在这篇文章中,我们将为您详细介绍aiohttp:速率限制并行请求的内容,并且讨论关于限制速率什么意思的相关问题。此外,我们还会涉及一些关于.NET7新增速率限制(RateLimiting)功能,轻松限
在这篇文章中,我们将为您详细介绍aiohttp:速率限制并行请求的内容,并且讨论关于限制速率什么意思的相关问题。此外,我们还会涉及一些关于.NET 7 新增速率限制 (Rate Limiting) 功能,轻松限制请求数量、1、asyncio aiohttp aiofile 异步爬取图片、aiohttp、aiohttp 如何发送带有标头的请求的知识,以帮助您更全面地了解这个主题。
本文目录一览:- aiohttp:速率限制并行请求(限制速率什么意思)
- .NET 7 新增速率限制 (Rate Limiting) 功能,轻松限制请求数量
- 1、asyncio aiohttp aiofile 异步爬取图片
- aiohttp
- aiohttp 如何发送带有标头的请求
")
aiohttp:速率限制并行请求(限制速率什么意思)
API通常具有用户必须遵循的速率限制。举个例子,让我们50个请求/秒。连续的请求采取0.5-1秒,因此是来接近极限速度太慢。但是,使用aiohttp的并行请求超出了速率限制。
轮询API尽可能快地允许,需要限速并行调用。
例如,我发现到目前为止装饰session.get,大约像这样:
session.get = rate_limited(max_calls_per_second)(session.get)这非常适用于连续通话。试图并行调用来实现这个按预期不起作用。
下面是一些代码示例:
async with aiohttp.ClientSession() as session: session.get = rate_limited(max_calls_per_second)(session.get) tasks = (asyncio.ensure_future(download_coroutine( timeout, session, url)) for url in urls) process_responses_function(await asyncio.gather(*tasks))这里的问题是,它会率限制 排队 的任务。与执行gather也会出现或多或少的在同一时间。两个世界最糟的;-)。
是的,我发现了一个类似的问题在这里aiohttp:每秒请求设定的最大数目,但既不答复答复限制请求的速率的实际问题。此外,从昆汀·普拉代博客文章仅适用于限速排队。
要包起来:一个人怎么可以限制 每秒请求数 并行aiohttp请求?
答案1
小编典典如果我理解你很好,你想限制并发请求数?
有一个内部的对象asyncio命名Semaphore,它就像一个异步RLock。
semaphore = asyncio.Semaphore(50)#...async def limit_wrap(url): async with semaphore: # do what you want#...results = asyncio.gather([limit_wrap(url) for url in urls])更新
假设我做50个并发请求,他们也都在2秒内完成。因此,它不接触限制(只有每秒25个请求)。
这意味着我应该做100个并发请求,他们也都在2秒内太(每秒50个请求)完成。但在此之前,你实际上使这些要求,你怎么能确定他们将如何悠长?
或者,如果你不介意 每秒完成的请求, 但 每秒发出的请求 。您可以:
async def loop_wrap(urls): for url in urls: asyncio.ensure_future(download(url)) await asyncio.sleep(1/50)asyncio.ensure_future(loop_wrap(urls))loop.run_forever()上面的代码将创建一个Future实例每隔1/50一秒。
 功能,轻松限制请求数量")
.NET 7 新增速率限制 (Rate Limiting) 功能,轻松限制请求数量
.NET 7 内置了速率限制(Rate Limiting)功能,速率限制指的是限制可访问资源的请求数。例如数据库每分钟可以安全处理 1000 个请求,再多不确定会不会崩。这时就可以在应用程序中放一个速率限制器,规定每分钟只允许 1000 个请求,在达到这个数量后开始拒绝请求。这是一种保护资源的方法,可以避免应用在高浏览的情况下崩溃。
有很多种不同的算法来控制请求流,下面介绍 .NET 7 中提供的 4 种方法:
并发限制
顾名思义,并发限制器就是限制有多少并发请求可以访问资源。如果限制是 10,那么只有 10 个请求可以同时访问一个资源,第 11 个请求将被拒绝。
一旦前面的请求完成,则允许的请求数量会增加 1,当第二个请求完成时,数量增加到 2,依此类推。该算法是通过 释放 RateLimitLease 来完成的。
令牌桶
令牌桶是另一种算法,就像一个装满令牌的桶。每隔一段时间,桶内会新增固定数量的令牌,但令牌数不能超过桶可容纳的最大数量。当一个请求进来时,它会获取并保存一个令牌,如果存储桶为空,则新请求进入时没有令牌可获取,即将被拒绝访问资源。
假设单个桶可以容纳 10 个令牌,且每分钟往里面加入 2 个令牌。现在有 3 个请求进来了,剩下 7 个令牌。一分钟后,桶自动补充到 9 个令牌,然后 9 个请求瞬间取走所有令牌。那么接下来在桶内添加令牌之前,所有请求都不允许访问资源。如果接下来没有请求,则桶会在 5 分钟内自动补到 10 个令牌,然后等待请求。
固定窗口限制
固定窗口算法使用“窗口”的概念,窗口采用时间计量,在固定的一段时间内限制最大请求,并在切换到下一个窗口的时候重置请求数。
假设现在有一个最多只能容纳 100 人(最大请求数)的电影院(窗口),每场电影需要播放 2 个小时(窗口持续时间)。电影开始后,剩下的观众(请求)只能排队等待下一场窗口,排队的最大数量也是 100 ,超出的部分不允许继续排队,只能等待下一个窗口开始后才能继续排队。
滑动窗口限制
滑动窗口算法类似于固定窗口算法,但增加了“段(segments)”的概念。
- 一个段是一个窗口的一部分,如果将前面 2 小时的窗口分成 4 个段,则会有 4 个 30 分钟的段。此外还有一个“段索引”,它始终指向窗口中的最新段。
- 30 分钟内的请求进入最新的段,且每 30 分钟窗口滑动一个段。如果在窗口滑过段期间出现了新的请求,则该请求会被刷新,且段的最大限制会增加。如果没有请求,则段的限制保持不变。
例设现在有一个滑动窗口,它包含 3 个 10 分钟的段,最多只能接受100 个请求。现在它的初始状态是 3 个段,计数均为 0,当前的段索引指向第 3 个段。
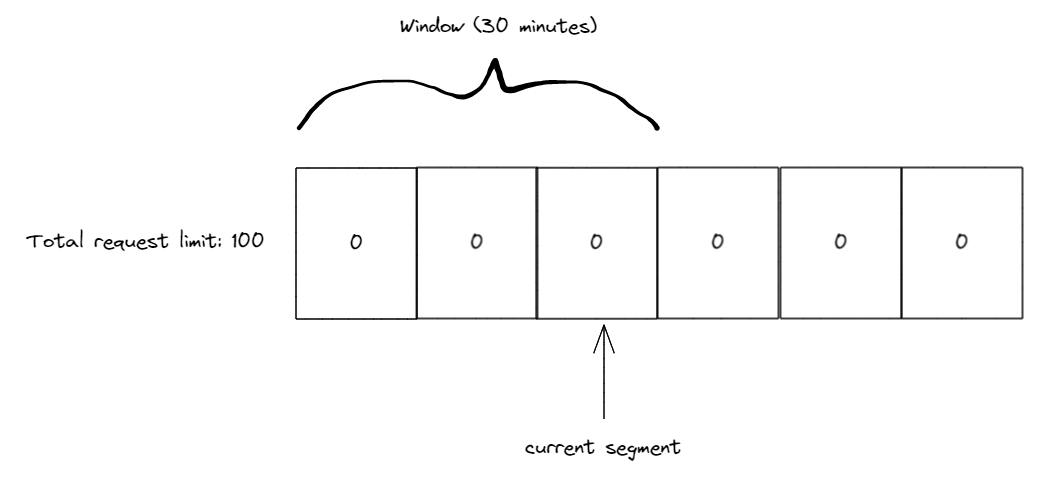
在前 10 分钟内,我们收到 50 个请求,所有请求都在第 3 段(段索引所在的位置)。10 分钟过去后,我们将窗口滑动 1 段,同时将当前段索引移动到第 4 段。
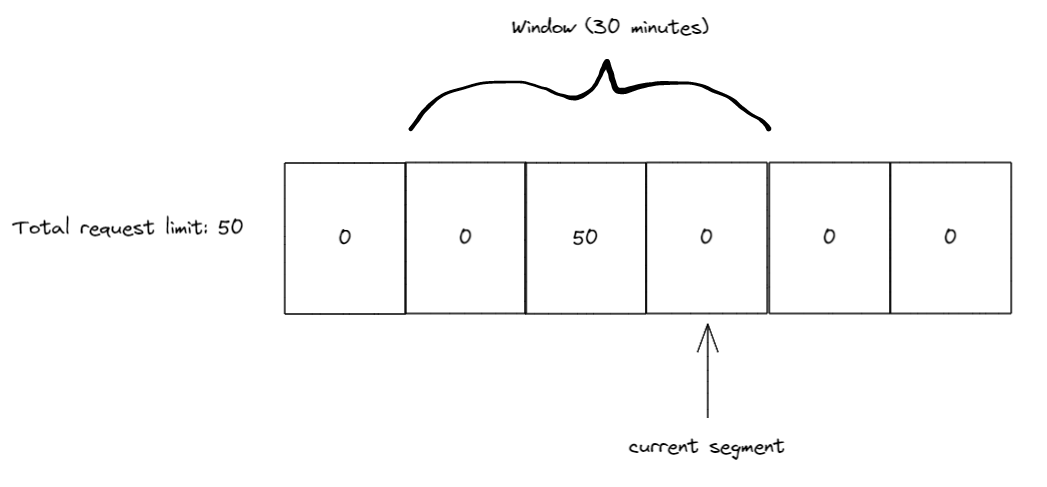
接下来的 10 分钟内,我们又收到了 20 个请求,所以现在第 3 段有 50 个,第 4 段有 20 个。同样在 10 分钟过去后窗口开始滑动,因此当前的段索引指向了 5,而由于段 3 和段 4 都在窗口内,因此窗口只剩 20 个请求名额。
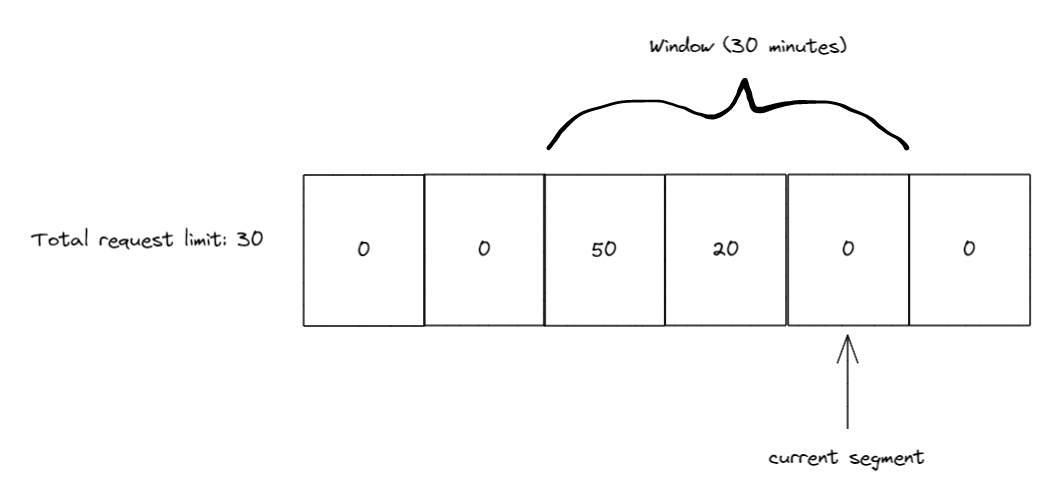
又过了 10 分钟后,再次滑动窗口,这一次窗口滑动后段索引为 6,但段 3(有 50 个请求的段)已位于窗口之外,因此窗口收回了 50 个请求限额。由于段 4 仍有 20 个请求,所以滑动窗口的请求限额变为 80 。
微软博客中有关于速率限制功能和相关 API 、中间件的详细介绍,对此功能感兴趣的朋友可在 Nuget 中进一步了解。

1、asyncio aiohttp aiofile 异步爬取图片
前后折腾了好多天,不废话,先直接上代码,再分析:
1 import aiohttp
2 import asyncio
3 import aiofiles
4
5 header = {''User-Agent'': ''Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1'',
6 ''Referer'': ''https://www.mzitu.com/'',
7 ''Accept'': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
8 ''Accept-Encoding'': ''gzip'',
9 }
10
11 async def fetch(session, url):
12 async with session.get(url, proxy=''http://59.62.164.252:9999'') as response:
13 return await response.read()
14
15 async def main():
16 async with aiohttp.ClientSession(headers=header) as session:
17 content = await fetch(session, ''https://i.meizitu.net/thumbs/2019/03/174061_01e35_236.jpg'')
18 print(content)
19 async with aiofiles.open(''D:/a.jpg'', ''wb'') as f:
20 f.write(content)
21
22 loop = asyncio.get_event_loop()
23 loop.run_until_complete(main())
24 loop.close()
开始心路历程:
1、看了廖雪峰老师python教程中协程一章节、《流畅的python》中协程一章节,以及前前后后网上查询的资料,不管怎么改均报错,人接近暴走状态。
最后Google查询ClientSession:Client Reference,复制源码做尝试:
1 import aiohttp
2 import asyncio
3
4 async def fetch(client):
5 async with client.get(''http://python.org'') as resp:
6 assert resp.status == 200
7 return await resp.text()
8
9 async def main():
10 async with aiohttp.ClientSession() as client:
11 html = await fetch(client)
12 print(html)
13
14 loop = asyncio.get_event_loop()
15 loop.run_until_complete(main())运行成功
2、改为下载图片,并想fetch函数能不能直接返回response?
1 import aiohttp
2 import asyncio
3 import aiofiles
4
5 header = {''User-Agent'': ''Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1'',
6 ''Referer'': ''https://www.mzitu.com/'',
7 ''Accept'': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
8 ''Accept-Encoding'': ''gzip'',
9 }
10
11 async def fetch(session, url):
12 async with session.get(url) as response:
13 return response
14
15 async def main():
16 async with aiohttp.ClientSession() as session:
17 response = await fetch(session, ''https://i.meizitu.net/thumbs/2019/03/174061_01e35_236.jpg'')
18 print(response.read())
19 with open(''D:/a.jpg'', ''wb'') as f:
20 f.write(response.read())
21
22 loop = asyncio.get_event_loop()
23 loop.run_until_complete(main())
24 loop.close()运行直接报错:
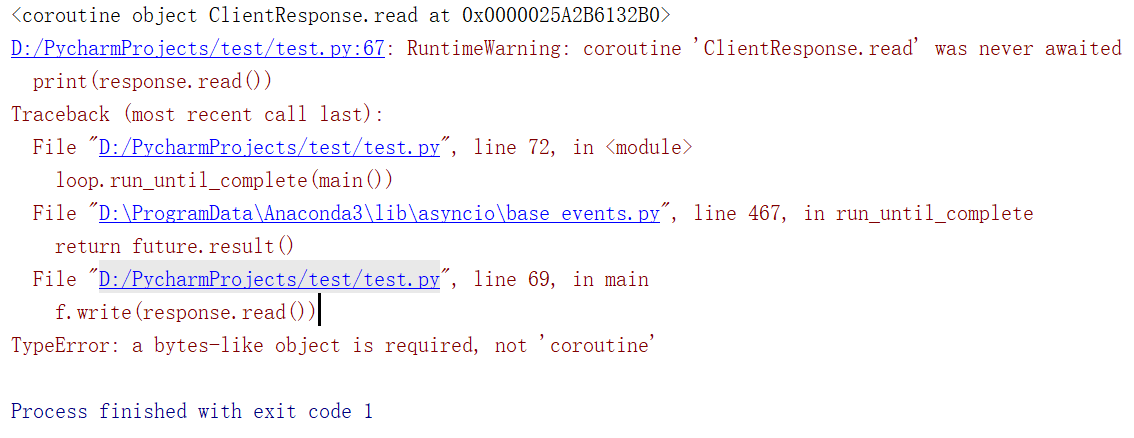
貌似fetch函数中不能返回response?百思不得姐,问题先放这,以后再解决吧
3、根据上面ClientSession文档中介绍:

请求头header应放在ClientSession实例化中
4、aiohttp supports HTTP/HTTPS proxies
但是,它根本就不支持 https 代理。
可参考 Python3 异步代理爬虫池
头疼,先写这么多吧
最后尝试貌似代理ip又有问题,晕

aiohttp
1. aiohttp安装
pip3 install aiohttp1.1. 基本请求用法
async with aiohttp.get(''https://github.com'') as r:
await r.text()其中r.text(), 可以在括号中指定解码方式,编码方式,例如
await resp.text(encoding=''utf-8'')或者也可以选择不编码,适合读取图像等,是无法编码的
await resp.read()2.发起一个session请求
首先是导入aiohttp模块:
import aiohttp然后我们试着获取一个web源码,这里以GitHub的公共Time-line页面为例:
async with aiohttp.ClientSession() as session:
async with session.get(''https://api.github.com/events'') as resp:
print(resp.status)
print(await resp.text())上面的代码中,我们创建了一个 ClientSession 对象命名为session,然后通过session的get方法得到一个 ClientResponse 对象,命名为resp,get方法中传入了一个必须的参数url,就是要获得源码的http url。至此便通过协程完成了一个异步IO的get请求。
有get请求当然有post请求,并且post请求也是一个协程:
session.post(''http://httpbin.org/post'', data=b''data'')用法和get是一样的,区别是post需要一个额外的参数data,即是需要post的数据。
除了get和post请求外,其他http的操作方法也是一样的:
session.put(''http://httpbin.org/put'', data=b''data'')
session.delete(''http://httpbin.org/delete'')
session.head(''http://httpbin.org/get'')
session.options(''http://httpbin.org/get'')
session.patch(''http://httpbin.org/patch'', data=b''data'')小记:
不要为每次的连接都创建一次session,一般情况下只需要创建一个session,然后使用这个session执行所有的请求。
每个session对象,内部包含了一个连接池,并且将会保持连接和连接复用(默认开启)可以加快整体的性能。
3.在URL中传递参数
我们经常需要通过 get 在url中传递一些参数,参数将会作为url问号后面的一部分发给服务器。在aiohttp的请求中,允许以dict的形式来表示问号后的参数。举个例子,如果你想传递 key1=value1 key2=value2 到 httpbin.org/get 你可以使用下面的代码:
可以看到,代码正确的执行了,说明参数被正确的传递了进去。不管是一个参数两个参数,还是更多的参数,都可以通过这种方式来传递。除了这种方式之外,还有另外一个,使用一个 list 来传递(这种方式可以传递一些特殊的参数,例如下面两个key是相等的也可以正确传递):
params = {''key1'': ''value1'', ''key2'': ''value2''}
async with session.get(''http://httpbin.org/get'',
params=params) as resp:
assert resp.url == ''http://httpbin.org/get?key2=value2&key1=value1''除了上面两种,我们也可以直接通过传递字符串作为参数来传递,但是需要注意,通过字符串传递的特殊字符不会被编码:
async with session.get(''http://httpbin.org/get'', params=''key=value+1'') as r:
assert r.url == ''http://httpbin.org/get?key=value+1''4.响应的内容
还是以GitHub的公共Time-line页面为例,我们可以获得页面响应的内容:
async with session.get(''https://api.github.com/events'') as resp:
print(await resp.text())运行之后,会打印出类似于如下的内容
''[{"created_at":"2015-06-12T14:06:22Z","public":true,"actor":{...resp的text方法,会自动将服务器端返回的内容进行解码--decode,当然我们也可以自定义编码方式:
await resp.text(encoding=''gb2312'')除了text方法可以返回解码后的内容外,我们也可以得到类型是字节的内容:
print(await resp.read())运行的结果是:
b''[{"created_at":"2015-06-12T14:06:22Z","public":true,"actor":{...gzip和deflate转换编码已经为你自动解码。
小记:
text(),read()方法是把整个响应体读入内存,如果你是获取大量的数据,请考虑使用”字节流“(streaming response)
5.特殊响应内容:json
如果我们获取的页面的响应内容是json,aiohttp内置了更好的方法来处理json:
async with session.get(''https://api.github.com/events'') as resp:
print(await resp.json())如果因为某种原因而导致resp.json()解析json失败,例如返回不是json字符串等等,那么resp.json()将抛出一个错误,也可以给json()方法指定一个解码方式:
print(await resp.json(encoding=''gb2312''))或者传递一个函数进去:
print(await resp.json( lambda(x:x.replace(''a'',''b''))))
6.以字节流的方式读取响应内容
虽然json(),text(),read()很方便的能把响应的数据读入到内存,但是我们仍然应该谨慎的使用它们,因为它们是把整个的响应体全部读入了内存。即使你只是想下载几个字节大小的文件,但这些方法却将在内存中加载所有的数据。所以我们可以通过控制字节数来控制读入内存的响应内容:
async with session.get(''https://api.github.com/events'') as resp:
await resp.content.read(10) #读取前10个字节一般地,我们应该使用以下的模式来把读取的字节流保存到文件中:
with open(filename, ''wb'') as fd:
while True:
chunk = await resp.content.read(chunk_size)
if not chunk:
break
fd.write(chunk)7.自定义请求头
如果你想添加请求头,可以像get添加参数那样以dict的形式,作为get或者post的参数进行请求:
import json
url = ''https://api.github.com/some/endpoint''
payload = {''some'': ''data''}
headers = {''content-type'': ''application/json'',"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
await session.post(url, data=json.dumps(payload), headers=headers)
8.自定义Cookie
给服务器发送cookie,可以通过给 ClientSession 传递一个cookie参数:
url = ''http://httpbin.org/cookies''
cookies = {''cookies_are'': ''working''}
async with ClientSession(cookies=cookies) as session:
async with session.get(url) as resp:
assert await resp.json() == {"cookies": {"cookies_are": "working"}}
9.post数据的几种方式
(1)模拟表单post数据
payload = {''key1'': ''value1'', ''key2'': ''value2''}
async with session.post(''http://httpbin.org/post'', data=payload) as resp:
print(await resp.text())注意:data=dict的方式post的数据将被转码,和form提交数据是一样的作用,如果你不想被转码,可以直接以字符串的形式 data=str 提交,这样就不会被转码。
(2)post json
import json
url = ''https://api.github.com/some/endpoint''
payload = {''some'': ''data''}
async with session.post(url, data=json.dumps(payload)) as resp:
pass其实json.dumps(payload)返回的也是一个字符串,只不过这个字符串可以被识别为json格式
(3)post 小文件
url = ''http://httpbin.org/post''
files = {''file'': open(''report.xls'', ''rb'')}
await session.post(url, data=files)可以设置好文件名和content-type:
url = ''http://httpbin.org/post''
data = FormData()
data.add_field(''file'', open(''report.xls'', ''rb''), filename=''report.xls'', content_type=''application/vnd.ms-excel'')
await session.post(url, data=data)如果将文件对象设置为数据参数,aiohttp将自动以字节流的形式发送给服务器。
(4)post 大文件
aiohttp支持多种类型的文件以流媒体的形式上传,所以我们可以在文件未读入内存的情况下发送大文件。
@aiohttp.streamer
def file_sender(writer, file_name=None):
with open(file_name, ''rb'') as f:
chunk = f.read(2 ** 16)
while chunk:
yield from writer.write(chunk)
chunk = f.read(2 ** 16)
# Then you can use `file_sender` as a data provider:
async with session.post(''http://httpbin.org/post'', data=file_sender(file_name=''huge_file'')) as resp:
print(await resp.text())同时我们可以从一个url获取文件后,直接post给另一个url,并计算hash值:
async def feed_stream(resp, stream):
h = hashlib.sha256()
while True:
chunk = await resp.content.readany()
if not chunk:
break
h.update(chunk)
stream.feed_data(chunk)
return h.hexdigest()
resp = session.get(''http://httpbin.org/post'')
stream = StreamReader()
loop.create_task(session.post(''http://httpbin.org/post'', data=stream))
file_hash = await feed_stream(resp, stream)因为响应内容类型是StreamReader,所以可以把get和post连接起来,同时进行post和get:
r = await session.get(''http://python.org'')
await session.post(''http://httpbin.org/post'',
data=r.content)(5)post预压缩数据
在通过aiohttp发送前就已经压缩的数据, 调用压缩函数的函数名(通常是deflate 或 zlib)作为content-encoding的值:
async def my_coroutine(session, headers, my_data):
data = zlib.compress(my_data)
headers = {''Content-Encoding'': ''deflate''}
async with session.post(''http://httpbin.org/post'', data=data, headers=headers)
pass10.keep-alive, 连接池,共享cookie
ClientSession 用于在多个连接之间共享cookie:
async with aiohttp.ClientSession() as session:
await session.get(
''http://httpbin.org/cookies/set?my_cookie=my_value'')
filtered = session.cookie_jar.filter_cookies(''http://httpbin.org'')
assert filtered[''my_cookie''].value == ''my_value''
async with session.get(''http://httpbin.org/cookies'') as r:
json_body = await r.json()
assert json_body[''cookies''][''my_cookie''] == ''my_value''也可以为所有的连接设置共同的请求头:
async with aiohttp.ClientSession(
headers={"Authorization": "Basic bG9naW46cGFzcw=="}) as session:
async with session.get("http://httpbin.org/headers") as r:
json_body = await r.json()
assert json_body[''headers''][''Authorization''] == \
''Basic bG9naW46cGFzcw==''ClientSession 还支持 keep-alive连接和连接池(connection pooling)
11.cookie安全性
默认ClientSession使用的是严格模式的 aiohttp.CookieJar. RFC 2109,明确的禁止接受url和ip地址产生的cookie,只能接受 DNS 解析IP产生的cookie。可以通过设置aiohttp.CookieJar 的 unsafe=True 来配置:
jar = aiohttp.CookieJar(unsafe=True)
session = aiohttp.ClientSession(cookie_jar=jar)12.控制同时连接的数量(连接池)
也可以理解为同时请求的数量,为了限制同时打开的连接数量,我们可以将限制参数传递给连接器:
conn = aiohttp.TCPConnector(limit=30)#同时最大进行连接的连接数为30,默认是100,limit=0的时候是无限制限制同时打开限制同时打开连接到同一端点的数量((host, port, is_ssl) 三的倍数),可以通过设置 limit_per_host 参数:
conn = aiohttp.TCPConnector(limit_per_host=30)#默认是013.自定义域名解析
我们可以指定域名服务器的 IP 对我们提供的get或post的url进行解析:
from aiohttp.resolver import AsyncResolver
resolver = AsyncResolver(nameservers=["8.8.8.8", "8.8.4.4"])
conn = aiohttp.TCPConnector(resolver=resolver)14.设置代理
aiohttp支持使用代理来访问网页:
async with aiohttp.ClientSession() as session:
async with session.get("http://python.org", proxy="http://some.proxy.com") as resp:
print(resp.status)当然也支持需要授权的页面:
async with aiohttp.ClientSession() as session:
proxy_auth = aiohttp.BasicAuth(''user'', ''pass'')
async with session.get("http://python.org", proxy="http://some.proxy.com", proxy_auth=proxy_auth) as resp:
print(resp.status)或者通过这种方式来验证授权:
session.get("http://python.org", proxy="http://user:pass@some.proxy.com")15.响应状态码 response status code
可以通过 resp.status来检查状态码是不是200:
async with session.get(''http://httpbin.org/get'') as resp:
assert resp.status == 20016.响应头
我们可以直接使用 resp.headers 来查看响应头,得到的值类型是一个dict:
>>> resp.headers
{''ACCESS-CONTROL-ALLOW-ORIGIN'': ''*'',
''CONTENT-TYPE'': ''application/json'',
''DATE'': ''Tue, 15 Jul 2014 16:49:51 GMT'',
''SERVER'': ''gunicorn/18.0'',
''CONTENT-LENGTH'': ''331'',
''CONNECTION'': ''keep-alive''}或者我们可以查看原生的响应头:
>>> resp.raw_headers
((b''SERVER'', b''nginx''),
(b''DATE'', b''Sat, 09 Jan 2016 20:28:40 GMT''),
(b''CONTENT-TYPE'', b''text/html; charset=utf-8''),
(b''CONTENT-LENGTH'', b''12150''),
(b''CONNECTION'', b''keep-alive''))17.查看cookie
url = ''http://example.com/some/cookie/setting/url''
async with session.get(url) as resp:
print(resp.cookies)18.重定向的响应头
如果一个请求被重定向了,我们依然可以查看被重定向之前的响应头信息:
>>> resp = await session.get(''http://example.com/some/redirect/'')
>>> resp
<ClientResponse(http://example.com/some/other/url/) [200]>
>>> resp.history
(<ClientResponse(http://example.com/some/redirect/) [301]>,)19.超时处理
默认的IO操作都有5分钟的响应时间 我们可以通过 timeout 进行重写:
async with session.get(''https://github.com'', timeout=60) as r:
...如果 timeout=None 或者 timeout=0 将不进行超时检查,也就是不限时长。

aiohttp 如何发送带有标头的请求
如何解决aiohttp 如何发送带有标头的请求?
import asyncio
import aiohttp
headers = {
''phone'': "Mymobile"
}
async def fetch(url,session):
async with session.get(url,headers=headers) as response:
res = await response.json()
async def main():
async with aiohttp.ClientSession() as session:
await fetch("https://www.kfc.ru/api/account/verify",session)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
错误:
headers=self.headers,aiohttp.client_exceptions.ContentTypeError: 0,message=''Attempt to decode JSON with unexpected mimetype: text/html; charset=utf-8'',url=URL(''https://www.kfc.ru/api/account/verify'')
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
今天关于aiohttp:速率限制并行请求和限制速率什么意思的分享就到这里,希望大家有所收获,若想了解更多关于.NET 7 新增速率限制 (Rate Limiting) 功能,轻松限制请求数量、1、asyncio aiohttp aiofile 异步爬取图片、aiohttp、aiohttp 如何发送带有标头的请求等相关知识,可以在本站进行查询。
本文标签:




