在本文中,我们将给您介绍关于为ML模型清理CSV文件中的数据的详细内容,此外,我们还将为您提供关于Ajax读取XML文件中的数据源代码、CSV文件数据如何读取、导入、导出到新的CSV文件中以及CSV文
在本文中,我们将给您介绍关于为 ML 模型清理 CSV 文件中的数据的详细内容,此外,我们还将为您提供关于Ajax 读取 XML 文件中的数据源代码、CSV文件数据如何读取、导入、导出到新的CSV文件中以及CSV文件的创建、Django不调用模型清理方法、Java CSV / CSV文件中的删除列的知识。
本文目录一览:- 为 ML 模型清理 CSV 文件中的数据
- Ajax 读取 XML 文件中的数据源代码
- CSV文件数据如何读取、导入、导出到新的CSV文件中以及CSV文件的创建
- Django不调用模型清理方法
- Java CSV / CSV文件中的删除列

为 ML 模型清理 CSV 文件中的数据
如何解决为 ML 模型清理 CSV 文件中的数据?
我正在尝试通过观看几个教程来清理 jupyterlab 中的数据,但我每次都遇到一个或另一个错误。所以我想我会在堆栈溢出时询问是否有人可以帮助我。
这是我要清理的 csv 文件:https://1drv.ms/u/s!AvOXB8kb-IHBgjaveis044GVoPpk
我正在构建一个机器学习模型,所以我想转换所有对象值,但我不知道如何转换。
编辑:我尝试从头开始清理数据。
我的代码输入:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
criminal_data = pd.read_csv(''database2.csv'')
X = criminal_data.drop(columns=[''Agency Type'',''City'',''State'',''Crime Solved''])
y = criminal_data[''City'']
model = DecisionTreeClassifier()
model.fit(X,y)
criminal_data
错误信息:
ValueError Traceback (most recent call
last)
<ipython-input-117-4b6968f9994f> in <module>
6 y = criminal_data[''City'']
7 model = DecisionTreeClassifier()
----> 8 model.fit(X,y)
9 criminal_data
~\anaconda3\lib\site-packages\sklearn\tree\_classes.py in fit(self,X,y,sample_weight,check_input,X_idx_sorted)
896 """
897
--> 898 super().fit(
899 X,900 sample_weight=sample_weight,~\anaconda3\lib\site-packages\sklearn\tree\_classes.py in fit(self,X_idx_sorted)
154 check_X_params = dict(dtype=DTYPE,accept_sparse="csc")
155 check_y_params = dict(ensure_2d=False,dtype=None)
--> 156 X,y = self._validate_data(X,157 validate_separately=(check_X_params,158 check_y_params))
~\anaconda3\lib\site-packages\sklearn\base.py in _validate_data(self,reset,validate_separately,**check_params)
428 # :(
429 check_X_params,check_y_params =
validate_separately
--> 430 X = check_array(X,**check_X_params)
431 y = check_array(y,**check_y_params)
432 else:
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in inner_f(*args,**kwargs)
61 extra_args = len(args) - len(all_args)
62 if extra_args <= 0:
---> 63 return f(*args,**kwargs)
64
65 # extra_args > 0
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in
check_array(array,accept_sparse,accept_large_sparse,dtype,order,copy,force_all_finite,ensure_2d,allow_nd,ensure_min_samples,ensure_min_features,estimator)
614 array = array.astype(dtype,casting="unsafe",copy=False)
615 else:
--> 616 array = np.asarray(array,order=order,dtype=dtype)
617 except ComplexWarning as complex_warning:
618 raise ValueError("Complex data not supported\n"
~\anaconda3\lib\site-packages\numpy\core\_asarray.py in asarray(a,like)
100 return _asarray_with_like(a,dtype=dtype,like=like)
101
--> 102 return array(a,copy=False,order=order)
103
104
~\anaconda3\lib\site-packages\pandas\core\generic.py in __array__(self,dtype)
1897
1898 def __array__(self,dtype=None) -> np.ndarray:
-> 1899 return np.asarray(self._values,dtype=dtype)
1900
1901 def __array_wrap__(
~\anaconda3\lib\site-packages\numpy\core\_asarray.py in asarray(a,order=order)
103
104
ValueError: Could not convert string to float: ''Anchorage''
解决方法
您正在尝试使用一些非数值数据来训练您的模型。在使用模型之前,您需要进行编码。你可以试试LabelEncoder。
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
for column_name in X.columns:
if X[column_name].dtype == object:
X[column_name] = le.fit_transform(X[column_name])
else:
pass
如果您在一行中有不同数据类型的组合。试试下面:
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
for column_name in X.columns:
X[column_name] = X[column_name].replace(np.nan,''none'',regex=True)
X[column_name] = le.fit_transform(X[column_name].astype(str))

Ajax 读取 XML 文件中的数据源代码
总结
以上是小编为你收集整理的Ajax 读取 XML 文件中的数据源代码全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。

CSV文件数据如何读取、导入、导出到新的CSV文件中以及CSV文件的创建
CSV文件数据如何读取、导入、导出到新的CSV文件中以及CSV文件的创建
一.csv文件的创建
(1)新建一个文本文档:
打开新建文本文档,进行编辑。
注意:关键字与关键字之间用英文半角逗号隔开。第一行为引用字段,第二行为对应值。例如:
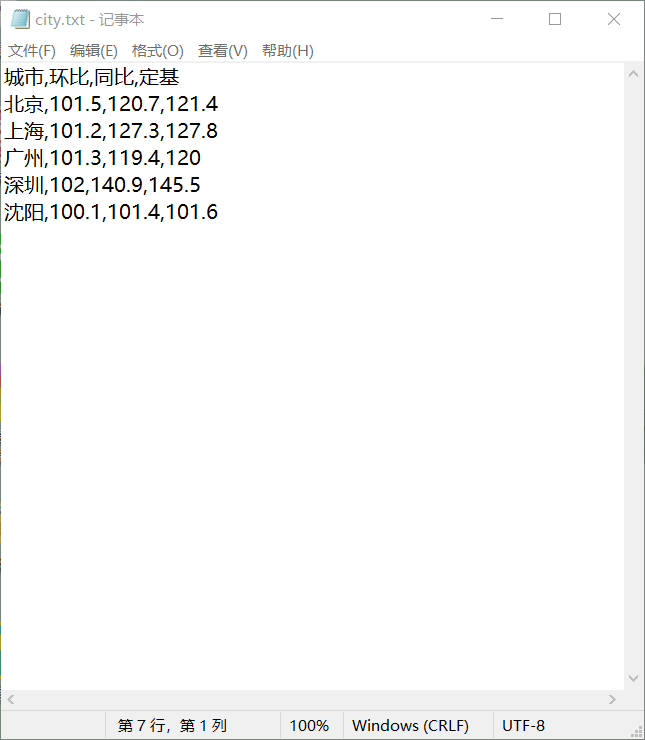
(2)生成csv文件
将文本文档重命名更改文件扩展名,将“.txt”改为“.csv”
重命名重新打开后就是一个CSV文件格式。例如:
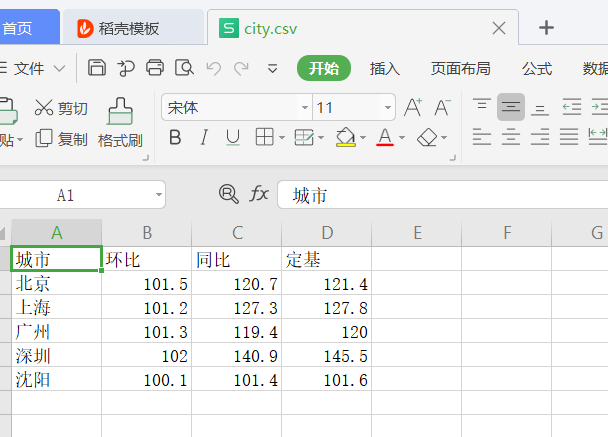
二.数据的表示和读写
csv文件的每一行都是一维数据,可以使用python中的列表类型表示,整个csv文件是一个二维数据,由表示每一行的列表类型作为元素,组成一个二维列表。
注:打开CSV文件的路径可以是绝对路径也可以是相对路径,可根据个人习惯来编写。
(1)导入csv格式数据到列表:
1 fo=open("city.csv","r")#打开命名为city的CSV文件
2 ls=[] #定义一个空列表,将CSV中读取的文件放进列表
3 for line in fo:
4 line=line.replace("\n","")
5 ls.append(line.split(","))
6 print(ls)
7 fo.close()#关闭文件运行结果:
[[''城市'', ''环比'', ''同比'', ''定基''], [''北京'', ''101.5'', ''120.7'', ''121.4''], [''上海'', ''101.2'', ''127.3'', ''127.8''], [''广州'', ''101.3'', ''119.4'', ''120.0''], [''深圳'', ''102.0'', ''140.9'', ''145.5''], [''沈阳'', ''100.1'', ''101.4'', ''101.6''], ['''', '''', '''', '''']](2)逐行处理CSV格式数据:
1 fo=open("city.csv","r")#打开命名为city的CSV文件
2 ls=[]#定义一个空列表,将CSV中读取的文件放进列表
3 for line in fo:
4 line=line.replace("\n","")
5 ls=line.split(",")
6 lns=""
7 for s in ls:
8 lns+="{}\t".format(s)
9 print(lns)
10 fo.close()运行结果:
城市 环比 同比 定基
北京 101.5 120.7 121.4
上海 101.2 127.3 127.8
广州 101.3 119.4 120.0
深圳 102.0 140.9 145.5
沈阳 100.1 101.4 101.6(3)将一维数据写入CSV文件:
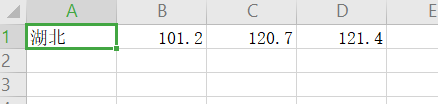
1 fo=open("city.csv","w")
2 ls=[''湖北'',''101.2'',''120.7'',''121.4'']
3 fo.write(",".join(ls)+"\n")
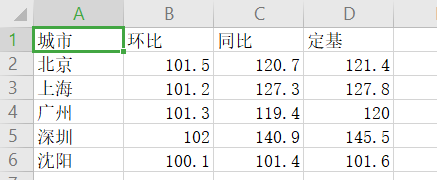
4 fo.close()运行结果;
city.csv文件原有数据:
运行之后的数据:
(4)将二维数据写入CSV文件:
1 fr=open("city1.csv","r")
2 fw=open("city1out.csv","w")
3 ls=[]
4 for line in fr:#将CSV文件当中的二维数据读到列表当中去
5 line=line.replace("\n","")
6 ls.append(line.split(","))
7 for i in range(len(ls)):#遍历列表变量计算百分数
8 for j in range(len(ls[i])):
9 if ls[i][j].replace(".","").isnumeric():
10 ls[i][j]="{:.2}%".format(float(ls[i][j])/100)
11 for row in ls:#将列表变量中的两位数据写入CSV文件当中去
12 print(row)
13 fw.write(",".join(row)+"\n")
14 fr.close()
15 fw.close()运行结果:
city1文件数据与前两个例子的city文件的内容相同,city1out.csv文件为新建立的一个CSV文件。
city1out.csv文件数据:

Django不调用模型清理方法
我有一个视图,该视图从CSV文件创建模型。我已经向模型类定义添加了clean方法,但是在创建模型时不会调用它。
这是models.py的示例:
class Run(models.Model):
name = models.CharField(max_length=120)
tested_build = models.ForeignKey('apps.Build')
timestamp_start = models.DateTimeField()
timestamp_end = models.DateTimeField()
class CommonMeasurement(models.Model):
timestamp = models.DateTimeField()
value = models.FloatField()
run = models.ForeignKey(Run)
def clean(self):
super(CommonMeasurement,self).clean()
print 'here we go'
if self.timestamp < self.run.timestamp_start or self.timestamp > self.run.timestamp_end:
raise django_excetions.ValidationError('Measurement is outside the run')
class ClientMeasurement(CommonMeasurement):
metric = models.ForeignKey(ClientMetric)
account = models.CharField(max_length=120,blank=True)
这是我的Form View代码示例:
class BaseMeasurementsUpload(generic_views.FormView):
template_name = 'upload.html'
models_to_upload = None
def get_success_url(self):
return self.request.get_full_path()
def form_valid(self,form):
uploader = getattr(importers,form.cleaned_data['uploader'])
try:
the_uploader = uploader(form.cleaned_data,self.models_to_upload)
upload_results = the_uploader.get_result_info()
except django_exceptions.ValidationError as e:
custom_errors = e
return render_to_response(self.template_name,{'upload_results': upload_results,'custom_errors': custom_errors},context_instance=RequestContext(self.request))
class ClientMeasurementsUploadView(BaseMeasurementsUpload):
form_class = forms.ClientMeasurementsUploadForm
models_to_upload = models.ClientMeasurement
def get_form(self,form_class):
uploaders = (('MeasurementsSimpleCsv',importers.MeasurementsSimpleCsv.__doc__),('ClientMeasurementsBulkCsv',importers.ClientMeasurementsBulkCsv.__doc__,))
if self.request.POST:
# get bound form
return self.form_class(uploaders,self.request.POST,self.request.FILES)
else:
return forms.ClientMeasurementsUploadForm(uploaders)
进口商执行实际验证并为每个模型调用create方法。

Java CSV / CSV文件中的删除列
我尝试在Java中删除csv文件中的列。
例如,我有这个csv文件
ID name1 name2 name31 hello hell hel2 try tr t3 browser bro br我想要下一个操作后:(删除csvFile,2)将是:
ID name1 name31 hello hel2 try t3 browser br我发现只有调用行而不是列的操作。
答案1
小编典典删除CSV文件中一列的唯一方法是删除整个文件(即文件的每一行)的标题和该列的信息。即使您使用第三方库,它也会在内部进行。
今天的关于为 ML 模型清理 CSV 文件中的数据的分享已经结束,谢谢您的关注,如果想了解更多关于Ajax 读取 XML 文件中的数据源代码、CSV文件数据如何读取、导入、导出到新的CSV文件中以及CSV文件的创建、Django不调用模型清理方法、Java CSV / CSV文件中的删除列的相关知识,请在本站进行查询。
本文标签:




