在这篇文章中,我们将带领您了解JavaCollection秋招复习的全貌,包括java秋招怎么准备的相关情况。同时,我们还将为您介绍有关.net–ObservableCollectionsCollec
在这篇文章中,我们将带领您了解Java Collection秋招复习的全貌,包括java秋招怎么准备的相关情况。同时,我们还将为您介绍有关.net – Observable Collections Collection已更改、3、Java基础复习----集合 Collection、List、c# – ICollection与ICollection- ICollection.Count和ICollection.Count之间的歧义、Collections 类的常用方法 —— 高淇 JAVA300 讲笔记之 Collections 类的知识,以帮助您更好地理解这个主题。
本文目录一览:- Java Collection秋招复习(java秋招怎么准备)
- .net – Observable Collections Collection已更改
- 3、Java基础复习----集合 Collection、List
- c# – ICollection与ICollection- ICollection.Count和ICollection.Count之间的歧义
- Collections 类的常用方法 —— 高淇 JAVA300 讲笔记之 Collections 类
")
Java Collection秋招复习(java秋招怎么准备)
抽象类和接口的区别
我们先来看一下抽象类
/**
* @auther draymonder
*/
public abstract class AbstractClassTest {
private int Test1;
public int Test2;
public void test1() {
return ;
}
protected void test2() {
return ;
}
private void test3() {
return ;
}
void test4() {
return ;
}
public abstract void test5();
protected abstract void test6();
public static void test7() {
return ;
}
}
我们再来看一下接口
/**
* @auther draymonder
*/
public interface IntefaceTest {
public int Test1 = 0;
void test1();
default void test2() {
return ;
}
public static void test3() {
return ;
}
}
由此我们可以知道
- 接口中没有构造方式
- 接口中的方法必须是抽象的(在
JDK8下interface可以使用default实现方法) - 接口中除了static、final变量,不能有其他变量
- 接口支持多继承
Java集合
ArrayList
数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
Vector
数组的默认大小为 10。
Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制; 可以使用collections的同步list的方法
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);
CopyOnWriteArrayList
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。 所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
hashMap
hash为2的幂的作用
key & (hash - 1)等同于key % hash,但前者效率比后者高- 扩容的时候,
table cap变为2 * table cap,rehash仅仅需要判断key & table cap如果为0,还是原来的table[old],否则是table[old+table cap]
mask码的作用
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
mask |= mask >> 1 11011000
mask |= mask >> 2 11111110
mask |= mask >> 4 11111111
mask+1 是大于原始数字的最小的 2 的 n 次方。
num 10010000
mask+1 100000000
以下是 HashMap 中计算数组容量的代码:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
JDK7版本下的链表循环
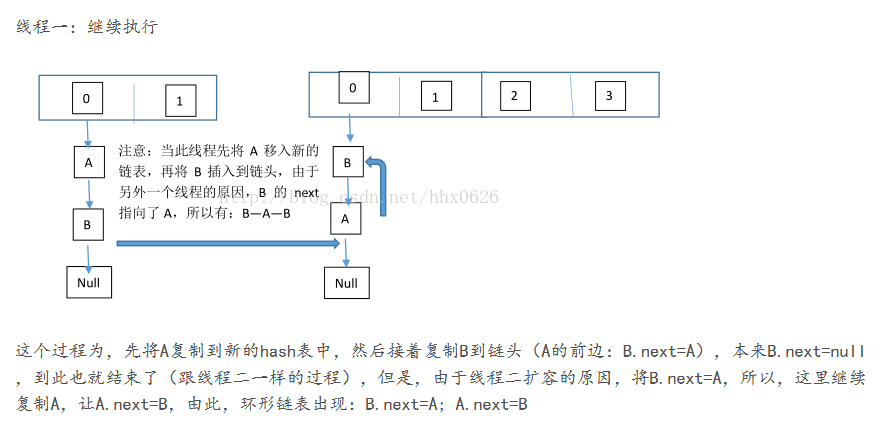
在扩容时候,由于是头插法,所以,原来是A->B,但是多线程情况下会出现。 线程1刚刚拿出A,此时A—>B 然后线程2拿到了B, 然后头插法 A插入到B后面, 最后情况就成了A->B->A 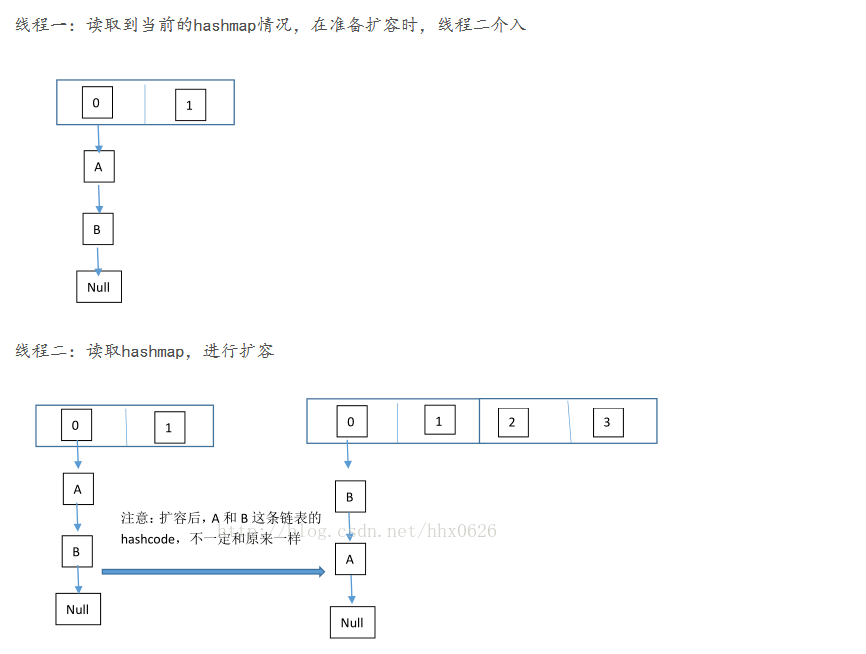
hashmap为什么load factor为0.75
如果load factor太小,那么空间利用率太低;如果load factor太大,那么hash冲撞就会比较多
JDK8下hashmap为什么为长度为8链表转为红黑树
我们来看一下hashmap的注释
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used. Ideally, under random hashCodes, the frequency of
nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because of
resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
我们去有道翻译translate一下
因为树节点的大小大约是普通节点的两倍,所以我们
只有当容器中包含足够的节点以保证使用时才使用它们
(见TREEIFY_THRESHOLD)。当它们变得太小的时候
移除或调整大小)它们被转换回普通的箱子。在
使用分布良好的用户哈希码,树箱是
很少使用。理想情况下,在随机哈希码下
箱中的节点遵循泊松分布
(http://en.wikipedia.org/wiki/Poisson_distribution)
默认大小调整的参数平均约为0.5
阈值为0.75,虽然由于方差较大
调整粒度。忽略方差,得到期望
列表大小k的出现次数为(exp(-0.5) * pow(0.5, k) /
阶乘(k))。第一个值是:
0:0.60653066
1:0.30326533
2:0.07581633
3:0.01263606
4:0.00157952
5:0.00015795
6:0.00001316
7:0.00000094
8:0.00000006
多于:少于千分之一
所以,节点插入遵循泊松分布,因此出现一个桶内8个节点是极小概率事件,所以遇到这种情况我们可以用红黑树加速get操作
红黑树的性质
- 每个节点要么是红色,要么是黑色
- 根节点是黑色的
- 每个叶节点(NULL)是黑色的
- 如果一个节点是红色的,那么他的子节点都是黑色的
- 对于每个节点,从该节点到后代叶节点的简单路径,包含相同数目的黑色节点
红黑树插入过程 参考博客 动态插入演示
ConcurrentHashMap
不支持 key为null 也不支持 value为null
JDK7版本下的
//默认的数组大小16(HashMap里的那个数组)
static final int DEFAULT_INITIAL_CAPACITY = 16;
//扩容因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//ConcurrentHashMap中的数组
final Segment<K,V>[] segments
//默认并发标准16
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//Segment是ReentrantLock子类,因此拥有锁的操作
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//HashMap的那一套,分别是数组、键值对数量、阈值、负载因子
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int threshold;
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
}
//换了马甲还是认识你!!!HashEntry对象,存key、value、hash值以及下一个节点
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
//segment中HashEntry[]数组最小长度
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
//用于定位在segments数组中的位置,下面介绍
final int segmentMask;
final int segmentShift;
put函数
public V put(K key, V value) {
Segment<K,V> s;
//步骤①注意valus不能为空!!!
if (value == null)
throw new NullPointerException();
//根据key计算hash值,key也不能为null,否则hash(key)报空指针
int hash = hash(key);
//步骤②派上用场了,根据hash值计算在segments数组中的位置
int j = (hash >>> segmentShift) & segmentMask;
//步骤③查看当前数组中指定位置Segment是否为空
//若为空,先创建初始化Segment再put值,不为空,直接put值。
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
ensureSegement
可以看到JDK7版本下,ConcurrentHashMap的segment也是使用写时复制的,并且使用CAS算法来将副本替换
private Segment<K,V> ensureSegment(int k) {
//获取segments
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
//拷贝一份和segment 0一样的segment
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
//大小和segment 0一致,为2
int cap = proto.table.length;
//负载因子和segment 0一致,为0.75
float lf = proto.loadFactor;
//阈值和segment 0一致,为1
int threshold = (int)(cap * lf);
//根据大小创建HashEntry数组tab
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
//再次检查
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
根据已有属性创建指定位置的Segment
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
put value
首先lock获取 tab[hash(key)] 然后进行操作
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//步骤① start
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
//步骤① end
V oldValue;
try {
//步骤② start
//获取Segment中的HashEntry[]
HashEntry<K,V>[] tab = table;
//算出在HashEntry[]中的位置
int index = (tab.length - 1) & hash;
//找到HashEntry[]中的指定位置的第一个节点
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
//如果不为空,遍历这条链
if (e != null) {
K k;
//情况① 之前已存过,则替换原值
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//情况② 另一个线程的准备工作
if (node != null)
//链表头插入方式
node.setNext(first);
else //情况③ 该位置为空,则新建一个节点(注意这里采用链表头插入方式)
node = new HashEntry<K,V>(hash, key, value, first);
//键值对数量+1
int c = count + 1;
//如果键值对数量超过阈值
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//扩容
rehash(node);
else //未超过阈值,直接放在指定位置
setEntryAt(tab, index, node);
++modCount;
count = c;
//插入成功返回null
oldValue = null;
break;
}
}
//步骤② end
} finally {
//步骤③
//解锁
unlock();
}
//修改成功,返回原值
return oldValue;
}
scanAndLockForPut
先retries64次,不行的话,才用ReentrantLock重入锁
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
//通过Segment和hash值寻找匹配的HashEntry
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
//重试次数
int retries = -1; // negative while locating node
//循环尝试获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
//步骤①
if (retries < 0) {
//情况① 没找到,之前表中不存在
if (e == null) {
if (node == null) // speculatively create node
//新建 HashEntry 备用,retries改成0
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
//情况② 找到,刚好第一个节点就是,retries改成0
else if (key.equals(e.key))
retries = 0;
//情况③ 第一个节点不是,移到下一个,retries还是-1,继续找
else
e = e.next;
}
//步骤②
//尝试了MAX_SCAN_RETRIES次还没拿到锁,简直B了dog!
else if (++retries > MAX_SCAN_RETRIES) {
//泉水挂机
lock();
break;
}
//步骤③
//在MAX_SCAN_RETRIES次过程中,key对应的entry发生了变化,则从头开始
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
最后的put流程
rehash的话 同jdk8版本下的rehash 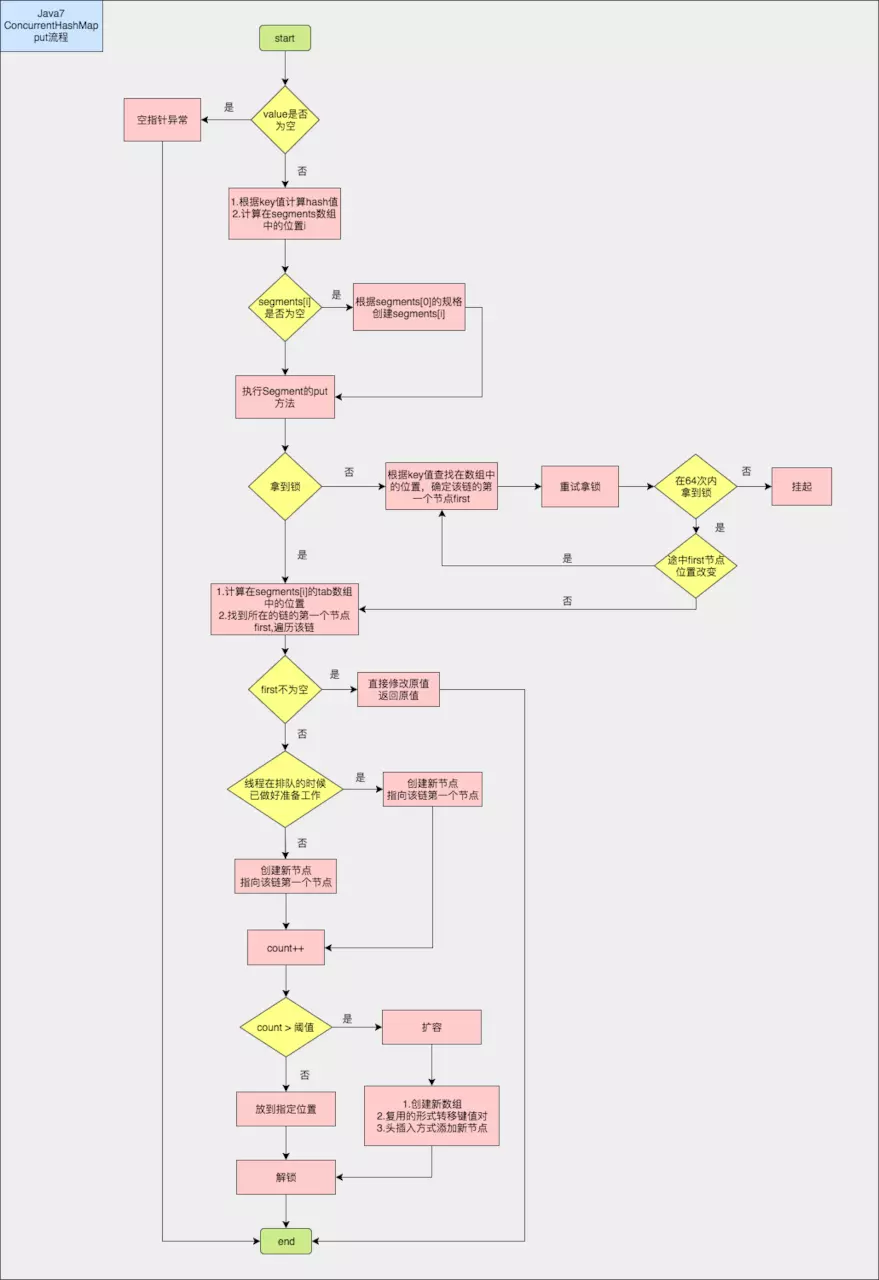
size
retries2次 如果还是不同,那么就reentranLock依次等待unlock计算每个tab的size
JDK8下的ConcurrentHashMap
put
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key/value不能为空!!!
if (key == null || value == null) throw new NullPointerException();
//计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//注释① 表为null则初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//CAS方法判断指定位置是否为null,为空则通过创建新节点,通过CAS方法设置在指定位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//当前节点正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//指定位置不为空
else {
V oldVal = null;
//注释② 加锁
synchronized (f) {
if (tabAt(tab, i) == f) {
//节点是链表的情况
if (fh >= 0) {
binCount = 1;
//遍历整体链
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果已存在,替换原值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//如果是新加节点,则以尾部插入实现添加
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//节点是红黑树的情况
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//遍历红黑树
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
//链表中节点个数超过8转成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//注释③ 添加节点
addCount(1L, binCount);
return null;
}
为什么tab[hash(key)]用cas,但put里面的元素都需要用synchronized呢
其实hash冲撞的几率蛮低的,所以synchronized调用的次数并不多,更多的是在cas那里... 然后就是cas比synchronized的优点...
size
每次put完毕,都会调用addCount方法
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
原文出处:https://www.cnblogs.com/Draymonder/p/11114263.html

.net – Observable Collections Collection已更改
ObservabelCollection<Person> personcollection... and if I change a property like:
Person p = personcollection.where(e => e.FirstName == "Joey").FirstOrDefault();
if (p != null) { p.FirstName = "Joe"; }
我希望在UI中发生一些事情,但没有任何改变.
任何帮助将不胜感激.
大卫
解决方法
它并不关心它的集合中某个对象的属性是否发生变化.您需要在这些对象的属性上实现INotifyPropertyChanged接口以触发对UI的更改.
我读了here,给了我一些有用的见解.虽然它针对WPF,但大多数仍然适用,因为Silverlight本质上是WPF的一个子集.
以及这篇MSDN文章,其中指出:
In particular,if you are using OneWay or TwoWay (for example,you want your UI to update when the source properties change dynamically),you must implement a suitable property changed notification mechanism such as the INotifyPropertyChanged interface.

3、Java基础复习----集合 Collection、List
1.容器 Java 所提供的一系列类的实例,用于在程序中存放对象 java.util
Collection Interface
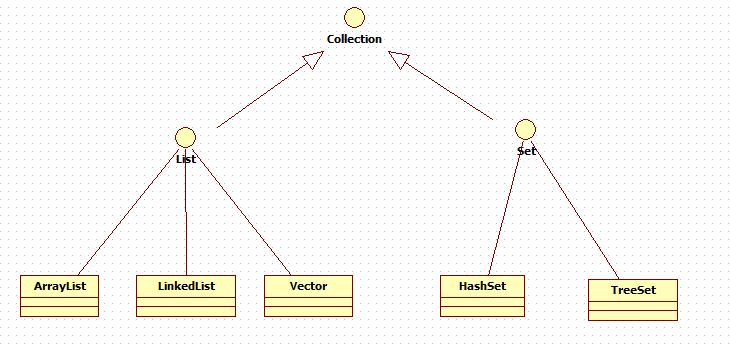
List interface (有序可重复) Set interface(无序不可重复)
public boolean add(E e);添加一个对象到集合中
public boolean addAll(Collection<? extends E> c) ;添加一组集合到集合中
public void clear();移除集合中所有元素
public boolean contains(Object o);集合中是否包含o对象
public boolean containsAll(Collection<?> c);集合中是否全部包含c里面的元素
public boolean isEmpty();集合是没有一个元素
public Iterator<E> iterator();获取集合迭代器
public boolean remove(Object o);移除集合中的o
public boolean removeAll(Collection<?> c) 移除集合中所有c集合的元素
public boolean retainAll(Collection<?> c) 集合与c集合是否存在交集
public int size();集合中元素个数
public Object[] toArray();集合转换成数组
2.List 可以存储null
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
RandomAccess 用来表明其支持快速(通常是固定时间)随机访问
public int indexOf(Object o)方法返回指定元素的第一个匹配项的索引在此列表中,或者-1
public int lastIndexOf(Object o)方法返回指定元素的最后一个匹配项的索引在此列表中,或者-1
pubblic E set(int index,E element)替换指定位置的元素
public List<E> subList(int fromIndex,int toIndex) 截取子集合在fromIndex和toIndex之间

c# – ICollection与ICollection- ICollection.Count和ICollection.Count之间的歧义
我已经实现了IBusinessCollection接口.它既来自ICollection< T>又来自旧的非通用ICollection.我更喜欢转储旧的已经破坏的ICollection,但我正在使用带有CollectionView的WPF数据绑定,它希望我实现旧的非泛型IList
总结
以上是小编为你收集整理的c# – ICollection与ICollection- ICollection.Count和ICollection.Count之间的歧义全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。

Collections 类的常用方法 —— 高淇 JAVA300 讲笔记之 Collections 类
注意,Collections 类是有 s 的,要跟 Collection 接口区分开。
以下代码介绍了 shuffle 和 reverse 方法。其中,用 shuffle 方法模拟了斗地主的洗牌。
1 package com.bjsxt.sort.util;
2
3 import java.util.ArrayList;
4 import java.util.Collections;
5 import java.util.List;
6
7 /**
8 * 1、binarySearch(List<? extends Comparable<? super T>> list, T key) 容器有序
9 * 2、sort(List<T> list)
10 * sort(List<T> list, Comparator<? super T> c)
11 * 3、reverse(List<?> list)
12 * 4、shuffle(List<?> list) 洗牌
13 * 5、swap(List<?> list, int i, int j)
14 */
15 public class CollectionsDemo01 {
16 public static void main(String[] args) {
17 List<Integer> cards = new ArrayList<Integer>();
18 //shuffle 洗牌 模拟斗地主
19 for(int i=0;i<54;i++) {
20 cards.add(i);
21 }
22 //洗牌
23 Collections.shuffle(cards);
24 //依次发牌
25 List<Integer> p1 = new ArrayList<Integer>(); //斗地主选手
26 List<Integer> p2 = new ArrayList<Integer>();
27 List<Integer> p3 = new ArrayList<Integer>();
28 List<Integer> last = new ArrayList<Integer>(); //底牌
29 for(int i=0;i<51;i+=3) {
30 p1.add(cards.get(i));
31 p2.add(cards.get(i+1));
32 p3.add(cards.get(i+2));
33 }
34
35 //最后三张为底牌
36 last.add(cards.get(51));
37 last.add(cards.get(52));
38 last.add(cards.get(53));
39
40 System.out.println("第一个人:"+p1);
41 System.out.println("第二个人:"+p2);
42 System.out.println("第三个人:"+p3);
43 System.out.println("底牌为:"+last);
44
45
46 }
47 //反转
48 public static void test1() {
49 List<Integer> list = new ArrayList<Integer>();
50 list.add(1);
51 list.add(2);
52 list.add(3);
53 list.add(4);
54 System.out.println(list);
55 Collections.reverse(list);
56 System.out.println("反转之后"+list);
57 }
58 }
关于Java Collection秋招复习和java秋招怎么准备的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.net – Observable Collections Collection已更改、3、Java基础复习----集合 Collection、List、c# – ICollection与ICollection- ICollection.Count和ICollection.Count之间的歧义、Collections 类的常用方法 —— 高淇 JAVA300 讲笔记之 Collections 类等相关知识的信息别忘了在本站进行查找喔。
本文标签:




