本文将为您提供关于为什么字典在C#中优于Hashtable?的详细介绍,我们还将为您解释c#字典的作用的相关知识,同时,我们还将为您提供关于.NETHashTable与字典-字典可以这么快吗?、c#–
本文将为您提供关于为什么字典在 C# 中优于 Hashtable?的详细介绍,我们还将为您解释c#字典的作用的相关知识,同时,我们还将为您提供关于.NET HashTable与字典-字典可以这么快吗?、c# – 将Hashtable添加到另一个Hashtable的末尾、C#基础-hashtable,泛型和字典集合、HashCode和hashMap、hashTable的实用信息。
本文目录一览:- 为什么字典在 C# 中优于 Hashtable?(c#字典的作用)
- .NET HashTable与字典-字典可以这么快吗?
- c# – 将Hashtable添加到另一个Hashtable的末尾
- C#基础-hashtable,泛型和字典集合
- HashCode和hashMap、hashTable
")
为什么字典在 C# 中优于 Hashtable?(c#字典的作用)
在大多数编程语言中,字典比哈希表更受欢迎。这背后的原因是什么?

.NET HashTable与字典-字典可以这么快吗?
我试图弄清楚何时以及为什么使用Dictionary或HashTable。我在这里做了一些搜索,发现人们谈论我完全同意的《词典》的一般优势,这导致装箱和拆箱的优势略有提高。
但是我也读过Dictionary并不会总是按插入对象的顺序返回对象,而是对其进行排序。像HashTable一样。据我了解,这在某些情况下会导致HashTable更快。
我的问题是,这些情况可能是什么?我在上面的假设中错了吗?您可能会使用哪种情况来选择另一种情况(是的,最后一种情况有点模棱两可)。
答案1
小编典典System.Collections.Generic.Dictionary<TKey,TValue>和System.Collections.Hashtable类都在内部维护哈希表数据结构。 它们都不能保证保留项目的顺序。
除了装箱/拆箱问题外,大多数情况下,它们应该具有非常相似的性能。
它们之间的主要结构差异是Dictionary依靠 链接 (为每个哈希表存储桶维护一个项目列表)来解决冲突,而Hashtable使用
重新哈希化 来解决冲突(当发生冲突时,尝试使用另一个哈希函数将键映射到存储桶) 。
Hashtable如果您针对.NET Framework 2.0+ ,则使用类几乎没有好处。有效地使它过时了Dictionary<TKey,TValue>。

c# – 将Hashtable添加到另一个Hashtable的末尾
The type arguments for method
System.Linq.Enumerable.Concat<TSource>(this System.Collections.Generic.IEnumerable<TSource>,System.Collections.Generic.IEnumerable<TSource>)'cannot be inferred from the usage.
我不完全明白这意味着什么或我错了什么.我的方法看起来像这样:
public void resetCameras(Hashtable hashTable)
{
Hashtable ht = new Hashtable();
ht.Add("time",2.0f);
ht.Add("easeType","easeInOutQuad");
ht.Add("onupdate","UpdateSize");
ht.Add("from",size);
ht.Add("to",5.0f);
if(hashTable != null) {
ht = ht.Concat(hashTable);
}
iTween.Valueto(gameObject,ht);
}
希望你能帮助解释我的错误,对C#来说还是新手.
解决方法
foreach (DictionaryEntry entry in hashTable)
{
if(!ht.ContainsKey(entry.Key))
{
ht.Add(entry.Key,entry.Value);
}
}
// rest of the logic

C#基础-hashtable,泛型和字典集合
hashtable 的存储方式 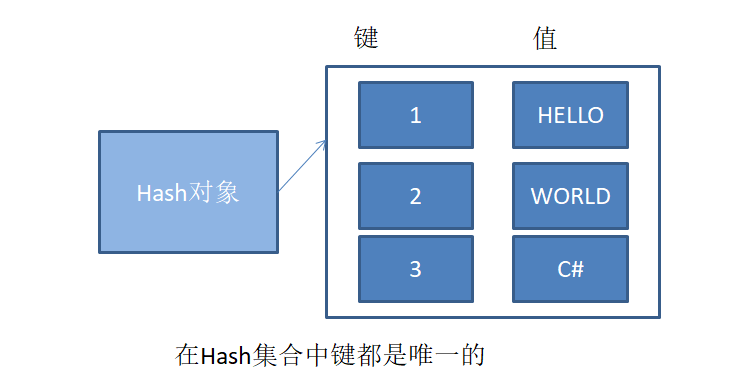
使用方法: 1.引入包含Hashtable的命名空间
using System.Collections; // 引入Hash所在的命名空间
2.往hash表里面添加数据
Hashtable hash = new Hashtable();
// 往hash里面添加数据
hash.Add(1, "Hello");
hash.Add(2, "World");
hash.Add(3, "C#");
3.访问Hash表的方法
1.键对于值 2.遍历键的集合 3.使用遍历器
// 访问hash数据的3种方法:
// 访问hash数据,采用键的方式
Console.WriteLine(hash[1]);
// 可以采用遍历它的键集合访问
var skeys = hash.Keys; // hash的键的集合
foreach(object o in skeys)
{
Console.WriteLine("键:{0},值:{1}", o, hash[o]);
}
// 遍历器访问
var ie = hash.GetEnumerator(); // 获取遍历器
while (ie.MoveNext()) // 依次遍历每一行数据
{
Console.WriteLine("键:{0},值:{1}", ie.Key,ie.Value);
}
泛型
ArrayList arrList = new ArrayList();
arrList.Add(1);
arrList.Add("hello");
arrList.Add(DateTime.Now);
在使用ArrayList的时候,无法保证类型的一致性,泛型的出现就是解决这个问题,泛型规定了数据类型
1.引入泛型的命名空间
using System.Collections.Generic; // 泛型使用的命名空间
2.泛型使用
// 泛型规定了数据类型
List<int> list = new List<int>();
list.Add(1);
list.Add(2);
3.泛型的遍历
foreach遍历
// 泛型的遍历
foreach(int i in list)
{
Console.WriteLine(i);
}
for语句遍历
// for语句遍历
for(int i = 0; i < list.Count; i++)
{
Console.WriteLine("泛型的索引:{0},泛型的数据:{1}", i, list[i]);
}
字典集合存储与访问
与hashtable差不多,但是类型是一致的
// 字典集合的存储
Dictionary<string, string> dic = new Dictionary<string, string>();
dic.Add("1001", "Jake");
dic.Add("1002", "Max");
dic.Add("1003", "Kate");
// 采用类似与访问hash方式访问
Console.WriteLine(dic["1001"]);
// 获取键遍历访问
var keys = dic.Keys;
foreach(string str in keys)
{
Console.WriteLine("键:{0},值:{1}",str,dic[str]);
}
// 采用遍历器去访问
var ie = dic.GetEnumerator();
while (ie.MoveNext())
{
Console.WriteLine("键:{0},值:{1}", ie.Current.Key, ie.Current.Value);
}

HashCode和hashMap、hashTable
什么是哈希码(HashCode)
在Java中,哈希码代表对象的特征。
例如对象 String str1 = “aa”, str1.hashCode= 3104
String str2 = “bb”, str2.hashCode= 3106
String str3 = “aa”, str3.hashCode= 3104
根据HashCode由此可得出str1!=str2,str1==str3
下面给出几个常用的哈希码的算法。
1:Object类的hashCode.返回对象的内存地址经过处理后的结构,由于每个对象的内存地址都不一样,所以哈希码也不一样。
2:String类的hashCode.根据String类包含的字符串的内容,根据一种特殊算法返回哈希码,只要字符串所在的堆空间相同,返回的哈希码也相同。
3:Integer类,返回的哈希码就是Integer对象里所包含的那个整数的数值,例如Integer i1=new Integer(100),i1.hashCode的值就是100 。由此可见,2个一样大小的Integer对象,返回的哈希码也一样。
HashSet和HashMap一直都是JDK中最常用的两个类,HashSet要求不能存储相同的对象,HashMap要求不能存储相同的键。
那么Java运行时环境是如何判断HashSet中相同对象、HashMap中相同键的呢?当存储了“相同的东西”之后Java运行时环境又将如何来维护呢?
在研究这个问题之前,首先说明一下JDK对equals(Object obj)和hashcode()这两个方法的定义和规范:
在Java中任何一个对象都具备equals(Object obj)和hashcode()这两个方法,因为他们是在Object类中定义的。
equals(Object obj)方法用来判断两个对象是否“相同”,如果“相同”则返回true,否则返回false。
hashcode()方法返回一个int数,在Object类中的默认实现是“将该对象的内部地址转换成一个整数返回”。
接下来有两个个关于这两个方法的重要规范(我只是抽取了最重要的两个,其实不止两个):
规范1:若重写equals(Object obj)方法,有必要重写hashcode()方法,确保通过equals(Object obj)方法判断结果为true的两个对象具备相等的hashcode()返回值。说得简单点就是:“如果两个对象相同,那么他们的hashcode应该 相等”。不过请注意:这个只是规范,如果你非要写一个类让equals(Object obj)返回true而hashcode()返回两个不相等的值,编译和运行都是不会报错的。不过这样违反了Java规范,程序也就埋下了BUG。
规范2:如果equals(Object obj)返回false,即两个对象“不相同”,并不要求对这两个对象调用hashcode()方法得到两个不相同的数。说的简单点就是:“如果两个对象不相同,他们的hashcode可能相同”。
根据这两个规范,可以得到如下推论:
1、如果两个对象equals,Java运行时环境会认为他们的hashcode一定相等。
2、如果两个对象不equals,他们的hashcode有可能相等。
3、如果两个对象hashcode相等,他们不一定equals。
4、如果两个对象hashcode不相等,他们一定不equals。
这样我们就可以推断Java运行时环境是怎样判断HashSet和HastMap中的两个对象相同或不同了。我的推断是:先判断hashcode是否相等,再判断是否equals。
测试程序如下:首先我们定义一个类,重写hashCode()和equals(Object obj)方法
class A {
@Override
public boolean equals(Object obj) {
System.out.println("判断equals");
return false;
}
@Override
public int hashCode() {
System.out.println("判断hashcode");
return 1;
}
}然后写一个测试类,代码如下:
public class Test {
public static void main(String[] args) {
Map<A,Object> map = new HashMap<A, Object>();
map.put(new A(), new Object());
map.put(new A(), new Object());
System.out.println(map.size());
}
}运行之后打印结果是:
判断hashcode
判断hashcode
判断equals
HashCode的作用
首先,想要明白hashCode的作用,你必须要先知道Java中的集合。
总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set。你知道它们的区别吗?前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。那么这里就有一个比较严重的问题了:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?这就是Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
于是,Java采用了哈希表的原理。哈希(Hash)实际上是个人名,由于他提出一哈希算法的概念,所以就以他的名字命名了。哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。如果详细讲解哈希算法,那需要更多的文章篇幅,我在这里就不介绍了。初学者可以这样理解,hashCode方法实际上返回的就是对象存储的物理地址(PS:这是一种算法,数据结构里面有提到。在某一个地址上(对应一个哈希值,该值并不特指内存地址),存储的是一个链表。在put一个新值时,根据该新值计算出哈希值,找到相应的位置,发现该位置已经蹲了一个,则新值就链接到旧值的下面,由旧值指向(next)它(也可能是倒过来指。。。)。可以参考HashMap)。
这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
所以,Java对于eqauls方法和hashCode方法是这样规定的:
1、如果两个对象相同,那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同
上面说的对象相同指的是用eqauls方法比较。
你当然可以不按要求去做了,但你会发现,相同的对象可以出现在Set集合中。同时,增加新元素的效率会大大下降。
怎么重写HashCode?
下面介绍如何来重写hashCode()方法。通常重写hashCode()方法按以下设计原则实现。
(1)把某个非零素数,例如17,保存在int型变量result中。
(2)对于对象中每一个关键域f(指equals方法中考虑的每一个域)参照以下原则处理。
boolean型,计算(f?0:1)。
byte、char和short型,计算(int)f。
long型,计算(int)(f^(f>>32))。
float型,计算Float.floatToIntBits(f)。
double型,计算Double.doubleToLongBits(f)得到一个long,再执行long型的处理。
对象引用,递归调用它的hashCode()方法。
数组域,对其中的每个元素调用它的hashCode()方法。
(3)将上面计算得到的散列码保存到int型变量c,然后执行result = 37 * result + c。
(4)返回result。
类 HashMap<K,V>
java.lang.Object
java.util.AbstractMap<K,V>
java.util.HashMap<K,V>类型参数:
K- 此映射所维护的键的类型V- 所映射值的类型基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashCode和HashMap之间的关系
先如下代码:
import java.util.HashMap;
public class Test {
//重写Equals不重写HashCode
static class Key {
private Integer id;
private String value;
public Key(Integer id, String value) {
super();
this.id = id;
this.value = value;
}
@Override
public boolean equals(Object o) {
if(o == null || !(o instanceof Key)) {
return false;
}else {
return this.id.equals(((Key)o).id);
}
}
}
//重写Equals也重写HashCode
static class Key_ {
private Integer id;
private String value;
public Key_(Integer id, String value) {
super();
this.id = id;
this.value = value;
}
@Override
public boolean equals(Object o) {
if(o == null || !(o instanceof Key_)) {
return false;
}else {
return this.id.equals(((Key_)o).id);
}
}
@Override
public int hashCode() {
return id.hashCode();
}
}
public static void main(String[] args) {
//test hashcode
HashMap<Object, String> values = new HashMap<Object, String>(5);
Test.Key key1 = new Test.Key(1, "one");
Test.Key key2 = new Test.Key(1, "one");
System.out.println(key1.equals(key2));
values.put(key1, "value 1");
System.out.println(values.get(key2));
Test.Key_ key_1 = new Test.Key_(1, "one");
Test.Key_ key_2 = new Test.Key_(1, "one");
System.out.println(key_1.equals(key_2));
System.out.println(key_1 == key_2);
values.put(key_1, "value 1");
System.out.println(values.get(key_2));
}
}输出如下: 由上述例子可见:只重写了equasl方法的Key类 在用做Hash中的键值的时候 两个equasl为true的对象不能获取相应 的Value的而重写了hashCode方法和equals方法的key_类 两个相等的对象 可以获取同一个Value的,这样更符合生活中 的逻辑HashMap对象是根据Key的hashCode来获取对应的Vlaue 因而两个HashCode相同的对象可以获取同一个Value
由上述例子可见:只重写了equasl方法的Key类 在用做Hash中的键值的时候 两个equasl为true的对象不能获取相应 的Value的而重写了hashCode方法和equals方法的key_类 两个相等的对象 可以获取同一个Value的,这样更符合生活中 的逻辑HashMap对象是根据Key的hashCode来获取对应的Vlaue 因而两个HashCode相同的对象可以获取同一个Value
<span >
</span>关于为什么字典在 C# 中优于 Hashtable?和c#字典的作用的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于.NET HashTable与字典-字典可以这么快吗?、c# – 将Hashtable添加到另一个Hashtable的末尾、C#基础-hashtable,泛型和字典集合、HashCode和hashMap、hashTable的相关信息,请在本站寻找。
本文标签:




