在本文中,我们将为您详细介绍horizontalcenterandverticalmiddleinCSS的相关知识,此外,我们还会提供一些关于Accesscontextofdatasourceandw
在本文中,我们将为您详细介绍horizontal center and vertical middle in CSS的相关知识,此外,我们还会提供一些关于Access context of data source and work center view do not match、Android Widget.AppCompat.ProgressBar.Horizontal 和 Widget.Material.ProgressBar.Horizontal 有什么区别?、ARP Poisoning Attack and Mitigation Techniques ARP欺骗 中间人攻击 Man-In-The-Middle (MITM) attack 嗅...、Center-based 3D Object Detection and Tracking的有用信息。
本文目录一览:- horizontal center and vertical middle in CSS
- Access context of data source and work center view do not match
- Android Widget.AppCompat.ProgressBar.Horizontal 和 Widget.Material.ProgressBar.Horizontal 有什么区别?
- ARP Poisoning Attack and Mitigation Techniques ARP欺骗 中间人攻击 Man-In-The-Middle (MITM) attack 嗅...
- Center-based 3D Object Detection and Tracking

horizontal center and vertical middle in CSS
写在前面的话:
1: 为了方便起见,接下来我都会把想要居中的元素,不管是一行text,还是一个div,都叫做‘目标元素’, 把包含这个目标元素的叫做‘父元素’。(额。。。。这两个名字如此不对称,我也是醉了。)
2: 我会给一个元素设置一个同名的class和id,class用了写一些实际上跟居中没有关系的css,只是为了好看;id呢用来写跟居中有关的css,免得混淆了。
Case 1: 最简单的单行的行内元素(inline element)
HTML Code:
<div id=''child''child''>
<span>aaaaa</span>
</div>CSS Code:
.child {
height: 100px;
width: 100px;
background-color: #F7F00E;
}
#child {
line-height: 100px;
text-align: center;
}
垂直居中:只需要给父元素(#child)设置‘等值’的height和line-height.
水平居中:当然就是text-align: center 就行了
Case 2: 一个div在另一个div里面居中
HTML code:
<div id=''child''child''>
<div>Apple</div>
</div>CSS code:
#child {
line-height: 100px;
text-align: center;
}case 2和case 1一样,对于垂直居中来说,只需要设置等值的line-height和height就可以了。达到的效果是:

Case 3: 多个div元素在父div元素中垂直水平居中
HTML code:
<div id=''child''child''>
<div>Apple</div>
<div>Orange</div>
</div>CSS code:
#child {
line-height: 100px;
text-align: center;
}这时候,我们往#child里面添加了一个div元素,如果我们保持我们之前的#child的css代码不变,这时候呈现的效果是:

因为我们给父元素#child设置了100px的line-height,而line-height是可以继承的,所以它里面的每一个div元素都通过继承拥有了100px的line-height。这个时候还想依赖于line-height来实现垂直居中,显然就不行了。对于这种情况,有多种解决方案:
1: table-cell +vertical-align
HTML code:
<div id=''child''child''>
<div>Apple</div>
<div>Orange</div>
</div>CSS code:
#child {
display: table-cell;
vertical-align: middle;
text-align: center;
}呈现的效果:

2: position relative + absolute + margin
HTML code:
<div id=''parent''parent''>
<div id=''child''child''>
<div>Apple</div>
<div>Orange</div>
</div>
</div>CSS code:
.parent {
height: 90px;
width: 90px;
border: 1px solid black;
}
.child {
height: 60px;
width: 60px;
background-color: #F7F00E;
}
#parent {
position: relative;
}
#child {
position: absolute;
top: 50%;
left: 50%;
margin: -30px 0 0 -30px;//修正中心点
}先来看看效果的演进。从第一个图到第二个图是我们添加了#parend和#child里面的css的效果,但是这时候不包括#child里面的最后一句 margin: -30px 0 0 -30px;。因为我们设置了top和left分别相对父元素间隔50%的距离,但是这个位移是以子元素也就是#child的左上角为原点的,所以如果我们想要达到子元素(#child)和父元素(#parent)的中心重合的话,还得再次向左和向上分别移动宽度和高度的一半的距离,也就是#child里面最后一句代码做的事情。那30px,其实就是#child一半的宽度和高度。


3: position relative + absolute + margin auto
HTML code:
<div id=''parent''parent''>
<div id=''child''child''>
<div>Apple</div>
<div>Orange</div>
</div>
</div>CSS code:
.parent {
height: 90px;
width: 90px;
border: 1px solid black;
}
.child {
height: 60px;
width: 60px;
background-color: #F7F00E;
}
#parent {
position: relative;
}
#child {
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
margin: auto;
}这个实现的技巧在于,我们给目标元素#child的四个方位都设置了相对父元素为0的距离,但是没有最后一行 margin: auto;就像四个方向都有一个同样大小的力在拉扯着你,这时候产生的效果是呆在原地不动,这时候是左边的效果。但是,当我们添加了最后一行代码:margin: auto;我们的目标元素就会跑到父元素的正中间。margin: 0 auto; 常常被我们用来设置水平位置的居中,所以当我们给它四个方向都设置auto的时候,它就只能在父元素的正中间了。

Access context of data source and work center view do not match
这个错误消息提示我们,data source的access context和待分配到工作中心的access context必须匹配:
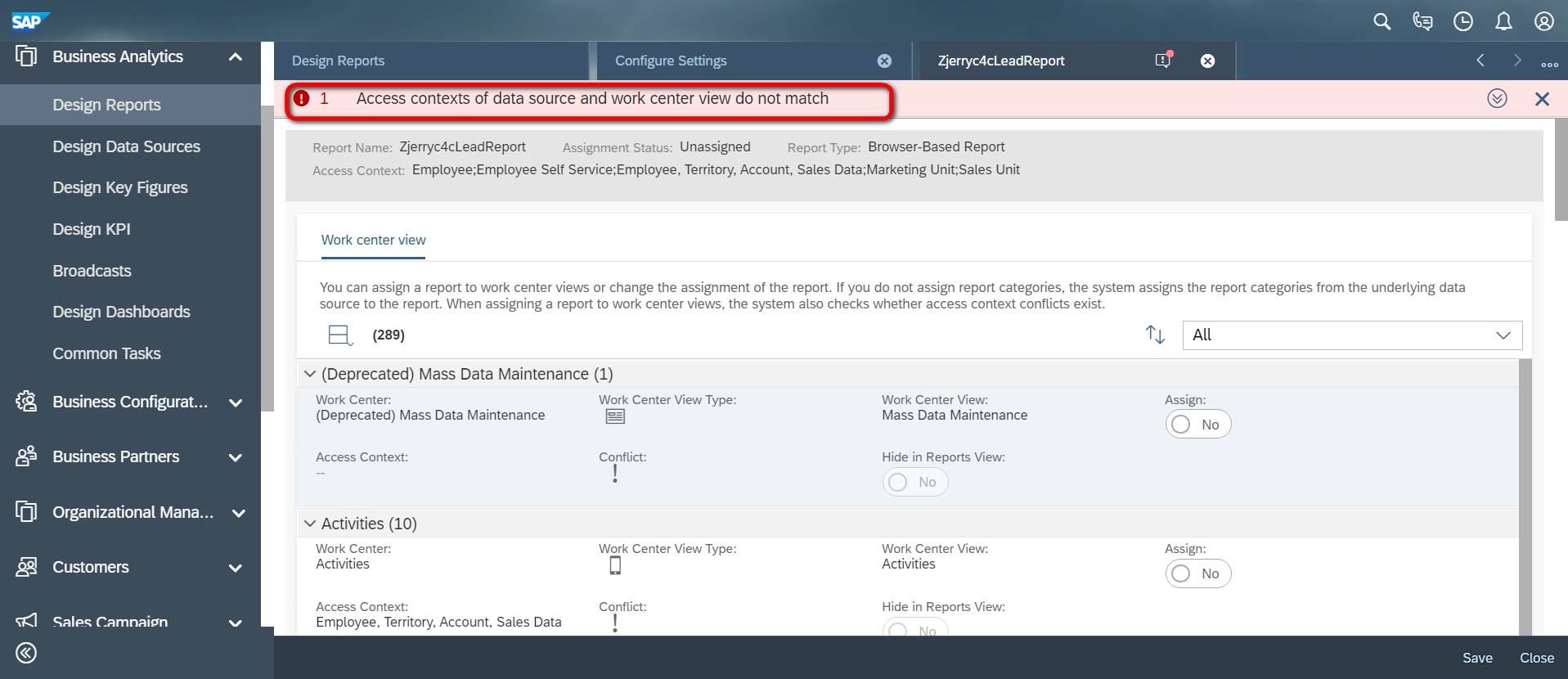
而另一个错误消息:Save not possible; wrong XRepository layer strategy selected, 意思是当前操作的用户分配有PDI_Development,这不是一个business user;
https://apps.support.sap.com/sap/support/knowledge/public/en/2530322
按照上述SAP官方帮助文档的说法,切换成一个business user登录操作,错误即消失。

要获取更多Jerry的原创文章,请关注公众号"汪子熙":
本文分享 CSDN - 汪子熙。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

Android Widget.AppCompat.ProgressBar.Horizontal 和 Widget.Material.ProgressBar.Horizontal 有什么区别?
如何解决Android Widget.AppCompat.ProgressBar.Horizontal 和 Widget.Material.ProgressBar.Horizontal 有什么区别?
我对两种风格感到困惑。我使用 api 级别 24 作为我的 android 应用程序的最低 sdk 版本。那么这两种风格的进度条有什么区别呢?我可以直接使用 Widget.Material.ProgressBar.Horizontal 因为我的最低 sdk 版本是 api 24 吗?喜欢:
<ProgressBar
android:id="@+id/t_progressbar1"android:layout_width="match_parent"
android:layout_height="wrap_content" />
注意:我正在为我的应用程序使用材料设计主题。哪种风格更可取或更正确?
解决方法
Widget.AppCompat.ProgressBar.Horizontal 只有在您看到代码时才在内部使用 Widget.Material.ProgressBar.Horizontal。
正如您提到的,您使用的是 Material Design,而您的最小 sdk 是 24,我认为您应该使用 Widget.Material.ProgressBar.Horizontal 本身。
 attack 嗅...")
ARP Poisoning Attack and Mitigation Techniques ARP欺骗 中间人攻击 Man-In-The-Middle (MITM) attack 嗅...
小结:
1、
ARP缓存投毒,窃听中毒者之间的通信;
2、
ARP Poisoning Attack and Mitigation Techniques - Cisco
https://www.cisco.com/c/en/us/products/collateral/switches/catalyst-6500-series-switches/white_paper_c11_603839.html
ARP Poisoning (Man-in-the-Middle) Attack and Mitigation Techniques
A CSSTG SE Residency Program White Paper
Jeff King, CCIE 11873, CCSP, CISSP 80875
Kevin Lauerman, CCSP, CISSP 80877
Abstract
Security is at the forefront of most networks, and many companies implement a comprehensive security policy encompassing many of the OSI layers, from application layer all the way down to IP security. However, one area that is often left untouched is hardening Layer 2 and this can open the network to a variety of attacks and compromises.
This document will have a focus on understanding and preventing the ARP Poisoning (also known as the Man-In-The-Middle [MITM]) Layer 2 attack on the Cisco® Catalyst® 6500 switching series switch running Cisco IOS® Software. The Ettercap attack tool will be used to initiate Layer 2 attacks that you might encounter. Mitigation techniques to stop this attack are also covered.
A MacBook Pro and a Lenovo T61P (laptops) was used for these test and acted as the attacker in some cases and the victim in others. Both computers also ran VMware.
Note that the attacks performed in this white paper were done in a controlled lab environment. We do not recommend that you perform this attack on your enterprise network.
ARP (Address Resolution Protocol) Poisoning (MITM) Attack
A Man-In-The-Middle (MITM) attack is achieved when an attacker poisons the ARP cache of two devices with the (48-bit) MAC address of their Ethernet NIC (Network Interface Card). Once the ARP cache has been successfully poisoned, each of the victim devices send all their packets to the attacker when communicating to the other device. This puts the attacker in the middle of the communications path between the two victim devices; hence the name Man-In-The-Middle (MITM) attack. It allows an attacker to easily monitor all communication between victim devices.
The objective of this MITM attack is to take over a session. The intent is to intercept and view the information being passed between the two victim devices.
Three (3) scenarios were used for the MITM attack. They were as follows:
Scenario
Description
1
Static IP Address on Attacker machine
2
DHCP from 881 Router (DHCP Server) on Attacker machine
3
DHCP from Cisco Catalyst 6509E DHCP Server on Attacker machine
These (3) scenarios were chosen because they were all valid configurations that one might see in a customer''s network; although scenario 2 and 3 are more likely in an enterprise network.
攻击步骤
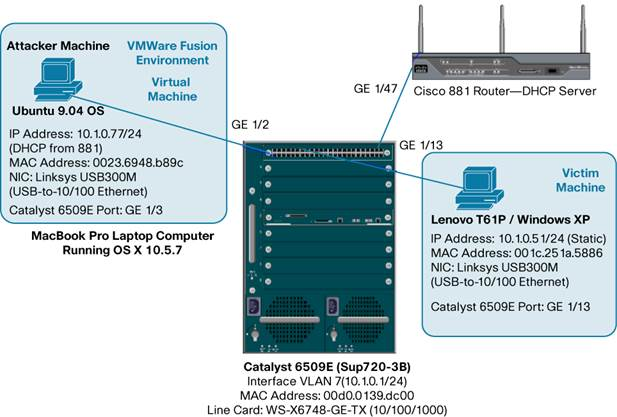
Steps for the MITM (ARP Poisoning) Attack:
1. View initial ARP cache on the Victim PC (Windows XP)
2. View initial ARP cache on the Attacker PC (Ubuntu 9.04)
3. View initial MAC Address-Table on the Cisco Catalyst 6509E (Sup 720-3B)
4. Start Ettercap attack application on the Attacker PC (Ubuntu 9.04)
5. Configure Ettercap for “Unified Sniffing”
6. Select Interface (eth2) to sniff on Ubuntu 9.04 Attacker PC
7. Scan for host on wire
8. List hosts discovered and select targets for attack
9. Start sniffing
10. Start the MITM (ARP Poisoning) attack
11. Activate the “repoison_arp” plugin in Ettercap
12. Activate the “remote_browser” plugin in Ettercap
13. Open a Telnet session from the Victim to 10.1.0.1 (Int Vlan 7 on 6509E)
14. View “connections” in Ettercap for “active” connections (telnet session)
15. Select “active” session and then “view details”
16. View login and password between Victims (Windows XP and 6509E)
17. Perform “character injection” from Ettercap toward the 6509E (CLI)
18. Perform “character injection” from Ettercap toward Windows XP (Victim)
19. Open up web browser to from Windows XP Victim to CVDM on 6509E
20. Spawn browser on Attacker PC to view Victim''s web pages being viewed
21. Scenario 2: DHCP from 881 Router (DHCP Server) on Attacker machine
22. Scenario 3: DHCP from Cisco Catalyst 6509E DHCP Server on Attacker machine
23. Mitigation of the MITM (ARP Poisoning) Attack
24. Summary
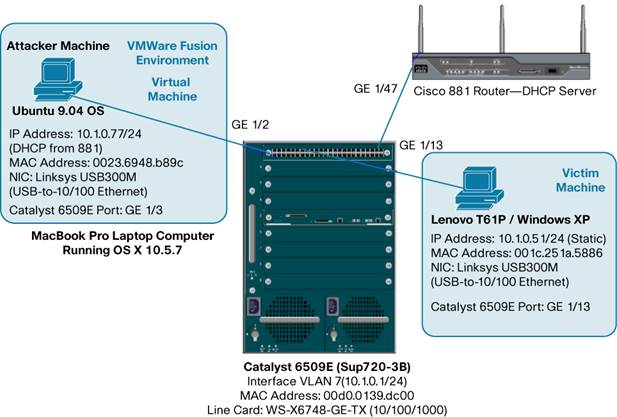
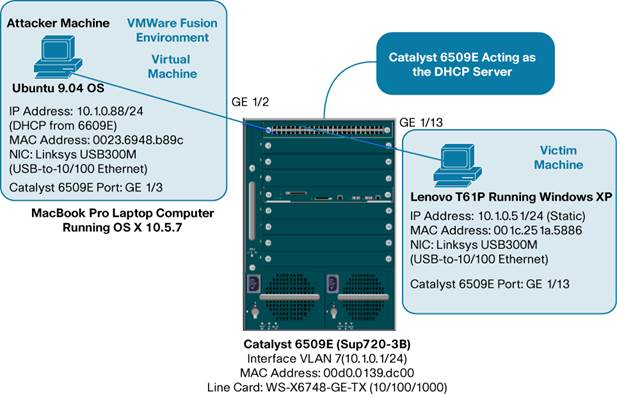
https://en.wikipedia.org/wiki/ARP_spoofing

Center-based 3D Object Detection and Tracking
https://arxiv.org/pdf/2006.11275.pdf
Abstract
三维对象通常表示为点云中的 3D 框。这种表示模仿了基于图像的 2D 边界框检测,但也带来了额外的挑战。 3D 世界中的对象不遵循任何特定的方向,基于框的检测器难以枚举所有方向或将轴对齐的边界框拟合到旋转的对象。在本文中,我们用点来表示、检测和跟踪三维物体。我们的框架 CenterPoint 首先使用关键点检测器检测对象的中心,然后回归其他属性,包括 3D 尺寸、3D 方向和速度。在第二阶段,它使用目标上的额外点特征来改进这些估计。在 CenterPoint 中,3D 对象跟踪简化为贪婪的最近点匹配。由此产生的检测和跟踪算法简单、高效、有效。 CenterPoint 在 nuScenes 基准测试中实现了 3D 检测和跟踪的最佳性能,单个模型的 NDS 为 65.5 和 AMOTA 为 63.8。在 Waymo 开放数据集上,CenterPoint 大大优于之前所有的单一模型方法,并且在所有仅使用激光雷达的提交中排名第一。
1. Introduction
强大的3D感知能力是许多先进驾驶系统的核心组成部分。 与已经深入研究的二维检测问题相比,点云的三维检测提出了一系列有趣的挑战:
- 首先,点云是稀疏的,大多数三维物体都没有测量。
- 其次,结果输出是一个三维的框,它通常没有与任何全局坐标系很好地对齐。
- 第三,3D物体有各种大小、形状和高宽比,例如,在交通领域,自行车接近平面,公共汽车和豪华轿车被拉长,行人很高。 2D和3D检测之间的这些显著差异使得这两个领域之间的idea转移更加困难。 轴向2D方框是自由形状3D目标的糟糕代理。 一种解决方案可能是为每个目标方向分类不同的模板(锚),但这不必要地增加了计算负担,并可能引入大量潜在的假正样本检测。 我们认为,连接2D和3D领域的主要潜在挑战在于目标的这种表示。
在本文中,我们展示了如何将物体表示为点(图1),极大地简化了3D识别。 我们的两阶段3D检测器CenterPoint使用关键点检测器来找到物体的中心和它们的属性,第二阶段改进了所有的估计。 具体来说,CenterPoint使用标准的基于Lidar的骨干网,即VoxelNet或PointPillars,来构建输入点云的表示。 然后,它将这种表示平铺到一个高架地图视图中,并使用基于标准图像的关键点检测器来寻找目标中心。 对于每个检测到的中心,它会从中心位置的点特征回归所有其他目标属性,如3D尺寸、方向和速度。 此外,我们使用一个轻量级的第二阶段来改善目标位置。 第二阶段提取被估计物体三维边界框中每个面的三维中心的点特征。 它恢复了由于步幅和有限的接收域而丢失的局部几何信息,并以较小的成本带来了良好的性能提升。

图 1:我们提出了一个基于中心的框架来表示、检测和跟踪对象。 以前的基于anchor的方法使用相对于车辆自身坐标轴对齐anchor。 当车辆在笔直的道路上行驶时,基于anchor的方法和我们的基于中心的方法都能够准确地检测到物体(上图)。 然而,在安全关键的左转(底部)期间,基于anchor的方法难以将轴对齐的边界框拟合到旋转的对象。 我们的基于中心的模型通过旋转不变的点准确地检测对象。
基于中心的表示法有几个关键的优点:
- 首先,与包围框不同,点没有内在的方向。 这大大减少了目标检测器的搜索空间,并允许主干学习目标的旋转不变性和等价性。
- 其次,基于中心的表示简化了下游任务,如跟踪。 如果物体是点,轨迹就是空间和时间中的路径。 中心点预测目标在连续帧和关联目标之间的相对偏移(速度)。
- 第三,基于点的特征提取使我们能够设计一个有效的两阶段细化模块,其速度远快于以往的方法。
我们在两个流行的大数据集上测试我们的模型:Waymo Open和nuScenes。 我们发现,在不同的主干下,从框表示到基于中心表示的简单切换可以增加3-4个mAP。 第两阶段细化进一步带来额外的2 mAP提升,计算开销很小(< 10%)。 我们最好的单一模型在Waymo上实现了71.8和66.4 level 2 mAPH的车辆和行人检测,在nuScenes上实现了58.0 mAP和65.5 NDS,优于所有已发布的方法。 值得注意的是,在NeurIPS 2020 nuScenes 3D检测挑战赛中,前4名获奖作品中有3个以CenterPoint为基础。 对于3D跟踪,在nuScenes上我们的模型执行63.8 AMOTA优于之前的先进的8.8 AMOTA。 在Waymo 3D跟踪基准上,我们的模型对车辆和行人的跟踪分别达到59.4和56.6 level 2 MOTA,比以前的方法高出50%。 我们的端到端3D检测和跟踪系统几乎是实时运行的,在Waymo上是11 FPS,在nuScenes上是16 FPS。
2. Related work
2D object detection 从图像输入预测轴对齐边界框。 RCNN家族找到一个category-agnostic的边界框候选人,然后对其进行分类和改进。 YOLO、SSD和RetinaNet直接找到一个category-specific的候选框,避免了后续的分类和细化。 基于中心的检测器,如CenterNet或CenterTrack,直接检测隐式的目标中心点,而不需要候选框。 许多三维检测器都是从这些二维检测器演化而来的。 我们证明基于中心的表示是3D应用的理想选择。
3D object detection 目标是预测三维旋转的包围框。 它们不同于输入编码器上的2D检测器。 Vote3Deep利用以特征为中心的投票有效地处理等距3D体素上的稀疏3D点云。 VoxelNet使用每个体素内部的PointNet生成统一的特征表示,使用3D稀疏卷积和2D卷积的头部生成检测。 SECOND简化了VoxelNet,加快了稀疏的3D卷积。 PIXOR将所有点投影到带有3D占用和点强度信息的2D特征图上,以消除昂贵的3D卷积。 PointPillars用支柱表示取代了所有的体素计算,每个映射位置都有一个细长的体素,提高了骨干效率。 MVF和Pillar-od结合多种视图特征来学习更有效的支柱表示。 我们的贡献集中在输出表示,并与任何3D编码器兼容,并可以改进它们。
VoteNet通过使用点特征抽样和分组的投票聚类来检测目标。 相反,我们直接通过中心点的特征回归到3D边界框,而不需要投票。 Wong等人和Chen等人在目标中心区域使用了类似的多点表示(即点锚),并回归到其他属性。 我们对每个目标使用一个正单元,并使用关键点估计损失。
Two-stage 3D object detection. 最近的研究考虑直接将RCNN风格的2D检测器应用于3D领域。 他们中的大多数应用RoIPool或RoIAlign在3D空间中聚合特定于ROI的特征,使用基于PointNet的点或体素特征提取器。 这些方法从3D激光雷达测量中提取区域特征(点和体素),由于大量的点,导致运行时间令人望而却步。 相反,我们从中间特征图中提取5个表面中心点的稀疏特征。 这使我们的第二阶段非常有效,并保持有效。
3D object tracking. 许多2D跟踪算法容易跟踪3D目标。 然而,基于3D卡尔曼滤波器的专用3D跟踪器仍然有边缘,因为它们更好地利用了场景中的三维运动。 在这里,我们采用了CenterTrack的一种更简单的方法。 我们使用基于点的检测的速度估计,通过多帧跟踪目标的中心。 这种跟踪器比专用的3D跟踪器更快、更准确。
3. Preliminaries
2D CenterNet 将目标检测改写为关键点估计。 它取一幅输入图像,对每K个类预测一个
w
×
h
w×h
w×h热图
Y
^
∈
[
0
,
1
]
w
×
h
×
K
\hat Y \in [0,1]^{w\times h \times K }
Y^∈[0,1]w×h×K。 输出热图中的每个局部最大值(即大于其8个邻居的像素)对应于检测目标的中心。 为了检索一个2D框,CenterNet回归所有类别之间共享的尺寸图
S
^
∈
R
w
×
h
×
K
\hat S \in \mathbb{R} ^{w\times h \times K}
S^∈Rw×h×K。 对于每个检测目标,尺寸图将其宽度和高度存储在中心位置。 CenterNet架构使用了标准的全卷积图像主干,并在顶部添加了密集的预测头。 在训练过程中,对每个类
c
i
∈
{
1...
K
}
c_i \in\left \{ 1...K \right \}
ci∈{1...K},CenterNet在每个标注的对象中心处学习预测带有渲染高斯核的热图,并回归标注边界框中心的目标尺寸S。 为了弥补由主干网结构的跨步引入的量化误差,CenterNet也回归到一个局部偏移
O
^
\hat O
O^。
在测试时,检测器生成K个热图和密集的类class-agnostic 回归图。 热图中的每个局部最大值(峰值)对应一个目标,其置信度与峰值处的热图值成正比。 对于每一个被检测的目标,检测器从相应的峰值位置的回归图中获取所有的回归值。 根据应用程序域的不同,非最大抑制(NMS)可能是合理的。
3D Detection 设 P = { ( x , y , z , r ) i } \mathcal{P} =\left \{(x, y, z,r)_i \right \} P={(x,y,z,r)i}是3位置 ( x , y , z ) (x,y,z) (x,y,z)和反射率 r r r的无序点云。 三维物体检测目标是从该点云鸟瞰图视角预测一组三维物体包围框 B = { b k } \mathcal{B}=\left\{b_k\right\} B={bk}。 每个包围框 b = ( u , v , d , w , l , h , α ) b=(u,v,d,w,l,h,\alpha) b=(u,v,d,w,l,h,α)由相对于物体地面的中心位置 ( u , v , d ) (u,v,d) (u,v,d)、3D尺寸 ( w , l , h ) (w,l,h) (w,l,h)和以俯仰角yaw α \alpha α表示的旋转。 在不失一般性的前提下,我们采用自中心坐标系统,传感器位置为 ( 0 , 0 , 0 ) , y a w = 0 (0,0,0),yaw= 0 (0,0,0),yaw=0。
现代3D物体检测器使用3D编码器将点云量化到常规bins中。 然后,基于点的网络提取一个bins内的所有点特征。 然后,3D编码器将这些特征集合到其主要特征表示中。 大部分的计算都发生在骨干网中,骨干网只对这些量化和池化的特征表示进行操作。在映射视图参考框架中,骨干网络的输出是一个宽度为W,长度为L,通道数为F的map-view feature-map 。 宽度和高度都直接与个体体素条的分辨率和主干网络的步幅有关。 常见的骨干包括VoxelNet和PointPillars。
对于一个map-view feature-map M,一个检测头(通常是一个或两级边界框检测器),然后在这些特征图的预定义边界框anchor生成目标检测。 由于3D包围框具有不同的尺寸和方向,基于anchor的3D检测器很难将轴向的2D框与3D目标相匹配。 此外,在训练过程中,以往基于anchor的3D检测器依赖于2D Box IoU进行目标分配,这为不同类别或不同数据集选择正/负阈值带来了不必要的负担。 在下一节中,我们将展示如何基于点表示建立一个有原则的3D目标检测和跟踪模型。 我们引入了一种新的基于中心的检测头,但依赖于现有的3D骨干(VoxelNet或PointPillars)
4. CenterPoint

图 2:我们的
CenterPoint框架概述。 我们依赖于从激光雷达点云中提取地图视图特征表示的标准 3D 主干。 然后,2D CNN 架构检测头找到对象中心并使用中心特征回归完整的 3D 边界框。 此框预测用于提取估计的 3D 边界框每个面的 3D 中心的点特征,将其传递到MLP以预测IoU引导的置信度得分和改善Box回归。
图2显示了CenterPoint模型的总体框架。 设
M
∈
R
W
×
H
×
F
M\in \mathbb{R} ^{W \times H \times F}
M∈RW×H×F为3D主干的输出。 CenterPoint的第一阶段预测class-specific 的热图、目标尺寸、sub-voxel 位置、旋转和速度。 所有的输出都是密集的预测。
Center heatmap head. 中心头部的目标是在任何被检测物体的中心位置产生一个热图峰值。 这个头产生一个
K
K
K通道热图
Y
^
\hat Y
Y^,每个
K
K
K类有一个通道。 在训练过程中,它的目标是由带的边界框的3D中心投影到map-view 中而产生的 2D 高斯分布。 我们使用focal loss。 自上而下map view 中的目标比图像中的目标更稀疏。 在map view 中,距离是绝对的,而image-view 通过透视扭曲了距离。 考虑一个道路场景,在map view中车辆所占的面积很小,但在image view中,一些大的物体可能会占据屏幕的大部分。 此外,透视投影中深度维数的压缩自然使图像中目标中心彼此更接近。 遵循 CenterNet的standard supervision会产生非常稀疏的监督信号,其中大多数位置都被认为是背景。 为了抵消这一点,我们增加了目标热图
Y
Y
Y的正向监督,通过放大每个ground-truth目标中心 Gaussian peak rendered。 具体来说,我们设置高斯半径为
σ
=
m
a
x
(
f
(
w
l
)
,
τ
)
\sigma =max(f(wl),\tau)
σ=max(f(wl),τ),其中
τ
=
2
\tau=2
τ=2 是允许的最小高斯半径,
f
f
f是CornerNet中定义的半径函数。 通过这种方式,CenterPoint保持了基于中心的目标分配的简单性;该模型从附近的像素得到更密集的监督。
Regression heads. 我们将一些目标属性存储在目标的中心特征处:sub-voxel 位置
o
∈
R
2
o \in \mathbb{R}^2
o∈R2,地面高度
h
g
∈
R
h_g \in \mathbb{R}
hg∈R,3D尺寸
s
∈
R
2
s \in \mathbb{R}^2
s∈R2,yaw旋转角度
s
i
n
(
α
)
,
c
o
s
(
α
)
)
∈
R
2
sin(\alpha),cos(\alpha)) \in \mathbb{R}^2
sin(α),cos(α))∈R2。 sub-voxel 位置减少了由于体素化和主干网络的步幅而产生的量化误差。 地面高度有助于在3D中定位物体,并添加被map-view投影删除的缺失海拔信息。 方位预测采用偏航角的正弦和余弦作为连续回归目标。 结合框尺寸,这些回归头提供了3D包围框的完整状态信息。 每个输出使用它自己的头。在训练时,仅使用
L
1
L1
L1 回归损失监督ground-truth中心,回归到对数大小,以更好地处理各种形状的框。 在推理时,我们通过在每个对象的峰值位置索引密集回归头输出来提取所有属性
VeLocity head and tracking. 为了通过时间跟踪目标,我们学习预测每个检测目标的二维速度估计
v
∈
R
2
v \in \mathbb{R}^2
v∈R2作为额外的回归输出。 速度估计是特殊的,因为它需要map-views中当前和前一个时间步长输入。它预测当前帧和过去帧之间目标位置的差异。 与其他回归目标一样,速度估计也使用当前时间步长的 ground truth 目标位置的
L
1
L1
L1 损失进行监督
在推断时,我们使用这个偏移量以一种贪婪的方式将当前的检测与过去的检测关联起来。 具体来说,我们利用负速度估计将当前帧中的目标中心投影回上一帧,然后通过最近距离匹配将它们与被跟踪的目标进行匹配。 按照SORT,在删除它们之前,我们保持不匹配的跟踪到 T = 3 T = 3 T=3 帧。 我们用最后已知的速度估计更新每个不匹配的轨迹。
CenterPoint将所有heatmap 和回归损失合并到一个共同的目标中,并联合优化它们。 它简化并改进了以前基于anchor的3D检测器。 然而,当前所有目标属性都是从目标的中心特征推断出来的,而中心特征可能不包含足够的信息来进行精确的目标定位。 例如,在自动驾驶中,传感器往往只看到物体的侧面,而不是中心。 接下来,我们通过使用带有轻量级点特征提取器的第二个细化阶段来改进 CenterPoint
4.1. Two-Stage CenterPoint
我们使用CenterPoint作为第一阶段。 第二阶段从骨干网的输出中提取额外的点特征。 我们从预测边界框的每个面的三维中心提取一个点特征。 注意,边界框的中心,顶部和底部的中心都投射到地图视图中的同一个点上。 因此,我们只考虑四个向外的框面和预测的目标中心。 对于每个点,我们使用双线性插值从主映射视图输出M中提取一个特征。接下来,我们将提取的点特征连接起来,并将它们通过一个MLP传递。 第二阶段在一级CenterPoint的预测结果之上预测一个类不可知的置信度得分和框的细化。
对于与class-agnostic 的置信度分数预测,我们遵循并使用由框的 3D IoU 引导的分数目标和相应的ground truth 边界框:
I
=
m
i
n
(
1
,
m
a
x
(
0
,
2
×
I
o
U
t
−
0.5
)
)
I=min(1,max(0,2 \times IoU_t -0.5))
I=min(1,max(0,2×IoUt−0.5))
其中
I
o
U
t
IoU_t
IoUt 是第
t
t
t 个提议框和 ground truth 之间的 IoU。 训练由二元交叉熵损失监督:
L
s
c
o
r
e
=
−
I
t
l
o
g
(
I
^
t
)
−
(
1
−
I
t
)
l
o
g
(
1
−
I
^
t
)
L_{score}=-I_tlog(\hat I_t)-(1-I_t)log(1-\hat I_t)
Lscore=−Itlog(I^t)−(1−It)log(1−I^t)
其中
I
^
t
\hat I_t
I^t是预测的置信度, 在推理,我们直接使用单阶段CenterPoint类别预测,并计算最终的置信度的几何平均 ,
Q
^
t
\hat Q_t
Q^t 是最后的预测目标
t
t
t的置信度,
Y
^
t
=
m
a
x
0
≤
k
≤
K
Y
^
p
,
k
\hat Y_t =max_{0\le k\le K} \hat Y_{p,k}
Y^t=max0≤k≤KY^p,k ,
I
^
t
\hat I_t
I^t分别是第一阶段和第二阶段目标t的置信度。
对于框回归,模型预测在第一阶段提议做出改进,我们用
L
1
L1
L1损失训练模型。 我们的两阶段CenterPoint简化并加速了之前使用昂贵的基于PointNet的特征提取器和RoIAlign操作的两阶段3D检测器。
4.2. Architecture
所有第一级输出共享一个前3 × 3卷积层、Batch normalization 和ReLU。 然后,每个输出使用自己的两个由batch norm和ReLU分隔的3 × 3卷积分支。 我们的第二阶段使用一个共享的两层MLP,batch norm 、ReLU和drop率为0.3的Dropout,然后是单独的三层MLP,用于置信度预测和框回归。
5. Experiments
我们在Waymo Open Dataset和nuScenes Dataset上评估CenterPoint。 我们使用两种3D编码器实现CenterPoint: VoxelNet和PointPillars,分别被称为CenterPoint-Voxel和CenterPoint-Pillar。
Waymo Open Dataset. Waymo Open Dataset包含798个训练序列和202个验证序列,用于车辆和行人。 点云包含激光雷达64道,对应每0.1s 180k点。 官方的三维检测评估指标包括三维包围框平均精度(mAP)和mAP加权方向精度(mAPH)。 mAP和mAPH是基于0.7 IoU的车辆和0.5的行人。 对于三维跟踪,官方指标是多目标跟踪精度(MOTA)和多目标跟踪精度(MOTP)。 官方评估工具包还提供了两个难度等级的性能分解:LEVEL_1 是包含5个以上激光雷达点的框,LEVEL_2是包含至少1个激光雷达点的框。
我们的Waymo模型对X轴和Y轴的检测范围为[-75.2m, 75.2m],对Z轴的检测范围为[2m, 4m]。 CenterPoint-Voxel使用(0.1m, 0.1m, 0.15m)体素大小,遵循PV-RCNN,而CenterPoint-Pillar使用网格大小(0.32m, 0.32m)。
nuScenes Dataset. nuScenes包含1000个驱动序列,分别有700、150、150个序列用于训练、验证和测试。 每个序列大约20秒长,激光雷达频率为20 FPS。 数据集为每个激光雷达帧提供校准的车辆姿态信息,但每10帧(0.5s)只提供框标注。 nuScenes使用32道激光雷达,每帧产生大约3万个点。 总共有28k, 6k, 6k,用于训练,验证和测试的注释框架。 这些注释包括10个具有长尾分布的类。 官方的评估指标是类别的平均水平。 对于3D检测,主要指标是平均平均精度(mAP)和nuScenes检测评分(NDS)。
-
mAP使用鸟瞰中心距离< 0.5m, 1m, 2m, 4m,而不是标准的框重叠。 -
NDS是mAP和其他属性度量的加权平均值,包括平移、比例、方向、速度和其他框属性。
在我们的测试集提交之后,nuScenes团队添加了一个新的神经规划度量(PKL)。 PKL度量基于规划者路线的KL散度(使用3D检测)和ground-truth轨迹来度量3D目标检测对下行自主驾驶任务的影响。 因此,我们也报告了在测试集上评估的所有方法的PKL度量。
对于3D跟踪,nuScenes使用AMOTA,它会惩罚ID开关、假阳性和假阴性,平均超过各种召回阈值。
对于nuScenes的实验,我们将X、Y轴的检测范围设置为[51.2m, 51.2m], Z轴是[5m, 3m]。 CenterPoint-Voxel使用(0.1m, 0.1m, 0.2m)体素大小,CenterPoint-Pillars使用(0.2m, 0.2m)网格。
Training and Inference. 我们使用与先前工作相同的网络设计和训练计划。 详细的超参数见补充。 在两阶段CenterPoint的训练过程中,我们从第一阶段的预测中随机抽取了128个正负比为1:1的框。 如果一个提议与至少0.55 IoU的ground truth注释重叠,则该提议是正样本。 在推断过程中,我们对非最大抑制(NMS)之后的前500个预测运行第二阶段。 推断时间是在Intel Core i7 cpu和Titan RTX GPU上测量的。
5.1. Main Results
3D Detection 我们首先在Waymo和nuScenes的测试集上展示我们的3D检测结果。 这两个结果都使用了一个CenterPoint-Voxel模型。 表1和表2总结了我们的结果。 在Waymo测试集上,我们的模型实现了71.8 level 2 mAPH的车辆检测和66.4 level 2 mAPH的行人检测,车辆和行人的mAPH分别比之前的方法提高了7.1%和10.6%。 在nuScenes(表2)上,我们的模型在多尺度输入和多模型集成方面比去年的冠军CBGS高出5.2% mAP和2.2% NDS。 如后面所示,我们的模型也快得多。 补充材料包含了沿着类的细分。 我们的模型在所有类别中显示了一致的性能改进,并在小类别(交通锥+5.6 mAP)和极端纵横比类别(自行车+6.4 mAP,施工车辆+7.0 mAP)中显示了更显著的改善。 更重要的是,我们的模型在神经平面度量(PKL)下显著优于所有其他提交的模型。 在我们的排行榜提交后。 这突出了我们框架的泛化能力。

表 1:
Waymo测试集上3D检测的最新比较。 我们展示了 1 级和 2 级基准的mAP和mAPH。

表 2:
nuScenes测试集上 3D 检测的最新比较。 我们展示了nuScenes检测分数 (NDS) 和平均平均精度 (mAP)。

表 3:
Waymo测试集上3D跟踪的最新比较。 我们展示了MOTA和MOTP。 $\uparrow 代表越高越好, 代表越高越好, 代表越高越好,\downarrow $ 代表越低越好。

表 4:nuScenes 测试集上 3D 跟踪的最新比较。 我们展示了
AMOTA、false positives(FP)、false negatives(FN)、id switches (IDS)和每个类别的AMOTA。 $\uparrow 代表越高越好, 代表越高越好, 代表越高越好,\downarrow $ 代表越低越好。
3D Tracking 表3显示了CenterPoint在Waymo测试集上的跟踪性能。 我们在第4节中描述的基于速度的最接近距离匹配显著优于Waymo论文中的官方跟踪基线,后者使用基于卡尔曼滤波的跟踪器。 我们观察到车辆和行人跟踪的MOTA分别提高了19.4和18.9。 在nuScenes(表4)上,我们的框架比上次挑战的获胜者Chiu et al.高出8.8 AMOTA。 值得注意的是,我们的跟踪不需要单独的运动模型,运行时间可以忽略不计,比检测时间长1毫秒。
5.2. Ablation studies

表 5:在
Waymo验证集中基于锚点和基于中心的3D检测方法的比较。 我们展示了每类和平均LEVEL 2 mAPH

表 6:
nuScenes验证中基于锚点和基于中心的3D检测方法的比较。 我们展示了平均精度 (mAP) 和nuScenes检测分数(NDS)。

表 7:基于锚点和基于中心的方法检测不同航向角目标的比较。在第二行和第三行中列出了旋转角度的范围及其对应的目标部分,在
Waymo验证集展示显示了这两种方法的LEVEL 2mAPH

表 8:目标大小对基于锚点和基于中心的方法性能的影响。 我们展示了不同大小范围内对象的每类
LEVEL 2 mAPH:小33%、中33%和大33%
Center-based vs Anchor-based 我们首先比较了基于中心的单阶段检测器和基于锚的同类检测器。 在Waymo上,我们遵循最先进的PV-RCNN来设置anchor超参数:我们在每个位置使用两个anchor,分别为0°和90°,车辆的正/负IoU阈值为0.55/0.4,行人的0.5/0.35。 在nuScenes上,我们遵循上一届挑战赛冠军CBGS的anchor分配策略。所有其他参数与我们的 CenterPoint 模型相同
如表5所示,在Waymo数据集上,简单地从anchor转换到中心,VoxelNet和PointPillars编码器分别得到4.3 mAPH和4.5 mAPH的改进。 在nuScenes上(表6),CenterPoint 通过不同主干 提升3.8-4.1 mAP 和 1.1-1.8 NDS。 为了了解改进的来源,我们进一步展示了基于 Waymo 验证集上的目标大小和方向角度的不同子集的性能细分
我们首先根据它们的方向角度将ground tructh实例分为三个条:0°到15°,15°到30°,和30°到45°。 该部门测试检测器检测严重旋转的箱体的性能,这对安全部署自动驾驶至关重要。 我们还将数据集分为三个部分:小、中、大,每个部分包含1/3的地面真值框。
表7和表8总结了结果。 当框旋转或偏离框的平均大小时,我们基于中心的检测器比基于锚的基线性能要好得多,这证明了模型在检测目标时捕获旋转和大小不变性的能力。 这些结果令人信服地突出了使用基于点的3D目标表示的优势。
One-stage vs. Two-stage 在表9中,我们展示了在Waymo验证中使用2D CNN特征的单级和两级CenterPoint模型之间的比较。 具有多个中心特征的两级细化为两种3D编码器提供了很大的精度提升,开销较小(6ms-7ms)。 我们还与RoIAlign进行了比较,RoIAlign对RoI中的6 × 6点进行了密集采样,我们基于中心的特征聚合取得了类似的性能,但速度更快、更简单。

表 9:在
Waymo验证集中使用单级、具有3D中心特征的两级和具有3D中心和表面中心特征的两级比较VoxelNet和PointPillars编码器的3D LEVEL 2 mAPH。
体素量化限制了两阶段CenterPoint对PointPillars行人检测的改进,因为行人在模型输入中通常只停留在1像素内。 在我们的实验中,两阶段细化并没有带来单阶段CenterPoint模型在nuScenes上的改进。 这部分是由于nuScenes中稀疏的点云。 nuScenes使用32道激光雷达,每帧产生约3万个激光雷达点,约为Waymo数据集点数的1/6。 这限制了可获得的信息和两阶段改进的潜力。 在PointRCNN和PV-RCNN两阶段方法中也观察到类似的结果。

图 3:
Waymo验证集中CenterPoint的示例定性结果。 我们以蓝色显示原始点云,以绿色边界框显示我们检测到的对象,以红色显示边界框内的激光雷达点。
Effects of different feature components 在我们的两阶段CenterPoint模型中,我们只使用2D CNN特征图中的特征。 然而,以前的方法也提出利用体素特征进行第二阶段的精化。 在这里,我们比较两种体素特征提取基线
-
Voxel-Set Abstraction:PV-RCNN提出了体素集抽象(VSA)模块,它扩展了Point-Net++的集合抽象层,以在一个固定半径球中聚合体素特征。 -
Radial basis function (RBF) Interpolation:Point-Net++和SA-SSD使用径向基函数从三个最近的非空3D特征体聚合网格点特征。对于这两个基线,我们使用官方实现将鸟瞰视图特征与体素特征结合。 表10总结了结果。 这表明鸟瞰图特征足以提供良好的性能,同时与文献中使用的体素特征相比效率更高。
为了与之前未对
Waymo测试进行评估的工作进行比较,我们还在表11中报告了Waymo验证的结果。 我们的模型在很大程度上优于所有已发布的方法,特别是对于2级数据集具有挑战性的行人类(+18.6 mAPH),其中框只包含一个激光雷达点
表 10:两阶段细化模块的不同特征组件的消融研究。
VSA代表Voxel Set Abstraction,这是PV-RCNN中使用的特征聚合方法。RBF使用径向基函数对 3 个最近邻进行插值。 我们在Waymo验证中使用LEVEL 2 mAPH比较鸟瞰图和3D体素特征。

表 11:Waymo 验证集中 3D 检测的最新比较。
3D Tracking. 表12显示了基于nuScenes验证的三维跟踪消融实验。 我们与去年的挑战赛冠军Chiu et al.进行了比较,后者使用基于马氏距离的卡尔曼滤波来关联CBGS检测结果。 我们将评估分解为检测器和跟踪器,使比较严格。 对于相同的检测目标,使用简单的基于速度的最近点距离匹配比基于卡尔曼滤波的马氏距离匹配的效果要好3.7 AMOTA(第1行vs. 3行,第2行vs. 4行)。 有两个改进的来源:
- 1)我们用学到的点速度建模物体运动,而不是用卡尔曼滤波器建模三维包围框动态;
- 2)我们通过中心点距离来匹配目标,而不是框状态的马氏距离或3D边界框IoU。
- 更重要的是,我们的跟踪是一个简单的最近邻匹配,没有任何隐藏状态计算。 这节省了3D卡尔曼滤波器的计算开销(73ms vs. 1ms)。
6. Conclusion
提出了一种基于中心的基于激光雷达点云的三维目标检测与跟踪框架。 我们的方法使用标准的三维点云。 编码器与几个卷积层在头部产生鸟瞰视角热图和其他密集的回归输出。 检测是一种简单的局部峰提取和精细化,跟踪是一种最接近邻的匹配。 CenterPoint简单,接近实时,在Waymo和nuScenes基准测试中实现了最先进的性能。
今天关于horizontal center and vertical middle in CSS的介绍到此结束,谢谢您的阅读,有关Access context of data source and work center view do not match、Android Widget.AppCompat.ProgressBar.Horizontal 和 Widget.Material.ProgressBar.Horizontal 有什么区别?、ARP Poisoning Attack and Mitigation Techniques ARP欺骗 中间人攻击 Man-In-The-Middle (MITM) attack 嗅...、Center-based 3D Object Detection and Tracking等更多相关知识的信息可以在本站进行查询。
本文标签:




