这篇文章主要围绕UNIX下IO模型分析和unixio模型展开,旨在为您提供一份详细的参考资料。我们将全面介绍UNIX下IO模型分析的优缺点,解答unixio模型的相关问题,同时也会为您带来BIO模型分
这篇文章主要围绕UNIX下IO模型分析和unix io模型展开,旨在为您提供一份详细的参考资料。我们将全面介绍UNIX下IO模型分析的优缺点,解答unix io模型的相关问题,同时也会为您带来BIO模型分析、I/O模型和Java NIO源码分析、I/O模型系列之三:IO通信模型BIO NIO AIO、IO 模型之一:Unix 的五种 I/O 模型的实用方法。
本文目录一览:")
UNIX下IO模型分析(unix io模型)
UNIX下IO模型分析
对UNIX下的五种常见IO模型分析,帮助理解
IO操作的两个阶段
以读数据操作为例:
1. 等待内核数据准备(数据拷贝到内核缓冲区)
2. 将数据从内核拷贝到用户空间
IO模型
UNIX下共有五种常见的IO模型:
下面以recvfrom接口举例
阻塞IO
默认情况下,所有的套接字都是阻塞的
调用recvfrom接口,进程在IO操作的两个阶段都会阻塞,直到最终数据拷贝到用户空间或者过程中出现错误才会返回,进程在阻塞状态下是不占用cpu资源的
最常见的错误是发生系统中断,此时需要重读,可参考这里
非阻塞IO
可以通过fcntl(sockfd,F_SETFL,O_NONBLOCK)将套接字设置成非阻塞
调用recvfrom接口,无论内核缓冲区是否有可用数据,进程都会立即返回,所以在IO操作的第一阶段是非阻塞的; 若无数据可用,内核将errno设置为为EWOULDBLOCK或者EAGAIN,进程可以使用轮询的方法,保证内核在数据准备好时,能立即拷贝到用户空间; 若有则立即将数据拷贝到用户空间,进程在数据拷贝到用户空间即IO操作的第二阶段是阻塞的;
非阻塞IO过于消耗cpu时间,将大部分时间用于轮询
多路复用IO
多路复用系统调用:select,poll和epoll,其中windows平台不支持poll和epoll,使用方法可以参考I/O 多路复用之select、poll、epoll详解和Linux select/poll和epoll实现机制对比
调用select,等待内核数据准备,所以IO操作的第一个阶段,进程是阻塞的,不过是阻塞在多路复用系统调用上,而不是IO系统调用上; 当select返回套接字可读条件时,再调用recvfrom将数据从内核拷贝到用户空间,IO操作的第二阶段,进程是阻塞的
多路复用IO和阻塞IO,在IO操作的两个阶段都是阻塞的,不过多路复用IO使用了两个系统调用,而阻塞IO只使用了一个,所以在连接数不是很多的情况下,阻塞IO可能性能更佳; 多路复用IO的优势在于可以同时监控多个用于IO的文件描述符。
多线程中的阻塞IO,与多路复用IO极为相似
信号驱动IO
调用sigaction等系统调用安装信号处理函数,并立即返回,所以IO操作的第一阶段,进程是非阻塞的; 当内核数据准备好时,内核会产生一个信号,通知进程将数据从内核拷贝到用户空间,IO操作的第二阶段,进程是阻塞的
使用方法:IO的多路复用和信号驱动
异步IO
异步IO有一组以aio开头的系统调用,使用方法可参考Linux AIO机制
调用异步IO系统调用,给内核传递描述字、缓冲区指针、缓冲区大小(与read相同的三个参数)、文件偏移(与lseek类似),告诉内核当整个操作完成时如何通知我们,并立即返回,在IO操作的两个阶段,进程都不阻塞
总结
- 同步IO和异步IO的主要区别是将数据从内核拷贝到用户空间是否阻塞,前者会在将数据从内核拷贝到用户空间时即IO操作的第二个阶段发生阻塞,而后者则在系统调用后直接返回,直到内核发送信号通知IO操作完成,在IO操作的两个阶段都没有阻塞
- 阻塞IO和非阻塞IO的主要区别是系统调用是否立即返回(默认将数据从内核拷贝到用户空间即IO操作的第二个阶段是立即返回的),前者会在IO操作的两个阶段完成前一直阻塞,后者在内核没有准备好数据的情况下立即返回,即只会在IO操作的第二个阶段阻塞
- 信号驱动IO和异步IO的主要区别在于前者由内核通知我们何时启动一个IO操作,在将数据从内核拷贝到用户空间过程中即IO操作的第一个阶段依旧是阻塞的,而后者是由内核通知我们IO操作何时完成,在IO操作的两个阶段都没有阻塞
知乎上有一个比较生动的例子可以说明这几种模型之间的关系。
Reference
- UNIX网络编程 卷1:套接字联网API
- Linux IO模式及 select、poll、epoll详解
- Linux下5种IO模型的小结
- UNIX网络编程读书笔记:I/O模型(阻塞、非阻塞、I/O复用、信号驱动、异步)
- IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
- Linux五种IO模型性能分析
About me
- GitHub:AnSwErYWJ
- Blog:http://www.answerywj.com
- Email:yuanweijie1993@gmail.com
- Weibo:@AnSwEr不是答案
- CSDN:AnSwEr不是答案的专栏
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. 本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。

BIO模型分析
伪代码
class Server {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPollExecutor(100);
serverSocket.bind(9090);
//主线程等待新连接的到来
while (!Thread.currentThread.isInturrupted()) {
Socket socket = serverSocket.accpet();
//将新的连接交给线程池处理
executor.submit(new ConnectIOHandler(socket));
}
}
}
class ConnectIOHandler implements Runnable {
private Socket socket;
public ConnectIOHandler(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
while (!Thread.currentThread.isInturruted()) {
//读取数据
String data = socket.read()....
if (data != null) {
//处理数据
dosomething();
//写数据
socket.write()...
}
}
}
}上述模型的一些特性:
1. 每连接每线程。socket.accept()、socket.read()、socket.write()这三个函数均是同步阻塞,当一个连接在处理I/O时,系统是阻塞的,如果是单线程的话必然会挂死。开启多线程,会将CPU释放出来,可以处理更多的事情。
2. 使用线程池,降低线程创建和回收的成本。
缺点就是严重依赖线程:
1. 线程的创建和销毁的成本很高,在Linux中,线程本质就是一个进程(科普:Linux里面的线程其实是通过fork函数来fork一个子进程的方式来实现的,并且是通过关闭COW(Copy on Write)特性来实现线程间独立但是又共享父进程内存的效果。总而言之,在Linux世界里,线程其实就是进程,进程是Linux内核调度的实体。),创建和销毁都是重量级的系统函数。
2. 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间(不显式设置-Xss或-XX:ThreadStackSize时,在Linux x64上ThreadStackSize的默认值就是1024KB,给Java线程创建栈会用这个参数指定的大小。),并发高时,JVM的内存会吃紧。
3. 线程的切换成本高,操作系统线程切换时,需要保留线程的上下文,然后进行系统调用。高并发时,可能会导致线程切换的时间大于线程执行的时间,带来系统load偏高,CPU sy使用率特别高,导致系统陷入几乎不可用状态。
4. 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。

I/O模型和Java NIO源码分析
最近在学习Java网络编程和Netty相关的知识,了解到Netty是NIO模式的网络框架,但是提供了不同的Channel来支持不同模式的网络通信处理,包括同步、异步、阻塞和非阻塞。学习要从基础开始,所以我们就要先了解一下相关的基础概念和Java原生的NIO。这里,就将最近我学习的知识总结一下,以供大家了解。
为了节约你的时间,本文主要内容如下:
- 异步,阻塞的概念
- 操作系统I/O的类型
- Java NIO的底层实现
异步,同步,阻塞,非阻塞
同步和异步关注的是消息通信机制,所谓同步就是调用者进行调用后,在没有得到结果之前,该调用一直不会返回,但是一旦调用返回,就得到了返回值,同步就是指调用者主动等待调用结果;而异步则相反,执行调用之后直接返回,所以可能没有返回值,等到有返回值时,由被调用者通过状态,通知来通知调用者.异步就是指被调用者来通知调用者调用结果就绪.所以,二者在消息通信机制上有所不同,一个是调用者检查调用结果是否就绪,一个是被调用者通知调用者结果就绪
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.阻塞调用是指在调用结果返回之前,当前线程会被挂起,调用线程只有在得到结果之后才会继续执行.非阻塞调用是指在不能立刻得到结构之前,调用线程不会被挂起,还是可以执行其他事情.
两组概念相互组合就有四种情况,分别是同步阻塞,同步非阻塞,异步阻塞,异步非阻塞.我们来举个例子来分别类比上诉四种情况.
比如你要从网上下载一个1G的文件,按下下载按钮之后,如果你一直在电脑旁边,等待下载结束,这种情况就是同步阻塞;如果你不需要一直呆在电脑旁边,你可以去看一会书,但是你还是隔一段时间来查看一下下载进度,这种情况就是同步非阻塞;如果你一直在电脑旁边,但是下载器在下载结束之后会响起音乐来提醒你,这就是异步阻塞;但是如果你不呆在电脑旁边,去看书,下载器下载结束后响起音乐来提醒你,那么这种情况就是异步非阻塞.
Unix的I/O类型
知道上述两组概念之后,我们来看一下Unix下可用的5种I/O模型:
- 阻塞I/O(bloking IO)
- 非阻塞I/O(nonblocking IO)
- 多路复用I/O(IO multiplexing)
- 信号驱动I/O(signal driven IO)
- 异步I/O(asynchronous IO)
前4种都是同步,只有最后一种是异步I/O.需要注意的是Java NIO依赖于Unix系统的多路复用I/O,对于I/O操作来说,它是同步I/O,但是对于编程模型来说,它是异步网络调用.下面我们就以系统read的调用来介绍不同的I/O类型.
当一个read发生时,它会经历两个阶段:
- 1 等待数据准备
- 2 将数据从内核内存空间拷贝到进程内存空间中
不同的I/O类型,在这两个阶段中有不同的行为.但是由于这块内容比较多,而且多为表述性的知识,所以这里我们只给出几张图片来解释,感觉兴趣的同学可以去具体了解一下。





Java NIO的底层实现
我们都知道Netty通过JNI的方式提供了Native Socket Transport,为什么Netty要提供自己的Native版本的NIO呢?明明Java NIO底层也是基于epoll调用(最新的版本)的.这里,我们先不明说,大家想一想可能的情况.下列的源码都来自于OpenJDK-8u40-b25版本.
open方法
如果我们顺着Selector.open()方法一个类一个类的找下去,很容易就发现Selector的初始化是由DefaultSelectorProvider根据不同操作系统平台生成的不同的SelectorProvider,对于Linux系统,它会生成EPollSelectorProvider实例,而这个实例会生成EPollSelectorImpl作为最终的Selector实现.
class EPollSelectorImpl extends SelectorImpl
{
.....
// The poll object
EPollArrayWrapper pollWrapper;
.....
EPollSelectorImpl(SelectorProvider sp) throws IOException {
.....
pollWrapper = new EPollArrayWrapper();
pollWrapper.initInterrupt(fd0, fd1);
.....
}
.....
} EpollArrayWapper将Linux的epoll相关系统调用封装成了native方法供EpollSelectorImpl使用.
private native int epollCreate();
private native void epollCtl(int epfd, int opcode, int fd, int events);
private native int epollWait(long pollAddress, int numfds, long timeout,
int epfd) throws IOException;上述三个native方法就对应Linux下epoll相关的三个系统调用
//创建一个epoll句柄,size是这个监听的数目的最大值.
int epoll_create(int size);
//事件注册函数,告诉内核epoll监听什么类型的事件,参数是感兴趣的事件类型,回调和监听的fd
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
//等待事件的产生,类似于select调用,events参数用来从内核得到事件的集合
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); 所以,我们会发现在EpollArrayWapper的构造函数中调用了epollCreate方法,创建了一个epoll的句柄.这样,Selector对象就算创造完毕了.
register方法
与open类似,ServerSocketChannel的register函数底层是调用了SelectorImpl类的register方法,这个SelectorImpl就是EPollSelectorImpl的父类.
protected final SelectionKey register(AbstractSelectableChannel ch,
int ops,
Object attachment)
{
if (!(ch instanceof SelChImpl))
throw new IllegalSelectorException();
//生成SelectorKey来存储到hashmap中,一共之后获取
SelectionKeyImpl k = new SelectionKeyImpl((SelChImpl)ch, this);
//attach用户想要存储的对象
k.attach(attachment);
//调用子类的implRegister方法
synchronized (publicKeys) {
implRegister(k);
}
//设置关注的option
k.interestOps(ops);
return k;
} EpollSelectorImpl的相应的方法实现如下,它调用了EPollArrayWrapper的add方法,记录下Channel所对应的fd值,然后将ski添加到keys变量中.在EPollArrayWrapper中有一个byte数组eventLow记录所有的channel的fd值.
protected void implRegister(SelectionKeyImpl ski) {
if (closed)
throw new ClosedSelectorException();
SelChImpl ch = ski.channel;
//获取Channel所对应的fd,因为在linux下socket会被当作一个文件,也会有fd
int fd = Integer.valueOf(ch.getFDVal());
fdToKey.put(fd, ski);
//调用pollWrapper的add方法,将channel的fd添加到监控列表中
pollWrapper.add(fd);
//保存到HashSet中,keys是SelectorImpl的成员变量
keys.add(ski);
} 我们会发现,调用register方法并没有涉及到EpollArrayWrapper中的native方法epollCtl的调用,这是因为他们将这个方法的调用推迟到Select方法中去了.
Select方法
和register方法类似,SelectorImpl中的select方法最终调用了其子类EpollSelectorImpl的doSelect方法
protected int doSelect(long timeout) throws IOException {
.....
try {
....
//调用了poll方法,底层调用了native的epollCtl和epollWait方法
pollWrapper.poll(timeout);
} finally {
....
}
....
//更新selectedKeys,为之后的selectedKeys函数做准备
int numKeysUpdated = updateSelectedKeys();
....
return numKeysUpdated;
} 由上述的代码,可以看到,EPollSelectorImpl先调用EPollArrayWapper的poll方法,然后在更新SelectedKeys.其中poll方法会先调用epollCtl来注册先前在register方法中保存的Channel的fd和感兴趣的事件类型,然后epollWait方法等待感兴趣事件的生成,导致线程阻塞.
int poll(long timeout) throws IOException {
updateRegistrations(); ////先调用epollCtl,更新关注的事件类型
////导致阻塞,等待事件产生
updated = epollWait(pollArrayAddress, NUM_EPOLLEVENTS, timeout, epfd);
.....
return updated;
} 等待关注的事件产生之后(或在等待时间超过预先设置的最大时间),epollWait函数就会返回.select函数从阻塞状态恢复.
selectedKeys方法
我们先来看SelectorImpl中的selectedKeys方法.
//是通过Util.ungrowableSet生成的,不能添加,只能减少
private Set<SelectionKey> publicSelectedKeys;
public Set<SelectionKey> selectedKeys() {
....
return publicSelectedKeys;
} 很奇怪啊,怎麽直接就返回publicSelectedKeys了,难道在select函数的执行过程中有修改过这个变量吗?
publicSelectedKeys这个对象其实是selectedKeys变量的一份副本,你可以在SelectorImpl的构造函数中找到它们俩的关系,我们再回头看一下select中updateSelectedKeys方法.
private int updateSelectedKeys() {
//更新了的keys的个数,或在说是产生的事件的个数
int entries = pollWrapper.updated;
int numKeysUpdated = 0;
for (int i=0; i<entries; i++) {
//对应的channel的fd
int nextFD = pollWrapper.getDescriptor(i);
//通过fd找到对应的SelectionKey
SelectionKeyImpl ski = fdToKey.get(Integer.valueOf(nextFD));
if (ski != null) {
int rOps = pollWrapper.getEventOps(i);
//更新selectedKey变量,并通知响应的channel来做响应的处理
if (selectedKeys.contains(ski)) {
if (ski.channel.translateAndSetReadyOps(rOps, ski)) {
numKeysUpdated++;
}
} else {
ski.channel.translateAndSetReadyOps(rOps, ski);
if ((ski.nioReadyOps() & ski.nioInterestOps()) != 0) {
selectedKeys.add(ski);
numKeysUpdated++;
}
}
}
}
return numKeysUpdated;
}后记
看到这里,详细大家都已经了解到了NIO的底层实现了吧.这里我想在说两个问题.
一是为什么Netty自己又从新实现了一边native相关的NIO底层方法? 听听Netty的创始人是怎麽说的吧链接。因为Java的版本使用的epoll的level-triggered模式,而Netty则希望使用edge-triggered模式,而且Java版本没有将epoll的部分配置项暴露出来,比如说TCP_CORK和SO_REUSEPORT。
二是看这么多源码,花费这么多时间有什么作用呢?我感觉如果从非功利的角度来看,那么就是纯粹的希望了解的更多,有时候看完源码或在理解了底层原理之后,都会用一种恍然大悟的感觉,比如说AQS的原理.如果从目的性的角度来看,那么就是你知道底层原理之后,你的把握性就更强了,如果出了问题,你可以更快的找出来,并且解决.除此之外,你还可以按照具体的现实情况,以源码为模板在自己造轮子,实现一个更加符合你当前需求的版本.
后续如果有时间,我希望好好了解一下epoll的操作系统级别的实现原理.


I/O模型系列之三:IO通信模型BIO NIO AIO
一、传统的BIO
网络编程的基本模型是Client/Server模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息(绑定的IP地址和监听端口),客户端通过连接操作向服务端监听的地址发起连接请求,通过三次握手建立连接,如果连接建立成功,双方就可以通过网络套接字(Socket)进行通信。
在基于传统同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听端口,Socket负责发起连接操作,连接成功之后,双方通过输入和输出流进行同步阻塞式通信。
BIO通信模型图
BIO的服务端通信模型:采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的一请求一应答通信模型。
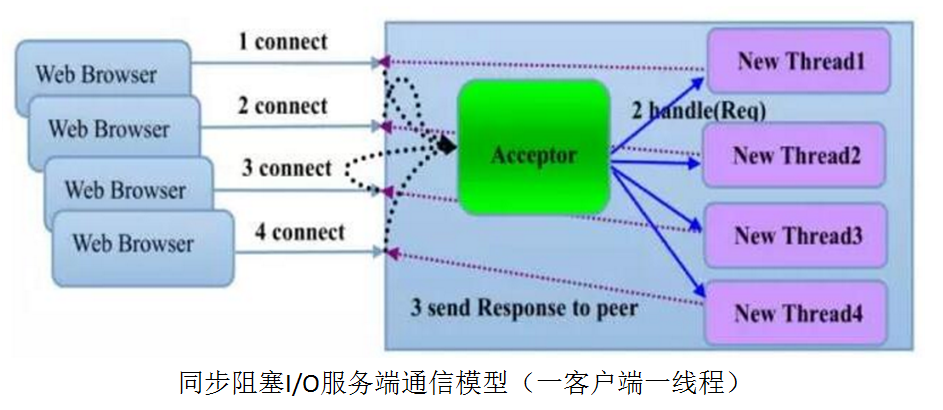
该模型最大的问题就是缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程个数和客户端并发访问数呈1:1的正比关系,由于线程是JAVA虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统的性能将急剧下降,随着并发访问量的继续增大,系统会发生线程堆栈溢出、创建新线程失败等问题,并最终导致进程宕机或者僵死,不能对外提供服务。
它的弊端有很多:
1.性能问题:一连接一线程模型导致服务端的并发接入数和系统吞吐量受到极大限制;
2.可靠性问题:由于I/O操作采用同步阻塞模式,当网络拥塞或者通信对端处理缓慢会导致I/O线程被挂住,阻塞时间无法预测;
3.可维护性问题:I/O线程数无法有效控制、资源无法有效共享(多线程并发问题),系统可维护性差;
二、伪异步IO编程
为了解决同步阻塞IO面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化,后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N,通过线程池可以灵活的调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。 下面,我们结合连接模型图和源码,对伪异步IO进行分析,看它是否能够解决同步阻塞IO面临的问题。
伪异步IO模型图
采用线程池和任务队列可以实现一种叫做伪异步的IO通信框架,它的模型图如下:

当有新的客户端接入的时候,将客户端的Socket封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK的线程池维护一个消息队列和N个活跃线程对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
三、NIO(多路复用器Selector)
Java NIO的实现关键是通过多路复用IO技术实现的,多路复用的核心就是通过Selector来轮询注册在其上的Channel,当发现某个或者多个Channel处于就绪状态后,从阻塞状态返回就绪的Channel的选择键集合,进行IO操作。
所有的 IO 在NIO 中都从一个Channel 开始。Channel 有点象流。 数据可以从Channel读到Buffer中,也可以从Buffer 写到Channel中。

Selector允许单线程处理多个Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。例如,在一个聊天服务器中。
这是在一个单线程中使用一个Selector处理3个Channel的图示:

四、AIO异步IO
五、几种IO模型对比

BIO | NIO | AIO 以Java的角度,理解如下:
-
- BIO,同步阻塞式IO,简单理解:一个线程处理一个连接,发起和处理IO请求都是同步的
- NIO,同步非阻塞IO,简单理解:一个线程处理多个连接,发起IO请求是非阻塞的但处理IO请求是同步的
- AIO,异步非阻塞IO,简单理解:一个有效请求一个线程,发起和处理IO请求都是异步的
1 BIO模型中通过Socket和ServerSocket完成套接字通道实现。阻塞,同步,连接耗时。
2 NIO模型中通过SocketChannel和ServerSocketChannel完成套接字通道实现。非阻塞/阻塞,同步,避免TCP建立连接使用三次握手带来的开销。
3 AIO模型中通过AsynchronousSocketChannel和AsynchronousServerSocketChannel完成套接字通道实现。非阻塞,异步
BIO 阻塞同步通信模式,客户端和服务器连接需要三次握手,使用简单,但吞吐量小
NIO 非阻塞同步通信模式,客户端与服务器通过Channel连接,采用多路复用器轮询注册的Channel。提高吞吐量和可靠性。
AIO 非阻塞异步通信模式,NIO的升级版,采用异步通道实现异步通信,其read和write方法均是异步方法。
六、抄录网址
BIO、NIO、AIO 区别和应用场景
java BIO/NIO/AIO 学习
Java 网络IO编程总结(BIO、NIO、AIO均含完整实例代码)
Netty序章之BIO NIO AIO演变

IO 模型之一:Unix 的五种 I/O 模型
1 阻塞 I/O(blocking IO)
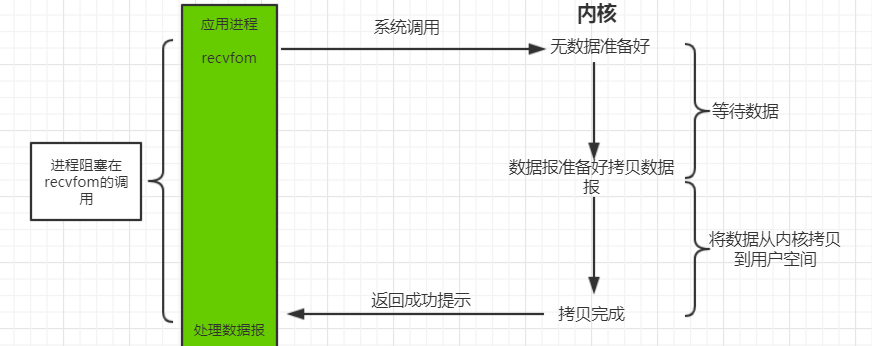
应用程序调用一个 IO 函数,导致应用程序阻塞,如果数据已经准备好,从内核拷贝到用户空间,否则一直等待下去。一个典型的读操作流程大致如下图,当用户进程调用 recvfrom 这个系统调用时,kernel 就开始了 IO 的第一个阶段:准备数据,就是数据被拷贝到内核缓冲区中的一个过程(很多网络 IO 数据不会那么快到达,如没收一个完整的 UDP 包),等数据到操作系统内核缓冲区了,就到了第二阶段:将数据从内核缓冲区拷贝到用户内存,然后 kernel 返回结果,用户进程才会解除 block 状态,重新运行起来。blocking IO 的特点就是在 IO 执行的两个阶段用户进程都会 block 住;
2 非阻塞 I/O(nonblocking IO)
非阻塞 I/O 模型,我们把一个套接口设置为非阻塞就是告诉内核,当所请求的 I/O 操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的 I/O 操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用 CPU 的时间。
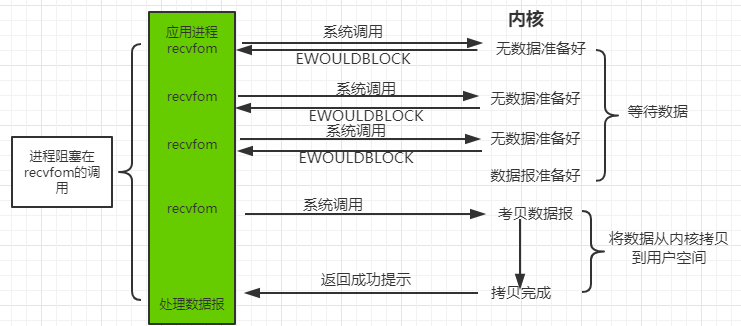
当用户进程发出 read 操作时,如果 kernel 中数据还没准备好,那么并不会 block 用户进程,而是立即返回 error,用户进程判断结果是 error,就知道数据还没准备好,用户可以再次发 read,直到 kernel 中数据准备好,并且用户再一次发 read 操作,产生 system call,那么 kernel 马上将数据拷贝到用户内存,然后返回;所以 nonblocking IO 的特点是用户进程需要不断的主动询问 kernel 数据好了没有。
阻塞 IO 一个线程只能处理一个 IO 流事件,要想同时处理多个 IO 流事件要么多线程要么多进程,这样做效率显然不会高,而非阻塞 IO 可以一个线程处理多个流事件,只要不停地询所有流事件即可,当然这个方式也不好,当大多数流没数据时,也是会大量浪费 CPU 资源;为了避免 CPU 空转,引进代理 (select 和 poll,两种方式相差不大),代理可以观察多个流 I/O 事件,空闲时会把当前线程阻塞掉,当有一个或多个 I/O 事件时,就从阻塞态醒过来,把所有 IO 流都轮询一遍,于是没有 IO 事件我们的程序就阻塞在 select 方法处,即便这样依然存在问题,我们从 select 出只是知道有 IO 事件发生,却不知道是哪几个流,还是只能轮询所有流,epoll 这样的代理就可以把哪个流发生怎样的 IO 事件通知我们;
3 I/O 多路复用模型 (IO multiplexing)
I/O 多路复用就在于单个进程可以同时处理多个网络连接 IO, 基本原理就是 select,poll,epoll 这些个函数会不断轮询所负责的所有 socket,当某个 socket 有数据到达了,就通知用户进程,这三个 functon 会阻塞进程,但和 IO 阻塞不同,这些函数可以同时阻塞多个 IO 操作,而且可以同时对多个读操作,写操作 IO 进行检验,直到有数据到达,才真正调用 IO 操作函数,调用过程如下图;所以 IO 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符 (套接字描述符) 其中任意一个进入就绪状态,select 函数就可以返回。
IO 多路复用的优势在于并发数比较高的 IO 操作情况,可以同时处理多个连接,和 bloking IO 一样 socket 是被阻塞的,只不过在多路复用中 socket 是被 select 阻塞,而在阻塞 IO 中是被 socket IO 给阻塞。
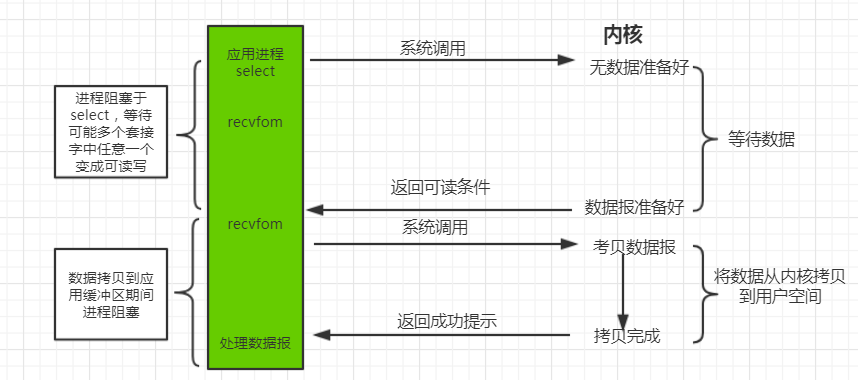
4 信号驱动 I/O 模型
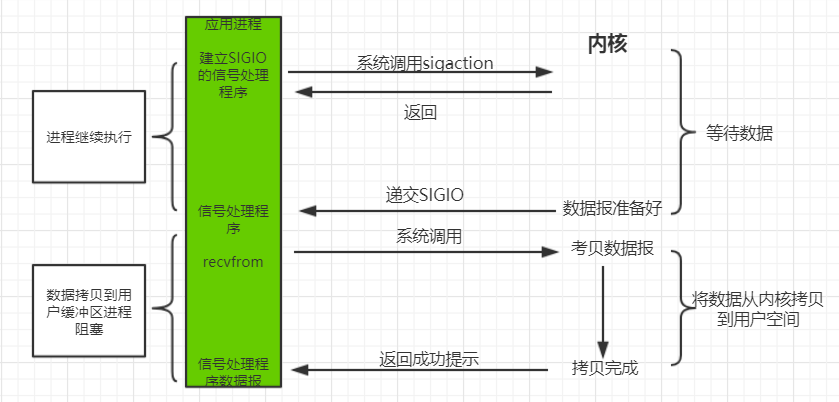
可以用信号,让内核在描述符就绪时发送 SIGIO 信号通知我们,通过 sigaction 系统调用安装一个信号处理函数。该系统调用将立即返回,我们的进程继续工作,也就是说它没有被阻塞。当数据报准备好读取时,内核就为该进程产生一个 SIGIO 信号。我们随后既可以在信号处理函数中调用 recvfrom 读取数据报,并通知主循环数据已经准备好待处理。特点:等待数据报到达期间进程不被阻塞。主循环可以继续执行,只要等待来自信号处理函数的通知:既可以是数据已准备好被处理,也可以是数据报已准备好被读取
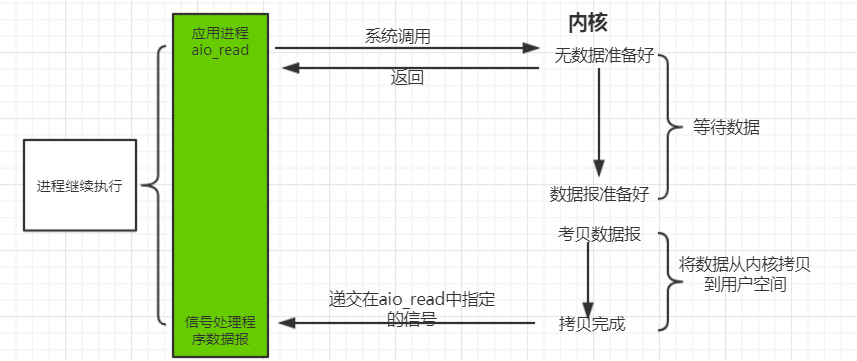
5 异步 I/O(asynchronous IO)
异步 IO 告知内核启动某个操作,并让内核在整个操作 (包括将内核数据复制到我们自己的缓冲区) 完成后通知我们,调用 aio_read(Posix 异步 I/O 函数以 aio_或 lio_开头)函数,给内核传递描述字、缓冲区指针、缓冲区大小(与 read 相同的 3 个参数)、文件偏移以及通知的方式,然后系统立即返回。我们的进程不阻塞于等待 I/0 操作的完成。当内核将数据拷贝到缓冲区后,再通知应用程序。
用户进程发起 read 操作之后,立刻就可以开始去做其它的事。而另一方面,从 kernel 的角度,当它受到一个 asynchronous read 之后,首先它会立刻返回,所以不会对用户进程产生任何 block。然后,kernel 会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel 会给用户进程发送一个 signal,告诉它 read 操作完成了
我们今天的关于UNIX下IO模型分析和unix io模型的分享已经告一段落,感谢您的关注,如果您想了解更多关于BIO模型分析、I/O模型和Java NIO源码分析、I/O模型系列之三:IO通信模型BIO NIO AIO、IO 模型之一:Unix 的五种 I/O 模型的相关信息,请在本站查询。
本文标签:




