如果您对通过mongodbriver在Elasticsearch中创建索引中的映射未生效感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于通过mongodbriver在Elas
如果您对通过mongodb river在Elasticsearch中创建索引中的映射未生效感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于通过mongodb river在Elasticsearch中创建索引中的映射未生效的详细内容,我们还将为您解答mongodb in 索引的相关问题,并且为您提供关于elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?、ElasticSearch NEST:通过指定json通过ElasticClient创建索引、elasticsearch 创建索引、Elasticsearch 索引的映射配置详解的有价值信息。
本文目录一览:- 通过mongodb river在Elasticsearch中创建索引中的映射未生效(mongodb in 索引)
- elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?
- ElasticSearch NEST:通过指定json通过ElasticClient创建索引
- elasticsearch 创建索引
- Elasticsearch 索引的映射配置详解
")
通过mongodb river在Elasticsearch中创建索引中的映射未生效(mongodb in 索引)
我正在尝试使用mongodb-
river使用以下命令在elasticsearch中为mongodb编制索引,但文档映射未生效。它仍然使用默认的分析器(标准)作为字段text
Mongodb-river 该文档指定了索引的创建,但是没有有关如何提供自定义映射的文档。这就是我尝试过的。是否有其他文档可以找到如何在使用mongodb-
river的过程中指定自定义分析器等。
curl -XPUT "localhost:9200/_river/autocompleteindex/_meta" -d ''{ "type": "mongodb", "mongodb": { "host": "rahulg-dc", "port": "27017", "db": "qna", "collection": "autocomplete_questions" }, "index": { "name": "autocompleteindex", "type": "autocomplete_questions", "analysis" : { "analyzer" : { "str_search_analyzer" : { "tokenizer" : "keyword", "filter" : ["lowercase"] }, "str_index_analyzer" : { "tokenizer" : "keyword", "filter" : ["lowercase", "ngram"] } }, "filter" : { "ngram" : { "type" : "ngram", "min_gram" : 2, "max_gram" : 20 } } } }, "autocompleteindex": { "_boost" : { "name" : "po", "null_value" : 1.0 }, "properties": { "po": { "type": "double" }, "text": { "type": "string", "boost": 3.0, "search_analyzer" : "str_search_analyzer", "index_analyzer" : "str_index_analyzer" } } }}''如果我按全字词搜索,但不匹配任何子字符串,则查询返回正确的结果。同样,增强因子没有显示出其效果。
我究竟做错了什么 ??
答案1
小编典典您必须首先使用索引设置(分析器)创建索引:
"analysis" : { "analyzer" : { "str_search_analyzer" : { "tokenizer" : "keyword", "filter" : ["lowercase"] }, "str_index_analyzer" : { "tokenizer" : "keyword", "filter" : ["lowercase", "ngram"] } }, "filter" : { "ngram" : { "type" : "ngram", "min_gram" : 2, "max_gram" : 20 } } }然后,您可以为您的类型定义一个映射:
"autocomplete_questions": { "_boost" : { "name" : "po", "null_value" : 1.0 }, "properties": { "po": { "type": "double" }, "text": { "type": "string", "boost": 3.0, "search_analyzer" : "str_search_analyzer", "index_analyzer" : "str_index_analyzer" } }}只有这样,您才能创建河流:
curl -XPUT "localhost:9200/_river/autocompleteindex/_meta" -d ''{"type": "mongodb","mongodb": { "host": "rahulg-dc", "port": "27017", "db": "qna", "collection": "autocomplete_questions"},"index": { "name": "autocompleteindex", "type": "autocomplete_questions"} }有帮助吗?

elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?
在升级elasticsearch时,需要替换river-mongodb插件。由于mongodb河已经过时,因此需要您的帮助来找出替代方案。我们需要索引整个mongodb集合。
答案1
小编典典我知道有两种选择:
- 使用Mongo连接器
- 将Logstash与社区支持的mongodb输入插件一起使用
1比2的优势在于它是MongoDB成员的官方连接器,但是如果您更喜欢Logstash,那么第二种选择可能更适合您。
更新
另一个是mongolastic,它在MongoDB和Elasticsearch之间提供双向同步
更新2
MongoDB,Inc.当前不支持mongo-
connector。

ElasticSearch NEST:通过指定json通过ElasticClient创建索引
如何解决ElasticSearch NEST:通过指定json通过ElasticClient创建索引?
最简单的解决方案是原始问题中选项1的实现。
public void CreateIndex(string indexName, string json)
{
Elasticclient client = GetClient();
var response = _client.Raw.IndicesCreatePost(indexName, json);
if (!response.Success || response.HttpStatusCode != 200)
{
throw new ElasticsearchServerException(response.ServerError);
}
}
修改了转换器,JsonReaders和JsonSerializers之后,我发现IndexSettingsConverter似乎没有正确地将任意设置json反序列化为有效的IndexSettings对象。感觉到一个兔子洞,我接受了Manolis的建议,并弄清楚了如何直接对Elasticclient.IElasticsearchClient应用任意json以避免对安全性和连接细节进行逆向工程。
做出这个结论是费力的,而且如果不处理大量未记录的nesT代码,这是完全不可能的。
解决方法
我们允许客户在创建索引时定义自定义分析器。我们希望在json中指定此名称,以通过基础的ElasticSearch文档提供最大的灵活性和可理解性。
我想使用对json字符串中定义的分析器,映射器等的任意描述来创建索引。凭感觉,我的命令是
PUT /my_index
{
"settings":
{
"analysis":
{
"char_filter" :
{
"my_mapping" :
{
"type" : "mapping","mappings" : [".=>,","''=>,"]
}
},"analyzer":
{
"my_analyzer":
{
"type": "custom","tokenizer": "standard","filter": ["lowercase" ],"char_filter" : ["my_mapping"]
}
}
}
}
}
}
理想情况下,我的代码看起来像
string json = RetrieveJson();
ElasticSearchClient client = InitializeClient();
client.CreateIndexUsingJson( json ); // this is the syntax I can''t figure out
这里的帖子试图通过实例化IndexSettings然后调用Add(“analysis”,json)来实现此目的,但是Add不是我正在使用的ElasticSearch库版本上的函数。
我可以想象的选项包括:
- 以某种方式使用ElasticClient.Raw.IndicesCreatePost或类似的方式
- 通过IndexSettingsConverter.ReadJson()将json字符串反序列化为IndexSettings对象,然后通过ElasticClient.CreateIndex(ICreateIndexRequest)应用它
这两种机制的文档都很少。
我绝对在尝试避免使用CreateIndex的lambda函数版本,因为将用户的json转换为lamdba表达式,只是立即将其转换回NEST中的json,这很痛苦。
上面#1或#2的其他选项或具体示例非常受赞赏,这是解决此问题的推荐方法。

elasticsearch 创建索引
一、基本概念
索引:含有相同属性的文档的集合。 //可以想象成一个数据库 database
类型:索引可以定义一个或多个类型,文档必须属于一个类型。 //可以想象成数据库中的表 table
文档:文档是可以被索引的基本数据单位。 //可以想象成数据库表中的一条数据
分片:每一个索引有多个分片,每个分片都是一个Lucene索引
备份:拷贝一份备份就完成了分片的备份
每创建一个所以默认会创建5个分片和一个备份,当主分片出问题时,备份可以代替工作;备份的分片还可以执行搜索操作
二、创建索引
索引分结构化索引和结构化索引,可以通过mappings来区分
1.创建非结构化索引,如图:
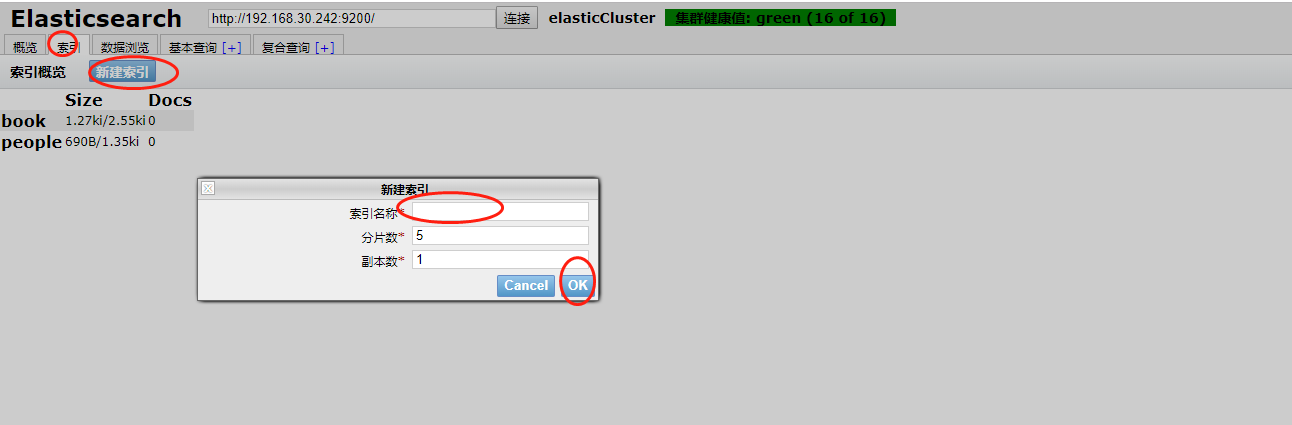
说明:看下图 master 粗框0是主分片,旁边较细的1是分片备份,而下面slave82中的细框0是粗框0的备份,以此类推2,3,4同理

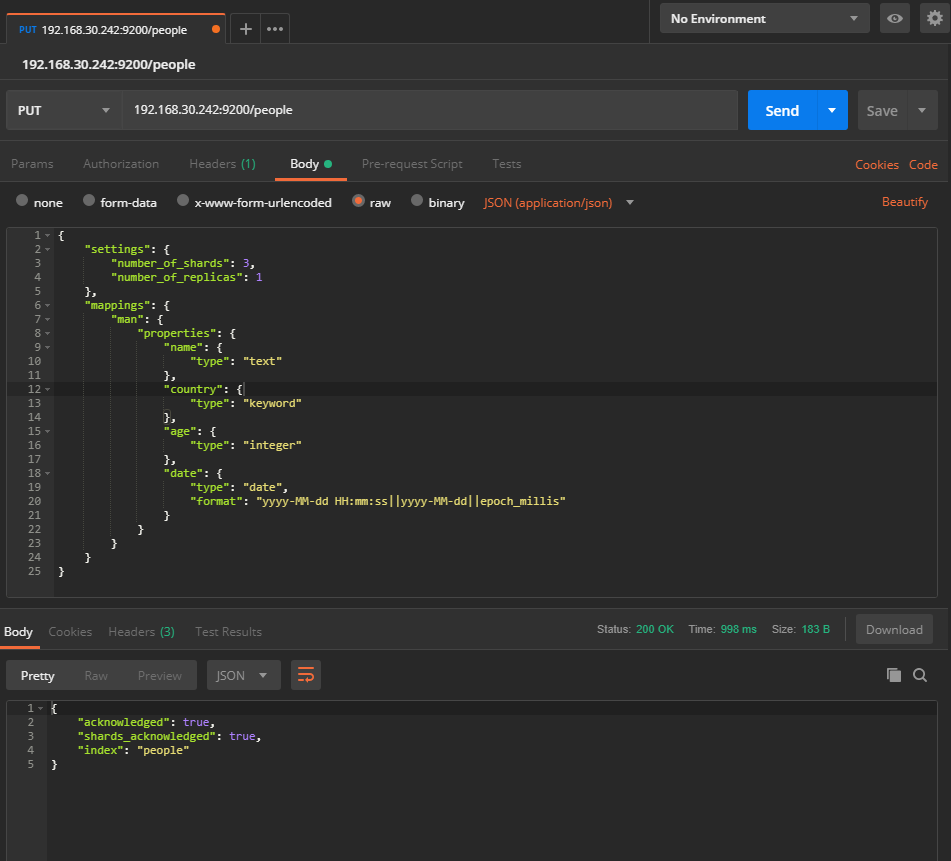
2.创建结构化索引,此处使用工具postman 调用api进行创建
elasticsearch的api是http协议 restful 风格的,格式如下:
http://<ip>:<port>/<索引>/<类型>/<文档id>
创建结构化索引,如图:
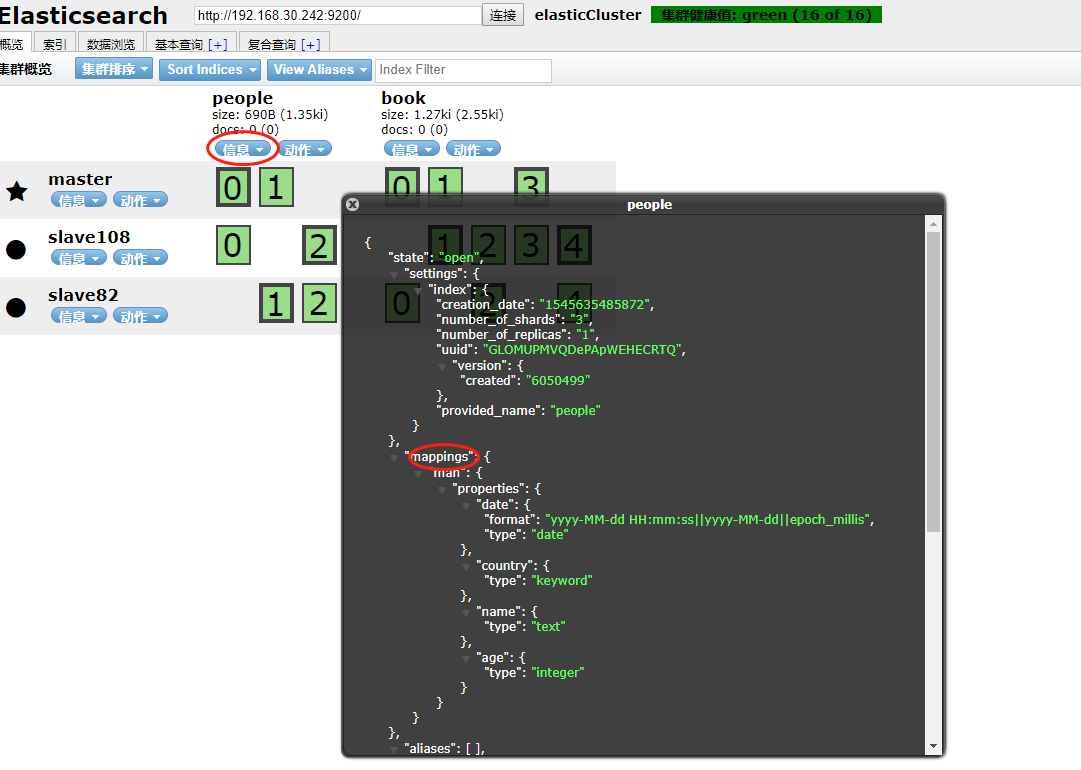
执行成功后刷新 可在信息,索引信息中查看结构化信息,如图:

Elasticsearch 索引的映射配置详解

概述
Elasticsearch 与传统的 SQL数据库的一个明显的不同点是,Elasticsearch 是一个 非结构化 的数据库,或者说是一个 无模式 的数据库。Elasticsearch 中数据最重要的三要素当属:索引、类型、文档,其中索引这个概念非常重要,我们可以粗略地将其类比到传统SQL数据库中的 数据表。本文就从 Elasticsearch 的索引映射如何配置开始讲起。
注: 本文首发于 My Personal Blog,欢迎光临 小站 !
本文内容脑图如下:文章共1540字,阅读本文大约需要5分钟 !

索引模式映射
创建索引时,可以自定义索引的结构,比如 创建一个保存用户信息数据的 users 索引,其典型的结构如下:
id:唯一表示符name:姓名birthday:出生日期hobby:爱好
为此我们可以创建一个 json 格式的索引模式映射文件:users.json
{
"mappings" : {
"user" : {
"properties" : {
"id" : {
"type" : "long",
"store" : "yes"
},
"name" : {
"type" : "string",
"store" : "yes",
"index" : "analyzed"
},
"birthday" : {
"type" : "date",
"store" : "yes"
},
"hobby" : {
"type" : "string",
"store" : "no",
"index" : "analyzed"
}
}
}
}
}
上面的 json代码意义如下:
- 创建一个名称为
users的 Index - 里面有一个名称为
user的 Type - 而
user有四个 field - 且每个 field 都有自己的 属性 定义
然后我们来执行如下命令来新建一个索引:
curl -X PUT http://47.98.43.236:9200/users -d @users.json
结果如下,索引 users、类型 user、以及 四个字段 都已经顺利插入:

关于字段的 可选类型,有如下几种:
string:字符串number:数字date:日期boolean:布尔型binary:二进制ip:IP地址token_count类型
关于每种类型有哪些 属性,可参考官方文档,由于内容太多,此处不再赘述。
分析器的使用
分析器是一种用于 分析数据 或者按照用户想要的方式 处理数据 的工具,对于 字符串类型 的字段,Elasticsearch 允许用户自定义分析器。
- 先来自定义一个分析器
{
"settings" : {
"index" : {
"analysis" : {
"analyzer" : {
"myanalyzer" : {
"tokenizer" : "standard",
"filter" : [
"asciifolding",
"lowercase",
"myFilter"
]
}
},
"filter" : {
"myFilter" : {
"type" : "kstem"
}
}
}
}
},
"mappings" : {
"user" : {
"properties" : {
"id" : {
"type" : "long",
"store" : "yes"
},
"name" : {
"type" : "string",
"store" : "yes",
"index" : "analyzed",
"analyzer" : "myanalyzer"
},
"birthday" : {
"type" : "date",
"store" : "yes"
},
"hobby" : {
"type" : "string",
"store" : "no",
"index" : "analyzed"
}
}
}
}
}
上述 json代码中,用户定义了一个名为 myanalyzer 的分析器,该分析器包含 一个分词器 + 三个过滤器,分别如下:
- 分词器:
standard - 过滤器:
asciifolding - 过滤器:
lowercase - 过滤器:
myFilter(自定义过滤器,其本质是kstem)
- 再来看如何测试和使用自定义的分析器
可以通过类似如下的 Restful接口来测试 analyze API 的工作情况:
curl -X GET ''http://47.98.43.236:9200/users/_analyze?field=user.name'' -d ''Cars Trains''
可见我们输入的时一行字符串普通"Cars Trains",而输出为:car 和 train,这说明短语 "Cars Trains" 被分成了两个词条,然后全部转为小写,最后做了词干提取的操作,由此证明我们上面自定义的分析器已然生效了!
相似度模型的配置
Elasticsearch 允许为索引模式映射文件中的不同字段指定不同的 相似度得分 计算模型,其用法例析如下:
"mappings" : {
"user" : {
"properties" : {
"id" : {
"type" : "long",
"store" : "yes"
},
"name" : {
"type" : "string",
"store" : "yes",
"index" : "analyzed",
"analyzer" : "myanalyzer",
"similarity" : "BM25"
},
"birthday" : {
"type" : "date",
"store" : "yes"
},
"hobby" : {
"type" : "string",
"store" : "no",
"index" : "analyzed"
}
}
}
}
上述 json文件中,我们为
name字段使用了BM25这种相似度模型,添加的方法是使用similarity属性的键值对,这样一来 Elasticsearch 将会为name字段使用BM25相似度计算模型来计算相似得分。
信息格式的配置
Elasticsearch 支持为每个字段指定信息格式,以满足通过改变字段被索引的方式来提高性能的条件。Elasticsearch 中的信息格式有如下几个:
default:默认信息格式,其提供了实时的对存储字段和词向量的压缩pulsing:将 重复值较少字段 的信息列表 编码为词条矩阵,可加快 该字段的查询速度direct:该格式在读过程中将词条加载到未经压缩而存在内存的矩阵中,该格式可以提升常用字段的性能,但损耗内存memory:该格式将所有的数据写到磁盘,然后需要FST来读取词条和信息列表到内存中bloom_default:默认信息格式的扩展,增加了把bloom filter写入磁盘的功能。读取时bloom filter被读取并存入内存,以便快速检查给定的值是否存在bloom_pulsing:pulsing格式的扩展,也加入bloom filter的支持
信息格式字段(postings_format)可以在 任何一个字段上 进行设置,配置信息格式的示例如下:
"mappings" : {
"user" : {
"properties" : {
"id" : {
"type" : "long",
"store" : "yes",
"postings_format" : "pulsing"
},
"name" : {
"type" : "string",
"store" : "yes",
"index" : "analyzed",
"analyzer" : "myanalyzer"
},
"birthday" : {
"type" : "date",
"store" : "yes"
},
"hobby" : {
"type" : "string",
"store" : "no",
"index" : "analyzed"
}
}
}
}
在该例子之中,我们手动配置改变了
id字段的信息格式为pulsing,因此可加快该字段的查询速度。
文档值及其格式的配置
文档值 这个字段属性作用在于:其允许将给定字段的值被写入一个更高内存效率的结构,以便进行更加高效的排序和搜索。我们通常可以将该属性加在 需要进行排序 的字段上,这样可以 提效。
其配置方式是 通过属性 doc_values_format 进行,有三种常用的 doc_values_format 属性值,其含义从名字中也能猜个大概:
default:默认格式,其使用少量的内存但性能也不错disk:将数据存入磁盘,几乎无需内存memory:将数据存入内存
举个栗子吧:
"mappings" : {
"user" : {
"properties" : {
"id" : {
"type" : "long",
"store" : "yes"
},
"name" : {
"type" : "string",
"store" : "yes",
"index" : "analyzed",
"analyzer" : "myanalyzer"
},
"birthday" : {
"type" : "date",
"store" : "yes"
},
"hobby" : {
"type" : "string",
"store" : "no",
"index" : "analyzed"
},
"age" : {
"type" : "integer",
"doc_values_format" : "memory"
}
}
}
}
上述 json配置中,我们给类型
user添加了一个age字段,假如我们想对年龄字段进行排序,那么给该字段设置文档值格式的属性是可以提升效率的。
后 记
由于能力有限,若有错误或者不当之处,还请大家批评指正,一起学习交流!
-
My Personal Blog
-
我的半年技术博客之路
今天关于通过mongodb river在Elasticsearch中创建索引中的映射未生效和mongodb in 索引的讲解已经结束,谢谢您的阅读,如果想了解更多关于elasticsearch 2.2.0支持的Elastic river-mongodb插件的替代方案是什么?、ElasticSearch NEST:通过指定json通过ElasticClient创建索引、elasticsearch 创建索引、Elasticsearch 索引的映射配置详解的相关知识,请在本站搜索。
本文标签:




