对于想了解的读者,本文将是一篇不可错过的文章,我们将详细介绍单机CentOS7_64位系统下搭建Hadoop_2.8.0分布式环境,并且为您提供关于64位CentOS系统下安装配置伪分布式hadoop
对于想了解的读者,本文将是一篇不可错过的文章,我们将详细介绍单机CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境,并且为您提供关于64位CentOS系统下安装配置伪分布式hadoop 2.5.2、centos 64位 hadoop 完全分布式安装、CentOS 7.6搭建Hadoop2.9.2完全分布式集群,狠详细!、CentOS 7下Hadoop3.1伪分布式环境搭建的有价值信息。
本文目录一览:- (单机)CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境
- 64位CentOS系统下安装配置伪分布式hadoop 2.5.2
- centos 64位 hadoop 完全分布式安装
- CentOS 7.6搭建Hadoop2.9.2完全分布式集群,狠详细!
- CentOS 7下Hadoop3.1伪分布式环境搭建
CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境")
(单机)CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境
准备条件:
CentOS 7 64位操作系统 | 选择minimal版本即可(不带可视化桌面环境),也可以选择带完整版
Hadoop-2.8.0 | 本文采用的是Hadoop-2.8.0版本。
JDK1.8 | 本文采用jdk-8u131-linux-x64.tar.gz版本。
- 解压并配置JDK并配置Hadoop
1. 将下载好的jdk放入/usr 下并在/usr目录下新建java目录
[root@localhost /]# cd /usr [root@localhost usr]# mkdir java [root@localhost usr]# cd /usr/java/jdk1.8
进入该目录,并解压jdk到当前文件夹
tar -xzvf jdk-8.tar.gz
解压得到文件夹修改文件夹名为jdk1.8以方便使用。
修改JAVA环境变量:
编辑java环境 vi ~/.bash_profile
添加如下命令:
export JAVA_HOME=/usr/java/jdk1.8.0_121 export PATH=$JAVA_HOME/bin:$PATH
执行source ~/.bash_profile 使变量生效
2. 解压hadoop-2.8.0
将下载好的Hadoop压缩包解压到目标文件夹下,(本文解压目录为:/usr/local)
修改解压后得到Hadoop的文件夹名为:Hadoop-2.8.0 并得到如下文件:
Hadoop不需要安装,下面进行环境配置
下面的修改过程可使用vi命令,或者vim命令,或使用xftp直接对文件进行修改
再次修改
bash_profile添加hadoop的文件路径:
加上之前修改的配置的jdk环境,改该文件整体修改为:
PATH=$PATH:$HOME/bin export PATH export JAVA_HOME=/usr/java/jdk1.8 export HADOOP_HOME=/usr/local/hadoop-2.8.0 export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin
再次执行 source ~/.bash_profile 使得文件立即生效
修改
etc/hadoop/core-site.xml将configurarion标签修改为:注意:192.168.0.181是本文的测试地址,相应的,需要修改成自己虚拟机的ip地址,如果虚拟机不是桥接方式,则可以改为:127.0.0.19000是Hadoop的默认端口,建议先不要修改
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.181:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.8.0/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
-
修改
etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-2.8.0/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-2.8.0/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.0.181:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>以上,分别配置的是相应的几个节点和安全认证,文件目录会在服务开启时自动创建
dfs.permissions设置为false可以允许完全分布式模式下的多机访问
-
修改
etc/hadoop/yarn-site.xml<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.0.181:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.0.181:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.0.181:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.0.181:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.0.181:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>6078</value> </property> </configuration> -
修改
etc/hadoop/hadoop-env.sh# The java implementation to use.
exportJAVA_HOME=/usr/java/jdk1.8以上修改JAVA_HOME为绝对路径
修改
etc/hadoop/mapred-site.xml注意:etc/hadoop/目录下并没有这个xml文件,仔细查找,有个mapred-site.xml.template把这个文件复制,重命名为mapred-site.xml并修改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.0.181:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.0.181:19888</value>
</property>
</configuration>
修改
etc/hadoop/yarn-env.sh
在其中找到export JAVA_HOME并去掉注释,编辑java地址export JAVA_HOME=/usr/java/jdk1.8
修改
etc/hadoop/slaves
添加当前主机ip
至此,基本配置已经完毕
3. 列表项目
hadoop目录下执行如下指令,进行编译
./bin/hdfs namenode –format
出现如上图,表示编译成功。
4. 关闭防火墙:
关闭防火墙服务:systemctl stop firewalld.service
使防火墙服务不随机器启动:systemctl disable firewalld.service
开启Hadoop服务
./sbin/start-all.sh
输入jps查看相关节点是否开启
打开浏览器:地址栏输入http://192.168.0.181:8088
使用过程中遇到的问题:
问题一:nameNode节点无法启动,jps目录缺少相应活动程序
在第一次格式化dfs后启动并使用了Hadoop,后来又重新执行了格式化命令hdfs namenode –format
这时namenode的clusterID会重新生成,而datanode的clusterID保持不变。
从而导致两者的id不一致,出现一系列错误。
解决办法:
到hadoop/hdfs目录下分别查看data/current下的VERSION和name/current下的VERSION文件对比两文件中的clusterID是否相同,若不同,使用name/current下的VERSION中的clusterID覆盖data/current下的clusterID. 修改后重新启动Hadoop即可问题二:如何配置单机互信?
每次启动和关闭Hadoop的时候,都需要频繁输入多次密码,通过配置单机互信或者多机互信来简化操作:
解决办法:
使用指令:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
随后:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
并执行:chmod 600 .ssh/authorized_keys
即可。-
问题三:在完全分布式模式下运行失败,无法登陆或没有访问权限
解决办法:
修改etc/hadoop/hdfs-site.xml
添加<property> <name>dfs.permissions</name> <value>false</value> </property>

64位CentOS系统下安装配置伪分布式hadoop 2.5.2
安装完之后进行配置,首先所有的配置文件从上一版本的hadoop/conf换成了hadoop/etc/hadoop,在hadoop安装目录下,修改 etc/hadoop/core-site.xml,将其配置为: configuration property namehadoop.tmp.dir/name value/usr/hadoop/tmp/value descriptionA ba
安装完之后进行配置,首先所有的配置文件从上一版本的hadoop/conf换成了hadoop/etc/hadoop,在hadoop安装目录下,修改 etc/hadoop/core-site.xml,将其配置为:
然后执行修改etc/hadoop/hdfs-site.xml进行第二项配置:
请注意上述路径都需要自己手动用mkdir创建,具体位置也可以自己选择,其中dfs.replication的值建议配置为与分布式 cluster 中实际的 DataNode 主机数一致,在这里由于是伪分布式环境所以设置其为1。
接下来修改 etc/hadoop/mapred-site.xml配置其使用 Yarn 框架执行 map-reduce 处理程序,内容如下:
最后修改 etc/hadoop/yarn-site.xml对yarn进行配置,其内容如下:
然后格式化:

centos 64位 hadoop 完全分布式安装
##### ####安装hadoop完全分布式集群 ##### ####文件及系统版本: #### hadoop-1.2.1 Javaversion1.7.0_79 centos64位 ####预备 #### 在/home/hadoop/下:mkdirCloud 把java和hadoop安装包放在/home/hadoop/Cloud下 ####配置静态ip #### master 192.168.116.100 slave1 192.168.116.110 slave2 192.168.116.120 ####修改机器相关名称(都是在root权限下) #### suroot vim/etc/hosts 在原信息下输入:(空格+tab) master 192.168.116.100 slave1 192.168.116.110 slave2 192.168.116.120 vim/etc/hostname master shutdown-rNow(重启机器) vim/etc/hostname slave1 shutdown-rNow vim/etc/hostname slave2 shutdown-rNow ####安装openssh #### suroot yuminstallopenssh ssh-keygen-trsa 然后一直确认 把slave1和slave2的公钥发给master: scp/home/hadoop/.ssh/id_rsa.pubhadoop@master:~/.ssh/slave1.pub scp/home/hadoop/.ssh/id_rsa.pubhadoop@master:~/.ssh/slave2.pub 在master下:cd.ssh/ catid_rsa.pub>>authorized_keys catslave1.pub>>authorized_keys catslave2.pub>>authorized_keys 把公钥包发给slave1和slave2: scpauthorized_keyshadoop@slave1:~/.ssh/ scpauthorized_keyshadoop@slave2:~/.ssh/ sshslave1 sshslave2 sshmaster 相应的输入yes 到这里ssh无密码登录配置完成 ####设计JAVA_HOMEHADOOP_HOME #### suroot vim/etc/profile 输入: exportJAVA_HOME=/home/hadoop/Cloud/jdk1.7.0_79 exportJRE_HOME=$JAVA_HOME/jre exportCLAsspATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar exportHADOOP_HOME=/home/hadoop/Cloud/hadoop-1.2.1 exportPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 然后source/etc/profile ####配置hadoop文件 #### 在/home/hadoop/Cloud/hadoop-1.2.1/conf下 vimmasters输入: master vimslaves输入: master slave1 slave2 vimhadoop-env.sh输入: exportJAVA_HOME=/home/hadoop/Cloud/jdk1.7.0_79 exportHADOOP_HOME_WARN_SUPPRESS="TRUE" 然后sourcehadoop-env.sh vimcore-site.xml输入: ###################################core <configuration> <property> <name>io.native.lib.avaliable</name> <value>true</value> </property> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> <final>true</final> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/Cloud/workspace/temp</value> </property> </configuration> ############################core vimhdfs-site.xml ##############################hdfs <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/Cloud/workspace/hdfs/data</value> <final>true</final> </property> <property> <name>dfs.namenode.dir</name> <value>/home/hadoop/Cloud/workspace/hdfs/name</value> </property> <property> <name>dfs.datanode.dir</name> <value>/home/hadoop/Cloud/workspace/hdfs/data</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> ##################################hdfs vimmapred-site.xml ####################################mapred <configuration> <property> <name>mapred.job.tracker</name> <value>master:9001</value> </property> </configuration> ######################################mapred 到这里hadoop配置完成 把hadoop发送到slave1和slave2 scp-rhadoop-1.2.1hadoop@slave1:~/Cloud/ scp-rhadoop-1.2.1hadoop@slave2:~/Cloud/ ########现在可以启动hadoop啦 ######## 首先格式化namenode hadoopnamenode-format(由于前面设计了hadoop-env.sh和系统环境,所以在任意目录下都可以执行) 查看日志没错的话往下 start-all.sh 然后 完整的的话会出现: [hadoop@master~]$jps 8330JobTracker 8452TaskTracker 8246SecondaryNameNode 8125Datanode 8000NameNode 8598Jps [hadoop@master~]$sshslave1 Lastlogin:ThuJan1207:08:062017frommaster [hadoop@slave1~]$jps 3885Datanode 3970TaskTracker 4078Jps [hadoop@slave1~]$sshslave2 Lastlogin:ThuJan1207:20:452017frommaster [hadoop@slave2~]$jps 2853TaskTracker 2771Datanode 2960Jps 至此,hadoop完全分布式配置完成。 下面是hadoop的浏览器端口号: localhost:50030/fortheJobtracker localhost:50070/fortheNamenode localhost:50060/fortheTasktracker 从此走上大数据这条不归路。。。

CentOS 7.6搭建Hadoop2.9.2完全分布式集群,狠详细!
一、概述
本文基于宿主机Win10笔记本(8G+256固态,连接无线wifi)+三台虚拟机进行搭建。以下为搭建的详细过程,接近于现场直播Live。
二、软件环境准备
使用到具体软件及版本如下:
虚拟机VMware
VMware-workstation-full-12.5.7-5813279.exe
下载地址 https://my.vmware.com/web/vmware/details?productId=524&rPId=20840&downloadGroup=WKST-1257-WIN 
Centos
CentOS-7-x86_64-Minimal-1810.iso(最小安装盘,只有必要的软件,自带的软件最少,只有918 MB)
下载地址 http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1810.iso 
JDK
jdk-8u181-linux-x64.tar.gz
下载地址 https://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html 
Hadoop
hadoop-2.9.2.tar.gz
下载地址 https://archive.apache.org/dist/hadoop/core/hadoop-2.9.2/
其他使用到的工具
远程连接工具Xshell6
上传工具xftp6
三、虚拟机准备
创建新的虚拟机,用于克隆,作为基础虚拟机,直接看图说话(虚拟机准备好的可略过)
新建虚拟机

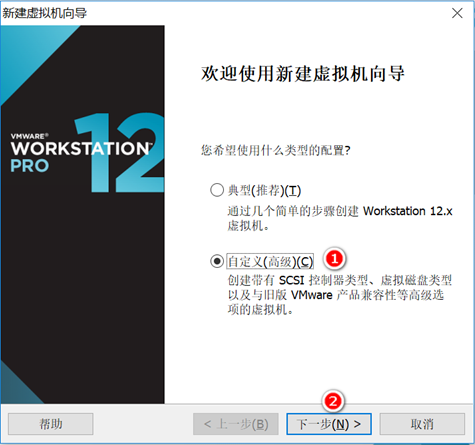
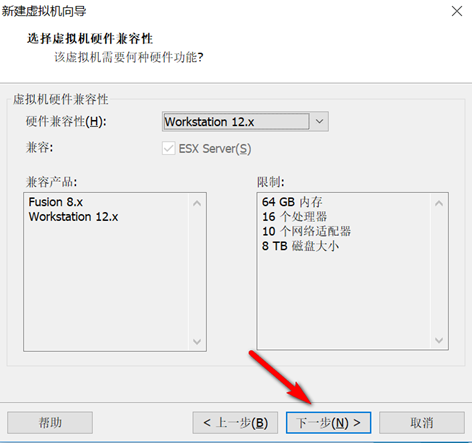
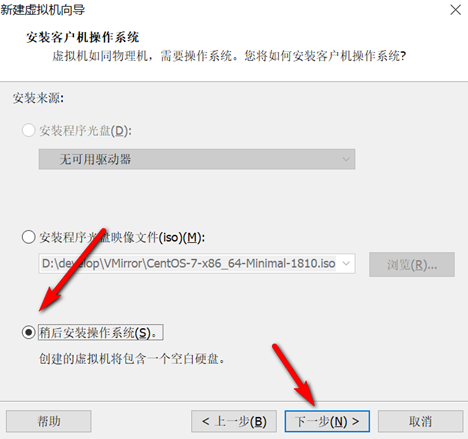
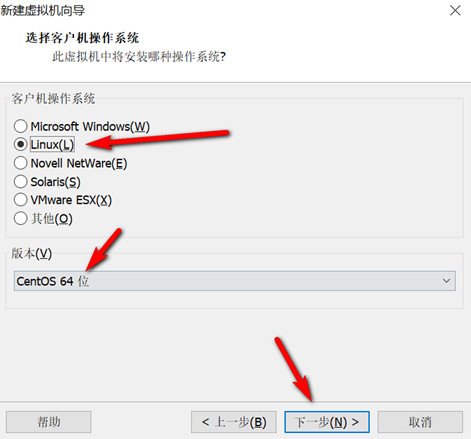
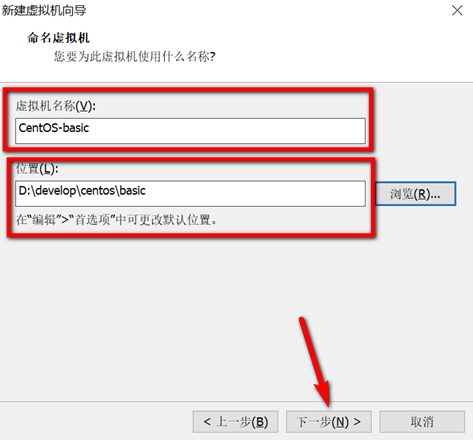
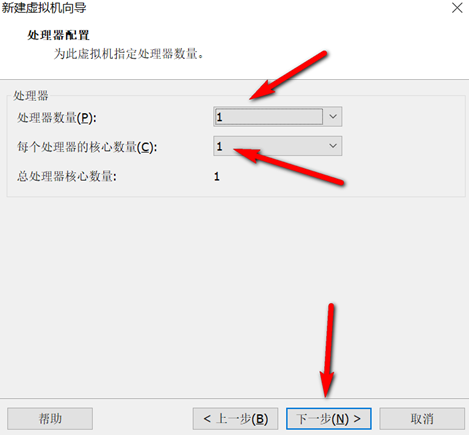
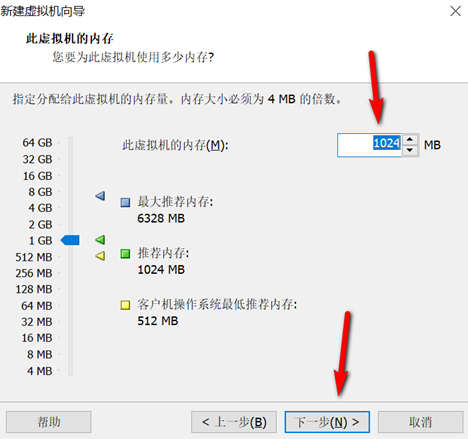
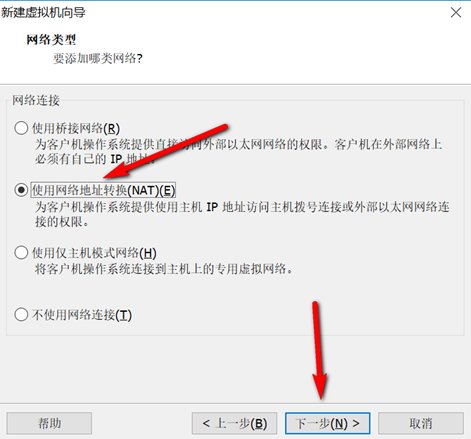

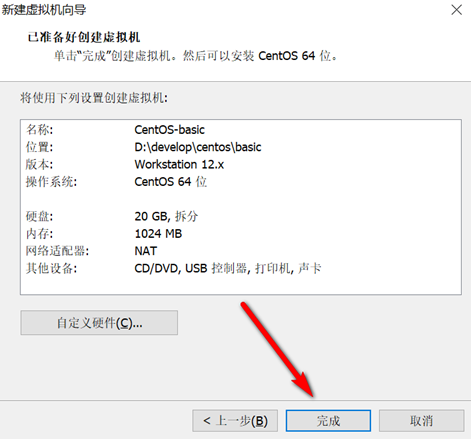

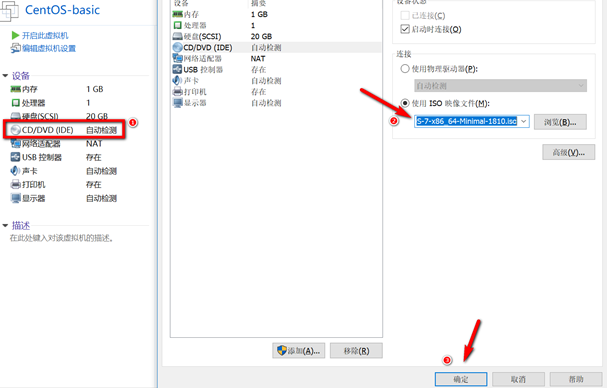
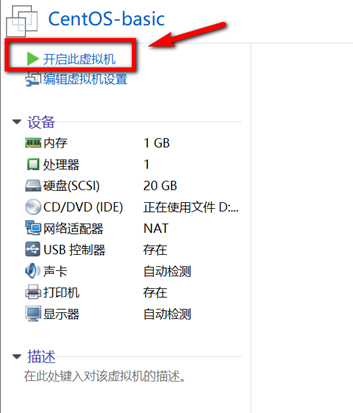
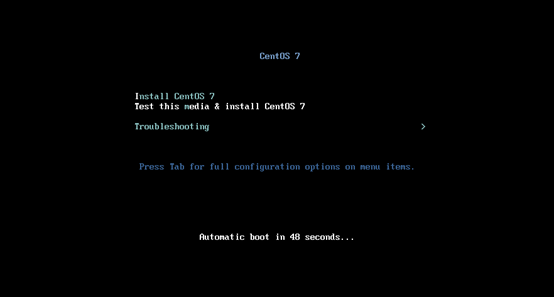
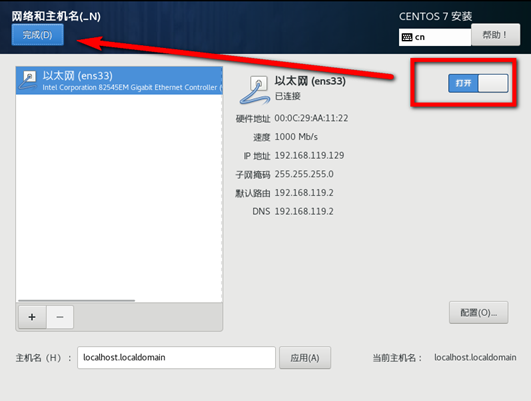
网络设置
VMware和Windows网络设置

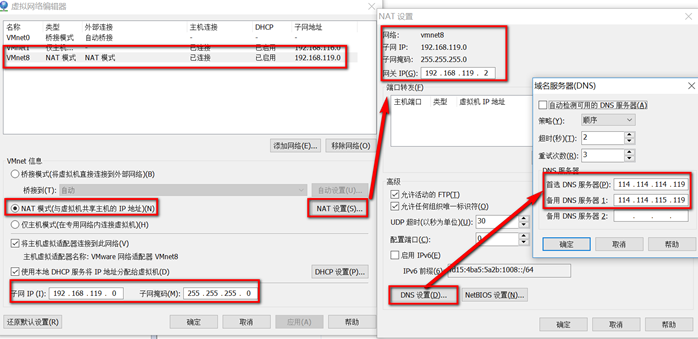
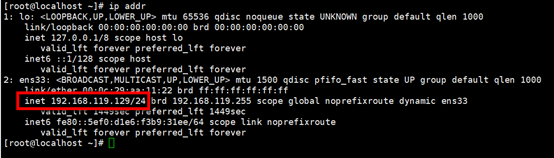
设置IP 网关 DNS
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改前
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="dafc2038-f4fc-4a6d-b704-30e3c32f52e9"
DEVICE="ens33"
ONBOOT="yes"
修改后
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="dafc2038-f4fc-4a6d-b704-30e3c32f52e9"
DEVICE="ens33"
ONBOOT="yes"
#实时生效
NM_CONTROLLED="yes"
#ip
IPADDR=192.168.119.130
#网关
GATEWAY=192.168.119.2
#子网掩码
NETMASK=255.255.255.0
#使用主的DNS
DNS1=114.114.114.119
#备用的DNS
DNS2=114.114.115.119
修改主机名
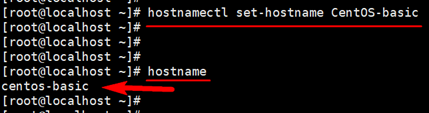
hostnamectl set-hostname centos-basic
查看主机名 hostname
关闭防火墙
//临时关闭
systemctl stop firewalld
//禁止开机启动
systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.

关闭SELinxu命令(永久)
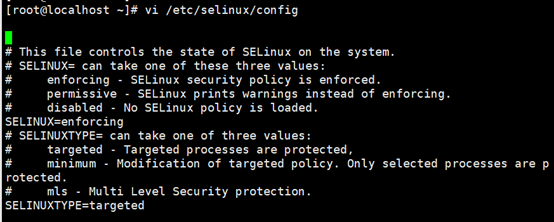
将SELINUX=enforcing改为SELINUX=disabled ,设置后需要重启才能生效。
vi /etc/selinux/config
修改前:
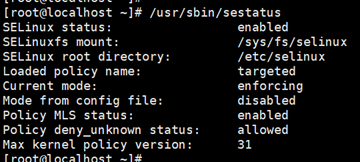
查看 /usr/sbin/sestatus/
修改后:

reboot重启后查看

创建用户并设置文件权限
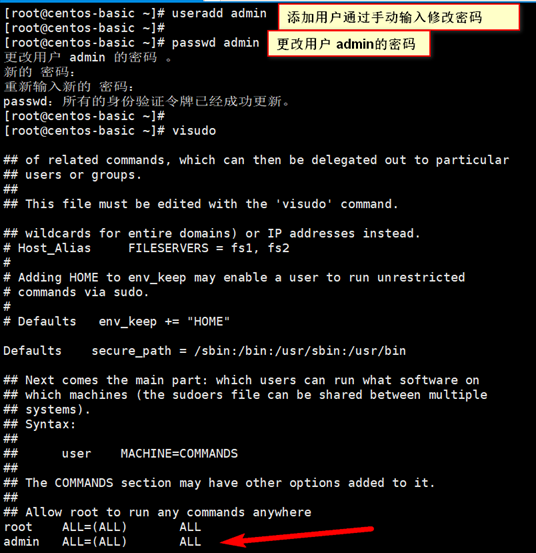
visudo操作时:vi编辑器一般模式下,
/root 定位到root所在行
yy 复制
p 粘贴
然后将root 改成admin即可
:x 保存退出,切换至admin用户 su - admin

创建文件夹并修改权限 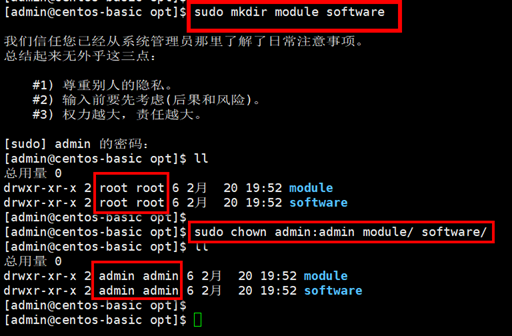
关机快照克隆
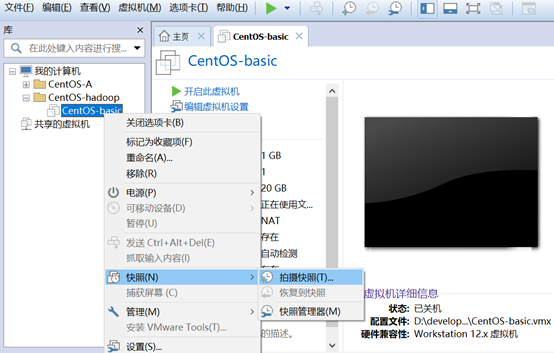
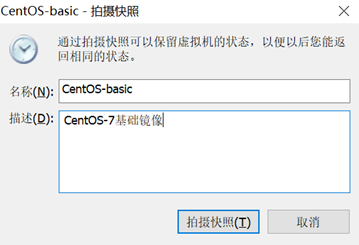
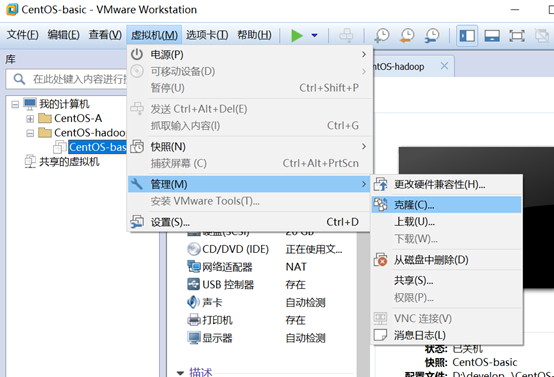
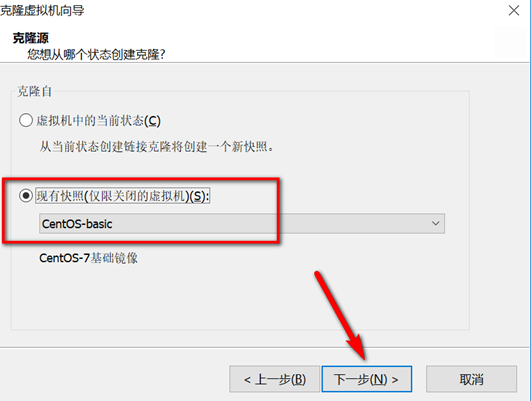
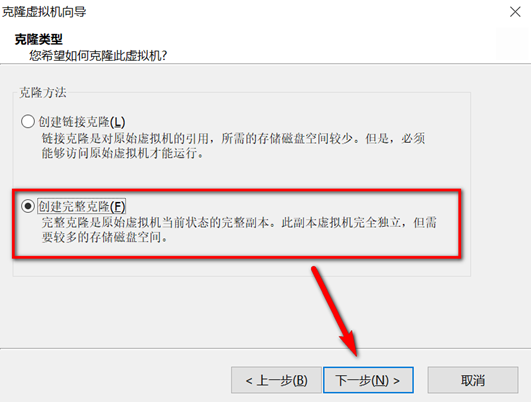
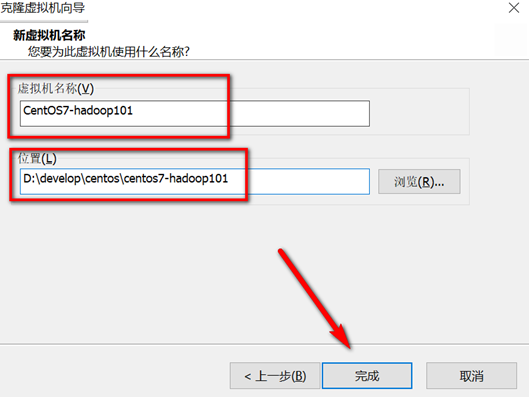
克隆完成后,打开新克隆的虚拟机进行如下操作:
修改静态Ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.119.101
修改主机名
hostnamectl set-hostname hadoop101
添加主机名与ip映射关系
vi /etc/hosts
192.168.119.101 hadoop101
192.168.119.102 hadoop102
192.168.119.103 hadoop103
重启生效
reboot
本地映射配置(宿主机)
C:\Windows\System32\drivers\etc\hosts
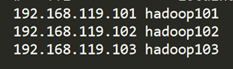
同hadoop101操作再克隆hadoop102、hadoop103。
四、安装JDK
登陆hadoop101 虚拟机 用xftp6将jdk和hadoop安装包上传至/opt/software文件夹下

解压jdk至/opt/module/文件夹下
tar -zxvf /opt/software/jdk-8u181-linux-x64.tar.gz -C /opt/module/
配置jdk环境变量
先获取jdk路径
[root@hadoop101 jdk1.8.0_181]# pwd
/opt/module/jdk1.8.0_181
打开/etc/profile文件,在profie文件末尾添加jdk路径
[root@hadoop101 jdk1.8.0_181]# vi /etc/profile
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
保存后退出 :wq
让修改后的文件生效
[root@hadoop101 jdk1.8.0_181]# source /etc/profile
测试jdk安装成功
[root@hadoop101 jdk1.8.0_181]# java -version
五、安装hadoop
解压 tar -zxvf /opt/software/hadoop-2.9.2.tar.gz -C /opt/module/
配置hadoop中的hadoop-env.sh
- 获取jdk的安装路径:
[root@hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_181
- 修改/opt/module/hadoop-2.9.2/etc/hadoop/hadoop-env.sh文件中JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_181
将hadoop添加到环境变量
- 获取hadoop安装路径:
[root@hadoop101 hadoop-2.9.2]# pwd
/opt/module/hadoop-2.9.2
- 打开/etc/profile文件,在profie文件末尾添加jdk路径:(shitf+g)【依次按G到最后一行,o光标下一行插入,vi 一般模式yy复制当前行,p粘贴】
root@ hadoop101 hadoop-2.9.2]# vi /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 保存后退出:
:wq
- 让修改后的文件生效:
root@ hadoop101 hadoop-2.9.2]# source /etc/profile
- 验证环境变量
root@ hadoop101 hadoop-2.9.2]# hadoop version
六、完全分布式运行模式搭建
跨服务器数据拷贝scp
将hadoop101中/opt/module文件拷贝到hadoop102、hadoop103上。
scp -r /opt/module/ root@hadoop102:/opt
scp -r /opt/module/ root@hadoop103:/opt
进入module文件夹修改hadoop102和hadoop103 /opt/module 下的用户组权限
sudo chown admin:admin /opt/module/ -R
SSH免密钥设置
Hadoop101
[admin@hadoop101 ~]# ssh-keygen -t rsa
[admin@hadoop101 ~]# ssh-copy-id hadoop101
[admin@hadoop101 ~]# ssh-copy-id hadoop102
[admin@hadoop101 ~]# ssh-copy-id hadoop103
Hadoop102
[admin@hadoop102 ~]# ssh-keygen -t rsa
[admin@hadoop102 ~]# ssh-copy-id hadoop102
[admin@hadoop102 ~]# ssh-copy-id hadoop101
[admin@hadoop102 ~]# ssh-copy-id hadoop103
Hadoop103
[admin@hadoop103 ~]# ssh-keygen -t rsa
[admin@hadoop103 ~]# ssh-copy-id hadoop103
[admin@hadoop103 ~]# ssh-copy-id hadoop101
[admin@hadoop103 ~]# ssh-copy-id hadoop102
集群分发脚本xsync
在/usr/local/bin目录下创建xsync文件
[admin@hadoop101 bin]$ sudo touch xsync
文件内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<104; host++)); do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
修改脚本 xsync 具有执行权限
[admin@hadoop101 bin]$ sudo chmod 777 xsync
xsync 调用脚本形式:xsync 文件名称
[admin@hadoop101 ~]$ xsync /usr/local/bin/xsync
fname=xsync
pdir=/usr/local/bin
--------------- hadoop102 ----------------
/usr/local/bin/xsync:行25: rsync: 未找到命令
--------------- hadoop103 ----------------
/usr/local/bin/xsync:行25: rsync: 未找到命令
发现未安装,将三台虚拟机分别安装
[admin@hadoop101 ~]$ sudo yum install rsync -y
[admin@hadoop102 ~]$ sudo yum install rsync -y
[admin@hadoop103 ~]$ sudo yum install rsync -y
安装完成后,执行该脚本
[root@hadoop101 ~]# xsync /usr/local/bin/xsync
fname=xsync
pdir=/usr/local/bin
--------------- hadoop102 ----------------
root@hadoop102''s password:
sending incremental file list
xsync
sent 638 bytes received 35 bytes 149.56 bytes/sec
total size is 549 speedup is 0.82
--------------- hadoop103 ----------------
root@hadoop103''s password:
sending incremental file list
xsync
sent 638 bytes received 35 bytes 192.29 bytes/sec
total size is 549 speedup is 0.82
完成后hadoop102和hadoop103就同步过来了xsync脚本文件
配置集群
集群部署规划

修改配置文件
[admin@hadoop101 ~]$ vi /opt/module/hadoop-2.9.2/etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.9.2/data/tmp</value>
</property>
HDFS
vi /opt/module/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
vi /opt/module/hadoop-2.9.2/etc/hadoop/ hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
</configuration>
slaves
vi /opt/module/hadoop-2.9.2/etc/hadoop/slaves
hadoop101
hadoop102
hadoop103
yarn
vi /opt/module/hadoop-2.9.2/etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
vi /opt/module/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
</configuration>
mapreduce
vi /opt/module/hadoop-2.9.2/etc/hadoop/mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
cp mapred-site.xml.template mapred-site.xml
vi /opt/module/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在集群上分发以上所有配置文件
xsync /opt/module/hadoop-2.9.2/etc/hadoop/
七、集群启动及测试
集群群起
- 如果集群是第一次启动,需要格式化namenode 【三台hadoop-2.9.2下将data和logs文件夹删除】
[admin@hadoop101 hadoop-2.9.2]$ bin/hdfs namenode -format
- 启动HDFS
[admin@hadoop101 hadoop-2.9.2]$ sbin/start-dfs.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-namenode-hadoop101.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-datanode-hadoop102.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-datanode-hadoop103.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-datanode-hadoop101.out
Starting secondary namenodes [hadoop103]
hadoop103: starting secondarynamenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-secondarynamenode-hadoop103.out
分别查看三台虚拟机进程
[admin@hadoop101 hadoop-2.9.2]$ jps
8146 NameNode
8483 Jps
8277 DataNode
[admin@hadoop102 hadoop-2.9.2]$ jps
7923 Jps
7807 DataNode
[admin@hadoop103 hadoop-2.9.2]$ jps
7411 DataNode
7512 SecondaryNameNode
7594 Jps
- 启动yarn (在ResouceManager所在的机器上启动yarn,即hadoop102上执行)
[admin@hadoop102 hadoop-2.9.2]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-resourcemanager-hadoop102.out
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-nodemanager-hadoop103.out
hadoop101: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-nodemanager-hadoop101.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-nodemanager-hadoop102.out
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
查看三台进程,与集群部署规划对比无误
[admin@hadoop101 ~]$ jps
8146 NameNode
8579 NodeManager
8277 DataNode
8699 Jps
[admin@hadoop102 hadoop-2.9.2]$ jps
7970 ResourceManager
8083 NodeManager
8378 Jps
7807 DataNode
[admin@hadoop103 hadoop-2.9.2]$ jps
7411 DataNode
7636 NodeManager
7512 SecondaryNameNode
7755 Jps
打开浏览器访问 http://hadoop101:50070/
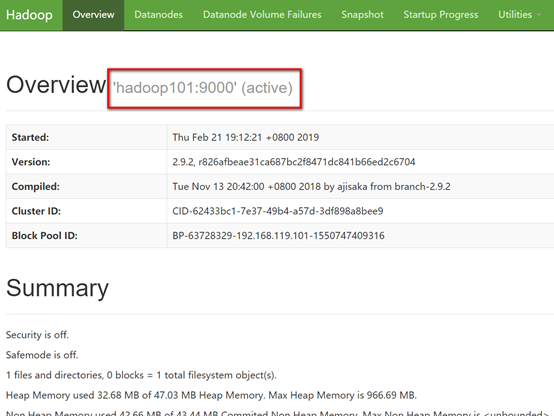
集群基本测试
查看根目录下
[admin@hadoop101 hadoop-2.9.2]$ hadoop fs -ls -R /
递归创建文件夹
[admin@hadoop101 hadoop-2.9.2]$ bin/hdfs dfs -mkdir -p /user/admin/temp/conf
查看
[admin@hadoop101 hadoop-2.9.2]$ hadoop fs -ls -R /
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin/temp
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin/temp/conf
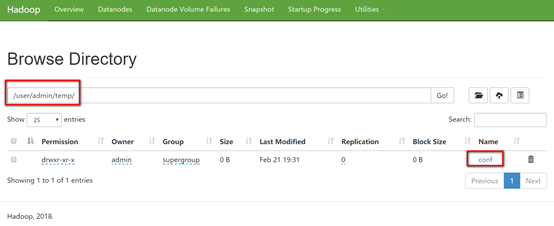
上传小文件,将hadoop满足*-site.xml的配置文件存放到刚创建的conf文件夹中
[admin@hadoop101 hadoop-2.9.2]$ bin/hdfs dfs -put etc/hadoop/*-site.xml /user/admin/temp/conf
查看
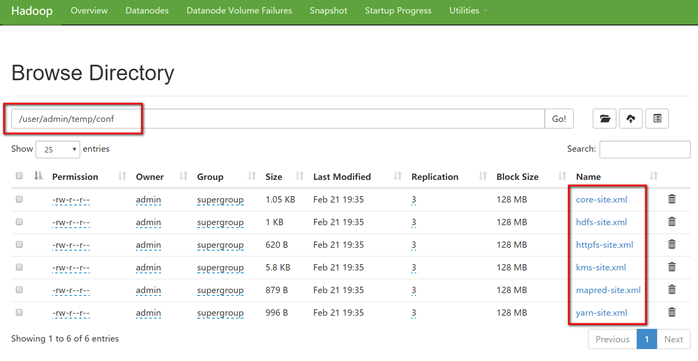
[admin@hadoop101 hadoop-2.9.2]$ hadoop fs -ls -R /
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin/temp
drwxr-xr-x - admin supergroup 0 2019-02-21 19:35 /user/admin/temp/conf
-rw-r--r-- 3 admin supergroup 1078 2019-02-21 19:35 /user/admin/temp/conf/core-site.xml
-rw-r--r-- 3 admin supergroup 1029 2019-02-21 19:35 /user/admin/temp/conf/hdfs-site.xml
-rw-r--r-- 3 admin supergroup 620 2019-02-21 19:35 /user/admin/temp/conf/httpfs-site.xml
-rw-r--r-- 3 admin supergroup 5939 2019-02-21 19:35 /user/admin/temp/conf/kms-site.xml
-rw-r--r-- 3 admin supergroup 879 2019-02-21 19:35 /user/admin/temp/conf/mapred-site.xml
-rw-r--r-- 3 admin supergroup 996 2019-02-21 19:35 /user/admin/temp/conf/yarn-site.xml
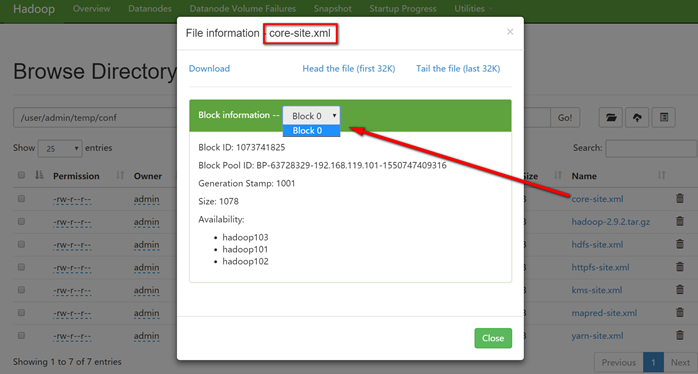
上传大文件
[admin@hadoop101 hadoop-2.9.2]$ bin/hadoop fs -put /opt/software/hadoop-2.9.2.tar.gz /user/admin/temp/conf
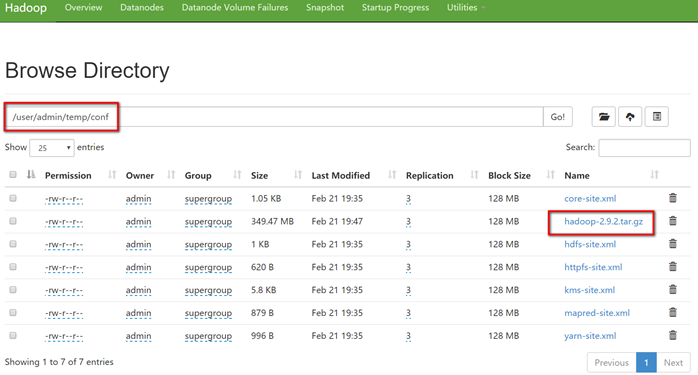
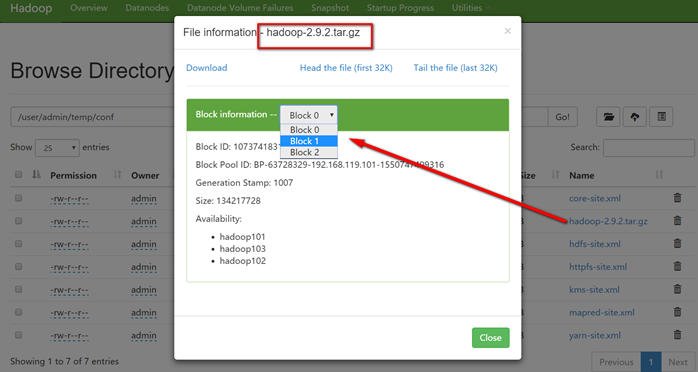
上传文件后查看文件存放在什么位置
文件存储路径
[admin@hadoop101 subdir0]$ pwd
/opt/module/hadoop-2.9.2/data/tmp/dfs/data/current/BP-63728329-192.168.119.101-1550747409316/current/finalized/subdir0/subdir0
[admin@hadoop101 subdir0]$
[admin@hadoop101 subdir0]$ ll
总用量 360716
-rw-rw-r-- 1 admin admin 1078 2月 21 19:35 blk_1073741825
-rw-rw-r-- 1 admin admin 19 2月 21 19:35 blk_1073741825_1001.meta
-rw-rw-r-- 1 admin admin 1029 2月 21 19:35 blk_1073741826
-rw-rw-r-- 1 admin admin 19 2月 21 19:35 blk_1073741826_1002.meta
-rw-rw-r-- 1 admin admin 620 2月 21 19:35 blk_1073741827
-rw-rw-r-- 1 admin admin 15 2月 21 19:35 blk_1073741827_1003.meta
-rw-rw-r-- 1 admin admin 5939 2月 21 19:35 blk_1073741828
-rw-rw-r-- 1 admin admin 55 2月 21 19:35 blk_1073741828_1004.meta
-rw-rw-r-- 1 admin admin 879 2月 21 19:35 blk_1073741829
-rw-rw-r-- 1 admin admin 15 2月 21 19:35 blk_1073741829_1005.meta
-rw-rw-r-- 1 admin admin 996 2月 21 19:35 blk_1073741830
-rw-rw-r-- 1 admin admin 15 2月 21 19:35 blk_1073741830_1006.meta
-rw-rw-r-- 1 admin admin 134217728 2月 21 19:47 blk_1073741831
-rw-rw-r-- 1 admin admin 1048583 2月 21 19:47 blk_1073741831_1007.meta
-rw-rw-r-- 1 admin admin 134217728 2月 21 19:47 blk_1073741832
-rw-rw-r-- 1 admin admin 1048583 2月 21 19:47 blk_1073741832_1008.meta
-rw-rw-r-- 1 admin admin 98011993 2月 21 19:47 blk_1073741833
-rw-rw-r-- 1 admin admin 765727 2月 21 19:47 blk_1073741833_1009.meta
八、Hadoop启动停止方式
- 各个服务组件逐一启动
1)分别启动hdfs组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
2)启动yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
- 各个模块分开启动(配置ssh是前提)常用 1)整体启动/停止hdfs
start-dfs.sh
stop-dfs.sh
2)整体启动/停止yarn
start-yarn.sh
stop-yarn.sh
- 全部启动(不建议使用)
start-all.sh
stop-all.sh
九、集群时间同步
时间同步的方式:找一台机器作为时间服务器,所有的机器与这台集群时间进行定时的同步。
时间服务器配置
- 检查ntp是否安装(因为CentOS选用的是Minimal版本,所以并没有安装)
[root@hadoop101 /]# rpm -qa|grep ntp
- 安装ntp
[root@hadoop101 /]# yum install ntp
再次检查发现安装成功
[root@hadoop101 /]# rpm -qa|grep ntp
ntpdate-4.2.6p5-28.el7.centos.x86_64
ntp-4.2.6p5-28.el7.centos.x86_64
- 修改ntp配置文件
[root@hadoop101 /]# vi /etc/ntp.conf

①:授权192.168.119.0-255.255.255.0网段上的所有机器可以从这台机器上查询和同步时间
②:集群在局域网中,不是用其他互联网上的时间(注掉)
③:当该节点网络连接丢失,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
- 修改/etc/sysconfig/ntpd 文件
[root@hadoop101 /]# vi /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
- 重启ntpd
[root@hadoop101 /]# service ntpd start
- 设置ntpd开机启动
chkconfig ntpd on
其他机器配置(必须root用户)
- 安装ntp
[root@hadoop102 sbin]# yum install ntp
- 在其他机器配置10分钟与时间服务器同步一次
[root@hadoop102 admin]# crontab -e
*/10 * * * * /usr/sbin/ntpdate hadoop101
- 修改任意机器时间
date -s "2019-10-10"
- 十分钟后查看机器是否与时间服务器同步
date
十、结尾
搭建过程还算顺利,期间参考了许多优秀博主的博客,受益良多,以下是涉及到的博客及地址,在此一一致谢!
Linux之CentOS7.5安装及克隆 https://www.cnblogs.com/frankdeng/p/9027037.html
Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群 http://www.cnblogs.com/frankdeng/p/9047698.html
Vmware虚拟机网络配置(固定IP) https://www.jianshu.com/p/6fdbba039d79
centos修改主机名的正确方法 https://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_043_hostname.html

CentOS 7下Hadoop3.1伪分布式环境搭建
本教程JDK版本为1.8.0 Hadoop版本为3.1.1
相关资源:https://pan.baidu.com/s/1EhkiCXidke-iN6kU3yuMJQ 提取码:p0bl
1.安装虚拟机
可自行选择VMware或者VirtualBox进行虚拟机安装
此教程基于VMware
2.安装操作系统
可从CentOS 官网自行选择版本进行安装
此教程基于CentOS 7 X86_64-Minimal-1804
3.检查是否安装ssh (CentOS 7 即使是最小化安装也已附带openssh 可跳过本步骤)
rpm -qa | grep ssh若已安装进行下一步骤 若未安装 请自行百度 本教程不做过多讲解
4.配置ssh,实现无密码登录
1.开启sshd服务
systemctl start sshd.service2.进入 ~/.ssh 文件夹
cd ~/.ssh若不存在该文件夹 可使用以下命令 使用root账户登录后生成
ssh root@localhost然后输入yes 并输入本机root密码
3.进入 .ssh目录后 执行
ssh-keygen -t rsa一路按回车就可以
4.做ssh免密认证 执行以下命令即可
cat id_rsa.pub >> authorized_keys5.修改文件权限
chmod 644 authorized_keys6.检测是否可以免密登录
ssh root@localhost无需输入密码登录 即为成功
5.上传jdk,并配置环境变量
通过xftp 或者 winSCP等工具 将文件上传至CentOS7 的 /usr/local/java 文件夹中
进入文件夹并进行解压缩
cd /usr/local/java
tar -zxvf jdk-8u191-linux-x64.tar.gz设置环境变量
vim ~/.bashrc
在最下方添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH使用以下命令使配置生效
source ~/.bashrc6.上传Hadoop,并配置环境变量
1.系统环境变量
通过xftp 或者 winSCP等工具 将文件上传至CentOS7 的 /usr/local/java 文件夹中
进入文件夹并进行解压缩
cd /usr/local/hadoop
tar -zxvf hadoop-3.1.1.tar.gz设置环境变量
vim ~/.bashrc在最下方添加
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin使用以下命令使配置生效
source ~/.bashrc2.准备工作
创建存放数据的目录
mkdir /usr/local/hadoop/tmp创建namenode 存放 name table 的目录
mkdir /usr/local/hadoop/tmp/dfs/name创建 datanode 存放 数据 block 的目录
mkdir /usr/local/hadoop/tmp/dfs/data3.修改/usr/local/hadoop/hadoop-3.1.1/etc/hadoop文件夹下的core-site.xml配置文件
默认情况下,Hadoop将数据保存在/tmp下,当重启系统时,/tmp中的内容将被自动清空,所以我们需要制定自己的一个Hadoop的目录,用来存放数据。另外需要配置Hadoop所使用的默认文件系统,以及Namenode进程所在的主机
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- 指定hadoop运行时产生文件的存储路径-->
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<!--hdfs namenode的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>4.修改/usr/local/hadoop/hadoop-3.1.1/etc/hadoop文件夹下的hdfs-site.xml配置文件
该文件指定与HDFS相关的配置信息。需要修改HDFS默认的块的副本属性,因为HDFS默认情况下每个数据块保存3个副本,而在伪分布式模式下运行时,由于只有一个数据节点,所以需要将副本个数改为1,否则Hadoop程序会报错
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!--指定HDFS储存数据的副本数目,默认情况下为3份-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!--name node 存放 name table 的目录-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<!--data node 存放数据 block 的目录-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<!--设置监控页面的端口及地址-->
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>5.修改/usr/local/hadoop/hadoop-3.1.1/etc/hadoop文件夹下的mapred-site.xml配置文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- 指定mapreduce 编程模型运行在yarn上 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6.修改/usr/local/hadoop/hadoop-3.1.1/etc/hadoop文件夹下的yarn-site.xml配置文件
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!-- 指定mapreduce 编程模型运行在yarn上 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>7.格式化namenode,只格式化一次即可
hadoop namenode -format8.启动hadoop
start-all.sh9.查看进程,检查是否启动
jps若显示五个进程 : namenode、secondarynamenode、datanode、resourcemanager、nodemanager 则启动成功
7.排除错误
1. 初始化时的问题
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable解决方案(共两种方式)
1.在~/.bashrc 中加入如下配置
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"使上面的配置生效
source ~/.bashrc2.修改core-site.xml文件,添加
<property>
<name>hadoop.native.lib</name>
<value>false</value>
</property>2.启动时的错误
错误 1
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [localhost.localdomain]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
解决方案
因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
/usr/local/hadoop/hadoop-3.1.1/sbin 下的 start-dfs.sh 和 stop-dfs.sh
在最上方 #/usr/bin/env bash 下空白处添加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root错误 2
Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
Starting nodemanagers
ERROR: Attempting to launch yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch. 解决方案
因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
/usr/local/hadoop/hadoop-3.1.1/sbin 下的 start-yarn.sh 和 stop-yarn.sh
在最上方 #/usr/bin/env bash 下空白处添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root错误 3
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.解决方案
在/usr/local/hadoop/hadoop-3.1.1/sbin 下的 start-dfs.sh 和 stop-dfs.sh 中将
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root改为
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root8.至此已经成功安装完成Hadoop
HDFS Web界面:http://192.168.0.3:50070
ResourceManager Web界面:http://192.168.0.3:8088
今天关于和单机CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境的讲解已经结束,谢谢您的阅读,如果想了解更多关于64位CentOS系统下安装配置伪分布式hadoop 2.5.2、centos 64位 hadoop 完全分布式安装、CentOS 7.6搭建Hadoop2.9.2完全分布式集群,狠详细!、CentOS 7下Hadoop3.1伪分布式环境搭建的相关知识,请在本站搜索。
本文标签:




