对于想了解elasticsearch拼音检索能力研究的读者,本文将提供新的信息,我们将详细介绍elasticsearch拼音搜索,并且为您提供关于docker部署elasticsearch+elast
对于想了解elasticsearch 拼音检索能力研究的读者,本文将提供新的信息,我们将详细介绍elasticsearch 拼音搜索,并且为您提供关于docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器、Docker部署ElasticSearch和ElasticSearch-Head、Docker部署ElasticSearch和ElasticSearch-Head的实现、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?的有价值信息。
本文目录一览:- elasticsearch 拼音检索能力研究(elasticsearch 拼音搜索)
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
- Docker部署ElasticSearch和ElasticSearch-Head
- Docker部署ElasticSearch和ElasticSearch-Head的实现
- ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
")
elasticsearch 拼音检索能力研究(elasticsearch 拼音搜索)
gitchennan/elasticsearch-analysis-lc-pinyin
配置参数少,功能满足需求。
对应版本
elasticsearch2.3.2 对应 elasticsearch-analysis-lc-pinyin 分支 2.4.2.1 或者 tag 2.2.2.1
创建一个类型
elasticsearch-analysis-lc-pinyin 的 README 是根据 elasticsearch5.0 编写的,给出的创建一个类型的语法如下
curl -XPOST http://localhost:9200/index/_mapping/brand -d'
{
"brand": {
"properties": {
"name": {
"type": "text","analyzer": "lc_index","search_analyzer": "lc_search","term_vector": "with_positions_offsets"
}
}
}
}'
type=text 是 elasticsearch5.0 之后的类型,所以无法创建成功,稍作修改 type=text,使用如下语法创建一个类型
curl -XPOST http://localhost:9200/index/_mapping/brand -d'
{
"brand": {
"properties": {
"name": {
"type": "string","term_vector": "with_positions_offsets"
}
}
}
}'
index 索引结构如下
{
"index": {
"aliases": {},"mappings": {
"brand": {
"properties": {
"name": {
"type": "string","term_vector": "with_positions_offsets","search_analyzer": "lc_search"
}
}
}
},"settings": {
"index": {
"creation_date": "1490152096129","number_of_shards": "5","number_of_replicas": "1","uuid": "Lp1sSHGhQZyZ57LKO5KwRQ","version": {
"created": "2030299"
}
}
},"warmers": {}
}
}
存入几条数据
curl -XPOST http://localhost:9200/index/brand/1 -d'{"name":"百度"}'
curl -XPOST http://localhost:9200/index/brand/8 -d'{"name":"百度糯米"}'
curl -XPOST http://localhost:9200/index/brand/2 -d'{"name":"阿里巴巴"}'
curl -XPOST http://localhost:9200/index/brand/3 -d'{"name":"腾讯科技"}'
curl -XPOST http://localhost:9200/index/brand/4 -d'{"name":"网易游戏"}'
curl -XPOST http://localhost:9200/index/brand/9 -d'{"name":"大众点评"}'
curl -XPOST http://localhost:9200/index/brand/10 -d'{"name":"携程旅行网"}'
查出目前的所有数据
http://localhost:9200/index/_search
{
"took": 70,"timed_out": false,"_shards": {
"total": 5,"successful": 5,"Failed": 0
},"hits": {
"total": 7,"max_score": 1,"hits": [
{
"_index": "index","_type": "brand","_id": "8","_score": 1,"_source": {
"name": "百度糯米"
}
},{
"_index": "index","_id": "9","_source": {
"name": "大众点评"
}
},"_id": "10","_source": {
"name": "携程旅行网"
}
},"_id": "2","_source": {
"name": "阿里巴巴"
}
},"_id": "4","_source": {
"name": "网易游戏"
}
},"_id": "1","_source": {
"name": "百度"
}
},"_id": "3","_source": {
"name": "腾讯科技"
}
}
]
}
}
插件自带分词器 lc_index
原文:lc_index : 该分词器用于索引数据时指定,将中文转换为全拼和首字,同时保留中文
分词器分词效果
curl -X POST -d '{
"analyzer" : "lc_index","text" : ["刘德华"]
}' "http://localhost:9200/lc/_analyze"
{
"tokens": [
{
"token": "刘","start_offset": 0,"end_offset": 1,"type": "word","position": 0
},{
"token": "liu",{
"token": "l",{
"token": "德","start_offset": 1,"end_offset": 2,"position": 1
},{
"token": "de",{
"token": "d",{
"token": "华","start_offset": 2,"end_offset": 3,"position": 2
},{
"token": "hua",{
"token": "h","position": 2
}
]
}
插件自带分词器 lc_search
原文:lc_search: 该分词器用于拼音搜索时指定,按最小拼音分词个数拆分拼音,优先拆分全拼
curl -X POST -d '{
"analyzer" : "lc_search","text" : ["刘德华"]
}' "http://localhost:9200/index/_analyze"
{
"tokens": [
{
"token": "刘","position": 2
}
]
}
拼音全拼
搜索 baidu,结果正确
curl -X POST -d '{
"query": {
"match": {
"name": {
"query": "baidu","analyzer": "lc_search","type": "phrase"
}
}
},"highlight" : {
"pre_tags" : ["<tag1>"],"post_tags" : ["</tag1>"],"fields" : {
"name" : {}
}
}
}' "http://localhost:9200/index/brand/_search"
{
"took": 4,"hits": {
"total": 2,"max_score": 1.4054651,"_score": 1.4054651,"_source": {
"name": "百度糯米"
},"highlight": {
"name": [
"<tag1>百度</tag1>糯米"
]
}
},"_score": 0.38356602,"_source": {
"name": "百度"
},"highlight": {
"name": [
"<tag1>百度</tag1>"
]
}
}
]
}
}
单字拼音全拼与中文混合
搜索 xie程lu行,结果正确
{
"took": 11,"hits": {
"total": 1,"max_score": 2.459564,"_score": 2.459564,"_source": {
"name": "携程旅行网"
},"highlight": {
"name": [
"<tag1>携程旅行</tag1>网"
]
}
}
]
}
}
单字拼音首字母与中文混合
搜索 携cl行,结果正确
curl -X POST -d '{
"query": {
"match": {
"name": {
"query": "携cl行","fields" : {
"name" : {}
}
}
}' "http://localhost:9200/index/brand/_search"
{
"took": 6,"highlight": {
"name": [
"<tag1>携程旅行</tag1>网"
]
}
}
]
}
}
拼音首字母
搜索 albb,结果正确
curl -X POST -d '{
"query": {
"match": {
"name": {
"query": "albb","max_score": 2.828427,"_score": 2.828427,"_source": {
"name": "阿里巴巴"
},"highlight": {
"name": [
"<tag1>阿里巴巴</tag1>"
]
}
}
]
}
}
结论
elasticsearch-analysis-lc-pinyin 按照全拼、首字母,拼音中文混合搜索
elasticsearch-analysis-pinyin v1.7.2
github 项目 elasticsearch-analysis-pinyin v1.7.2 完全是为 elasticsearch 2.3.2 服务
first_letter 改变
first_letter=prefix padding_char=" "
curl -X POST -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","analyzer": "pinyin_analyzer"
}
}
}
},"settings": {
"index" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin","filter" : ["word_delimiter"]
}
},"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin","first_letter" : "prefix","padding_char" : " "
}
}
}
}
}
}' "http://localhost:9200/medcl"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl/_analyze"
{
"tokens": [
{
"token": "ldh","position": 3
}
]
}
first_letter=append padding_char=" "
curl -X POST -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","first_letter" : "append","padding_char" : " "
}
}
}
}
}
}' "http://localhost:9200/medcl2"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl2/_analyze"
{
"tokens": [
{
"token": "liu",{
"token": "ldh","position": 3
}
]
}
first_letter=only padding_char=" "
curl -X POST -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","first_letter" : "only","padding_char" : " "
}
}
}
}
}
}' "http://localhost:9200/medcl3"
拼音效果如下
curl -X POST -H "Cache-Control: no-cache" -H "Postman-Token: 67015c0d-cd07-961b-4c46-da90f7d558d8" -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl3/_analyze"
{
"tokens": [
{
"token": "ldh","position": 0
}
]
}
first_letter=none padding_char=" "
curl -X POST -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","first_letter" : "none","padding_char" : " "
}
}
}
}
}
}' "http://localhost:9200/medcl4"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl4/_analyze"
{
"tokens": [
{
"token": "liu","position": 2
}
]
}
padding_char 改变
first_letter=prefix padding_char=""
curl -X POST -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","padding_char" : ""
}
}
}
}
}
}' "http://localhost:9200/medcl5"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl5/_analyze"
{
"tokens": [
{
"token": "ldhliudehua","position": 0
}
]
}
first_letter=append padding_char=""
curl -X PUT -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","padding_char" : ""
}
}
}
}
}
}' "http://localhost:9200/medcl7"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl7/_analyze"
{
"tokens": [
{
"token": "liudehualdh","position": 0
}
]
}
first_letter=only padding_char=""
curl -X PUT -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","padding_char" : ""
}
}
}
}
}
}' "http://localhost:9200/medcl8"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl8/_analyze"
{
"tokens": [
{
"token": "ldh","position": 0
}
]
}
first_letter=none padding_char=""
curl -X PUT -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","padding_char" : ""
}
}
}
}
}
}' "http://localhost:9200/medcl9"
拼音效果如下
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl9/_analyze"
{
"tokens": [
{
"token": "liudehua","position": 0
}
]
}
结论
-
elasticsearch 2.3.2对应elasticsearch-analysis-pinyin 1.7.2,pinyin 1.7.2可配置参数有:first_letter和padding_char。 -
padding_char的作用是将字符串按照什么字符分隔,比如padding_char = " ",那么刘德华将先被分隔为刘,德,华;如果padding_char = "",那么刘德华将不会被分隔 -
first_letter取值:prefix,append,only,none。 -
padding_char与first_letter的组合会影响拼音输出的结果
elasticsearch-analysis-pinyin 2.x 分支
github 项目 elasticsearch-analysis-pinyin 2.x 分支 是为 elasticsearch 2.x 服务,经过测试 elasticsearch 2.3.2 也可以使用该插件。
官方文档中的说明
- remove_duplicated_term when this option enabled,duplicated term will be removed to save index,eg: de的>de,default: false,NOTE: position related query maybe influenced
- keep_first_letter when this option enabled,eg: 刘德华>ldh,default: true
- keep_separate_first_letter when this option enabled,will keep first letters separately,eg: 刘德华>l,d,h,NOTE: query result maybe too fuzziness due to term too frequency
- limit_first_letter_length set max length of the first_letter result,default: 16
- keep_full_pinyin when this option enabled,eg: 刘德华> [liu,de,hua],default: true
- keep_joined_full_pinyin when this option enabled,eg: 刘德华> [liudehua],default: false
- keep_none_chinese keep non chinese letter or number in result,default: true
- keep_none_chinese_together keep non chinese letter together,default: true,eg: DJ音乐家 -> DJ,yin,yue,jia,when set to false,eg: DJ音乐家 -> D,J,NOTE: keep_none_chinese should be enabled first
- keep_none_chinese_in_first_letter keep non Chinese letters in first letter,eg: 刘德华AT2016->ldhat2016,default: true
- none_chinese_pinyin_tokenize break non chinese letters into separate pinyin term if they are pinyin,eg: liudehuaalibaba13zhuanghan -> liu,hua,a,li,ba,13,zhuang,han,NOTE: keep_none_chinese and keep_none_chinese_together should be enabled first
- keep_original when this option enabled,will keep original input as well,default: false
- lowercase lowercase non Chinese letters,default: true
- trim_whitespace default: true
基准配置
基准配置参数
"keep_joined_full_pinyin": "false","lowercase": "true","keep_original": "false","keep_none_chinese_together": "true","remove_duplicated_term": "false","keep_first_letter": "true","keep_separate_first_letter": "false","trim_whitespace": "true","keep_none_chinese": "true","limit_first_letter_length": "16","keep_full_pinyin": "true"
创建索引与分词器
curl -X POST -d '{
"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","analyzer": "pinyin_analyzer"
}
}
}
},"settings": {
"index" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin","remove_duplicated_term" : false,"keep_joined_full_pinyin" : false,"keep_separate_first_letter" : false,"keep_first_letter" : true,"limit_first_letter_length" : 16,"keep_full_pinyin" : true,"keep_original" : true,"keep_none_chinese" : true,"keep_none_chinese_together" : true,"lowercase" : true,"trim_whitespace" : true
}
}
}
}
}
}' "http://localhost:9200/medcl20"
生成索引结构
curl -X GET "http://localhost:9200/medcl20"
{
"medcl20": {
"aliases": {},"mappings": {
"folk": {
"properties": {
"text": {
"type": "string","analyzer": "pinyin_analyzer"
}
}
}
},"settings": {
"index": {
"creation_date": "1490170676090","analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "my_pinyin"
}
},"tokenizer": {
"my_pinyin": {
"keep_joined_full_pinyin": "false","keep_original": "true","type": "pinyin","keep_full_pinyin": "true"
}
}
},"uuid": "31Y9PizQQ2KQn_Fl6bpPNw","warmers": {}
}
}
分词器分词效果
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl20/_analyze"
{
"tokens": [
{
"token": "liu",{
"token": "刘德华","position": 3
},"position": 4
}
]
}
keep_original
keep_original = true
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","position": 4
}
]
}
keep_original = false
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","position": 3
}
]
}
keep_original 功能
keep_original=true 将保留原字符串,比如存入索引的数据为 刘德华 那么 刘德华 将也会被保存到索引中。keep_original=false 则不保存原字符串到索引
trim_whitespace
trim_whitespace=true
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : [" 最爱 刘德华 的帅气帅气的 "]
}' "http://localhost:9200/medcl20/_analyze"
{
"tokens": [
{
"token": "zui","start_offset": 3,"end_offset": 4,{
"token": "ai","start_offset": 4,"end_offset": 5,"start_offset": 8,"end_offset": 9,"start_offset": 9,"end_offset": 10,"start_offset": 10,"end_offset": 11,"position": 4
},"start_offset": 14,"end_offset": 15,"position": 5
},{
"token": "shuai","start_offset": 15,"end_offset": 16,"position": 6
},{
"token": "qi","start_offset": 16,"end_offset": 17,"position": 7
},"start_offset": 17,"end_offset": 18,"position": 8
},"start_offset": 18,"end_offset": 19,"position": 9
},"start_offset": 19,"end_offset": 20,"position": 10
},{
"token": "最爱 刘德华 的帅气帅气的","end_offset": 23,"position": 11
},{
"token": "zaldhdsqsqd","position": 12
}
]
}
trim_whitespace=false
curl -X POST -d '{
"analyzer" : "pinyin_analyzer",{
"token": " 最爱 刘德华 的帅气帅气的 ","position": 12
}
]
}
trim_whitespace 功能
去除字符串首尾空格字符,不去除字符串中间的空格。这个参数只有当 keep_original=true 时才能够看到效果。 例如当字符串为: 最爱 刘德华 的帅气帅气的 ,trim_whitespace=true 则原字符串将被保存为 最爱 刘德华 的帅气帅气的,如果 trim_whitespace=false 则原字符串将被保存为 最爱 刘德华 的帅气帅气的 。如果 keep_original=false,那么原字符串没有被保存,也将看不到效果。
keep_joined_full_pinyin
keep_joined_full_pinyin = false
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl21/_analyze"
{
"tokens": [
{
"token": "liu","position": 4
}
]
}
keep_joined_full_pinyin = true
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华"]
}' "http://localhost:9200/medcl22/_analyze"
{
"tokens": [
{
"token": "liu",{
"token": "liudehua","end_offset": 8,"position": 5
}
]
}
keep_joined_full_pinyin 功能
keep_joined_full_pinyin=true 将保存字符串拼音全拼,false 则不保存。例如,当 kepp_joined_full_pinyin=true 时,文本 刘德华 的拼音全拼 liudehua 将会被保留;当 keep_joined_full_pinyin=false 则 全拼liudehua
remove_duplicated_term
remove_duplicated_term = false
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华刘德华帅帅帅,帅帅帅"]
}' "http://localhost:9200/medcl20/_analyze"
{
"tokens": [
{
"token": "liu","start_offset": 5,"end_offset": 6,"start_offset": 6,"end_offset": 7,"start_offset": 7,"start_offset": 11,"end_offset": 12,"start_offset": 12,"end_offset": 13,{
"token": "刘德华刘德华帅帅帅,帅帅帅","position": 12
},{
"token": "ldhldhssssss","position": 13
}
]
}
remove_duplicated_term = true
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华刘德华帅帅帅,帅帅帅"]
}' "http://localhost:9200/medcl26/_analyze"
{
"tokens": [
{
"token": "liu","position": 5
}
]
}
remove_duplicated_term 功能
remove_duplicated_term=true 则会将文本中相同的拼音只保存一份,比如 刘德华刘德华 只会保留一份拼音 liu,de,hua;相对的 remove_duplicated_term=false 则会保留两份 liu,de,hua。注意:remove_duplicated_term 并不会影响文本首字母的文本,刘德华刘德华 生成的首字母拼音始终都为 ldhldh
remove_duplicated_term = true 并且 keep_joined_full_pinyin = true
curl -X POST -d '{
"analyzer" : "pinyin_analyzer","text" : ["刘德华刘德华帅帅帅,帅帅帅"]
}' "http://localhost:9200/medcl27/_analyze"
{
"tokens": [
{
"token": "liu",{
"token": "liudehualiudehuashuaishuaishuaishuaishuaishuai","end_offset": 46,"position": 6
}
]
}
remove_duplicated_term 功能
remove_duplicated_term = true 会过滤相同的拼音,但是不影响全拼,刘德华刘德华 生成的字符串全拼为 liudehualiudehua
keep_none_chinese
keep_none_chinese = true
POST /medcl20/_analyze HTTP/1.1
Host: localhost:9200
{
"analyzer" : "pinyin_analyzer","text" : ["刘*20*德b华DJ"]
}
{
"tokens": [
{
"token": "liu",{
"token": "20",{
"token": "b",{
"token": "j",{
"token": "刘*20*德b华dj",{
"token": "l20dbhdj","position": 8
}
]
}
keep_none_chinese = false
POST /medcl28/_analyze HTTP/1.1
Host: localhost:9200
{
"analyzer" : "pinyin_analyzer","position": 4
}
]
}
keep_none_chinese 功能
keep_none_chinese = true 则非中文字母以及数字将会被保留,但是要确定所有的特别字符都是无法被保留下来的。例如,文本 刘*20*德b华dj 中的数字 20,字母 b 与 dj 将会被保留,而特殊字符 * 是不会保留的;当 keep_none_chinese=false 则非中文字母以及数字将不会被保留,上述文本中的数字 20,字母 b 与 dj 将不会被保留。注意:参数 keep_none_chinese 是不会影响首字母以及所有字符组成全拼的拼音,上述文本生成的首字母拼音为 l20dbhdj,所有字符组成的全拼为:liu20debhuadj,特别字符始终是被过滤去除的。
欢迎转载,请注明本文链接,谢谢你。
2017.4.12 20:44

docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
0. docker pull 拉取 elasticsearch + elasticsearch-head 镜像
1. 启动 elasticsearch Docker 镜像
docker run -di --name tensquare_elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch![]()
对应 IP:9200 ---- 反馈下边 json 数据,表示启动成功

2. 启动 elasticsearch-head 镜像
docker run -d -p 9100:9100 elasticsearch-head![]()
对应 IP:9100 ---- 得到下边页面,即启动成功
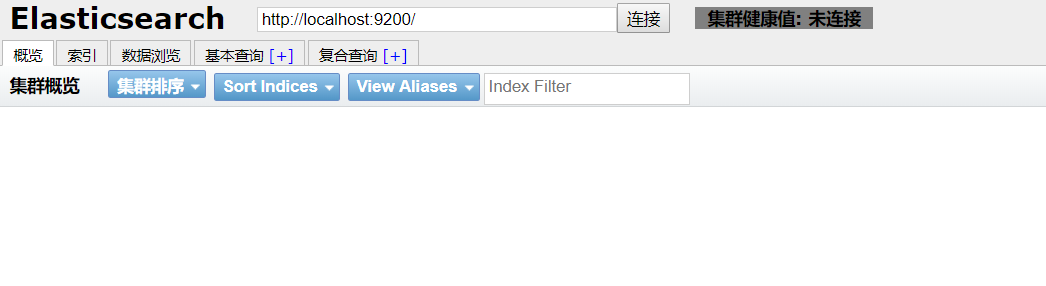
3. 解决跨域问题
进入 elasticsearch-head 页面,出现灰色未连接状态 , 即出现跨域问题

1. 根据 docker ps 得到 elasticsearch 的 CONTAINER ID
2. docker exec -it elasticsearch 的 CONTAINER ID /bin/bash 进入容器内
3. cd ./config
4. 修改 elasticsearch.yml 文件
echo "
http.cors.enabled: true
http.cors.allow-origin: ''*''" >> elasticsearch.yml
4. 重启 elasticsearch
docker restart elasticsearch的CONTAINER ID重新进入 IP:9100 进入 elasticsearch-head, 出现绿色标注,配置成功 !

5. ik 分词器的安装
将在 ik 所在的文件夹下,拷贝到 /usr/share/elasticsearch/plugins --- 注意: elasticsearch 的版本号必须与 ik 分词器的版本号一致
docker cp ik elasticsearch的CONTAINER ID:/usr/share/elasticsearch/plugins
重启elasticsearch
docker restart elasticsearch
未添加ik分词器:http://IP:9200/_analyze?analyzer=chinese&pretty=true&text=我爱中国
添加ik分词器后:http://IP:9200/_analyze?analyzer=ik_smart&pretty=true&text=我爱中国
Docker部署ElasticSearch和ElasticSearch-Head
Docker部署ElasticSearch和ElasticSearch-Head
本篇主要讲解使用Docker如何部署ElasticSearch:6.8.4 版本,讲解了从Docker拉取到最终运行ElasticSearch 以及 安装 ElasticSearch-Head 用来管理ElasticSearch相关信息的一个小工具,本博客系统首页的搜索正是使用了ElasticSearch来实现的,由于ElasticSearch 更新太快 以至于SpringData-ElasticSearch都跟不上 Es的更新 我也是一开始下载8.x的版本 导致SpringData-ElasticSearch 报错 最终我选择了6.8.4 在此记录一下
1.Docker部署ElasticSearch:6.8.4版本
1.1 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.4
1.2 运行容器
ElasticSearch的默认端口是9200,我们把宿主环境9200端口映射到Docker容器中的9200端口,就可以访问到Docker容器中的ElasticSearch服务了,同时我们把这个容器命名为es。
docker run -d --name es -p 9200:9200 -p 9300:9300
-e "discovery.type=single-node"
-e ES_JAVA_OPTS="-Xms=256m -Xms=256m"
docker.elastic.co/elasticsearch/elasticsearch:6.8.4
说明:
-e discovery.type=single-node :表示单节点启动
-e ES_JAVA_OPTS="-Xms=256m -Xms=256m" :表示设置es启动的内存大小,这个真的要设置,不然后时候会内存不够,比如我自己的辣鸡服务器!
1.3 内存不足问题
centos下载完elasticsearch并修改完配置后运行docker命令:
发现没有启动成功,去除命令的-d后打印错误如下
Java HotSpot(TM) 64-Bit Server VM warning: INFO:
os::commit_memory(0x0000000085330000, 2060255232, 0) failed;
error=’Cannot allocate memory’ (errno=12)
经过一番查找发现这是由于elasticsearch6.0默认分配jvm空间大小为2g,内存不足以分配导致。
解决方法就是修改jvm空间分配
运行命令:
find /var/lib/docker/overlay/ -name jvm.options
查找jvm.options文件,找到后进入使用vi命令打开jvm.options如下:
将
-Xms2g
-Xmx2g
修改为
-Xms512m
-Xmx512m
保存退出即可。再次运行创建运行elasticsearch命令,成功启动。
2.Docker部署ElasticSearch-Heard
2.1 拉取镜像
docker pull mobz/elasticsearch-head:52.2 运行容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
2.3 启动容器
docker start elasticsearch-head
2.4 打开浏览器: http://IP:9100
发现连接不上,是因为有跨域问题,因为前后端分离开发的所以需要设置一下es
2.5 进入刚刚启动的 es 容器,容器name = es
docker exec -it es /bin/bash
2.6 修改elasticsearch.yml文件
vi config/elasticsearch.yml
添加
http.cors.enabled: true
http.cors.allow-origin: "*"
其实就是SpringBoot的yml文件 添加跨域支持
2.7 退出容器 并重启
exit
docker restart es
2.8 访问http://localhost:9100

总结:
本篇只是简单的讲解了如何用Docker安装ElasticSearch 并且会遇到的坑,包括内存不足,或者版本太高等问题,以及ElasticSearch-Heard的安装和跨域的配置 ,下一篇将讲解ElasticSearch如何安装中文分词器
个人博客网站 https://www.askajohnny.com 欢迎来访问!
本文由博客一文多发平台 OpenWrite 发布!

Docker部署ElasticSearch和ElasticSearch-Head的实现
本篇主要讲解使用Docker如何部署ElasticSearch:6.8.4 版本,讲解了从Docker拉取到最终运行ElasticSearch 以及 安装 ElasticSearch-Head 用来管理ElasticSearch相关信息的一个小工具,本博客系统首页的搜索正是使用了ElasticSearch来实现的,由于ElasticSearch 更新太快 以至于SpringData-ElasticSearch都跟不上 Es的更新 我也是一开始下载8.x的版本 导致SpringData-ElasticSearch 报错 最终我选择了6.8.4 在此记录一下
1.Docker部署ElasticSearch:6.8.4版本
1.1 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.4
1.2 运行容器
ElasticSearch的默认端口是9200,我们把宿主环境9200端口映射到Docker容器中的9200端口,就可以访问到Docker容器中的ElasticSearch服务了,同时我们把这个容器命名为es。
docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms=256m -Xms=256m" docker.elastic.co/elasticsearch/elasticsearch:6.8.4
说明:
-e discovery.type=single-node :表示单节点启动
-e ES_JAVA_OPTS="-Xms=256m -Xms=256m" :表示设置es启动的内存大小,这个真的要设置,不然后时候会内存不够,比如我自己的辣鸡服务器!
1.3 内存不足问题
centos下载完elasticsearch并修改完配置后运行docker命令:
发现没有启动成功,去除命令的-d后打印错误如下
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error=''Cannot allocate memory'' (errno=12)
经过一番查找发现这是由于elasticsearch6.0默认分配jvm空间大小为2g,内存不足以分配导致。
解决方法就是修改jvm空间分配
运行命令:
find /var/lib/docker/overlay/ -name jvm.options 查找jvm.options文件,找到后进入使用vi命令打开jvm.options如下: 将 -Xms2g -Xmx2g 修改为 -Xms512m -Xmx512m
保存退出即可。再次运行创建运行elasticsearch命令,成功启动。
2.Docker部署ElasticSearch-Heard
2.1 拉取镜像
docker pull mobz/elasticsearch-head:5
2.2 运行容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
2.3 启动容器
docker start elasticsearch-head
2.4 打开浏览器: http://IP:9100
发现连接不上,是因为有跨域问题,因为前后端分离开发的所以需要设置一下es
2.5 进入刚刚启动的 es 容器,容器name = es
docker exec -it es /bin/bash
2.6 修改elasticsearch.yml文件
vi config/elasticsearch.yml
添加
http.cors.enabled: true http.cors.allow-origin: "*"
其实就是SpringBoot的yml文件 添加跨域支持
2.7 退出容器 并重启
exit docker restart es
2.8 访问http://localhost:9100

总结:
本篇只是简单的讲解了如何用Docker安装ElasticSearch 并且会遇到的坑,包括内存不足,或者版本太高等问题,以及ElasticSearch-Heard的安装和跨域的配置 ,下一篇将讲解ElasticSearch如何安装中文分词器
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
- Docker安装ElasticSearch和Kibana的问题及处理方法
- docker安装Elasticsearch7.6集群并设置密码的方法步骤
- 一文搞定Docker安装ElasticSearch的过程
- 在Docker中安装Elasticsearch7.6.2的教程
- 教你使用docker安装elasticsearch和head插件的方法
 ElasticSearch 的应用场景及为什么要选择 ElasticSearch?")
ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
先了解一下数据的分类
结构化数据
又可以称之为行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。其实就是可以能够用数据或者统一的结构加以表示的数据。比如在数据表存储商品的库存,可以用整型表示,存储价格可以用浮点型表示,再比如给用户存储性别,可以用枚举表示,这都是结构化数据。
非结构化数据
无法用数字或者统一的结构表示的数据,称之为飞结构化数据。如:文本、图像、声音、网页。
其实结构化数据又数据非结构化数据。商品标题、描述、文章描述都是文本,其实文本就是非结构化数据。那么就可以说非结构化数据即为全文数据。
什么是全文检索?
一种将文件或者数据库中所有文本与检索项相匹配的文字资料检索方法,称之为全文检索。
全文检索的两种方法
顺序扫描法:将数据表的所有数据逐个扫描,再对文字描述扫描,符合条件的筛选出来,非常慢!
索引扫描法:全文检索的基本思路,也就是将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对快的目的。
全文检索的过程:
先索引的创建,然后索引搜索
为什么要选择用 ElasticSearch?
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
分布式的实时文件存储,每个字段都被索引可被搜索。
分布式的实时分析搜索引擎。
可以扩展到上百台服务器,处理 PB 级别结构化或者非结构化数据。
所有功能集成在一个服务器里,可以通过 RESTful API、各种语言的客户端甚至命令与之交互。
上手容易,提供了很多合理的缺省值,开箱即用,学习成本低。
可以免费下载、使用和修改。
配置灵活,比 Sphinx 灵活的多。
关于elasticsearch 拼音检索能力研究和elasticsearch 拼音搜索的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器、Docker部署ElasticSearch和ElasticSearch-Head、Docker部署ElasticSearch和ElasticSearch-Head的实现、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

