在这篇文章中,我们将为您详细介绍【Elasticsearch】-elasticsearch文档数据的增删改查的内容,并且讨论关于elasticsearch修改数据的相关问题。此外,我们还会涉及一些关于
在这篇文章中,我们将为您详细介绍【Elasticsearch】- elasticsearch文档数据的增删改查的内容,并且讨论关于elasticsearch修改数据的相关问题。此外,我们还会涉及一些关于Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、Elasticsearch Java API 索引的增删改查(二)、ELASTICSEARCH JAVA 的增删改查、elasticsearch java索引的增删改查的知识,以帮助您更全面地了解这个主题。
本文目录一览:- 【Elasticsearch】- elasticsearch文档数据的增删改查(elasticsearch修改数据)
- Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
- Elasticsearch Java API 索引的增删改查(二)
- ELASTICSEARCH JAVA 的增删改查
- elasticsearch java索引的增删改查
")
【Elasticsearch】- elasticsearch文档数据的增删改查(elasticsearch修改数据)
文章目录
- 创建文档并添加数据
- 修改文档数据
- 全量修改
- 局部数据修改
- 删除文档数据
- 查询文档数据
- 主键查询和全查询
- 条件查询
- 分页查询
- 查询部分属性
- 查询排序
- 多条件查询
- 范围查询
- 完全匹配查询
- 聚合查询
- 分组
- 求平均值
创建文档并添加数据
Elasticsearch中的文档就相当于MysqL数据库中的表,文档中的数据格式为JSON格式。
首先创建一个索引(数据库),然后在索引中创建文档(表),并添加数据。
创建一个名为user的索引:
PUT : localhost:9200/user

向user索引中创建文档并添加数据:
POST : localhost:9200/user/_doc
请求体:
{
"name":"张三","age":18,"sex":"男","email":"111222333@qq.com"
}

如果在添加数据的时候没有指定id,Elasticsearch会自动生成一个随机id。 但是使用随机生成的id进行查询的时候会比较复杂,因此,我们也可以手动给数据添加id,
手动给数据添加id只需要在请求路径后面加上指定id即可,如下:
POST : localhost:9200/user/_doc/10001
或
PUT:localhost:9200/user/_doc/10001 (在指定id的条件下,可以使用PUT请求方式)

修改文档数据
全量修改
PUT :localhost:9200/user/_doc/10001

局部数据修改
POST:localhost:9200/user/_update/10001

删除文档数据
DELETE : localhost:9200/user/_doc/10001

查询文档数据
在进行查询之前先向user索引中添加几条数据
{
"name":"李四","age":16,"email":"23434353@qq.com"
}
{
"name":"1+1=王","age":22,"email":"123123123@qq.com"
}
{
"name":"王五","age":25,"sex":"女","email":"wangwu@outlook.com"
}
{
"name":"curry","age":30,"email":"curry30@nba.com"
}
主键查询和全查询
根据id查询GET : localhost:9200/user/_doc/10001

查询所有数据
GET : localhost:9200/user/_search

条件查询
方式一:请求路径中添加查询
GET : localhost:9200/user/_search?q=name:王

方式二:请求中添加查询
GET : localhost:9200/user/_search
{
"query":{
"match":{
"name":"王"
}
}
}

分页查询
GET : localhost:9200/user/_search
{
"query":{
"match_all":{ //查询所有
}
},"from":0,//页码(从第0页开始)
"size":2 //每页显示条数
}

查询部分属性
GET : localhost:9200/user/_search
{
"query":{
"match_all":{ //查询所有
}
},//页码(从第0页开始)
"size":2,//每页显示条数
"_source":["name","age"] //需要查询的属性
}

查询排序
GET : localhost:9200/user/_search
{
"sort":{
"age":{
"order":"asc" //按年龄升序查询
}
}
}

多条件查询
1. 多个条件同时满足(and)
GET : localhost:9200/user/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"王"
}
},{
"match":{
"sex":"男"
}
}
]
}
}
}

2. 满足多个条件中的一个(or)
GET : localhost:9200/user/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"王"
}
},{
"match":{
"name":"张"
}
}
]
}
}
}

范围查询
GET : localhost:9200/user/_search
{
"query":{
"bool":{
"filter":{
"range":{
"age":{
"gt":22
// gt: > 大于(greater than)
// lt: < 小于(less than)
// gte: >= 大于或等于(greater than or equal to)
// lte: <= 小于或等于(less than or equal to)
}
}
}
}
}
}

完全匹配查询
GET : localhost:9200/user/_search
{
"query":{
"match_phrase":{
"name":"1+1=王"
}
}
}

聚合查询
分组
GET : localhost:9200/user/_search
{
"aggs":{ //聚合操作
"age_group":{ //名称,随意起名
"terms":{ //分组
"field":"age" //分组字段
}
}
}
}

求平均值
GET : localhost:9200/user/_search
{
"aggs":{ //聚合操作
"age_avg":{ //名称,随意起名
"avg":{ //求平均值
"field":"age" //求平均值的字段
}
}
}
}


Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
CentOS6.5下安装ElasticSearch6.2.4
(1)配置JDK环境
配置环境变量
export JAVA_HOME="/opt/jdk1.8.0_144"
export PATH="$JAVA_HOME/bin:$PATH"
export CLASSPATH=".:$JAVA_HOME/lib"
(2)安装ElasticSearch6.2.4
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-4
启动报错:
解决方式:
bin/elasticsearch -Des.insecure.allow.root=true
或者修改bin/elasticsearch,加上ES_JAVA_OPTS属性:
ES_JAVA_OPTS="-Des.insecure.allow.root=true"
再次启动: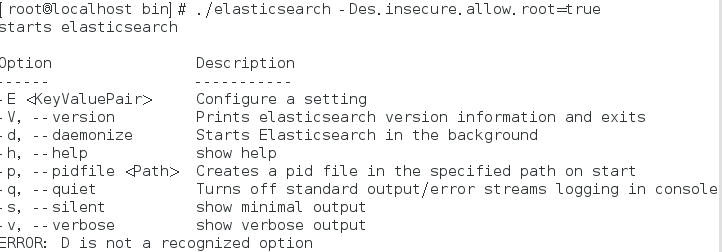
这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考 虑,建议创建一个单独的用户用来运行ElasticSearch。
如果没有普通用户就要创建一个普通用户组和普通用户,下面介绍一下怎么创建用户组和普通用户
创建用户组和用户:
groupadd esgroup
useradd esuser -g esgroup -p espassword
更改elasticsearch文件夹及内部文件的所属用户及组:
cd /opt
chown -R esuser:esgroup elasticsearch-6.2.4
切换用户并运行:
su esuser
./bin/elasticsearch
再次启动显示已杀死: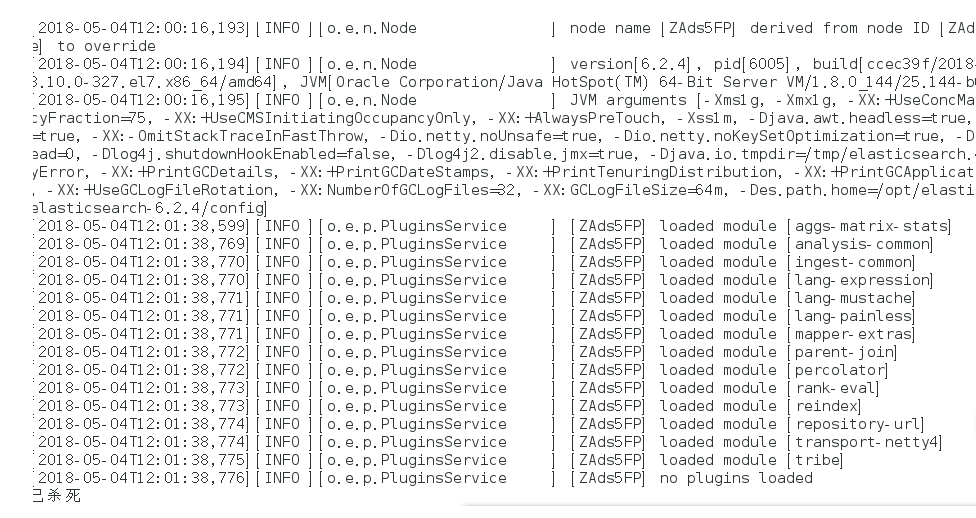
需要调整JVM的内存大小:
vi bin/elasticsearch
ES_JAVA_OPTS="-Xms512m -Xmx512m"
再次启动:启动成功
如果显示如下类似信息:
[INFO ][o.e.c.r.a.DiskThresholdMonitor] [ZAds5FP] low disk watermark [85%] exceeded on [ZAds5FPeTY-ZUKjXd7HJKA][ZAds5FP][/opt/elasticsearch-6.2.4/data/nodes/0] free: 1.2gb[14.2%], replicas will not be assigned to this node
需要清理磁盘空间。
后台运行:./bin/elasticsearch -d
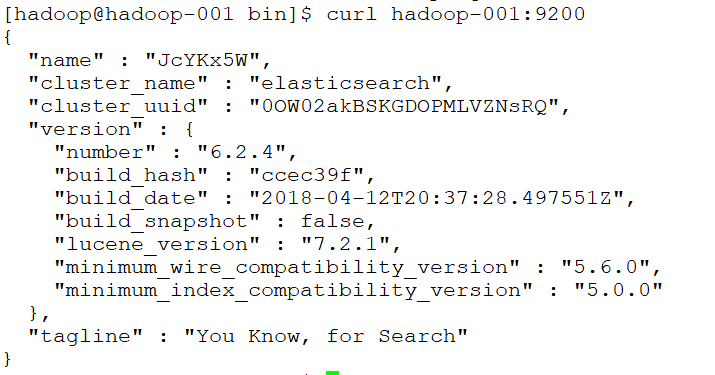
测试连接:curl 127.0.0.1:9200
会看到一下JSON数据:
[root@localhost ~]# curl 127.0.0.1:9200
{
"name" : "rBrMTNx",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "-noR5DxFRsyvAFvAzxl07g",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
实现远程访问:
需要对config/elasticsearch.yml进行 配置:
network.host: hadoop-001
再次启动报错:Failed to load settings from [elasticsearch.yml]
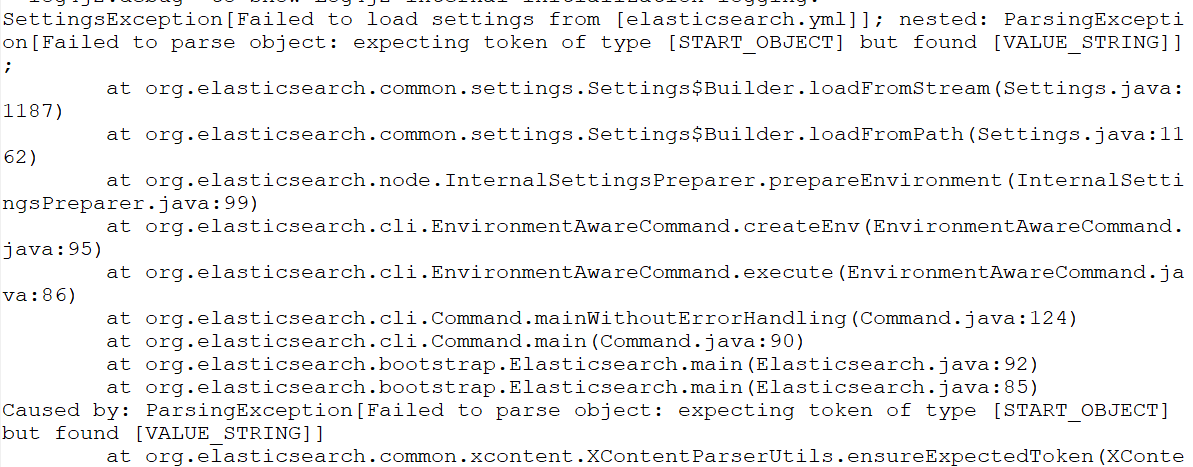
这个错就是参数的冒号前后没有加空格,加了之后就好,我找了好久这个问题;
后来在一个外国网站找到了这句话.
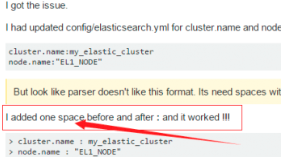
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ElasticsearchParseException[malformed, expected end of settings but encountered additional content starting at line number: [3], column number: [1]]; nested: ParserException[expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
^
];
Likely root cause: expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
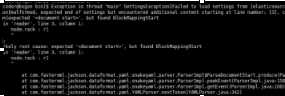
这个是行的开头没有加空格,fuck!
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ScannerException[while scanning a simple key
in ''reader'', line 11, column 2:
discovery.zen.ping.unicast.hosts ...
^

参数冒号后加空格,或者是数组中间加空格
例如:
# discovery.zen.minimum_master_nodes: 3
再次启动
还是报错
max file descriptors [4096] for elasticsearch process is too low
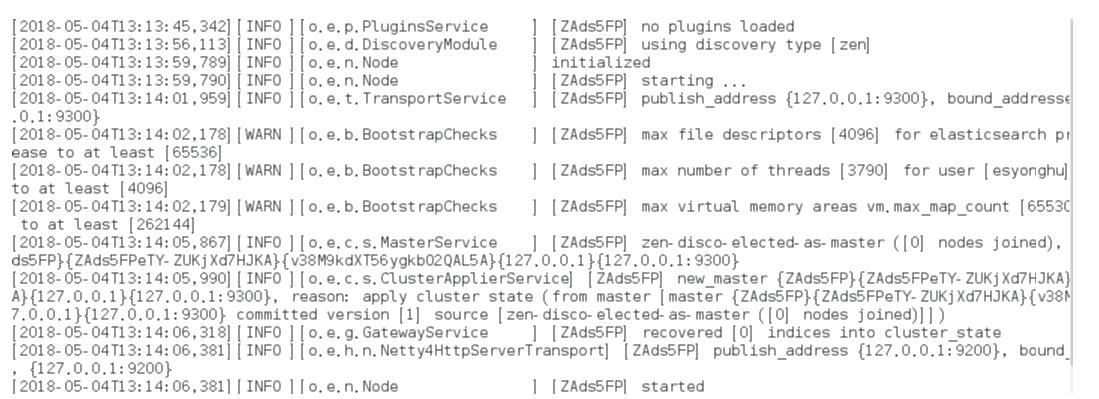
处理第一个错误:
vim /etc/security/limits.conf //文件最后加入
esuser soft nofile 65536
esuser hard nofile 65536
esuser soft nproc 4096
esuser hard nproc 4096
处理第二个错误:
进入limits.d目录下修改配置文件。
vim /etc/security/limits.d/20-nproc.conf
修改为 esuser soft nproc 4096
注意重新登录生效!!!!!!!!
处理第三个错误:
vim /etc/sysctl.conf
vm.max_map_count=655360
执行以下命令生效:
sysctl -p
关闭防火墙:systemctl stop firewalld.service
启动又又又报错
system call filters failed to install; check the logs and fix your configuration or disable sys

直接在
config/elasticsearch.yml 末尾加上一句
bootstrap.system_call_filter: false再次启动成功!
安装Head插件
Head是elasticsearch的集群管理工具,可以用于数据的浏览和查询
(1)elasticsearch-head是一款开源软件,被托管在github上面,所以如果我们要使用它,必须先安装git,通过git获取elasticsearch-head
(2)运行elasticsearch-head会用到grunt,而grunt需要npm包管理器,所以nodejs是必须要安装的
nodejs和npm安装:
http://blog.java1234.com/blog/articles/354.html
git安装
yum install -y git
(3)elasticsearch5.0之后,elasticsearch-head不做为插件放在其plugins目录下了。
使用git拷贝elasticsearch-head到本地
cd ~
git clone git://github.com/mobz/elasticsearch-head.git
(4)安装elasticsearch-head依赖包
[root@localhost local]# npm install -g grunt-cli
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# cnpm install
(5)修改Gruntfile.js
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# vi Gruntfile.js
在connect-->server-->options下面添加:hostname:’*’,允许所有IP可以访问
(6)修改elasticsearch-head默认连接地址
[root@localhost elasticsearch-head]# cd /usr/local/elasticsearch-head/_site/
[root@localhost _site]# vi app.js
将this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";中的localhost修改成你es的服务器地址
(7)配置elasticsearch允许跨域访问
打开elasticsearch的配置文件elasticsearch.yml,在文件末尾追加下面两行代码即可:
http.cors.enabled: true
http.cors.allow-origin: "*"
(8)打开9100端口
[root@localhost elasticsearch-head]# firewall-cmd --zone=public --add-port=9100/tcp --permanent
重启防火墙
[root@localhost elasticsearch-head]# firewall-cmd --reload
(9)启动elasticsearch
(10)启动elasticsearch-head
[root@localhost _site]# cd ~/elasticsearch-head/
[root@localhost elasticsearch-head]# node_modules/grunt/bin/grunt server 或者 npm run start
(11)访问elasticsearch-head
关闭防火墙:systemctl stop firewalld.service
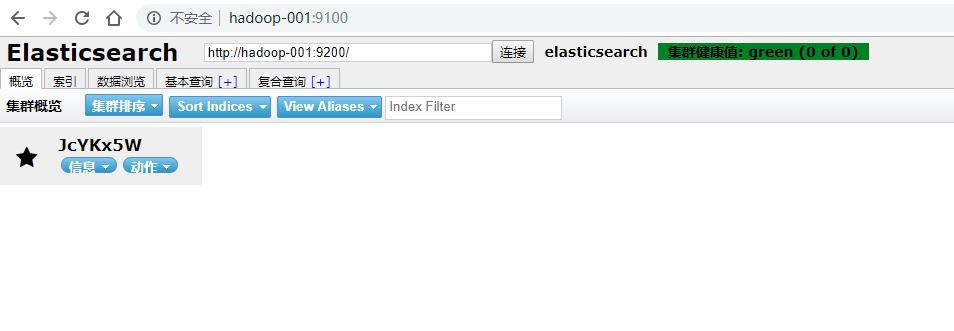
浏览器输入网址:hadoop-001:9100/
安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据
(1)下载Kibana
https://www.elastic.co/downloads/kibana
(2)把下载好的压缩包拷贝到/soft目录下
(3)解压缩,并把解压后的目录移动到/user/local/kibana
(4)编辑kibana配置文件
[root@localhost /]# vi /usr/local/kibana/config/kibana.yml
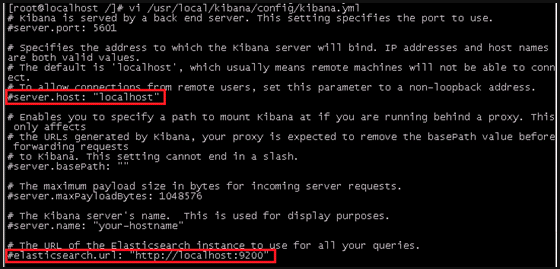
将server.host,elasticsearch.url修改成所在服务器的ip地址
server.port: 5601 //监听端口
server.host: "hadoo-001" //监听IP地址,建议内网ip
elasticsearch.url: "http:/hadoo-001" //elasticsearch连接kibana的URL,也可以填写192.168.137.188,因为它们是一个集群
(5)开启5601端口
Kibana的默认端口是5601
开启防火墙:systemctl start firewalld.service
开启5601端口:firewall-cmd --permanent --zone=public --add-port=5601/tcp
重启防火墙:firewall-cmd –reload
(6)启动Kibana
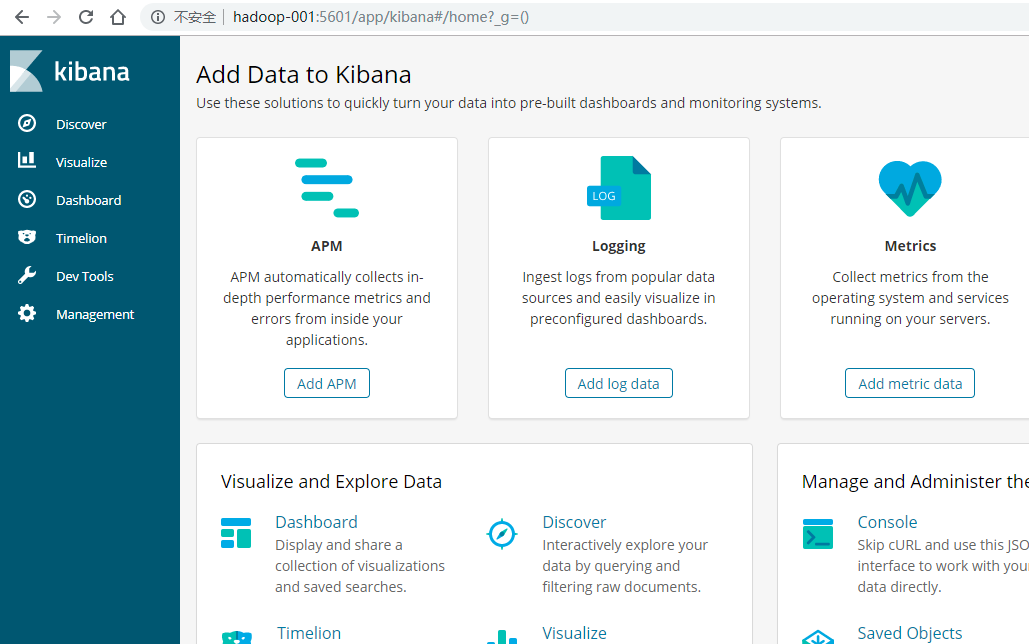
[root@localhost /]# /usr/local/kibana/bin/kibana
浏览器访问:http://192.168.137.188:5601
安装中文分词器
一.离线安装
(1)下载中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
下载elasticsearch-analysis-ik-master.zip
(2)解压elasticsearch-analysis-ik-master.zip
unzip elasticsearch-analysis-ik-master.zip
(3)进入elasticsearch-analysis-ik-master,编译源码
mvn clean install -Dmaven.test.skip=true
(4)在es的plugins文件夹下创建目录ik
(5)将编译后生成的elasticsearch-analysis-ik-版本.zip移动到ik下,并解压
(6)解压后的内容移动到ik目录下
二.在线安装
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
")
Elasticsearch Java API 索引的增删改查(二)
Elasticsearch Java API - 客户端连接(TransportClient,PreBuiltXPackTransportClient)(一)
本节介绍以下 CRUD API:
单文档 APIs
- Index API
- Get API
- Delete API
- Delete By Query API
- Update API
多文档 APIs
- Multi Get API
- Bulk API
- Using Bulk Processor
Multi Get API
Bulk API
注意:所有的单文档的CRUD API,index参数只能接受单一的索引库名称,或者是一个指向单一索引库的alias。
Index API
Index API 允许我们存储一个JSON格式的文档,使数据可以被搜索。文档通过index、type、id唯一确定。我们可以自己提供一个id,或者也使用Index API 为我们自动生成一个。
这里有几种不同的方式来产生JSON格式的文档(document):
- 手动方式,使用原生的byte[]或者String
- 使用Map方式,会自动转换成与之等价的JSON
- 使用第三方库来序列化beans,如Jackson
- 使用内置的帮助类 XContentFactory.jsonBuilder()
手动方式
数据格式
String json = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
实例
/**
* 手动生成JSON
*/
@Test
public void CreateJSON(){
String json = "{" +
"\"user\":\"fendo\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"Hell word\"" +
"}";
IndexResponse response = client.prepareIndex("fendo", "fendodate")
.setSource(json)
.get();
System.out.println(response.getResult());
}
Map方式
Map是key:value数据类型,可以代表json结构.
Map<String, Object> json = new HashMap<String, Object>();
json.put("user","kimchy");
json.put("postDate",new Date());
json.put("message","trying out Elasticsearch");
实例
/**
* 使用集合
*/
@Test
public void CreateList(){
Map<String, Object> json = new HashMap<String, Object>();
json.put("user","kimchy");
json.put("postDate","2013-01-30");
json.put("message","trying out Elasticsearch");
IndexResponse response = client.prepareIndex("fendo", "fendodate")
.setSource(json)
.get();
System.out.println(response.getResult());
}
序列化方式
ElasticSearch已经使用了jackson,可以直接使用它把javabean转为json.
import com.fasterxml.jackson.databind.*;
// instance a json mapper
ObjectMapper mapper = new ObjectMapper(); // create once, reuse
// generate json
byte[] json = mapper.writeValueAsBytes(yourbeaninstance);
实例
/**
* 使用JACKSON序列化
* @throws Exception
*/
@Test
public void CreateJACKSON() throws Exception{
CsdnBlog csdn=new CsdnBlog();
csdn.setAuthor("fendo");
csdn.setContent("这是JAVA书籍");
csdn.setTag("C");
csdn.setView("100");
csdn.setTitile("编程");
csdn.setDate(new Date().toString());
// instance a json mapper
ObjectMapper mapper = new ObjectMapper(); // create once, reuse
// generate json
byte[] json = mapper.writeValueAsBytes(csdn);
IndexResponse response = client.prepareIndex("fendo", "fendodate")
.setSource(json)
.get();
System.out.println(response.getResult());
}
XContentBuilder帮助类方式
ElasticSearch提供了一个内置的帮助类XContentBuilder来产生JSON文档
// Index name
String _index = response.getIndex();
// Type name
String _type = response.getType();
// Document ID (generated or not)
String _id = response.getId();
// Version (if it''s the first time you index this document, you will get: 1)
long _version = response.getVersion();
// status has stored current instance statement.
RestStatus status = response.status();
实例
/**
* 使用ElasticSearch 帮助类
* @throws IOException
*/
@Test
public void CreateXContentBuilder() throws IOException{
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("user", "ccse")
.field("postDate", new Date())
.field("message", "this is Elasticsearch")
.endObject();
IndexResponse response = client.prepareIndex("fendo", "fendodata").setSource(builder).get();
System.out.println("创建成功!");
}
综合实例
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Before;
import org.junit.Test;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class CreateIndex {
private TransportClient client;
@Before
public void getClient() throws Exception{
//设置集群名称
Settings settings = Settings.builder().put("cluster.name", "my-application").build();// 集群名
//创建client
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
}
/**
* 手动生成JSON
*/
@Test
public void CreateJSON(){
String json = "{" +
"\"user\":\"fendo\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"Hell word\"" +
"}";
IndexResponse response = client.prepareIndex("fendo", "fendodate")
.setSource(json)
.get();
System.out.println(response.getResult());
}
/**
* 使用集合
*/
@Test
public void CreateList(){
Map<String, Object> json = new HashMap<String, Object>();
json.put("user","kimchy");
json.put("postDate","2013-01-30");
json.put("message","trying out Elasticsearch");
IndexResponse response = client.prepareIndex("fendo", "fendodate")
.setSource(json)
.get();
System.out.println(response.getResult());
}
/**
* 使用JACKSON序列化
* @throws Exception
*/
@Test
public void CreateJACKSON() throws Exception{
CsdnBlog csdn=new CsdnBlog();
csdn.setAuthor("fendo");
csdn.setContent("这是JAVA书籍");
csdn.setTag("C");
csdn.setView("100");
csdn.setTitile("编程");
csdn.setDate(new Date().toString());
// instance a json mapper
ObjectMapper mapper = new ObjectMapper(); // create once, reuse
// generate json
byte[] json = mapper.writeValueAsBytes(csdn);
IndexResponse response = client.prepareIndex("fendo", "fendodate")
.setSource(json)
.get();
System.out.println(response.getResult());
}
/**
* 使用ElasticSearch 帮助类
* @throws IOException
*/
@Test
public void CreateXContentBuilder() throws IOException{
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("user", "ccse")
.field("postDate", new Date())
.field("message", "this is Elasticsearch")
.endObject();
IndexResponse response = client.prepareIndex("fendo", "fendodata").setSource(builder).get();
System.out.println("创建成功!");
}
}
你还可以通过startArray(string)和endArray()方法添加数组。.field()方法可以接受多种对象类型。你可以给它传递数字、日期、甚至其他XContentBuilder对象。
Get API
根据id查看文档:
GetResponse response = client.prepareGet("twitter", "tweet", "1").get();
更多请查看 rest get API 文档
配置线程
operationThreaded 设置为 true 是在不同的线程里执行此次操作
下面的例子是operationThreaded 设置为 false :
GetResponse response = client.prepareGet("twitter", "tweet", "1")
.setOperationThreaded(false)
.get();
Delete API
根据ID删除:
DeleteResponse response = client.prepareDelete("twitter", "tweet", "1").get();
更多请查看 delete API 文档
配置线程
operationThreaded 设置为 true 是在不同的线程里执行此次操作
下面的例子是operationThreaded 设置为 false :
GetResponse response = client.prepareGet("twitter", "tweet", "1")
.setOperationThreaded(false)
.get();
DeleteResponse response = client.prepareDelete("twitter", "tweet", "1")
.setOperationThreaded(false)
.get();
Delete By Query API
通过查询条件删除
BulkByScrollResponse response =
DeleteByQueryAction.INSTANCE.newRequestBuilder(client)
.filter(QueryBuilders.matchQuery("gender", "male")) //查询条件
.source("persons") //index(索引名)
.get(); //执行
long deleted = response.getDeleted(); //删除文档的数量
如果需要执行的时间比较长,可以使用异步的方式处理,结果在回调里面获取
DeleteByQueryAction.INSTANCE.newRequestBuilder(client)
.filter(QueryBuilders.matchQuery("gender", "male")) //查询
.source("persons") //index(索引名)
.execute(new ActionListener<BulkByScrollResponse>() { //回调监听
@Override
public void onResponse(BulkByScrollResponse response) {
long deleted = response.getDeleted(); //删除文档的数量
}
@Override
public void onFailure(Exception e) {
// Handle the exception
}
});
Update API
有两种方式更新索引:
- 创建
UpdateRequest,通过client发送; - 使用
prepareUpdate()方法;
使用UpdateRequest
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("index");
updateRequest.type("type");
updateRequest.id("1");
updateRequest.doc(jsonBuilder()
.startObject()
.field("gender", "male")
.endObject());
client.update(updateRequest).get();
使用 prepareUpdate() 方法
这里官方的示例有问题,new Script()参数错误,所以一下代码是我自己写的(2017/11/10)
client.prepareUpdate("ttl", "doc", "1")
.setScript(new Script("ctx._source.gender = \"male\"" ,ScriptService.ScriptType.INLINE, null, null))//脚本可以是本地文件存储的,如果使用文件存储的脚本,需要设置 ScriptService.ScriptType.FILE
.get();
client.prepareUpdate("ttl", "doc", "1")
.setDoc(jsonBuilder() //合并到现有文档
.startObject()
.field("gender", "male")
.endObject())
.get();
Update by script
使用脚本更新文档
UpdateRequest updateRequest = new UpdateRequest("ttl", "doc", "1")
.script(new Script("ctx._source.gender = \"male\""));
client.update(updateRequest).get();
Update by merging documents
合并文档
UpdateRequest updateRequest = new UpdateRequest("index", "type", "1")
.doc(jsonBuilder()
.startObject()
.field("gender", "male")
.endObject());
client.update(updateRequest).get();
Upsert
更新插入,如果存在文档就更新,如果不存在就插入
IndexRequest indexRequest = new IndexRequest("index", "type", "1")
.source(jsonBuilder()
.startObject()
.field("name", "Joe Smith")
.field("gender", "male")
.endObject());
UpdateRequest updateRequest = new UpdateRequest("index", "type", "1")
.doc(jsonBuilder()
.startObject()
.field("gender", "male")
.endObject())
.upsert(indexRequest); //如果不存在此文档 ,就增加 `indexRequest`
client.update(updateRequest).get();
如果 index/type/1 存在,类似下面的文档:
{
"name" : "Joe Dalton",
"gender": "male"
}
如果不存在,会插入新的文档:
{
"name" : "Joe Smith",
"gender": "male"
}
Multi Get API
一次获取多个文档
MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("twitter", "tweet", "1") //一个id的方式
.add("twitter", "tweet", "2", "3", "4") //多个id的方式
.add("another", "type", "foo") //可以从另外一个索引获取
.get();
for (MultiGetItemResponse itemResponse : multiGetItemResponses) { //迭代返回值
GetResponse response = itemResponse.getResponse();
if (response.isExists()) { //判断是否存在
String json = response.getSourceAsString(); //_source 字段
}
}
更多请浏览REST multi get 文档
Bulk API
Bulk API,批量插入:
import static org.elasticsearch.common.xcontent.XContentFactory.*;
BulkRequestBuilder bulkRequest = client.prepareBulk();
// either use client#prepare, or use Requests# to directly build index/delete requests
bulkRequest.add(client.prepareIndex("twitter", "tweet", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
);
bulkRequest.add(client.prepareIndex("twitter", "tweet", "2")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "another post")
.endObject()
)
);
BulkResponse bulkResponse = bulkRequest.get();
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
//处理失败
}
使用 Bulk Processor
BulkProcessor 提供了一个简单的接口,在给定的大小数量上定时批量自动请求
创建BulkProcessor实例
首先创建BulkProcessor实例
import org.elasticsearch.action.bulk.BackoffPolicy;
import org.elasticsearch.action.bulk.BulkProcessor;
import org.elasticsearch.common.unit.ByteSizeUnit;
import org.elasticsearch.common.unit.ByteSizeValue;
import org.elasticsearch.common.unit.TimeValue;
BulkProcessor bulkProcessor = BulkProcessor.builder(
client, //增加elasticsearch客户端
new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId,
BulkRequest request) { ... } //调用bulk之前执行 ,例如你可以通过request.numberOfActions()方法知道numberOfActions
@Override
public void afterBulk(long executionId,
BulkRequest request,
BulkResponse response) { ... } //调用bulk之后执行 ,例如你可以通过request.hasFailures()方法知道是否执行失败
@Override
public void afterBulk(long executionId,
BulkRequest request,
Throwable failure) { ... } //调用失败抛 Throwable
})
.setBulkActions(10000) //每次10000请求
.setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB)) //拆成5mb一块
.setFlushInterval(TimeValue.timeValueSeconds(5)) //无论请求数量多少,每5秒钟请求一次。
.setConcurrentRequests(1) //设置并发请求的数量。值为0意味着只允许执行一个请求。值为1意味着允许1并发请求。
.setBackoffPolicy(
BackoffPolicy.exponentialBackoff(TimeValue.timeValueMillis(100), 3))//设置自定义重复请求机制,最开始等待100毫秒,之后成倍更加,重试3次,当一次或多次重复请求失败后因为计算资源不够抛出 EsRejectedExecutionException 异常,可以通过BackoffPolicy.noBackoff()方法关闭重试机制
.build();
BulkProcessor 默认设置
- bulkActions 1000
- bulkSize 5mb
- 不设置flushInterval
- concurrentRequests 为 1 ,异步执行
- backoffPolicy 重试 8次,等待50毫秒
增加requests
然后增加requests到BulkProcessor
bulkProcessor.add(new IndexRequest("twitter", "tweet", "1").source(/* your doc here */));
bulkProcessor.add(new DeleteRequest("twitter", "tweet", "2"));
关闭 Bulk Processor
当所有文档都处理完成,使用awaitClose 或 close 方法关闭BulkProcessor:
bulkProcessor.awaitClose(10, TimeUnit.MINUTES);
或
bulkProcessor.close();
在测试中使用Bulk Processor
如果你在测试种使用Bulk Processor可以执行同步方法
BulkProcessor bulkProcessor = BulkProcessor.builder(client, new BulkProcessor.Listener() { /* Listener methods */ })
.setBulkActions(10000)
.setConcurrentRequests(0)
.build();
// Add your requests
bulkProcessor.add(/* Your requests */);
// Flush any remaining requests
bulkProcessor.flush();
// Or close the bulkProcessor if you don''t need it anymore
bulkProcessor.close();
// Refresh your indices
client.admin().indices().prepareRefresh().get();
// Now you can start searching!
client.prepareSearch().get();
所有实例 已经上传到Git
更多请浏览 spring-boot-starter-es 开源项目
作者:quanke
链接:http://www.jianshu.com/p/42b0c4cd0232
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

ELASTICSEARCH JAVA 的增删改查
操作 ES 的对象 :TransportClient
<!--elasticsear使用的jar --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>${elasticsearch.client.version}</version> </dependency> <!--elasticsear使用的jar -->
我的版本是 5.4.0
创建 TransportClient 对象
我是使用 spring 的 bean 注入的
@SuppressWarnings("resource") @Bean(name="transportClient") @Lazy public TransportClient getTransportClient(){ TransportClient client =null; try{ Settings settings= Settings.builder().put("cluster.name", "elasticsearch").build(); client=new PreBuiltTransportClient(settings).addTransportAddress( new InetSocketTransportAddress(InetAddress.getByName("192.168.0.11"),9300)); log.info("创建es客户端对象成功"); }catch(Exception e){ log.error("创建es客户端对象失败"); log.error("失败原因:"+e.getMessage()); System.exit(-1); } return client; }
创建对象那个成功后,就可以用来操作 es 库了,他的作用跟 spring-jdbctemplate,spring-jdbctemplate 一样,提供了对数据库增删改查的功能,
spring 也提供了对 es 操作的对象叫 Spring Data Elasticsearch
参考文档:
- http://www.ibm.com/developerworks/cn/opensource/os-cn-spring-jpa
我用的就是 es 自己提供的对象 TransportClient
添加数据
es 的添加数据提供了多种方法,跟 hql 语言有点相似,都是面向对象的。
es 支持批量操作的方法,为了提供效率都是用批量的对象
BulkRequestBuilder builder=transportClient.prepareBulk();
BulkRequestBuilder 对象有一个地方需要注意,因为是批量操作,es 忽略了数据的不正确性,就算你的数据不对,builder 也不会报错,所以在调试阶段需要先确保数据的准确性再用该对象进行操作。
插入数据,其实只需要把你的对象转成 json,然后批量插入即可
@Override public void batchAddMyZu(List<Family> list) { BulkRequestBuilder builder=transportClient.prepareBulk(); for(Family family:list){ String objstr= JSON.toJSONString(family); builder.add(client.prepareIndex("family","myfamily",family.getPrimaryKey()).setSource(objstr, XContentType.JSON)); } builder.execute().actionGet(); System.out.println("此次插入数据的个数是 "+list.size()); }
setSource 方法里面可以指定各种插入类型,我一般都是用 json 格式。
删除操作
es 可以通过指定 index,type,id 删除数据,也支持搜索删除 deleteByQuery
- 通过指定 id 删除方法
@Override public void batchUndercarriageFamilies(List<String> publishIds) { BulkRequestBuilder builder=transportClient.prepareBulk(); for(String publishId:publishIds){ builder.add(transportClient.prepareDelete(FAMILY, FAMILY_MARKETFAMILY, publishId).request()); } builder.get(); }
- 通过 deleteByQuery 删除
-
@Override public void delMyZu(String guid, String userId) { DeleteByQueryAction.INSTANCE.newRequestBuilder(transportClient) .source(FAMILY) .filter(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("zuGUID", guid)).must(QueryBuilders.termQuery("userId", userId)).must(QueryBuilders.typeQuery(FAMILY_MYFAMILY))) .get(); }
QueryBuilder 对象可以做任何查询
修改操作
我现在修改是根据指定索引后然后修改指定字段酱样的
@Override public void updateMyZu_Related4MyZuValue(List<Related4MyZuValue> list) { BulkRequestBuilder builder=transportClient.prepareBulk(); for(Related4MyZuValue value:list){ try { XContentBuilder source=XContentFactory.jsonBuilder().startObject() .field("related4ZuValue",value.getRelated4ZuValue()) .field("zuSalePrice",value.getZuSalePrice()) .endObject(); builder.add(transportClient.prepareUpdate(FAMILY, FAMILY_MYFAMILY, value.getPrimaryKey()).setDoc(source)); } catch (IOException e) { continue; } } builder.get(); }
我这种操作是执行 id 后修改该数据的 related4ZuValue 的值和 zuSalePrice 的值
查询操作
es 最主要功能就是查询
QueryBuilder 就是设置查询条件的对象,你可以通过他设置各种条件
随便贴几个,自己感受吧。。。。
BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery(); if(keyword!=null&&!keyword.equals("")){ QueryBuilder nameBuilder=QueryBuilders.matchQuery("zuName", keyword).analyzer("ik_max_word").boost(10); QueryBuilder labelBuilder=QueryBuilders.matchQuery("zuLabelName", keyword).analyzer("ik_max_word").boost(10); QueryBuilder categoryBuilder=QueryBuilders.matchQuery("categoryName", keyword).analyzer("ik_max_word").boost(10); boolQueryBuilder.should(nameBuilder).should(labelBuilder).should(categoryBuilder); }else{ boolQueryBuilder.must(QueryBuilders.matchAllQuery()); } SearchResponse response=transportClient.prepareSearch(FAMILY).setTypes(FAMILY_MARKETFAMILY) .setQuery(boolQueryBuilder) .setFrom((page-1)*pageSize).setSize(pageSize) .setExplain(true) .get(); SearchHits hits=response.getHits();
BoolQueryBuilder builders=new BoolQueryBuilder(); //加上条件 builders.must(QueryBuilders.termQuery("userId", userId)); if(relatedValue==RelatedValue.MyBuyerZu.value()){ builders.must(QueryBuilders.nestedQuery("related4ZuValue", QueryBuilders.boolQuery() .must(QueryBuilders.termQuery("related4ZuValue.nameValue", UserReltatedValueUtil.getUserRelatedValue(relatedValue))) //.must(QueryBuilders.rangeQuery("endTime").lte(LongformStringDate(System.currentTimeMillis()))) ,ScoreMode.None)); }else{ builders.must(QueryBuilders.nestedQuery("related4ZuValue", QueryBuilders.termQuery("related4ZuValue.nameValue", UserReltatedValueUtil.getUserRelatedValue(relatedValue)), ScoreMode.None)); } SearchResponse response=transportClient.prepareSearch(FAMILY).setTypes(FAMILY_MYFAMILY) .setQuery(builders).setFrom((page-1)*pageSize) .setSize(pageSize) .get(); SearchHits hits=response.getHits();
@Override public MarketFamily getMarketFamily(String guid) { MarketFamily marketFamily=new MarketFamily(); SearchResponse response=transportClient.prepareSearch(FAMILY) .setTypes(FAMILY_MYFAMILY).setQuery(QueryBuilders.termQuery("zuGUID", guid)) .setSize(1) .get(); SearchHits hits=response.getHits(); for(SearchHit hit:hits.getHits()){ marketFamily=JSON.parseObject(hit.getSourceAsString(),MarketFamily.class); } return marketFamily; }
取查询结果总和 count
@Override public long countMyAllZu(String userId, int relatedValue) { BoolQueryBuilder builders=new BoolQueryBuilder(); builders.must(QueryBuilders.termQuery("userId", userId)); if(relatedValue==RelatedValue.MyBuyerZu.value()){ builders.must(QueryBuilders.nestedQuery("related4ZuValue", QueryBuilders.boolQuery() .must(QueryBuilders.termQuery("related4ZuValue.nameValue", UserReltatedValueUtil.getUserRelatedValue(relatedValue))) .must(QueryBuilders.rangeQuery("endTime").lte(LongformStringDate(System.currentTimeMillis()))) ,ScoreMode.None)); }else{ builders.must(QueryBuilders.nestedQuery("related4ZuValue", QueryBuilders.termQuery("related4ZuValue.nameValue", UserReltatedValueUtil.getUserRelatedValue(relatedValue)), ScoreMode.None)); } SearchResponse response=transportClient.prepareSearch(FAMILY).setTypes(FAMILY_MYFAMILY) .setQuery(builders) .setSize(1) .get(); SearchHits hits=response.getHits(); return hits.getTotalHits(); }
聚合求和 sum
@Override public long getPlatformZuOrdersTotalAmount(String keyword,String startTime,String endTime) { BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery(); if(keyword==null||keyword.equals("")){ QueryBuilder queryBuilder=QueryBuilders.matchAllQuery(); boolQueryBuilder.must(queryBuilder); }else{ QueryBuilder zuNameBuilder=QueryBuilders.matchQuery("zuName", keyword); QueryBuilder buyerNameBuilder=QueryBuilders.matchQuery("buyerName", keyword); QueryBuilder sellerNameBuilder=QueryBuilders.matchQuery("sellerName", keyword); boolQueryBuilder.should(zuNameBuilder).should(buyerNameBuilder).should(sellerNameBuilder); } if(!startTime.equals("")){ QueryBuilder addTimeBuilder=QueryBuilders.rangeQuery("addTime").from(startTime).to(endTime); boolQueryBuilder.must(addTimeBuilder); } SearchResponse response=transportClient.prepareSearch(FAMILY).setTypes(FAMILY_FAMILYORDER) .setQuery(boolQueryBuilder) .addAggregation(AggregationBuilders.sum("price").field("price")) .get(); Sum sum=response.getAggregations().get("price"); return (long) sum.getValue(); }
我是使用 java 操作 es 的,大家可以在扣扣群互相交流
要下班了,暂时更新到这里

elasticsearch java索引的增删改查
1.创建索引并插入数据
Map<String, Object> json = new HashMap<String, Object>();
json.put("user", "kimchy5");
json.put("postDate", new Date());
json.put("message", "trying out Elasticsearch");
//参数设置
//Settings settings = Settings.settingsBuilder().put("cluster.name", "elasticsearch").build();
//TransportClient client = TransportClient.builder().settings(settings).build();
Client client = TransportClient.builder().build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 第一个参数:索引名;第二个参数:索引类型;第三个参数:索引ID(相同的id时修改数据,默认为随机字符串)
IndexResponse indexResponse = client.prepareIndex("twitter", "json", "1").setSource(json).get();
System.out.println(indexResponse);
// 不指定id会随机生成一个
//client.prepareIndex("twitter", "tweet").setSource(json);
client.close();
2.索引数据批量插入(插入效率高)
// 批量插入数据,删除和修改也可以,不举例了
BulkRequestBuilder bulkRequest = client.prepareBulk();
IndexRequest request = client.prepareIndex("twitter", "tweet", "1").setSource(json).request();
IndexRequest request2 = client.prepareIndex("twitter", "tweet", "2").setSource(json2).request();
bulkRequest.add(request);
bulkRequest.add(request2);
bulkRequest.execute().actionGet();
3.判断索引是否存在
IndicesExistsRequest inExistsRequest = new IndicesExistsRequest("twitter");
IndicesExistsResponse inExistsResponse = client.admin().indices().exists(inExistsRequest).actionGet();
System.out.println("索引twitter是否存在:"+inExistsResponse.isExists());
4.删除索引
//删除索引twitter
client.admin().indices().prepareDelete("twitter").execute().actionGet();
//删除索引中的某个文档(一条数据)
client.prepareDelete("twitter", "tweet", "1");
5.查询索引库
Client client = TransportClient.builder().build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 第一个参数:要查找的内容 第二,三个参数:要查找的字段
QueryBuilder qb = QueryBuilders.multiMatchQuery("喧嚣", "content","message");
// twitter:索引名 tweet:索引类型
SearchResponse response = client.prepareSearch("twitter").setTypes("tweet").setQuery(qb)
//设置查询类型 SearchType.QUERY_AND_FETCH:全部获取
.setSearchType(SearchType.DFS_QUERY_AND_FETCH).execute().actionGet();
SearchHits hits = response.getHits();
if (hits.totalHits() > 0) {
for (SearchHit hit : hits) {
System.out.println("score:" + hit.getScore() + ":\t" + hit.getSource());// .get("title")
}
} else {
System.out.println("搜到0条结果");
}
client.close();
6.刷新索引
//刷新所有
client.admin().indices().prepareRefresh().get();
//刷新某一个
client.admin().indices().prepareRefresh("twitter").get();
//刷新某个类型
client.admin().indices().prepareRefresh("twitter","tweet").get();
7.更新索引数据
//更新索引(根据索引,类型,id)
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("twitter");
updateRequest.type("tweet");
updateRequest.id("1");
updateRequest.doc(jsonBuilder().startObject().field("content", "如果我说爱我没有如果").endObject());
client.update(updateRequest).get();
或
UpdateRequest updateRequest = new UpdateRequest("twitter", "tweet", "1")
.doc(jsonBuilder().startObject().field("content", "如果我说爱我没有如果").endObject());
client.update(updateRequest).get();
8.插入更新
//插入更新(如果不存在id为3的则插入content为IndexRequest的内容,如果存在则更新content为UpdateRequest的内容)
IndexRequest indexRequest = new IndexRequest("twitter", "tweet", "3")
.source(jsonBuilder().startObject()
.field("content", "每当我迷失在黑夜里")
.endObject());
UpdateRequest updateRequest2 = new UpdateRequest("twitter", "tweet", "3")
.doc(jsonBuilder().startObject()
.field("content", "请照亮我前行")
.endObject())
.upsert(indexRequest);
client.update(updateRequest2).get();
client.close();
关于【Elasticsearch】- elasticsearch文档数据的增删改查和elasticsearch修改数据的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、Elasticsearch Java API 索引的增删改查(二)、ELASTICSEARCH JAVA 的增删改查、elasticsearch java索引的增删改查等相关知识的信息别忘了在本站进行查找喔。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

