在本文中,我们将详细介绍如何使用Scikit-Learn包装器获得XGBoost和XGBoost的预测以进行匹配?的各个方面,并为您提供关于包装器函数的相关解答,同时,我们也将为您带来关于Adaboo
在本文中,我们将详细介绍如何使用Scikit-Learn包装器获得XGBoost和XGBoost的预测以进行匹配?的各个方面,并为您提供关于包装器函数的相关解答,同时,我们也将为您带来关于Adaboost和GBDT的区别以及xgboost和GBDT的区别、Boosting学习笔记(Adboost、GBDT、Xgboost)、LightGBM和XGBoost的区别?、ML之xgboost:利用xgboost算法对breast_cancer数据集实现二分类预测并进行graphviz二叉树节点图可视化的有用知识。
本文目录一览:- 如何使用Scikit-Learn包装器获得XGBoost和XGBoost的预测以进行匹配?(包装器函数)
- Adaboost和GBDT的区别以及xgboost和GBDT的区别
- Boosting学习笔记(Adboost、GBDT、Xgboost)
- LightGBM和XGBoost的区别?
- ML之xgboost:利用xgboost算法对breast_cancer数据集实现二分类预测并进行graphviz二叉树节点图可视化
")
如何使用Scikit-Learn包装器获得XGBoost和XGBoost的预测以进行匹配?(包装器函数)
我是Python的XGBoost的新手,所以我很抱歉,如果答案是显而易见的,但是我尝试使用panda数据框并以Python的形式获取XGBoost,以提供与使用Scikit-
Learn包装器相同时得到的相同预测行使。到目前为止,我一直无法做到这一点。举个例子,在这里我拿波士顿数据集,转换为熊猫数据框,训练该数据集的前500个观察值,然后预测最后6个。我先使用XGBoost,然后使用Scikit-
Learn包装器和即使将模型的参数设置为相同,我也会得到不同的预测。具体而言,数组预测看起来与数组预测2完全不同(请参见下面的代码)。任何帮助将非常感激!
from sklearn import datasetsimport pandas as pdimport xgboost as xgbfrom xgboost.sklearn import XGBClassifierfrom xgboost.sklearn import XGBRegressor### Use the boston data as an example, train on first 500, predict last 6 boston_data = datasets.load_boston()df_boston = pd.DataFrame(boston_data.data,columns=boston_data.feature_names)df_boston[''target''] = pd.Series(boston_data.target)#### Code using XGBoostSub_train = df_boston.head(500)target = Sub_train["target"]Sub_train = Sub_train.drop(''target'', axis=1)Sub_predict = df_boston.tail(6)Sub_predict = Sub_predict.drop(''target'', axis=1)xgtrain = xgb.DMatrix(Sub_train.as_matrix(), label=target.tolist())xgtest = xgb.DMatrix(Sub_predict.as_matrix())params = {''booster'': ''gblinear'', ''objective'': ''reg:linear'', ''max_depth'': 2, ''learning_rate'': .1, ''n_estimators'': 500, ''min_child_weight'': 3, ''colsample_bytree'': .7, ''subsample'': .8, ''gamma'': 0, ''reg_alpha'': 1}model = xgb.train(dtrain=xgtrain, params=params)predictions = model.predict(xgtest)#### Code using Sk learn Wrapper for XGBoostmodel = XGBRegressor(learning_rate =.1, n_estimators=500,max_depth=2, min_child_weight=3, gamma=0, subsample=.8, colsample_bytree=.7, reg_alpha=1, objective= ''reg:linear'')target = "target"Sub_train = df_boston.head(500)Sub_predict = df_boston.tail(6)Sub_predict = Sub_predict.drop(''target'', axis=1)Ex_List = [''target'']predictors = [i for i in Sub_train.columns if i not in Ex_List]model = model.fit(Sub_train[predictors],Sub_train[target])predictions2 = model.predict(Sub_predict)答案1
小编典典请在这里看这个答案
xgboost.train在xgboost.XGBRegressor接受时将忽略参数n_estimators
。在xgboost.train中,增强迭代(即n_estimators)由num_boost_round(默认值:10)控制
建议n_estimators从提供给xgb.train它的参数中删除并替换为num_boost_round。
因此,像这样更改您的参数:
params = {''objective'': ''reg:linear'', ''max_depth'': 2, ''learning_rate'': .1, ''min_child_weight'': 3, ''colsample_bytree'': .7, ''subsample'': .8, ''gamma'': 0, ''alpha'': 1}像这样训练xgb.train:
model = xgb.train(dtrain=xgtrain, params=params,num_boost_round=500)您将获得相同的结果。
或者,保持xgb.train不变,并像这样更改XGBRegressor:
model = XGBRegressor(learning_rate =.1, n_estimators=10, max_depth=2, min_child_weight=3, gamma=0, subsample=.8, colsample_bytree=.7, reg_alpha=1, objective= ''reg:linear'')然后,您也将获得相同的结果。

Adaboost和GBDT的区别以及xgboost和GBDT的区别
Adaboost和GBDT的区别以及xgboost和GBDT的区别
以下内容转自 https://blog.csdn.net/chengfulukou/article/details/76906710 ,本文主要用作记录收藏
AdaBoost VS GBDT
和AdaBoost一样,Gradient Boosting每次基于先前模型的表现选择一个表现一般的新模型并且进行调整。不同的是,AdaBoost是通过提升错分数据点的权重来定位模型的不足,而Gradient Boosting是通过算梯度(gradient)来定位模型的不足。因此相比AdaBoost, Gradient Boosting可以使用更多种类的目标函数,而当目标函数是均方误差时,计算损失函数的负梯度值在当前模型的值即为残差。
GBDT VS LR
从决策边界来说,线性回归的决策边界是一条直线,逻辑回归的决策边界是一条曲线,而GBDT的决策边界可能是很多条线。GBDT并不一定总是好于线性回归或逻辑回归。根据没有免费的午餐原则,没有一个算法是在所有问题上都能好于另一个算法的。根据奥卡姆剃刀原则,如果GBDT和线性回归或逻辑回归在某个问题上表现接近,那么我们应该选择相对比较简单的线性回归或逻辑回归。具体选择哪一个算法还是要根据实际问题来决定。
机器学习算法中GBDT和XGBOOST的区别有哪些?
- 基分类器的选择:传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候XGBoost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 二阶泰勒展开:传统GBDT在优化时只用到一阶导数信息,XGBoost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,XGBoost工具支持自定义损失函数,只要函数可一阶和二阶求导。
- 方差-方差权衡:XGBoost在目标函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出分数的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
- Shrinkage(缩减):相当于学习速率(xgboost中的)。XGBoost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling):XGBoost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是XGBoost异于传统GBDT的一个特性。
- 缺失值处理:XGBoost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。即对于特征的值有缺失的样本,XGBoost可以自动学习出它的分裂方向。
- XGBoost工具支持并行:Boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第次迭代的损失函数里包含了前面次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block(块)结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 线程缓冲区存储:按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer(缓冲区),主要是结合多线程、数据压缩、分片的方法,然后再计算,提高算法的效率。
- 可并行的近似直方图算法:树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
")
Boosting学习笔记(Adboost、GBDT、Xgboost)
http://www.cnblogs.com/willnote/p/6801496.html 总结得不错
AdaBoost是最著名的Boosting族算法。开始时,所有样本的权重相同,训练得到第一个基分类器。从第二轮开始,每轮开始前都先根据上一轮基分类器的分类效果调整每个样本的权重,上一轮分错的样本权重提高,分对的样本权重降低。之后根据新得到样本的权重指导本轮中的基分类器训练,即在考虑样本不同权重的情况下得到本轮错误率最低的基分类器。重复以上步骤直至训练到约定的轮数结束,每一轮训练得到一个基分类器
AdaBoost算法可以认为是一种模型为加法模型、损失函数为指数函数、学习算法为前向分步算法的而分类学习方法
GBDT
GBDT与Adboost最主要的区别在于两者如何识别模型的问题。Adaboost用错分数据点来识别问题,通过调整错分数据点的权重来改进模型。GBDT通过负梯度来识别问题,通过计算负梯度来改进模型。
xgboost
xgboost 的全称是eXtreme Gradient Boosting
GBDT算法只利用了一阶的导数信息,xgboost对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项对整体求最优解,用以权衡目标函数的下降和模型的复杂程度,避免过拟合。所以不考虑细节方面,两者最大的不同就是目标函数的定义
Bagging(套袋法)
bagging的算法过程如下:
1、从原始样本集中使用Bootstraping方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集。(k个训练集之间相互独立,元素可以有重复)
2、对于k个训练集,我们训练k个模型(这k个模型可以根据具体问题而定,比如决策树,knn等)
3、对于分类问题:由投票表决产生分类结果;
对于回归问题:由k个模型预测结果的均值作为最后预测结果。(所有模型的重要性相同)
Boosting(提升法)
boosting的算法过程如下:
1、对于训练集中的每个样本建立权值wi,表示对每个样本的关注度。当某个样本被误分类的概率很高时,需要加大对该样本的权值。
2、进行迭代的过程中,每一步迭代都是一个弱分类器。我们需要用某种策略将其组合,作为最终模型。
(例如AdaBoost给每个弱分类器一个权值,将其线性组合最为最终分类器。误差越小的弱分类器,权值越大)
Bagging,Boosting的主要区别
1、样本选择上:
Bagging采用的是Bootstrap随机有放回抽样;
而Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
2、样本权重:
Bagging使用的是均匀取样,每个样本权重相等;
Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
3、预测函数:
Bagging所有的预测函数的权重相等;
Boosting中误差越小的预测函数其权重越大。
4、并行计算:
Bagging各个预测函数可以并行生成;
Boosting各个预测函数必须按顺序迭代生成。
1)Bagging + 决策树 = 随机森林 RF
- 2)AdaBoost + 决策树 = 提升树
- 3)Gradient Boosting + 决策树 = GBDT
- 常用的决策树算法有ID3,C4.5,CART三种。
1、CART树是二叉树,而ID3和C4.5可以是多叉树
2、CART在生成子树时,是选择一个特征一个取值作为切分点,生成两个子树
选择特征和切分点的依据是基尼指数,选择基尼指数最小的特征及切分点生成子树
梯度提升决策树GBDT
Gradient Boosting Decision Tree
GBDT也是迭代,使用了前向分布算法,但是弱学习器限定了只能使用CART回归树模型,同时迭代思路和Adaboost也有所不同

LightGBM和XGBoost的区别?
首先声明,LightGBM是针对大规模数据(样本量多,特征多)时,对XGBoost算法进行了一些优化,使得速度有大幅度提高,但由于优化方法得当,而精度没有减少很多或者变化不大,理论上还是一个以精度换速度的目的。如果数据量不大,那就对XGBoost没有什么优势了。
我认为有这几点:
1.GOSS(Gradient-based One-Side Sampling),基于梯度的单侧采样,对训练样本的采样。
如原始训练数据100w,高梯度数据有1w,那么会计算 1w+随机选择b%*余下的99w数据,然后把后部分数据进行加倍(*(1-a)/b),基于这些数据来得到特征的切分点。
2.EFB(Exclusive Feature Bundling),排斥特征整合,通过对某些特征整合来降低特征数量。
上面两点是在原论文中多次提到的,主要的不同。
参考原论文:https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
其它的我认为还有两点:
3.查找连续变量 切分点 的方法
XGBoost默认使用的是pre-sorted algorithm,即先将连续变量排序,然后从前向后计算每个切分点后的信息增益,这样算法复杂度是#data*#feature。好像也可以支持使用histogram。
LightGBM使用的是histogram-based algorithms,即将连续值先bin成k箱,然后再求切分点,每次计算切分点的复杂度是#k*#feature,但这样会有一些精度损失。但由于,a粗精度可以相当于正则化的效果,防止过拟合。b单棵树的精度可能会差一些,但在gbdt框架下,总体的效果不一定差。c在gbdt中决策树是弱模型,精度不高影响也不大。
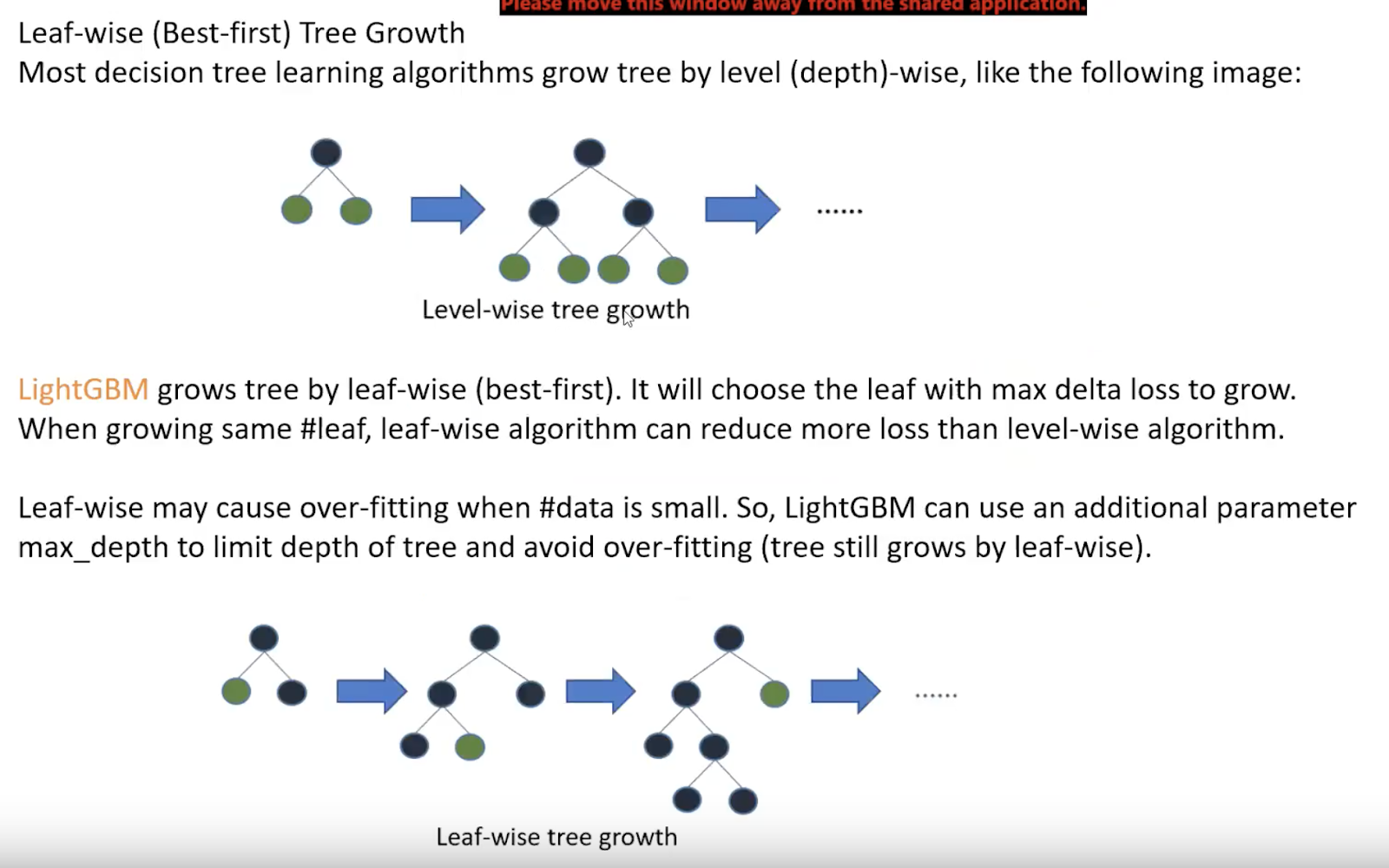
4.树的生长方式
XGBoost是level(depdh)-wise,即左右子树都是一样深的,要生长一块生长,要停一块停。
LightGBM是leaf-wise,即可能左右子树是不一样深的,即使左子树已经比右子树深很多,但只要左子树的梯度划分仍然比右子树占优,就继续在左子树进行划分。
5、对类别特征的支持
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1 特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM 优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1 展开。并在决策树算法上增加了类别特征的决策规则。在 Expo 数据集上的实验,相比0/1 展开的方法,训练速度可以加速 8 倍,并且精度一致。据我们所知,LightGBM 是第一个直接支持类别特征的 GBDT 工具。
参考:https://blog.csdn.net/friyal/article/details/82756777
lightGBM原理

ML之xgboost:利用xgboost算法对breast_cancer数据集实现二分类预测并进行graphviz二叉树节点图可视化
ML之xgboost:利用xgboost算法对breast_cancer数据集实现二分类预测并进行graphviz二叉树节点图可视化
目录
实现结果
实现代码
实现结果


今天关于如何使用Scikit-Learn包装器获得XGBoost和XGBoost的预测以进行匹配?和包装器函数的介绍到此结束,谢谢您的阅读,有关Adaboost和GBDT的区别以及xgboost和GBDT的区别、Boosting学习笔记(Adboost、GBDT、Xgboost)、LightGBM和XGBoost的区别?、ML之xgboost:利用xgboost算法对breast_cancer数据集实现二分类预测并进行graphviz二叉树节点图可视化等更多相关知识的信息可以在本站进行查询。
本文标签:




