此处将为大家介绍关于聊聊MongoDB的详细内容,并且为您解答有关五AggregateDemo的相关问题,此外,我们还将为您介绍关于com.mongodb.client.model.Aggregate
此处将为大家介绍关于聊聊MongoDB的详细内容,并且为您解答有关五Aggregate Demo的相关问题,此外,我们还将为您介绍关于com.mongodb.client.model.Aggregates的实例源码、egg学习笔记第二十一天:MongoDB的高级查询aggregate聚合管道、golang mongodb Aggregate、Mongodb aggregate timezone 问题的有用信息。
本文目录一览:- 聊聊MongoDB(五)Aggregate Demo(mongodb aggregate project)
- com.mongodb.client.model.Aggregates的实例源码
- egg学习笔记第二十一天:MongoDB的高级查询aggregate聚合管道
- golang mongodb Aggregate
- Mongodb aggregate timezone 问题
Aggregate Demo(mongodb aggregate project)")
聊聊MongoDB(五)Aggregate Demo(mongodb aggregate project)
首先列出所需部分数据
集合user:
/* 1 */
{
"_id" : 1.0,
"hire" : ISODate("2016-12-15T02:52:04.630Z")
}
/* 2 */
{
"_id" : 2.0,
"chinese" : 80.0,
"math" : 90.0,
"name" : "lisi"
}
/* 3 */
{
"_id" : 3.0,
"chinese" : 70.0,
"math" : 90.0,
"name" : "wangwu"
}
/* 4 */
{
"_id" : 4.0,
"name" : "zs",
"chinese" : 50,
"math" : 60
}集合date:
/* 1 */
{
"_id" : 1,
"hire" : ISODate("2016-12-20T08:37:15.705Z")
}集合mycol:
/* 1 */
{
"_id" : ObjectId("57ec6d0d7fbbc90bccc18e13"),
"title" : "MongoDB1",
"description" : "nosql",
"likes" : 0,
"by_user" : "lzq"
}
/* 2 */
{
"_id" : ObjectId("57ec6d0d7fbbc90bccc18e14"),
"title" : "MongoDB2",
"description" : "nosql",
"likes" : 2,
"by_user" : "lzq"
}
/* 3 */
{
"_id" : ObjectId("57ec6d0d7fbbc90bccc18e15"),
"title" : "MongoDB3",
"description" : "nosql",
"likes" : 3,
"by_user" : "lzq"
}集合tree:
/* 1 */
{
"_id" : ObjectId("584e47110dc763ff7e50347b"),
"management" : {
"organization" : [
{
"name" : "Organizational institution",
"index" : 1.0
},
{
"name" : "Company files",
"index" : 2.0
},
{
"name" : "department files",
"index" : 3.0
}
],
"authority" : [
{
"name" : "user",
"sequence" : 100.0
},
{
"name" : "role",
"sequence" : 102.0
},
{
"name" : {
"source_register" : [
{
"name" : "button"
},
{
"name" : "field"
}
]
},
"sequence" : 103.0
}
]
},
"num" : 1.0
}Code:
聚合操作所有JSON定义类
package db.mongo.feature.util;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.Arrays;
import java.util.List;
public class AggregateJson{
//$project操作
public static final String USERPROJECT = "{$project:{\"userid\":\"$_id\",\"_id\":0}}";
//$project操作与$add操作(示例:perStuTotalScore)
public static final String PROJECT_ADD = "{\n" +
" $project:{\n" +
" chinese:1,\n" +
" math:1,\n" +
" totalgrade:{$add:[\"$chinese\",\"$math\"]}\n" +
" }\n" +
" }";
//日期操作(示例date集合)
public static final String DATE_EXPRESSION = "{\n" +
" $project:\n" +
" {\n" +
" year: { $year: \"$hire\" },\n" +
" month: { $month: \"$hire\" },\n" +
" day: { $dayOfMonth: \"$hire\" },\n" +
" hour: { $hour: \"$hire\" },\n" +
" minutes: { $minute: \"$hire\" },\n" +
" seconds: { $second: \"$hire\" },\n" +
" milliseconds: { $millisecond: \"$hire\" },\n" +
" dayOfYear: { $dayOfYear: \"$hire\" },\n" +
" dayOfWeek: { $dayOfWeek: \"$hire\" },\n" +
" week: { $week: \"$hire\" }\n" +
" }\n" +
" }";
//截取name的第一个字节,与.和$sex值拼接(示例mycol集合)
public static final String[] PROJECT_CONCAT_SUBSTR = {"{$project:{\"title\":{\n" +
" $concat:[\"$by_user\",\".\",{$substr:[\"$title\",5,8]}]\n" +
" }}}","{$limit:2}"};
//比较两个数值大小(示例user集合)
public static final String PROJECT_CMP = "{\n" +
" $project:{\n" +
" chinese:1,\n" +
" math:1,\n" +
" compareTo:{$cmp:[\"$chinese\",\"$math\"]}\n" +
" }\n" +
" }";
public static final String[] PRJECT_GROUP_SORT_LIMIT = {"{ \n" +
" $project: {\n" +
" \"name\": 1,\n" +
" \"chinese\":1,\n" +
" \"math\":1\n" +
" }\n" +
" }", "{ $group: { _id: \"$name\" ,totalScore:{$sum:{$add:[\"$chinese\",\"$math\"]}}} }", "{\n" +
" $sort: {\n" +
" \"totalScore\": -1\n" +
" }\n" +
" }", "{\n" +
" $limit: 3\n" +
" }"};
public static final String PROJECT_COND = "{\n" +
" $project:\n" +
" {\n" +
" \n" +
" discount:\n" +
" {\n" +
" $cond: { if: { $gte: [ \"$chinese\", 60 ] }, then: \"$chinese\", else: \"不合格\" }\n" +
" }\n" +
" }\n" +
" }";
public static final String UNWIND = "{$unwind:\"$management.organization\"}";
public static final String DISTINCT = "{\"distinct\":\"user\",\"key\":\"chinese\"}";
}
聚合操作类:
package db.mongo.feature;
import com.mongodb.AggregationOptions;
import com.mongodb.GroupCommand;
import com.mongodb.MongoClient;
import com.mongodb.client.*;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.FindOptions;
import com.mongodb.client.model.Projections;
import com.mongodb.client.model.Sorts;
import com.mongodb.operation.GroupOperation;
import db.mongo.feature.util.AggregateJson;
import db.mongo.util.Constants;
import org.apache.log4j.Logger;
import org.bson.BsonDocument;
import org.bson.Document;
import org.bson.conversions.Bson;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class MongoAggregate {
/*
聚合:对集合中的文档进行变换和组合,可对文档进行一连串的处理.
$match $project $group $unwind $limit $skip $sort...
需要将聚合操作传给aggregate,db.articles.aggregate如果不是从数据库返回的集合,那么Mongo Shell会自动迭代20次
MongoDB不允许管道占用很多内存,如20%,会直接报错
*/
/*$project代表将articles集合投射出author字段,结果集中只包含_id和author字段;
$match匹配以x开头的author;
然后"_id":"$author"指定了分组字段author;
$group会在结果集中创建count字段,执行结果类似这样的结构:{ "_id" : "xiaobao", "count" : 10 };
$sort按照count字段将以上结果排序;
$limit将限制返回结果集的前三个文档
"$filename"是为了引用字段的值
*/
private static Logger logger = Logger.getLogger(MongoAggregate.class);
MongoDatabase database = null;
public MongoCollection<Document> getCollection(String collectionName) {
return this.database.getCollection(collectionName);
}
@Before
public void connect(){
MongoClient client = new MongoClient(Constants.MONGO_HOST,Constants.MONGO_PORT);
//当前获取这个数据库时并没有这个名称的数据库,不会报错,当有数据添加的时候才会创建
database = client.getDatabase("test");
}
/**
* @param collection 接收一个指定的mongo集合
* @param jsons 接收json数组,用来聚合查询时解析多个json过滤条件
*
* 接收多个json字符串
*/
public void aggregate(MongoCollection<Document> collection,String... jsons){
List<Document> pileline = new ArrayList<Document>();
for (String json : jsons){
pileline.add(Document.parse(json));
}
List<Document> results = collection.aggregate(pileline).into(new ArrayList<Document>());
for (Document cur : results) {
System.out.println(cur.toJson());
}
}
/**
* 测试所有聚合操作
*/
@Test
public void testAggregate() {
/*$project操作
MongoCollection<Document> collection = getCollection("user");
aggregate(collection, AggregateJson.USERPROJECT);
*/
/*查询日期
MongoCollection<Document> collection = getCollection("date");
aggregate(collection, AggregateJson.DATE_EXPRESSION);*/
//$project操作与$add操作(示例:perStuTotalScore)
/*MongoCollection<Document> collection = getCollection("user");
aggregate(collection, AggregateJson.PROJECT_ADD);*/
//截取name的第一个字节,与.和$sex值拼接(示例mycol集合)
/*MongoCollection<Document> collection = getCollection("mycol");
aggregate(collection, AggregateJson.PROJECT_CONCAT_SUBSTR);*/
//学生总成绩排名前三甲
/*MongoCollection<Document> collection = getCollection("user");
aggregate(collection, AggregateJson.PRJECT_GROUP_SORT_LIMIT);*/
/*比较成绩高低,返回比较记录,类似java的Comparable比较器的compareTo方法,返回1,0,-1*/
/*MongoCollection<Document> collection = getCollection("user");
aggregate(collection, AggregateJson.PROJECT_CMP);*/
//判断语文成绩大小,如果大于60分显示其分数,如果小于60分则显示不合格,如果没有这个字段也会显示不合格
/*MongoCollection<Document> collection = getCollection("user");
aggregate(collection, AggregateJson.PROJECT_COND);*/
//将数组的每个值拆分为单独的文档
/*MongoCollection<Document> collection = getCollection("tree");
aggregate(collection, AggregateJson.UNWIND);*/
//distinct找出给定键不同的值,找出不同的语文成绩
/* Document document = database.runCommand(Document.parse(AggregateJson.DISTINCT));
System.out.println(document.toJson());*/
}
}

com.mongodb.client.model.Aggregates的实例源码
/**
* Takes `uploadID` and returns all bed names as a json format string
* @param uploadID - the year that the data was uploaded
* @return String representation of json with all bed names
*/
public String getGardenLocationsAsJson(String uploadID){
AggregateIterable<Document> documents
= plantCollection.aggregate(
Arrays.asList(
Aggregates.match(eq("uploadID",uploadID)),//!! Order is important here
Aggregates.group("$gardenLocation"),Aggregates.sort(Sorts.ascending("_id"))
));
List<Document> listDoc = new ArrayList<>();
for (Document doc : documents) {
listDoc.add(doc);
}
listDoc.sort(new bedComparator());
return JSON.serialize(listDoc);
}
/**
*
* @return a date-sorted List of all the distinct uploadIds in the DB
*/
public static List<String> listUploadIds(MongoDatabase database) {
MongoCollection<Document> plantCollection = database.getCollection("plants");
AggregateIterable<Document> documents
= plantCollection.aggregate(
Arrays.asList(
Aggregates.group("$uploadId"),Aggregates.sort(Sorts.ascending("_id"))
));
List<String> lst = new LinkedList<>();
for(Document d: documents) {
lst.add(d.getString("_id"));
}
return lst;
}
public int returnValuetoURL(String URL)
{
Block<Document> printBlock = new Block<Document>() {
@Override
public void apply(final Document document) {
System.out.println(document.toJson());
}
};
MongoCollection<Document> collection = db.getCollection("ratings");
collection.aggregate(
Arrays.asList(
Aggregates.group("URL",Accumulators.avg("rating",1))))
.forEach(printBlock);
System.out.println(printBlock.toString());
return 0;
}
@Test
public void ageCounts() {
AggregateIterable<Document> documents
= userDocuments.aggregate(
Arrays.asList(
/*
* Groups data by the "age" field,and then counts
* the number of documents with each given age.
* This creates a new "constructed document" that
* has "age" as it's "_id",and the count as the
* "ageCount" field.
*/
Aggregates.group("$age",Accumulators.sum("ageCount",1)),Aggregates.sort(Sorts.ascending("_id"))
)
);
List<Document> docs = intoList(documents);
assertEquals("Should be two distinct ages",2,docs.size());
assertEquals(docs.get(0).get("_id"),25);
assertEquals(docs.get(0).get("ageCount"),1);
assertEquals(docs.get(1).get("_id"),37);
assertEquals(docs.get(1).get("ageCount"),2);
}
@Test
public void averageAge() {
AggregateIterable<Document> documents
= userDocuments.aggregate(
Arrays.asList(
Aggregates.group("$company",Accumulators.avg("averageAge","$age")),Aggregates.sort(Sorts.ascending("_id"))
));
List<Document> docs = intoList(documents);
assertEquals("Should be three companies",3,docs.size());
assertEquals("Frogs,Inc.",docs.get(0).get("_id"));
assertEquals(37.0,docs.get(0).get("averageAge"));
assertEquals("IBM",docs.get(1).get("_id"));
assertEquals(37.0,docs.get(1).get("averageAge"));
assertEquals("UMM",docs.get(2).get("_id"));
assertEquals(25.0,docs.get(2).get("averageAge"));
}
@Test
public void ageCounts() {
AggregateIterable<Document> documents
= userDocuments.aggregate(
Arrays.asList(
/*
* Groups data by the "age" field,2);
}
@Test
public void averageAge() {
AggregateIterable<Document> documents
= userDocuments.aggregate(
Arrays.asList(
Aggregates.group("$company",docs.get(2).get("averageAge"));
}
@Test
public void ageCounts() {
AggregateIterable<Document> documents
= userDocuments.aggregate(
Arrays.asList(
/*
* Groups data by the "age" field,2);
}
@Test
public void averageAge() {
AggregateIterable<Document> documents
= userDocuments.aggregate(
Arrays.asList(
Aggregates.group("$company",docs.get(2).get("averageAge"));
}
private static List<Bson> getServerQuery(Bson filter) {
final List<Bson> pipeline = new ArrayList<>(6);
if (filter != ALL) {
pipeline.add(Aggregates.match(filter));
}
pipeline.add(Aggregates.unwind("$deployments",new UnwindOptions().preserveNullAndEmptyArrays(true)));
pipeline.add(Aggregates.lookup(Collections.APPLICATIONS,"deployments.applicationId","id","applications"));
pipeline.add(Aggregates.unwind("$applications",new UnwindOptions().preserveNullAndEmptyArrays(true)));
pipeline.add(Aggregates.group(
new Document().append("hostname","$hostname").append("environment","$environment"),new BsonField("fqdn",new Document("$first","$fqdn")),new BsonField("description","$description")),new BsonField("os","$os")),new BsonField("network","$network")),new BsonField("Meta","$Meta")),new BsonField("attributes","$attributes")),new BsonField("applications",new Document("$push","$applications")),new BsonField("deployments","$deployments"))));
pipeline.add(Aggregates.sort(Sorts.ascending("_id")));
return pipeline;
}
/**
* Get a json containing a list of commonNames sorted by common name
* @param uploadID
* @return
*/
public String getCommonNamesJSON(String uploadID){
if (!ExcelParser.isValidUploadId(db,uploadID))
return "null";
AggregateIterable<Document> documents
= plantCollection.aggregate(
Arrays.asList(
Aggregates.match(eq("uploadId",//!! Order is important here
Aggregates.group("$commonName"),Aggregates.sort(Sorts.ascending("commonName"))
));
return JSON.serialize(documents);
}
public String getGardenLocationsAsJson(String uploadID) {
AggregateIterable<Document> documents
= plantCollection.aggregate(
Arrays.asList(
Aggregates.match(eq("uploadId",Aggregates.sort(Sorts.ascending("_id"))
));
return JSON.serialize(documents);
}
/**
*
* @return a sorted JSON array of all the distinct uploadIds in the DB
*/
public String listUploadIds() {
AggregateIterable<Document> documents
= plantCollection.aggregate(
Arrays.asList(
Aggregates.group("$uploadId"),Aggregates.sort(Sorts.ascending("_id"))
));
List<String> lst = new LinkedList<>();
for(Document d: documents) {
lst.add(d.getString("_id"));
}
return JSON.serialize(lst);
// return JSON.serialize(plantCollection.distinct("uploadId","".getClass()));
}
/**
*
* @return a sorted JSON array of all the distinct uploadIDs in plant collection of the DB
*/
public List<String> listUploadIDs() {
AggregateIterable<Document> documents
= plantCollection.aggregate(
Arrays.asList(
Aggregates.group("$uploadID"),Aggregates.sort(Sorts.ascending("_id"))
));
List<String> lst = new LinkedList<>();
for(Document d: documents) {
lst.add(d.getString("_id"));
}
return lst;
// return JSON.serialize(plantCollection.distinct("uploadID","".getClass()));
}
public List<SyncNodeDetails> getNodeDetails(String lifeCycle) {
UnwindOptions options = new UnwindOptions();
options.preserveNullAndEmptyArrays(true);
Document group = new Document("$group",new Document(SyncAttrs.ID,new Document("_id","$_id").append("host","$host").append("node","$node").append("state","$state")
.append("concurrencyLevel","$concurrencyLevel").append("totalHeapSize","$totalHeapSize")
.append("usedHeapSize","$usedHeapSize").append("lifeCycle","$lifeCycle"))
.append("eventArr",new Document("$addToSet","$event_docs")));
return migrationNodeMapping.aggregate(Arrays.asList(Aggregates.match(Filters.eq(SyncAttrs.LIFE_CYCLE,lifeCycle)),Aggregates.unwind("$activeEvents",options),Aggregates.lookup("SyncEvents","activeEvents","_id","event_docs"),Aggregates.unwind("$event_docs",group,Aggregates.project(new Document("node","$_id").append("events","$eventArr").append("_id",false))),SyncNodeDetails.class)
.into(new ArrayList<SyncNodeDetails>());
}
public Syncmarker getEventStats(ObjectId eventId) {
Document group = new Document("$group",null).append(SyncAttrs.TOTAL_ROWS,new Document("$sum","$marker.totalRows"))
.append(SyncAttrs.ROWS_READ,"$marker.rowsRead"))
.append(SyncAttrs.ROWS_DUMPED,"$marker.rowsDumped"))
.append(SyncAttrs.START_TIME,new Document("$min","$marker.startTime"))
.append(SyncAttrs.END_TIME,new Document("$max","$marker.endTime")));
return syncEvents.aggregate(Arrays.asList(Aggregates.match(Filters.eq(SyncAttrs.PARENT_EVENT_ID,eventId)),Aggregates.project(Projections.include(SyncAttrs.MARKER)),group),Syncmarker.class).first();
}
public List<SyncError> getEventErrors(ObjectId eventId) {
Document group = new Document("$group",null).append(SyncAttrs.ERRORS,"$errors")));
return syncEvents.aggregate(
Arrays.asList(Aggregates.match(Filters.eq(SyncAttrs.PARENT_EVENT_ID,Aggregates.unwind("$errors"),Aggregates
.project(Projections.include(SyncAttrs.ERRORS)),Aggregates.project(new Document(SyncAttrs.ERROR_MESSAGE,"$errors.errorMessage")
.append(SyncAttrs.TRACE,"$errors.trace")
.append(SyncAttrs.THREAD_NAME,"$errors.threadName"))),SyncError.class).allowdiskUse(true).into(new ArrayList<SyncError>());
}
public String getAverageAgeByCompany() {
AggregateIterable<Document> documents
= userCollection.aggregate(
Arrays.asList(
Aggregates.group("$company",Aggregates.sort(Sorts.ascending("_id"))
));
System.err.println(JSON.serialize(documents));
return JSON.serialize(documents);
}
@Test
public void testAggregate()
{
List<Document> docList = new ArrayList<Document>();
coll.aggregate(Arrays.asList(Aggregates.match(Filters.eq("name","Alto")),Aggregates.group("color",Accumulators.sum("count",1)))).into(docList);
assertEquals(1,docList.size());
docList.clear();
Document first = coll
.aggregate(Arrays.asList(Aggregates.match(Filters.eq("name",1))),Document.class)
.allowdiskUse(true).batchSize(12).bypassDocumentValidation(true).collation(Collation.builder().build())
.first();
Assert.assertNotNull(first);
first = coll
.aggregate(Arrays.asList(Aggregates.match(Filters.eq("name",Document.class)
.allowdiskUse(true).batchSize(12).bypassDocumentValidation(true).collation(Collation.builder().build())
.map(new Function<Document,Document>()
{
@Override
public Document apply(Document t)
{
t.put("hello","world");
return t;
}
}).first();
Assert.assertNotNull(first);
}
@Test
public void testFilterParametersBsonDocumentMatchInAndEq()
{
Bson in = Filters.in("dateKey","593898622313868b72a296ad","593898622313868b72a296b4");
Bson eq = Filters.eq("eqfield","123");
Bson and = Filters.and(in,eq);
Bson match = Aggregates.match(and);
BsonDocument filterParameters = MongoUtilities.filterParameters(match);
assertEquals("{ \"$match\" : { \"dateKey\" : { \"$in\" : [\"*?\"] },\"eqfield\" : \"?\" } }",filterParameters.toString());
}
@Test
public void testFilterParametersBsonDocumentMatchInorEq()
{
Bson in = Filters.in("dateKey","123");
Bson or = Filters.or(in,eq);
Bson match = Aggregates.match(or);
BsonDocument filterParameters = MongoUtilities.filterParameters(match);
assertEquals("{ \"$match\" : { \"$or\" : [{ \"dateKey\" : { \"$in\" : [\"*?\"] } },{ \"eqfield\" : \"?\" }] } }",filterParameters.toString());
}
private PaginatedCollection<Application> findApplications(Bson filter) {
final List<Bson> pipeline = new ArrayList<>(2);
if (filter != ALL) {
pipeline.add(Aggregates.match(filter));
}
pipeline.add(Aggregates.lookup(Collections.GROUPS,"group","group"));
return RestHelper.paginatedList(database
.getCollection(Collections.APPLICATIONS)
.aggregate(pipeline)
.map(Application::new)
);
}
private Document findApplication(Bson filter) {
final Document bson = database.getCollection(Collections.APPLICATIONS)
.aggregate(Lists.newArrayList(
Aggregates.match(filter),Aggregates.lookup(Collections.GROUPS,"group")
)).first();
if (bson == null) {
throw new WebApplicationException(Status.NOT_FOUND);
}
return bson;
}
private Map<String,Group> getAllGroups() {
return Maps.uniqueIndex(database
.getCollection(Collections.GROUPS)
.aggregate(Lists.newArrayList(
Aggregates.lookup(Collections.APPLICATIONS,"applications"),Aggregates.lookup(Collections.ASSETS,"assets")
)).map(Group::new),t->t.id
);
}
private PaginatedCollection<Tag> getTags() {
return RestHelper.paginatedList(database
.getCollection(Collections.GROUPS)
.aggregate(Lists.newArrayList(
Aggregates.unwind("$tags"),Aggregates.group("$tags")
)).map(t->new Tag(t.getString("_id")))
);
}
private List<String> getRootGroupIds(Optional<Function<String,Bson>> filterProvider) {
final List<Bson> pipeline = new ArrayList<>(5);
/*
* Optional filter,needs to be applied both before and after self join to include
* groups with inbound links from non tagged groups
*/
Bson inboundLinksFilter = Filters.size("inbound_links",0);
if (filterProvider.isPresent()) {
final Bson tagFilter = filterProvider.get().apply("tags");
pipeline.add(Aggregates.match(tagFilter));
final Bson inboundLinksTagFilter = filterProvider.get().apply("inbound_links.tags");
inboundLinksFilter = Filters.or(inboundLinksFilter,Filters.not(inboundLinksTagFilter));
}
// Unwind groups field to be able to self-join
pipeline.add(Aggregates.unwind("$groups",new UnwindOptions().preserveNullAndEmptyArrays(true)));
// Self join on inbound references: group.groups -> group.id and filter no inbound references
pipeline.add(Aggregates.lookup(Collections.GROUPS,"groups.id","inbound_links"));
pipeline.add(Aggregates.match(inboundLinksFilter));
// Group on id to get distinct group names
pipeline.add(Aggregates.group("$id"));
return database
.getCollection(Collections.GROUPS)
.aggregate(pipeline)
.map(t->t.getString("_id"))
.into(Lists.newArrayList());
}
private PaginatedCollection<String> getEnvironments() {
return RestHelper.paginatedList(database
.getCollection(Collections.SERVERS)
.aggregate(Lists.newArrayList(
Aggregates.group("$environment")
)).map(t->t.getString("_id"))
);
}
private PaginatedCollection<Asset> findAssets(Bson filter) {
final List<Bson> pipeline = new ArrayList<>(2);
if (filter != ALL) {
pipeline.add(Aggregates.match(filter));
}
pipeline.add(Aggregates.lookup(Collections.GROUPS,"group"));
return RestHelper.paginatedList(database
.getCollection(Collections.ASSETS)
.aggregate(pipeline)
.map(Asset::new)
);
}
private Document findAsset(Bson filter) {
final Document bson = database.getCollection(Collections.ASSETS)
.aggregate(Lists.newArrayList(
Aggregates.match(filter),"group")
)).first();
if (bson == null) {
throw new WebApplicationException(Status.NOT_FOUND);
}
return bson;
}
/**
* Create a pipeline query node based on a StatementPattern.
* @param collection The collection of triples to query.
* @param baseSP The leaf node in the query tree.
*/
public AggregationPipelineQueryNode(MongoCollection<Document> collection,StatementPattern baseSP) {
this.collection = Preconditions.checkNotNull(collection);
Preconditions.checkNotNull(baseSP);
this.varToOriginalName = HashBiMap.create();
StatementvarMapping mapping = new StatementvarMapping(baseSP,varToOriginalName);
this.assuredBindingNames = new HashSet<>(mapping.varNames());
this.bindingNames = new HashSet<>(mapping.varNames());
this.pipeline = new LinkedList<>();
this.pipeline.add(Aggregates.match(getMatchExpression(baseSP)));
this.pipeline.add(Aggregates.project(mapping.getProjectExpression()));
}
/**
* Add a $group step to filter out redundant solutions.
* @return True if the distinct operation was successfully appended.
*/
public boolean distinct() {
List<String> key = new LinkedList<>();
for (String varName : bindingNames) {
key.add(hashFieldExpr(varName));
}
List<BsonField> reduceOps = new LinkedList<>();
for (String field : FIELDS) {
reduceOps.add(new BsonField(field,"$" + field)));
}
pipeline.add(Aggregates.group(new Document("$concat",key),reduceOps));
return true;
}
/**
* Add a join with an individual {@link StatementPattern} to the pipeline.
* @param sp The statement pattern to join with
* @return true if the join was successfully added to the pipeline.
*/
public boolean joinWith(StatementPattern sp) {
Preconditions.checkNotNull(sp);
// 1. Determine shared variables and new variables
StatementvarMapping spMap = new StatementvarMapping(sp,varToOriginalName);
NavigableSet<String> sharedVars = new ConcurrentSkipListSet<>(spMap.varNames());
sharedVars.retainAll(assuredBindingNames);
// 2. Join on one shared variable
String joinKey = sharedVars.pollFirst();
String collectionName = collection.getNamespace().getCollectionName();
Bson join;
if (joinKey == null) {
return false;
}
else {
join = Aggregates.lookup(collectionName,HASHES + "." + joinKey,spMap.hashField(joinKey),JOINED_TRIPLE);
}
pipeline.add(join);
// 3. Unwind the joined triples so each document represents a binding
// set (solution) from the base branch and a triple that may match.
pipeline.add(Aggregates.unwind("$" + JOINED_TRIPLE));
// 4. (Optional) If there are any shared variables that weren't used as
// the join key,project all existing fields plus a new field that
// tests the equality of those shared variables.
BasicDBObject matchOpts = getMatchExpression(sp,JOINED_TRIPLE);
if (!sharedVars.isEmpty()) {
List<Bson> eqTests = new LinkedList<>();
for (String varName : sharedVars) {
String oldField = valueFieldExpr(varName);
String newField = joinFieldExpr(spMap.valueField(varName));
Bson eqTest = new Document("$eq",Arrays.asList(oldField,newField));
eqTests.add(eqTest);
}
Bson eqProjectOpts = Projections.fields(
Projections.computed(FIELDS_MATCH,Filters.and(eqTests)),Projections.include(JOINED_TRIPLE,VALUES,HASHES,TYPES,LEVEL,TIMESTAMP));
pipeline.add(Aggregates.project(eqProjectOpts));
matchOpts.put(FIELDS_MATCH,true);
}
// 5. Filter for solutions whose triples match the joined statement
// pattern,and,if applicable,whose additional shared variables
// match the current solution.
pipeline.add(Aggregates.match(matchOpts));
// 6. Project the results to include variables from the new SP (with
// appropriate renaming) and variables referenced only in the base
// pipeline (with prevIoUs names).
Bson finalProjectOpts = new StatementvarMapping(sp,varToOriginalName)
.getProjectExpression(assuredBindingNames,str -> joinFieldExpr(str));
assuredBindingNames.addAll(spMap.varNames());
bindingNames.addAll(spMap.varNames());
pipeline.add(Aggregates.project(finalProjectOpts));
return true;
}
/**
* Add a SPARQL filter to the pipeline,if possible. A filter eliminates
* results that don't satisfy a given condition. Not all conditional
* expressions are supported. If unsupported expressions are used in the
* filter,the pipeline will remain unchanged and this method will return
* false. Currently only supports binary {@link Compare} conditions among
* variables and/or literals.
* @param condition The filter condition
* @return True if the filter was successfully converted into a pipeline
* step,false otherwise.
*/
public boolean filter(ValueExpr condition) {
if (condition instanceof Compare) {
Compare compare = (Compare) condition;
Compare.CompareOp operator = compare.getoperator();
Object leftArg = valueFieldExpr(compare.getLeftArg());
Object rightArg = valueFieldExpr(compare.getRightArg());
if (leftArg == null || rightArg == null) {
// unsupported value expression,can't convert filter
return false;
}
final String opFunc;
switch (operator) {
case EQ:
opFunc = "$eq";
break;
case NE:
opFunc = "$ne";
break;
case LT:
opFunc = "$lt";
break;
case LE:
opFunc = "$le";
break;
case GT:
opFunc = "$gt";
break;
case GE:
opFunc = "$ge";
break;
default:
// unrecognized comparison operator,can't convert filter
return false;
}
Document compareDoc = new Document(opFunc,Arrays.asList(leftArg,rightArg));
pipeline.add(Aggregates.project(Projections.fields(
Projections.computed("FILTER",compareDoc),Projections.include(VALUES,TIMESTAMP))));
pipeline.add(Aggregates.match(new Document("FILTER",true)));
pipeline.add(Aggregates.project(Projections.fields(
Projections.include(VALUES,TIMESTAMP))));
return true;
}
return false;
}
/**
* Given that the current state of the pipeline produces data that can be
* interpreted as triples,add a project step to map each result from the
* intermediate result structure to a structure that can be stored in the
* triple store. Does not modify the internal pipeline,which will still
* produce intermediate results suitable for query evaluation.
* @param timestamp Attach this timestamp to the resulting triples.
* @param requireNew If true,add an additional step to check constructed
* triples against existing triples and only include new ones in the
* result. Adds a potentially expensive $lookup step.
* @throws IllegalStateException if the results produced by the current
* pipeline do not have variable names allowing them to be interpreted as
* triples (i.e. "subject","predicate",and "object").
*/
public List<Bson> getTriplePipeline(long timestamp,boolean requireNew) {
if (!assuredBindingNames.contains(SUBJECT)
|| !assuredBindingNames.contains(PREDICATE)
|| !assuredBindingNames.contains(OBJECT)) {
throw new IllegalStateException("Current pipeline does not produce "
+ "records that can be converted into triples.\n"
+ "required variable names: <" + SUBJECT + "," + PREDICATE
+ "," + OBJECT + ">\nCurrent variable names: "
+ assuredBindingNames);
}
List<Bson> triplePipeline = new LinkedList<>(pipeline);
List<Bson> fields = new LinkedList<>();
fields.add(Projections.computed(SUBJECT,valueFieldExpr(SUBJECT)));
fields.add(Projections.computed(SUBJECT_HASH,hashFieldExpr(SUBJECT)));
fields.add(Projections.computed(PREDICATE,valueFieldExpr(PREDICATE)));
fields.add(Projections.computed(PREDICATE_HASH,hashFieldExpr(PREDICATE)));
fields.add(Projections.computed(OBJECT,valueFieldExpr(OBJECT)));
fields.add(Projections.computed(OBJECT_HASH,hashFieldExpr(OBJECT)));
fields.add(Projections.computed(OBJECT_TYPE,ConditionalOperators.ifNull(typeFieldExpr(OBJECT),DEFAULT_TYPE)));
fields.add(Projections.computed(CONTEXT,DEFAULT_CONTEXT));
fields.add(Projections.computed(STATEMENT_MetaDATA,DEFAULT_MetaDATA));
fields.add(DEFAULT_DV);
fields.add(Projections.computed(TIMESTAMP,new Document("$literal",timestamp)));
fields.add(Projections.computed(LEVEL,new Document("$add",Arrays.asList("$" + LEVEL,1))));
triplePipeline.add(Aggregates.project(Projections.fields(fields)));
if (requireNew) {
// Prune any triples that already exist in the data store
String collectionName = collection.getNamespace().getCollectionName();
Bson includeAll = Projections.include(SUBJECT,SUBJECT_HASH,PREDICATE,PREDICATE_HASH,OBJECT,OBJECT_HASH,OBJECT_TYPE,CONTEXT,STATEMENT_MetaDATA,DOCUMENT_VISIBILITY,TIMESTAMP,LEVEL);
List<Bson> eqTests = new LinkedList<>();
eqTests.add(new Document("$eq",Arrays.asList("$$this." + PREDICATE_HASH,"$" + PREDICATE_HASH)));
eqTests.add(new Document("$eq",Arrays.asList("$$this." + OBJECT_HASH,"$" + OBJECT_HASH)));
Bson redundantFilter = new Document("$filter",new Document("input","$" + JOINED_TRIPLE)
.append("as","this").append("cond",new Document("$and",eqTests)));
triplePipeline.add(Aggregates.lookup(collectionName,JOINED_TRIPLE));
String numRedundant = "REDUNDANT";
triplePipeline.add(Aggregates.project(Projections.fields(includeAll,Projections.computed(numRedundant,new Document("$size",redundantFilter)))));
triplePipeline.add(Aggregates.match(Filters.eq(numRedundant,0)));
triplePipeline.add(Aggregates.project(Projections.fields(includeAll)));
}
return triplePipeline;
}
@Test
public void testFilterParametersBsonDocumentMatchIn()
{
Bson match = Aggregates.match(Filters.in("dateKey","593898622313868b72a296b4"));
BsonDocument filterParameters = MongoUtilities.filterParameters(match);
assertEquals("{ \"$match\" : { \"dateKey\" : { \"$in\" : [\"*?\"] } } }",filterParameters.toString());
}
@Test
public void testFilterParametersBsonDocumentGroup()
{
Bson group = Aggregates.group("_id",Accumulators.sum("totalQuantity","$quantity"));
BsonDocument filterParameters = MongoUtilities.filterParameters(group);
assertEquals("{ \"$group\" : { \"_id\" : \"_id\",\"totalQuantity\" : { \"$sum\" : \"$quantity\" } } }",filterParameters.toString());
}
@Test
public void testFilterParametersBsonDocumentLookup()
{
Bson lookup = Aggregates.lookup("fromField","localField","foreignField","as");
BsonDocument filterParameters = MongoUtilities.filterParameters(lookup);
assertEquals("{ \"$lookup\" : { \"from\" : \"fromField\",\"localField\" : \"localField\",\"foreignField\" : \"foreignField\",\"as\" : \"as\" } }",filterParameters.toString());
}
/**
* Add a step to the end of the current pipeline which prunes the results
* according to the recorded derivation level of their sources. At least one
* triple that was used to construct the result must have a derivation level
* at least as high as the parameter,indicating that it was derived via
* that many steps from the original data. (A value of zero is equivalent to
* input data that was not derived at all.) Use in conjunction with
* getTriplePipeline (which sets source level for generated triples) to
* avoid repeatedly deriving the same results.
* @param requiredLevel required derivation depth. Reject a solution to the
* query if all of the triples involved in producing that solution have a
* lower derivation depth than this. If zero,does nothing.
*/
public void requireSourceDerivationDepth(int requiredLevel) {
if (requiredLevel > 0) {
pipeline.add(Aggregates.match(new Document(LEVEL,new Document("$gte",requiredLevel))));
}
}
/**
* Add a step to the end of the current pipeline which prunes the results
* according to the timestamps of their sources. At least one triple that
* was used to construct the result must have a timestamp at least as
* recent as the parameter. Use in iterative applications to avoid deriving
* solutions that would have been generated in an earlier iteration.
* @param t Minimum required timestamp. Reject a solution to the query if
* all of the triples involved in producing that solution have an earlier
* timestamp than this.
*/
public void requireSourceTimestamp(long t) {
pipeline.add(Aggregates.match(new Document(TIMESTAMP,t))));
}

egg学习笔记第二十一天:MongoDB的高级查询aggregate聚合管道
一、MongoDB聚合管道
使用聚合管道可以对集合中的文档进行变换和组合。实际项目:表的关联查询、数据的统计。
MongoDB中使用db.COLLECTION_NAME.aggregate([{<stage>},...])方法来构建和使用聚合管道,先看下官网给的实例,感受一下聚合管道的用法。
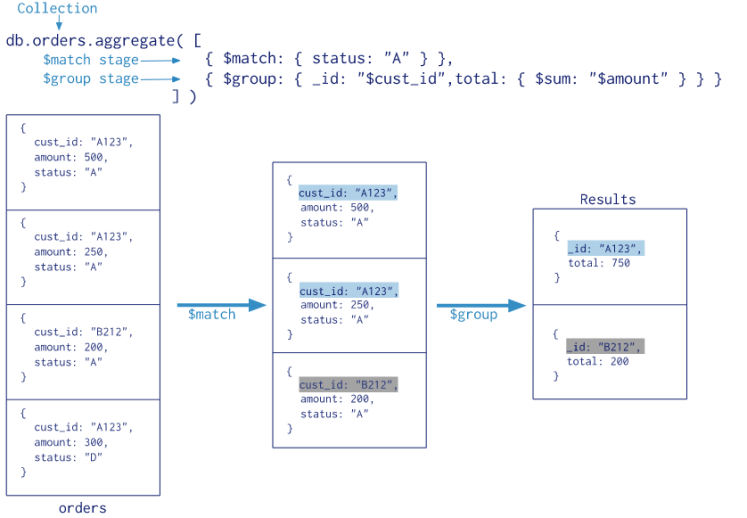
二、常见的管道操作符:
| 管道操作符 |
Description |
|
| $project |
增加、删除、重命名字段 |
|
| $match |
条件匹配。只满足条件的文档才能进入下一阶段 |
|
| $limit |
限制结果的数量 |
|
| $skip |
跳过文档的数量 |
|
| $sort |
条件排序。 |
|
| $group |
条件组合结果 统计 |
|
| $lookup |
$lookup 操作符 用以引入其它集合的数据 (表关联查询) |
|
三、SQL和NOSQL对比:
| WHERE |
$match |
| GROUP BY |
$group |
| HAVING |
$match |
| SELECT |
$project |
| ORDER BY |
$sort |
| LIMIT |
$limit |
| SUM() |
$sum |
| COUNT() |
$sum |
| join |
$lookup |
四、管道表达式:
管道操作符作为“键”,所对应的“值”叫做管道表达式。
例如{$match:{status:"A"}},$match称为管道操作符,而status:"A"称为管道表达式,是管道操作符的操作数(Operand)。
每个管道表达式是一个文档结构,它是由字段名、字段值、和一些表达式操作符组成的。
| 常用表达式操作符 |
Description |
| $addToSet |
将文档指定字段的值去重 |
| $max |
文档指定字段的最大值 |
| $min |
文档指定字段的最小值 |
| $sum |
文档指定字段求和 |
| $avg |
文档指定字段求平均 |
| $gt |
大于给定值 |
| $lt |
小于给定值 |
| $eq |
等于给定值 |
五、模拟数据
db.order.insert({"order_id":"1","uid":10,"trade_no":"111","all_price":100,"all_num":2})
db.order.insert({"order_id":"2","uid":7,"trade_no":"222","all_price":90,"all_num":2})
db.order.insert({"order_id":"3","uid":9,"trade_no":"333","all_price":20,"all_num":6})
db.order_item.insert({"order_id":"1","title":"商品鼠标1","price":50,num:1})
db.order_item.insert({"order_id":"1","title":"商品键盘2","price":50,num:1})
db.order_item.insert({"order_id":"1","title":"商品键盘3","price":0,num:1})
db.order_item.insert({"order_id":"2","title":"牛奶","price":50,num:1})
db.order_item.insert({"order_id":"2","title":"酸奶","price":40,num:1})
db.order_item.insert({"order_id":"3","title":"矿泉水","price":2,num:5})
db.order_item.insert({"order_id":"3","title":"毛巾","price":10,num:1})六、$project
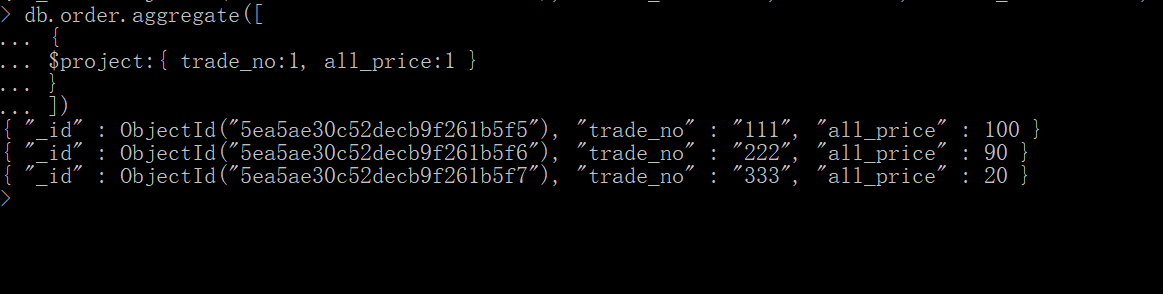
修改文档的结构,可以用来重命名、增加或删除文档中的字段。
①order表只显示订单号和总价格
首先查看order表中的所有数据:

聚合管道可以将这个表中的指定字段查询
db.order.aggregate([
{
$project:{ trade_no:1, all_price:1 }
}
])
七、$match
作用
用于过滤文档。用法类似于 find() 方法中的参数。
先过滤出trade_no和all_price两个字段,在匹配all_price大于90的
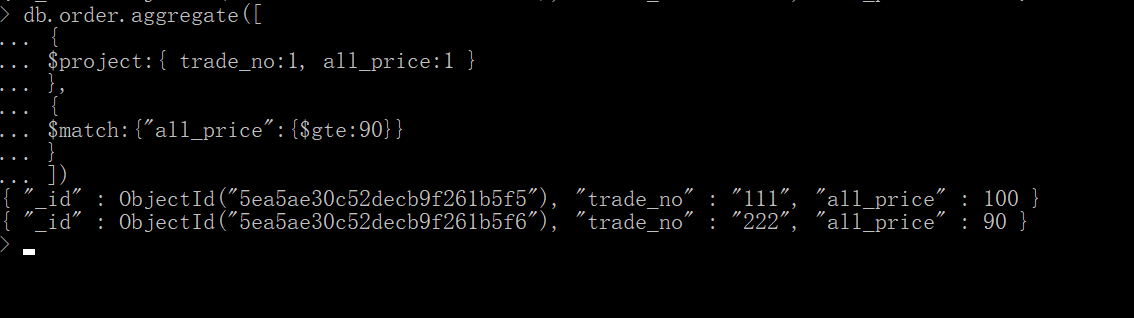
八、$group
分组
将集合中的文档进行分组,可用于统计结果。
统计每个订单的订单数量,按照订单号分组。
db.order_item.aggregate(
[
{
$group: {_id: "$order_id", total: {$sum: "$num"}}
}
]
)
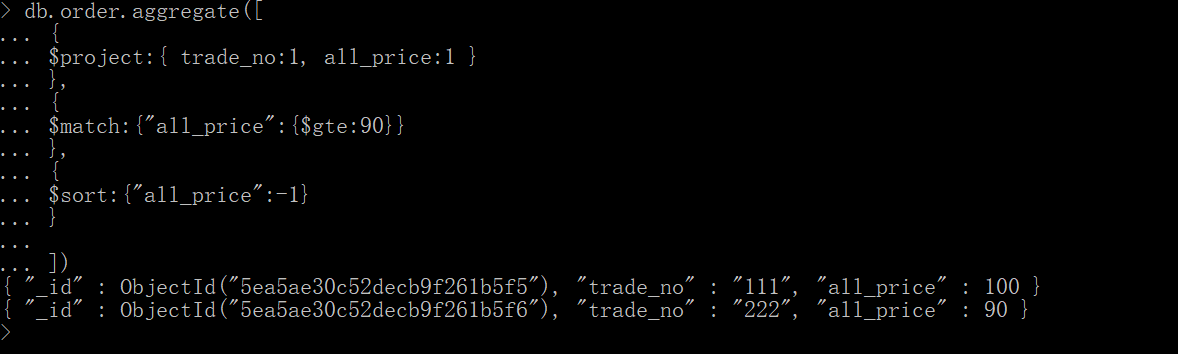
九、$sort
将集合中的文档进行排序。
筛选字段--》过滤--》排序(-1从大到小)
db.order.aggregate([
{
$project:{ trade_no:1, all_price:1 }
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}
}
])
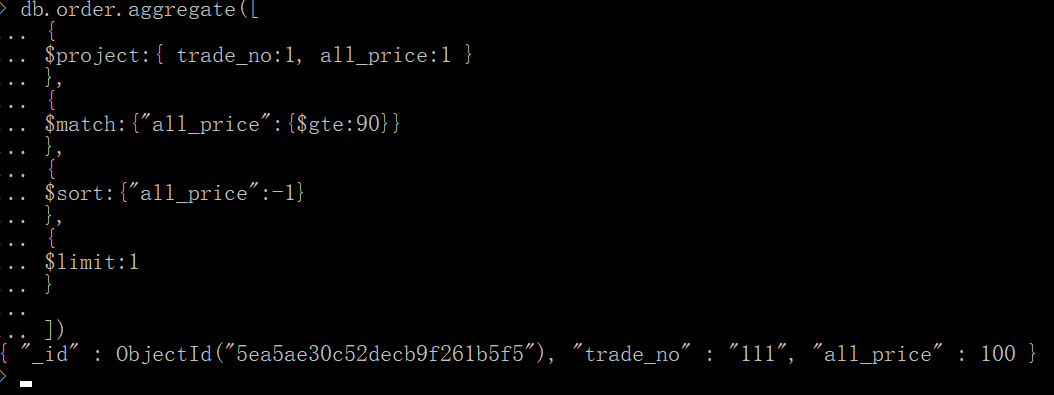
十、$limit
筛选字段--》过滤--》排序(-1从大到小)--》只选一个
db.order.aggregate([
{
$project:{ trade_no:1, all_price:1 }
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}
},
{
$limit:1
}
])
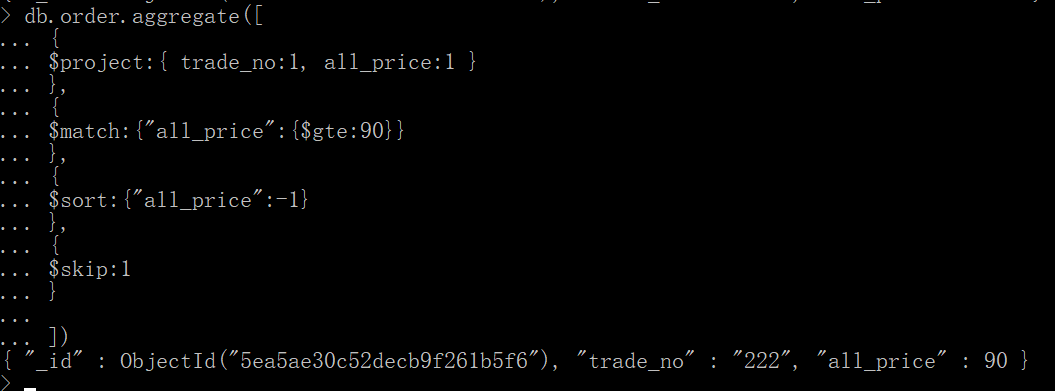
十一、$skip
降序跳过了一个
db.order.aggregate([
{
$project:{ trade_no:1, all_price:1 }
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}
},
{
$skip:1
}
])
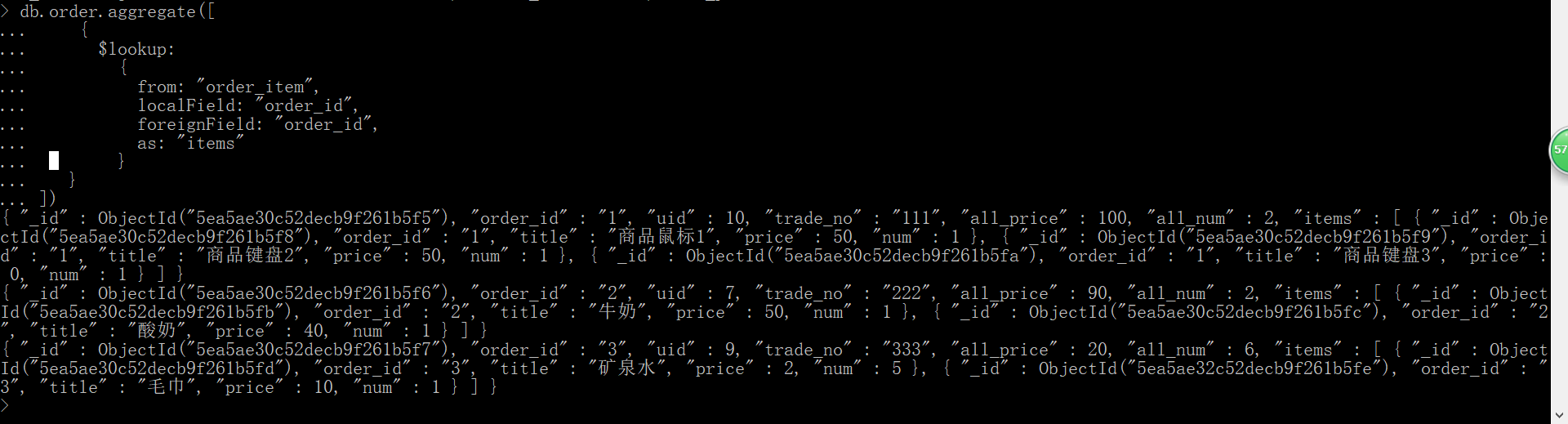
十二、$lookup 表关联
db.order.aggregate([
{
$lookup:
{
from: "order_item",
localField: "order_id",
foreignField: "order_id",
as: "items"
}
}
])
十三、$lookup 表关联+筛选+过滤+排序
db.order.aggregate([
{
$lookup:
{
from: "order_item",
localField: "order_id",
foreignField: "order_id",
as: "items"
}
},
{
$project:{ trade_no:1, all_price:1,items:1 }
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}
},
])
休息休息。

golang mongodb Aggregate
{"$sort": bson.M{"timestamp": -1}}}

Mongodb aggregate timezone 问题
在用aggregate 进行数据统计处理的时候,由于系统默认使用Mongodb的UTC时间,与我们时区差了8小时,会出现结果误差。为了获得正确的结果,在进行
aggregate 处理时需要在原来的基础上做加8小时处理。
测试数据如下

下面我们来计算下shop_id 等于57300412且时间大于’2014-04-01T00:02:00Z’ 按天排序的统计结果。shell表达式如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
对比结果如下

注意上图增加时差和未增加时差的结果是不一样的。
说明:
| 1 2 |
|
相应的Java代码片段如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
关于聊聊MongoDB和五Aggregate Demo的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于com.mongodb.client.model.Aggregates的实例源码、egg学习笔记第二十一天:MongoDB的高级查询aggregate聚合管道、golang mongodb Aggregate、Mongodb aggregate timezone 问题等相关内容,可以在本站寻找。
本文标签:




