关于眼见macOS运行iOSApp,微软希望Windows10原生支持AndroidApp和macos运行windows软件的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于angular–
关于眼见 macOS 运行 iOS App,微软希望 Windows 10 原生支持 Android App和macos运行windows软件的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于angular – ng new hello错误:路径“/app/app.module.ts”不存在.路径“/app/app.module.ts”不存在、Apache Hadoop 3.1.0 发布,原生支持 GPU 和 FPGA、Apache Spark 2.3 原生支持 Kubernetes、Build 2023 亮点:Windows 原生支持 rar 格式、发布 Windows Copilot等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- 眼见 macOS 运行 iOS App,微软希望 Windows 10 原生支持 Android App(macos运行windows软件)
- angular – ng new hello错误:路径“/app/app.module.ts”不存在.路径“/app/app.module.ts”不存在
- Apache Hadoop 3.1.0 发布,原生支持 GPU 和 FPGA
- Apache Spark 2.3 原生支持 Kubernetes
- Build 2023 亮点:Windows 原生支持 rar 格式、发布 Windows Copilot
")
眼见 macOS 运行 iOS App,微软希望 Windows 10 原生支持 Android App(macos运行windows软件)
根据外国科技媒体 Windows Central 的报道,微软正在将 Android 应用引入 Windows 10 的 Microsoft Store,具体的上线时间尚未确定,Windows Central 表示可能是 2021 年。
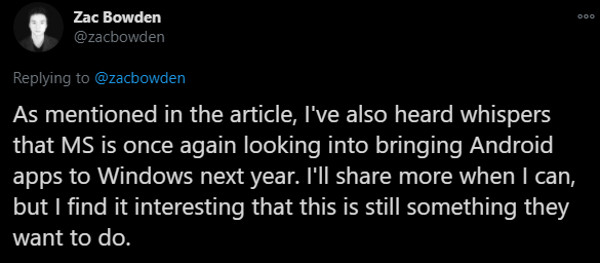
来自:Twitter/Zac Bowden
微软希望 Windows 系统跑 Android 应用的愿景最早可以追溯到 2014 年,当时微软启动了 Android 应用移植项目 "Project Astoria" 和 iOS 应用移植项目 "Project Islandwood" 进行探索,旨在为开发者提供将 Android 和 iOS 应用移植到 Windows 平台 (Windows Phone) 的简便方法。
到 2015 年,微软正式放弃了应用移植项目,原因有两个,一是 Windows 开发者对微软的方案不满意;二是项目会引入 “Android 子系统 (Android subsystem)”,并导致 Windows 10 Mobile 的运行速度变慢。
事实上,Windows 10 "Your Phone" 应用的最近更新已支持通过流式传输在 Windows 10 上运行 Android。
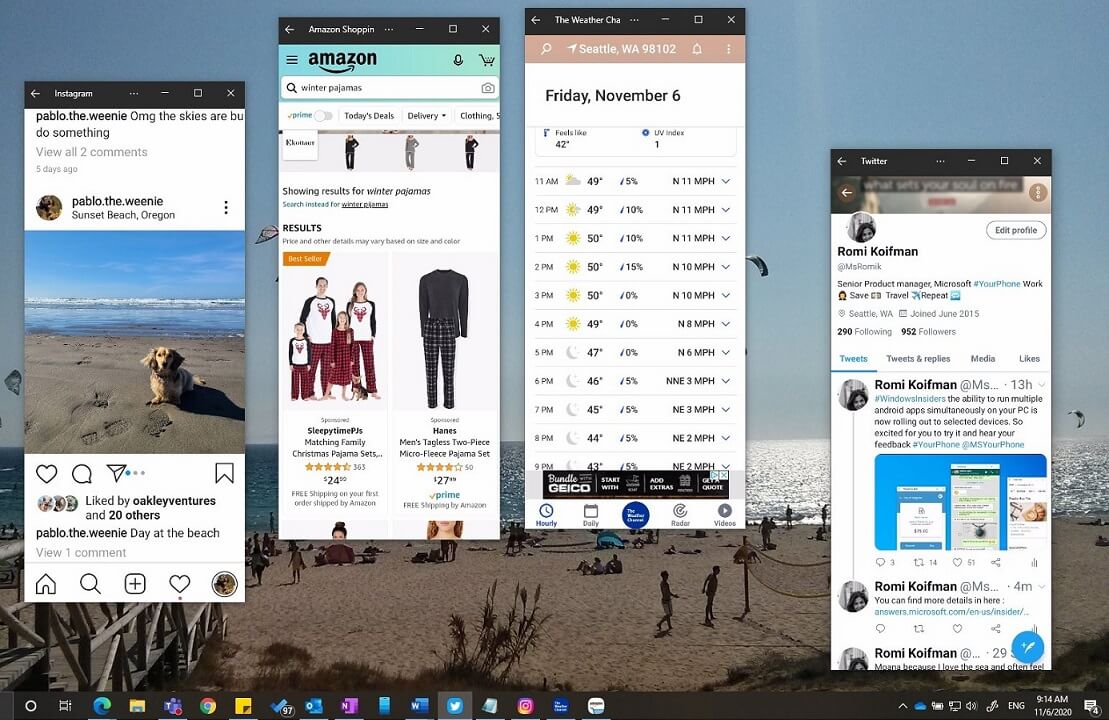
不过从 Windows Central 透露的信息来看,这显然不是 “原生” 支持 Android 应用的方案,更大的可能是像文章一开始所说,允许用户通过 Microsoft Store 获取可原生运行的 Android 应用。
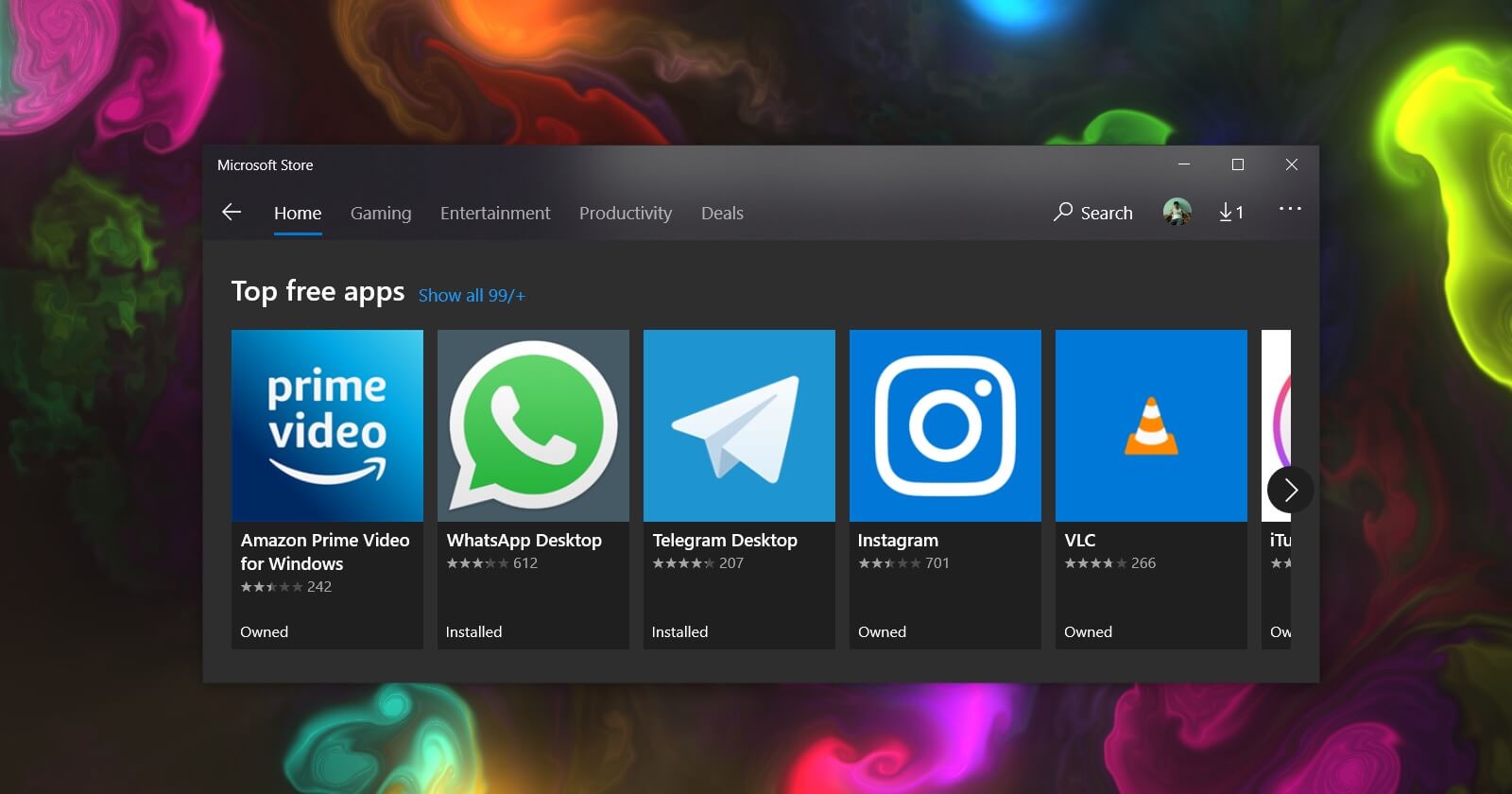
目前没有确切的消息介绍微软如何实现在 Windows 10 运行 Android 应用的计划,以及它是否支持 Windows on Arm。但考虑到绝大多数 Android 应用都是基于 Arm 设备而构建,因此后者无疑更具意义。
延伸阅读
- 微软正在为 Windows 10 开发 Android 子系统

angular – ng new hello错误:路径“/app/app.module.ts”不存在.路径“/app/app.module.ts”不存在
当我运行新的myapp命令时,我得到以下命令
新的你好
Error: Path "/app/app.module.ts" does not exist. Path "/app/app.module.ts" does not exist.
谁能帮我吗???
解决方法
Please make sure that your new folder have write permission
如果您使用的是ubuntu,请将以下命令运行到该文件夹
sudo chmod 644 -R foldername
然后运行新的appname
并检查您的节点版本

Apache Hadoop 3.1.0 发布,原生支持 GPU 和 FPGA
Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。
这个版本的 Hadoop 带来了许多重大的变化,如下:
YARN 原生支持 GPU(详见 YARN-6223)
YARN 原生支持 FPGA(详见 YARN-5983)
支持原生的 YARN 服务(详见 YARN-5079 / YARN-4793 / YARN-4757 / YARN-6419)
YARN 新的调度放置策略
支持 docker container
容量调度(Capacity Scheduler):支持在执行队列映射时自动创建叶队列(详见 YARN-7117)
允许将存储在 HDFS 之外的数据映射到 HDFS 并从 HDFS 进行寻址。
更多的详情请参见官方 Release Notes

Apache Spark 2.3 原生支持 Kubernetes
Apache Spark 2.3 原生支持 Kubernetes
This is a community blog from Anirudh Ramanathan and Palak Bhatia, software engineer and product manager respectively at Google, working in the Kubernetes team. They are part of the group of companies that contributed to native Kubernetes support for the Apache Spark 2.3. This post is cross-posted on blog.kubernetes.io
Kubernetes and Big Data
The open source community has been working over the past year to enable first-class support for data processing, data analytics and machine learning workloads in Kubernetes. New extensibility features in Kubernetes, such as custom resources and custom controllers, can be used to create deep integrations with individual applications and frameworks.
Traditionally, data processing workloads have been run in dedicated setups like the YARN/Hadoop stack. However, unifying the control plane for all workloads on Kubernetes simplifies cluster management and can improve resource utilization.
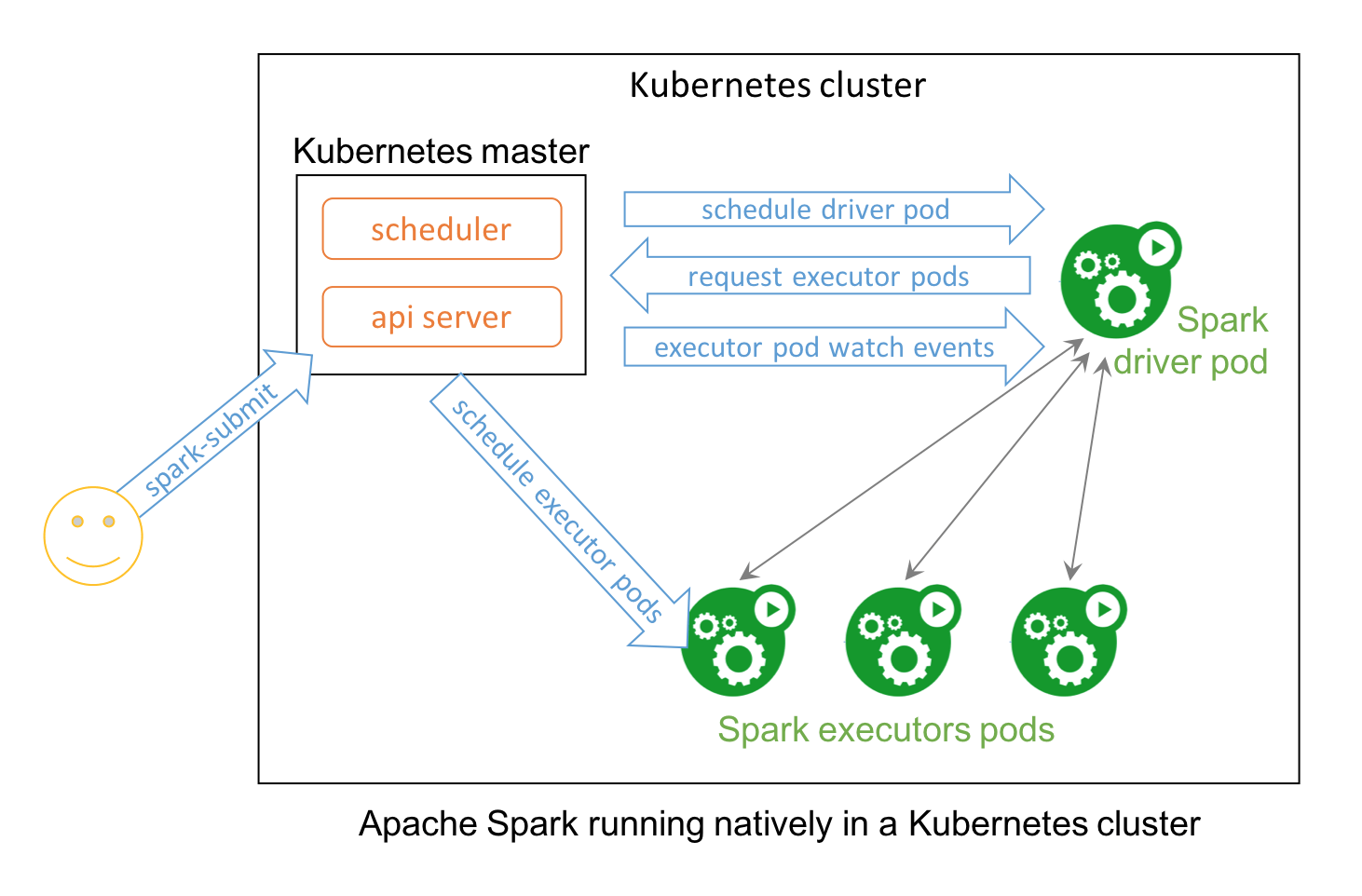
Apache Spark 2.3 with native Kubernetes support combines the best of the two prominent open source projects — Apache Spark, a framework for large-scale data processing; and Kubernetes.
Apache Spark is an essential tool for data scientists, offering a robust platform for a variety of applications ranging from large scale data transformation to analytics to machine learning. Data scientists are adopting containers en masse to improve their workflows by realizing benefits such as packaging of dependencies and creating reproducible artifacts. Given that Kubernetes is the de facto standard for managing containerized environments, it is a natural fit to have support for Kubernetes APIs within Spark.
Starting with Spark 2.3, users can run Spark workloads in an existing Kubernetes 1.7+ cluster and take advantage of Apache Spark’s ability to manage distributed data processing tasks. Apache Spark workloads can make direct use of Kubernetes clusters for multi-tenancy and sharing through Namespaces and Quotas, as well as administrative features such as Pluggable Authorization and Logging. Best of all, it requires no changes or new installations on your Kubernetes cluster; simply create a container image and set up the right RBAC rolesfor your Spark Application and you’re all set.
Concretely, a native Spark Application in Kubernetes acts as a custom controller, which creates Kubernetes resources in response to requests made by the Spark scheduler. In contrast with deploying Apache Spark in Standalone Mode in Kubernetes, the native approach offers fine-grained management of Spark Applications, improved elasticity, and seamless integration with logging and monitoring solutions. The community is also exploring advanced use cases such as managing streaming workloads and leveraging service meshes like Istio.
To try this yourself on a Kubernetes cluster, simply download the binaries for the official Apache Spark 2.3 release. For example, below, we describe running a simple Spark application to compute the mathematical constant Pi across three Spark executors, each running in a separate pod. Please note that this requires a cluster running Kubernetes 1.7 or above, a kubectl client that is configured to access it, the necessary RBAC rules for the default namespace and service account.
$ kubectl cluster-info
Kubernetes master is running at https://xx.yy.zz.ww
$ bin/spark-submit \
--master k8s://https://xx.yy.zz.ww \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
--conf spark.kubernetes.driver.pod.name=spark-pi-driver \
local:///opt/spark/examples/jars/spark-examples_2.11-2.3.0.jar
To watch Spark resources that are created on the cluster, you can use the following kubectl command in a separate terminal window.
$ kubectl get pods -l ''spark-role in (driver, executor)'' -w
NAME READY STATUS RESTARTS AGE
spark-pi-driver 1/1 Running 0 14s
spark-pi-da1968a859653d6bab93f8e6503935f2-exec-1 0/1 Pending 0 0s
...
The results can be streamed during job execution by running:
$ kubectl logs -f spark-pi-driver
When the application completes, you should see the computed value of Pi in the driver logs.
In Spark 2.3, we’re starting with support for Spark applications written in Java and Scala with support for resource localization from a variety of data sources including HTTP, GCS, HDFS, and more. We have also paid close attention to failure and recovery semantics for Spark executors to provide a strong foundation to build upon in the future. Get started with the open-source documentation today.
Get Involved
There’s lots of exciting work to be done in the near future. We’re actively working on features such as dynamic resource allocation, in-cluster staging of dependencies, support for PySpark & SparkR, support for Kerberized HDFS clusters, as well as client-mode and popular notebooks’ interactive execution environments. For people who fell in love with the Kubernetes way of managing applications declaratively, we’ve also been working on a Kubernetes Operator for spark-submit, which allows users to declaratively specify and submit Spark Applications.
And we’re just getting started! We would love for you to get involved and help us evolve the project further.
- Join the spark-dev and spark-user mailing lists.
- File an issue in Apache Spark JIRA under the Kubernetes component.
- Join our SIG meetings on Wednesdays at 10am PT.
Huge thanks to the Apache Spark and Kubernetes contributors spread across multiple organizations (Google, Databricks, Red Hat, Palantir, Bloomberg, Cloudera, PepperData, Datalayer, HyperPilot and others) who spent many hundreds of hours working on this effort. We look forward to seeing more of you contribute to the project and help it evolve further.

Build 2023 亮点:Windows 原生支持 rar 格式、发布 Windows Copilot
今天凌晨,微软 Build 2023 开发者大会正式开幕,这是 2019 年以来首次回归线下举办,主题十分突出,基本是围绕“AI”展开。本文对部分值得开发者关注的亮点进行汇总。

微软推出 Windows Copilot
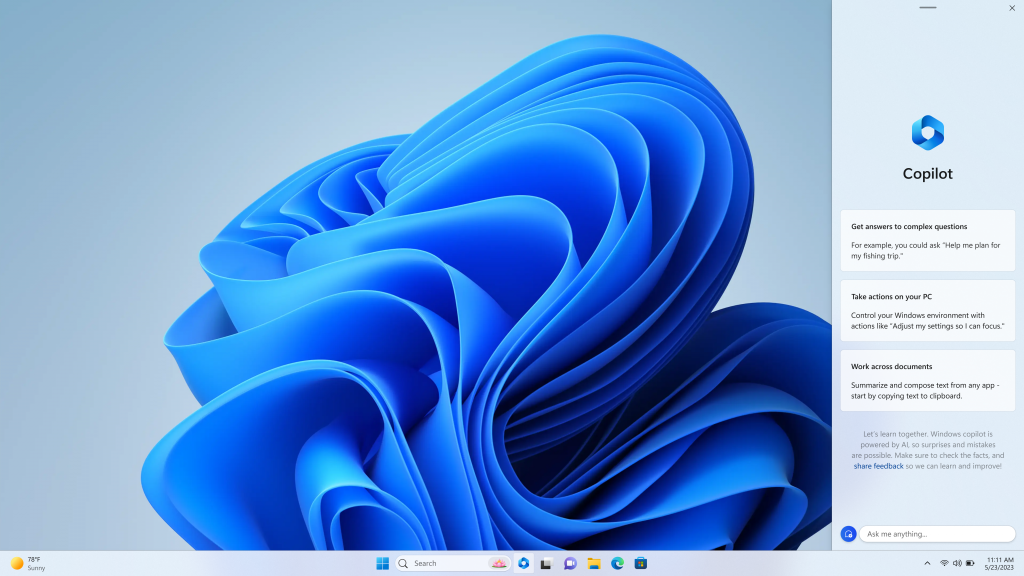
微软宣布在 Windows 11 中加入名为 Windows Copilot 的 AI 助手。这是一个集成在操作系统中的侧边栏工具,可以帮助用户完成各种任务,如内容摘要、重写、解释等。微软表示,Copilot 可以让每个用户都成为高效能者,提升工作和学习效率。
Copilot 并不会完全的取代目前 Windows 11 上的搜索功能,而是相对独立的存在,它有一个独立的按钮,用户点击后就能获得相应的 AI 能力。
Windows Copilot 预计将于今年 6 月份开始在 Windows 11 预览版中提供。
必应 (Bing) 成为 ChatGPT 内置搜索引擎
微软宣布 ChatGPT 将使用 Bing 作为其内置搜索数据提供商、与 OpenAI 共建统一 AI 插件平台,以及扩展 Bing 聊天机器人在微软 Copilots 产品线上的广泛应用。
Bing 搜索功能已经开始面向 ChatGPT Plus 用户滚动推出,很快将以 ChatGPT 插件形式为所有免费用户提供。
Windows 11 原生支持解压 RAR 和 7Z
微软宣布,Windows 11 增加了对额外压缩格式的原生支持,包括 tar,7-zip,rar,gz 等,增加这一支持是因为 Windows 11 现在使用了 libarchive 开源项目。

libarchive 是一个开源的 C 库,旨在为各种不同的压缩格式提供读取和写入支持。它支持许多常见的压缩格式,并提供了许多高级功能,例如加密、数字签名、多卷支持等。libarchive 的主要优点是它的跨平台支持,它可以在各种操作系统上运行,包括 Linux、Windows、macOS 等。它还提供了多种语言的绑定,如 Python、Ruby、Perl 等,使得开发人员可以方便地在自己喜欢的编程语言中使用它。
也正是因为使用了 libarchive 提供的开源解决方案,Windows 11 还将支持 tar、gz 等许多其他格式。
请注意,虽然 Windows 11 原生支持上述这些格式的解压缩,但暂时还无法使用 RAR 格式来压缩文件。
微软推出 Dev Home —— 面向开发者的开源生产力工具
微软发布了一款开源的开发者工具:Dev Home,称可帮助开发者在 Windows 11 上释放生产力。
据介绍,Dev Home 是一个控制中心,能够在一个位置跟踪所有工作流和编码任务。它具有简化的设置工具,方便开发者在集中位置安装应用程序和包,将开发环境部署自动化,扩展允许连接到开发者帐户(例如 GitHub),以及带有各种以开发者为中心的小部件的可自定义仪表板,为开发者提供触手可及的信息。
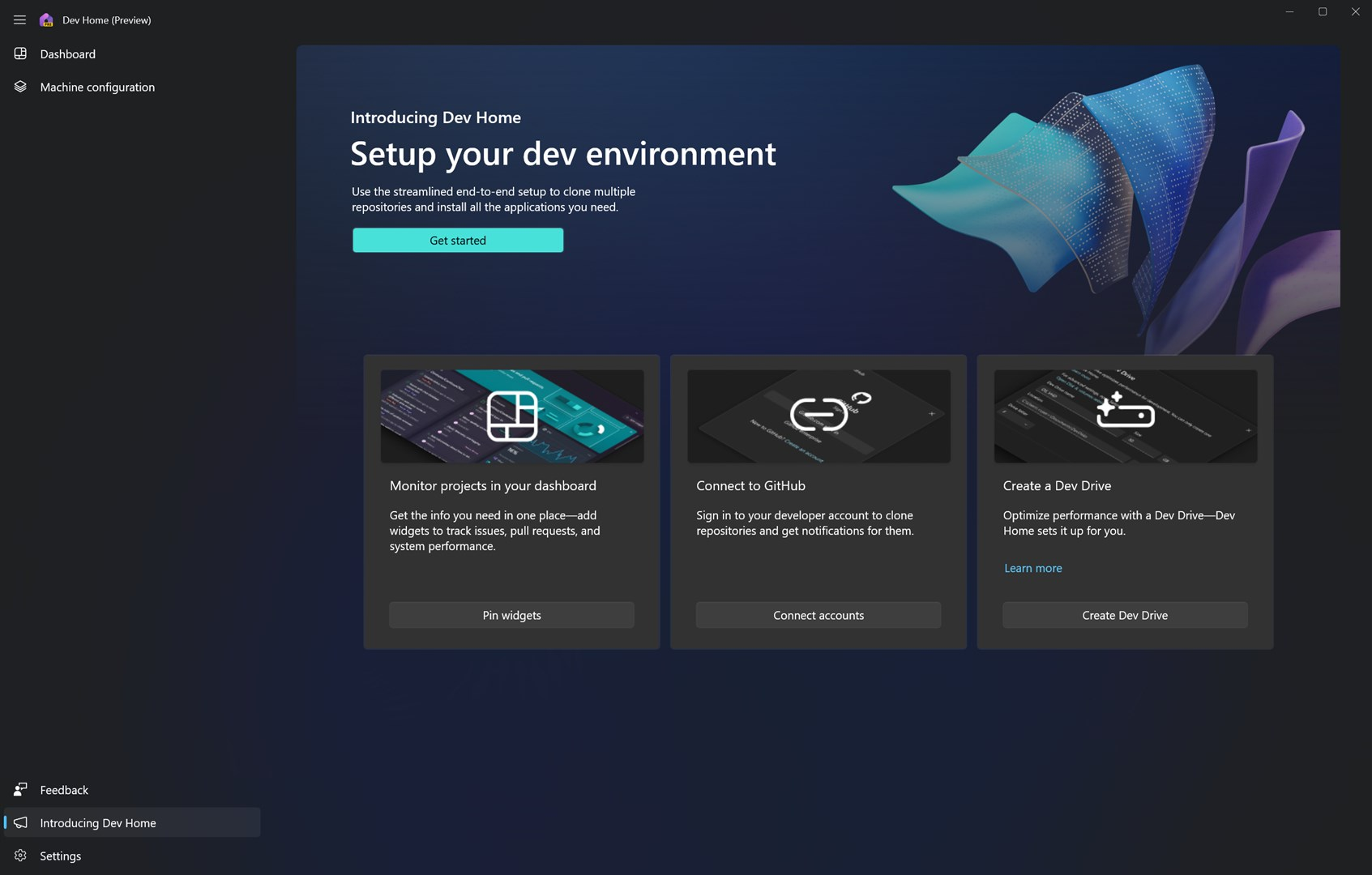
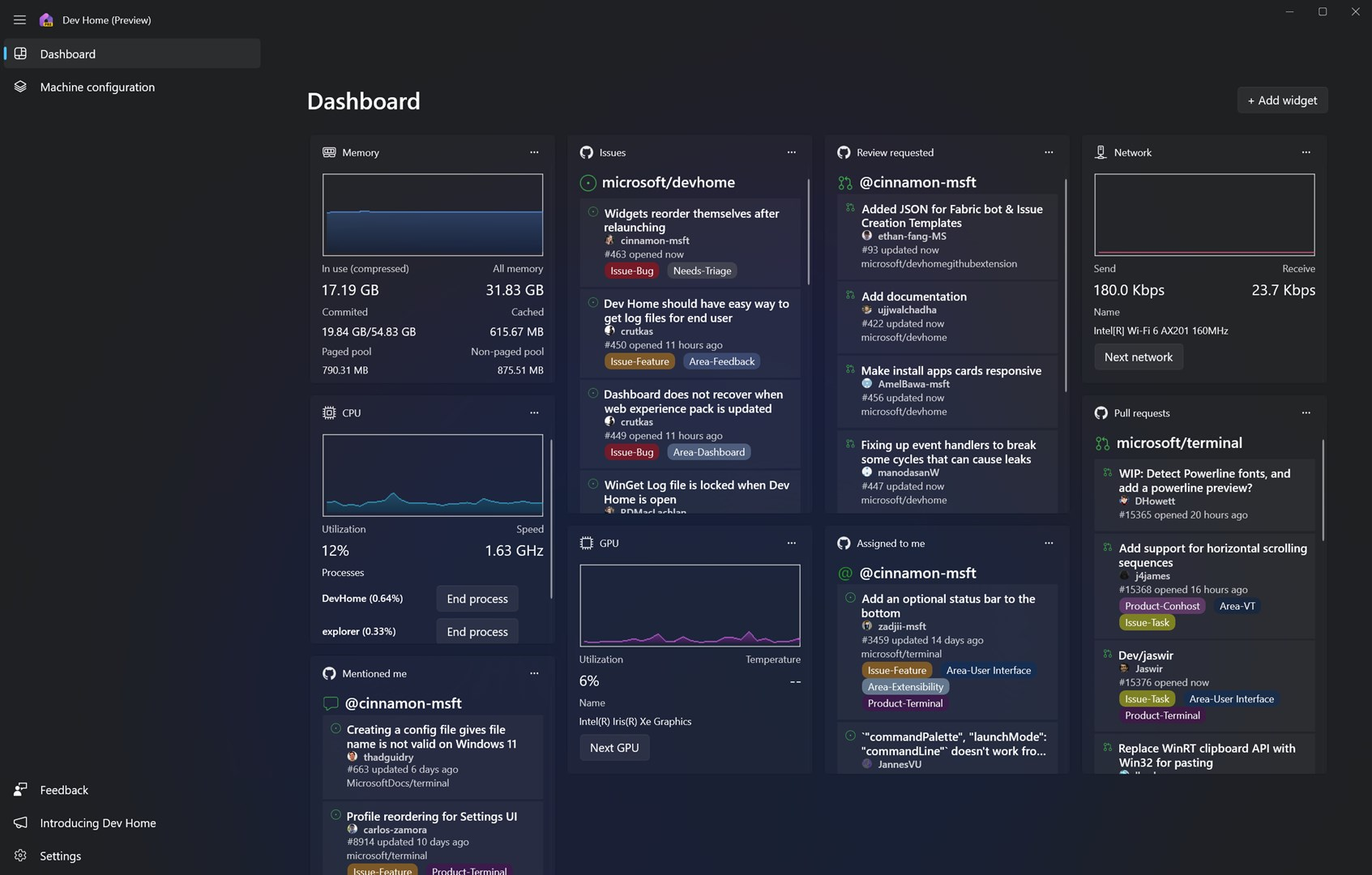
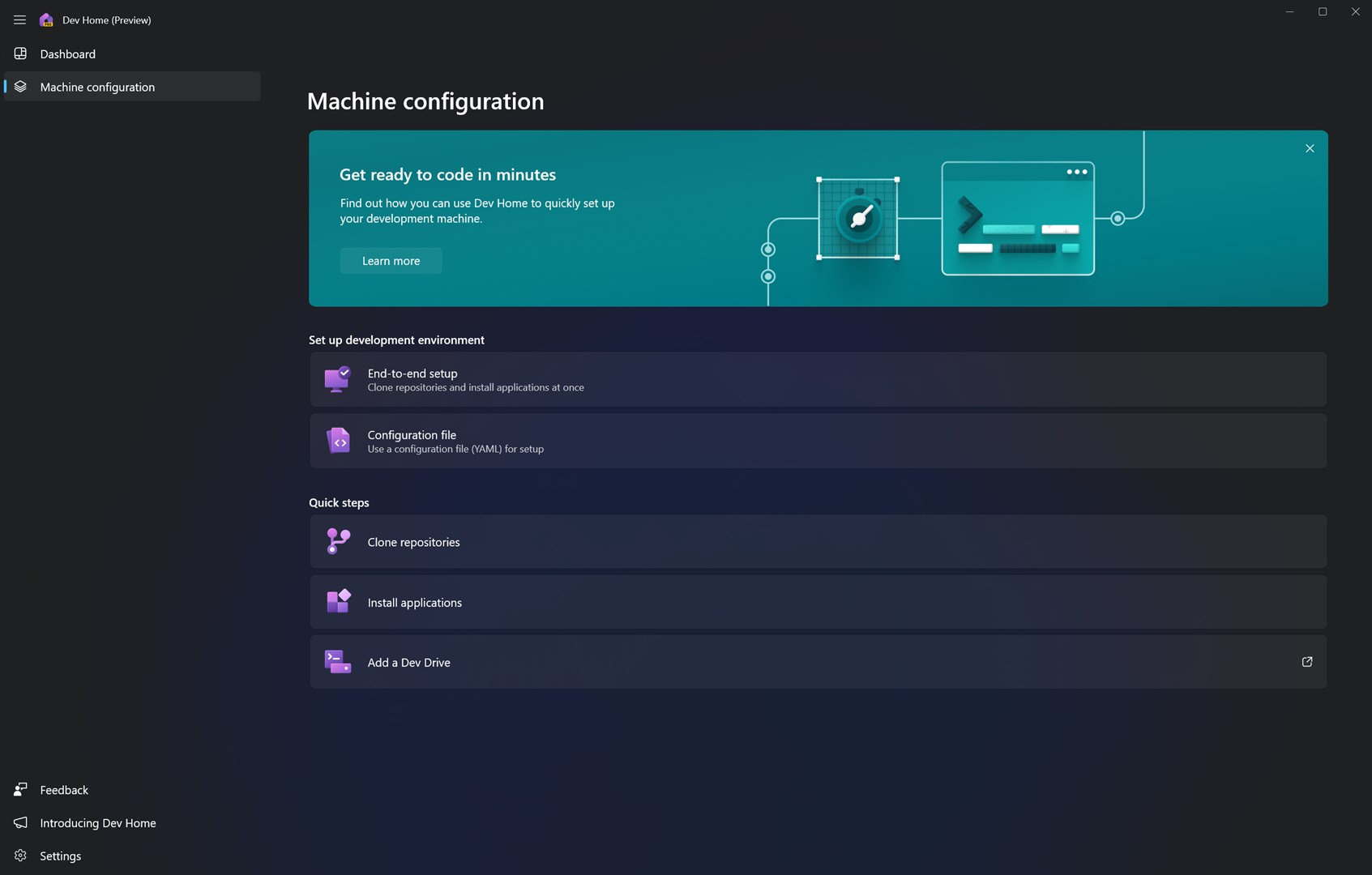
目前 Dev Home 已提供预览版,下载地址:Dev Home。
Windows Terminal 集成 GitHub Copilot X
Windows 11 默认终端 Windows Terminal 将集成 GitHub Copilot X。
GitHub Copilot X 是 Copilot 的升级版,作为一款 “GPT-4 加持” 的 AI 编程助手,微软表示,它利用自然语言人工智能的优势,能够以内联和对话式聊天的方式在终端应用程序中推荐命令、解释错误,并帮助用户进行后续操作。
微软还表示目前尝试在其他开发者工具(如 WinDBG)中集成 GitHub Copilot AI 技术,帮助开发者高效完成任务。开发人员通常使用 WinDbg 来调试用户模式应用程序、设备驱动程序,甚至 Windows 本身。它是 IT 管理员通过分析 Windows 生成的内存转储来解决蓝屏死机 (BSOD) 错误的流行工具。
对了,Windows Terminal 已支持对选项卡进行拖拽使其成为独立窗口:
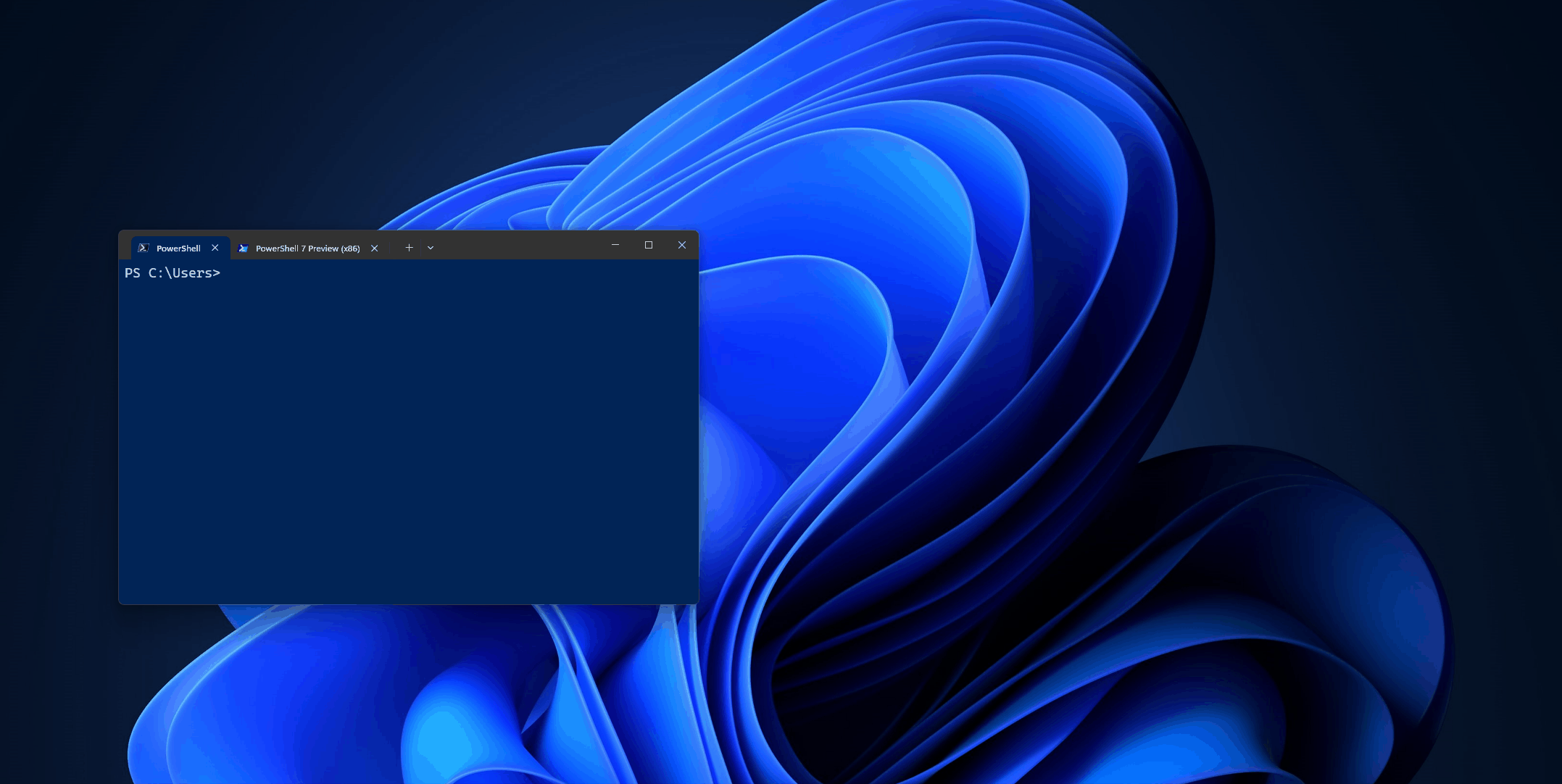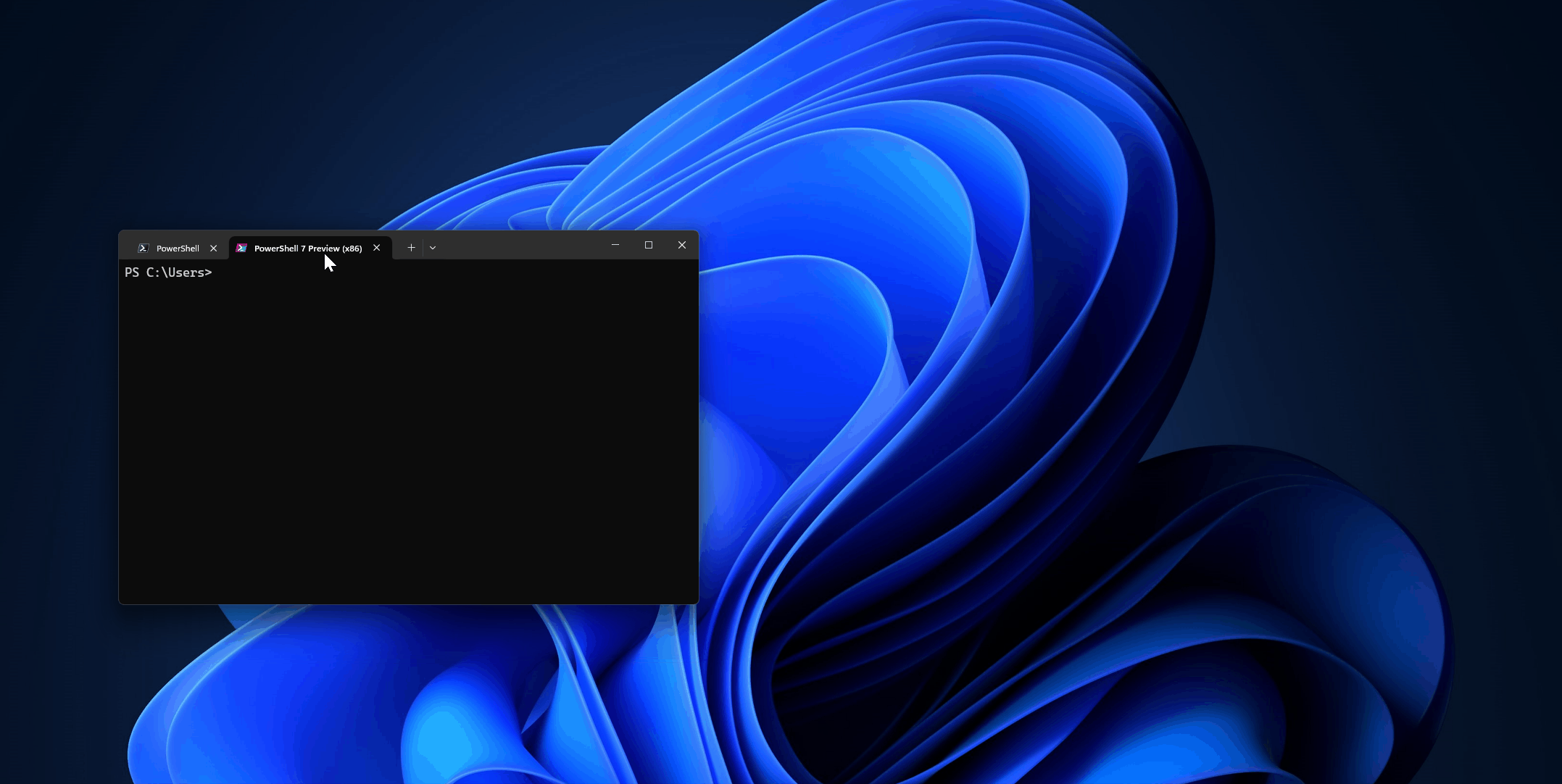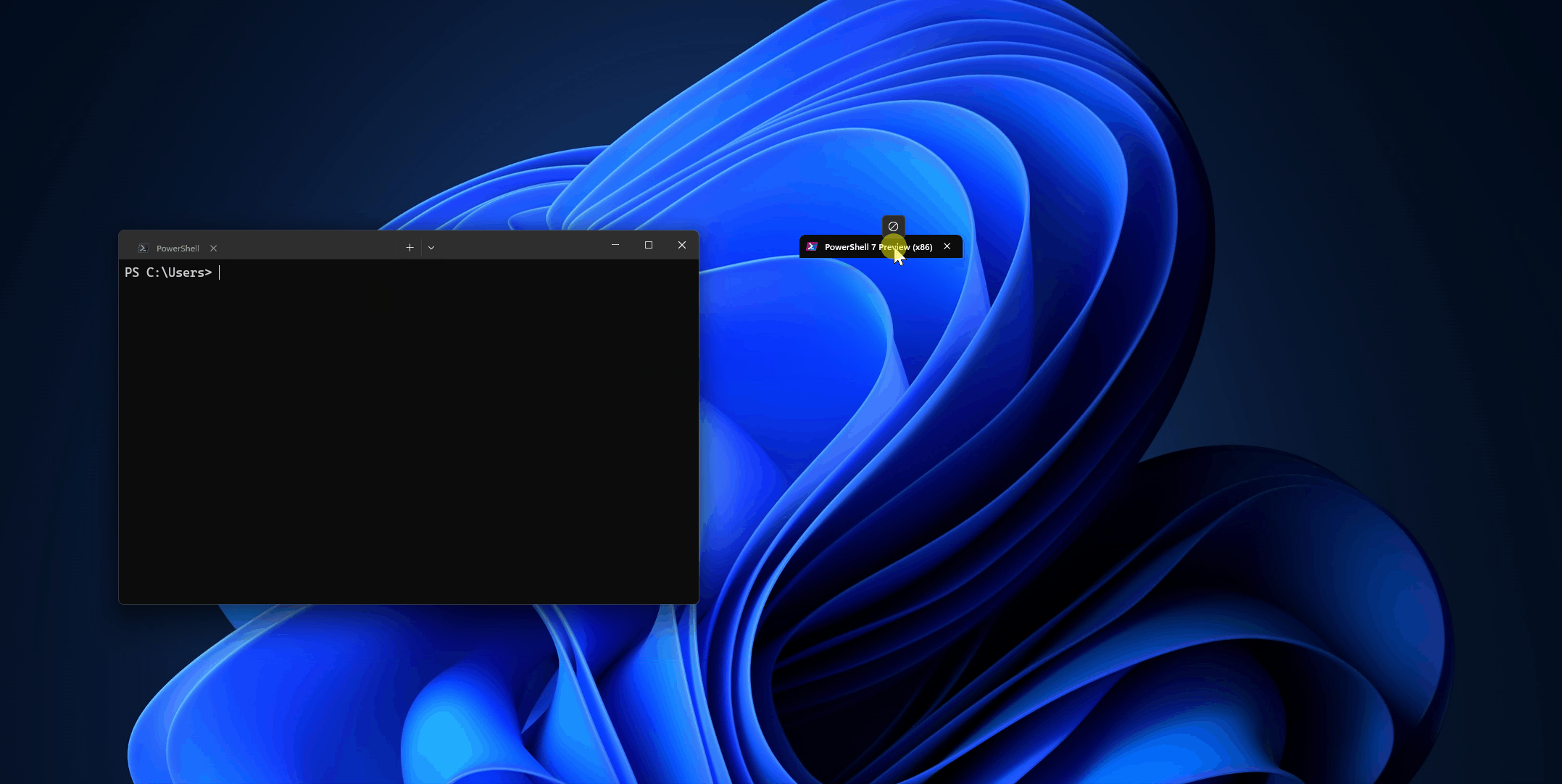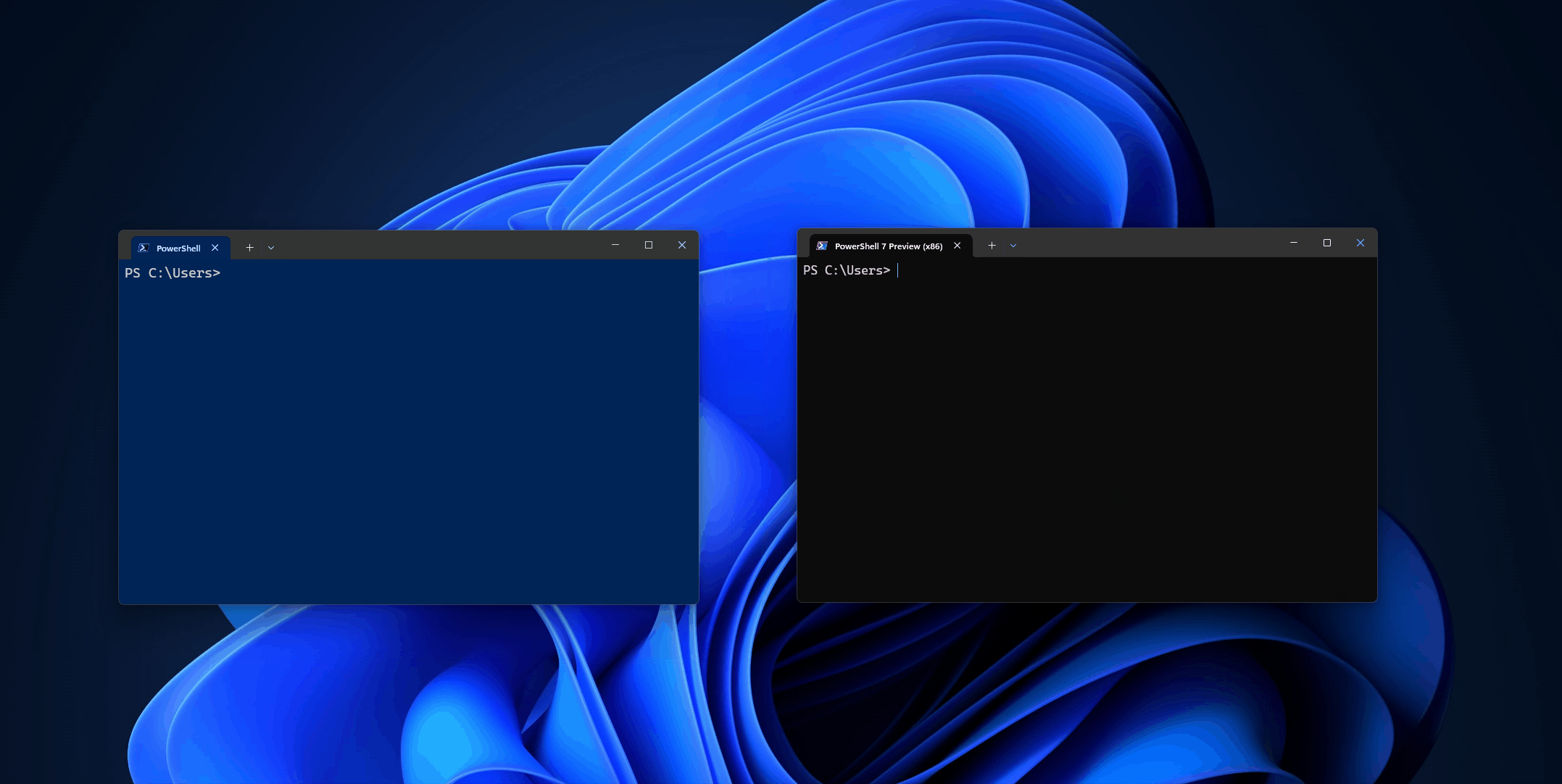
Windows on Arm
在过去的一年里,微软发布了 Windows Dev Kit 2023、Visual Studio 和 .NET 的 Arm 原生版本,以帮助加速在 Arm 上的开发。Windows 正在延续这一势头,并欢迎更多第三方 Windows 应用程序、中间件合作伙伴和 Arm 原生开源软件。
一些成果
- Visual Studio 17.6 为 Arm 提供了对 MAUI 的支持
- Visual Studio 17.71 Preview 1 支持使用 C++ 进行 Linux 开发
- LLVM v12.0 及更高版本,提供了用于 Arm 的交叉编译和原生编译选项
- 4 月份发布的 Node 20.0.0 已原生支持 Arm
- WiX installer v4.0 可用于为 Arm 创建原生安装程序
- 过去 12 个月内发布的新中间件项目:Qt 6.2, CMake 3.24, Bazel, 5.1, OpenSSL 3.0, OpenBLAS, 0.3.21, Python 3.11
- Unity Player 在 Windows on Arm 上已经正式 GA。使用该游戏引擎的开发者可轻松地将 Windows on Arm 设备作为 target
- Arm64 即将推出其他解决方案,例如 GNU GCC、Flutter & Dart、PyTorch、GIMP
让 Windows 11 开发者都能成为 AI 开发者
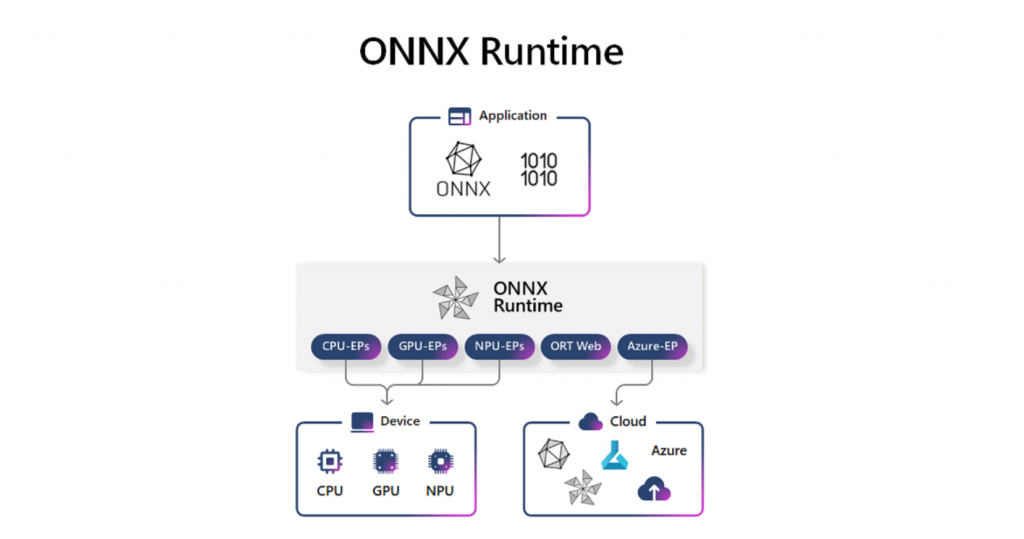
去年在 Build 大会上,微软宣布了一种新的开发模式 Hybrid Loop,可以跨 Azure 和客户端设备实现混合 AI 场景。在今年的 Build 上,微软表示其愿景已经实现,使用 ONNX Runtime 作为 Windows AI 和 Olive 的网关,微软创建的工具链减轻了用户在优化各种 Windows 和其他设备模型时的负担。
借助 ONNX Runtime,第三方开发者可以访问微软内部使用的工具,以便在 Windows 或跨 CPU、GPU、NPU 或与 Azure 混合的其他设备上运行 AI 模型。
在运行模型时,ONNX Runtime 现在支持在设备上或云端运行相同的 API,支持混合推理场景。此外,用户应用程序可以使用本地资源,并在需要时切换到云端。
今天关于眼见 macOS 运行 iOS App,微软希望 Windows 10 原生支持 Android App和macos运行windows软件的讲解已经结束,谢谢您的阅读,如果想了解更多关于angular – ng new hello错误:路径“/app/app.module.ts”不存在.路径“/app/app.module.ts”不存在、Apache Hadoop 3.1.0 发布,原生支持 GPU 和 FPGA、Apache Spark 2.3 原生支持 Kubernetes、Build 2023 亮点:Windows 原生支持 rar 格式、发布 Windows Copilot的相关知识,请在本站搜索。
本文标签:




