这篇文章主要围绕Python:从multiprocessing.Process获取回溯和pythonmultiprocessing返回值展开,旨在为您提供一份详细的参考资料。我们将全面介绍Python
这篇文章主要围绕Python:从multiprocessing.Process获取回溯和python multiprocessing 返回值展开,旨在为您提供一份详细的参考资料。我们将全面介绍Python:从multiprocessing.Process获取回溯的优缺点,解答python multiprocessing 返回值的相关问题,同时也会为您带来multiprocessing whith python3、Python 3.2 Multiprocessing.Process没有运行目标函数、Python multiprocessing、python multiprocessing 模块 Process 类的 target 函数的实用方法。
本文目录一览:- Python:从multiprocessing.Process获取回溯(python multiprocessing 返回值)
- multiprocessing whith python3
- Python 3.2 Multiprocessing.Process没有运行目标函数
- Python multiprocessing
- python multiprocessing 模块 Process 类的 target 函数
")
Python:从multiprocessing.Process获取回溯(python multiprocessing 返回值)
我试图从multiprocessing.Process获取一个追溯对象。不幸的是,通过管道传递异常信息不起作用,因为无法腌制回溯对象:
def foo(pipe_to_parent): try: raise Exception(''xxx'') except: pipe_to_parent.send(sys.exc_info())to_child, to_self = multiprocessing.Pipe()process = multiprocessing.Process(target = foo, args = (to_self,))process.start()exc_info = to_child.recv()process.join()print traceback.format_exception(*exc_info)to_child.close()to_self.close()追溯:
Traceback (most recent call last): File "/usr/lib/python2.6/multiprocessing/process.py", line 231, in _bootstrap self.run() File "/usr/lib/python2.6/multiprocessing/process.py", line 88, in run self._target(*self._args, **self._kwargs) File "foo", line 7, in foo to_parent.send(sys.exc_info())PicklingError: Can''t pickle <type ''traceback''>: attribute lookup __builtin__.traceback failed还有另一种访问异常信息的方法吗?我想避免传递格式化的字符串。
答案1
小编典典使用tblib您可以传递包装的异常并在以后重新引发它们:
import tblib.pickling_supporttblib.pickling_support.install()from multiprocessing import Poolimport sysclass ExceptionWrapper(object): def __init__(self, ee): self.ee = ee __, __, self.tb = sys.exc_info() def re_raise(self): raise self.ee.with_traceback(self.tb) # for Python 2 replace the previous line by: # raise self.ee, None, self.tb# example of how to use ExceptionWrapperdef inverse(i): """ will fail for i == 0 """ try: return 1.0 / i except Exception as e: return ExceptionWrapper(e)def main(): p = Pool(1) results = p.map(inverse, [0, 1, 2, 3]) for result in results: if isinstance(result, ExceptionWrapper): result.re_raise()if __name__ == "__main__": main()因此,如果您在远程进程中捕获到异常,则将其包装ExceptionWrapper,然后将其传递回去。调用re_raise()主流程即可完成工作。

multiprocessing whith python3
OSC 请你来轰趴啦!1028 苏州源创会,一起寻宝 AI 时代 
代码如下
from multiprocessing import Process, Lock import time, os, sys def sayhi(i): print(''hello %s '' % i) time.sleep(10) if __name__ == "__main__": for n in range(20): p = Process(target=sayhi, args=(n,)) p.start() #sys.stdout.flush()
print 不出结果 不然就报错 要么就是 print 信息不完整。
错误信息如下!~
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "D:\Python34\lib\multiprocessing\spawn.py", line 100, in spawn_main
new_handle = steal_handle(parent_pid, pipe_handle)
File "D:\Python34\lib\multiprocessing\reduction.py", line 86, in steal_handle
_winapi.DUPLICATE_SAME_ACCESS | _winapi.DUPLICATE_CLOSE_SOURCE)
PermissionError: [WinError 5] 拒绝访问。

Python 3.2 Multiprocessing.Process没有运行目标函数
我有一个问题,我无法弄清楚是什么问题。 embedded式代码(3.2文档中最简单的示例代码,只是为了debugging)不会运行目标函数。 该过程完成后,程序导入并运行没有错误,正确安装Python 3.2和目录添加到Path环境variables。 我正在使用f5运行IDLE程序,其他所有代码都可以正常工作,但目标函数f(在这种情况下)中的代码很简单,不会运行。 如你所知,这是令人沮丧的。 这个代码不会打印,并且目标函数(以及任何函数)内的每个testing打印都不会执行; 它被简单地跳过。
#!/usr/bin/env python from multiprocessing import Process def f(name): print('hello',name) if __name__ == '__main__': p = Process(target=f,args=('bob',)) p.start()
有什么想法吗? 我在Windows 7系统上运行Python 3.2,并且使用Python 2.7在我的系统上成功运行了多处理(尽pipe我的项目需要我在3.2中进行开发)。 对不起,我认为这样一个简单的问题肯定是一些path问题,但我不确定我可能需要做什么来完成这个工作,并且找不到Google提供的任何解决scheme,因为Python肯定会识别这个包拼错时失败); 它只是行为不正确。 感谢您的任何帮助/build议!
Python:用于检测物理非HT cpu的跨平台解决scheme?
python中map.pool的用法是什么?
为什么在python pool.map不起作用
Python多处理内存使用情况
如何设置优先级来获取C / C ++中的互斥量
多处理和IDLE不能很好地协同工作。 确保它在IDLE之外运行,如果是的话,那就很好。
我自己不使用IDE,所以我没有别的东西可以提供给你,但是如何使用简单的print来进行调试真是太棒了。

Python multiprocessing
 

推荐教程
- 官方文档
- multiprocess各个模块较详细介绍
- 廖雪峰教程--推荐
- Pool中apply, apply_async的区别联系
- (推荐)python多进程的理解 multiprocessing Process join run
multiprocessing.Manager.Queuue vs multiprocessing.Queuue
| 队列 | 说明 |
|---|---|
| multiprocessing.Queuue | 只应通过继承在进程之间共享 Queue 对象 |
| multiprocessing.Manager.Queue | 如上所述,在进行并发编程时,通常最好尽量避免使用共享状态。使用多个进程时尤其如此。但是,如果您确实需要使用某些共享数据,那么多处理提供了两种方法。其中一种就是使用 Manager |
范例一
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 17:24
# @Author : wangbin
# @FileName: demo06.py
# @mail : bupt_wangbin@163.com
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print(''Process to write: %s'' % os.getpid())
for value in range(8):
print(''Put %s to queue...'' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print(''Process to read: %s'' % os.getpid())
while True:
if not q.empty():
value = q.get(True)
print(''Get %s from queue.'' % value)
time.sleep(random.random())
else:
break
if __name__ == ''__main__'':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
p = Pool()
pw = Process(target=write, args=(q,))
pw.start()
time.sleep(0.5)
pr = p.apply(read, args=(q,))
p.close()
p.join()
pw.join()
报错: Queue objects should only be shared between processes through inheritance(只应通过继承在进程之间共享 Queue 对象, 即为只可以父进程和子进程之间共享 Queue 对象)
 

范例二
一下方式可以使用
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 15:45
# @Author : wangbin
# @FileName: demo04.py
# @mail : bupt_wangbin@163.com
"""
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。
Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
"""
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print(''Process to write: %s'' % os.getpid())
for value in range(10):
# print(''Put %s to queue...'' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print(''Process to read: %s'' % os.getpid())
while True:
value = q.get(True)
print(''Get %s from queue.'' % value)
if __name__ == ''__main__'':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr1 = Process(target=read, args=(q,))
pr2 = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr1.start()
pr2.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr1.terminate()
pr2.terminate()
上述程序由于都是死循环, pr1 和 pr2如果有一个调用 join 方法的话, 程序就会一直在 block 住. 如果使用 Pool 会比较好管理, 而之前第一个范例说明, Pool 与 Produce 之间使用 multiprocessing.Queue 会出现错误, 所以, 如果使用 Pool 来产生多个进程用于生产者或者消费者, 用 Pool 很简单. 所以, 当要共享数据时候, 使用Manager.Queue() 准没错
总结: 如果使用进程共享数据的话, 就使用 Manager.Queue()
范例三
下面是使用进程池来做的
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 15:45
# @Author : wangbin
# @FileName: demo04.py
# @mail : bupt_wangbin@163.com
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print(''Process to write: %s'' % os.getpid())
for value in range(3):
print(''Put %s to queue...'' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print(''Process to read: %s'' % os.getpid())
while True:
value = q.get(True)
print(''Get %s from queue.'' % value)
if __name__ == ''__main__'':
# 父进程创建Queue,并传给各个子进程:
with Manager() as manager:
with Pool(processes=8) as pool:
# 启动子进程pr,读取:
q = manager.Queue()
for i in range(3):
pool.apply_async(func=write, args=(q,))
pool.apply_async(func=read, args=(q,)).get()
pool.close()
pool.join()
pool.terminate()
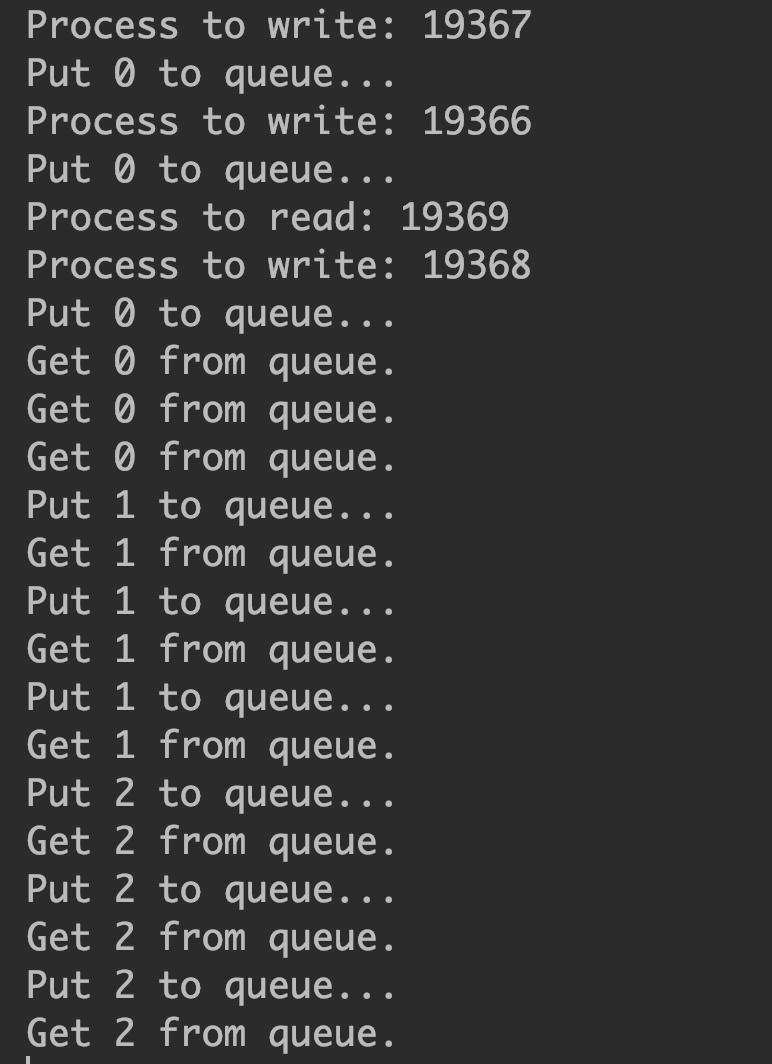 

由此可以看出, 每个进程中, 每个程序都会跑一边. 所以炼丹测试时, 验证集数据集只能使用一个进程跑, 而读取的进程需要多设置几个
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print(''Run task %s (%s)...'' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print(''Task %s runs %0.2f seconds.'' % (name, (end - start)))
if __name__==''__main__'':
print(''Parent process %s.'' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print(''Waiting for all subprocesses done...'')
p.close()
p.join()
print(''All subprocesses done.'')
执行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.
代码解读:
-
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
-
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:p = Pool(5), 就可以同时跑5个进程。
-
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。

python multiprocessing 模块 Process 类的 target 函数
在最近在学python的进程,因为一直在linux下学的,今天到win下测试了一下,发下了个问题代码如下
import multiprocessing as mp
import time
import os
def th():
print("我的父亲是%d" % os.getppid())
time.sleep(2)
while True:
time.sleep(2)
print("我是儿子!")
print("我的父亲是%d" % os.getppid())
p = mp.Process(target=th)
p.daemon = False
p.start()
time.sleep(1)
print("爸爸我over了!", os.getpid())
这段代码在linux运行无错误但是在win下
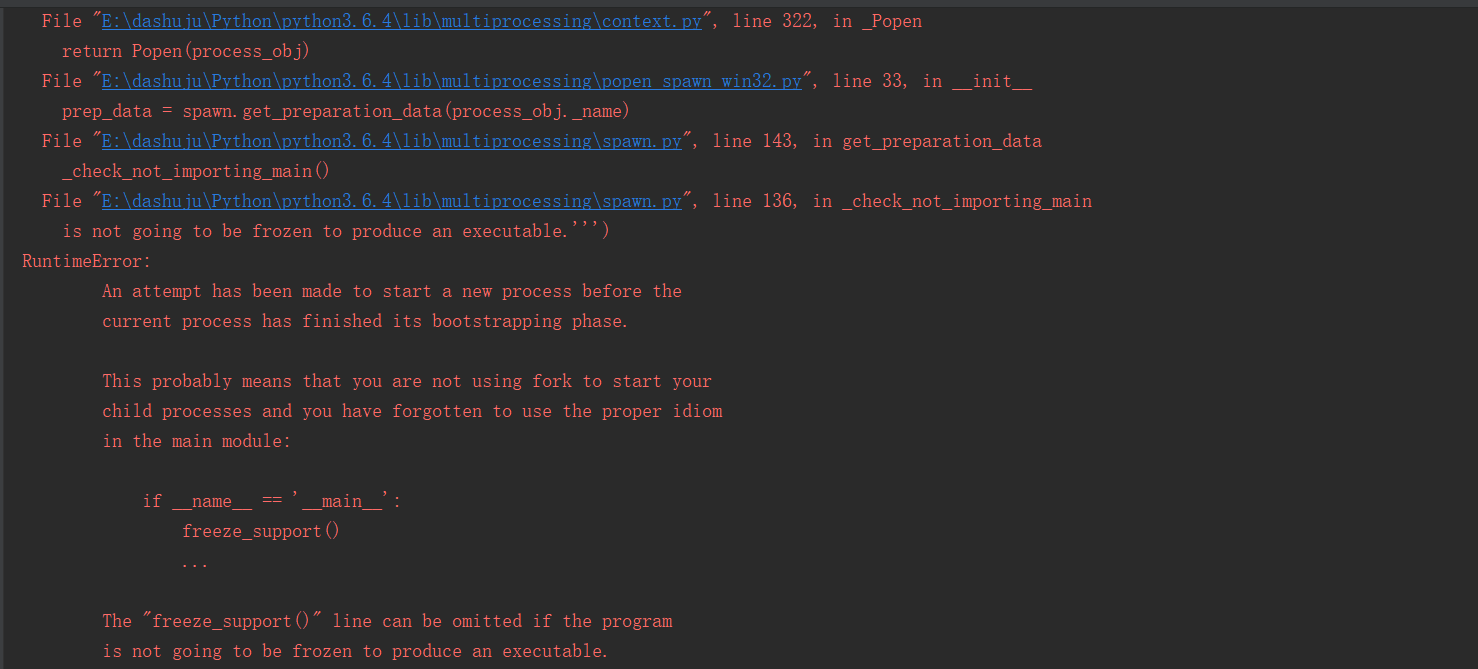
后来我发现在代码里面加一个逻辑控制的 if __name__ == ''main''就可以解决了
欢迎大牛批评教导,解决疑惑,谢谢
今天关于Python:从multiprocessing.Process获取回溯和python multiprocessing 返回值的分享就到这里,希望大家有所收获,若想了解更多关于multiprocessing whith python3、Python 3.2 Multiprocessing.Process没有运行目标函数、Python multiprocessing、python multiprocessing 模块 Process 类的 target 函数等相关知识,可以在本站进行查询。
本文标签:




