本文将带您了解关于怎么查看网站的日记spider爬行的新内容,同时我们还将为您解释怎么看网站日志的相关知识,另外,我们还将为您提供关于CrawlSpider爬虫、docker怎么查看网络详情、moo日
本文将带您了解关于怎么查看网站的日记spider爬行的新内容,同时我们还将为您解释怎么看网站日志的相关知识,另外,我们还将为您提供关于CrawlSpider爬虫、docker怎么查看网络详情、moo日记怎么查看自己的日记、moo日记怎么查看自己的日记本的实用信息。
本文目录一览:")
怎么查看网站的日记spider爬行(怎么看网站日志)
想把一个网站的优化排名做好,就要知道baiduspider到底是个什么东西,喜欢怎样的食物,怎样才能做好合适它胃口的美味大餐!作为一个合格的优化工作者,就需要知道怎么看网络日记,因为这里记录了spider的爬行记录! 看log都看什么?这个大家都知道要看ht
想把一个网站的优化排名做好,就要知道baiduspider到底是个什么东西,喜欢怎样的食物,怎样才能做好合适它胃口的美味大餐!作为一个合格的优化工作者,就需要知道怎么看网络日记,因为这里记录了spider的爬行记录!
看log都看什么?这个大家都知道要看http的状态码,分析里面返回的200,304,404等等通过这些来看看服务器是不是不稳定,看看屏蔽一些页面等等.
再者就是看看spider爬行的频率。看看spider爬为什么总是在这个时间爬取这个页面而是是频繁的爬取?为什么会爬取这个页面?
对比分析一下我们会发现
1. 一般凡是spider爬取的目录页面,他的搜索引擎的相关收录就会相对还得好一些。
2.在这个目录中的长尾词的排名也相对的好一些。
那么根据这个我们为什么不投“蛛”所好呢?不是有句话吗:爱它就给它(我也不知道出处)。
问题又来了,要投其所好也要知道spider为什么会喜欢这个页面?为什么要频繁的爬取它,到底是什么吸引了它。所以我们就要对这个页面进行分析:
分析一下spider到底喜欢什么样的东西
1. 更新速度快的页面。这个页面的内容更新的频率很快,每次spider爬取的时候它总是有新的内容,就好像去报亭买报纸,每天去一个报亭买报纸,相同的时间相同的地点,相同的位置,不同的内容更新的报纸。你可以付钱拿起来就走不用啰嗦!我想这样谁都喜欢。
2. 网页的内容丰富。同样是报纸的例子,每次去买相同的报纸,但是你慢慢的发现报纸的内容就是那么窄窄的一个方面,想看国内文章他只有地方的,想看国际的文章他还是只有地方的。慢慢的我想你也会考虑换一家。但是如果内容丰富想看什么内容都有即使旁边的地方报纸包装的在好你也会选这个内容丰富的.
3. 内容的重复性低。这个就很好理解了,谁喜欢天天看一样的东西。一期的报纸每个版面都重复的在说一个事情会让人很烦的。
以上就是我对log的一点理解,也许大家都知道。这是我的一点想法想拿出来和大家分享一下

CrawlSpider爬虫
CrawlSpider
在上一个糗事百科的爬虫案例中。我们是自己在解析完整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过是在之前的基础之上增加了新的功能,可以定义爬取的url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
CrawlSpider爬虫:
创建CrawlSpider爬虫:
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -t crawl [爬虫名字] [域名]
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = (''a'',''area''),
attrs = (''href''),
canonicalize = True,
unique = True,
process_value = None
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
微信小程序社区CrawlSpider案例
CrawlSpider
在上一个糗事百科的爬虫案例中。我们是自己在解析完整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过是在之前的基础之上增加了新的功能,可以定义爬取的url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
CrawlSpider爬虫:
创建CrawlSpider爬虫:
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -c crawl [爬虫名字] [域名]
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = (''a'',''area''),
attrs = (''href''),
canonicalize = True,
unique = True,
process_value = None
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
微信小程序社区CrawlSpider案例
CrawlSpider
在上一个糗事百科的爬虫案例中。我们是自己在解析完整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过是在之前的基础之上增加了新的功能,可以定义爬取的url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
CrawlSpider爬虫:
创建CrawlSpider爬虫:
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -c crawl [爬虫名字] [域名]
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = (''a'',''area''),
attrs = (''href''),
canonicalize = True,
unique = True,
process_value = None
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
微信小程序社区CrawlSpider案例
CrawlSpider
在上一个糗事百科的爬虫案例中。我们是自己在解析完整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过是在之前的基础之上增加了新的功能,可以定义爬取的url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
CrawlSpider爬虫:
创建CrawlSpider爬虫:
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -c crawl [爬虫名字] [域名]
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = (''a'',''area''),
attrs = (''href''),
canonicalize = True,
unique = True,
process_value = None
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
微信小程序社区CrawlSpider案例
CrawlSpider
在上一个糗事百科的爬虫案例中。我们是自己在解析完整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过是在之前的基础之上增加了新的功能,可以定义爬取的url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
CrawlSpider爬虫:
创建CrawlSpider爬虫:
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -t crawl [爬虫名字] [域名]
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = (''a'',''area''),
attrs = (''href''),
canonicalize = True,
unique = True,
process_value = None
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类:
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
微信小程序社区CrawlSpider案例
一、创建爬虫项目
scrapy genspider -t crawl wxapp_spider wxapp-union.com
二、代码
修改settings.py文件:
1 # -*- coding: utf-8 -*-
2
3 BOT_NAME = ''wxapp''
4
5 SPIDER_MODULES = [''wxapp.spiders'']
6 NEWSPIDER_MODULE = ''wxapp.spiders''
7
8
9 # Obey robots.txt rules
10 ROBOTSTXT_OBEY = False
11
12
13 # Configure a delay for requests for the same website (default: 0)
14 # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
15 # See also autothrottle settings and docs 设置访问页面的延时,防止频繁访问页面被反爬
16 DOWNLOAD_DELAY = 1
17
18 # Override the default request headers:
19 DEFAULT_REQUEST_HEADERS = {
20 ''Accept'': ''text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'',
21 ''Accept-Language'': ''en'',
22 ''User-Agent'': ''Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36''
23 }
24
25
26 # Configure item pipelines
27 # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
28 ITEM_PIPELINES = {
29 ''wxapp.pipelines.WxappPipeline'': 300,
30 }wxapp_spider.py文件
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from scrapy.linkextractors import LinkExtractor
4 from scrapy.spiders import CrawlSpider, Rule
5 from wxapp.items import WxappItem
6
7
8 class WxappSpiderSpider(CrawlSpider):
9 name = ''wxapp_spider''
10 allowed_domains = [''wxapp-union.com'']
11 start_urls = [''http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1'']
12
13 rules = (
14 Rule(LinkExtractor(allow=r''.+mod=list&catid=2&page=\d+''), follow=True),
15 Rule(LinkExtractor(allow=r''.+/article-\d+-1\.html''), callback=''parse_item'', follow=False)
16 )
17
18 def parse_item(self, response):
19 title = response.xpath(''//h1/text()'').get()
20 author = response.xpath(''//p[@]/a/text()'').get()
21 time = response.xpath(''//p[@]//span[@]/text()'').get()
22 content = response.xpath(''//td[@id="article_content"]//text()'').getall()
23 content = "".join(content).strip()
24 item = WxappItem(title=title, author=author, time=time, content=content)
25 yield item #这里return item一样可以.因为只需要返回一个item给pipe处理items.py文件
# -*- coding: utf-8 -*-
import scrapy
class WxappItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
time = scrapy.Field()
content = scrapy.Field()pipelines.py文件
1 # -*- coding: utf-8 -*-
2
3 # Define your item pipelines here
4 #
5 # Don''t forget to add your pipeline to the ITEM_PIPELINES setting
6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
7 from scrapy.exporters import JsonLinesItemExporter
8
9
10 class WxappPipeline(object):
11 def __init__(self):
12 self.fp = open("wxjc.json", ''wb'')
13 self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding=''utf-8'')
14
15 def process_item(self, item, spider):
16 self.exporter.export_item(item)
17 return item #这里一定要return,如果有多个pipelines的话,不返回就不能给其他的pipeline用了
18
19 def close_spider(self, spider):
20 self.fp.close()运行结果:
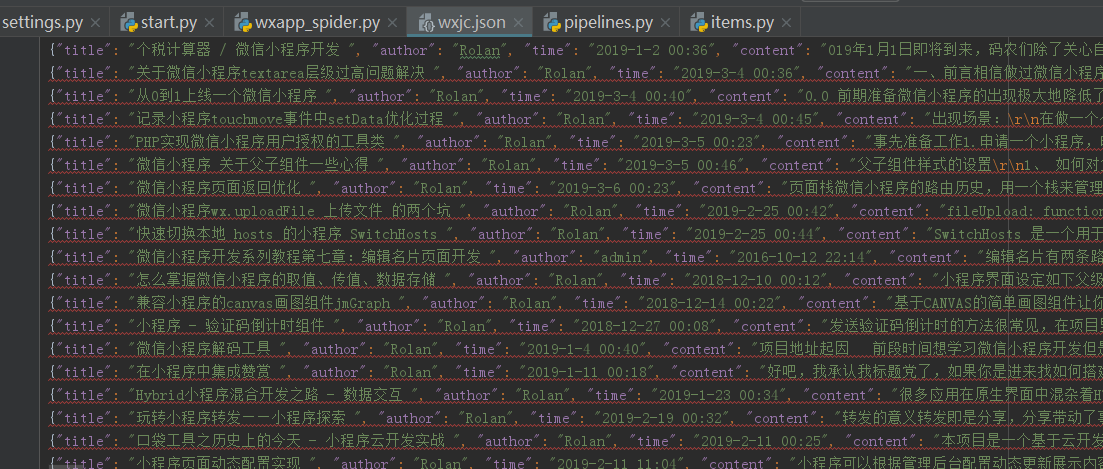
笔记:
rules = (
Rule(LinkExtractor(allow=r''.+mod=list&catid=2&page=\d+''), follow=True),
Rule(LinkExtractor(allow=r''.+/article-\d+-1\.html''), callback=''parse_item'', follow=False)
)在写规则的时候,注意正则中的.和?号要转义,不然正则会错误!!
关于CrawlSpider爬虫,是在页面中查找所有符合正则规则的链接,如果需要进入链接继续跟进,那么就设置follow为True,如果只是需要提取这个链接的数据,那么只需要设置callback,并设置follow为False.
在运行的时候,这个爬虫并不会按照顺序依次一页一页的爬取,看起来好像有点随机爬取页面.
爬虫能自己去重,所以也不要担心有重复数据

docker怎么查看网络详情

1、查看网络列表
命令:
docker network ls

2、查看网络详情
命令格式:
docker network inspect [OPTIONS] NETWORK [NETWORK...]
如下图所示:

推荐教程:docker/" target="_blank">docker教程
以上就是

moo日记怎么查看自己的日记
可以通过以下步骤查看你的 moo 日记:1. 打开应用程序并登录你的帐户;2. 点击“日记”选项卡;3. 查看日记条目列表,最新条目显示在顶部;4. 点击特定条目查看详细信息;5. 点击日记本名称切换日记本;6. 使用搜索图标查找条目。

如何查看你的 moo 日记
1. 打开 moo 日记应用程序
- 在你的移动设备或平板电脑上找到并点击 moo 日记图标。
2. 登入你的账号
- 如果需要,输入你的电子邮件地址和密码以登入。
3. 前往“日记”选项卡
- 应用程序底部会有一个导航栏。点击“日记”选项卡。
4. 查看你的日记条目
- 你会看到一个带有所有日记条目的列表。
- 最新条目将显示在顶部。
- 点击任何条目以查看详细信息。
5. 浏览不同日记本
- 如果你创建了多个日记本,可以点击屏幕顶部的日记本名称来切换。
6. 搜索你的日记
- 如果要查找特定条目,可以点击屏幕右上角的放大镜图标,然后输入你的搜索词。
7. 其他选项
-
点击日记条目后,你可以:
- 编辑条目
- 删除条目
- 添加标签
- 与他人分享条目
以上就是moo日记怎么查看自己的日记的详细内容,更多请关注php中文网其它相关文章!

moo日记怎么查看自己的日记本
要查看 moo 日记本,请在 moo 网站上登陆账户,然后转到“账户设置”中“我的日记本”选项卡,即可查看全部日记本列表和内容。

如何查看 Moo 日记本
要查看 Moo 日记本,请按照以下步骤操作:
1. 登陆 Moo 网站:
访问 Moo 网站:https://www.moo.com/。
2. 登陆账户:
点击页面右上角的“登陆”按钮,然后使用您的电子邮件地址和密码登陆账户。
3. 前往我的日记本:
登陆后,点击页面顶部的“账户设置”。
在左侧菜单中,选择“我的日记本”。
4. 查看日记本:
在“我的日记本”页面,您将看到您创建的所有日记本列表。
点击您想要查看的日记本,即可查看日记本中的内容。
提示:
- 您还可以在 Moo
- 如果您忘记了密码,可以点击“忘记密码?”链接重置密码。
- 如果您在查看日记本时遇到任何问题,请联系 Moo 客服以寻求帮助。
以上就是moo日记怎么查看自己的日记本的详细内容,更多请关注php中文网其它相关文章!
今天关于怎么查看网站的日记spider爬行和怎么看网站日志的介绍到此结束,谢谢您的阅读,有关CrawlSpider爬虫、docker怎么查看网络详情、moo日记怎么查看自己的日记、moo日记怎么查看自己的日记本等更多相关知识的信息可以在本站进行查询。
本文标签:




