在本文中,我们将给您介绍关于如何阻止Python的csv.DictWriter.writerows在Windows中的行之间添加空行?的详细内容,并且为您解答python阻止换行的相关问题,此外,我们
在本文中,我们将给您介绍关于如何阻止Python的csv.DictWriter.writerows在Windows中的行之间添加空行?的详细内容,并且为您解答python阻止换行的相关问题,此外,我们还将为您提供关于CSDN博客频道支持Windows Live Writer离线写博客 – test by Windows Live Writer、csv 文件读写 (函数 reader、writer;类 DictReader、DictWriter)、CSVWriter生成文件时writer.writeRecord();方法保存的文件末尾多一个空行、csv:writer.writerows()分割我的字符串输入的知识。
本文目录一览:- 如何阻止Python的csv.DictWriter.writerows在Windows中的行之间添加空行?(python阻止换行)
- CSDN博客频道支持Windows Live Writer离线写博客 – test by Windows Live Writer
- csv 文件读写 (函数 reader、writer;类 DictReader、DictWriter)
- CSVWriter生成文件时writer.writeRecord();方法保存的文件末尾多一个空行
- csv:writer.writerows()分割我的字符串输入
")
如何阻止Python的csv.DictWriter.writerows在Windows中的行之间添加空行?(python阻止换行)
当我csv.DictWriter.writerows在Windows上使用Python时,在行之间添加空换行符。如何停止呢?该代码在Linux上运行良好。

CSDN博客频道支持Windows Live Writer离线写博客 – test by Windows Live Writer
各位尊敬的CSDN用户:
你们好!
为了更好的服务于用户,CSDN博客频道已经支持Windows Live Writer离线写博客啦。Windows Live Writer于2014年5月29日正式上线啦!欢迎大家抢先体验!
有了WLW ,现在您可以随时随地撰写博客,不用登录即可编辑和发表博客啦。WLW 可以直接打开任何之前已经发布的日志,修改并重新发布,确保您在脱机时所作的修改与您发布的内容同步。
以下是安装WLW 和相关设置:
1、 下载安装WLW (步骤略,可自行下载),添加日志账户,如图所示:

2、下一步,您所使用的日志类型,选择MetaweblogAPI

3、 日志的远程发布网址,填写http://write.blog.csdn.net/xmlrpc/index

4、 点击下一步,出现下面这个对话框时,选择“是”或“否”都可以,选择“是”时,会下载失败,可忽略。

5、 设置完成

6、 可以编辑内容,进行,点击发布

7、 点击发布后,如想看发布结果,可勾选“发布后在浏览器中打开日志”

各位用户如对此功能有任何疑问或意见,欢迎私信soledadzz反馈 。
感谢大家对CSDN博客的支持!
CSDN博客产品研发团队
2014-05-29
")
csv 文件读写 (函数 reader、writer;类 DictReader、DictWriter)
;方法保存的文件末尾多一个空行")
CSVWriter生成文件时writer.writeRecord();方法保存的文件末尾多一个空行
一.问题,CSVWriter生成文件时使用writer.writeRecord();方法保存的文件末尾多一个空行,效果图如下:
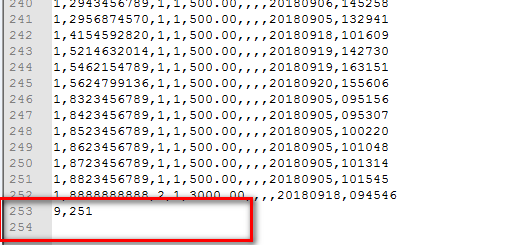
目标结果:(去掉末尾空行)
二.关键代码如下(修改前代码):
1 /**
2 * 生成CSV文件
3 * @param filePath 文件保存路径,例如:D:/temp/test.csv
4 * @param headerBeans 实体对象集合
5 * @param detailBeans 实体对象集合
6 * @param trailerBeans 实体对象集合
7 * @param <T>
8 */
9 public static <T> void createFile(String filePath, List<T> headerBeans, List<T> detailBeans, List<T> trailerBeans) {
10 CsvWriter writer = null;
11 try {
12 // 创建文件对象
13 File file = createFile(filePath);
14 // 生成文件
15 writer = new CsvWriter(filePath, '','', Charset.forName("GBK"));
16 // 获取内容
17 List<String[]> contents = new ArrayList<>();
18 List<String[]> headerContents = getStringArrayFromBean(headerBeans);
19 List<String[]> detailContents = getStringArrayFromBean(detailBeans);
20 List<String[]> trailerContents = getStringArrayFromBean(trailerBeans);
21 contents.addAll(headerContents);
22 contents.addAll(detailContents);
23 contents.addAll(trailerContents);
24 // 写入内容
25 for (String[] each : contents) {
26 writer.writeRecord(each);
27 }
28 } catch (Exception e) {
29 LOGGER.error("生成CSV文件失败", e);
30 } finally {
31 if (writer != null) {
32 writer.close();
33 }
34 }
35 }输出文件就在第26行,writer.writeRecord(each);点进去跳到import com.csvreader.CsvWriter;这个包中,如下截图(序号为程序执行调用顺序):
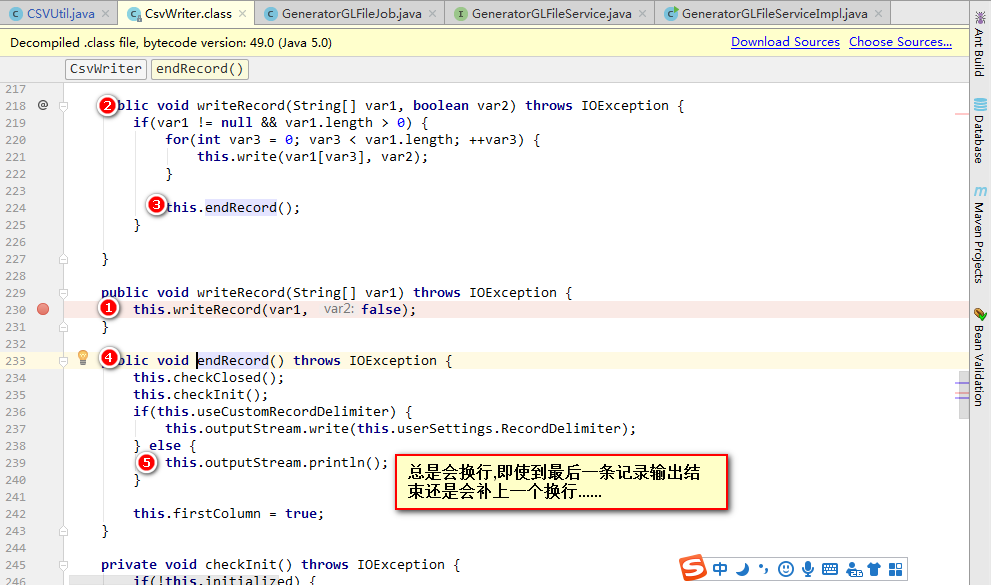
可以看到执行到endRecord()方法时,总是会执行else中的内容,因为useCustomRecordDeliniter定义的为false...(就是这导致了末尾多一空行)
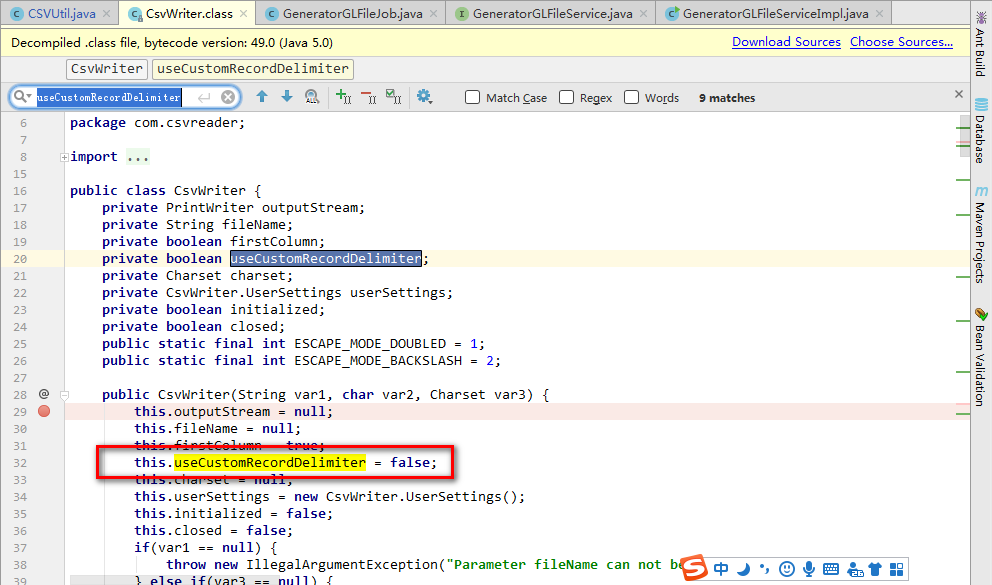
三.解决问题:
.class文件又不能改, 在这里是换了一种写法 ( 由原来的CSVWriter的writeRecord() 改为用PrintWriter的pw.write() )
1 /**
2 * 生成CSV文件
3 * @param filePath 文件保存路径,例如:D:/temp/test.csv
4 * @param headerBeans 实体对象集合
5 * @param detailBeans 实体对象集合
6 * @param trailerBeans 实体对象集合
7 * @param <T>
8 */
9 public static <T> void createFile(String filePath, List<T> headerBeans, List<T> detailBeans, List<T> trailerBeans) {
10 CsvWriter writer = null;
11 try {
12 // 创建文件对象
13 File file = createFile(filePath);
14 // 生成文件
15 writer = new CsvWriter(filePath, '','', Charset.forName("GBK"));
16 // 获取内容
17 List<String[]> contents = new ArrayList<>();
18 List<String[]> headerContents = getStringArrayFromBean(headerBeans);
19 List<String[]> detailContents = getStringArrayFromBean(detailBeans);
20 List<String[]> trailerContents = getStringArrayFromBean(trailerBeans);
21 contents.addAll(headerContents);
22 contents.addAll(detailContents);
23 contents.addAll(trailerContents);
24 // 重组内容
25 String result = "";
26 for (String[] each : contents) {
27 for (String s : each){
28 writer.writeRecord(each);
29 result += s ;
30 result += ",";
31 }
32 result = result.substring(0,result.length()-1);
33 result += "\r\n";
34 }
35 result = result.substring(0,result.length()-2);
36
37 writeFileContent(filePath,result);//写入
38 } catch (Exception e) {
39 LOGGER.error("生成CSV文件失败", e);
40 } finally {
41 if (writer != null) {
42 writer.close();
43 }
44 }
45 }调用的writeFileContent()方法如下:
/**
* 向文件中写入内容
*
* @param filepath 文件路径与名称
* @param newstr 写入的内容
* @return
* @throws IOException
*/
public static boolean writeFileContent(String filepath, String newstr) throws IOException {
Boolean bool = false;
String temp = "";
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
FileOutputStream fos = null;
PrintWriter pw = null;
try {
/* File file = new File(filepath);*///文件路径(包括文件名称)
//将文件读入输入流
fis = new FileInputStream(filepath);
isr = new InputStreamReader(fis);
br = new BufferedReader(isr);
// StringBuffer buffer = new StringBuffer();
// //文件原有内容
// for (int i = 0; (temp = br.readLine()) != null; i++) {
// buffer.append(temp);
// // 行与行之间的分隔符 相当于“\n”
// buffer = buffer.append(System.getProperty("line.separator"));
// }
// buffer.append(newstr);
fos = new FileOutputStream(filepath);
pw = new PrintWriter(fos);
pw.write(newstr.toCharArray());
pw.flush();
bool = true;
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
throw e;
} finally {
//不要忘记关闭
if (pw != null) {
pw.close();
}
if (fos != null) {
fos.close();
}
if (br != null) {
br.close();
}
if (isr != null) {
isr.close();
}
if (fis != null) {
fis.close();
}
}
return bool;
}
贴上完整的新utils留个备份:


1 package com.sp.ppms.console.finance.CSV;
2
3 import java.io.*;
4 import java.lang.reflect.Field;
5 import java.lang.reflect.Method;
6 import java.nio.charset.Charset;
7 import java.util.ArrayList;
8 import java.util.Collections;
9 import java.util.HashMap;
10 import java.util.List;
11 import java.util.Map;
12 import java.util.Map.Entry;
13 import org.apache.commons.lang3.StringUtils;
14 import org.apache.log4j.Logger;
15 import org.springframework.util.ReflectionUtils;
16 import com.csvreader.CsvReader;
17 import com.csvreader.CsvWriter;
18
19 /**
20 * CSV工具类
21 */
22 public class CSVUtil {
23 /**
24 * 日志对象
25 **/
26 private static final Logger LOGGER = Logger.getLogger(CSVUtil.class);
27
28 /**
29 * 生成CSV文件
30 * @param filePath 文件保存路径,例如:D:/temp/test.csv
31 * @param headerBeans 实体对象集合
32 * @param detailBeans 实体对象集合
33 * @param trailerBeans 实体对象集合
34 * @param <T>
35 */
36 public static <T> void createFile(String filePath, List<T> headerBeans, List<T> detailBeans, List<T> trailerBeans) {
37 CsvWriter writer = null;
38 try {
39 // 创建文件对象
40 File file = createFile(filePath);
41 // 生成文件
42 writer = new CsvWriter(filePath, '','', Charset.forName("GBK"));
43 // 获取内容
44 List<String[]> contents = new ArrayList<>();
45 List<String[]> headerContents = getStringArrayFromBean(headerBeans);
46 List<String[]> detailContents = getStringArrayFromBean(detailBeans);
47 List<String[]> trailerContents = getStringArrayFromBean(trailerBeans);
48 contents.addAll(headerContents);
49 contents.addAll(detailContents);
50 contents.addAll(trailerContents);
51 // 重组内容
52 String result = "";
53 for (String[] each : contents) {
54 for (String s : each){
55 result += s ;
56 result += ",";
57 }
58 result = result.substring(0,result.length()-1);
59 result += "\r\n";
60 }
61 result = result.substring(0,result.length()-2);
62
63 writeFileContent(filePath,result);//写入
64 } catch (Exception e) {
65 LOGGER.error("生成CSV文件失败", e);
66 } finally {
67 if (writer != null) {
68 writer.close();
69 }
70 }
71 }
72
73 /**
74 * 向文件中写入内容
75 *
76 * @param filepath 文件路径与名称
77 * @param newstr 写入的内容
78 * @return
79 * @throws IOException
80 */
81 public static boolean writeFileContent(String filepath, String newstr) throws IOException {
82 Boolean bool = false;
83 String temp = "";
84 FileInputStream fis = null;
85 InputStreamReader isr = null;
86 BufferedReader br = null;
87 FileOutputStream fos = null;
88 PrintWriter pw = null;
89 try {
90 /* File file = new File(filepath);*///文件路径(包括文件名称)
91 //将文件读入输入流
92 fis = new FileInputStream(filepath);
93 isr = new InputStreamReader(fis);
94 br = new BufferedReader(isr);
95
96 // StringBuffer buffer = new StringBuffer();
97 // //文件原有内容
98 // for (int i = 0; (temp = br.readLine()) != null; i++) {
99 // buffer.append(temp);
100 // // 行与行之间的分隔符 相当于“\n”
101 // buffer = buffer.append(System.getProperty("line.separator"));
102 // }
103 // buffer.append(newstr);
104
105 fos = new FileOutputStream(filepath);
106 pw = new PrintWriter(fos);
107 pw.write(newstr.toCharArray());
108 pw.flush();
109 bool = true;
110 } catch (Exception e) {
111 // TODO: handle exception
112 e.printStackTrace();
113 throw e;
114 } finally {
115 //不要忘记关闭
116 if (pw != null) {
117 pw.close();
118 }
119 if (fos != null) {
120 fos.close();
121 }
122 if (br != null) {
123 br.close();
124 }
125 if (isr != null) {
126 isr.close();
127 }
128 if (fis != null) {
129 fis.close();
130 }
131 }
132 return bool;
133 }
134
135 /**
136 * 读取CSV文件内容
137 *
138 * @param filePath 文件存放的路径,如:D:/csv/xxx.csv
139 * @param bean 类类型
140 * @return List<T>
141 */
142 public static <T> List<T> readFile(String filePath, Class<T> bean) {
143 List<String[]> dataList = new ArrayList<String[]>();
144 CsvReader reader = null;
145 try {
146 // 创建CSV读对象 例如:CsvReader(文件路径,分隔符,编码格式);
147 reader = new CsvReader(filePath, '','', Charset.forName("GBK"));
148 if (reader != null) {
149 // 跳过表头,如果需要表头的话,这句可以忽略
150 //reader.readHeaders();
151 // 逐行读入除表头的数据
152 while (reader.readRecord()) {
153 dataList.add(reader.getValues());
154 }
155 if (!dataList.isEmpty()) {
156 // 数组转对象
157 return getBeanFromStringArray(dataList, bean);
158 }
159 }
160 } catch (Exception e) {
161 LOGGER.error("读取CSV文件失败", e);
162 } finally {
163 if (reader != null) {
164 reader.close();
165 }
166 }
167 return Collections.emptyList();
168 }
169
170 /**
171 * 删除该目录下所有文件
172 *
173 * @param filePath 文件目录路径,如:d:/test
174 */
175 public static boolean deleteFiles(String filePath) {
176 File file = new File(filePath);
177 if (file.exists()) {
178 File[] files = file.listFiles();
179 if (files != null && files.length > 0) {
180 for (File f : files) {
181 if (f.isFile() && f.delete()) {
182 LOGGER.info("删除" + f.getName() + "文件成功");
183 }
184 }
185 return true;
186 }
187 }
188 return false;
189 }
190
191 /**
192 * 删除单个文件
193 *
194 * @param filePath 文件目录路径,如:d:/test
195 * @param fileName 文件名称,如:110.csv
196 */
197 public static boolean deleteFile(String filePath, String fileName) {
198 File file = new File(filePath);
199 if (file.exists()) {
200 File[] files = file.listFiles();
201 if (files != null && files.length > 0) {
202 for (File f : files) {
203 if (f.isFile() && f.getName().equals(fileName)) {
204 return f.delete();
205 }
206 }
207 }
208 }
209 return false;
210 }
211
212 /**
213 * 泛型实体转换为数组
214 *
215 * @param beans
216 * @return List<String[]>
217 */
218 private static <T> List<String[]> getStringArrayFromBean(List<T> beans) {
219 List<String[]> result = new ArrayList<String[]>();
220 Class<? extends Object> cls = beans.get(0).getClass();
221 Field[] declaredFields = cls.getDeclaredFields();
222 List<Field> annoFields = new ArrayList<Field>();
223 // 筛选出标有注解的字段
224 for (Field field : declaredFields) {
225 CSVField anno = field.getAnnotation(CSVField.class);
226 if (anno != null) {
227 annoFields.add(field);
228 }
229 }
230 // 获取注解的值,即内容标题
231 String[] title = new String[annoFields.size()];
232 /*for (int i = 0; i < annoFields.size(); i++) {
233 title[i] = annoFields.get(i).getAnnotation(CSVField.class).name();
234 }
235 result.add(title);*/
236 try {
237 // 获取内容
238 for (T t : beans) {
239 String[] item = new String[annoFields.size()];
240 int index = 0;
241 for (Field field : annoFields) {
242 String fieldName = field.getName();
243 String methodName = "get" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1);
244 Method method = ReflectionUtils.findMethod(t.getClass(), methodName);
245 if (method != null) {
246 Object value = ReflectionUtils.invokeMethod(method, t);
247 if (value == null) {
248 item[index] = "";
249 } else {
250 item[index] = value.toString();
251 }
252 }
253 index++;
254 }
255 result.add(item);
256 }
257 } catch (Exception e) {
258 LOGGER.info("实体对象转数组失败", e);
259 }
260 return result;
261 }
262
263 /**
264 * 数组转为对象集合
265 *
266 * @param dataList
267 * @param bean
268 * @return List<T>
269 */
270 private static <T> List<T> getBeanFromStringArray(List<String[]> dataList, Class<T> bean) {
271 List<T> list = new ArrayList<>();
272 List<Map<String, String>> titles = getTitles(dataList);
273 Map<String, Field> fields = getFields(bean);
274 try {
275 for (Map<String, String> map : titles) {
276 T t = bean.newInstance();
277 for (Entry<String, String> entry : map.entrySet()) {
278 if (fields.containsKey(entry.getKey())) {
279 Field field = fields.get(entry.getKey());
280 Class<?> valType = field.getType();
281 String fieldName = field.getName();
282 String methodName = "set" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1);
283 Method method = ReflectionUtils.findMethod(bean, methodName, valType);
284 if (method != null) {
285 ReflectionUtils.invokeMethod(method, t, entry.getValue());
286 }
287 }
288 }
289 list.add(t);
290 }
291 } catch (Exception e) {
292 LOGGER.error("创建实体失败", e);
293 }
294 return list;
295 }
296
297 /**
298 * 数组标题与值的对应关系
299 *
300 * @param dataList
301 * @return
302 */
303 private static <T> List<Map<String, String>> getTitles(List<String[]> dataList) {
304 List<Map<String, String>> list = new ArrayList<>();
305 String[] titles = dataList.get(0);
306 dataList.remove(0);
307 for (String[] values : dataList) {
308 Map<String, String> titleMap = new HashMap<>();
309 for (int i = 0; i < values.length; i++) {
310 titleMap.put(titles[i], values[i]);
311 }
312 list.add(titleMap);
313 }
314 return list;
315 }
316
317 /**
318 * 注解名称与字段属性的对应关系
319 *
320 * @param clazz 实体对象类类型
321 * @param <T> 泛型类型
322 * @return Map<String , Field>
323 */
324 private static <T> Map<String, Field> getFields(Class<T> clazz) {
325 Map<String, Field> annoMap = new HashMap<>();
326 Field[] fileds = clazz.getDeclaredFields();
327 for (Field filed : fileds) {
328 CSVField anno = filed.getAnnotation(CSVField.class);
329 if (anno != null) {
330 // 获取name属性值
331 if (StringUtils.isNotBlank(anno.name())) {
332 annoMap.put(anno.name(), filed);
333 }
334 }
335 }
336 return annoMap;
337 }
338
339 /**
340 * 创建文件对象
341 *
342 * @param filePath 文件路径,例如:temp/test.csv
343 * @return File
344 */
345 private static File createFile(String filePath) {
346 File file = null;
347 try {
348 // 创建文件目录
349 file = new File(filePath.substring(0, filePath.lastIndexOf(''/'')));
350 if (!file.exists()) {
351 file.mkdirs();
352 }
353 // 创建文件对象
354 file = new File(filePath);
355 if (!file.exists() && file.createNewFile()) {
356 LOGGER.info("创建文件对象成功");
357 }
358 } catch (IOException e) {
359 LOGGER.error("创建文件对象失败", e);
360 }
361 return file;
362
363 }
364 }废弃utils:


1 package com.sp.ppms.console.finance.CSV;
2
3 import java.io.File;
4 import java.io.IOException;
5 import java.lang.reflect.Field;
6 import java.lang.reflect.Method;
7 import java.nio.charset.Charset;
8 import java.util.ArrayList;
9 import java.util.Collections;
10 import java.util.HashMap;
11 import java.util.List;
12 import java.util.Map;
13 import java.util.Map.Entry;
14 import org.apache.commons.lang3.StringUtils;
15 import org.apache.log4j.Logger;
16 import org.springframework.util.ReflectionUtils;
17 import com.csvreader.CsvReader;
18 import com.csvreader.CsvWriter;
19
20 /**
21 * CSV工具类
22 */
23 public class CSVUtil {
24 /**
25 * 日志对象
26 **/
27 private static final Logger LOGGER = Logger.getLogger(CSVUtil.class);
28
29 /**
30 * 生成CSV文件
31 * @param filePath 文件保存路径,例如:D:/temp/test.csv
32 * @param headerBeans 实体对象集合
33 * @param detailBeans 实体对象集合
34 * @param trailerBeans 实体对象集合
35 * @param <T>
36 */
37 public static <T> void createFile(String filePath, List<T> headerBeans, List<T> detailBeans, List<T> trailerBeans) {
38 CsvWriter writer = null;
39 try {
40 // 创建文件对象
41 File file = createFile(filePath);
42 // 生成文件
43 writer = new CsvWriter(filePath, '','', Charset.forName("GBK"));
44 // 获取内容
45 List<String[]> contents = new ArrayList<>();
46 List<String[]> headerContents = getStringArrayFromBean(headerBeans);
47 List<String[]> detailContents = getStringArrayFromBean(detailBeans);
48 List<String[]> trailerContents = getStringArrayFromBean(trailerBeans);
49 contents.addAll(headerContents);
50 contents.addAll(detailContents);
51 contents.addAll(trailerContents);
52 // 写入内容
53 for (String[] each : contents) {
54 writer.writeRecord(each);
55 }
56 } catch (Exception e) {
57 LOGGER.error("生成CSV文件失败", e);
58 } finally {
59 if (writer != null) {
60 writer.close();
61 }
62 }
63 }
64
65 /**
66 * 读取CSV文件内容
67 *
68 * @param filePath 文件存放的路径,如:D:/csv/xxx.csv
69 * @param bean 类类型
70 * @return List<T>
71 */
72 public static <T> List<T> readFile(String filePath, Class<T> bean) {
73 List<String[]> dataList = new ArrayList<String[]>();
74 CsvReader reader = null;
75 try {
76 // 创建CSV读对象 例如:CsvReader(文件路径,分隔符,编码格式);
77 reader = new CsvReader(filePath, '','', Charset.forName("GBK"));
78 if (reader != null) {
79 // 跳过表头,如果需要表头的话,这句可以忽略
80 //reader.readHeaders();
81 // 逐行读入除表头的数据
82 while (reader.readRecord()) {
83 dataList.add(reader.getValues());
84 }
85 if (!dataList.isEmpty()) {
86 // 数组转对象
87 return getBeanFromStringArray(dataList, bean);
88 }
89 }
90 } catch (Exception e) {
91 LOGGER.error("读取CSV文件失败", e);
92 } finally {
93 if (reader != null) {
94 reader.close();
95 }
96 }
97 return Collections.emptyList();
98 }
99
100 /**
101 * 删除该目录下所有文件
102 *
103 * @param filePath 文件目录路径,如:d:/test
104 */
105 public static boolean deleteFiles(String filePath) {
106 File file = new File(filePath);
107 if (file.exists()) {
108 File[] files = file.listFiles();
109 if (files != null && files.length > 0) {
110 for (File f : files) {
111 if (f.isFile() && f.delete()) {
112 LOGGER.info("删除" + f.getName() + "文件成功");
113 }
114 }
115 return true;
116 }
117 }
118 return false;
119 }
120
121 /**
122 * 删除单个文件
123 *
124 * @param filePath 文件目录路径,如:d:/test
125 * @param fileName 文件名称,如:110.csv
126 */
127 public static boolean deleteFile(String filePath, String fileName) {
128 File file = new File(filePath);
129 if (file.exists()) {
130 File[] files = file.listFiles();
131 if (files != null && files.length > 0) {
132 for (File f : files) {
133 if (f.isFile() && f.getName().equals(fileName)) {
134 return f.delete();
135 }
136 }
137 }
138 }
139 return false;
140 }
141
142 /**
143 * 泛型实体转换为数组
144 *
145 * @param beans
146 * @return List<String[]>
147 */
148 private static <T> List<String[]> getStringArrayFromBean(List<T> beans) {
149 List<String[]> result = new ArrayList<String[]>();
150 Class<? extends Object> cls = beans.get(0).getClass();
151 Field[] declaredFields = cls.getDeclaredFields();
152 List<Field> annoFields = new ArrayList<Field>();
153 // 筛选出标有注解的字段
154 for (Field field : declaredFields) {
155 CSVField anno = field.getAnnotation(CSVField.class);
156 if (anno != null) {
157 annoFields.add(field);
158 }
159 }
160 // 获取注解的值,即内容标题
161 String[] title = new String[annoFields.size()];
162 /*for (int i = 0; i < annoFields.size(); i++) {
163 title[i] = annoFields.get(i).getAnnotation(CSVField.class).name();
164 }
165 result.add(title);*/
166 try {
167 // 获取内容
168 for (T t : beans) {
169 String[] item = new String[annoFields.size()];
170 int index = 0;
171 for (Field field : annoFields) {
172 String fieldName = field.getName();
173 String methodName = "get" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1);
174 Method method = ReflectionUtils.findMethod(t.getClass(), methodName);
175 if (method != null) {
176 Object value = ReflectionUtils.invokeMethod(method, t);
177 if (value == null) {
178 item[index] = "";
179 } else {
180 item[index] = value.toString();
181 }
182 }
183 index++;
184 }
185 result.add(item);
186 }
187 } catch (Exception e) {
188 LOGGER.info("实体对象转数组失败", e);
189 }
190 return result;
191 }
192
193 /**
194 * 数组转为对象集合
195 *
196 * @param dataList
197 * @param bean
198 * @return List<T>
199 */
200 private static <T> List<T> getBeanFromStringArray(List<String[]> dataList, Class<T> bean) {
201 List<T> list = new ArrayList<>();
202 List<Map<String, String>> titles = getTitles(dataList);
203 Map<String, Field> fields = getFields(bean);
204 try {
205 for (Map<String, String> map : titles) {
206 T t = bean.newInstance();
207 for (Entry<String, String> entry : map.entrySet()) {
208 if (fields.containsKey(entry.getKey())) {
209 Field field = fields.get(entry.getKey());
210 Class<?> valType = field.getType();
211 String fieldName = field.getName();
212 String methodName = "set" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1);
213 Method method = ReflectionUtils.findMethod(bean, methodName, valType);
214 if (method != null) {
215 ReflectionUtils.invokeMethod(method, t, entry.getValue());
216 }
217 }
218 }
219 list.add(t);
220 }
221 } catch (Exception e) {
222 LOGGER.error("创建实体失败", e);
223 }
224 return list;
225 }
226
227 /**
228 * 数组标题与值的对应关系
229 *
230 * @param dataList
231 * @return
232 */
233 private static <T> List<Map<String, String>> getTitles(List<String[]> dataList) {
234 List<Map<String, String>> list = new ArrayList<>();
235 String[] titles = dataList.get(0);
236 dataList.remove(0);
237 for (String[] values : dataList) {
238 Map<String, String> titleMap = new HashMap<>();
239 for (int i = 0; i < values.length; i++) {
240 titleMap.put(titles[i], values[i]);
241 }
242 list.add(titleMap);
243 }
244 return list;
245 }
246
247 /**
248 * 注解名称与字段属性的对应关系
249 *
250 * @param clazz 实体对象类类型
251 * @param <T> 泛型类型
252 * @return Map<String , Field>
253 */
254 private static <T> Map<String, Field> getFields(Class<T> clazz) {
255 Map<String, Field> annoMap = new HashMap<>();
256 Field[] fileds = clazz.getDeclaredFields();
257 for (Field filed : fileds) {
258 CSVField anno = filed.getAnnotation(CSVField.class);
259 if (anno != null) {
260 // 获取name属性值
261 if (StringUtils.isNotBlank(anno.name())) {
262 annoMap.put(anno.name(), filed);
263 }
264 }
265 }
266 return annoMap;
267 }
268
269 /**
270 * 创建文件对象
271 *
272 * @param filePath 文件路径,例如:temp/test.csv
273 * @return File
274 */
275 private static File createFile(String filePath) {
276 File file = null;
277 try {
278 // 创建文件目录
279 file = new File(filePath.substring(0, filePath.lastIndexOf(''/'')));
280 if (!file.exists()) {
281 file.mkdirs();
282 }
283 // 创建文件对象
284 file = new File(filePath);
285 if (!file.exists() && file.createNewFile()) {
286 LOGGER.info("创建文件对象成功");
287 }
288 } catch (IOException e) {
289 LOGGER.error("创建文件对象失败", e);
290 }
291 return file;
292
293 }
294 }
另:
严格讲\n是换行,\r是回车。但不同的系统、不同的应用可能做不同的处理。在文本文件中,换行是两者的组合"\r\n"。
感谢:https://bbs.csdn.net/topics/40116687.
https://jingyan.baidu.com/article/0aa223754f1fc288cd0d6479.html
拓展:https://blog.csdn.net/pfm685757/article/details/47806469#commentBox
分割我的字符串输入")
csv:writer.writerows()分割我的字符串输入
我有一个要写入csv文件的字符串列表。列表list_results看起来像
[''False, 60, 40 '', ''True, 70, 30, '']所以,我会尝试这样的事情:
with open(''example1.csv'', ''w'') as result: writer = csv.writer(result, delimiter=",") writer.writerow( (''Correct?'', ''Successes'', ''Failures'') ) writer.writerows(list_results)不幸的是,数据没有写入三列。我发现:
[''Correct?'', ''Successes'', ''Failures''] [''F'', ''a'', ''l'', ''s'', ''e'', '','', '' '', ''6'', ''0'', '','', '' '', ''4'', ''0'', '' ''] [''T'', ''r'', ''u'', ''e'', '','', '' '', ''7'', ''0'', '','', '' '', ''3'', ''0'', '','', '' '']如何正确格式化此行为以获得
[''Correct?'', ''Successes'', ''Failures''] [''False'', 60, 40] [''True'', 70, 30]最好采用格式%s %d %d?
答案1
小编典典您正在使用writer.writerows()与s结尾。该方法需要一个 lists列表
,但是您传入了一个字符串列表。该writerows()方法实质上是这样做的:
def writerows(self, rows): for row in rows: self.writerow(row)其中每一行必须是一列列。字符串是单个字符的序列,因此这就是您所写的:单个字符由您选择的定界符分隔。
您需要将字符串分成几列,不要自己包括逗号,writer对象的工作是包括以下内容:
with open(''example1.csv'', ''w'') as result: writer = csv.writer(result, delimiter=",") writer.writerow((''Correct?'', ''Successes'', ''Failures'')) for row in list_results: columns = [c.strip() for c in row.strip('', '').split('','')] writer.writerow(columns)或使用生成器表达式,以便您可以继续使用writerows():
with open(''example1.csv'', ''w'') as result: writer = csv.writer(result, delimiter=",") writer.writerow((''Correct?'', ''Successes'', ''Failures'')) writer.writerows([c.strip() for c in r.strip('', '').split('','')] for r in list_results)演示:
>>> import csv>>> list_results = [''False, 60, 40 '', ''True, 70, 30, '']>>> import csv>>> import sys>>> list_results = [''False, 60, 40 '', ''True, 70, 30, '']>>> writer = csv.writer(sys.stdout)>>> writer.writerow((''Correct?'', ''Successes'', ''Failures''))Correct?,Successes,Failures>>> for row in list_results:... columns = [c.strip() for c in row.strip('', '').split('','')]... writer.writerow(columns)...False,60,40True,70,30>>> writer.writerows([c.strip() for c in r.strip('', '').split('','')]... for r in list_results)False,60,40True,70,30今天关于如何阻止Python的csv.DictWriter.writerows在Windows中的行之间添加空行?和python阻止换行的讲解已经结束,谢谢您的阅读,如果想了解更多关于CSDN博客频道支持Windows Live Writer离线写博客 – test by Windows Live Writer、csv 文件读写 (函数 reader、writer;类 DictReader、DictWriter)、CSVWriter生成文件时writer.writeRecord();方法保存的文件末尾多一个空行、csv:writer.writerows()分割我的字符串输入的相关知识,请在本站搜索。
本文标签:




