对于ReactFiber源码分析第二篇感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解同步模式,并且为您提供关于canal源码分析——DirectLogFetcher源码分析、Java并发系
对于React Fiber源码分析 第二篇感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解同步模式,并且为您提供关于canal源码分析——DirectLogFetcher源码分析、Java并发系列之AbstractQueuedSynchronizer源码分析(共享模式)、Java并发系列之AbstractQueuedSynchronizer源码分析(独占模式)、Libevent源码分析-----跨平台Reactor接口的实现的宝贵知识。
本文目录一览:- React Fiber源码分析 第二篇(同步模式)(react同步异步)
- canal源码分析——DirectLogFetcher源码分析
- Java并发系列之AbstractQueuedSynchronizer源码分析(共享模式)
- Java并发系列之AbstractQueuedSynchronizer源码分析(独占模式)
- Libevent源码分析-----跨平台Reactor接口的实现
(react同步异步)")
React Fiber源码分析 第二篇(同步模式)(react同步异步)
先附上两张流程图
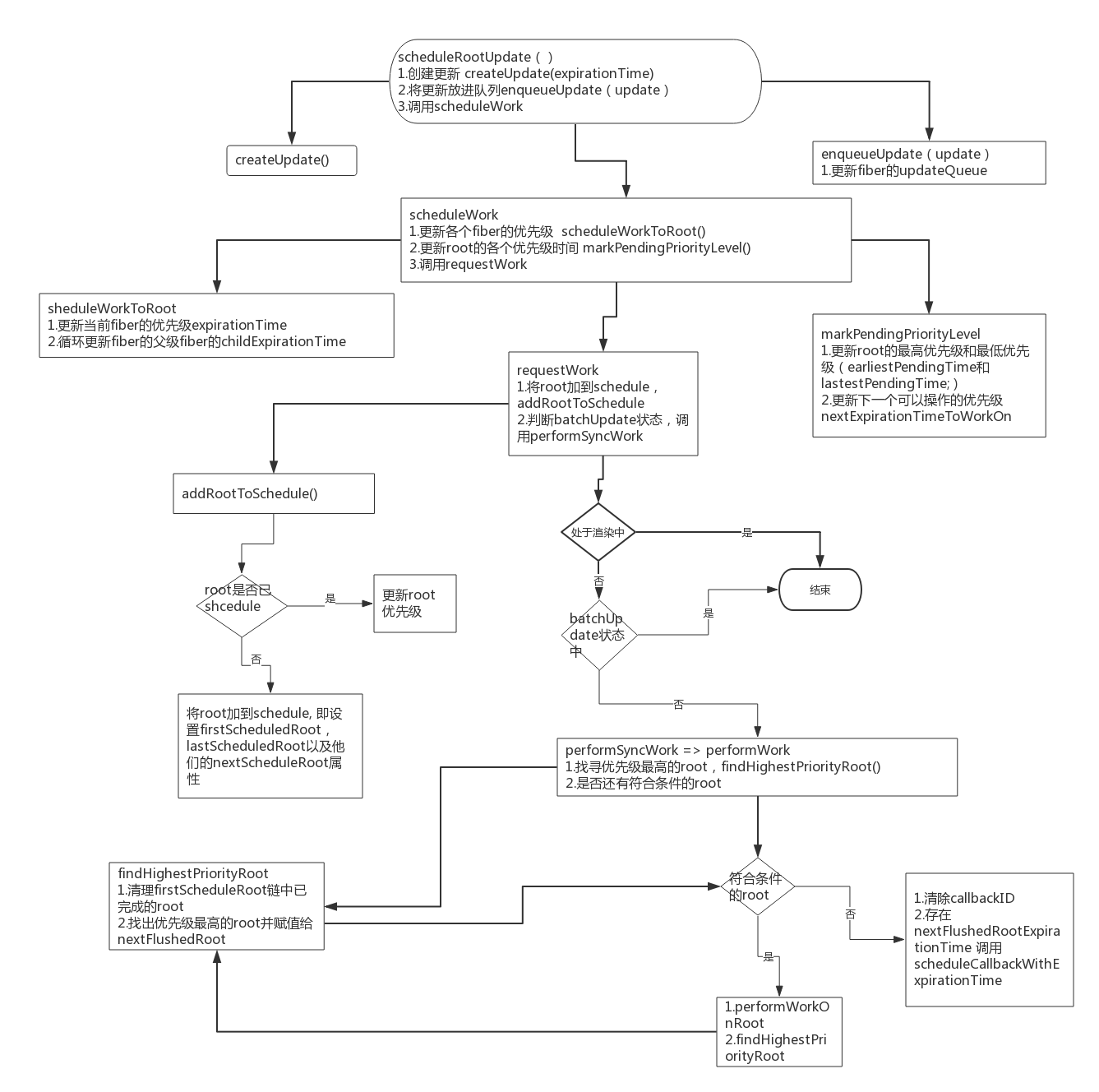
1.scheduleRootUpdate 这个函数主要执行了两个操作 1个是创建更新createUpdate并放到更新队列enqueueUpdate, 1个是执行sheculeWork函数
function scheduleRootUpdate(current$$1, element, expirationTime, callback) {
var update = createUpdate(expirationTime);
update.payload = { element: element };
callback = callback === undefined ? null : callback;
if (callback !== null) {
update.callback = callback;
}
enqueueUpdate(current$$1, update);
scheduleWork(current$$1, expirationTime);
return expirationTime;
}
先从createUpdate函数分析, 他直接返回了一个包含了更新信息的对象
function createUpdate(expirationTime) {
return {
// 优先级
expirationTime: expirationTime,
// 更新类型
tag: UpdateState,
// 更新的对象
payload: null,
callback: null,
// 指向下一个更新
next: null,
// 指向下一个更新effect
nextEffect: null
};
}接着更新payload和callback属性, payload即为更新的对象, 然后执行enqueuUpdate, enqueueUpdate相对比较容易理解, 不过里面有一注释挺重要
Both queues are non-empty. The last update is the same in both lists, because of structural sharing. So, only append to one of the lists 意思是alternate的updateQueue和fiber的updateQueue是同一个对象引用,这里会在createWorkInProcess提到
往下走就是重要的scheduleWork, 它是render阶段真正的开始
function scheduleWork(fiber, expirationTime) {
// 更新优先级
var root = scheduleWorkToRoot(fiber, expirationTime);
...if (!isWorking && nextRenderExpirationTime !== NoWork && expirationTime < nextRenderExpirationTime) {
// This is an interruption. (Used for performance tracking.) 如果这是一个打断原有更新的任务, 先把现有任务记录
interruptedBy = fiber;
resetStack();
}
// 设置下一个操作时间nextExpirationTimeToWorkOn
markPendingPriorityLevel(root, expirationTime);
if (
// If we''re in the render phase, we don''t need to schedule this root
// for an update, because we''ll do it before we exit...
!isWorking || isCommitting$1 ||
// ...unless this is a different root than the one we''re rendering.
nextRoot !== root) {
var rootExpirationTime = root.expirationTime;
requestWork(root, rootExpirationTime);
}
...
}
scheduleWork先执行一个scheduleWorkToRoot函数, 该函数主要是更新其expirationTime以及上层fiber的childrenExpirationTime
function scheduleWorkToRoot(fiber, expirationTime) {
// Update the source fiber''s expiration time
if (fiber.expirationTime === NoWork || fiber.expirationTime > expirationTime) {
fiber.expirationTime = expirationTime;
}
var alternate = fiber.alternate;
if (alternate !== null && (alternate.expirationTime === NoWork || alternate.expirationTime > expirationTime)) {
alternate.expirationTime = expirationTime;
}
// 如果是HostRoot 即直接返回
var node = fiber.return;
if (node === null && fiber.tag === HostRoot) {
return fiber.stateNode;
}
// 若子fiber中有更新, 即更新其childrenExpirationTime
while (node !== null) {
...
}
return null;
}接着会执行一个markPendingPriorityLevel函数, 这个函数主要是更新root的最高优先级和最低优先级(earliestPendingTime和lastestPendingTime;), 同时设置下一个执行操作的时间nextExpirationTimeToWorkOn(即root中具有最高优先级的fiber的expirationTime),关于这个函数的 latestSuspendedTime;以后再说
最后scheduleWork会执行requestWork
function requestWork(root, expirationTime) {
addRootToSchedule(root, expirationTime);
if (isRendering) {
// rendering状态,直接返回
return;
}
if (isBatchingUpdates) {
// isBatchingUpdates, 直接返回。 react的state更新是会合并的
...return;
}
// TODO: Get rid of Sync and use current time?
if (expirationTime === Sync) {
// 执行同步
performSyncWork();
} else {
// 异步, 暂不分析
scheduleCallbackWithExpirationTime(root, expirationTime);
}
}
requestWork 会先执行addRootToSchedule,由函数名称可知其作用,将root加到schedule, 即设置firstScheduledRoot, lastScheduledRoot以及他们的nextScheduleRoot属性, 说白了就是一个闭环链式结构 first => next => next => last(next => first), 同时更新root的expirationTime属性
function addRootToSchedule(root, expirationTime) {
// root尚未开始过任务 将root加到schedule
if (root.nextScheduledRoot === null) {
...
} else {
// root已经开始执行过任务, 更新root的expirationTime
var remainingExpirationTime = root.expirationTime;
if (remainingExpirationTime === NoWork || expirationTime < remainingExpirationTime) {
root.expirationTime = expirationTime;
}
}
}接着requestWork会判断是否正在渲染中,防止重入。剩余的工作将安排在当前渲染批次的末尾
如果正在渲染直接返回后, 因为已经把root加上到Schedule里面了,依然会把该root执行
同时判断是否正在batch update, 这里留到分析setState的时候说, 最后根据异步或者同步执行不同函数, 此处执行同步performSyncWork(),performSyncWork直接执行performWork(Sync, null);
function performWork(minExpirationTime, dl) {
deadline = dl;
// 找出优先级最高的root
findHighestPriorityRoot();
if (deadline !== null) {
// ...异步
} else {
// 循环执行root任务
while (nextFlushedRoot !== null && nextFlushedExpirationTime !== NoWork && (minExpirationTime === NoWork || minExpirationTime >= nextFlushedExpirationTime)) {
performWorkOnRoot(nextFlushedRoot, nextFlushedExpirationTime, true);
findHighestPriorityRoot();
}
}
...
// If there''s work left over, schedule a new callback.
if (nextFlushedExpirationTime !== NoWork) {
scheduleCallbackWithExpirationTime(nextFlushedRoot, nextFlushedExpirationTime);
}
...
}
performWork首先执行findHighestPriorityRoot函数。findHighestPriorityRoot函数主要执行两个操作, 一个是判断当前root是否还有任务,如果没有, 则从firstScheuleRoot链中移除。 一个是找出优先级最高的root和其对应的优先级并赋值给
nextFlushedRoot\nextFlushedExpirationTime
function findHighestPriorityRoot() {
var highestPriorityWork = NoWork;
var highestPriorityRoot = null;
if (lastScheduledRoot !== null) {
var previousScheduledRoot = lastScheduledRoot;
var root = firstScheduledRoot;
while (root !== null) {
var remainingExpirationTime = root.expirationTime;
if (remainingExpirationTime === NoWork) {
// 判断是否还有任务并移除
} else {
// 找出最高的优先级root和其对应的优先级
}
}
}
// 赋值
nextFlushedRoot = highestPriorityRoot;
nextFlushedExpirationTime = highestPriorityWork;
}
紧着, performWork会根据传入的参数dl来判断进行同步或者异步操作, 这里暂不讨论异步,
while (nextFlushedRoot !== null && nextFlushedExpirationTime !== NoWork && (minExpirationTime === NoWork || minExpirationTime >= nextFlushedExpirationTime)) {
performWorkOnRoot(nextFlushedRoot, nextFlushedExpirationTime, true);
findHighestPriorityRoot();
}
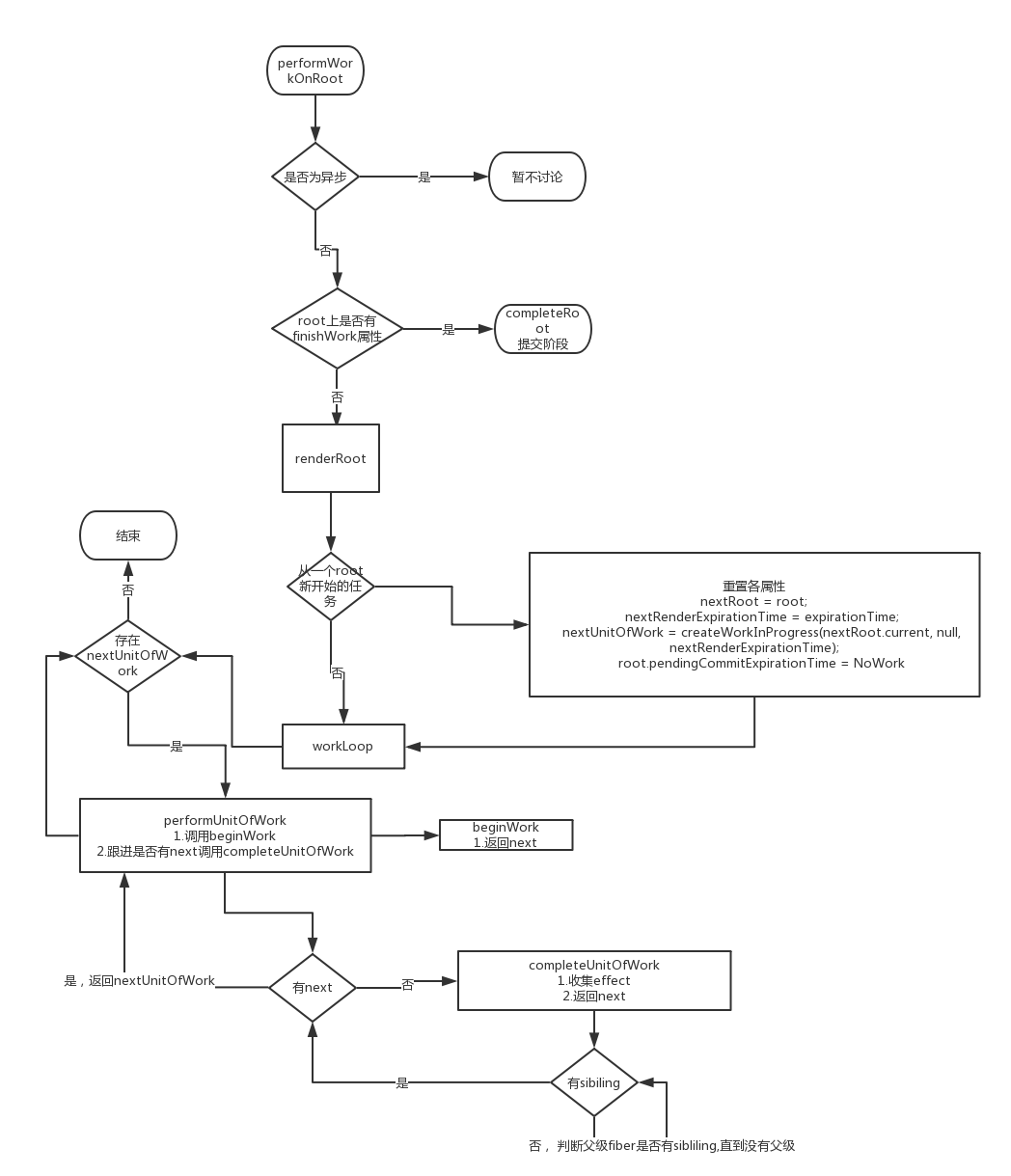
接着, 会进行performWorkOnRoot函数, 并传入优先级最高的root和其对应的expirationTime以及一个true作为参数,
performWorkOnRoot函数的第三个参数isExpired主要是用来判断是否已超过执行时间, 由于进行的是同步操作, 所以默认超过
performWorkOnRoot函数会先将rendering状态设为true, 然后判断是否异步或者超时进行操作
function performWorkOnRoot(root, expirationTime, isExpired) {
// 将rendering状态设为true
isRendering = true;
// Check if this is async work or sync/expired work.
if (deadline === null || isExpired) {
// Flush work without yielding.
// 同步
var finishedWork = root.finishedWork;
if (finishedWork !== null) {
// This root is already complete. We can commit it.
completeRoot(root, finishedWork, expirationTime);
} else {
root.finishedWork = null;
// If this root previously suspended, clear its existing timeout, since
// we''re about to try rendering again.
var timeoutHandle = root.timeoutHandle;
if (enableSuspense && timeoutHandle !== noTimeout) {
root.timeoutHandle = noTimeout;
// $FlowFixMe Complains noTimeout is not a TimeoutID, despite the check above
cancelTimeout(timeoutHandle);
}
var isYieldy = false;
renderRoot(root, isYieldy, isExpired);
finishedWork = root.finishedWork;
if (finishedWork !== null) {
// We''ve completed the root. Commit it.
completeRoot(root, finishedWork, expirationTime);
}
}
} else {
// Flush async work.异步操作
......
}
}
isRendering = false;
}renderRoot的产物会挂载到root的finishWork属性上, 首先performWorkOnRoot会先判断root的finishWork是否不为空, 如果存在的话则直接进入commit的阶段, 否则进入到renderRoot函数, 设置finishWork属性
renderRoot有三个参数, renderRoot(root, isYieldy, isExpired), 同步状态下isYield的值是false,
renderRoot 先将 isWorking设为true,
renderRoot会先判断是否是一个从新开始的root, 是的话会重置各个属性
首先是resetStach()函数, 对原有的进行中的root任务中断, 进行存储
紧接着将nextRoot\nextRendeExpirationTime重置, 同时创建第一个nextUnitOfWork, 也就是一个工作单元
这个nextUnitOfWork也是一个workProgress, 也是root.current的alternater属性, 而它的alternate属性则指向了root.current, 形成了一个双缓冲池
if (expirationTime !== nextRenderExpirationTime || root !== nextRoot || nextUnitOfWork === null) {
// 判断是否是一个从新开始的root
resetStack();
nextRoot = root;
nextRenderExpirationTime = expirationTime;
nextUnitOfWork = createWorkInProgress(nextRoot.current, null, nextRenderExpirationTime);
root.pendingCommitExpirationTime = NoWork;
....
....
}
接着执行wookLoop(isYield)函数, 该函数通过循环执行, 遍历每一个nextUniOfWork,function workLoop(isYieldy) {
if (!isYieldy) {
// Flush work without yielding
while (nextUnitOfWork !== null) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
} else {
// Flush asynchronous work until the deadline runs out of time.
while (nextUnitOfWork !== null && !shouldYield()) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
}
}performUnitOfWork 先 获取 参数的alaernate属性, 赋值给current,
根据注释的意思, workInProgress是作为一个代替品存在来操作, 然后会执行下面这个语句
next = beginWork(current$$1, workInProgress, nextRenderExpirationTime);beginWork主要根据workInprogress的tag来做不同的处理, 并返回其child, 也就是下一个工作单元 如<div><p></p><div>, div作为一个工作单元, 处理完后就返回工作单元p, 同时收集他们的effect
若next存在, 则返回到workLoop函数继续循环, 若不存在, 则执行completeUnitOfWork(workInProgress)函数
completeUnitOfWork函数, 会判断是否有sibiling, 有则直接返回赋值给next, 否则判断父fiber是否有sibiling, 一直循环到最上层 父fiber为null, 执行的同时会把effect逐级传给父fiber
这个时候函数执行完毕, 会返回到renderRoot函数, renderRoot函数继续往下走
首先将isWorking = false;执行, 然后会判断nextUnitWork是否为空, 否的话则将root.finishWork设为空(异步, 该任务未执行完)并结束函数
isWorking = false;
if (nextUnitOfWork !== null) {
onYield(root);
return;
}
重置nextRoot等nextRoot = null;
interruptedBy = null;
赋值finishWorkvar rootWorkInProgress = root.current.alternate;
onComplete(root, rootWorkInProgress, expirationTime);
function onComplete(root, finishedWork, expirationTime) {
root.pendingCommitExpirationTime = expirationTime;
root.finishedWork = finishedWork;
}返回到performWorkOnRoot函数, 进入commit阶段, 将rending状态设为false,返回到performWork函数, 继续进入循环执行root, 直到所有root完成
重置各个状态量, 如果还存在nextFlushedExpirationTime不为空, 则进行scheduleCallbackWithExpirationTime函数异步操作
if (deadline !== null) {
callbackExpirationTime = NoWork;
callbackID = null;
}
// If there''s work left over, schedule a new callback.
if (nextFlushedExpirationTime !== NoWork) {
scheduleCallbackWithExpirationTime(nextFlushedRoot, nextFlushedExpirationTime);
}
// Clean-up.
deadline = null;
deadlineDidExpire = false;

canal源码分析——DirectLogFetcher源码分析
类结构
DirectLogFetcher的类结构图如下。
LogBuffer
|
LogFetcher
|
DirectLogFetcher
LogBuffer是一个数据库复制日志的缓存区,可将日志缓冲存储起来。
LogFetcher是一个日志提取器的抽象类,它定义了一些提取日志的抽象方法,供子类实现。
DirectLogFetcher是一个既有socket的日志提取器实现类,它实现了LogFetcher类。我们重点研究这个类中代码的实现。
DirectLogFetcher源码分析
package com.alibaba.otter.canal.parse.inbound.mysql.dbsync;
import java.io.IOException;
import java.io.InterruptedIOException;
import java.net.SocketTimeoutException;
import java.nio.ByteBuffer;
import java.nio.channels.ClosedByInterruptException;
import java.nio.channels.SocketChannel;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.taobao.tddl.dbsync.binlog.LogFetcher;
/**
* 基于socket的logEvent实现
*
* @author jianghang 2013-1-14 下午07:39:30
* @version 1.0.0
*/
public class DirectLogFetcher extends LogFetcher {
protected static final Logger logger = LoggerFactory.getLogger(DirectLogFetcher.class);
/** Command to dump binlog */
public static final byte COM_BINLOG_DUMP = 18;
/** Packet header sizes */
public static final int NET_HEADER_SIZE = 4;
public static final int SQLSTATE_LENGTH = 5;
/** Packet offsets */
public static final int PACKET_LEN_OFFSET = 0;
public static final int PACKET_SEQ_OFFSET = 3;
/** Maximum packet length */
public static final int MAX_PACKET_LENGTH = (256 * 256 * 256 - 1);
private SocketChannel channel;
// private BufferedInputStream input;
public DirectLogFetcher(){
super(DEFAULT_INITIAL_CAPACITY, DEFAULT_GROWTH_FACTOR);
}
public DirectLogFetcher(final int initialCapacity){
super(initialCapacity, DEFAULT_GROWTH_FACTOR);
}
public DirectLogFetcher(final int initialCapacity, final float growthFactor){
super(initialCapacity, growthFactor);
}
public void start(SocketChannel channel) throws IOException {
this.channel = channel;
// 和mysql driver一样,提供buffer机制,提升读取binlog速度
// this.input = new
// BufferedInputStream(channel.socket().getInputStream(), 16384);
}
/**
* {@inheritDoc}
*
* @see com.taobao.tddl.dbsync.binlog.LogFetcher#fetch()
*/
public boolean fetch() throws IOException {
try {
// Fetching packet header from input.
if (!fetch0(0, NET_HEADER_SIZE)) {
logger.warn("Reached end of input stream while fetching header");
return false;
}
// Fetching the first packet(may a multi-packet).
int netlen = getUint24(PACKET_LEN_OFFSET);
int netnum = getUint8(PACKET_SEQ_OFFSET);
if (!fetch0(NET_HEADER_SIZE, netlen)) {
logger.warn("Reached end of input stream: packet #" + netnum + ", len = " + netlen);
return false;
}
// Detecting error code.
final int mark = getUint8(NET_HEADER_SIZE);
if (mark != 0) {
if (mark == 255) // error from master
{
// Indicates an error, for example trying to fetch from
// wrong
// binlog position.
position = NET_HEADER_SIZE + 1;
final int errno = getInt16();
String sqlstate = forward(1).getFixString(SQLSTATE_LENGTH);
String errmsg = getFixString(limit - position);
throw new IOException("Received error packet:" + " errno = " + errno + ", sqlstate = " + sqlstate
+ " errmsg = " + errmsg);
} else if (mark == 254) {
// Indicates end of stream. It''s not clear when this would
// be sent.
logger.warn("Received EOF packet from server, apparent"
+ " master disconnected. It''s may be duplicate slaveId , check instance config");
return false;
} else {
// Should not happen.
throw new IOException("Unexpected response " + mark + " while fetching binlog: packet #" + netnum
+ ", len = " + netlen);
}
}
// The first packet is a multi-packet, concatenate the packets.
while (netlen == MAX_PACKET_LENGTH) {
if (!fetch0(0, NET_HEADER_SIZE)) {
logger.warn("Reached end of input stream while fetching header");
return false;
}
netlen = getUint24(PACKET_LEN_OFFSET);
netnum = getUint8(PACKET_SEQ_OFFSET);
if (!fetch0(limit, netlen)) {
logger.warn("Reached end of input stream: packet #" + netnum + ", len = " + netlen);
return false;
}
}
// Preparing buffer variables to decoding.
origin = NET_HEADER_SIZE + 1;
position = origin;
limit -= origin;
return true;
} catch (SocketTimeoutException e) {
close(); /* Do cleanup */
logger.error("Socket timeout expired, closing connection", e);
throw e;
} catch (InterruptedIOException e) {
close(); /* Do cleanup */
logger.info("I/O interrupted while reading from client socket", e);
throw e;
} catch (ClosedByInterruptException e) {
close(); /* Do cleanup */
logger.info("I/O interrupted while reading from client socket", e);
throw e;
} catch (IOException e) {
close(); /* Do cleanup */
logger.error("I/O error while reading from client socket", e);
throw e;
}
}
private final boolean fetch0(final int off, final int len) throws IOException {
ensureCapacity(off + len);
ByteBuffer buffer = ByteBuffer.wrap(this.buffer, off, len);
while (buffer.hasRemaining()) {
int readNum = channel.read(buffer);
if (readNum == -1) {
throw new IOException("Unexpected End Stream");
}
}
// for (int count, n = 0; n < len; n += count) {
// if (0 > (count = input.read(buffer, off + n, len - n))) {
// // Reached end of input stream
// return false;
// }
// }
if (limit < off + len) limit = off + len;
return true;
}
/**
* {@inheritDoc}
*
* @see com.taobao.tddl.dbsync.binlog.LogFetcher#close()
*/
public void close() throws IOException {
// do nothing
}
}
start()方法特别简单,几乎什么都没有干,直接给内部的channel赋值而已,这个没有什么看的。
重点是fetch()方法的实现特别复杂,
")
Java并发系列之AbstractQueuedSynchronizer源码分析(共享模式)
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取。在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快的理解其他的方式。虽然说AbstractQueuedSynchronizer源码有一千多行,但是重复的也比较多,所以读者不要刚开始的时候被吓到,只要耐着性子去看慢慢的自然能够渐渐领悟。就我个人经验来说,阅读AbstractQueuedSynchronizer源码有几个比较关键的地方需要弄明白,分别是独占模式和共享模式的区别,结点的等待状态,以及对条件队列的理解。理解了这些要点那么后续源码的阅读将会轻松很多。当然这些在我的《Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析》这篇文章里都有详细的介绍,读者可以先去查阅。本篇对于共享模式的分析也是分为三种获取锁的方式和一种释放锁的方式。
1. 不响应线程中断的获取
//以不可中断模式获取锁(共享模式)
public final void acquireShared(int arg) {
//1.尝试去获取锁
if (tryAcquireShared(arg) < 0) {
//2.如果获取失败就进入这个方法
doAcquireShared(arg);
}
}
//尝试去获取锁(共享模式)
//负数:表示获取失败
//零值:表示当前结点获取成功,但是后继结点不能再获取了
//正数:表示当前结点获取成功,并且后继结点同样可以获取成功
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
调用acquireShared方法是不响应线程中断获取锁的方式。在该方法中,首先调用tryAcquireShared去尝试获取锁,tryAcquireShared方法返回一个获取锁的状态,这里AQS规定了返回状态若是负数代表当前结点获取锁失败,若是0代表当前结点获取锁成功,但后继结点不能再获取了,若是正数则代表当前结点获取锁成功,并且这个锁后续结点也同样可以获取成功。子类在实现tryAcquireShared方法获取锁的逻辑时,返回值需要遵守这个约定。如果调用tryAcquireShared的返回值小于0,就代表这次尝试获取锁失败了,接下来就调用doAcquireShared方法将当前线程添加进同步队列。我们看到doAcquireShared方法。
//在同步队列中获取(共享模式)
private void doAcquireShared(int arg) {
//添加到同步队列中
final Node node = addWaiter(Node.SHARED);
boolean Failed = true;
try {
boolean interrupted = false;
for (;;) {
//获取当前结点的前继结点
final Node p = node.predecessor();
//如果前继结点为head结点就再次尝试去获取锁
if (p == head) {
//再次尝试去获取锁并返回获取状态
//r < 0,表示获取失败
//r = 0,表示当前结点获取成功,但是后继结点不能再获取了
//r > 0,并且后继结点同样可以获取成功
int r = tryAcquireShared(arg);
if (r >= 0) {
//到这里说明当前结点已经获取锁成功了,此时它会将锁的状态信息传播给后继结点
setHeadAndPropagate(node,r);
p.next = null;
//如果在线程阻塞期间收到中断请求,就在这一步响应该请求
if (interrupted) {
selfInterrupt();
}
Failed = false;
return;
}
}
//每次获取锁失败后都会判断是否可以将线程挂起,如果可以的话就会在parkAndCheckInterrupt方法里将线程挂起
if (shouldParkAfterFailedAcquire(p,node) && parkAndCheckInterrupt()) {
interrupted = true;
}
}
} finally {
if (Failed) {
cancelAcquire(node);
}
}
}
进入doAcquireShared方法首先是调用addWaiter方法将当前线程包装成结点放到同步队列尾部。这个添加结点的过程我们在讲独占模式时讲过,这里就不再讲了。结点进入同步队列后,如果它发现在它前面的结点就是head结点,因为head结点的线程已经获取锁进入房间里面了,那么下一个获取锁的结点就轮到自己了,所以当前结点先不会将自己挂起,而是再一次去尝试获取锁,如果前面那人刚好释放锁离开了,那么当前结点就能成功获得锁,如果前面那人还没有释放锁,那么就会调用shouldParkAfterFailedAcquire方法,在这个方法里面会将head结点的状态改为SIGNAL,只有保证前面结点的状态为SIGNAL,当前结点才能放心的将自己挂起,所有线程都会在parkAndCheckInterrupt方法里面被挂起。如果当前结点恰巧成功的获取了锁,那么接下来就会调用setHeadAndPropagate方法将自己设置为head结点,并且唤醒后面同样是共享模式的结点。下面我们看下setHeadAndPropagate方法具体的操作。
//设置head结点并传播锁的状态(共享模式)
private void setHeadAndPropagate(Node node,int propagate) {
Node h = head;
//将给定结点设置为head结点
setHead(node);
//如果propagate大于0表明锁可以获取了
if (propagate > 0 || h == null || h.waitStatus < 0) {
//获取给定结点的后继结点
Node s = node.next;
//如果给定结点的后继结点为空,或者它的状态是共享状态
if (s == null || s.isShared()) {
//唤醒后继结点
doReleaseShared();
}
}
}
//释放锁的操作(共享模式)
private void doReleaseShared() {
for (;;) {
//获取同步队列的head结点
Node h = head;
if (h != null && h != tail) {
//获取head结点的等待状态
int ws = h.waitStatus;
//如果head结点的状态为SIGNAL,表明后面有人在排队
if (ws == Node.SIGNAL) {
//先把head结点的等待状态更新为0
if (!compareAndSetWaitStatus(h,Node.SIGNAL,0)) {
continue;
}
//再去唤醒后继结点
unparkSuccessor(h);
//如果head结点的状态为0,表明此时后面没人在排队,就只是将head状态修改为PROPAGATE
}else if (ws == 0 && !compareAndSetWaitStatus(h,Node.PROPAGATE)) {
continue;
}
}
//只有保证期间head结点没被修改过才能跳出循环
if (h == head) {
break;
}
}
}
调用setHeadAndPropagate方法首先将自己设置成head结点,然后再根据传入的tryAcquireShared方法的返回值来决定是否要去唤醒后继结点。前面已经讲到当返回值大于0就表明当前结点成功获取了锁,并且后面的结点也可以成功获取锁。这时当前结点就需要去唤醒后面同样是共享模式的结点,注意,每次唤醒仅仅只是唤醒后一个结点,如果后一个结点不是共享模式的话,当前结点就直接进入房间而不会再去唤醒更后面的结点了。共享模式下唤醒后继结点的操作是在doReleaseShared方法进行的,共享模式和独占模式的唤醒操作基本也是相同的,都是去找到自己座位上的牌子(等待状态),如果牌子上为SIGNAL表明后面有人需要让它帮忙唤醒,如果牌子上为0则表明队列此时并没有人在排队。在独占模式下是如果发现没人在排队就直接离开队列了,而在共享模式下如果发现队列后面没人在排队,当前结点在离开前仍然会留个小纸条(将等待状态设置为PROPAGATE)告诉后来的人这个锁的可获取状态。那么后面来的人在尝试获取锁的时候可以根据这个状态来判断是否直接获取锁。
2. 响应线程中断的获取
//以可中断模式获取锁(共享模式)
public final void acquireSharedInterruptibly(int arg) throws InterruptedException {
//首先判断线程是否中断,如果是则抛出异常
if (Thread.interrupted()) {
throw new InterruptedException();
}
//1.尝试去获取锁
if (tryAcquireShared(arg) < 0) {
//2. 如果获取失败则进人该方法
doAcquireSharedInterruptibly(arg);
}
}
//以可中断模式获取(共享模式)
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {
//将当前结点插入同步队列尾部
final Node node = addWaiter(Node.SHARED);
boolean Failed = true;
try {
for (;;) {
//获取当前结点的前继结点
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node,r);
p.next = null;
Failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p,node) && parkAndCheckInterrupt()) {
//如果线程在阻塞过程中收到过中断请求,那么就会立马在这里抛出异常
throw new InterruptedException();
}
}
} finally {
if (Failed) {
cancelAcquire(node);
}
}
}
响应线程中断获取锁的方式和不响应线程中断获取锁的方式在流程上基本是相同的,唯一的区别就是在哪里响应线程的中断请求。在不响应线程中断获取锁时,线程从parkAndCheckInterrupt方法中被唤醒,唤醒后就立马返回是否收到中断请求,即使是收到了中断请求也会继续自旋直到获取锁后才响应中断请求将自己给挂起。而响应线程中断获取锁会才线程被唤醒后立马响应中断请求,如果在阻塞过程中收到了线程中断就会立马抛出InterruptedException异常。
3. 设置超时时间的获取
//以限定超时时间获取锁(共享模式)
public final boolean tryAcquireSharednanos(int arg,long nanosTimeout) throws InterruptedException {
if (Thread.interrupted()) {
throw new InterruptedException();
}
//1.调用tryAcquireShared尝试去获取锁
//2.如果获取失败就调用doAcquireSharednanos
return tryAcquireShared(arg) >= 0 || doAcquireSharednanos(arg,nanosTimeout);
}
//以限定超时时间获取锁(共享模式)
private boolean doAcquireSharednanos(int arg,long nanosTimeout) throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.SHARED);
boolean Failed = true;
try {
for (;;) {
//获取当前结点的前继结点
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node,r);
p.next = null;
Failed = false;
return true;
}
}
//如果超时时间用完了就结束获取,并返回失败信息
if (nanosTimeout <= 0) {
return false;
}
//1.检查是否满足将线程挂起要求(保证前继结点状态为SIGNAL)
//2.检查超时时间是否大于自旋时间
if (shouldParkAfterFailedAcquire(p,node) && nanosTimeout > spinForTimeoutThreshold) {
//若满足上面两个条件就将当前线程挂起一段时间
LockSupport.parkNanos(this,nanosTimeout);
}
long Now = System.nanoTime();
//超时时间每次减去获取锁的时间
nanosTimeout -= Now - lastTime;
lastTime = Now;
//如果在阻塞时收到中断请求就立马抛出异常
if (Thread.interrupted()) {
throw new InterruptedException();
}
}
} finally {
if (Failed) {
cancelAcquire(node);
}
}
}
如果看懂了上面两种获取方式,再来看设置超时时间的获取方式就会很轻松,基本流程都是一样的,主要是理解超时的机制是怎样的。如果第一次获取锁失败会调用doAcquireSharednanos方法并传入超时时间,进入方法后会根据情况再次去获取锁,如果再次获取失败就要考虑将线程挂起了。这时会判断超时时间是否大于自旋时间,如果是的话就会将线程挂起一段时间,否则就继续尝试获取,每次获取锁之后都会将超时时间减去获取锁的时间,一直这样循环直到超时时间用尽,如果还没有获取到锁的话就会结束获取并返回获取失败标识。在整个期间线程是响应线程中断的。
4. 共享模式下结点的出队操作
//释放锁的操作(共享模式)
public final boolean releaseShared(int arg) {
//1.尝试去释放锁
if (tryReleaseShared(arg)) {
//2.如果释放成功就唤醒其他线程
doReleaseShared();
return true;
}
return false;
}
//尝试去释放锁(共享模式)
protected boolean tryReleaseShared(int arg) {
throw new UnsupportedOperationException();
}
//释放锁的操作(共享模式)
private void doReleaseShared() {
for (;;) {
//获取同步队列的head结点
Node h = head;
if (h != null && h != tail) {
//获取head结点的等待状态
int ws = h.waitStatus;
//如果head结点的状态为SIGNAL,Node.PROPAGATE)) {
continue;
}
}
//只有保证期间head结点没被修改过才能跳出循环
if (h == head) {
break;
}
}
}
线程在房间办完事之后就会调用releaseShared方法释放锁,首先调用tryReleaseShared方法尝试释放锁,该方法的判断逻辑由子类实现。如果释放成功就调用doReleaseShared方法去唤醒后继结点。走出房间后它会找到原先的座位(head结点),看看座位上是否有人留了小纸条(状态为SIGNAL),如果有就去唤醒后继结点。如果没有(状态为0)就代表队列没人在排队,那么在离开之前它还要做最后一件事情,就是在自己座位上留下小纸条(状态设置为PROPAGATE),告诉后面的人锁的获取状态,整个释放锁的过程和独占模式唯一的区别就是在这最后一步操作。
注:以上全部分析基于JDK1.7,不同版本间会有差异,读者需要注意。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持编程小技巧。
您可能感兴趣的文章:
- Java并发系列之Semaphore源码分析
- Java并发系列之CountDownLatch源码分析
- Java并发系列之CyclicBarrier源码分析
- Java并发系列之ConcurrentHashMap源码分析
- Java并发系列之AbstractQueuedSynchronizer源码分析(独占模式)
- Java并发系列之AbstractQueuedSynchronizer源码分析(概要分析)
- Java并发系列之ReentrantLock源码分析
- Java并发系列之AbstractQueuedSynchronizer源码分析(条件队列)
- Java并发系列之Semaphore源码分析
- Java并发系列之ReentrantLock源码分析
")
Java并发系列之AbstractQueuedSynchronizer源码分析(独占模式)
这篇文章主要为大家详细介绍了Java并发系列之AbstractQueuedSynchronizer源码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
在上一篇《Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析》中我们介绍了AbstractQueuedSynchronizer基本的一些概念,主要讲了AQS的排队区是怎样实现的,什么是独占模式和共享模式以及如何理解结点的等待状态。理解并掌握这些内容是后续阅读AQS源码的关键,所以建议读者先看完我的上一篇文章再回过头来看这篇就比较容易理解。在本篇中会介绍在独占模式下结点是怎样进入同步队列排队的,以及离开同步队列之前会进行哪些操作。AQS为在独占模式和共享模式下获取锁分别提供三种获取方式:不响应线程中断获取,响应线程中断获取,设置超时时间获取。这三种方式整体步骤大致是相同的,只有少部分不同的地方,所以理解了一种方式再看其他方式的实现都是大同小异。在本篇中我会着重讲不响应线程中断的获取方式,其他两种方式也会顺带讲一下不一致的地方。
1. 怎样以不响应线程中断获取锁?
//不响应中断方式获取(独占模式) public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) { selfInterrupt(); } }
上面代码中虽然看起来简单,但是它按照顺序执行了下图所示的4个步骤。下面我们会逐个步骤进行演示分析。

第一步:!tryAcquire(arg)
//尝试去获取锁(独占模式) protected boolean tryAcquire(int arg) { throw new UnsupportedOperationException(); }
这时候来了一个人,他首先尝试着去敲了敲门,如果发现门没锁(tryAcquire(arg)=true),那就直接进去了。如果发现门锁了(tryAcquire(arg)=false),就执行下一步。这个tryAcquire方法决定了什么时候锁是开着的,什么时候锁是关闭的。这个方法必须要让子类去覆盖,重写里面的判断逻辑。
第二步:addWaiter(Node.EXCLUSIVE)
//将当前线程包装成结点并添加到同步队列尾部 private Node addWaiter(Node mode) { //指定持有锁的模式 Node node = new Node(Thread.currentThread(), mode); //获取同步队列尾结点引用 Node pred = tail; //如果尾结点不为空, 表明同步队列已存在结点 if (pred != null) { //1.指向当前尾结点 node.prev = pred; //2.设置当前结点为尾结点 if (compareAndSetTail(pred, node)) { //3.将旧的尾结点的后继指向新的尾结点 pred.next = node; return node; } } //否则表明同步队列还没有进行初始化 enq(node); return node; } //结点入队操作 private Node enq(final Node node) { for (;;) { //获取同步队列尾结点引用 Node t = tail; //如果尾结点为空说明同步队列还没有初始化 if (t == null) { //初始化同步队列 if (compareAndSetHead(new Node())) { tail = head; } } else { //1.指向当前尾结点 node.prev = t; //2.设置当前结点为尾结点 if (compareAndSetTail(t, node)) { //3.将旧的尾结点的后继指向新的尾结点 t.next = node; return t; } } } }
执行到这一步表明第一次获取锁失败,那么这个人就给自己领了块号码牌进入排队区去排队了,在领号码牌的时候会声明自己想要以什么样的方式来占用房间(独占模式or共享模式)。注意,这时候他并没有坐下来休息(将自己挂起)哦。
第三步:acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
//以不可中断方式获取锁(独占模式) final boolean acquireQueued(final Node node, int arg) { boolean Failed = true; try { boolean interrupted = false; for (;;) { //获取给定结点的前继结点的引用 final Node p = node.predecessor(); //如果当前结点是同步队列的第一个结点, 就尝试去获取锁 if (p == head && tryAcquire(arg)) { //将给定结点设置为head结点 setHead(node); //为了帮助垃圾收集, 将上一个head结点的后继清空 p.next = null; //设置获取成功状态 Failed = false; //返回中断的状态, 整个循环执行到这里才是出口 return interrupted; } //否则说明锁的状态还是不可获取, 这时判断是否可以挂起当前线程 //如果判断结果为真则挂起当前线程, 否则继续循环, 在这期间线程不响应中断 if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) { interrupted = true; } } } finally { //在最后确保如果获取失败就取消获取 if (Failed) { cancelAcquire(node); } } } //判断是否可以将当前结点挂起 private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { //获取前继结点的等待状态 int ws = pred.waitStatus; //如果前继结点状态为SIGNAL, 表明前继结点会唤醒当前结点, 所以当前结点可以安心的挂起了 if (ws == Node.SIGNAL) { return true; } if (ws > 0) { //下面的操作是清理同步队列中所有已取消的前继结点 do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { //到这里表示前继结点状态不是SIGNAL, 很可能还是等于0, 这样的话前继结点就不会去唤醒当前结点了 //所以当前结点必须要确保前继结点的状态为SIGNAL才能安心的挂起自己 compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; } //挂起当前线程 private final boolean parkAndCheckInterrupt() { LockSupport.park(this); return Thread.interrupted(); }
领完号码牌进入排队区后就会立马执行这个方法,当一个结点首次进入排队区后有两种情况,一种是发现他前面的那个人已经离开座位进入房间了,那他就不坐下来休息了,会再次去敲一敲门看看那小子有没有完事。如果里面的人刚好完事出来了,都不用他叫自己就直接冲进去了。否则,就要考虑坐下来休息一会儿了,但是他还是不放心,如果他坐下来睡着后没人提醒他怎么办?他就在前面那人的座位上留一个小纸条,好让从里面出来的人看到纸条后能够唤醒他。还有一种情况是,当他进入排队区后发现前面还有好几个人在座位上排队呢,那他就可以安心的坐下来咪一会儿了,但在此之前他还是会在前面那人(此时已经睡着了)的座位上留一个纸条,好让这个人在走之前能够去唤醒自己。当一切事情办妥了之后,他就安安心心的睡觉了,注意,我们看到整个for循环就只有一个出口,那就是等线程成功的获取到锁之后才能出去,在没有获取到锁之前就一直是挂在for循环的parkAndCheckInterrupt()方法里头。线程被唤醒后也是从这个地方继续执行for循环。
第四步:selfInterrupt()
//当前线程将自己中断 private static void selfInterrupt() { Thread.currentThread().interrupt(); }
由于上面整个线程一直是挂在for循环的parkAndCheckInterrupt()方法里头,没有成功获取到锁之前不响应任何形式的线程中断,只有当线程成功获取到锁并从for循环出来后,他才会查看在这期间是否有人要求中断线程,如果是的话再去调用selfInterrupt()方法将自己挂起。
2. 怎样以响应线程中断获取锁?
//以可中断模式获取锁(独占模式) private void doAcquireInterruptibly(int arg) throws InterruptedException { //将当前线程包装成结点添加到同步队列中 final Node node = addWaiter(Node.EXCLUSIVE); boolean Failed = true; try { for (;;) { //获取当前结点的前继结点 final Node p = node.predecessor(); //如果p是head结点, 那么当前线程就再次尝试获取锁 if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC Failed = false; //获取锁成功后返回 return; } //如果满足条件就挂起当前线程, 此时响应中断并抛出异常 if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) { //线程被唤醒后如果发现中断请求就抛出异常 throw new InterruptedException(); } } } finally { if (Failed) { cancelAcquire(node); } } }
响应线程中断方式和不响应线程中断方式获取锁流程上大致上是相同的。唯一的一点区别就是线程从parkAndCheckInterrupt方法中醒来后会检查线程是否中断,如果是的话就抛出InterruptedException异常,而不响应线程中断获取锁是在收到中断请求后只是设置一下中断状态,并不会立马结束当前获取锁的方法,一直到结点成功获取到锁之后才会根据中断状态决定是否将自己挂起。
3. 怎样设置超时时间获取锁?
//以限定超时时间获取锁(独占模式) private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException { //获取系统当前时间 long lastTime = System.nanoTime(); //将当前线程包装成结点添加到同步队列中 final Node node = addWaiter(Node.EXCLUSIVE); boolean Failed = true; try { for (;;) { //获取当前结点的前继结点 final Node p = node.predecessor(); //如果前继是head结点, 那么当前线程就再次尝试获取锁 if (p == head && tryAcquire(arg)) { //更新head结点 setHead(node); p.next = null; Failed = false; return true; } //超时时间用完了就直接退出循环 if (nanosTimeout spinForTimeoutThreshold) { //将当前线程挂起一段时间, 之后再自己醒来 LockSupport.parkNanos(this, nanosTimeout); } //获取系统当前时间 long Now = System.nanoTime(); //超时时间每次都减去获取锁的时间间隔 nanosTimeout -= Now - lastTime; //再次更新lastTime lastTime = Now; //在获取锁的期间收到中断请求就抛出异常 if (Thread.interrupted()) { throw new InterruptedException(); } } } finally { if (Failed) { cancelAcquire(node); } } }
设置超时时间获取首先会去获取一下锁,第一次获取锁失败后会根据情况,如果传入的超时时间大于自旋时间那么就会将线程挂起一段时间,否则的话就会进行自旋,每次获取锁之后都会将超时时间减去获取一次锁所用的时间。一直到超时时间小于0也就说明超时时间用完了,那么这时就会结束获取锁的操作然后返回获取失败标志。注意在以超时时间获取锁的过程中是可以响应线程中断请求的。
4. 线程释放锁并离开同步队列是怎样进行的?
//释放锁的操作(独占模式) public final boolean release(int arg) { //拨动密码锁, 看看是否能够开锁 if (tryRelease(arg)) { //获取head结点 Node h = head; //如果head结点不为空并且等待状态不等于0就去唤醒后继结点 if (h != null && h.waitStatus != 0) { //唤醒后继结点 unparkSuccessor(h); } return true; } return false; } //唤醒后继结点 private void unparkSuccessor(Node node) { //获取给定结点的等待状态 int ws = node.waitStatus; //将等待状态更新为0 if (ws 0) { s = null; //从后向前遍历队列找到第一个不是取消状态的结点 for (Node t = tail; t != null && t != node; t = t.prev) { if (t.waitStatus
线程持有锁进入房间后就会去办自己的事情,等事情办完后它就会释放锁并离开房间。通过tryRelease方法可以拨动密码锁进行解锁,我们知道tryRelease方法是需要让子类去覆盖的,不同的子类实现的规则不一样,也就是说不同的子类设置的密码不一样。像在reentrantlock当中,房间里面的人每调用tryRelease方法一次,state就减1,直到state减到0的时候密码锁就开了。大家想想这个过程像不像我们在不停的转动密码锁的转轮,而每次转动转轮数字只是减少1。CountDownLatch和这个也有点类似,只不过它不是一个人在转,而是多个人每人都去转一下,集中大家的力量把锁给开了。线程出了房间后它会找到自己原先的座位,也就是找到head结点。看看座位上有没有人给它留了小纸条,如果有的话它就知道有人睡着了需要让它帮忙唤醒,那么它就会去唤醒那个线程。如果没有的话就表明同步队列中暂时还没有人在等待,也没有人需要它唤醒,所以它就可以安心的离去了。以上过程就是在独占模式下释放锁的过程。
注:以上全部分析基于JDK1.7,不同版本间会有差异,读者需要注意。

Libevent源码分析-----跨平台Reactor接口的实现
转载请注明出处:http://www.jb51.cc/article/p-kofkkjra-gp.html
之前的博文讲了怎么实现线程、锁、内存分配、日志等功能的跨平台。Libevent最重要的跨平台功能还是实现了多路IO接口的跨平台(即Reactor模式)。这使得用户可以在不同的平台使用统一的接口。这篇博文就是来讲解Libevent是怎么实现这一点的。
Libevent在实现线程、内存分配、日志时,都是使用了函数指针和全局变量。在实现多路IO接口上时,Libevent也采用了这种方式,不过还是有点差别的。
相关结构体:
现在来看一下event_base结构体,下面代码只列出了本文要讲的内容:
//event-internal.h文件
struct event_base {
const struct eventop *evsel;
void *evbase;
…
};
struct eventop {
const char *name; //多路IO复用函数的名字
void *(*init)(struct event_base *);
int (*add)(struct event_base *,evutil_socket_t fd,short old,short events,void *fdinfo);
int (*del)(struct event_base *,void *fdinfo);
int (*dispatch)(struct event_base *,struct timeval *);
void (*dealloc)(struct event_base *);
int need_reinit; //是否要重新初始化
//多路IO复用的特征。参考http://blog.csdn.net/luotuo44/article/details/38443569
enum event_method_feature features;
size_t fdinfo_len; //额外信息的长度。有些多路IO复用函数需要额外的信息
};
可以看到event_base结构体中有一个struct eventop类型指针。而这个struct eventop结构体的成员就是一些函数指针。名称也像一个多路IO复用函数应该有的操作:add可以添加fd,del可以删除一个fd,dispatch可以进入监听。明显只要给event_base的evsel成员赋值就能使用对应的多路IO复用函数了。
选择后端:
可供选择的后端:
现在来看一下有哪些可以用的多路IO复用函数。其实在Libevent的源码目录中,已经为每一个多路IO复用函数专门创建了一个文件,如select.c、poll.c、epoll.c、kqueue.c等。
打开这些文件就可以发现在文件的前面都会声明一些多路IO复用的操作函数,而且还会定义一个struct eventop类型的全局变量。如下面代码所示:
//select.c文件
static void *select_init(struct event_base *);
static int select_add(struct event_base *,int,void*);
static int select_del(struct event_base *,void*);
static int select_dispatch(struct event_base *,struct timeval *);
static void select_dealloc(struct event_base *);
const struct eventop selectops = {
"select",select_init,select_add,select_del,select_dispatch,select_dealloc,/* doesn't need reinit. */
EV_FEATURE_FDS,};
//poll.c文件
static void *poll_init(struct event_base *);
static int poll_add(struct event_base *,void *_idx);
static int poll_del(struct event_base *,void *_idx);
static int poll_dispatch(struct event_base *,struct timeval *);
static void poll_dealloc(struct event_base *);
const struct eventop pollops = {
"poll",poll_init,poll_add,poll_del,poll_dispatch,poll_dealloc,/* doesn't need_reinit */
EV_FEATURE_FDS,sizeof(struct pollidx),};
如何选定后端:
看到这里,读者想必已经知道,只需将对应平台的多路IO复用函数的全局变量赋值给event_base的evsel变量即可。可是怎么让Libevent根据不同的平台选择不同的多路IO复用函数呢?另外像大部分OS都会实现select、poll和一个自己的高效多路IO复用函数。怎么从多个中选择一个呢?下面看一下Libevent的解决方案吧:
//event.c文件
#ifdef _EVENT_HAVE_EVENT_PORTS
extern const struct eventop evportops;
#endif
#ifdef _EVENT_HAVE_SELECT
extern const struct eventop selectops;
#endif
#ifdef _EVENT_HAVE_POLL
extern const struct eventop pollops;
#endif
#ifdef _EVENT_HAVE_EPOLL
extern const struct eventop epollops;
#endif
#ifdef _EVENT_HAVE_WORKING_KQUEUE
extern const struct eventop kqops;
#endif
#ifdef _EVENT_HAVE_DEVPOLL
extern const struct eventop devpollops;
#endif
#ifdef WIN32
extern const struct eventop win32ops;
#endif
/* Array of backends in order of preference. */
static const struct eventop *eventops[] = {
#ifdef _EVENT_HAVE_EVENT_PORTS
&evportops,#endif
#ifdef _EVENT_HAVE_WORKING_KQUEUE
&kqops,#endif
#ifdef _EVENT_HAVE_EPOLL
&epollops,#endif
#ifdef _EVENT_HAVE_DEVPOLL
&devpollops,#endif
#ifdef _EVENT_HAVE_POLL
&pollops,#endif
#ifdef _EVENT_HAVE_SELECT
&selectops,#endif
#ifdef WIN32
&win32ops,#endif
NULL
};
它根据宏定义判断当前的OS环境是否有某个多路IO复用函数。如果有,那么就把与之对应的struct eventop结构体指针放到一个全局数组中。有了这个数组,现在只需将数组的某个元素赋值给evsel变量即可。因为是条件宏,在编译器编译代码之前完成宏的替换,所以是可以这样定义一个数组的。关于这些检测当前OS环境的宏,可以参考《event-config.h指明所在系统的环境》。
从数组的元素可以看到,低下标存的是高效多路IO复用函数。如果从低到高下标选取一个多路IO复用函数,那么将优先选择高效的。
具体实现:
现在看一下Libevent是怎么选取一个多路IO复用函数的://event.c文件
struct event_base *
event_base_new_with_config(const struct event_config *cfg)
{
int i;
struct event_base *base;
int should_check_environment;
//分配并清零event_base内存. event_base里的所有成员都会为0
if ((base = mm_calloc(1,sizeof(struct event_base))) == NULL) {
event_warn("%s: calloc",__func__);
return NULL;
}
...
should_check_environment =
!(cfg && (cfg->flags & EVENT_BASE_FLAG_IGnorE_ENV));
//遍历数组的元素
for (i = 0; eventops[i] && !base->evbase; i++) {
if (cfg != NULL) {
/* determine if this backend should be avoided */
if (event_config_is_avoided_method(cfg,eventops[i]->name))
continue;
if ((eventops[i]->features & cfg->require_features)
!= cfg->require_features)
continue;
}
/* also obey the environment variables */
if (should_check_environment &&
event_is_method_disabled(eventops[i]->name))
continue;
//找到了一个满足条件的多路IO复用函数
base->evsel = eventops[i];
//初始化evbase,后面会说到
base->evbase = base->evsel->init(base);
}
if (base->evbase == NULL) {
event_warnx("%s: no event mechanism available",__func__);
base->evsel = NULL;
event_base_free(base);
return NULL;
}
....
return (base);
}
可以看到,首先从eventops数组中选出一个元素。如果设置了event_config,那么就对这个元素(即多路IO复用函数)特征进行检测,看其是否满足event_config所描述的特征。关于event_config,可以查看《多路IO复用函数的选择配置》。
后端数据存储结构体:
在本文最前面列出的event_base结构体中,除了evsel变量外,还有一个evbase变量。这也是一个很重要的变量,而且也是用于跨平台的。
像select、poll、epoll之类多路IO复用函数在调用时要传入一些数据,比如监听的文件描述符fd,监听的事件有哪些。在Libevent中,这些数据都不是保存在event_base这个结构体中的,而是存放在evbase这个指针指向的一个结构体中。
IO复用结构体:
由于不同的多路IO复用函数需要使用不同格式的数据,所以Libevent为每一个多路IO复用函数都定义了专门的结构体(即结构体是不同的),本文姑且称之为IO复用结构体。evbase指向的就是这些结构体。由于这些结构体是不同的,所以要用一个void类型指针。
在select.c、poll.c这类文件中都定义了属于自己的IO复用结构体,如下面代码所示://select.c文件
struct selectop {
int event_fds; /* Highest fd in fd set */
int event_fdsz;
int resize_out_sets;
fd_set *event_readset_in;
fd_set *event_writeset_in;
fd_set *event_readset_out;
fd_set *event_writeset_out;
};
//poll.c文件
struct pollop {
int event_count; /* Highest number alloc */
int nfds; /* Highest number used */
int realloc_copy; /* True iff we must realloc
* event_set_copy */
struct pollfd *event_set;
struct pollfd *event_set_copy;
};
前面event_base_new_with_config的代码中,有下面一行代码:
base->evbase = base->evsel->init(base);明显这行代码就是用来赋值evbase的。下面是poll对应的init函数:
//poll.c文件
static void *
poll_init(struct event_base *base)
{
struct pollop *pollop;
if (!(pollop = mm_calloc(1,sizeof(struct pollop))))
return (NULL);
evsig_init(base);//其他的一些初始化
return (pollop);
}
经过上面的一些处理后,Libevent在特定的OS下能使用到特定的多路IO复用函数。在之前博文中说到的evmap_io_add和evmap_signal_add函数中都会调用evsel->add。由于在新建event_base时就选定了对应的多路IO复用函数,给evsel、evbase变量赋值了,所以evsel->add能把对应的fd和监听事件加到对应的IO复用结构体保存。比如poll的add函数在一开始就有下面一行代码:
struct polloP*pop = base->evbase;
当然,poll的其他函数在一开始时也是会有这行代码的,因为要使用到fd和对应的监听事件等数据,就必须要获取那个IO复用结构体。
由于有evsel和evbase这个两个指针变量,当初始化完成之后,再也不用担心具体使用的多路IO复用函数是哪个了。evsel结构体的函数指针提供了统一的接口,上层的代码要使用到多路IO复用函数的一些操作函数时,直接调用evsel结构体提供的函数指针即可。也正是如此,Libevent实现了统一的跨平台Reactor接口。今天关于React Fiber源码分析 第二篇和同步模式的介绍到此结束,谢谢您的阅读,有关canal源码分析——DirectLogFetcher源码分析、Java并发系列之AbstractQueuedSynchronizer源码分析(共享模式)、Java并发系列之AbstractQueuedSynchronizer源码分析(独占模式)、Libevent源码分析-----跨平台Reactor接口的实现等更多相关知识的信息可以在本站进行查询。
本文标签:




