如果您对使用Logstash将数据从Elasticsearch导出到CSV感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于使用Logstash将数据从Elasticsearc
如果您对使用Logstash将数据从Elasticsearch导出到CSV感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于使用Logstash将数据从Elasticsearch导出到CSV的详细内容,我们还将为您解答logstash 导出csv的相关问题,并且为您提供关于CSV & Lgstash & Elasticsearch、docker 使用elasticsearch+logstash、Elasticsearch - logstash 插件、Elasticsearch - Logstash实现mysql同步数据到elasticsearch的有价值信息。
本文目录一览:- 使用Logstash将数据从Elasticsearch导出到CSV(logstash 导出csv)
- CSV & Lgstash & Elasticsearch
- docker 使用elasticsearch+logstash
- Elasticsearch - logstash 插件
- Elasticsearch - Logstash实现mysql同步数据到elasticsearch
")
使用Logstash将数据从Elasticsearch导出到CSV(logstash 导出csv)
如何使用Logstash将数据从Elasticsearch导出到CSV?我只需要包括特定的列。
答案1
小编典典安装2个插件:elasticsearch输入插件和csv输出插件。然后创建一个配置文件。这是这种情况的一个很好的例子。
您现在就可以开始了,只需运行:bin/logstash -f /path/to/logstash-es-to-csv-example.conf
并检查中export.csv指定的文件output -> csv -> path。

CSV & Lgstash & Elasticsearch
如何解决CSV & Lgstash & Elasticsearch?
我需要帮助!
我是 Elasticsearch 的新手……我刚刚从 kaggle 导入了 CSV 格式的数据,并通过指定配置文件通过 logstash 将它们集成到 elasticsearch 中,但是在 elasticsearch 上我的数据不再可读(它是这种格式: u0000E\u0000l) 我是否需要向配置文件添加任何转换?
谢谢。
解决方法
我试过: codec => plain { charset=> "UTF-8" } 和 ruby { code => ''event.set("decoded",Base64.decode64(event.get("message")))''但是没有用 这就是我得到的:{ "host" => "HIND",“ID”=>“\ u0000G \ u0000u \ u0000e \ u0000s \ u0000t \ u0000s \ u0000的\ u0000c \ u0000a \ u0000n \ u0000的\ u0000r \ u0000e \ u0000l \ u0000a \ u0000x \ u0000的\ u0000i \ u0000n \ u0000的\ u0000t \ u0000h \ u0000e \ u0000的\ u0000g \ u0000a \ u0000r \ u0000d \ u0000e \ u0000n \ u0000的\ u0000a \ u0000t \ u0000的\ u0000t \ u0000h \ u0000e \ u0000的\ u0000p \ u0000r \ u0000o \ u0000p \ u0000e \ u0000r \ u0000t \ u0000y \ u0000的.\u0000",“消息”=>“\ u0000G \ u0000u \ u0000e \ u0000s \ u0000t \ u0000s \ u0000的\ u0000c \ u0000a \ u0000n \ u0000的\ u0000r \ u0000e \ u0000l \ u0000a \ u0000x \ u0000的\ u0000i \ u0000n \ u0000的\ u0000t \ u0000h \ u0000e \ u0000的\ u0000g \ u0000a \ u0000r \ u0000d \ u0000e \ u0000n \ u0000的\ u0000a \ u0000t \ u0000的\ u0000t \ u0000h \ u0000e \ u0000的\ u0000p \ u0000r \ u0000o \ u0000p \ u0000e \ u0000r \ u0000t \ u0000y \ u0000的.\u0000","解码" => "\x1A\xE7\xAC\xB6\xC7\x1A\x9E\xB7\xA5k\x18\xA7\xB6\x17\xA0j\xB7^\x9D\xABm\x85\xEAk\xA2\x97\ xAB\xB7","路径" => "C:/elastic_stack/data/hotelsb_df_es.csv","@version" => "1",“@timestamp” => 2021-08-04T18:04:46.170Z }

docker 使用elasticsearch+logstash
1.1部署elasticsearch:6.5.4
docker pull elasticsearch:6.5.4 docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.5.4
http://localhost:9200/
1.2添加elasticsearch-head
docker pull mobz/elasticsearch-head:5 docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5 docker start elasticsearch-head
docker exec -it elasticsearch /bin/bash vi config/elasticsearch.yml
在最下面添加2行
http.cors.enabled: true http.cors.allow-origin: "*"
2.1部署logstash:6.5.4
docker pull logstash:6.5.4
2.2映射配置文件
mkdir -p /usr/local/src/docker_logstash
mkdir -p /usr/local/src/docker_logstash/logs
touch logstash.yml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.url: http://sandBox:9200
vi log4j2.properties
logger.elasticsearchoutput.name = logstash.outputs.elasticsearch
logger.elasticsearchoutput.level = debug
vi pipelines.yml
- pipeline.id: my-logstash
path.config: "/usr/share/logstash/config/*.conf"
pipeline.workers: 3
vi *.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4567
}
}
output {
elasticsearch {
action => "index"
hosts => "sandBox:9200"
index => "index"
}
}
docker run -d -p 5044:5044 -p 9600:9600 -it --name logstash -v /usr/local/src/docker_logstash:/usr/share/logstash/config logstash:6.5.4
docker exec -it logstash /bin/bash
bin/logstash -e 'input { stdin { } } output { stdout {} }'
2.3 MysqL --> elasticsearch
vi MysqL.conf
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:MysqL://sandBox:3306/erp_test4"
jdbc_user => "root"
jdbc_password => "123456"
jdbc_driver_library => "/usr/share/logstash/config/mysql-connector-java-5.1.27.jar"
jdbc_driver_class => "com.MysqL.jdbc.Driver"
statement => "SELECT * FROM nrd2_project"
type => "project"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => "sandBox:9200"
index => "project"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
bin/logstash -f config/MysqL.conf

Elasticsearch - logstash 插件
Logstash

简介: Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到"储存库" 数据的收集,处理和储存。
- Logstash 是 Elastic Stack 的中央数据流引擎,用于收集、丰富和统一所有数据,不管格式或模式
1、下载与使用
官网下载地址 下载和你elasticsearch一致的版本
(链接:https://pan.baidu.com/s/1sucD1jATrZ3ONptT6a90QQ 提取码:dlwa)
- 解压
-
使用
- 这个不用安装,主要通过
logstash将数据集导elasticsearch
- 这个不用安装,主要通过
-
1、在 bin 目录下创建 logstash.conf,写入
input { stdin{ } } output { stdout{ } }

-
2、启动
- 切换到 logstash/bin 目录下
logstash -f logstash.conf

- 3、访问http://localhost:9600/

2、输入、过滤器和输出
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
输入
采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持 各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器
实时解析和转换数据
官网过滤器插件

数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,更轻松、更快速地分析和实现商业价值。
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
输出
选择储存库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。

Elasticsearch - Logstash实现mysql同步数据到elasticsearch
有的时候,我们在做查询时,由于查询条件的多样、变化多端(比如根据时间查、根据名称模糊查、根据id查等等),或者查询的数据来自很多不同的库表或者系统,这时就很难以一个较快的速度(几百毫秒)去从关系型数据库中直接获取我们想要的数据。
针对上面的情况,可以考虑使用elasticsearch来进行数据的汇总,然后提供给后台进行搜索,可以大大提高检索的效率。
数据在存储在关系型数据库(如mysql)中,我们怎样将这部分数据转移到elasticsearch中。这篇文章将介绍一个同步神器:logstash-input-jdbc
安装
- 在官网下载最新的安装包:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz解压并转移目录:
tar zxvf logstash-6.2.4.tar.gz mv ./logstash-6.2.4 /usr/local/logstash
配置
- 安装插件
由于这里是从mysql同步数据到elasticsearch,所以需要安装jdbc的入插件和elasticsearch的出插件:logstash-input-jdbc、logstash-output-elasticsearch
安装效果图如下所示:
- 下载mysql连接库
由于logstash是ruby开发的,所以这里要下载mysql的连接库jar包,从官网下载,我这里下载的是:mysql-connector-java-5.1.46.jar
将下载好的mysql-connector-java-5.1.46.jar,放至/usr/local/logstash/config/目录下。- 修改配置文件
在config目录下,创建配置文件(logstash-mysql-es.conf):这里有几个注意点:input { jdbc { # mysql相关jdbc配置 jdbc_connection_string => "jdbc:mysql://10.112.76.30:3306/jack_test?useUnicode=true&characterEncoding=utf-8&useSSL=false" jdbc_user => "root" jdbc_password => "123456" # jdbc连接mysql驱动的文件目录,可去官网下载:https://dev.mysql.com/downloads/connector/j/ jdbc_driver_library => "./config/mysql-connector-java-5.1.46.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => true jdbc_page_size => "50000" jdbc_default_timezone =>"Asia/Shanghai" # mysql文件, 也可以直接写SQL语句在此处,如下: # statement => "select * from t_order where update_time >= :sql_last_value;" statement_filepath => "./config/jdbc.sql" # 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年) schedule => "* * * * *" #type => "jdbc" # 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中 #record_last_run => true # 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值. use_column_value => true # 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键 tracking_column => "update_time" tracking_column_type => "timestamp" last_run_metadata_path => "./logstash_capital_bill_last_id" # 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录 clean_run => false #是否将 字段(column) 名称转小写 lowercase_column_names => false } } output { elasticsearch { hosts => "10.112.76.31:9200" index => "mysql_order" document_id => "%{id}" template_overwrite => true } # 这里输出调试,正式运行时可以注释掉 stdout { codec => json_lines } }
(1)jdbc_driver_library
mysql-connector-java-5.1.46.jar的存放目录,这个一定要配置正确,支持全路径和相对路径。如果配置不对,将会报“can ”错误。
(2)sql_last_value
标志目前logstash同步的位置信息(类似offset)。比如id、updatetime。logstash通过这个标志,可以判断目前同步到哪一条数据。
(3)statement、statement_filepath
statement:执行同步的sql语句,可以同步部分数据。
statement_filepath:存储执行同步的sql语句。不和statement同时使用。
(4)schedule
定时器,表示每隔多长时间同步一次数据。格式类似crontab。
(5)tracking_column、tracking_column_type
tracking_column:表示表中哪一列用于判断logstash同步的位置信息。与sql_last_value比较判断是否需要同步这条数据。
tracking_column_type:racking_column指定列的类型。支持两种类型:numeric(默认)、timestamp。注意:如果列是时间字段(比如updateTime),一定要指定这个类型为timestamp。我就踩了这个大坑。。。一直同步不成功!!!
(6)last_run_metadata_path
存储sql_last_value值的文件名称及位置。
(7)document_id
生成elasticsearch的文档值,尽量使用同步的数据中已有的唯一标识。比如同步订单数据,可以使用订单号。


启动
在根目录下,执行命令:
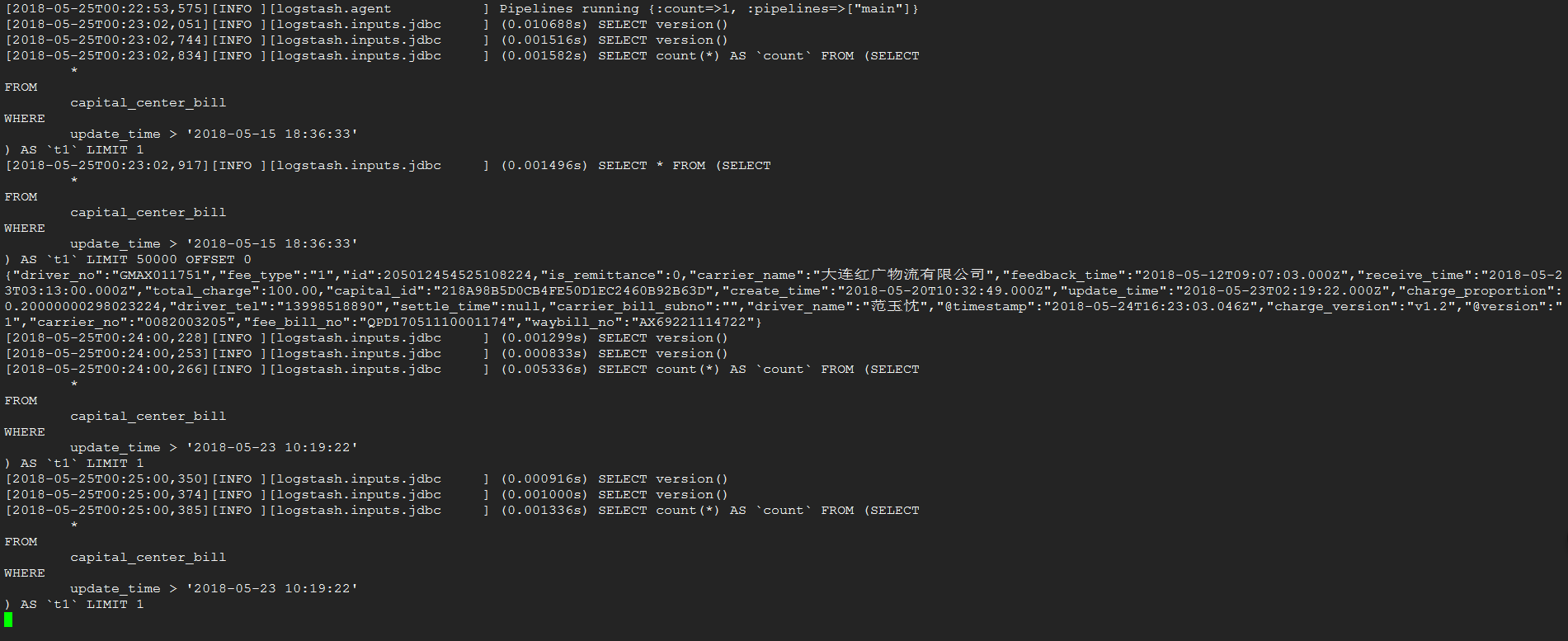
nohup bin/logstash -f config/logstash-mysql-es.conf > logs/logstash.out &效果图如下:
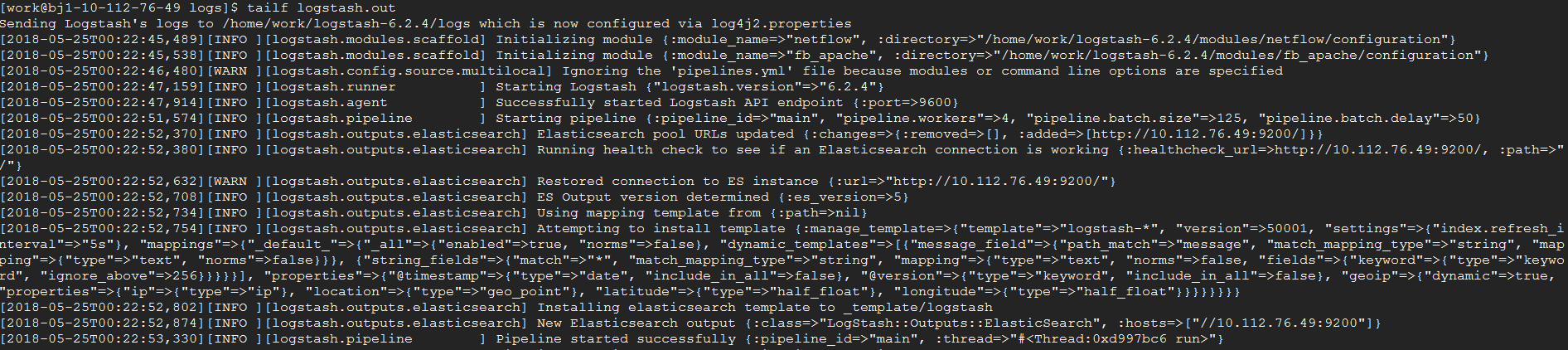
同步
完成了一条数据的同步
我们今天的关于使用Logstash将数据从Elasticsearch导出到CSV和logstash 导出csv的分享就到这里,谢谢您的阅读,如果想了解更多关于CSV & Lgstash & Elasticsearch、docker 使用elasticsearch+logstash、Elasticsearch - logstash 插件、Elasticsearch - Logstash实现mysql同步数据到elasticsearch的相关信息,可以在本站进行搜索。
本文标签:




