如果您想了解向ElasticSearch术语聚合添加其他字段和elasticsearch嵌套聚合的知识,那么本篇文章将是您的不二之选。我们将深入剖析向ElasticSearch术语聚合添加其他字段的各
如果您想了解向ElasticSearch术语聚合添加其他字段和elasticsearch嵌套聚合的知识,那么本篇文章将是您的不二之选。我们将深入剖析向ElasticSearch术语聚合添加其他字段的各个方面,并为您解答elasticsearch嵌套聚合的疑在这篇文章中,我们将为您介绍向ElasticSearch术语聚合添加其他字段的相关知识,同时也会详细的解释elasticsearch嵌套聚合的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- 向ElasticSearch术语聚合添加其他字段(elasticsearch嵌套聚合)
- Elastic Search中嵌套字段的术语聚合
- ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
- Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
- ElasticSearch java API - 聚合查询-聚合多字段聚合demo
")
向ElasticSearch术语聚合添加其他字段(elasticsearch嵌套聚合)
索引文件如下:
{ id: 1, title: ''Blah'', ... platform: {id: 84, url: ''http://facebook.com'', title: ''Facebook''} ...}我想要的是按平台计数和输出统计信息。为了进行计数,我可以将术语聚合platform.id作为字段进行计数:
aggs: { platforms: { terms: {field: ''platform.id''} }}这样,我就可以像{key: 8, doc_count: 162511}预期那样将统计数据作为多个存储桶接收到。
现在,我还能以某种方式添加到这些存储桶中吗(platform.name以及platform.url用于统计的漂亮输出)?我附带的最好的看起来像:
aggs: { platforms: { terms: {field: ''platform.id''}, aggs: { name: {terms: {field: ''platform.name''}}, url: {terms: {field: ''platform.url''}} } }}实际上,它可以工作,并且在每个存储桶中返回非常复杂的结构:
{key: 7, doc_count: 528568, url: {doc_count_error_upper_bound: 0, sum_other_doc_count: 0, buckets: [{key: "http://facebook.com", doc_count: 528568}]}, name: {doc_count_error_upper_bound: 0, sum_other_doc_count: 0, buckets: [{key: "Facebook", doc_count: 528568}]}},当然,可以从此结构中提取平台的名称和网址(例如bucket.url.buckets.first.key),但是是否有更干净,更简单的方法来完成任务?
答案1
小编典典表示意图的最佳方法似乎是热门匹配:“从每个聚合组中仅选择一个文档”,然后从中提取平台:
aggs: { platforms: { terms: {field: ''platform.id''}, aggs: { platform: {top_hits: {size: 1, _source: {include: [''platform'']}}} }}这样,每个被推销的对象将看起来像:
{"key": 7, "doc_count": 529939, "platform": { "hits": { "hits": [{ "_source": { "platform": {"id": 7, "name": "Facebook", "url": "http://facebook.com"} } }] } },}有点过深(与ES一样),但是很干净: bucket.platform.hits.hits.first._source.platform

Elastic Search中嵌套字段的术语聚合
我在elasticsearch(YML中的定义)中具有字段的下一个映射:
my_analyzer: type: custom tokenizer: keyword filter: lowercase products_filter: type: "nested" properties: filter_name: {"type" : "string", analyzer: "my_analyzer"} filter_value: {"type" : "string" , analyzer: "my_analyzer"}每个文档都有很多过滤器,看起来像:
"products_filter": [{"filter_name": "Rahmengröße","filter_value": "33,5 cm"},{"filter_name": "color","filter_value": "gelb"},{"filter_name": "Rahmengröße","filter_value": "39,5 cm"},{"filter_name": "Rahmengröße","filter_value": "45,5 cm"}]我试图获取唯一过滤器名称的列表以及每个过滤器的唯一过滤器值的列表。
我的意思是,我想获得结构是怎样的:Rahmengröße:
39.5厘米
45.5厘米
33.5厘米
颜色:
盖尔布
为了得到它,我尝试了几种聚合的变体,例如:
{ "aggs": { "bla": { "terms": { "field": "products_filter.filter_name" }, "aggs": { "bla2": { "terms": { "field": "products_filter.filter_value" } } } } }}这个请求是错误的。
它将为我返回唯一过滤器名称的列表,并且每个列表将包含所有filter_values的列表。
"bla": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 103,"buckets": [{"key": "color","doc_count": 9,"bla2": {"doc_count_error_upper_bound": 4,"sum_other_doc_count": 366,"buckets": [{"key": "100","doc_count": 5},{"key": "cm","doc_count": 5},{"key": "unisex","doc_count": 5},{"key": "11","doc_count": 4},{"key": "160","doc_count": 4},{"key": "22","doc_count": 4},{"key": "a","doc_count": 4},{"key": "alu","doc_count": 4},{"key": "aluminium","doc_count": 4},{"key": "aus","doc_count": 4}]}},另外,我尝试使用反向嵌套聚合,但这对我没有帮助。
所以我认为我的尝试有逻辑上的错误吗?
答案1
小编典典如我所说。您的问题是您的文本被分析,elasticsearch总是在令牌级别聚合。因此,为了解决该问题,必须将字段值索引为单个标记。有两种选择:
- 不分析它们
- 使用关键字分析器+小写(不区分大小写的aggs)为它们编制索引
因此,将使用小写过滤器并删除重音符号(ö => o以及ß =>ss您的字段的其他字段,以创建自定义关键字分析器)来进行设置,以便将它们用于聚合(raw和keyword):
PUT /test{ "settings": { "analysis": { "analyzer": { "my_analyzer_keyword": { "type": "custom", "tokenizer": "keyword", "filter": [ "asciifolding", "lowercase" ] } } } }, "mappings": { "data": { "properties": { "products_filter": { "type": "nested", "properties": { "filter_name": { "type": "string", "analyzer": "standard", "fields": { "raw": { "type": "string", "index": "not_analyzed" }, "keyword": { "type": "string", "analyzer": "my_analyzer_keyword" } } }, "filter_value": { "type": "string", "analyzer": "standard", "fields": { "raw": { "type": "string", "index": "not_analyzed" }, "keyword": { "type": "string", "analyzer": "my_analyzer_keyword" } } } } } } } }}测试文件,您给了我们:
PUT /test/data/1{ "products_filter": [ { "filter_name": "Rahmengröße", "filter_value": "33,5 cm" }, { "filter_name": "color", "filter_value": "gelb" }, { "filter_name": "Rahmengröße", "filter_value": "39,5 cm" }, { "filter_name": "Rahmengröße", "filter_value": "45,5 cm" } ]}这将是查询以使用raw字段进行汇总:
GET /test/_search{ "size": 0, "aggs": { "Nesting": { "nested": { "path": "products_filter" }, "aggs": { "raw_names": { "terms": { "field": "products_filter.filter_name.raw", "size": 0 }, "aggs": { "raw_values": { "terms": { "field": "products_filter.filter_value.raw", "size": 0 } } } } } } }}它确实带来了预期的结果(带有过滤器名称的存储桶和带有其值的子存储桶):
{ "took": 1, "timed_out": false, "_shards": { "total": 5, "successful": 5, "failed": 0 }, "hits": { "total": 1, "max_score": 0, "hits": [] }, "aggregations": { "Nesting": { "doc_count": 4, "raw_names": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "Rahmengröße", "doc_count": 3, "raw_values": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "33,5 cm", "doc_count": 1 }, { "key": "39,5 cm", "doc_count": 1 }, { "key": "45,5 cm", "doc_count": 1 } ] } }, { "key": "color", "doc_count": 1, "raw_values": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "gelb", "doc_count": 1 } ] } } ] } } }}另外,您可以将field与关键字分析器(以及一些规范化)结合使用,以获得更通用且不区分大小写的结果:
GET /test/_search{ "size": 0, "aggs": { "Nesting": { "nested": { "path": "products_filter" }, "aggs": { "keyword_names": { "terms": { "field": "products_filter.filter_name.keyword", "size": 0 }, "aggs": { "keyword_values": { "terms": { "field": "products_filter.filter_value.keyword", "size": 0 } } } } } } }}结果就是:
{ "took": 1, "timed_out": false, "_shards": { "total": 5, "successful": 5, "failed": 0 }, "hits": { "total": 1, "max_score": 0, "hits": [] }, "aggregations": { "Nesting": { "doc_count": 4, "keyword_names": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "rahmengrosse", "doc_count": 3, "keyword_values": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "33,5 cm", "doc_count": 1 }, { "key": "39,5 cm", "doc_count": 1 }, { "key": "45,5 cm", "doc_count": 1 } ] } }, { "key": "color", "doc_count": 1, "keyword_values": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "gelb", "doc_count": 1 } ] } } ] } } }} ElasticSearch 的应用场景及为什么要选择 ElasticSearch?")
ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
先了解一下数据的分类
结构化数据
又可以称之为行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。其实就是可以能够用数据或者统一的结构加以表示的数据。比如在数据表存储商品的库存,可以用整型表示,存储价格可以用浮点型表示,再比如给用户存储性别,可以用枚举表示,这都是结构化数据。
非结构化数据
无法用数字或者统一的结构表示的数据,称之为飞结构化数据。如:文本、图像、声音、网页。
其实结构化数据又数据非结构化数据。商品标题、描述、文章描述都是文本,其实文本就是非结构化数据。那么就可以说非结构化数据即为全文数据。
什么是全文检索?
一种将文件或者数据库中所有文本与检索项相匹配的文字资料检索方法,称之为全文检索。
全文检索的两种方法
顺序扫描法:将数据表的所有数据逐个扫描,再对文字描述扫描,符合条件的筛选出来,非常慢!
索引扫描法:全文检索的基本思路,也就是将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对快的目的。
全文检索的过程:
先索引的创建,然后索引搜索
为什么要选择用 ElasticSearch?
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
分布式的实时文件存储,每个字段都被索引可被搜索。
分布式的实时分析搜索引擎。
可以扩展到上百台服务器,处理 PB 级别结构化或者非结构化数据。
所有功能集成在一个服务器里,可以通过 RESTful API、各种语言的客户端甚至命令与之交互。
上手容易,提供了很多合理的缺省值,开箱即用,学习成本低。
可以免费下载、使用和修改。
配置灵活,比 Sphinx 灵活的多。

Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
CentOS6.5下安装ElasticSearch6.2.4
(1)配置JDK环境
配置环境变量
export JAVA_HOME="/opt/jdk1.8.0_144"
export PATH="$JAVA_HOME/bin:$PATH"
export CLASSPATH=".:$JAVA_HOME/lib"
(2)安装ElasticSearch6.2.4
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-4
启动报错:
解决方式:
bin/elasticsearch -Des.insecure.allow.root=true
或者修改bin/elasticsearch,加上ES_JAVA_OPTS属性:
ES_JAVA_OPTS="-Des.insecure.allow.root=true"
再次启动:
这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考 虑,建议创建一个单独的用户用来运行ElasticSearch。
如果没有普通用户就要创建一个普通用户组和普通用户,下面介绍一下怎么创建用户组和普通用户
创建用户组和用户:
groupadd esgroup
useradd esuser -g esgroup -p espassword
更改elasticsearch文件夹及内部文件的所属用户及组:
cd /opt
chown -R esuser:esgroup elasticsearch-6.2.4
切换用户并运行:
su esuser
./bin/elasticsearch
再次启动显示已杀死:
需要调整JVM的内存大小:
vi bin/elasticsearch
ES_JAVA_OPTS="-Xms512m -Xmx512m"
再次启动:启动成功
如果显示如下类似信息:
[INFO ][o.e.c.r.a.DiskThresholdMonitor] [ZAds5FP] low disk watermark [85%] exceeded on [ZAds5FPeTY-ZUKjXd7HJKA][ZAds5FP][/opt/elasticsearch-6.2.4/data/nodes/0] free: 1.2gb[14.2%], replicas will not be assigned to this node
需要清理磁盘空间。
后台运行:./bin/elasticsearch -d
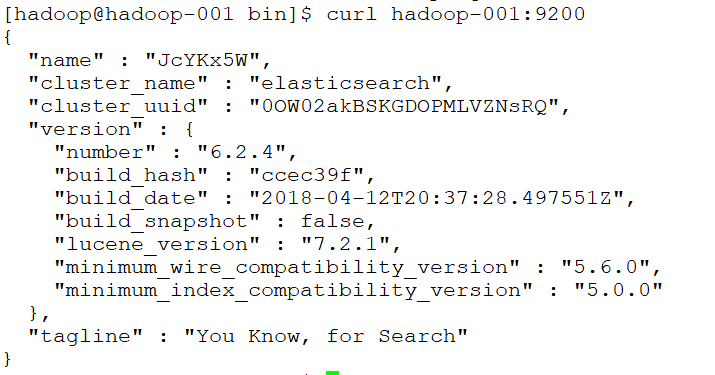
测试连接:curl 127.0.0.1:9200
会看到一下JSON数据:
[root@localhost ~]# curl 127.0.0.1:9200
{
"name" : "rBrMTNx",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "-noR5DxFRsyvAFvAzxl07g",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
实现远程访问:
需要对config/elasticsearch.yml进行 配置:
network.host: hadoop-001
再次启动报错:Failed to load settings from [elasticsearch.yml]
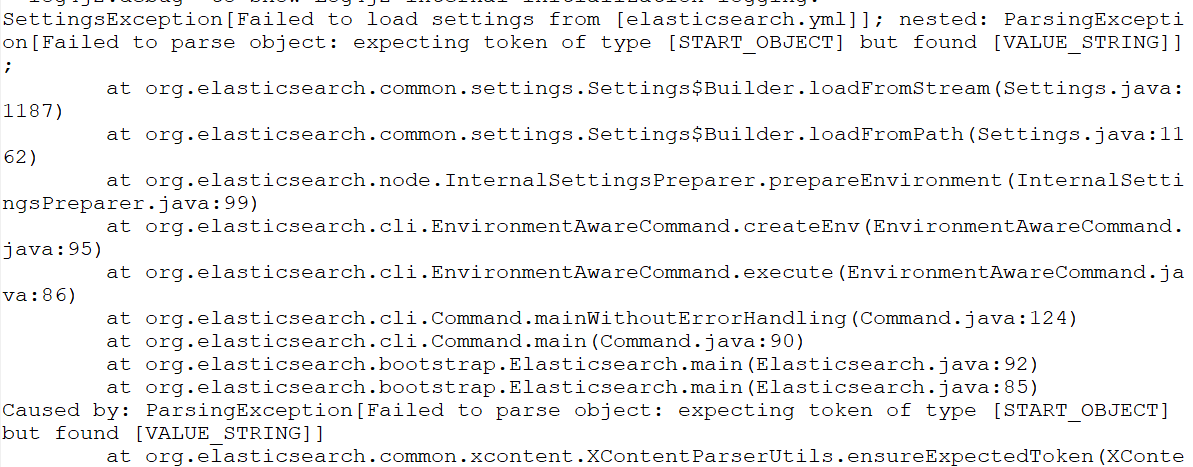
这个错就是参数的冒号前后没有加空格,加了之后就好,我找了好久这个问题;
后来在一个外国网站找到了这句话.
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ElasticsearchParseException[malformed, expected end of settings but encountered additional content starting at line number: [3], column number: [1]]; nested: ParserException[expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
^
];
Likely root cause: expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
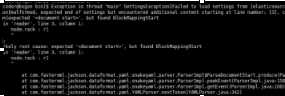
这个是行的开头没有加空格,fuck!
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ScannerException[while scanning a simple key
in ''reader'', line 11, column 2:
discovery.zen.ping.unicast.hosts ...
^

参数冒号后加空格,或者是数组中间加空格
例如:
# discovery.zen.minimum_master_nodes: 3
再次启动
还是报错
max file descriptors [4096] for elasticsearch process is too low
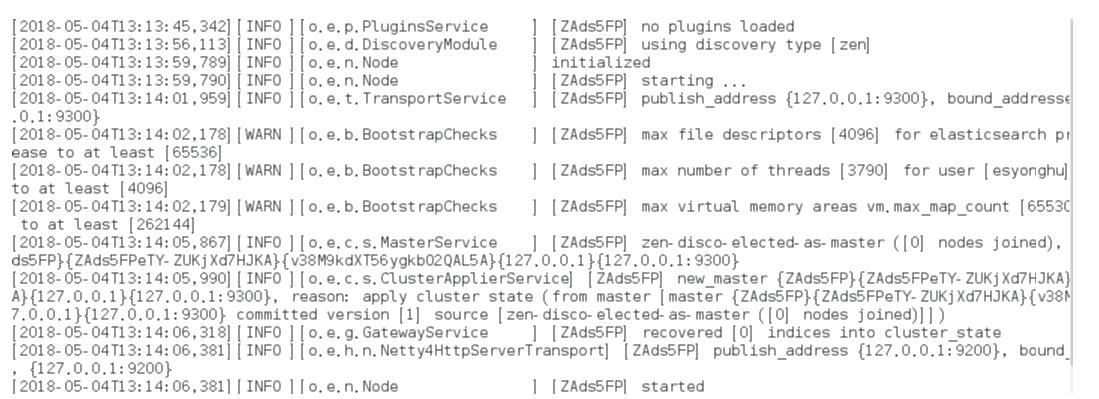
处理第一个错误:
vim /etc/security/limits.conf //文件最后加入
esuser soft nofile 65536
esuser hard nofile 65536
esuser soft nproc 4096
esuser hard nproc 4096
处理第二个错误:
进入limits.d目录下修改配置文件。
vim /etc/security/limits.d/20-nproc.conf
修改为 esuser soft nproc 4096
注意重新登录生效!!!!!!!!
处理第三个错误:
vim /etc/sysctl.conf
vm.max_map_count=655360
执行以下命令生效:
sysctl -p
关闭防火墙:systemctl stop firewalld.service
启动又又又报错
system call filters failed to install; check the logs and fix your configuration or disable sys

直接在
config/elasticsearch.yml 末尾加上一句
bootstrap.system_call_filter: false再次启动成功!
安装Head插件
Head是elasticsearch的集群管理工具,可以用于数据的浏览和查询
(1)elasticsearch-head是一款开源软件,被托管在github上面,所以如果我们要使用它,必须先安装git,通过git获取elasticsearch-head
(2)运行elasticsearch-head会用到grunt,而grunt需要npm包管理器,所以nodejs是必须要安装的
nodejs和npm安装:
http://blog.java1234.com/blog/articles/354.html
git安装
yum install -y git
(3)elasticsearch5.0之后,elasticsearch-head不做为插件放在其plugins目录下了。
使用git拷贝elasticsearch-head到本地
cd ~
git clone git://github.com/mobz/elasticsearch-head.git
(4)安装elasticsearch-head依赖包
[root@localhost local]# npm install -g grunt-cli
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# cnpm install
(5)修改Gruntfile.js
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# vi Gruntfile.js
在connect-->server-->options下面添加:hostname:’*’,允许所有IP可以访问
(6)修改elasticsearch-head默认连接地址
[root@localhost elasticsearch-head]# cd /usr/local/elasticsearch-head/_site/
[root@localhost _site]# vi app.js
将this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";中的localhost修改成你es的服务器地址
(7)配置elasticsearch允许跨域访问
打开elasticsearch的配置文件elasticsearch.yml,在文件末尾追加下面两行代码即可:
http.cors.enabled: true
http.cors.allow-origin: "*"
(8)打开9100端口
[root@localhost elasticsearch-head]# firewall-cmd --zone=public --add-port=9100/tcp --permanent
重启防火墙
[root@localhost elasticsearch-head]# firewall-cmd --reload
(9)启动elasticsearch
(10)启动elasticsearch-head
[root@localhost _site]# cd ~/elasticsearch-head/
[root@localhost elasticsearch-head]# node_modules/grunt/bin/grunt server 或者 npm run start
(11)访问elasticsearch-head
关闭防火墙:systemctl stop firewalld.service
浏览器输入网址:hadoop-001:9100/
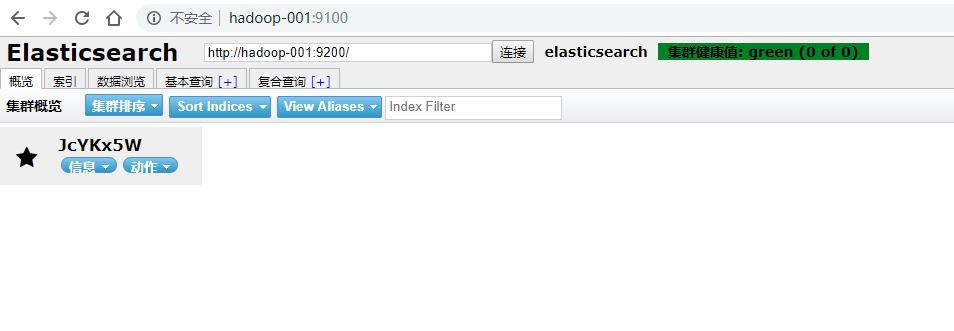
安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据
(1)下载Kibana
https://www.elastic.co/downloads/kibana
(2)把下载好的压缩包拷贝到/soft目录下
(3)解压缩,并把解压后的目录移动到/user/local/kibana
(4)编辑kibana配置文件
[root@localhost /]# vi /usr/local/kibana/config/kibana.yml
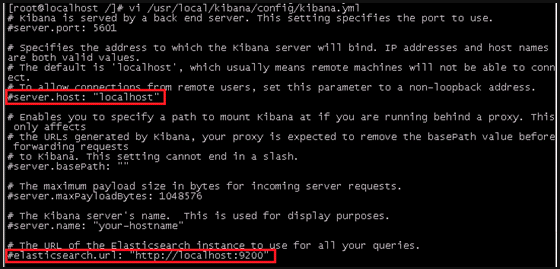
将server.host,elasticsearch.url修改成所在服务器的ip地址
server.port: 5601 //监听端口
server.host: "hadoo-001" //监听IP地址,建议内网ip
elasticsearch.url: "http:/hadoo-001" //elasticsearch连接kibana的URL,也可以填写192.168.137.188,因为它们是一个集群
(5)开启5601端口
Kibana的默认端口是5601
开启防火墙:systemctl start firewalld.service
开启5601端口:firewall-cmd --permanent --zone=public --add-port=5601/tcp
重启防火墙:firewall-cmd –reload
(6)启动Kibana
[root@localhost /]# /usr/local/kibana/bin/kibana
浏览器访问:http://192.168.137.188:5601
安装中文分词器
一.离线安装
(1)下载中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
下载elasticsearch-analysis-ik-master.zip
(2)解压elasticsearch-analysis-ik-master.zip
unzip elasticsearch-analysis-ik-master.zip
(3)进入elasticsearch-analysis-ik-master,编译源码
mvn clean install -Dmaven.test.skip=true
(4)在es的plugins文件夹下创建目录ik
(5)将编译后生成的elasticsearch-analysis-ik-版本.zip移动到ik下,并解压
(6)解压后的内容移动到ik目录下
二.在线安装
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip

ElasticSearch java API - 聚合查询-聚合多字段聚合demo
以球员信息为例,player索引的player type包含5个字段,姓名,年龄,薪水,球队,场上位置。
index的mapping为:
"mappings": {
"player": {
"properties": {
"name": {
"index": "not_analyzed",
"type": "string"
},
"age": {
"type": "integer"
},
"salary": {
"type": "integer"
},
"team": {
"index": "not_analyzed",
"type": "string"
},
"position": {
"index": "not_analyzed",
"type": "string"
}
},
"_all": {
"enabled": false
}
}
}
索引中的全部数据:
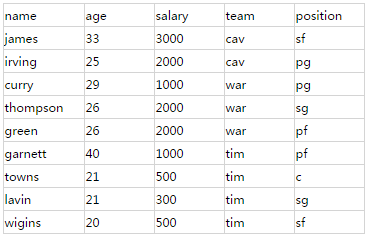
首先,初始化Builder:
SearchRequestBuilder sbuilder = client.prepareSearch("player").setTypes("player");接下来举例说明各种聚合操作的实现方法,因为在es的api中,多字段上的聚合操作需要用到子聚合(subAggregation),初学者可能找不到方法(网上资料比较少,笔者在这个问题上折腾了两天,最后度了源码才彻底搞清楚T_T),后边会特意说明多字段聚合的实现方法。另外,聚合后的排序也会单独说明。
- group by/count
例如要计算每个球队的球员数,如果使用SQL语句,应表达如下:
select team, count(*) as player_count from player group by team;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
sbuilder.addAggregation(teamAgg);
SearchResponse response = sbuilder.execute().actionGet();
- group by多个field
例如要计算每个球队每个位置的球员数,如果使用SQL语句,应表达如下:
select team, position, count(*) as pos_count from player group by team, position;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
TermsBuilder posAgg= AggregationBuilders.terms("pos_count").field("position");
sbuilder.addAggregation(teamAgg.subAggregation(posAgg));
SearchResponse response = sbuilder.execute().actionGet();
- max/min/sum/avg
例如要计算每个球队年龄最大/最小/总/平均的球员年龄,如果使用SQL语句,应表达如下:
select team, max(age) as max_age from player group by team;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
MaxBuilder ageAgg= AggregationBuilders.max("max_age").field("age");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg));
SearchResponse response = sbuilder.execute().actionGet();
- 对多个field求max/min/sum/avg
例如要计算每个球队球员的平均年龄,同时又要计算总年薪,如果使用SQL语句,应表达如下:
select team, avg(age)as avg_age, sum(salary) as total_salary from player group by team;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("team");
AvgBuilder ageAgg= AggregationBuilders.avg("avg_age").field("age");
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg).subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
- 聚合后对Aggregation结果排序
例如要计算每个球队总年薪,并按照总年薪倒序排列,如果使用SQL语句,应表达如下:
select team, sum(salary) as total_salary from player group by team order by total_salary desc;ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("team").order(Order.aggregation("total_salary ", false);
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();需要特别注意的是,排序是在TermAggregation处执行的,Order.aggregation函数的第一个参数是aggregation的名字,第二个参数是boolean型,true表示正序,false表示倒序。
- Aggregation结果条数的问题
默认情况下,search执行后,仅返回10条聚合结果,如果想反悔更多的结果,需要在构建TermsBuilder 时指定size:
TermsBuilder teamAgg= AggregationBuilders.terms("team").size(15);
- Aggregation结果的解析/输出
得到response后:
Map<String, Aggregation> aggMap = response.getAggregations().asMap();
StringTerms teamAgg= (StringTerms) aggMap.get("keywordAgg");
Iterator<Bucket> teamBucketIt = teamAgg.getBuckets().iterator();
while (teamBucketIt .hasNext()) {
Bucket buck = teamBucketIt .next();
//球队名
String team = buck.getKey();
//记录数
long count = buck.getDocCount();
//得到所有子聚合
Map subaggmap = buck.getAggregations().asMap();
//avg值获取方法
double avg_age= ((InternalAvg) subaggmap.get("avg_age")).getValue();
//sum值获取方法
double total_salary = ((InternalSum) subaggmap.get("total_salary")).getValue();
//...
//max/min以此类推
}
- 总结
综上,聚合操作主要是调用了SearchRequestBuilder的addAggregation方法,通常是传入一个TermsBuilder,子聚合调用TermsBuilder的subAggregation方法,可以添加的子聚合有TermsBuilder、SumBuilder、AvgBuilder、MaxBuilder、MinBuilder等常见的聚合操作。
从实现上来讲,SearchRequestBuilder在内部保持了一个私有的 SearchSourceBuilder实例, SearchSourceBuilder内部包含一个List<AbstractAggregationBuilder>,每次调用addAggregation时会调用 SearchSourceBuilder实例,添加一个AggregationBuilder。
同样的,TermsBuilder也在内部保持了一个List<AbstractAggregationBuilder>,调用addAggregation方法(来自父类addAggregation)时会添加一个AggregationBuilder。有兴趣的读者也可以阅读源码的实现。
如果有什么问题,欢迎一起讨论,如果文中有什么错误,欢迎批评指正。
注:文中使用的Elastic Search API版本为2.3.2
public List<Map<String, Object>> queryAggregationsByAttr(BoolQueryBuilder boolQueryBld){
List<Map<String, Object>> result = new ArrayList<>();
NestedBuilder nestedBuilder= AggregationBuilders.nested("negstedAttr").path("spuAttrList");
//属性名称分组
TermsBuilder tbName= AggregationBuilders.terms("attrNameAgg").field("spuAttrList.name");
//嵌套查询的子查询中分组count
TermsBuilder tb= AggregationBuilders.terms("attrvIdAgg").field("spuAttrList.attrvId");
//属性值字段
TermsBuilder tbVal= AggregationBuilders.terms("attrValAgg").field("spuAttrList.value");
NestedBuilder all = nestedBuilder.subAggregation(tbName.subAggregation(tb.subAggregation(tbVal)));
NativeSearchQueryBuilder nativeQueryBuilderAgg = new NativeSearchQueryBuilder()
.withQuery(boolQueryBld)
.withIndices("skus").withTypes("skus")
.addAggregation(all);
SearchQuery searchQueryAgg = nativeQueryBuilderAgg.build();
Aggregations aggregations = elasticsearchTemplate.query(searchQueryAgg, new ResultsExtractor<Aggregations>() {
@Override
public Aggregations extract(SearchResponse response) {
return response.getAggregations();
}
});
Map<String, Aggregation> map=aggregations.asMap();
for(String s:map.keySet()){
if("negstedAttr".equals(s)) {
InternalNested internalNested = (InternalNested)map.get(s);
//属性名称
StringTerms nameTerms=(StringTerms) internalNested.getAggregations().get("attrNameAgg");
//属性子表id
for(org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket tbket:nameTerms.getBuckets()){
//对应一组属性值
Map<String, Object> categoryIdsMapTerms = new HashMap<String, Object>();
categoryIdsMapTerms.put("typeId", "attrValueIds");
categoryIdsMapTerms.put("typeName", tbket.getKeyAsString());
LongTerms attrvIdTerms=(LongTerms)tbket.getAggregations().asMap().get("attrvIdAgg");
if(attrvIdTerms == null || CollectionUtils.isEmpty(attrvIdTerms.getBuckets())) {
continue;
}
List<Map<String, Object>> dataList = new ArrayList<>();
//属性子表val
for(org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket attrIdB : attrvIdTerms.getBuckets()) {
//dataListMap
Map<String, Object> dataListMap = new HashMap<String, Object>();
Long attrvId = (Long) attrIdB.getKeyAsNumber();
StringTerms valTerms=(StringTerms) attrIdB.getAggregations().asMap().get("attrValAgg");
if(valTerms == null || CollectionUtils.isEmpty(valTerms.getBuckets())) {
continue;
}
String attrValStr = valTerms.getBuckets().get(0).getKeyAsString();
dataListMap.put("id", attrvId);
dataListMap.put("name", attrValStr);
dataList.add(dataListMap);
}
if(!CollectionUtils.isEmpty(dataList)) {
categoryIdsMapTerms.put("dataList", dataList);
}
result.add(categoryIdsMapTerms);
}
}
}
return result;
}
我们今天的关于向ElasticSearch术语聚合添加其他字段和elasticsearch嵌套聚合的分享已经告一段落,感谢您的关注,如果您想了解更多关于Elastic Search中嵌套字段的术语聚合、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?、Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、ElasticSearch java API - 聚合查询-聚合多字段聚合demo的相关信息,请在本站查询。
本文标签:




