在本文中,我们将带你了解DockerSwanm集群配置在这篇文章中,我们将为您详细介绍DockerSwanm集群配置的方方面面,并解答dockerswarm集群常见的疑惑,同时我们还将给您一些技巧,以
在本文中,我们将带你了解Docker Swanm集群配置在这篇文章中,我们将为您详细介绍Docker Swanm集群配置的方方面面,并解答docker swarm集群常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的010 docker搭建swarm集群、8天入门docker系列 —— 第八天 让程序跑在swarm集群上、ansible-playbook部署Docker Swarm集群、Ceph实现DockerSwarm集群共享存储的尝试。
本文目录一览:- Docker Swanm集群配置(docker swarm集群)
- 010 docker搭建swarm集群
- 8天入门docker系列 —— 第八天 让程序跑在swarm集群上
- ansible-playbook部署Docker Swarm集群
- Ceph实现DockerSwarm集群共享存储的尝试
")
Docker Swanm集群配置(docker swarm集群)
首先 可以用ContOS虚拟机 克隆 5个虚拟机,注意(克隆主机必须装了Docker,克隆后,克隆机都会有Docker)
配置 网络
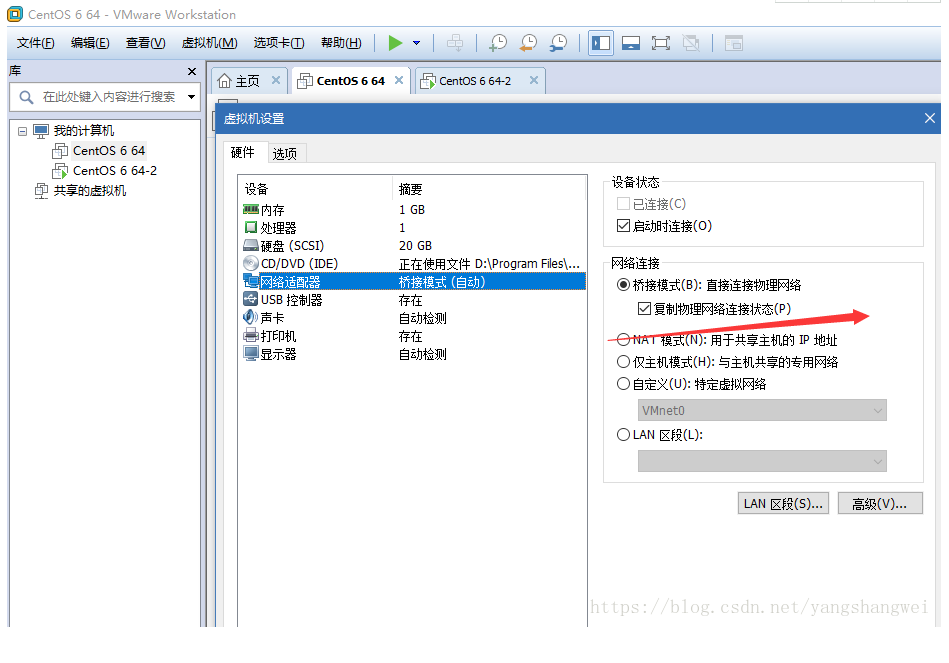
克隆CentOS虚拟机

最后和到如下结果
打开2377端口
firewall-cmd --zone=public --add-port=2377/tcp --permanent
重启防火墙
firewall-cmd --reload
然后进入CentOS 7 64位
初始化 Swarm
sudo docker swarm init --advertise-addr 192.168.0.102:2377 --listen-addr 192.168.0.102:2377
A: (初始化后Swarm后可以通过 docker swarm join-token worker 查看Swarm的Token信息 )

上图下箭头即是添加功能节点命令,代码如下:
sudo docker swarm join --token SWMTKN-1-1fmeankvtj5x8483gsxuhgwvhrdt2yt6japzopemjcucv8ykit-4xj0shobna3bu2u1tk377z2ch 192.168.0.102:2377 --advertise-addr 192.168.0.105:2377 --listen-addr 192.168.0.105:2377
B: 查看添管理能节点命令
docker swarm join-token manager

上图下箭头即是添加管理节点命令 (注意 先关闭添加管理节点机器的防火墙,不然可能不成功),代码如下:
sudo docker swarm join --token SWMTKN-1-1fmeankvtj5x8483gsxuhgwvhrdt2yt6japzopemjcucv8ykit-4xj0shobna3bu2u1tk377z2ch 192.168.0.102:2377 --advertise-addr 192.168.0.104:2377 --listen-addr 192.168.0.104:2377
可以通过Docker info查看相关信息

添加管理节点 (注意 先关闭104的
防火墙,不然可能不成功)
先登入另一台虚拟机

关闭防火墙
systemctl stop firewalld

添加管理节点
sudo docker swarm join --token SWMTKN-1-1fmeankvtj5x8483gsxuhgwvhrdt2yt6japzopemjcucv8ykit-4xj0shobna3bu2u1tk377z2ch 192.168.0.102:2377 --advertise-addr 192.168.0.104:2377 --listen-addr 192.168.0.104:2377
![]()
添加功能节点
sudo docker swarm join --token SWMTKN-1-1fmeankvtj5x8483gsxuhgwvhrdt2yt6japzopemjcucv8ykit-4xj0shobna3bu2u1tk377z2ch 192.168.0.102:2377 --advertise-addr 192.168.0.105:2377 --listen-addr 192.168.0.105:2377

创建Swarm Service

这里的five是我用.net Core创建的Image,现在我要用这个境像创建5个Swarm Servie容器
sudo docker service create --name myfiveweb -p 8080:5000 --replicas 5 five

查看Swarm Service 运行情况
docker service ls

详情
docker service ps myfiveweb
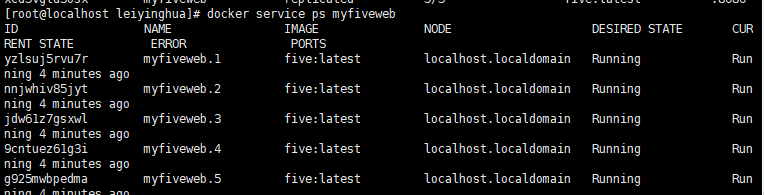
查看Docker 节点信息
docker node ls

如果报 docker node ls错:
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It''s possible that too few managers are online. Make sure more than half of the managers are online.
解决方法:
docker swarm init --force-new-cluster
提升为管理节点命令
sudo docker node promote fhdpncl3ay8vl5ogmbdh42ia8
将管理节点降级
docker node demote 0nbt 降级
删了节点
先在节点机器上执行
sudo docker swarm leave --force
然后再Swarm主管理机上执行
docker node rm ablwad6b 删除

010 docker搭建swarm集群
1.前言
刚开始找资料搭建时,发现网上有两种搭建方式:
第一种:docker run --rm swarm create 一代 Swarm,也被称为 Docker Swarm
第二种:docker swarm init 二代 Swarm,这是内置的 Swarm
本文采用第二种方式搭建swarm集群
2.搭建
假设有三台机器:192.168.20.201 192.168.20.202 192.168.20.203,准备用 201 作为master
2-1创建管理节点
docker swarm init --advertise-addr 192.168.20.201执行完会显示token,创建工作节点时需要该token,Manager和Worker节点之间通信端口是2377
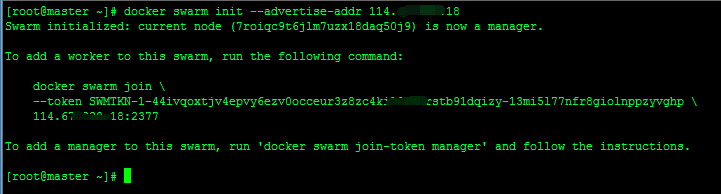
2-2创建子节点
分别在 192.168.20.202 和 192.168.20.203 上执行命令,指定IP:--advertise-addr 192.168.20.202,
我用的是三台云主机,内网不通,必须用 --advertise-addr 指定当前机器IP,否则会造成后面网络不通
docker swarm join --advertise-addr 192.168.20.202 --token 上面的token 192.168.20.202:2377
docker swarm join --advertise-addr 192.168.20.203 --token 上面的token 192.168.20.203:2377
![]()
2-3查看集群信息
该命令只能在master上执行
docker node ls
2-4查看节点IP信息
docker node inspect master
docker node inspect slave01
docker node inspect slave02可以分别查看swarm中各主机的IP,如果跟机器IP不一样,网络会访问不通

3.配置跨主机网络访问
3-1配置docker启动参数
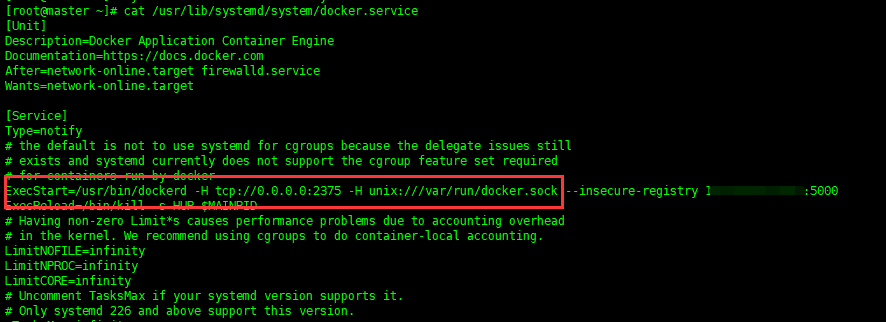
在 /usr/lib/systemd/system/docker.service 中找到 ExecStart=/usr/bin/dockerd 并在其后添加 :
-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock 结果如下:
3-2新建overlay网络
docker network create -d overlay central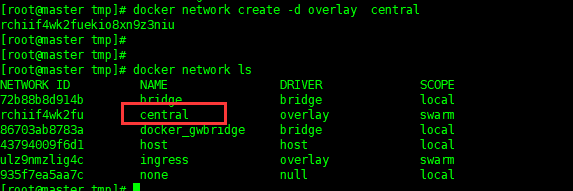
4.测试
4-1从仓库拉取一个tomcat镜像
docker pull tomcat
docker tag docker.io/tomcat tomcat4-2启动镜像,指定网络类型
docker service create -p 8080:8080 --replicas 3 --name web --network central tomcat
4-3查看相关信息
docker service ls
#web为启动镜像时的名称
docker service ps web
4-4查看是否在同一网络中
docker network inspect centralcentral 是我们启动服务时使用的 overlay 网络,由于服务分到了三台机器上,这三台机器都加入了central网络,这样三台主机才能互通
4-4访问测试
分别在 三台机器上 docker ps 均能看见Tomcat项目在运行,用浏览器分别访问:192.168.20.201-3:8080 都会出现tomcat首页
4-5主机互通测试
分别在 master 和 slave01 执行命令,查看到二者的容器IP:
# 查看容器信息,记下这里的 CONTAINER ID 和 NAMES
docker ps
# 查看容器详细信息
docker inspect f884d3151995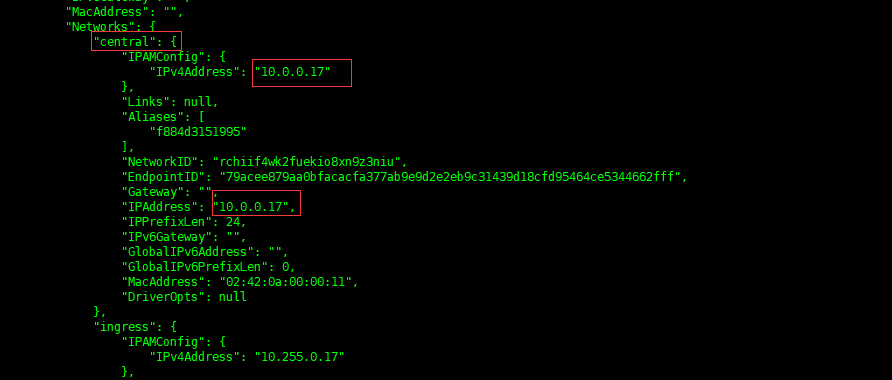
进入 slave02 的容器:
docker ps
docker exec -it da10f3f58af7 /bin/bash
测试网络,如果能ping通,则成功,如果不成功,兄弟,那就看缘分了
# 容器IP
ping 10.0.0.17
ping 10.0.0.18
# 容器NAMES
ping web.2.yru4aykeld6h5kgg3nryw0m74
ping web.1.7gqta8k7sf8vbsvyvcxnx8vhd另外,docker stop其中一台机器上的服务,服务会重新自动新建一个:
![]()

移除运行项目,必须在master执行:
docker service rm web4.删除swarm
首先在所有子节点机器执行:
# 子节点退出swarm
docker swarm leave然后master执行:
# 主节点移除子节点
docker node rm slave01
docker node rm slave02
# 主节点退出集群
docker swarm leave --force

8天入门docker系列 —— 第八天 让程序跑在swarm集群上
真正的落地部署都是希望程序跑在集群下,而不是单机版下测测玩玩,所以这篇就来聊一下怎么使用docker swarm进行部署,因为是swarm是docker自带的,
所以部署起来还是非常简单的。
一:前置条件
准备三台centos机器:
192.168.23.154 manager
192.168.23.155 work1
192.168.23.156 work2
二:构建集群
1. manger节点上使用 docker swarm init 即可创建只有一个master节点的集群。
[root@manager ~]# docker swarm init
Swarm initialized: current node (h303fwvspazsv74h6jcj0urz3) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0wakl67xyg5ia13yhvd7rvs7anvh6yn2t9tqcu8wxhpel26gjc-9bror7wo9dh2e7nswwtpjyd0u 192.168.23.154:2377
To add a manager to this swarm, run ''docker swarm join-token manager'' and follow the instructions.
2. 将上面红色字体copy到work1和work2 这两个node节点即可,这样就可以构建3个节点的swarm集群。
《1》 work1
[root@work1 ~]# docker swarm join --token SWMTKN-1-0wakl67xyg5ia13yhvd7rvs7anvh6yn2t9tqcu8wxhpel26gjc-9bror7wo9dh2e7nswwtpjyd0u 192.168.23.154:2377
This node joined a swarm as a worker.
《2》 work2
[root@work2 ~]# docker swarm join --token SWMTKN-1-0wakl67xyg5ia13yhvd7rvs7anvh6yn2t9tqcu8wxhpel26gjc-9bror7wo9dh2e7nswwtpjyd0u 192.168.23.154:2377
This node joined a swarm as a worker.
最后到manager节点查看一下三台机器的分布情况。
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
h303fwvspazsv74h6jcj0urz3 * manager Ready Active Leader 18.09.6
zaud8bjpttqno3swqjilfzbo3 work1 Ready Active 18.09.6
ihxnypgl1wamfv583xonl483f work2 Ready Active 18.09.6
三:程序部署
程序还是采用上节课说到的python+redis,现在有了三个节点,我希望web程序可以有5个镜像,redis因为是db服务,所以尽量安排在某一个节点寄存,这是因为
如果redis做成了多个,db文件没不好同步处理了,当然你可以采用类似的clusterfs来实现多机器间的db同步,这里就不麻烦了,接下来我来画一张部署图。

这里要注意的一点就是,集群中的manager节点不仅可以作为调度节点,同时也可以兼职work节点的功能,直白一点就是可以在manager上跑容器。
1. pythonweb 推送到远程
前面博文中我只在本地做了一个build,其实在swarm部署中是建议全部做成镜像,然后推送到自己的docker registry中,这样各个work节点只需要从远程拉取
镜像即可,不需要带着一些源码文件到处跑。
[root@manager data]# docker build -t webapp .
Sending build context to Docker daemon 6.144kB
Step 1/6 : FROM python:2.7-slim
2.7-slim: Pulling from library/python
f5d23c7fed46: Pull complete
cdc362a1b8d3: Pull complete
d43d1ec67d25: Pull complete
0269ba15cf1b: Pull complete
Digest: sha256:4149310fdae239c7b09aa5fa04263e86b89d11da9bfb1116b4f74782358bfea8
[root@manager data]# docker tag webapp:latest huangxincheng520/webapp:latest
[root@manager data]# docker push huangxincheng520/webapp:latest
The push refers to repository [docker.io/huangxincheng520/webapp]
48e326095e39: Layer already exists
2be3ac14ba61: Pushed
fb23e9b75b52: Layer already exists
c04915bf1261: Layer already exists
32d47307f796: Layer already exists
c86aa07d5fdb: Pushed
d8a33133e477: Pushed
latest: digest: sha256:2c79581255988e78efa97ec9b5c43d742ce8b9535b00660f8e7061f2a0d1d30d size: 1788
2. docker-compose
version: "3"
services:
web:
image: huangxincheng520/webapp
deploy:
replicas: 5
restart_policy:
condition: on-failure
ports:
- "80:80"
networks:
- webnet
redis:
image: redis
ports:
- "6379:6379"
volumes:
- "myvol:/data"
deploy:
placement:
constraints: [node.hostname == work2]
command: redis-server --appendonly yes
networks:
- webnet
networks:
webnet:
volumes:
myvol:
如果大家了解单机版docker-compose的写法,那分布式版也就不难,主要在于deploy节点的使用。
《1》 replicas: 5 从这个可以看到,当前我希望web部署成5份,到底怎么分配由swarm集群自己决定,我只需要知道结果就可以了。
《2》 constraints: [node.hostname == work2] 可以看到,我已经要求swarm将redis部署在hostname=work2的节点上。
3. docker stack deploy
都准备好了,接下来就可以跑一下。
[root@manager data]# docker stack deploy -c ./docker-compose.yml web
Creating network web_webnet
Creating service web_web
Creating service web_redis
然后通过 docker stack ps web 看一下stack 的各服务下的所有container的部署情况。
[root@manager data]# docker stack ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
qym36md95ni6 web_redis.1 redis:latest work2 Running Running 33 seconds ago
c0zmb5j9zx6q web_web.1 huangxincheng520/webapp:latest manager Running Running 3 minutes ago
lczqz66skupc web_web.2 huangxincheng520/webapp:latest work2 Running Running 3 minutes ago
ota9lz0aws21 web_web.3 huangxincheng520/webapp:latest work1 Running Running 3 minutes ago
2snnttrgoq43 web_web.4 huangxincheng520/webapp:latest manager Running Running 3 minutes ago
5735udmor57z web_web.5 huangxincheng520/webapp:latest work1 Running Running 3 minutes ago
通过命令可以看到,web确实是5个,manager上有两个,work1上有两个,work2上有一个,同时redis也是部署在work2上的,接下来我们随便通过一个ip地址
访问一下web是否可以访问的通。

现在这个横向扩容能力就非常强大了,只要机器足够,你都可以扩展到100个web,对吧,好了,本系列就说到这里,希望对你学习docker有帮助。
原文出处:https://www.cnblogs.com/huangxincheng/p/11295062.html

ansible-playbook部署Docker Swarm集群
通过ansible-playbook,部署Docker Swarm集群。
docker安装目录: /var/lib/docker docker命令目录: /usr/bin/docker compose命令目录: /usr/local/bin/docker-compose weavescope: docker可视化管理工具 scope命令目录: /usr/local/bin/scope
| role | ip | hostname |
|---|---|---|
| manager/scope | 192.168.1.51 | manager1 |
| manager/scope | 192.168.1.52 | manager2 |
| worker/scope | 192.168.1.53 | worker1 |
| worker/scope | 192.168.1.54 | worker2 |
| worker/scope | 192.168.1.55 | worker3 |
| worker/scope | 192.168.1.56 | worker4 |
| worker/scope | 192.168.1.57 | worker5 |
准备
- 将所有部署swarm集群的主机分组:
# vim /etc/ansible/hosts[manager]192.168.1.51 hostname=manager1[add_manager]192.168.1.52 hostname=manager2[add_worker]192.168.1.53 hostname=worker1 192.168.1.54 hostname=worker2 192.168.1.55 hostname=worker3 192.168.1.56 hostname=worker4 192.168.1.57 hostname=worker5
- 创建管理目录:
# mkdir -p swarm/roles/{docker_install,init_install,manager_install,worker_install,scope_install}/{files,handlers,Meta,tasks,templates,vars}# cd swarm/说明:
files:存放需要同步到异地服务器的源码文件及配置文件; handlers:当资源发生变化时需要进行的操作,若没有此目录可以不建或为空; Meta:存放说明信息、说明角色依赖等信息,可留空; tasks:Docker Swarm 安装过程中需要进行执行的任务; templates:用于执行 Docker Swarm 安装的模板文件,一般为脚本; vars:本次安装定义的变量
# tree ..├── roles │ ├── docker_install │ │ ├── files │ │ ├── handlers │ │ ├── Meta │ │ ├── tasks │ │ │ ├── install.yml │ │ │ ├── main.yml │ │ │ └── prepare.yml │ │ ├── templates │ │ └── vars │ │ └── main.yml │ ├── init_install │ │ ├── files │ │ ├── handlers │ │ ├── Meta │ │ ├── tasks │ │ │ ├── install.yml │ │ │ └── main.yml │ │ ├── templates │ │ └── vars │ ├── manager_install │ │ ├── files │ │ ├── handlers │ │ ├── Meta │ │ ├── tasks │ │ │ ├── install.yml │ │ │ └── main.yml │ │ ├── templates │ │ └── vars │ ├── scope_install │ │ ├── files │ │ ├── handlers │ │ ├── Meta │ │ ├── tasks │ │ │ ├── install.yml │ │ │ └── main.yml │ │ ├── templates │ │ └── vars │ └── worker_install │ ├── files │ ├── handlers │ ├── Meta │ ├── tasks │ │ ├── install.yml │ │ └── main.yml │ ├── templates │ └── vars └── swarm.yml 36 directories, 13 files
- 创建安装入口文件,用来调用roles:
# vim swarm.yml--- - hosts: all remote_user: root gather_facts: True roles: - docker_install - hosts: manager remote_user: root gather_facts: True roles: - init_install - hosts: add_manager remote_user: root gather_facts: True roles: - manager_install - hosts: add_worker remote_user: root gather_facts: True roles: - worker_install - hosts: all remote_user: root gather_facts: True roles: - scope_install
docker部分
- 创建docker入口文件,用来调用docker_install:
# vim docker.yml#用于批量安装Docker- hosts: all remote_user: root gather_facts: True roles: - docker_install
- 创建变量:
# vim roles/docker_install/vars/main.yml#定义docker安装中的变量COMPOSE_VER: 1.24.1
- 环境准备prepare.yml:
# vim roles/docker_install/tasks/prepare.yml
- name: 关闭firewalld service: name=firewalld state=stopped enabled=no - name: 临时关闭 selinux shell: "setenforce 0" Failed_when: false- name: 永久关闭 selinux lineinfile: dest: /etc/selinux/config regexp: "^SELINUX=" line: "SELINUX=disabled"- name: 添加EPEL仓库 yum: name=epel-release state=latest- name: 安装常用软件包 yum: name: - vim - lrzsz - net-tools - wget - curl - bash-completion - rsync - gcc - unzip - git state: latest- name: 更新系统 shell: "yum update -y" ignore_errors: yes args: warn: False
- docker安装install.yml:
# vim roles/docker_install/tasks/install.yml
- name: 创建software目录 file: name=/software state=directory- name: 更改hostname raw: "echo {{ hostname }} > /etc/hostname"- name: 更改生效 shell: "hostname {{ hostname }}"- name: 下载repo文件 shell: "if [ ! -f /etc/yum.repos.d/docker.repo ]; then curl http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker.repo; fi"- name: 生成缓存 shell: "yum makecache fast"
args:
warn: False- name: 安装docker-ce yum:
name: docker-ce state: present- name: 启动docker并开机启动 service:
name: docker state: started enabled: yes
- name: 下载docker-compose shell: "if [ ! -f /usr/local/bin/docker-compose ]; then curl -L https://github.com/docker/compose/releases/download/{{ COMPOSE_VER }}/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose; fi"
- name: 给予执行权限 file: name=/usr/local/bin/docker-compose mode=0755
- name: 提高docker pull速度 shell: "curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io"
args:
warn: False- name: 重启docker service:
name: docker state: restarted- 引用文件main.yml:
# vim roles/docker_install/tasks/main.yml#引用prepare、install模块- include: prepare.yml - include: install.yml
init部分
- 创建init入口文件,用来调用init_install:
# vim init.yml#用于初始化swarm集群- hosts: manager remote_user: root gather_facts: True roles: - init_install
- 集群初始化install.yml:
# vim roles/init_install/tasks/install.yml
- name: manager离开集群 shell: "docker swarm leave -f"
ignore_errors: yes- name: 初始化swarm集群 shell: "docker swarm init --advertise-addr {{ ansible_ssh_host }}"
- name: 获取manager的token shell: "echo `docker swarm join-token manager |grep docker` > /software/manager.sh"
- name: 获取worker的token shell: "echo `docker swarm join-token worker |grep docker` > /software/worker.sh"- name: 获取所有ip shell: "echo `ansible all -m setup -a 'filter='ansible_default_ipv4'' |grep 'address' |grep -v 'macaddress' |awk -F '\"' '{print $4}'` > /software/hosts.txt"
- name: 拷贝manager.sh shell: "ansible all -m copy -a 'src=/software/manager.sh dest=/software mode=0755'"
args:
warn: False
- name: 拷贝worker.sh shell: "ansible all -m copy -a 'src=/software/worker.sh dest=/software mode=0755'"
args:
warn: False- name: 拷贝hosts.txt shell: "ansible all -m copy -a 'src=/software/hosts.txt dest=/software'"
args:
warn: False- 引用文件main.yml:
# vim roles/init_install/tasks/main.yml#引用install模块- include: install.yml
manager部分
- 创建manager入口文件,用来调用manager_install:
# vim manager.yml#用于集群增加manager- hosts: add_manager remote_user: root gather_facts: True roles: - manager_install
- 添加manager到集群install.yml:
# vim roles/manager_install/tasks/install.yml
- name: manager离开集群 shell: "docker swarm leave -f" ignore_errors: yes- name: 集群增加manager script: /software/manager.sh
- 引用文件main.yml:
# vim roles/manager_install/tasks/main.yml#引用install模块- include: install.yml
worker部分
- 创建worker入口文件,用来调用worker_install:
# vim worker.yml#用于集群增加worker- hosts: add_worker remote_user: root gather_facts: True roles: - worker_install
- 添加worker到集群install.yml:
# vim roles/worker_install/tasks/install.yml
- name: worker离开集群 shell: "docker swarm leave -f" ignore_errors: yes - name: 集群增加worker script: /software/worker.sh
- 引用文件main.yml:
# vim roles/worker_install/tasks/main.yml#引用install模块- include: install.yml
scope部分
- 创建scope入口文件,用来调用scope_install:
# vim scope.yml#用于安装weavescope- hosts: all remote_user: root gather_facts: True roles: - scope_install
- scope安装install.yml:
# vim roles/scope_install/tasks/install.yml
- name: 下载scope shell: "if [ ! -f /usr/local/bin/scope ]; then curl -L git.io/scope -o /usr/local/bin/scope; fi"
- name: 给予执行权限 file: name=/usr/local/bin/scope mode=0755- name: 停止scope容器 shell: "docker stop weavescope && docker rm weavescope"
ignore_errors: yes- name: 启动scope容器 shell: "hosts=`cat /software/hosts.txt`; scope launch $hosts"
register: scope_url- debug: msg="{{ scope_url.stdout }}"- 引用文件main.yml:
# vim roles/scope_install/tasks/main.yml#引用install模块- include: install.yml
安装测试
- 执行安装:
# ansible-playbook swarm.yml
- 查看结果:
# docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION o6zkxtp0qmvq6r1dxydmprmi4 * manager1 Ready Active leader 19.03.4 nv1t4p8axfr1zn8k99tegsdhy manager2 Ready Active Reachable 19.03.4 thpss999qnn3e0gun3pi20oy4 worker1 Ready Active 19.03.4 y26tkhebj6u8b7psjnwghcbex worker2 Ready Active 19.03.4 7ygwplwy06sukkhag3kdu022p worker3 Ready Active 19.03.4 hzyd0fz8gx1pld5agjs9afri2 worker4 Ready Active 19.03.4 j2r873fcjqxtbf6p3xjplybee worker5 Ready Active 19.03.4
打开浏览器,访问任一节点的ip:4040

测试安装没有问题。已存放至个人gitgub:ansible-playbook

Ceph实现DockerSwarm集群共享存储的尝试
一、背景与结论
在一个四节点的Docker Swarm集群上,尝试使用Ceph作为Docker集群的共享存储,解决有状态服务在分布式环境下的数据存储问题。
经过尝试,成功使用CephFS实现了多个Docker节点之间的存储共享。但同时注意到,对于小规模Docker集群并且运维成本有限的场景,Ceph这样的分布式对象存储系统仍然显得有点重了,本文的4节点docker swarm集群上,在Ceph集群与Portainer-Agent(docker运维工具)部署之后,容器数量达到了30个。因此最终决定采用其他方案实现小规模docker集群的共享存储,比如NFS。
但Ceph作为一个高可用高性能的分布式对象/块/文件存储系统,在其他场景还是有使用价值的。
本文主要记述Ceph的搭建过程以及如何用cephfs实现docker swarm集群的共享存储。其他诸如原理机制,运维资料等请参考社区文档。
Ceph对外提供了三种存储接口,分别是对象存储 RGW(rados gateway)、块存储 RBD(rados block device) 和文件存储 CephFS。RGW是RestAPI,docker的数据卷无法直接使用。从性能角度考虑,应该是RBD最快,但本文使用的Ceph版本与使用RBD做共享存储所需要的中间件RexRay貌似存在版本不兼容问题,最终没能成功。。。
最终本文使用了CephFS来实现docker swarm集群的共享存储。
二、版本与相关资料
本文搭建Ceph使用了目前社区文档推荐的安装工具cephadm,安装的版本为octopus。四个节点的操作系统均为CentOS7。
- 社区文档入口:
https://docs.ceph.com/docs/master/ - 中文社区文档入口:
http://docs.ceph.org.cn/
注意,编写本文时,中文社区文档并非最新版本,比如社区文档中目前建议使用的安装工具cephadm在中文社区文档中就没有相关资料。三、Ceph角色规划
| No | ip | hostname | OSD盘 | Ceph角色 |
|---|---|---|---|---|
| 1 | 172.17.13.1 | manager01.xxx.com | /dev/sdb | mon,osd,ceph-mds,mgr |
| 2 | 172.17.13.2 | manager02.xxx.com | /dev/sdb | mon,osd,ceph-mds |
| 3 | 172.17.13.3 | worker01.xxx.com | /dev/sdb | mon,osd,ceph-mds |
| 4 | 172.17.13.4 | worker02.xxx.com | /dev/sdb | mon,osd,ceph-mds,mgr,cephadm,NTP服务器 |
Ceph用于存储数据的服务OSD需要使用干净的磁盘,要求如下:
- 设备没有分区
- 设备不得具有任何LVM状态
- 设备没有挂载
- 设备不包含任何文件系统
- 设备不包含ceph bluestore osd
- 设备必须大于5G
也就是给节点增加一块新磁盘之后,只要linux能识别到即可,不要做分区/格式化/mount等操作。
四、各节点环境准备工作
4.1 防火墙与Selinux
提前将Ceph相关防火墙规则设置好。或直接关闭防火墙。
firewall-cmd --permanent --zone=public --add-service=http
firewall-cmd --permanent --zone=public --add-service=https
firewall-cmd --permanent --zone=public --add-service=ceph
firewall-cmd --permanent --zone=public --add-service=ceph-mon
firewall-cmd --reload
firewall-cmd --zone=public --list-services
firewall-cmd --zone=public --add-port=3300/tcp --permanent
firewall-cmd --zone=public --add-port=3300/udp --permanent
firewall-cmd --zone=public --add-port=6789/tcp --permanent
firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
firewall-cmd --zone=public --add-port=8443/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports
Ceph集群在使用中最好禁用Selinux。在各个节点上以root用户vi /etc/selinux/config,修改:
#SELINUX=enforcing
SELINUX=disabled然后执行setenforce 0
4.2 各节点添加epel-release资源包
从阿里云镜像获取/etc/yum.repos.d/epel.repo,如下:
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
4.3 各节点安装依赖库
填坑的过程中尝试过不同的搭建方案,这里有些依赖库可能不是必须的。。。
yum -y install python3 yum-utils
yum install yum-plugin-priorities -y
yum install gcc python-setuptools python-devel -y
easy_install pip
4.4 安装Docker CE
本文的环境已经提前安装了docker ce,docker compose,并创建了docker swarm集群。
每个节点都需要先安装好Docker,具体方法参考官方文档:https://docs.docker.com/engine/install/centos/。
注意最好使用国内的dokcer安装yum镜像。
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo安装完成之后,添加docker镜像仓库地址,vi /etc/docker/daemon.json,添加:
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://dockerhub.azk8s.cn",
"https://reg-mirror.qiniu.com",
"https://hub-mirror.c.163.com",
"https://mirror.ccs.tencentyun.com",
"https://registry.docker-cn.com"
],然后重启docker服务:
systemctl daemon-reload
systemctl restart docker然后提前为每个节点拉取Ceph相关镜像:
docker pull ceph/ceph:v15
docker pull ceph/ceph-grafana
docker pull prom/prometheus:v2.18.1
docker pull prom/alertmanager:v0.20.0
docker pull prom/node-exporter:v0.18.14.5 安装NTP并同步各节点时间
各节点安装ntp服务
yum install ntp ntpdate ntp-doc -y在管理节点worker02.xxx.com上安装ntp服务,vi /etc/ntp.conf:
...
restrict 127.0.0.1
restrict ::1
restrict 172.17.13.0 mask 255.255.255.0
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 127.127.1.0
...配置了NTP服务的管理节点需要防火墙配置端口:
firewall-cmd --zone=public --add-port=123/udp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports在其他节点设置ntp服务器为刚刚设定的ntp服务器,vi /etc/ntp.conf:
…
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server worker02.xxx.com
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
…重启各个节点的ntp服务,并设置开机启动:
systemctl enable ntpd
systemctl restart ntpd
systemctl status ntpd
# Centos7默认安装了chronyd并且默认enable,这里需要关闭,否则重启以后会导致ntpd不能启动
systemctl disable chronyd管理节点从外网同步时间,其他节点从管理节点同步时间:
# 管理节点
ntpdate -u ntp1.aliyun.com
# 其他节点
ntpdate -u worker02.xxx.com4.6 更新SSH服务
各节点默认已安装,可以更新最新版本,并确认服务状态
yum install openssh-server -y
service sshd status4.7 确保短主机名可以ping通
在每个节点以root身份vi /etc/hosts,添加:
172.17.13.1 manager01
172.17.13.2 manager02
172.17.13.3 worker01
172.17.13.4 worker02Ceph默认使用短域名,社区文档在环境检查中要求能以短域名ping通,但本文环境都是用的FQDN,这里即使设置短域名到hosts文件,后续依然有些许小问题。
五、Ceph集群搭建
5.1 cephadm节点安装cephadm
以下操作均在cephadm节点上执行。(本文规划将worker02.xxx.com作为cephadm节点)
cd ~
mkdir cephadmin
cd cephadmin
curl --silent --remote-name --location https://hub.fastgit.org/ceph/ceph/raw/octopus/src/cephadm/cephadm
chmod +x cephadm
ll -h
官方地址https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm总是下载失败,因此使用了国内某镜像地址。5.2 初始化Ceph集群
以下操作均在cephadm节点上执行。
生成ceph的yum源文件并将其替换为使用阿里云yum源:
./cephadm add-repo --release octopus
cat /etc/yum.repos.d/ceph.repo
sed -i ''s#download.ceph.com#mirrors.aliyun.com/ceph#'' /etc/yum.repos.d/ceph.repo
cat /etc/yum.repos.d/ceph.repo
yum list | grep ceph注意版本是octopus安装cephadm:
./cephadm install
which cephadm引导ceph集群:
mkdir -p /etc/ceph
cephadm bootstrap --mon-ip 172.17.13.4 --allow-fqdn-hostname成功后会出现如下信息:
...
INFO:cephadm:Ceph Dashboard is now available at:
URL: https://worker02.xxx.com:8443/
User: admin
Password: 3y44vf60ms
INFO:cephadm:You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid fbd10774-c8cf-11ea-8bcc-00505683571d -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
INFO:cephadm:Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
INFO:cephadm:Bootstrap complete.尝试登录Ceph CLI:
[root@worker02 ~]# cephadm shell --fsid fbd10774-c8cf-11ea-8bcc-00505683571d -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
INFO:cephadm:Using recent ceph image ceph/ceph:v15
[ceph: root@worker02 /]# exit
exit在浏览器中访问https://worker02.xxx.com:8443/,打开 ceph ui, 第一次登陆要求更改默认密码
域名访问前先配置浏览器所在节点的hosts文件
5.3 安装ceph-common并验证集群
以下操作均在cephadm节点上执行。
安装 ceph 工具包, 其中包括 ceph, rbd, mount.ceph 等命令:
cephadm install ceph-common验证集群状态:
# 查看 ceph 集群所有组件运行状态
ceph orch ps
# 查看指定组件运行状态
ceph orch ps --daemon-type mon
# 查看集群当前状态
ceph status
ceph -s
5.4 向集群添加主机
将之前cephadm bootstrap初始化集群命令所生成的ceph密钥拷贝到其他节点root用户的"~/.ssh"目录。注意要输入其他节点root用户密码。
ssh-copy-id -f -i /etc/ceph/ceph.pub root@manager01.xxx.com
ssh-copy-id -f -i /etc/ceph/ceph.pub root@manager02.xxx.com
ssh-copy-id -f -i /etc/ceph/ceph.pub root@worker01.xxx.com将其他节点加入集群
ceph orch host add manager01.xxx.com
ceph orch host add manager02.xxx.com
ceph orch host add worker01.xxx.com
ceph orch host ls查看集群当前服务分布(此时应该有4个crash,4个mon,两个mgr)
ceph orch ps5.5 部署OSD
检查每个节点是否有一块尚未分区的新磁盘,例如这里的sdb:
[root@worker01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
fd0 2:0 1 4K 0 disk
sda 8:0 0 300G 0 disk
├─sda1 8:1 0 500M 0 part /boot
└─sda2 8:2 0 299.5G 0 part
├─centos-root 253:0 0 295.5G 0 lvm /
└─centos-swap 253:1 0 4G 0 lvm [SWAP]
sdb 8:16 0 300G 0 disk
sr0 11:0 1 1024M 0 rom 对于虚拟机,在虚拟机控制台直接给运行中的虚拟机添加新磁盘之后,每个节点执行以下命令就可以刷出磁盘信息,不用重启:
echo "- - -" > /sys/class/scsi_host/host0/scan
echo "- - -" > /sys/class/scsi_host/host1/scan
echo "- - -" > /sys/class/scsi_host/host2/scan将新磁盘设备加入集群
ceph orch daemon add osd manager01.xxx.com:/dev/sdb
ceph orch daemon add osd manager02.xxx.com:/dev/sdb
ceph orch daemon add osd worker01.xxx.com:/dev/sdb
ceph orch daemon add osd worker02.xxx.com:/dev/sdb
# 查看设备信息
ceph orch device ls
# 查看挂载好的osd信息
ceph osd df5.6 其他节点安装ceph-common
为了在其他节点也能够直接访问Ceph集群,我们需要在其他节点上也安装ceph-common。
cephadm以外的其他节点执行:
mkdir ~/cephadmin
mkdir /etc/ceph从cephadm节点以拷贝ceph.repo,cephadm,ceph集群配置文件,ceph客户端管理员密钥到其他节点:
scp /etc/yum.repos.d/ceph.repo root@manager01.xxx.com:/etc/yum.repos.d
scp /etc/yum.repos.d/ceph.repo root@manager02.xxx.com:/etc/yum.repos.d
scp /etc/yum.repos.d/ceph.repo root@worker01.xxx.com:/etc/yum.repos.d
scp ~/cephadmin/cephadm root@manager01.xxx.com:~/cephadmin/
scp ~/cephadmin/cephadm root@manager02.xxx.com:~/cephadmin/
scp ~/cephadmin/cephadm root@worker01.xxx.com:~/cephadmin/
scp /etc/ceph/ceph.conf root@manager01.xxx.com:/etc/ceph/
scp /etc/ceph/ceph.conf root@manager02.xxx.com:/etc/ceph/
scp /etc/ceph/ceph.conf root@worker01.xxx.com:/etc/ceph/
scp /etc/ceph/ceph.client.admin.keyring root@manager01.xxx.com:/etc/ceph/
scp /etc/ceph/ceph.client.admin.keyring root@manager02.xxx.com:/etc/ceph/
scp /etc/ceph/ceph.client.admin.keyring root@worker01.xxx.com:/etc/ceph/
其他节点执行:
cd ~/cephadmin
./cephadm install ceph-common
ceph -s5.7 健康检查的错误
在执行ceph -s或者ceph health时,可能会发现如下的错误:
Module ''cephadm'' has failed: auth get failed: failed to find client.crash.worker02 in keyring retval: -2推测是Ceph对长域名支持不足的原因。通过ceph auth ls命令可以查看ceph集群所有的用户的密钥,能查到对应的长域名client.crash.worker02.xxx.com用户但没有短域名用户。通过以下命令创建对应的短域名用户:
# 手动添加用户client.crash.xxx,任意节点执行
ceph auth add client.crash.worker02 mgr ''profile crash'' mon ''profile crash''
ceph auth add client.crash.manager01 mgr ''profile crash'' mon ''profile crash''
ceph auth add client.crash.manager02 mgr ''profile crash'' mon ''profile crash''
ceph auth add client.crash.worker01 mgr ''profile crash'' mon ''profile crash''
# 查看新增用户是否成功
ceph auth ls
# 重启ceph集群,各个节点上都需要执行
systemctl restart ceph.target
# 也可以用下面的命令停止再重启ceph集群,各个节点上都需要执行
systemctl stop ceph.target
systemctl stop ceph\*.service ceph\*.target
ps -ef | grep ceph
docker ps -a
systemctl restart ceph.target
# 重启后重新检查状态
ceph -s六、部署cephfs服务
6.1 创建cephfs
任意节点上执行:
# 创建一个用于cephfs数据存储的池,相关参数自行参阅社区文档,一言难尽。。。
ceph osd pool create cephfs_data 64 64
# 创建一个用于cephfs元数据存储的池
ceph osd pool create cephfs_metadata 32 32
# 创建一个新的fs服务,名为cephfs
ceph fs new cephfs cephfs_metadata cephfs_data
# 查看集群当前的fs服务
ceph fs ls
# 设置cephfs最大mds服务数量
ceph fs set cephfs max_mds 4
# 部署4个mds服务
ceph orch apply mds cephfs --placement="4 manager01.xxx.com manager02.xxx.com worker01.xxx.com worker02.xxx.com"
# 查看mds服务是否部署成功
ceph orch ps --daemon-type mds本文在这里遇到一个问题,mds服务一直不能启动,查看ceph health发现一个1 filesystem is online with fewer MDS than max_mds的警告,应该是ceph fs set cephfs max_mds 4没有生效。后来重启了整个集群就好了。
# 在所有节点上执行
systemctl restart ceph.target
# 重启之后检查相关服务
ceph orch ps --daemon-type mds
ceph osd lspools
ceph fs ls6.2 创建cephfs访问用户
创建用户,用于客户端访问CephFs
ceph auth get-or-create client.cephfs mon ''allow r'' mds ''allow r, allow rw path=/'' osd ''allow rw pool=cephfs_data'' -o ceph.client.cephfs.keyring查看输出的ceph.client.cephfs.keyring密钥文件,或使用下面的命令查看密钥:
ceph auth get-key client.cephfs6.3 挂载cephfs到各节点本地目录
在各个节点执行:
mkdir /mnt/cephfs/
mount -t ceph manager01.xxx.com:6789,manager02.xxx.com:6789,worker01.xxx.com:6789,worker02.xxx.com:6789:/ /mnt/cephfs/ -o name=cephfs,secret=<cephfs访问用户的密钥>manager01.xxx.com:6789,manager02.xxx.com:6789,worker01.xxx.com:6789,worker02.xxx.com:6789 是所有mon服务
编辑各个节点的/etc/fstab文件,实现开机自动挂载,添加以下内容:
manager01.xxx.com:6789,manager02.xxx.com:6789,worker01.xxx.com:6789,worker02.xxx.com:6789:/ /mnt/cephfs ceph name=cephfs,secretfile=<cephfs访问用户的密钥>,noatime,_netdev 0 2相关参数请自行查阅linux下fstab的配置资料。
6.4 使用cephfs实现docker共享存储
将挂载到本地的cephfs作为本地磁盘使用即可。例如本文中,可以在docker run命令中,或者docker compose编排文件中,使用volume本地挂载到/mnt/cephfs下。
示例,注意volumes:
...
portainer:
image: portainer/portainer
...
volumes:
- /mnt/cephfs/docker/portainer:/data
...
deploy:
mode: replicated
replicas: 1
placement:
constraints: [node.role == manager]
...至此,使用cephfs实现docker共享存储的尝试已经OK。
七、部署RBD
Ceph的RBD对外提供的是块存储,但块存储直接作为磁盘挂载到各节点的话,并不能实现不同节点之间的数据共享。因此需要配合中间件Rexray,以及docker插件rexray/rbd来实现共享存储。
但本文并未成功,原因后叙。
7.1 初始化rbd pool并创建RBD的image
在任意节点上执行:
ceph osd pool create rbd01 32
rbd pool init rbd01
# 在rbd01上创建一个300G的image
rbd create img01 --size 307200 --pool rbd01
rbd ls rbd01
rbd info --image img01 -p rbd01此时可以在各个节点上挂载RBD的img01,但是并不能实现存储共享。
# 向linux系统内核载入rbd模块
modprobe rbd
# 将img01映射到系统内核
rbd map img01 --pool rbd01 --id admin
# 失败,需要禁用当前系统内核不支持的feature
rbd feature disable img01 --pool rbd01 exclusive-lock, object-map, fast-diff, deep-flatten
# 重新映射
rbd map img01 --pool rbd01 --id admin
# 映射成功后,会返回映射目录"/dev/rbd0",对该目录进行格式化:
[root@worker01 ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=17, agsize=4914176 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=78643200, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=38400, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# mount到本地
mkdir /mnt/data01
mount /dev/rbd0 /mnt/data01
# 查看本地磁盘信息
df -hT
# 卸除挂载并删除image
umount /mnt/data01
rbd unmap img01 --pool rbd01 --id admin
rbd rm --image img01 -p rbd01
7.2 安装rexray与rexray/rbd
任意某个节点下载rexray:
curl -sSL https://rexray.io/install | sh编辑配置文件vi /etc/rexray/config.yml,内容如下:
rexray:
logLevel: debug
libstorage:
logging:
level: debug
httpRequests: true
httpResponses: true
libstorage:
service: rbd
rbd:
defaultPool: rbd01尝试启动Rexray服务,这里一直失败:
[root@manager01 rexray]# rexray start
...
error: service startup failed: agent: mod init failed: error initializing instance ID cache日志中除了最后的错误,并无其他有用的信息。在github对应项目的issue中有类似问题,解决方法是ceph配置文件/etc/ceph/ceph.conf中添加mon_host配置。但本文使用的ceph版本octopus的配置文件中已经明确配置了mon_host,且格式与issue所述不同。最终也没有找到原因,怀疑是Ceph版本太新,与rexray不兼容所致。所以这里的尝试到此为止,后续安装docker插件与创建rbd数据卷并未进行。
如果Rexray服务能成功启动,那么后续还需要在每个节点安装docker插件rexray/rbd:
docker plugin install rexray/rbd RBD_DEFAULTPOOL=rbd01 LINUX_VOLUME_FILEMODE=0777最后在docker swarm上创建rbd驱动的数据卷:
docker volume create -d <rexrayHost>:5011/rexray/rbd <数据卷名称>如果成功,docker run或编排文件中的volume使用事先创建好的数据卷即可实现存储共享。
今天关于Docker Swanm集群配置和docker swarm集群的分享就到这里,希望大家有所收获,若想了解更多关于010 docker搭建swarm集群、8天入门docker系列 —— 第八天 让程序跑在swarm集群上、ansible-playbook部署Docker Swarm集群、Ceph实现DockerSwarm集群共享存储的尝试等相关知识,可以在本站进行查询。
本文标签:




