在本文中,我们将带你了解配置Flask-SQLAlchemy以使用Flask-Restless的多个数据库在这篇文章中,同时我们还将给您一些技巧,以帮助您实现更有效的23.Flask操作Mysql数据
在本文中,我们将带你了解配置Flask-SQLAlchemy以使用Flask-Restless的多个数据库在这篇文章中,同时我们还将给您一些技巧,以帮助您实现更有效的23. Flask 操作Mysql数据库 - flask-sqlalchemy扩展、5.5 使用Flask-SQLAlchemy管理数据库、6、使用Flask-SQLAlchemy管理数据库和数据库的迁移、Flask 中使用 Flask-SQLAlchemy 查询数据库在数据库内容更新时无法实时返回。
本文目录一览:- 配置Flask-SQLAlchemy以使用Flask-Restless的多个数据库
- 23. Flask 操作Mysql数据库 - flask-sqlalchemy扩展
- 5.5 使用Flask-SQLAlchemy管理数据库
- 6、使用Flask-SQLAlchemy管理数据库和数据库的迁移
- Flask 中使用 Flask-SQLAlchemy 查询数据库在数据库内容更新时无法实时返回

配置Flask-SQLAlchemy以使用Flask-Restless的多个数据库
我有一个使用Flask-SQLAlchemy的Flask应用,并且正在尝试将其配置为使用Flask-Restless软件包使用多个数据库。
根据文档,配置模型以使用多个数据库__bind_key__似乎非常简单。
但是,它似乎不适用于我。
我创建我的应用程序并初始化数据库,如下所示:
from flask import Flask
from flask.ext.sqlalchemy import SQLAlchemy
SQLALCHEMY_DATABASE_URI = 'postgres://db_user:db_pw@localhost:5432/db_name'
SQLALCHEMY_BINDS = {
'db1': SQLALCHEMY_DATABASE_URI,'db2': 'mysql://db_user:db_pw@localhost:3306/db_name'
}
app = Flask(__name__)
db = SQLALchemy(app)
然后定义包括在内的模型__bind_key__,这些模型应该告诉SQLAlchemy它需要使用哪个数据库:
class PostgresModel(db.Model):
__tablename__ = 'postgres_model_table'
__bind_key__ = 'db1'
id = db.Column(db.Integer,primary_key=True)
...
class MySQLModel(db.Model):
__tablename__ = 'mysql_model_table'
__bind_key__ = 'db2'
id = db.Column(db.Integer,primary_key=True)
...
然后我像这样启动Flask-Restless:
manager = restless.APIManager(app,flask_sqlalchemy_db=db)
manager.init_app(app,db)
auth_func = lambda: is_authenticated(app)
manager.create_api(PostgresModel,methods=['GET'],collection_name='postgres_model',authentication_required_for=['GET'],authentication_function=auth_func)
manager.create_api(MySQLModel,collection_name='mysql_model',authentication_function=auth_func)
该应用程序运行良好,当我点击时,我http://localhost:5000/api/postgres_model/[id]从Postgres
DB中获得了对象的预期JSON响应(我猜这是因为我在SQLALCHEMY_DATABASE_URI中拥有凭据)。
尽管当我点击时http://localhost:5000/api/mysql_model/[id],我得到一个mysql_model_table不存在的错误,表明它在Postgres
DB中查找,而不是MySQL中。
我在这里做错了什么?

23. Flask 操作Mysql数据库 - flask-sqlalchemy扩展
官网文档
https://flask-sqlalchemy.palletsprojects.com/en/master/quickstart/
数据库的设置
Web应用中普遍使用的是关系模型的数据库,关系型数据库把所有的数据都存储在表中,表用来给应用的实体建模,表的列数是固定的,行数是可变的。它使用结构化的查询语言。关系型数据库的列定义了表中表示的实体的数据属性。比如:商品表里有name、price、number等。 Flask本身不限定数据库的选择,你可以选择sql或NOsql的任何一种。也可以选择更方便的sqlALchemy,类似于Django的ORM。sqlALchemy实际上是对数据库的抽象,让开发者不用直接和sql语句打交道,而是通过Python对象来操作数据库,在舍弃一些性能开销的同时,换来的是开发效率的较大提升。
sqlAlchemy是一个关系型数据库框架,它提供了高层的ORM和底层的原生数据库的操作。flask-sqlalchemy是一个简化了sqlAlchemy操作的flask扩展。
下面使用MysqL作为示例进行说明。
创建MysqL数据库
1.登录数据库
MysqL -u root -p password
2.创建数据库,并设定编码
create database <数据库名> charset=utf8;
3.显示所有数据库
show databases;
4.执行如下
MysqL> create database flask_ex charset=utf8;
Query OK, 1 row affected (0.06 sec)
安装flask-sqlalchemy的扩展
pip install -U Flask-sqlAlchemy
python2:要连接MysqL数据库,仍需要安装flask-MysqLdb
pip install flask-MysqLdb
python3:要连接MysqL数据库,仍需要安装pyMysqL
pip install pyMysqL
本篇章内容以python3作为开讲。
使用Flask-sqlAlchemy连接MysqL数据库
使用Flask-sqlAlchemy扩展操作数据库,首先需要建立数据库连接。数据库连接通过URL指定,而且程序使用的数据库必须保存到Flask配置对象的sqlALCHEMY_DATABASE_URI键中。
对比下Django和Flask中的数据库设置:
Django的数据库设置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.MysqL', # 修改后端数据库使用MysqL
'NAME': 'mydb', # 设置访问数据库名称
'USER': 'root', # 访问访问MysqL用户名
'PASSWORD': 'password', # 设置访问密码
'HOST': 'localhost', # 设置访问ip地址
'PORT': 3306, # 设置访问端口号
}
}
Flask的数据库设置:
app.config['sqlALCHEMY_DATABASE_URI'] = 'MysqL://root:MysqL@127.0.0.1:3306/flask_ex'
常用的sqlAlchemy字段类型
上面看完了如何设置连接数据库,那么来看看,使用sqlAlchemy创建数据模型的时候,基本的字段类型如下:
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
常用的sqlAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
常用的sqlAlchemy关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多中记录的排序方式 |
| secondary join | 在sqlAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
上面这些有很多基本选项的说明,下面来进行数据库的基本增删改等操作来加强理解。
数据库基本操作
在Flask-sqlAlchemy中,插入、修改、删除操作,均由数据库会话管理。会话用db.session表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用commit()方法提交会话。
数据库会话是为了保证数据的一致性,避免因部分更新导致数据不一致。提交操作把会话对象全部写入数据库,如果写入过程发生错误,整个会话都会失效。
数据库会话也可以回滚,通过db.session.rollback()方法,实现会话提交数据前的状态。
在Flask-sqlAlchemy中,查询操作是通过query对象操作数据。最基本的查询是返回表中所有数据,可以通过过滤器进行更精确的数据库查询。
下面先来创建两个表的数据模型:用户表和角色表。
在视图函数中定义模型类
看完了上面那么多的概念说明,下面来看看如何创建数据模型以及创建数据表,如下:
1.在脚本15_sqlAlchemy.py编写创建User和Role数据模型
from flask import Flask
from flask_sqlalchemy import sqlAlchemy
import pyMysqL
pyMysqL.install_as_MysqLdb()
app = Flask(__name__)
class Config(object):
"""配置参数"""
# 设置连接数据库的URL
user = 'root'
password = '********'
database = 'flask_ex'
app.config['sqlALCHEMY_DATABASE_URI'] = 'MysqL://%s:%s@127.0.0.1:3306/%s' % (user,password,database)
# 设置sqlalchemy自动更跟踪数据库
sqlALCHEMY_TRACK_MODIFICATIONS = True
# 查询时会显示原始sql语句
app.config['sqlALCHEMY_ECHO'] = True
# 禁止自动提交数据处理
app.config['sqlALCHEMY_COMMIT_ON_TEARDOWN'] = False
# 读取配置
app.config.from_object(Config)
# 创建数据库sqlalchemy工具对象
db = sqlAlchemy(app)
class Role(db.Model):
# 定义表名
__tablename__ = 'roles'
# 定义字段
id = db.Column(db.Integer, primary_key=True,autoincrement=True)
name = db.Column(db.String(64), unique=True)
users = db.relationship('User',backref='role') # 反推与role关联的多个User模型对象
class User(db.Model):
# 定义表名
__tablename__ = 'users'
# 定义字段
id = db.Column(db.Integer, primary_key=True,autoincrement=True)
name = db.Column(db.String(64), unique=True, index=True)
email = db.Column(db.String(64),unique=True)
pswd = db.Column(db.String(64))
role_id = db.Column(db.Integer, db.ForeignKey('roles.id')) # 设置外键
if __name__ == '__main__':
# 删除所有表
db.drop_all()
# 创建所有表
db.create_all()
- 执行脚本,创建数据库
python3 15_sqlAlchemy.py
3.在MysqL查看已经创建的表结构
MysqL> show tables;
+--------------------+
| Tables_in_flask_ex |
+--------------------+
| roles |
| users |
+--------------------+
2 rows in set (0.00 sec)
MysqL>
MysqL> desc users;
+---------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(64) | YES | UNI | NULL | |
| email | varchar(64) | YES | UNI | NULL | |
| pswd | varchar(64) | YES | | NULL | |
| role_id | int(11) | YES | MUL | NULL | |
+---------+-------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
MysqL>
MysqL> desc roles;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(64) | YES | UNI | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
MysqL>
创建好了数据表之后,下面来看看如何执行数据的增删查改的。
常用的sqlAlchemy查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
常用的sqlAlchemy查询执行器
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回404 |
| get() | 返回指定主键对应的行,如不存在,返回None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回404 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个Paginate对象,它包含指定范围内的结果 |
创建表:
db.create_all()
删除表
db.drop_all()
每次插入单条数据
if __name__ == '__main__':
# 插入一条角色数据
role1 = Role(name='admin')
db.session.add(role1)
db.session.commit()
# 再次插入一条数据
role2 = Role(name='user')
db.session.add(role2)
db.session.commit()
执行脚本:
python3 15_sqlAlchemy.py
在MysqL中查看插入的数据,如下:
MysqL> select * from roles \G
*************************** 1. row ***************************
id: 1
name: admin
*************************** 2. row ***************************
id: 2
name: user
2 rows in set (0.00 sec)
一次插入多条数据
# 一次性插入多条数据
user1 = User(name='wang',email='wang@163.com',pswd='123456',role_id=role1.id)
user2 = User(name='zhang',email='zhang@189.com',pswd='201512',role_id=role2.id)
user3 = User(name='chen',email='chen@126.com',pswd='987654',role_id=role2.id)
user4 = User(name='zhou',email='zhou@163.com',pswd='456789',role_id=role1.id)
db.session.add_all([user1,user2,user3,user4])
db.session.commit()
执行插入数据,如下:
python3 15_sqlAlchemy.py
在MysqL中查询插入的数据如下:
MysqL> select * from users \G
*************************** 1. row ***************************
id: 1
name: wang
email: wang@163.com
pswd: 123456
role_id: 1
*************************** 2. row ***************************
id: 2
name: zhang
email: zhang@189.com
pswd: 201512
role_id: 2
*************************** 3. row ***************************
id: 3
name: chen
email: chen@126.com
pswd: 987654
role_id: 2
*************************** 4. row ***************************
id: 4
name: zhou
email: zhou@163.com
pswd: 456789
role_id: 1
4 rows in set (0.00 sec)
MysqL>
虽然这里在python中看上去是一次性插入多条数据,其实在MysqL也是执行多行插入的语句,通过MysqL的日志可以看到如下:
2019-11-23T16:48:56.984459Z 9061 Query INSERT INTO users (name, email, pswd, role_id) VALUES ('wang', 'wang@163.com', '123456', 1)
2019-11-23T16:48:56.997132Z 9061 Query INSERT INTO users (name, email, pswd, role_id) VALUES ('zhang', 'zhang@189.com', '201512', 2)
2019-11-23T16:48:57.010175Z 9061 Query INSERT INTO users (name, email, pswd, role_id) VALUES ('chen', 'chen@126.com', '987654', 2)
2019-11-23T16:48:57.024134Z 9061 Query INSERT INTO users (name, email, pswd, role_id) VALUES ('zhou', 'zhou@163.com', '456789', 1)
实际上并没有将多个values合并到一个insert语句,依然是多个insert语句逐个插入的。
查询:filter_by精确查询
返回名字等于wang的所有user
User.query.filter_by(name='wang').all()
在交互模型执行如下:
>python3 db_demo.py shell
In [1]: from db_demo import User
In [2]: User.query.filter_by(name='wang').all()
Out[2]: [<User 1>]
In [3]:
first()返回查询到的第一个对象
User.query.first()
执行如下:
In [3]: User.query.first()
Out[3]: <User 1>
all()返回查询到的所有对象
User.query.all()
执行如下:
In [4]: User.query.all()
Out[4]: [<User 1>, <User 2>, <User 3>, <User 4>]
In [5]:
filter模糊查询,返回名字结尾字符为g的所有数据。
User.query.filter(User.name.endswith('g')).all()
执行如下:
In [5]: User.query.filter(User.name.endswith('g')).all()
Out[5]: [<User 1>, <User 2>]
get(),参数为主键,如果主键不存在没有返回内容
User.query.get()
执行如下:
In [6]: User.query.get(2)
Out[6]: <User 2>
In [7]: user2 = User.query.get(2)
In [8]: user2.name
Out[8]: 'zhang'
逻辑非,返回名字不等于wang的所有数据。
User.query.filter(User.name!='wang').all()
执行如下:
In [9]: User.query.filter(User.name!='wang').all()
Out[9]: [<User 2>, <User 3>, <User 4>]
逻辑与,需要导入and*,返回and*()条件满足的所有数据。
from sqlalchemy import and_
User.query.filter(and_(User.name!='wang',User.email.endswith('163.com'))).all()
执行如下:
In [10]: from sqlalchemy import and_
In [15]: users = User.query.filter(and_(User.name!='wang',User.email.endswith('163.com'))).all()
In [16]: for user in users:
...: print(user.email)
...:
zhou@163.com
逻辑或,需要导入or_
from sqlalchemy import or_
User.query.filter(or_(User.name!='wang',User.email.endswith('163.com'))).all()
执行如下:
In [17]: from sqlalchemy import or_
In [18]: users = User.query.filter(or_(User.name!='wang',User.email.endswith('163.com'))).all()
In [19]: for user in users:
...: print(user.name, user.email)
...:
wang wang@163.com
zhang zhang@189.com
chen chen@126.com
zhou zhou@163.com
In [20]:
not_ 相当于取反
from sqlalchemy import not_
User.query.filter(not_(User.name=='chen')).all()
执行如下:
In [22]: from sqlalchemy import not_
In [25]: users = User.query.filter(not_(User.name=='chen')).all()
In [26]: for user in users:
...: print(user.name, user.email)
...:
wang wang@163.com
zhang zhang@189.com
zhou zhou@163.com
查询数据后删除
user = User.query.first()
db.session.delete(user)
db.session.commit()
User.query.all()
执行如下:
(venv) $ >python3 db_demo.py shell
In [1]: from db_demo import User
In [3]: user = User.query.first()
In [5]: from db_demo import db
In [6]: db.session.delete(user)
In [7]: db.session.commit()
In [8]: User.query.all()
Out[8]: [<User 2>, <User 3>, <User 4>]
更新数据
user = User.query.first()
user.name = 'dong'
db.session.commit()
User.query.first()
执行如下:
In [1]: from db_demo import User
In [5]: from db_demo import db
In [9]: user = User.query.first()
In [10]: user
Out[10]: <User 2>
In [11]: user.name
Out[11]: 'zhang'
In [12]: user.name = 'dong'
In [13]: db.session.commit()
In [14]: user = User.query.first()
In [15]: user.name
Out[15]: 'dong'
使用update
User.query.filter_by(name='zhang').update({'name':'li'})
执行如下:
In [21]: User.query.filter_by(name='dong').update({'name':'li'})
Out[21]: 0
In [22]: User.query.get(2)
Out[22]: <User 2>
In [23]: user = User.query.get(2)
In [24]: user.name
Out[24]: 'li'
关联查询示例:角色和用户的关系是一对多的关系,一个角色可以有多个用户,一个用户只能属于一个角色。
关联查询角色的所有用户:
#查询roles表id为1的角色
role1 = Role.query.get(1)
#查询该角色的所有用户
role1.users
执行如下:
In [25]: from db_demo import Role
In [26]: role1 = Role.query.get(1)
In [27]: role1.users
Out[27]: [<User 4>]
In [28]: role2 = Role.query.get(2)
In [29]: role2.users
Out[29]: [<User 2>, <User 3>]
关联查询用户所属角色:
#查询users表id为3的用户
user1 = User.query.get(3)
#查询用户属于什么角色
user1.role
执行如下:
In [30]: user1 = User.query.get(3)
In [31]: user1.role
Out[31]: <Role 2>

5.5 使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy 是一个 Flask 扩展,简化了在 Flask 应用中使用 SQLAlchemy 的操作。 SQLAlchemy 是一个强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy 提供了高层 ORM,也提供了使用数据库原生 SQL 的低层功能。
与其他多数扩展一样,Flask-SQLAlchemy 也使用 pip 安装:
pip3 install flask-sqlalchemy
在 Flask-SQLAlchemy 中,数据库使用 URL 指定。几种最流行的数据库引擎使用的URL格式如表 5-1 所示。
表5-1:FLask-SQLAlchemy数据库URL
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite(Linux,macOS) | sqlite:////absolute/path/to/database |
| SQLite(Windows) | sqlite:///c:/absolute/path/to/database |
在这些 URL 中,hostname 表示数据库服务所在的主机,可以是本地主机(localhost),也可以是远程服务器。数据库服务器上可以托管多个数据库,因此 database 表示要使用的数据库名。如果数据库需要验证身份,使用 username 和 password 提供数据库用户的凭据。
- SQLite 数据库没有服务器,因此不用指定 hostname、username 和 password。URL 中的 database 是磁盘中的文件名。
应用使用的数据库 URL 必须保存到 Flask 配置对象的 SQLALCHEMY_DATABASE_URI 键中。
Flask-SQLAlchemy 文档还建议把 SQLALCHEMY_TRACK_MODIFICATIONS 键设为 False,以便在不需要跟踪对象变化时降低内存消耗。其他配置选项的作用参阅 Flask-SQLAlchemy 的文档。
示例 5-1 展示如何初始化及配置一个简单的 SQLite 数据库。
示例 5-1 hello.py:配置数据库
import os
from flask_sqlalchemy import SQLAlchemy
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config[''SQLALCHEMY_DATABASE_URI''] =\
''sqlite:///'' + os.path.join(basedir, ''data.sqlite'') app.config[''SQLALCHEMY_TRACK_MODIFICATIONS''] = False
db = SQLAlchemy(app)
db 对象是 SQLAlchemy 类的实例,表示应用使用的数据库,通过它可获得 Flask-SQLAlchemy提供的所有功能。
《基于Python的Web应用开发实战(第二版)》

6、使用Flask-SQLAlchemy管理数据库和数据库的迁移
使用Flask-SQLAlchemy管理数据库
在视图函数中操作数据库
使用Flask-Migrate实现数据库的迁移
1、安装Flask-SQLAlchemy
2、hello.py配置数据库
from flask_script import Manager
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
manager = Manager(app)
app.config[''SQLALCHEMY_DATABASE_URI''] = ''sqlite:///data.sqlite''
app.config[''SQLALCHEMY_TRACK_MODIFICATIONS''] = True
db = SQLAlchemy(app)
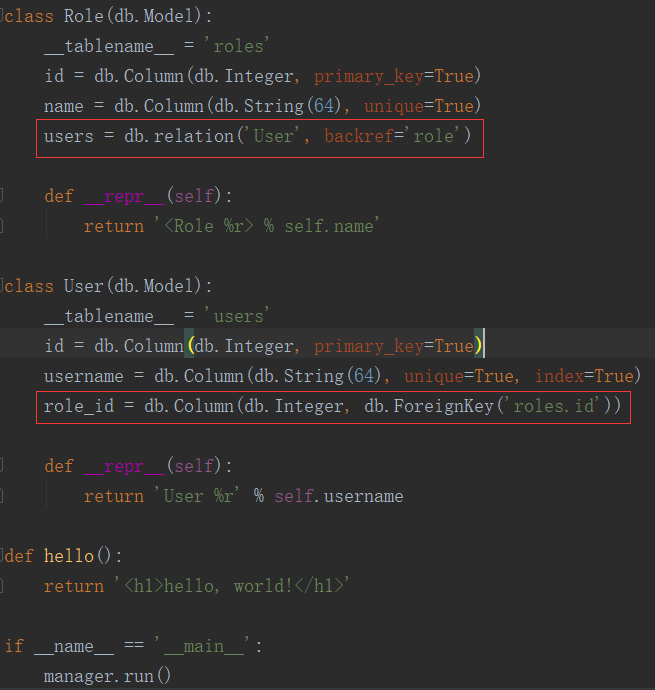
3、hello.py 定义Role和User模型
类变量__tablename__定义在数据库中使用的表名。如果没有定义,Flask-SQLAlchemy会使用一个默认的名字,但默认的表名没有遵守使用复数形式进行命名的约定,最好由我们自己指定表名。其余变量都是该模型的属性,被定义为db.Cloumn类的实例
#定义数据库模型
class Role(db.Model):
__tablename__ = ''roles''
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return ''<Role %r>'' %self.name
class User(db.Model):
__tablename__ = ''users''
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return ''User %r'' %self.username
4、关系
users = db.relation(''User'', backref=''role'')
添加到Role模型中的users属性代表这个关系的面向对象视角。对于一个Role类的实例,其users属性将返回与角色相关联的用户组成的列表。
db.relationship()第一个参数表明这个关系的另一端是哪个模型(类)。如果模型类尚未定义,可使用字符串形式指定。
db.relationship()第二个参数backref,将向User类中添加一个role属性,从而定义反向关系。这一属性可替代role_id访问Role模型,此时获取的是模型对象,而不是外键的值。
role_id = db.Column(db.Integer, db.ForeignKey(''roles.id''))
这句话是说,User类中添加了一个role_id变量,数据类型db.Integer,第二个参数指定外键是哪个表中哪个id
当表之间的关系是一对一的关系时,可添加userlist参数
db.Relationship(''User'',backref=''role'',uselist=False)
5、在shell中创建数据库
在shell中激活虚拟环境,运行python hello.py shell
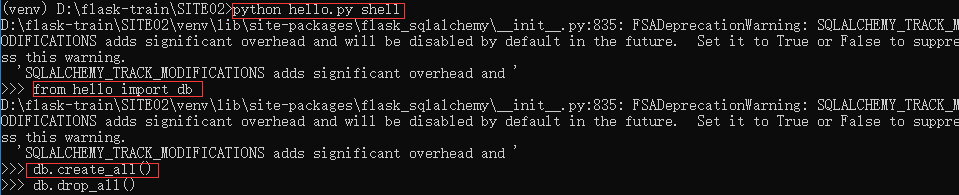
我们要让 Flask-SQLAlchemy 根据模型类创建数据库。方法是使用 db.create_all()函数,执行完后,目录下会多一个data.sqlite的文件
6、生成data.sqlite文件后,在pycharm中需下载相应包进行支持,否则数据库不能用
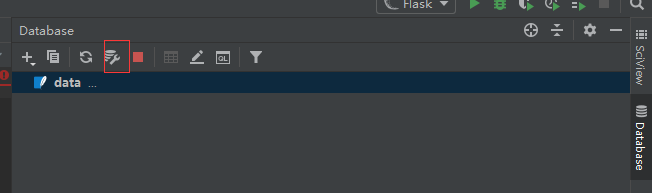
如果没有下载相应文件,红框处会有下载提示,点击下载即可
6、插入行
创建一些角色和用户
from hello import Role, User
admin_role = Role(name=''Admin'')
mod_role = Role(name=''Moderator'')
user_role = Role(name=''User'')
user_john = User(username=''john'', role=admin_role)
user_susan = User(username=''susan'', role=user_role)
user_david = User(username=''david'', role=user_role)
此时新建对象的id属性并没有明确设定,因为主键是由 Flask-SQLAlchemy 管理的,现在这些对象只存在于python中,还未写入数据库,因此id未赋值
在 Flask-SQLAlchemy 中,会话由 db.session表示。准备把对象写入数据库之前,先要将其添加到会话中
db.session.add(admin_role)
db.session.add(mod_role)
db.session.add(user_role)
db.session.add(user_john)
db.session.add(user_susan)
db.session.add(user_david)
也可简写为:
db.session.add_all([admin_role, mod_role, user_role,... user_john, user_susan, user_david])
提交到会话
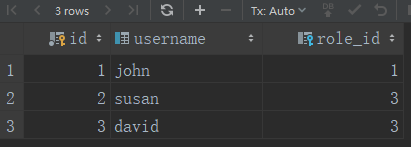
db.session.commit()roles表 users表
SELECT * FROM roles SELECT * FROM users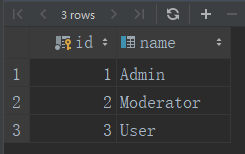
说明:
users表中的用户拥有唯一的角色,在users表中定义role_id并设置属性为外键,在roles表中给users表添加role属性,该属性可以替代users表中的role_id访问roles模型
user_john = User(username=''john'', role=admin_role) 可以看到可以通过role属性,访问了roles表中的id,并通过设置的关系,自动关联users表中role_id 和roles表中的id列
7、修改行
admin_role.name = ''Administrator''
db.session.add(admin_role)
db.session.commit()roles表状态
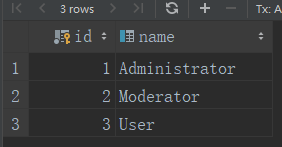
8、删除行
db.session.delete(mod_role)
db.session.commit()roles表状态
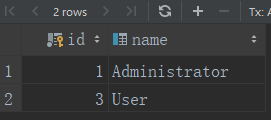
9、查询行
Flask-SQLAlchemy为每个模型类都提供了query对象,最基本的模型查询对象是取回对应表中的所有记录:

使用过滤器可以配置query对象进行更精确的数据库查询,下面是查找角色为“User”的所有用户

若要查看SQLAlchemy为查询生成的原生SQL查询语句,只需把query对象转换成字符串:

退出shell后,重新打开一个shell会话,就要从数据库中读取行,再重新创建python对象,下面是发起一个查询,加载名为“User”的用户角色

filter_by()等过滤器在query对象上调用,返回一个更精确的query对象。多个过滤器可以一起调用,知道获取结果
在视图函数中操作数据库
1、修改hello.py中的index方法
@app.route(''/'', methods=[''GET'', ''POST''])
def index():
form = NameForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.name.data).first()
if user is None:
user = User(username = form.name.data)
db.session.add(user)
session[''known''] = False
else:
session[''known''] = True
session[''name''] = form.name.data
form.name.data = ''''
return redirect(url_for(''index''))
return render_template(''index.html'', form = form, name = session.get(''name''), known = session.get(''known'', False))提交表单后,程序会使用filter_by()查询过滤器在数据库中查找提交的名字。变量known被写入用户会话中,因此重定向后,可以把数据传给模板,用来显示自定义的欢迎消息。
2、修改templates/index.html
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf%}
{% block title %}Flasky{% endblock %}
{% block page_content %}
<div class="page-header">
<h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}</h1>
{% if not known %}
<p>Pleased to meet you!</p>
{% else %}
<p>Happy to see you again!</p>
{% endif %}
</div>
{{ wtf.quick_form(form)}}
{% endblock %}
3、集成python shell
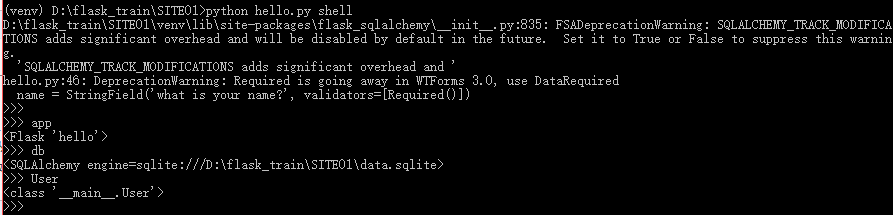
每次启动shell都要导入数据库实例和模型,为避免重复,下面命令可让Flask-Script的shell命令自动导入特点的对象
from flask_script import Manager,Shell
#为shell命令添加一个上下文
def make_shell_context():
return dict(app=app, db=db, User=User, Role=Role)
manager.add_command("shell", Shell(make_context=make_shell_context))在次启动时,自动导入了模型
使用Flask-Migrate实现数据库的迁移
1、安装Flask-Migrate
2、在hello.py中配置Flask-Migrate
from flask_migrate import Migrate, MigrateCommand
app = Flask(__name__)
app.config[''SQLALCHEMY_DATABASE_URI''] = ''sqlite:///data.sqlite''
app.config[''SQLALCHEMY_COMMIT_ON_TEARDOWN''] = True
app.config["SECRET_KEY"] = "123456"
bootstrap = Bootstrap(app)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
manager = Manager(app)
manager.add_command(''db'', MigrateCommand)
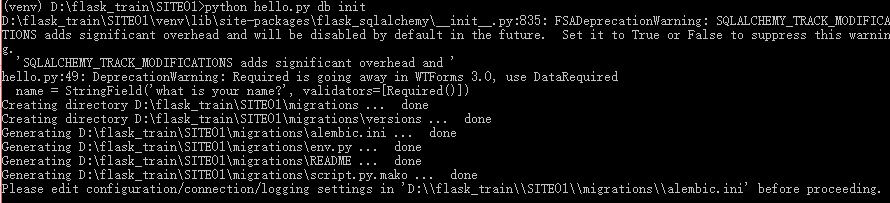
3、在迁移前,使用init子命令创建迁移仓库
python hello.py db init
该命令会创建migrations文件夹,所有迁移脚本都会存放其中
执行完之后的目录结构

4、创建迁移脚本
在Alembic中,数据库迁移用迁移脚本表示,有两个函数:
upgrade() 把迁移中的改动应用到数据库中
downgrad() 将改动删除
数据库可以重设到修改历史的任意一点
迁移操作分为:
手动迁移,只是一个骨架,uograde()和downgrade()函数都是空的,开发者要使用Alembic提供的Operations对象指令实现具体操作
自动迁移,会根据模型定义和数据库当前状态之间的差异生成upgrade()和downgrade()函数的内容
migrate子命令用来自动创建迁移脚本:
python hello.py db migrate -m "initial migration"

5、更新数据库
检查并修正好迁移脚本后,可以使用 db upgrade 命令将迁移应用到数据库中:
python hello.py db uograde

生成需求文件
pip freeze >requirements.txt


在新的虚拟环境中创建完整副本
pip install -r requirements.txt

Flask 中使用 Flask-SQLAlchemy 查询数据库在数据库内容更新时无法实时返回
Flask 中使用 Flask-SQLAlchemy 查询数据库在数据库内容更新时无法实时返回 Flask-SQLAlchemy 版本 :2.3.2
"""python
from flask.ext.sqlalchemy import SQLAlchemy
class UnlockedAlchemy(SQLAlchemy):
def apply_driver_hacks(self, app, info, options):
if "isolation_level" not in options:
options["isolation_level"] = "READ COMMITTED"
return super(UnlockedAlchemy, self).apply_driver_hacks(app, info, options)
# db = SQLAlchemy() # 源码中options没有isolation_level设置项, 弃用
db = UnlockedAlchemy()
"""
关于配置Flask-SQLAlchemy以使用Flask-Restless的多个数据库的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于23. Flask 操作Mysql数据库 - flask-sqlalchemy扩展、5.5 使用Flask-SQLAlchemy管理数据库、6、使用Flask-SQLAlchemy管理数据库和数据库的迁移、Flask 中使用 Flask-SQLAlchemy 查询数据库在数据库内容更新时无法实时返回的相关知识,请在本站寻找。
本文标签:




