以上就是给各位分享如何使用Arrow对CSV进行分块?,其中也会对csv数据怎么分列进行解释,同时本文还将给你拓展c#–如何使用CsvHelper将选定的类字段写入CSV?、c#–如何使用简单的页面进
以上就是给各位分享如何使用 Arrow 对 CSV 进行分块?,其中也会对csv数据怎么分列进行解释,同时本文还将给你拓展c# – 如何使用CsvHelper将选定的类字段写入CSV?、c# – 如何使用简单的页面进行分页?、css – 如何使用z-index对盒子阴影进行分层?、linux如何使用parted对大容量硬盘进行分区等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- 如何使用 Arrow 对 CSV 进行分块?(csv数据怎么分列)
- c# – 如何使用CsvHelper将选定的类字段写入CSV?
- c# – 如何使用简单的页面进行分页?
- css – 如何使用z-index对盒子阴影进行分层?
- linux如何使用parted对大容量硬盘进行分区
")
如何使用 Arrow 对 CSV 进行分块?(csv数据怎么分列)
如何解决如何使用 Arrow 对 CSV 进行分块??
我想做什么
我正在使用 PyArrow 读取一些 CSV 并将它们转换为 Parquet。我读过的一些文件有很多列并且内存占用很高(足以使运行作业的机器崩溃)。我正在尝试以类似于 Pandas read_csv 和 chunksize 的工作方式读取 CSV 文件的同时对文件进行分块。
例如这是分块代码在 Pandas 中的工作方式:
chunks = pandas.read_csv(data,chunksize=100,iterator=True)
# Iterate through chunks
for chunk in chunks:
do_stuff(chunk)
我想移植与 Arrow 类似的功能
我尝试做的事情
我注意到 Arrow 有 ReadOptions,其中包含一个 block_size 参数,我想也许我可以像这样使用它:
# Reading in-memory csv file
arrow_table = arrow_csv.read_csv(
input_file=input_buffer,read_options=arrow_csv.ReadOptions(
use_threads=True,block_size=4096
)
)
# Iterate through batches
for batch in arrow_table.to_batches():
do_stuff(batch)
由于这个 (block_size) 似乎没有返回迭代器,我的印象是这仍然会使 Arrow 读取内存中的整个表,从而重新创建我的问题。
最后,我知道我可以首先使用 Pandas 读取 csv 并对其进行分块,然后转换为 Arrow 表。但我尽量避免使用 Pandas,只使用 Arrow。
如果需要,我很乐意提供其他信息
解决方法
您要查找的函数是 pyarrow.csv.open_csv,它返回一个 pyarrow.csv.CSVStreamingReader。批次的大小将由您注意到的 block_size 选项控制。完整示例:
import pyarrow as pa
import pyarrow.parquet as pq
import pyarrow.csv
in_path = ''/home/pace/dev/benchmarks-proj/benchmarks/data/nyctaxi_2010-01.csv.gz''
out_path = ''/home/pace/dev/benchmarks-proj/benchmarks/data/temp/iterative.parquet''
convert_options = pyarrow.csv.ConvertOptions()
convert_options.column_types = {
''rate_code'': pa.utf8(),''store_and_fwd_flag'': pa.utf8()
}
writer = None
with pyarrow.csv.open_csv(in_path,convert_options=convert_options) as reader:
for next_chunk in reader:
if next_chunk is None:
break
if writer is None:
writer = pq.ParquetWriter(out_path,next_chunk.schema)
next_table = pa.Table.from_batches([next_chunk])
writer.write_table(next_table)
writer.close()
此示例还强调了流式 CSV 阅读器带来的挑战之一。它需要返回具有一致数据类型的批次。但是,在解析 CSV 时,您通常需要推断数据类型。在我的示例数据中,文件的前几 MB 具有 rate_code 列的整数值。在批处理中间的某个地方,该列有一个非整数值(在本例中为 *)。要解决此问题,您可以像我在这里所做的那样预先指定列的类型。

c# – 如何使用CsvHelper将选定的类字段写入CSV?
CsvHelper读取和写入CSV文件,这是伟大的,但我不明白如何只写选择的类型字段.
说我们有
using CsvHelper.Configuration;
namespace Project
{
public class DataView
{
[CsvField(Name = "N")]
public string ElementId { get; private set; }
[CsvField(Name = "Quantity")]
public double ResultQuantity { get; private set; }
public DataView(string id,double result)
{
ElementId = id;
ResultQuantity = result;
}
}
}
我们想从我们目前通过以下类似的生成的CSV文件中排除“Quantity”CsvField:
using (var myStream = saveFileDialog1.OpenFile())
{
using (var writer = new CsvWriter(new StreamWriter(myStream)))
{
writer.Configuration.Delimiter = '\t';
writer.WriteHeader(typeof(ResultView));
_researchResults.ForEach(writer.WriteRecord);
}
}
我可以用什么来动态地从CSV中排除类型字段?
如果有必要,我们可以处理生成的文件,但我不知道如何使用CsvHelper删除整个CSV列.
解决方法
using (var myStream = saveFileDialog1.OpenFile())
{
using (var writer = new CsvWriter(new StreamWriter(myStream)))
{
writer.Configuration.AttributeMapping(typeof(DataView)); // Creates the CSV property mapping
writer.Configuration.Properties.RemoveAt(1); // Removes the property at the position 1
writer.Configuration.Delimiter = "\t";
writer.WriteHeader(typeof(DataView));
_researchResults.ForEach(writer.WriteRecord);
}
}
我们强制创建属性映射,然后修改它,动态删除列.

c# – 如何使用简单的页面进行分页?
Mike Culver的An Introduction to Amazon SimpleDB网络研讨会提到使用了面包屑,但他并没有在视频中实现它们.
编辑:视频提到实现向后分页的示例项目,但视频在可以显示下载的URL之前结束.我发现的一个示例项目没有处理分页.
解决方法
SELECT title,summary,Votecount FROM posts WHERE userid = '000022656' LIMIT 25
您已经知道如何处理NextToken,但是如果您使用这种策略,则可以通过存储下一个令牌的导航痕迹(例如在Web会话中)来支持“上一页”,并使用以前的NextToken重新发出查询,而不是接下来的一个.
然而,在SimpleDB中处理任意分页的一般情况与前一个和下一个相同.在一般情况下,用户可以点击任意页面号码,如5,而不用访问第4页或第6页.
您可以在SimpleDB中使用NextToken仅需要WHERE子句才能正常工作的事实来处理此问题.所以,而不是按顺序查询每个页面,拉下所有的插入项,通常可以分两步进行.
>发出您的查询,并以所需页面开始的极限值和SELECT count(*)代替所需的实际属性.
>使用第一步中的NextToken使用所需的属性和页面大小作为LIMIT来获取实际页面数据
所以在伪代码中:
int targetPage,pageSize; ... int jumpLimit = pageSize * (targetPage - 1); String query = "SELECT %1 FROM posts WHERE userid = '000022656' LIMIT %2"; String output = "title,Votecount"; Result temp = sdb.select(query,"count(*)",jumpLimit); Result data = sdb.select(query,output,pageSize,temp.getToken());
其中%1和%2是String替换,“sdb.select()”是一个虚构的方法,包括String替换代码以及SimpleDB调用.
您是否可以在对SimpleDB的两次调用(如代码中所示)中完成此操作将取决于WHERE子句的复杂性和数据集的大小.上述代码简化为,如果查询花费超过5秒钟运行,临时结果可能已返回部分计数.你真的想把这一行放在一个循环中,直到达到正确的数值.为了使代码更加现实,我将其放在方法中,并摆脱String替换:
private Result fetchPage(String query,int targetPage)
{
int pageSize = extractLimitValue(query);
int skipLimit = pageSize * (targetPage - 1);
String token = skipAhead(query,skipLimit);
return sdb.select(query,token);
}
private String skipAhead(String query,int skipLimit)
{
String tempQuery = replaceClause(query,"SELECT","count(*)");
int accumulatedCount = 0;
String token = "";
do {
int tempLimit = skipLimit - accumulatedCount;
tempQuery = replaceClause(tempQuery,"LIMIT",tempLimit + "");
Result tempResult = sdb.select(query,token);
token = tempResult.getToken();
accumulatedCount += tempResult.getCount();
} while (accumulatedCount < skipLimit);
return token;
}
private int extractLimitValue(String query) {...}
private String replaceClause(String query,String clause,String value){...}
这是没有错误处理的一般想法,适用于任意页面,不包括第1页.

css – 如何使用z-index对盒子阴影进行分层?
HTML
<div id="a">
<div id="b">bbb</div>
<div id="c">
<ul>
<li>a</li>
<li>b</li>
<li>c</li>
<li>d</li>
</ul>
</div>
</div>
<div id="d">dddd
</div>
CSS
#b {
background: orange;
Box-shadow: 0 0 10px black;
z-index: 2;
position: relative;
}
#c {
background: red;
z-index: 1;
position: relative;
}
ul {
list-style: none;
margin: 0;
padding: 0;
z-index: 1;
position: relative;
}
li {
display: inline-block;
padding: 2px 5px;
}
.current {
background-color: orange;
z-index: 3;
position: relative;
}
#d {
Box-shadow: 0 0 10px black;
z-index: 2;
}
看看代码笔.我的层数或多或少都是我想要的,除了我希望“b”标签位于由上面的橙色div引起的盒子阴影之上.
要详细说明,橙色#b div应该在红色#c div上投射阴影,.current选项卡应该与橙色#b div齐平(没有阴影),#d不应该在#上投射阴影# c.
问题是.current上的z-index似乎不起作用.
解决方法
有关z-index和堆栈上下文以及优先级的更多信息,请参阅我的答案here.
以上,结合了盒子阴影的插图
inset
If not specified (default),the shadow is assumed to be a drop shadow (as if the Box were raised above the content).
The presence of the inset keyword changes the shadow to one inside the frame (as if the content was depressed inside the Box).
Inset shadows are drawn inside the border (even transparent ones),above the
background,but below content.
而负面的传播
spread-radius
This is a fourth value. Positive values will cause the shadow to expand and grow bigger,negative values will cause the
shadow to shrink. If not specified,it will be 0 (the shadow will be the same size as the element).
(两者都是here)
会给你你想要的效果.
因此,您需要更改阴影应用于元素的位置.
所以最终的CSS:
#b {
background: orange;
z-index: 2;
position: relative;
}
#c {
background: red;
-webkit-Box-shadow: inset 0 10px 10px -10px black;
-moz-Box-shadow: inset 0 10px 10px -10px black;
Box-shadow: inset 0 10px 10px -10px black;
z-index: 1;
position: relative;
}
ul {
list-style: none;
margin: 0;
padding: 0;
z-index: 1;
position: relative;
}
li {
display: inline-block;
padding: 2px 5px;
}
.current {
background-color: orange;
z-index: 3;
position: relative;
}
#d {
Box-shadow: 0 0 10px black;
z-index: 2;
}

linux如何使用parted对大容量硬盘进行分区
随 着单块硬盘容量的增大和硬盘价格的下降,2TB的磁盘使用将很快会普及,由于传统的MBR方式存储分区表的方 式缺陷,将可能导致很多分区工具不能正确地读取大于2TB容量的硬盘而无法正常分区大容量硬盘。其实linux在很早就已经有相关的工具来化解这个困境 了,那就是parted。 parted是类似fdisk的命令行分区软件,假设我们在linux系统中有一块未分区的硬盘挂载为/dev/sdb,下面 以实例的方式来讲解如何使用 parted
工具/原料
Red Hat linux
方法/步骤
1
首先类似fdisk一样,先选择要分区的硬盘,此处为/dev/sdb: # parted /dev/sdb

2
现在我们已经选择了/dev/hdd作为我们操作的磁盘,接下来需要创建一个分区表(在parted中可以 使用help命令打印帮助信息): (parted) mklabel
Warning: The existing disk label on /dev/hdd will be destroyed and all data on this disk will be lost. Do you want to continue? Yes/No?(警告用户磁盘上的数据将会被销毁,询问是否继续,我们这里是新的磁盘,输入yes后回车)

3
创建好分区表以后,接下来就可以进行分区操作了,执行mkpart命令,分别输入分区名称,文件系统和分区 的起止位置 (parted) mkpart

4
分好区后可以使用print命令打印分区信息,下面是一个print的样例 (parted) print

5
如果分区错了,可以使用rm命令删除分区,比如我们要删除上面的分区,然后打印删除后的结果 (parted)rm 1 #rm后面使用分区的号码
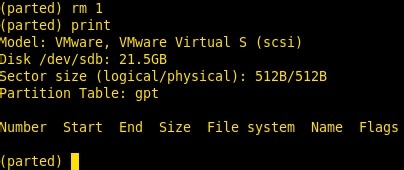
6
到此大家就可以使用parted对大容量硬盘进行分区了, 善加利用哦!
END
注意事项
parted的操作都是实时的,也就是说你执行了一个分区的命令,他就实实在在地分区了,而不是像fdisk那样,需要执行w命令写入所做的修 改, 所以进行parted的测试千万注意不能在生产环境中!!
标记:#开始表示在shell的root下输入的命令,(parted)表示在parted中 输入的命令,其他为自动打印的信息
我们今天的关于如何使用 Arrow 对 CSV 进行分块?和csv数据怎么分列的分享已经告一段落,感谢您的关注,如果您想了解更多关于c# – 如何使用CsvHelper将选定的类字段写入CSV?、c# – 如何使用简单的页面进行分页?、css – 如何使用z-index对盒子阴影进行分层?、linux如何使用parted对大容量硬盘进行分区的相关信息,请在本站查询。
本文标签:




