想了解为什么唯一约束会删除与cassandra一起使用的Janusgraph中的现有数据?的新动态吗?本文将为您提供详细的信息,此外,我们还将为您介绍关于360数科实践:JanusGraph到Nebu
想了解为什么唯一约束会删除与 cassandra 一起使用的 Janusgraph 中的现有数据?的新动态吗?本文将为您提供详细的信息,此外,我们还将为您介绍关于360 数科实践:JanusGraph 到 NebulaGraph 迁移、android.graphics.Canvas中的drawPosText(),什么是起源?、Cannot start Cassandra db using bin/cassandra、Cassandra--JAVA访问Cassandra数据的新知识。
本文目录一览:- 为什么唯一约束会删除与 cassandra 一起使用的 Janusgraph 中的现有数据?
- 360 数科实践:JanusGraph 到 NebulaGraph 迁移
- android.graphics.Canvas中的drawPosText(),什么是起源?
- Cannot start Cassandra db using bin/cassandra
- Cassandra--JAVA访问Cassandra数据

为什么唯一约束会删除与 cassandra 一起使用的 Janusgraph 中的现有数据?
如何解决为什么唯一约束会删除与 cassandra 一起使用的 Janusgraph 中的现有数据??
如文档中所述,我已向我的数据库添加了唯一约束。 假设我已经运行了以下
#__next {
display: flex;
flex-direction: column;
min-height: 100vh;
}
我收到了顶点 ID。
但是当我再次添加一个顶点如下
g.V().has(''name'',"myname")
results Unique constraint Failed error ,这是好的和需要的。 但是当我再次尝试以下操作时,我没有得到顶点 ID。唯一约束也会删除原始数据。
g.addV("myvertex").has("name","myname")
我使用的是 cassandra 4.0 和 janusgraph 6.0
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

360 数科实践:JanusGraph 到 NebulaGraph 迁移
摘要:在本文中 360 数科的周鹏详细讲解了业务从 JanusGraph 迁移到 Nebula Graph 带来的性能提升,在机器资源不到之前 JanusGraph 配置三分之一的情况下,业务性能提升至少 20 倍。

本文作者系 360 数科开发工程师:周鹏
迁移背景
我们之前图数据用的是单机版的 AgensGraph, 后面因为单机带来的性能限制问题,迁移到了分布式数据库 JanusGraph,详细的迁移信息可以看我之前的一篇文章《百亿级图数据 JanusGraph 迁移之旅》。但是随着数据量和业务调用量的增加,新的问题又出现了 —— 单次查询的耗时很高个别业务场景已经到了 10s,数据量稍微多点,逻辑复杂点的查询耗时也在 2~3s 左右,这严重影响了整个业务流程的性能和相关业务的发展。
JanusGraph 的架构决定了单次耗时高,核心的原因在于它的存储依赖外部,自身不能很好地控制外部存储,我们生产环境用的便是 HBase 集群,这导致所有的查询没法下推到存储层进行处理,只能把数据从 HBase 查询到 JanusGraph Server 内存再做相应的过滤。
举个例子,查询一层关联关系年龄大于 50 岁的用户,如果一层关联有 1,000 人,年龄大于 50 岁的只有 2 个人。介于 JanusGraph 查询请求发送到 HBase 时做不了一层关联顶点属性的过滤,我们不得不通过并发请求去查询 HBase 获取这 1,000 人的顶点属性,再在 JanusGraph Server 的内存做过滤,最后返回给客户端满足条件的 2 个用户。
这样做的问题就是磁盘 IO、网络 IO 浪费很大,而且查询返回的大多数据在而后查的查询并未用到。我们生产环境用的 HBase 为 19 台高配 SSD 服务器的,具体的网络 IO、磁盘 IO 使用情况如下图:
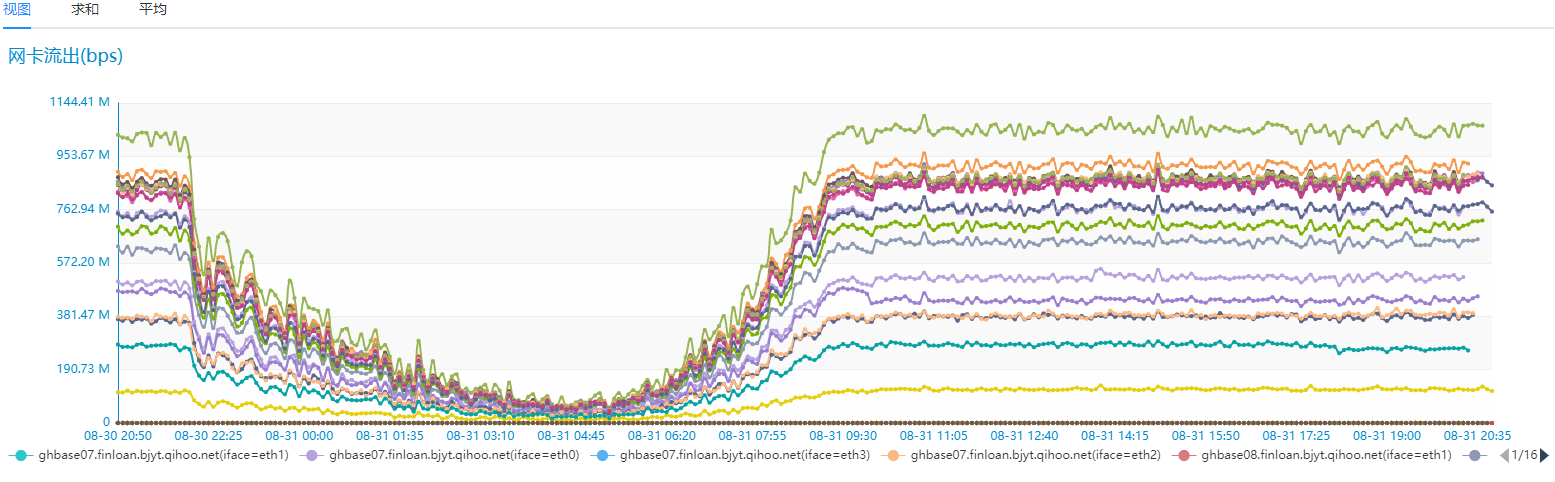
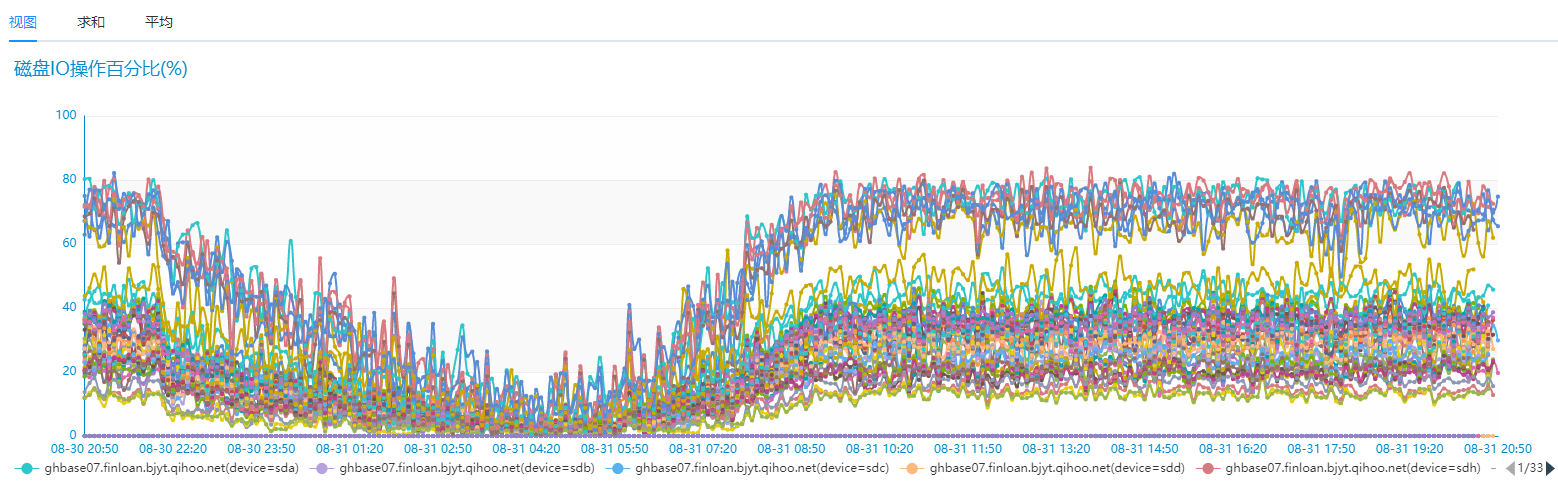
我们对比相同的业务场景,但是只有 6 台相同配置的 SSD 服务器 Nebua Graph 的磁盘 IO 和网络 IO 情况如下:
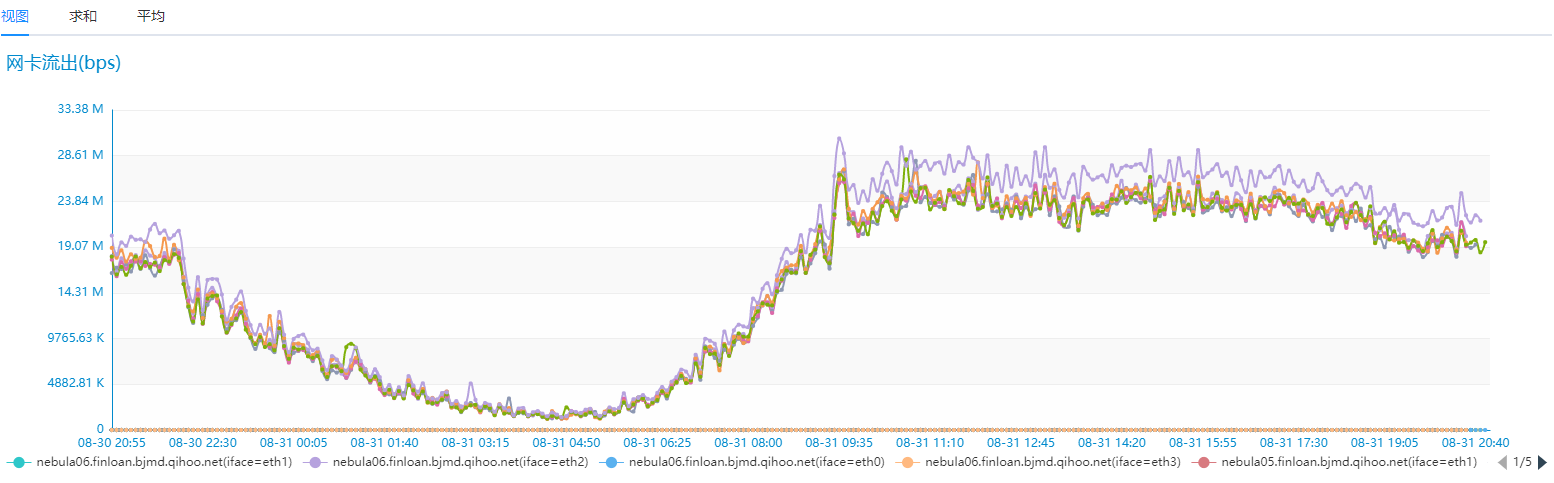
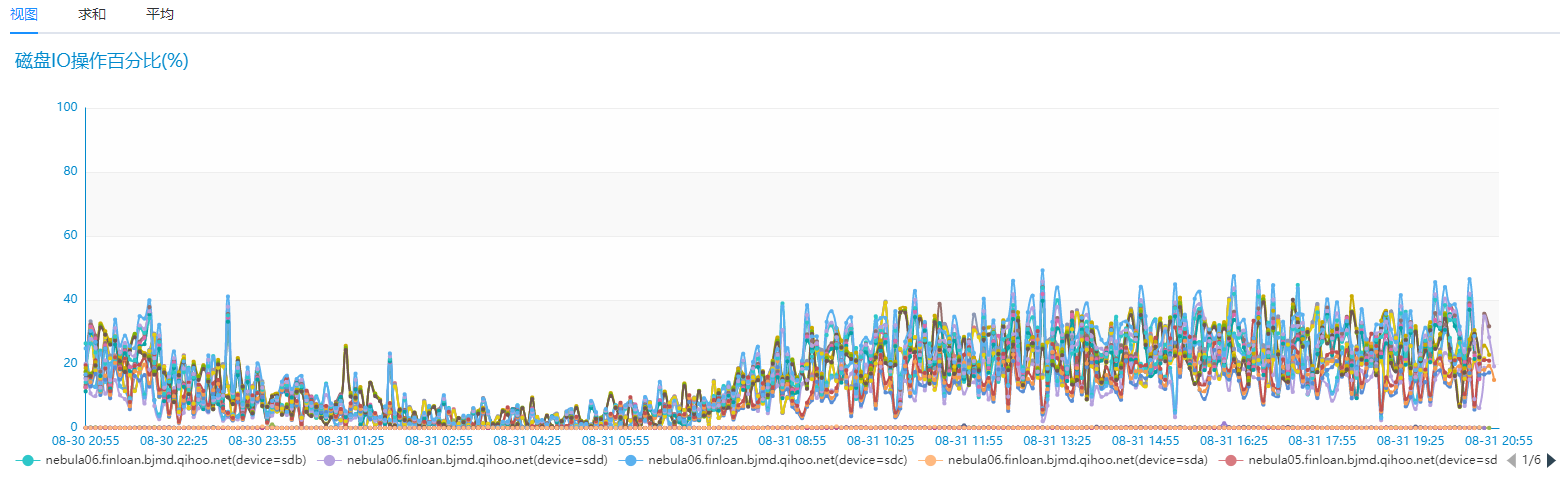
Nebula Graph 性能确实优秀太多,而且是在机器资源只有之前 Hbase 集群 30% 的情况下。我们再来看下业务场景下的耗时情况,之前业务场景中查询耗时需要 2~3s 情况的在 Nebula Graph 这边 100ms 左右返回了,之前需要 10~20s 情况的业务场景现在也基本在 2s 就能返回,并且平均耗时也基本在 500ms 左右就能搞定,性能提升至少 20 倍以上 :)
就冲上面的这些数据,如果你还在用 JanusGraph,就应该立马把这篇文章转发给你的领导,并立个项开始迁移到 Nebua Graph
历史数据迁移
数据迁移这块,因为我们的数据量比较大,20 亿左右的顶点,200 亿左右的边,好在 Nebula Graph 提供 Spark 导入工具 ——Spark Writer,整个数据导入过程还算比较流畅。这里有个可分享经验,当时使用 Spark 导入工具采用异步方式导入导致了不少 error,稍微改下导入方式换成同步写入就没问题了。另外一个经验是关于 Spark 的,如果导入的数据量比较大,对应的 partitions 需要设置大一点,我们就设置过 8w 个 patitions。如果你设置的 partitions 比较小,单个 partition 的数据量便会比较大,容易导致 Spark 任务 OOM Fail。
查询调优
我们现在生产环境 Nebula Graph 用的是 1.0 的版本,生产环境上 ID 生产我们用的是 hash 函数, uuid 导入数据会很慢,后面官方也不会再支持 uuid。
在我们的生产环境主要参数调优配置如下,主要是 nebula-storage 需要调优
# The default reserved bytes for one batch operation
--rocksdb_batch_size=4096
# The default block cache size used in BlockBasedTable.
# The unit is MB. 我们生产服务器内存为128G
--rocksdb_block_cache=44024
############## rocksdb Options ##############
--rocksdb_disable_wal=true
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={"max_subcompactions":"3","max_background_jobs":"3"}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"disable_auto_compactions":"false","write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"8192"}
--max_handlers_per_req=10
--heartbeat_interval_secs=10
# 新添加参数
--raft_rpc_timeout_ms=5000
--raft_heartbeat_interval_secs=10
--wal_ttl=14400
--max_batch_size=512
# 参数配置减小内存使用
--enable_partitioned_index_filter=true
--max_edge_returned_per_vertex=10000
Linux 机器的调优主要就是把服务的 swap 关闭掉,开启后会因为磁盘 IO 影响查询性能。另外关于 minor compact 和 major compact 调优,我们生产环境是开启 minor compact 关闭 major compact。关闭 major compact 主要是因为这个操作很占磁盘 IO,并且很难通过线程数(--rocksdb_db_options={"max_subcompactions":"3","max_background_jobs":"3"})控制,后续 Nebula Graph 官方有计划优化这块。
最后,来重点提下 max_edge_returned_per_vertex 这个参数,能想到这个参数 Nebula Graph 不愧是图数据行业的老司机 —— 我们之前的图查询一直受到超级节点的困扰,线上环境如果查询遇到这种关联几百万数据的超级节点能直接把 JanusGraph 的 HBase 集群查崩掉(我们生产环境出现过几次)。之前在查询 JanusGraph 的 Gremlin 语句上加各种 limit 限制都没能很好的解决这个问题,在 Nebula Graph 有了这个 max_edge_returned_per_vertex 参数,数据在最底层存储层直接做了过滤,生产环境就不会再有这种超级节点的困扰,就这一点就应该给 NebulaGraph 一个 FIVE STAR !
本文首发于 Nebula Graph 论坛,阅读本文的你有任何疑问,欢迎前往论坛和作者进行讨论,原帖传送门:https://discuss.nebula-graph.com.cn/t/topic/1172
,什么是起源?")
android.graphics.Canvas中的drawPosText(),什么是起源?
drawPosText(char[] text, int index,
int count, float[] pos, Paint paint)
Draw the text in the array, with each
character’s origin specified by the
pos array.
有没有人知道drawPosText究竟在哪里考虑“原点”,因为你将“origin”指定为坐标对;即,它是字符的左下角,中心,是什么?
另外drawPosText在绘制时如何计算字符高度?
解决方法:
啊,我昨天花了一大块时间玩一些文字!
如果您处于左对齐状态,则文本原点位于左下角.如果您处于中心对齐位置,则文本将水平居中,原点位于底部中心.
您可以使用获得文本的高度
Math.abs(p.ascent())p.descent()
其中p是你的油漆.

Cannot start Cassandra db using bin/cassandra
|
13
down vote
favorite
1
|
I have Ubuntu 12.04 with cassandra 1.1.3 (tarball installation), When I try to start cassandra, I get the following: According to cassandra documentation, the output does not look as expected: So, what is the problem?
cassandra
|
||||||||||||
| |
|

2 Answers
|
up vote
16
down vote
|
The problem may be caused by using OpenJDK, as described in a Cassandra bug report but, see the comments here for occurrences of this issue on Sun/Oracle and other JVMs:
If you cannot install the Oracle JVM, then try changing the stack size in theconf/cassandra-env.shconfiguration script. Look for the following section, at around line 185, and change the-Xss180kto a higher value. I have used 280k successfully when testing installations on Ubuntu servers at Rackspace and Amazon. Based on reports in the comments below, I would either suggest increasing the stack size in 20k increments, starting with-Xss200k, until Cassandra starts properly. Note that it is also possible to remove this option and use the default stack size per thread, but be aware of the impact this will have on memory consumption.
|
||||||||||||||
| |
|
|
up vote
1
down vote
|
This is most likely caused by attempting to run under OpenJDK 1.6, which causes a segmentation fault under Ubuntu/Debian. The seg fault is hidden because of the way the shell script executes the process. You can test for this problem by modifying $CASSANDRA_HOME/bin/cassandra as follows: Change this line: to this: Then runbin/cassandra -fand copy the resulting java command. Run this directly to see if it produces the segmentation fault. If this is your problem, you need to switch to the Sun or IBM JDK, or alternatively you can upgrade to OpenJDK 1.7.
|
||||||
| |
|

Cassandra--JAVA访问Cassandra数据
JAVA创建Cluster对象
cluster = Cluster.builder()
.addContactPoints(contactPoints)
.withRetryPolicy(new LoggingRetryPolicy(DefaultRetryPolicy.INSTANCE))
.withSocketOptions(new SocketOptions().setKeepAlive(true).setReadTimeoutMillis(10000))
.withAuthProvider(new PlainTextAuthProvider(cassandraUser, cassandraPwd))
.withTimestampGenerator(new AtomicMonotonicTimestampGenerator())
.withPoolingOptions(new PoolingOptions().setMaxConnectionsPerHost(HostDistance.LOCAL, 4))
.build();
相关知识点:
针对数据库操作失败,Cassandra提供四种重试策略:
1、DefaultRetryPolicy,没有查询到数据,或者写入时超时的情况下进行重新查询
2、DowngradingConsistencyRetryPolicy,与DefaultRetryPolicy一样,不同点是考虑了最终数据一致性问题
3、FallthroughRetryPolicy,不重试查询,但允许客户端业务逻辑实现重试
4、LoggingRetryPolicy,不重试查询,用来记录日志信息,info级别
针对数据节点连接失败,Casssandra提供两种重连策略:
1、ConstantReconnectionPolicy,固定时间间隔进行重连
2、ExponentialReconnectionPolicy,指数级别增加重连时间,但不会超过最大重连时间
在创建Cluster时,无需将所有Cassandra节点信息录入到ContactPoints列表中,Cassandra驱动会自动从录入节点获取所有群集节点数据。
今天关于为什么唯一约束会删除与 cassandra 一起使用的 Janusgraph 中的现有数据?的讲解已经结束,谢谢您的阅读,如果想了解更多关于360 数科实践:JanusGraph 到 NebulaGraph 迁移、android.graphics.Canvas中的drawPosText(),什么是起源?、Cannot start Cassandra db using bin/cassandra、Cassandra--JAVA访问Cassandra数据的相关知识,请在本站搜索。
本文标签:




