如果您想了解PostgresqlGROUP_CONCAT等效?的知识,那么本篇文章将是您的不二之选。同时我们将深入剖析concat和concat_ws()区别及group_concat(),repea
如果您想了解Postgresql GROUP_CONCAT 等效?的知识,那么本篇文章将是您的不二之选。同时我们将深入剖析concat和concat_ws()区别及group_concat() ,repeat()字符串函数_MySQL、group_concat on postgresql、MSSQL – GROUP_CONCAT、my sql Group_concat 函数的各个方面,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- Postgresql GROUP_CONCAT 等效?
- concat和concat_ws()区别及group_concat() ,repeat()字符串函数_MySQL
- group_concat on postgresql
- MSSQL – GROUP_CONCAT
- my sql Group_concat 函数

Postgresql GROUP_CONCAT 等效?
我有一张表,我想为每个 id 拉一行,并连接字段值。
例如,在我的表中,我有这个:
TM67 | 4 | 32556TM67 | 9 | 98200TM67 | 72 | 22300TM99 | 2 | 23009TM99 | 3 | 11200我想输出:
TM67 | 4,9,72 | 32556,98200,22300TM99 | 2,3 | 23009,11200在 MySQL 中,我能够使用聚合函数GROUP_CONCAT,但这似乎在这里不起作用...... PostgreSQL
是否有等价物,或者其他方式来完成这个?
答案1
小编典典这可能是一个很好的起点(仅限 8.4+ 版):
SELECT id_field, array_agg(value_field1), array_agg(value_field2)FROM data_tableGROUP BY id_fieldarray_agg返回一个数组,但您可以将其转换为文本并根据需要进行编辑(请参阅下面的说明)。
在 8.4 版本之前,您必须在使用之前自己定义它:
CREATE AGGREGATE array_agg (anyelement)( sfunc = array_append, stype = anyarray, initcond = ''{}'');(从 PostgreSQL 文档解释)
说明:
- 将数组转换为文本的结果是生成的字符串以花括号开头和结尾。如果不需要,这些大括号需要通过某种方法移除。
- 将 ANYARRAY 转换为 TEXT 可以最好地模拟 CSV 输出,因为包含嵌入式逗号的元素在标准 CSV 样式的输出中被双引号引起来。array_to_string() 或 string_agg()(9.1 中添加的“group_concat”函数)都没有引用嵌入逗号的字符串,导致结果列表中的元素数量不正确。
- 新的 9.1 string_agg() 函数不会首先将内部结果转换为 TEXT。因此,如果 value_field 是整数,“string_agg(value_field)”会产生错误。”string_agg(value_field::text)” 将是必需的。array_agg() 方法只需要在聚合之后进行一次转换(而不是对每个值进行一次转换)。
区别及group_concat() ,repeat()字符串函数_MySQL")
concat和concat_ws()区别及group_concat() ,repeat()字符串函数_MySQL
1、concat()函数
1.1
mysql> select concat(''10'');
+--------------+
| concat(''10'') |
+--------------+
| 10 |
+--------------+
1 row in set (0.00 sec)
mysql> select concat(''11'',''22'',''33'');
+------------------------+
| concat(''11'',''22'',''33'') |
+------------------------+
| 112233 |
+------------------------+
1 row in set (0.00 sec)
而Oracle的concat函数只能连接两个字符串
SQL> select concat(''11'',''22'') from dual;
点击下载“修复打印机驱动工具”;
1.2 MySQL的concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
mysql> select concat(''11'',''22'',null);
+------------------------+
| concat(''11'',''22'',null) |
+------------------------+
| NULL |
+------------------------+
1 row in set (0.00 sec)
而Oracle的concat函数连接的时候,只要有一个字符串不是NULL,就不会返回NULL
SQL> select concat(''11'',NULL) from dual;
CONCAT
--
11
2、concat_ws()函数, 表示concat with separator,即有分隔符的字符串连接
如连接后以逗号分隔
mysql> select concat_ws('','',''11'',''22'',''33'');
+-------------------------------+
| concat_ws('','',''11'',''22'',''33'') |
+-------------------------------+
| 11,22,33 |
+-------------------------------+
1 row in set (0.00 sec)
和concat不同的是, concat_ws函数在执行的时候,不会因为NULL值而返回NULL
mysql> select concat_ws('','',''11'',''22'',NULL);
+-------------------------------+
| concat_ws('','',''11'',''22'',NULL) |
+-------------------------------+
| 11,22 |
+-------------------------------+
1 row in set (0.00 sec)
3、group_concat()可用来行转列, Oracle没有这样的函数 (mysql4.1及以上 )
完整的语法如下
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator ''分隔符''])
如下例子
mysql> select * from aa;
+------+------+
| id | name |
+------+------+
| 1 | 10 |
| 1 | 20 |
| 1 | 20 |
| 2 | 20 |
| 3 | 200 |
| 3 | 500 |
+------+------+
6 rows in set (0.00 sec)
3.1 以id分组,把name字段的值打印在一行,逗号分隔(默认)
mysql> select id,group_concat(name) from aa group by id;
+------+--------------------+
| id | group_concat(name) |
+------+--------------------+
| 1 | 10,20,20 |
| 2 | 20 |
| 3 | 200,500 |
+------+--------------------+
3 rows in set (0.00 sec)
3.2 以id分组,把name字段的值打印在一行,分号分隔
mysql> select id,group_concat(name separator '';'') from aa group by id;
+------+----------------------------------+
| id | group_concat(name separator '';'') |
+------+----------------------------------+
| 1 | 10;20;20 |
| 2 | 20 |
| 3 | 200;500 |
+------+----------------------------------+
3 rows in set (0.00 sec)
3.3 以id分组,把去冗余的name字段的值打印在一行,逗号分隔
mysql> select id,group_concat(distinct name) from aa group by id;
+------+-----------------------------+
| id | group_concat(distinct name) |
+------+-----------------------------+
| 1 | 10,20 |
| 2 | 20 |
| 3 | 200,500 |
+------+-----------------------------+
3 rows in set (0.00 sec)
3.4 以id分组,把name字段的值打印在一行,逗号分隔,以name排倒序
mysql> select id,group_concat(name order by name desc) from aa group by id;
+------+---------------------------------------+
| id | group_concat(name order by name desc) |
+------+---------------------------------------+
| 1 | 20,20,10 |
| 2 | 20 |
| 3 | 500,200 |
+------+---------------------------------------+
3 rows in set (0.00 sec)
4、repeat()函数,用来复制字符串,如下''ab''表示要复制的字符串,2表示复制的份数
mysql> select repeat(''ab'',2);
+----------------+
| repeat(''ab'',2) |
+----------------+
| abab |
+----------------+
1 row in set (0.00 sec)
又如
mysql> select repeat(''a'',2);
+---------------+
| repeat(''a'',2) |
+---------------+
| aa |
+---------------+
1 row in set (0.00 sec)
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/shuicaohui5/archive/2008/10/23/3129489.aspx

group_concat on postgresql
MysqL:
Postgresql:
first approach:
second approach (MysqL-compatible approach):
MysqL GROUP_CONCAT with ordering:
Postgresql equivalent:
using customized sort:
http://s2.diffuse.it/blog/show/10-group_concat_on_postgresql

MSSQL – GROUP_CONCAT
IdProduit Localisation Qte_EnMain 4266864286880063006 E2-R40-B-T 13.00000 4266864286880063006 E2-R45-B-T 81.00000 4266864286880063007 E2-R45-C-T 17.00000 4266864286880063008 E2-R37-B-T 8.00000
这就是我想要的
IdProduit AllLocalisation 4266864286880063006 E2-R40-B-T (13),E2-R45-B-T (81) 4266864286880063007 E2-R45-C-T (17) 4266864286880063008 E2-R37-B-T (8)
我在论坛上看了GROUP_CONCAT的所有例子,我尝试了几个测试.
我真的不懂STUFF().
这是我想做的事情:
SELECT
a.IdProduit,GROUP_CONCAT(
CONCAT(b.Localisation,' (',CAST(ROUND(a.Qte_EnMain,0) AS NUMERIC(36,0)),')')
) AS AllLocation
FROM
ogasys.INV_InventENTLoc a
LEFT JOIN ogasys.INV_LocName b ON a.IdLoc = b.IdLoc
GROUP BY a.IdProduit,b.Localisation,a.Qte_EnMain
现在因为GROUP_CONCAT不能和MSsql一起工作,这是我在这个论坛上用所有例子创建的查询.
SELECT
disTINCT
a1.IdProduit,STUFF((SELECT disTINCT '' + b2.Localisation
FROM
ogasys.INV_InventENTLoc a2
LEFT JOIN ogasys.INV_LocName b2 ON a2.IdLoc = b2.IdLoc
WHERE a2.IdLoc = a1.IdLoc
FOR XML PATH(''),TYPE).value('.','NVARCHAR(MAX)'),1,'') data
FROM
ogasys.INV_InventENTLoc a1
LEFT JOIN ogasys.INV_LocName b1 ON a1.IdLoc = b1.IdLoc
ORDER BY a1.IdProduit
查询仅按行返回一个本地化我不明白如何使此查询工作.
编辑:
这是我的情况的解决方案:
SELECT
a.IdProduit,STUFF(
(SELECT ',' + b2.Localisation + ' (' + CAST(CAST(ROUND(a2.Qte_EnMain,0)) AS VARCHAR(32)) + ')'
FROM ogasys.INV_InventENTLoc a2
LEFT JOIN ogasys.INV_LocName b2 ON a2.IdLoc = b2.IdLoc
WHERE a.IdProduit = a2.IdProduit
FOR XML PATH ('')),'') AS AllLocalisation
FROM
ogasys.INV_InventENTLoc a
LEFT JOIN ogasys.INV_LocName b ON a.IdLoc = b.IdLoc
GROUP BY a.IdProduit
解决方法
declare @table table (IdProduit varchar(100),Localisation varchar(50),Qte_EnMain float)
insert into @table
values
('4266864286880063006','E2-R40-B-T',13.00000),('4266864286880063006','E2-R45-B-T',81.00000),('4266864286880063007','E2-R45-C-T',17.00000),('4266864286880063008','E2-R37-B-T',8.00000)
select IdProduit,STUFF (
(SELECT
',' + localisation + concat(' (',cast(qte_enMain as varchar(4)),') ')
FROM @table t2
where t2.IdProduit = t1.IdProduit
FOR XML PATH('')),''
)
from @table t1
group by
IdProduit

my sql Group_concat 函数
完整语法如下
group_concat ([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '' 分隔符 ''])
SELECT * FROM testgroup
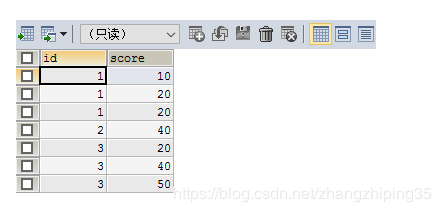
表结构与数据如上
现在的需求就是每个 id 为一行 在前台每行显示该 id 所有分数
group_concat 上场!!!
SELECT id,GROUP_CONCAT(score) FROM testgroup GROUP BY id
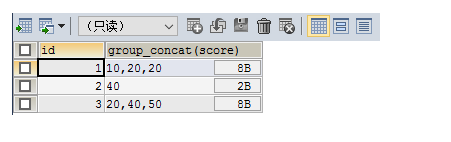
可以看到 根据 id 分成了三行 并且分数默认用 逗号 分割 但是有每个 id 有重复数据 接下来去重
SELECT id,GROUP_CONCAT(DISTINCT score) FROM testgroup GROUP BY id
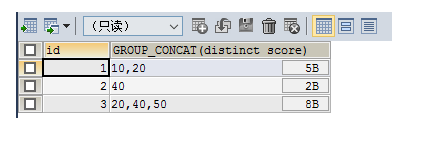
排序
SELECT id,GROUP_CONCAT(score ORDER BY score DESC) FROM testgroup GROUP BY id
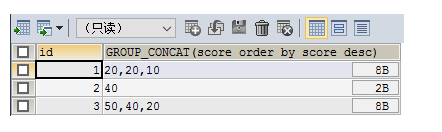
最后可以设置分隔符
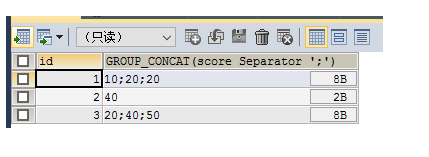
SELECT id,GROUP_CONCAT(score SEPARATOR '';'') FROM testgroup GROUP BY id
今天关于Postgresql GROUP_CONCAT 等效?的分享就到这里,希望大家有所收获,若想了解更多关于concat和concat_ws()区别及group_concat() ,repeat()字符串函数_MySQL、group_concat on postgresql、MSSQL – GROUP_CONCAT、my sql Group_concat 函数等相关知识,可以在本站进行查询。
本文标签:




