Detailed error:
Not within tolerance rtol=1e-05 atol=1e-05 at input[5] (0.0 vs. 0.5454154014587402) and 5 other locations (60.00%)
check_tolerance, _force_outplace, True, _module_class)一个简单的解决办法:
In [4]: model = nn.Sequential(
...: nn.Linear(10, 10),
...: nn.Dropout(.5)
...: )
...:
...: traced_model = torch.jit.trace(model.eval(), torch.rand(10))
# 没有警告!torch.jit.trace运行模型几次并比较结果。然而torch.jit.trace并不是万能的,你应该了解并记住。
5.复制粘贴问题
很多东西都是成对存在的:训练和验证、宽度和高度、纬度和经度……如果你仔细阅读,你会很容易发现一个bug是由某一个成员中复制粘贴到另外一个成员中引起的:
def make_dataloaders(train_cfg, val_cfg, batch_size):
train = Dataset.from_config(train_cfg)
val = Dataset.from_config(val_cfg)
shared_params = {''batch_size'': batch_size, ''shuffle'': True, ''num_workers'': cpu_count()}
train = DataLoader(train, **shared_params)
val = DataLoader(train, **shared_params)
return train, val不仅仅是我犯了愚蠢的错误,例如。流行的albumentations库中也有类似的问题。
# https://github.com/albu/albumentations/blob/0.3.0/albumentations/augmentations/transforms.py
def apply_to_keypoint(self, keypoint, crop_height=0, crop_width=0, h_start=0, w_start=0, rows=0, cols=0, **params):
keypoint = F.keypoint_random_crop(keypoint, crop_height, crop_width, h_start, w_start, rows, cols)
scale_x = self.width / crop_height
scale_y = self.height / crop_height
keypoint = F.keypoint_scale(keypoint, scale_x, scale_y)
return keypoint不过别担心,现在已经修复好了。
如何避免?尽量以不需要复制和粘贴的方式编写代码。
下面这种编程方式不是一个好的方式:
datasets = []
data_a = get_dataset(MyDataset(config[''dataset_a'']), config[''shared_param''], param_a)
datasets.append(data_a)
data_b = get_dataset(MyDataset(config[''dataset_b'']), config[''shared_param''], param_b)
datasets.append(data_b)而下面的方式看起来好多了:
datasets = []
for name, param in zip((''dataset_a'', ''dataset_b''),
(param_a, param_b),
):
datasets.append(get_dataset(MyDataset(config[name]), config[''shared_param''], param))6.正确的数据类型
让我们编写一个新的增强:
def add_noise(img: np.ndarray) -> np.ndarray:
mask = np.random.rand(*img.shape) .5
img = img.astype(''float32'') * mask
return img.astype(''uint8'')图像已被更改。这是我们所期望的吗?嗯,可能修改得有点过了。这里有一个危险的操作:将float32转换为uint8。它可能会导致溢出:
def add_noise(img: np.ndarray) -> np.ndarray:
mask = np.random.rand(*img.shape) .5
img = img.astype(''float32'') * mask
return np.clip(img, 0, 255).astype(''uint8'')
img = add_noise(cv2.imread(''two_hands.jpg'')[:, :, ::-1])
_ = plt.imshow(img)看起来好多了,是吧?
顺便说一句,还有一种方法可以避免这个问题:不要重造轮子,不要从头开始编写增强代码,而是使用现有的增强,比如:albumentations.augmentations.transforms.GaussNoise。
我曾经犯过另一个同样的错误。
raw_mask = cv2.imread(''mask_small.png'')
mask = raw_mask.astype(''float32'') / 255
mask = cv2.resize(mask, (64, 64), interpolation=cv2.INTER_LINEAR)
mask = cv2.resize(mask, (128, 128), interpolation=cv2.INTER_CUBIC)
mask = (mask * 255).astype(''uint8'')
_ = plt.imshow(np.hstack((raw_mask, mask)))这里出了什么问题?首先,用三次样条插值调整mask的大小是一个坏主意。与转换float32到uint8的问题是一样的:三次样条插值的输出值会大于输入值,会导致溢出。

我在做可视化的时候发现了这个问题。在你的训练循环中到处使用断言也是一个好主意。
7. 拼写错误发生
假设需要对全卷积网络(如语义分割问题)和一个巨大的图像进行推理。该图像是如此巨大,没有机会把它放在你的GPU上 -例如,它可以是一个医疗或卫星图像。
在这种情况下,可以将图像分割成网格,独立地对每一块进行推理,最后合并。此外,一些预测交叉可能有助于平滑边缘的伪影
让我们编码实现吧!
from tqdm import tqdm
class GridPredictor:
"""
你有GPU内存限制时,此类可用于预测大图像的分割掩码
"""
def __init__(self, predictor: AbstractPredictor, size: int, stride: Optional[int] = None):
self.predictor = predictor
self.size = size
self.stride = stride if stride is not None else size // 2
def __call__(self, x: np.ndarray):
h, w, _ = x.shape
mask = np.zeros((h, w, 1), dtype=''float32'')
weights = mask.copy()
for i in tqdm(range(0, h - 1, self.stride)):
for j in range(0, w - 1, self.stride):
a, b, c, d = i, min(h, i self.size), j, min(w, j self.size)
patch = x[a:b, c:d, :]
mask[a:b, c:d, :] = np.expand_dims(self.predictor(patch), -1)
weights[a:b, c:d, :] = 1
return mask / weights有一个符号输入错误,可以很容易地找到它,检查代码是否正确:
class Model(nn.Module):
def forward(self, x):
return x.mean(axis=-1)
model = Model()
grid_predictor = GridPredictor(model, size=128, stride=64)
simple_pred = np.expand_dims(model(img), -1)
grid_pred = grid_predictor(img)
np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)AssertionError Traceback (most recent call last)
<ipython-input-24-a72034c717e9> in <module>
9 grid_pred = grid_predictor(img)
10
---> 11 np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)
~/.pyenv/versions/3.6.6/lib/python3.6/site-packages/numpy/testing/_private/utils.py in assert_allclose(actual, desired, rtol, atol, equal_nan, err_msg, verbose)
1513 header = ''Not equal to tolerance rtol=%g, atol=%g'' % (rtol, atol)
1514 assert_array_compare(compare, actual, desired, err_msg=str(err_msg),
-> 1515 verbose=verbose, header=header, equal_nan=equal_nan)
1516
1517
~/.pyenv/versions/3.6.6/lib/python3.6/site-packages/numpy/testing/_private/utils.py in assert_array_compare(comparison, x, y, err_msg, verbose, header, precision, equal_nan, equal_inf)
839 verbose=verbose, header=header,
840 names=(''x'', ''y''), precision=precision)
--> 841 raise AssertionError(msg)
842 except ValueError:
843 import traceback
AssertionError:
Not equal to tolerance rtol=1e-07, atol=0.001
Mismatch: 99.6%
Max absolute difference: 765.
Max relative difference: 0.75000001
x: array([[[215.333333],
[192.666667],
[250. ],...
y: array([[[ 215.33333],
[ 192.66667],
[ 250. ],...call方法的正确版本如下:
def __call__(self, x: np.ndarray):
h, w, _ = x.shape
mask = np.zeros((h, w, 1), dtype=''float32'')
weights = mask.copy()
for i in tqdm(range(0, h - 1, self.stride)):
for j in range(0, w - 1, self.stride):
a, b, c, d = i, min(h, i self.size), j, min(w, j self.size)
patch = x[a:b, c:d, :]
mask[a:b, c:d, :] = np.expand_dims(self.predictor(patch), -1)
weights[a:b, c:d, :] = 1
return mask / weights如果你仍然不知道问题是什么,注意行weights[a:b, c:d, :] = 1。
8.Imagenet归一化
当一个人需要做迁移学习时,用训练Imagenet时的方法将图像归一化通常是一个好主意。
让我们使用熟悉的albumentations来实现:
from albumentations import Normalize
norm = Normalize()
img = cv2.imread(''img_small.jpg'')
mask = cv2.imread(''mask_small.png'', cv2.IMREAD_GRAYSCALE)
mask = np.expand_dims(mask, -1) # shape (64, 64) -> shape (64, 64, 1)
normed = norm(image=img, mask=mask)
img, mask = [normed[x] for x in [''image'', ''mask'']]
def img_to_batch(x):
x = np.transpose(x, (2, 0, 1)).astype(''float32'')
return torch.from_numpy(np.expand_dims(x, 0))
img, mask = map(img_to_batch, (img, mask))
criterion = F.binary_cross_entropy现在是时候训练一个网络并对单个图像进行拟合——正如我所提到的,这是一种很好的调试技术:
model_a = UNet(3, 1)
optimizer = torch.optim.Adam(model_a.parameters(), lr=1e-3)
losses = []
for t in tqdm(range(20)):
loss = criterion(model_a(img), mask)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
_ = plt.plot(losses)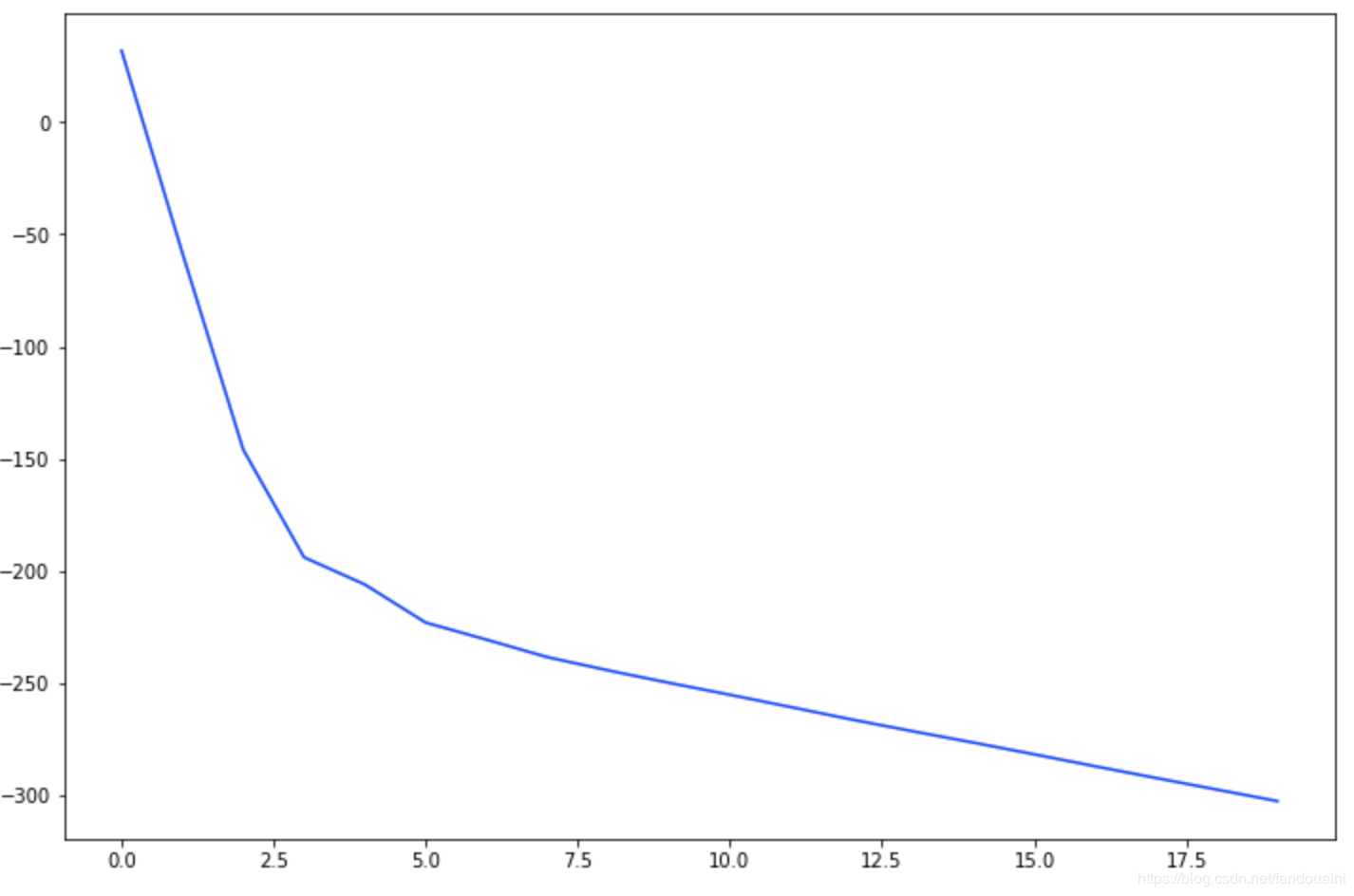
曲率看起来很好,但是-300不是我们期望的交叉熵的损失值。是什么问题?
归一化处理图像效果很好,但掩码需要缩放到[0,1]之间。
model_b = UNet(3, 1)
optimizer = torch.optim.Adam(model_b.parameters(), lr=1e-3)
losses = []
for t in tqdm(range(20)):
loss = criterion(model_b(img), mask / 255.)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
_ = plt.plot(losses)在训练循环时一个简单运行断言(例如assert mask.max() <= 1)可以很快地检测到问题。同样,也可以是单元测试。
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/

C# 获取计算机相关信息
整理了一个关于计算机相关系统的资料
需要引入命名空间:
1. 在''解决方案资源管理器'' 窗口中->右击项目-> ''添加'' -> ''引用'' 弹出引用管理器
2. 在引用处理器中,程序集-> 框架 -> 选中 ''System.Management'' -> 确认
using System;
using System.Management;
using System.IO;using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Management;
using System.IO;
namespace WindowsFormsApp1
{
/// <summary>
/// 计算机信息类
/// </summary>
public class GetComputerInfo
{
public string CpuID;//Cpu编号
public string MacAddress;//Mac地址
public string DiskID;//磁盘ID
public string IpAddress;//IP地址
public string LoginUserName;//系统用户名
public string ComputerName;//计算机名称
public string SystemType;//系统类型
public string TotalPhysicalMemory; //单位:M
private static GetComputerInfo _instance;
public static GetComputerInfo GetInstance()
{
if (_instance == null)
_instance = new GetComputerInfo();
return _instance;
}
public GetComputerInfo()
{
CpuID = GetCpuID();
MacAddress = GetMacAddress();
DiskID = GetDiskID();
IpAddress = GetIPAddress();
LoginUserName = GetUserName();
SystemType = GetSystemType();
TotalPhysicalMemory = GetTotalPhysicalMemory();
ComputerName = GetComputerName();
}
/// <summary>
/// 获取CPU的个数
/// </summary>
/// <returns></returns>
public static int GetCpuCount()
{
try
{
using (ManagementClass mCpu = new ManagementClass("Win32_Processor"))
{
ManagementObjectCollection cpus = mCpu.GetInstances();
return cpus.Count;
}
}
catch
{
}
return -1;
}
/// <summary>
/// 获取CPU的频率 这里之所以使用string类型的数组,主要是因为cpu的多核
/// </summary>
/// <returns></returns>
public static string[] GetCpuMHZ()
{
ManagementClass mc = new ManagementClass("Win32_Processor");
ManagementObjectCollection cpus = mc.GetInstances();
string[] mHz = new string[cpus.Count];
int c = 0;
ManagementObjectSearcher mySearch = new ManagementObjectSearcher("select * from Win32_Processor");
foreach (ManagementObject mo in mySearch.Get())
{
mHz[c] = mo.Properties["CurrentClockSpeed"].Value.ToString();
c++;
}
mc.Dispose();
mySearch.Dispose();
return mHz;
}
/// <summary>
/// 获取本机硬盘的大小
/// </summary>
/// <returns></returns>
public static string GetSizeOfDisk()
{
ManagementClass mc = new ManagementClass("Win32_DiskDrive");
ManagementObjectCollection moj = mc.GetInstances();
foreach (ManagementObject m in moj)
{
return m.Properties["Size"].Value.ToString();
}
return "-1";
}
/// <summary>
/// 获取本机内存的大小:
/// </summary>
/// <returns></returns>
public static string GetSizeOfMemery()
{
ManagementClass mc = new ManagementClass("Win32_OperatingSystem");
ManagementObjectCollection moc = mc.GetInstances();
double sizeAll = 0.0;
foreach (ManagementObject m in moc)
{
if (m.Properties["TotalVisibleMemorySize"].Value != null)
{
sizeAll += Convert.ToDouble(m.Properties["TotalVisibleMemorySize"].Value.ToString());
}
}
mc = null;
moc.Dispose();
return sizeAll.ToString();
}
/// <summary>
/// 获取磁盘剩余空间
/// </summary>
/// <param name="str_HardDiskName"></param>
/// <returns></returns>
long GetHardDiskFreeSpace(string str_HardDiskName)
{
long num = 0L;
str_HardDiskName = str_HardDiskName + @":\";
foreach (DriveInfo info in DriveInfo.GetDrives())
{
if (info.Name.ToUpper() == str_HardDiskName.ToUpper())
{
num = info.TotalFreeSpace / 0x100000L;
}
}
return num;
}
//获得CPU编号
string GetCpuID()
{
try
{
//获取CPU序列号代码
string cpuInfo = "";//cpu序列号
ManagementClass mc = new ManagementClass("Win32_Processor");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
cpuInfo = mo.Properties["ProcessorId"].Value.ToString();
}
moc = null;
mc = null;
return cpuInfo;
}
catch
{
return "unknow";
}
}
//获得Mac地址
string GetMacAddress()
{
try
{
//获取网卡硬件地址
string mac = "";
ManagementClass mc = new ManagementClass("Win32_NetworkAdapterConfiguration");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
if ((bool)mo["IPEnabled"] == true)
{
mac = mo["MacAddress"].ToString();
break;
}
}
moc = null;
mc = null;
return mac;
}
catch
{
return "unknow";
}
}
//获得Ip地址
string GetIPAddress()
{
try
{
//获取IP地址
string st = "";
ManagementClass mc = new ManagementClass("Win32_NetworkAdapterConfiguration");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
if ((bool)mo["IPEnabled"] == true)
{
//st=mo["IpAddress"].ToString();
System.Array ar;
ar = (System.Array)(mo.Properties["IpAddress"].Value);
st = ar.GetValue(0).ToString();
break;
}
}
moc = null;
mc = null;
return st;
}
catch
{
return "unknow";
}
}
//获得磁盘Id
string GetDiskID()
{
try
{
//获取硬盘ID
String HDid = "";
ManagementClass mc = new ManagementClass("Win32_DiskDrive");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
HDid = (string)mo.Properties["Model"].Value;
}
moc = null;
mc = null;
return HDid;
}
catch
{
return "unknow";
}
}
/// <summary>
/// 操作系统的登录用户名
/// </summary>
/// <returns></returns>
string GetUserName()
{
try
{
string st = "";
ManagementClass mc = new ManagementClass("Win32_ComputerSystem");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
st = mo["UserName"].ToString();
}
moc = null;
mc = null;
return st;
}
catch
{
return "unknow";
}
}
/// <summary>
/// PC类型
/// </summary>
/// <returns></returns>
string GetSystemType()
{
try
{
string st = "";
ManagementClass mc = new ManagementClass("Win32_ComputerSystem");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
st = mo["SystemType"].ToString();
}
moc = null;
mc = null;
return st;
}
catch
{
return "unknow";
}
}
/// <summary>
/// 物理内存
/// </summary>
/// <returns></returns>
string GetTotalPhysicalMemory()
{
try
{
string st = "";
ManagementClass mc = new ManagementClass("Win32_ComputerSystem");
ManagementObjectCollection moc = mc.GetInstances();
foreach (ManagementObject mo in moc)
{
st = mo["TotalPhysicalMemory"].ToString();
}
moc = null;
mc = null;
return st;
}
catch
{
return "unknow";
}
}
/// <summary>
/// 获取计算机名称
/// </summary>
/// <returns></returns>
string GetComputerName()
{
try
{
return System.Environment.GetEnvironmentVariable("ComputerName");
}
catch
{
return "unknow";
}
}
}
}ok,今天分享到这了,如果有疑问的可以留言,讲的不对的欢迎指出!!!
关于本科阶段,一门计算机相关课结束后,应该留下些什么?和计算机专业一节课多长时间的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于1.计算机发展阶段 计算机发展历史 机械式计算机 机电式计算机 电子计算机 逻辑电路与计算机 二极管 电子管 晶体管 硅 门电路 计算机 电磁学计算机二进制、2020 年,哪一门计算机技能最当红?、8个深度学习/计算机视觉错误,应该如何避免它们、C# 获取计算机相关信息等相关内容,可以在本站寻找。
本文标签:




