这篇文章主要围绕Boosting算法的前世今生和下篇展开,旨在为您提供一份详细的参考资料。我们将全面介绍Boosting算法的前世今生的优缺点,解答下篇的相关问题,同时也会为您带来Angular的前世
这篇文章主要围绕Boosting算法的前世今生和下篇展开,旨在为您提供一份详细的参考资料。我们将全面介绍Boosting算法的前世今生的优缺点,解答下篇的相关问题,同时也会为您带来Angular 的前世今生、async & await 的前世今生(Updated)、Boosting算法之Adaboost和GBDT、ES6-前世今生(0)的实用方法。
本文目录一览:- Boosting算法的前世今生(下篇)(boosting算法原理)
- Angular 的前世今生
- async & await 的前世今生(Updated)
- Boosting算法之Adaboost和GBDT
- ES6-前世今生(0)
(boosting算法原理)")
Boosting算法的前世今生(下篇)(boosting算法原理)
目录
- 引言
-
LightGBM 的提出
- 单边梯度采样 GOSS
- 互斥特征合并 EFB
- 决策树生长策略
- 结果
-
CatBoost
- 关键创新点
- 处理类别特征
- 完全对称树
- 结果
- Boosting算法发展流程
- 关注AIKaggle
- 赞赏Kaggle实战机器学习
微信公众号:AIKaggle
欢迎建议和拍砖,若需要资源,请公众号留言;
如果你觉得AIKaggle对你有帮助,欢迎赞赏
Boosting算法的前世今生(下篇)
本系列文章将会梳理Boosting算法的发展,介绍Boosting算法族的原理,框架,推导等,Boosting算法的前世今生(上篇)介绍了AdaBoost算法和梯度提升树算法,中篇详细介绍了陈天奇教主提出的XGBoost算法,下篇(本文)将会介绍LightGBM算法,catboost算法。LightGBM算法由Microsoft Research提出,主打梯度提升算法的轻量级实现,他的两个创新点在于基于单边梯度的采样算法(GOSS)和互斥系数特征合并(EFB)。而catboost是由俄罗斯Yandex公司提出的,他嵌入了自动将类别特征处理为数值型特征的创新型算法,并且使用完全对称树作为基模型。如果对机器学习算法和实战案例感兴趣,也可关注公众号:AIkaggle获取算法动态
引言
- 传统的boosting算法(如GBDT和XGBoost)已经有相当好的效率,但是在如今的大样本和高维度的环境下,传统的boosting似乎在效率和可扩展性上不能满足现在的需求了,主要的原因就是传统的boosting算法需要对每一个特征都要扫描所有的样本点来选择最好的切分点,这是非常的耗时。
LightGBM 的提出
LightGBM算法是由Microsoft Research提出的一种梯度提升算法的轻量级实现,发表论文为:"LightGBM: A Highly Efficient Gradient Boosting Decision Tree"。
梯度提升回归树(GBRT)是目前最流行的机器学习算法之一,它的几个具体实现包括 XGBoost 和 pGBRT 。虽然 XGBoost 和 pGBRT 在实现过程中已经采用了许多工程优化的技术,但是当涉及到庞大的数据量和高维的特征空间时,XGBoost 和 pGBRT 等算法依旧存在效率和可扩展性上的局限性。之前的算法实现非常耗时的重要原因是对每一个特征来说,XGBoost 和 pGBRT 都需要遍历所有的实例来计算最佳的信息增益,从而确定最优的分裂节点。
为了解决这些问题,LightGBM 算法采用了单边梯度采样方法(Gradient-based One-Side Sampling,简称为 GOSS)和互斥稀疏特征绑定(Exclusive Feature Bundling,简称为 EFB)。使用 GOSS 可以大量减少具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有大梯度的数据,大大减少了时间开销。由于具有大梯度的数据实例在计算信息增益的时候更为重要,所以在体量较小的数据集上使用 GOSS 能获得较为精准的信息增益估计。使用 EFB 可以将许多互斥的特征绑定为一个特征(互斥特征的含义为几乎不同时为零的特征),这样就达到了降维的目的。虽然将互斥特征进行绑定是一个 NP 难问题,但是运用贪心算法可以取得较好的近似结果,即在很少影响分割点的前提下有效地减少特征数目。使用 GOSS 和 EFB 的 LightGBM 算法对比传统的 GBRT 算法,能在实现近似准确率的前提下大大提高训练进程的速度。
单边梯度采样 GOSS
GOSS 的目的是保留对计算信息增益贡献大的数据实例,即保留梯度较大的实例,而在梯度较小的实例上进行随机采样。具有较大梯度的数据对计算信息增益的贡献比较大,这在论文 Greedy Function Approximation: A Gradient Boosting Machine已经给出了证明。
GOSS(基于梯度的单边采样)方法的主要思想就是,梯度大的样本点在信息增益的计算上扮演着主要的作用,也就是说这些梯度大的样本点会贡献更多的信息增益,因此为了保持信息增益评估的精度,当我们对样本进行下采样的时候保留这些梯度大的样本点,而对于梯度小的样本点按比例进行随机采样即可。
在AdaBoost算法中,我们在每次迭代时更加注重上一次错分的样本点,也就是上一次错分的样本点的权重增大,而在GBDT中并没有本地的权重来实现这样的过程,所以在AdaBoost中提出的采样模型不能应用在GBDT中。但是,每个样本的梯度对采样提供了非常有用的信息。也就是说,如果一个样本点的梯度小,那么该样本点的训练误差就小并且已经经过了很好的训练。一个直接的办法就是直接抛弃梯度小的样本点,但是这样做的话会改变数据的分布和损失学习的模型精度。
GOSS的提出就是为了避免这两个问题的发生,为了不影响原始数据的分布,GOSS 的做法是先将所有数据实例按照他们梯度绝对值大小按降序排列,选取绝对值最大的 \(a\times 100\%\) 的数据,然后在余下的小梯度数据中随机选择 \(b\timES100\%\) 的数据,并且在计算信息增益的时候将这些随机选取的小梯度数据乘以一个常数 \(\frac{1-a}{b}\) ,GOSS 具体算法流程如下:
// Algorithm:Gradient-based One-Side Sampling
// 算法描述:?基于梯度的单边采样
输入: I:训练数据,d:迭代次数
输入: a:大梯度数据的采样比例
输入: b:小梯度数据的采样比例
输入: loss:损失函数,L: 弱学习器
模型models初始化:models = {}
常数fact初始化:fact = (1-a)/b
大梯度样本个数 topN = a * len(I)
小梯度样本采样个数 randN = b * len(I)
for(i = 1:d){
用现有模型对样本进行预测:
preds = models.predict(I)
计算梯度:
g = loss(I,preds)
分配样本权重:
w = {1,1,...}
将样本按梯度大小进行排序:
sorted = GetSortedindices(abs(g))
选取大梯度样本:
topSet = sorted[1:topN]
随机选取小梯度样本:
randSet = RandomPick(sorted[topN:len(I)],randN)
合并大梯度样本和随机选取的样本:
usedSet = topSet + randSet
将随机采样得到的样本权重乘上常数:fact:
w[randSet] *= fact
在合并样本上最小化损失函数得到第i个模型:
newModel = L(I[usedSet],-g[usedSet],w[usedSet])
将第i个模型添加到现有模型中:models.append(newModel)
}
由 GOSS 算法流程可知,在第 \(d\) 次迭代中 LightGBM 只使用了
usedSet个实例进行训练,每一轮迭代都学习了一个弱学习器,并且在进行下一轮学习时,前面的每一轮所学习的弱学习器都将影响该轮的学习。通过上面的算法可以在不改变数据分布的前提下不损失学习器精度的同时大大的减少模型学习的速率。从上面的描述可知,当\(a=0\)时,GOSS算法退化为随机采样算法;当\(a=1\)时,GOSS算法变为采取整个样本的算法。在许多情况下,GOSS算法训练出的模型精确度要高于随机采样算法。另一方面,采样也将会增加若学习器的多样性,从而潜在的提升了训练出的模型泛化能力。
互斥特征合并 EFB
EFB 中文名叫互斥特征合并,顾名思义它就是将若干个互斥特征合并在一起。使用这个算法的原因是我们要解决高维数据稀疏的问题。在很多时候,数据通常都是几千几万维的稀疏数据,因此我们将不同维度的数据合并,使得一个稀疏矩阵变成一个稠密矩阵。这里就有两个问题,其一是如何确定应该合并的特征;其二是如何将这些特征合并到一起。
对于第一个问题,这是一个 NP 难问题。我们把特征看作是图中的点,特征之间的总冲突看作是图中的边。而寻找需要合并的特征且使得合并后的束数目最小,这可以看成是一个图着色问题,可以采用贪心算法。所以找出需要合并的特征且使得束个数最小的问题可以采用近似的贪心算法来完成,算法流程见下:
// 算法描述:贪心法合并特征
输入:特征 F,最大冲突数 K
输出:束 bundles
构造图G
按照图中的度数排序 searchOrder = G.sortByDegree()
初始化束 bundles = {}
初始化束冲突 bundlesConflict = {}
for ( i in searchOrder){
初始化指针 neednew = True
for (j : len(bundles)){
计算当前冲突数
cnt = ConflictCnt(bundles[j],F[i])
if (cnt+bundlesConflict[i] <= K){
将当前特征添加到第j个束中 bundles[j].append(F[i])
更改指针的值 neednew = True
break
}
}
if (neednew){
把F[i]作为新成员添加到束bundles中
}
}
- 问题二是将这些束中的特征合并起来。由于在每一个束当中,特征的取值范围都不一样,所以我们需要重新构建合并后束中特征的取值范围。在第一个
for循环当中,我们记录每个特征与之前特征累积的总取值范围totalRange。在第二个for循环当中,根据之前的binRanges重新计算出新的箱值F[j].bin[i] + binRanges[j]保证特征之间的值不会冲突。这是针对于稀疏矩阵进行优化。由于之前贪心法合并特征算法对特征进行冲突检查,确保束内特征冲突尽可能少,所以特征之间的非零元素不会有太多的冲突,互斥特征合并算法流程见下。
// 算法描述:合并互斥特征
// algorithm: Exclusive Feature Bundling
输入: 样本数量 numData
输入: 一束互斥特征 F
输出: newBin,binRanges
初始化 binRange: binRanges = {0}
初始化 totalBin: totalBin = 0
for (f in F){
增加当前特征的取值范围 totalBin += f.numBin
添加totalBin进入binRange: binRanges.append(totalBin)
}
初始化新的箱
newBin = new Bin(numData)
for (i=1:numData){
初始化第i个新的箱 newBin[i] = 0
for (j=1:len(F)){
if (F[j].bin[i] != 0){
计算第i个新的箱值
newBin[i] = F[j].bin[i] + binRanges[j]
}
}
}
- 采用了 EFB 算法之后,数据特征从原来的特征数骤减为束数,从而有效减小了数据的特征规模,提高了模型的训练速度。
决策树生长策略
Level-wise
- 大部分决策树的学习算法通过 level-wise 策略生长树,记一次分裂同一层的叶子,不加区分的对待同一层的叶子,而实际上很多叶子的分裂增益较低没必要进行分裂,带来了没必要的开销。如下图:

Leaf-wise
- LightGBM 通过 leaf-wise 策略来生长树。每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。但是,当样本量较小的时候,leaf-wise 可能会造成过拟合。 所以,LightGBM 可以利用额外的参数?max_depth?来限制树的深度并避免过拟合。

结果
- 数据集

- 总体训练时间比较。(表格内是训练一轮的平均时间消耗,单位:秒)LightGBM代表运用了GOSS和EFB算法的lgb_baseline。EFB_only代表只运用了EFB算法的lgb_baseline。

- 测试集上的Accuracy。分类评价指标:AUC,排序评价指标:[email protected]。SGB代表运用了随机梯度提升的lgb_baseline,SGB和LightGBM采用了相同的采样比。


catboost
catboost是由俄罗斯Yandex公司在2017年4月提出的,当年发表了一篇论文
"catboost: gradient boosting with categorical features support",不过里面并没有对各种创新点进行详细的描述,在2019年初,Yandex公司又发表了一篇论文“catboost - unbiased boosting with categorical features”,在这篇论文里较为详细的描述了catboost算法的关键创新点。
关键创新点
- catboost 有三个关键创新点,一是嵌入了自动将类别特征处理为数值型特征的创新算法,二是采用排序提升的方法对抗训练集中的噪声点,从而避免梯度估计的偏差,三是采用了完全对称树作为基模型。
处理类别特征
- catboost 算法的设计初衷是为了更好的处理类别特征。在处理类别特征的时候,需要用数值型特征替代原先的类别特征。处理类别特征 \(i\) 的一个简单有效的方法是用目标统计量(Target Statistic) TS \(\hat{x}_k^i\) 来替代第 \(k\) 个训练样本的第 \(i\) 维特征 \(x_k^i\)。通常情况下,使用标签 \(y\) 在该类别下的条件期望来作为 \(\hat{x}_k^i\) 的取值,即:\(\hat{x}_k^i \simeq E(y|x^i = x_k^i)\)。
- catboost 受到在线学习算法的启发,认为每个样本目标统计量的值都依赖于之前的观测数据,所以在训练集上引入了随机置换 \(\sigma\) 来模拟一种抽象的时间概念,提出了基于随机置换 \(\sigma\) 的目标统计量估计方法,称为 Ordered TS。而且 catboost 会在梯度提升的迭代过程中使用不同的置换方式。设 \(D_k = \{x_j: \sigma(j)<\sigma(k)\}\),对 \(\hat{x}_k^i\) 的估计为:
\[ \hat{x}_k^i = \frac{\sum_{x_j \in D_k} 1_{x_j^i=x_k^i}\cdot y_j + ap }{\sum_{x_j \in D_k} 1_{x_j^i=x_k^i}+ap}\]
其中 \(a>0\) 为参数, \(p\) 是平滑参数,通常被设定为目标平均值。
完全对称树
catboost 使用完全对称树作为基模型。XGBoost 一层一层地建立节点,LightGBM 一个一个地建立节点,而 catboost 建立的节点是镜像的。catboost 称完全对称树有利于避免过拟合,增加可靠性,并且能大大加速预测进程。
结果
- catboost的logloss结果对比,可以显示出比之前的算法有一定程度的减小(可是没有Accuracy结果的对比,所以不能进行更进一步的比较,根据我的几次实验结果,往往是LightGBM和XGBoos的提升效果更好)。

Boosting算法发展流程

之后NUS的同学们还提出了梯度提升算法在GPU上的高性能实现——ThunderGBM: Fast GBDTs and Random Forests on GPUs,由于篇幅原因,不在Boosting算法的前世今生(下篇)中介绍,可能会单独写一篇小的随笔介绍这篇论文包含的技术创新点。
关注AIkaggle
下面的是我的公众号二维码图片,本公众号深度解读机器学习算法,分享kaggle比赛信息及实战案例,介绍数据科学方法论,分享竞赛技巧,分享tensorflow、keras、pytorch、深度学习、机器学习实战案例,欢迎关注。

赞赏kaggle实战机器学习
如果你觉得到kaggle实战机器学习对你有帮助,欢迎赞赏,有你的支持,kaggle实战机器学习一定会越来越好!

有帮助的话,点个在看支持一下哦~~

Angular 的前世今生
目录
- 序言
- AngularJS 简介
- Angular 2.0 的动机
- 现如今的 Angular
- Angular 的核心概念
- 参考
序言
Angular 一般意义上是指 Angular v2 及以上版本,而 AngularJS 专指 Angular 的所有 1.x 版本。出现这种区别是由于 Angular 对 AngularJS 进行了完全重写,两者区别很大,直接形成了两个独立的产品。
- AngularJS 官网:Superheroic JavaScript MVW Framework
- Angular 官网:One framework. Mobile & desktop.

接下来主要介绍 Angular 最初出现的动机以及其核心概念。
AngularJS 简介
AngularJS 诞生于 2009 年,由 Misko Hevery 等人创建,后被 Google 收购,是一款的前端 JS 框架。AngularJS 有着诸多特性,最为核心的是:MVVM、模块化、自动化双向数据绑定、语义化标签、依赖注入等等。
Angular 2.0 的动机
为了解决 AngularJS 1.x 中存在的各种问题以及跟上新的标准规范,而进行了一次彻底革新。
(1)性能
AngularJS 最初作为一个工具被创建,并不是为开发人员设计的,更倾向于设计人员用来快速创建持久化 HTML 表单。在之后的发展中,为了让开发人员也能用它进行构建更多、更复杂的程序,Angualr 1.x 的维护团队不断增量地改进,使它能适应现代 Web 应用程序的需求。不过,由于原始设计上的一些潜规则,不论如何改进终究是有其局限性,而这也导致了当前的绑定和模板基础架构始终存在性能瓶颈。而为了解决性能问题,需要新的策略。
(2)变化的 Web
在 AngularJS 被创建出来的5年中,Web 也在不断的发展,不仅仅是 JavaScript 的规范快速发展,使得浏览器开始支持 module、class、lambda、generator 等新的语法特性,另外 Web Components 的技术标准也被提出并被浏览器逐步支持。现如今 Web Components 主要由三种技术组成:
- Custom elements(自定义元素),允许通过一组 JavaScript API 来自定义标签扩展 HTML。
- Shadow DOM(影子DOM),允许对元素功能私有化(对HTML、CSS 和 JavaScript 进行封装),不用担心与文档的其他部分发生冲突。
- HTML templates(HTML模板),允许在 HTML 中定义模板,模板可以反复使用,并且只有调用的时候才会被渲染。
Web Components 是一种创建封装的、可复用的网页 UI 组件的标准化方式,其不仅可以弥补标准的 HTML 工具集所存在的不足,也能提升开发人员的创造能力和开发效率。
Angular 1.x 本身是包含数据绑定功能的,其构建在一部分已知的 HTML 元素和常用事件、行为的基础上,而为了使其支持 Web Components 技术,就需要有一个全新的数据绑定实现。
(3)移动端
随着互联网的不断发展,手机等移动端开始崛起,通用计算场景逐步发送变化。而最初设计的 AngularJS 虽然可以被用于创建移动应用,但它本身的理念并非为此设计。这也导致了它在移动端这块面临诸多问题,包括前面提到的性能问题,不能缓存预编译视图以及过于普通的触摸支持等等。
(4)易用性
AngularJS 的很多核心特性都是逐步被“拼凑”出来的,比如最开始没有自定义指令,都是硬编码,之后增加了专门用于添加指令的API,最开始也没有控制器,也是之后才增加了控制器的概念和功能等。可以说 AngularJS 最初被设计时,其核心特性就不是很清晰,这也就造就了很多 API 的设计得不够优雅,这也增加开发人员的学习和使用的难度。
现如今的 Angular
Angular 是一个用 HTML 和 TypeScript 构建客户端应用的平台与框架。 Angular 本身由 TypeScript 写成,它将核心功能和可选功能作为一组 TypeScript 库进行实现,开发人员可以直接导入使用。
Angular 的核心概念
Angular 的很多核心概念是继承至 AngularJS 的(依赖注入、数据绑定等等),并在其基础上进一步发展。
Angular 框架有八大核心概念,它们是 Angular 的重要组成部分,如下图:
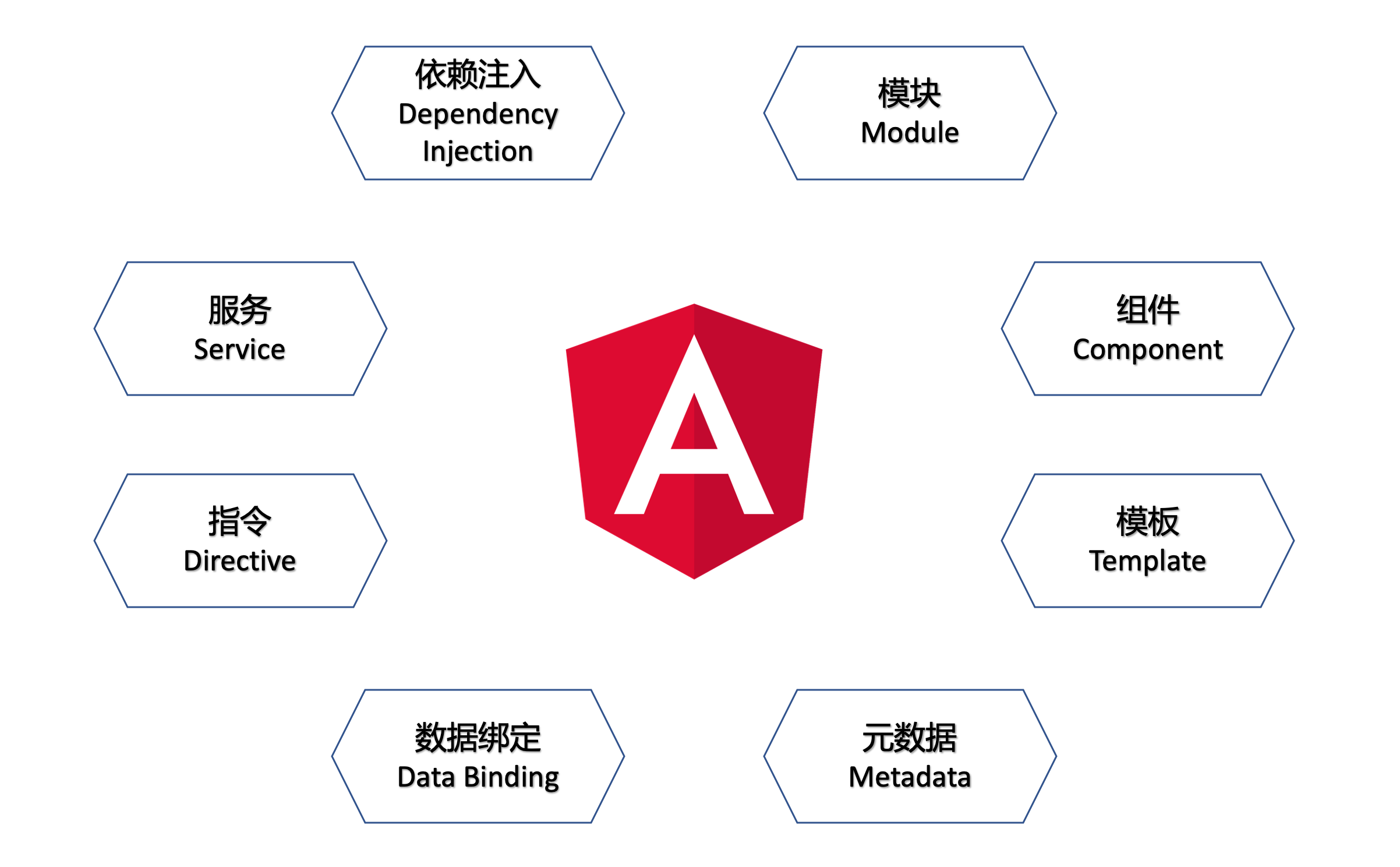
模块 (Module):Angular 应用是模块化的,它拥有自己的模块化系统,称作 NgModule。 一个 NgModule 就是一个容器,用于存放一些内聚的代码块,这些代码块专注于某个应用领域、某个工作流或一组紧密相关的功能。
组件 (Component): 组件用来包装特定的功能,在类(class)中定义组件的应用逻辑,为视图提供支持。
模板 (Template):模板就是一种 HTML,用它来告诉 Angular 如何渲染该组件。模板很像标准的 HTML,但是它也包含 Angular 的模板语法,这些模板语法可以根据自定义的应用逻辑、状态和 DOM 数据来修改 HTML。
元数据 (Metadata):元数据用于告诉 Angular 如何处理一个类,例如从哪里获取它需要的主要构造块,以创建和展示这个组件及其视图。
数据绑定 (Data Binding):数据绑定就是把数据映射到模板上,或者从模板中取回数据。 Angular 支持双向数据绑定。
指令 (Directive):指令就是一个带有 @Directive() 装饰器的类。在 Angualr 渲染时,会根据指令给出的指示对 DOM 进行转换。(组件从技术角度上说也是一个指令)
服务 (Service):广义的服务包括应用所需的任何值、函数或特性。狭义的服务是一个明确定义了用途的类,它应该做一些具体的事,并做好。
依赖注入 (Dependency Injection):依赖注入(DI)是一种重要的设计模式。在 Angular 框架中,依赖注入被用于在任何地方给新建的组件提供服务或所需的其它东西。 组件是服务的消费者,通过 DI 把一个服务注入到组件中,让组件类得以访问该服务类。
Angular 框架的八大核心概念相互之间的关系,如下图:
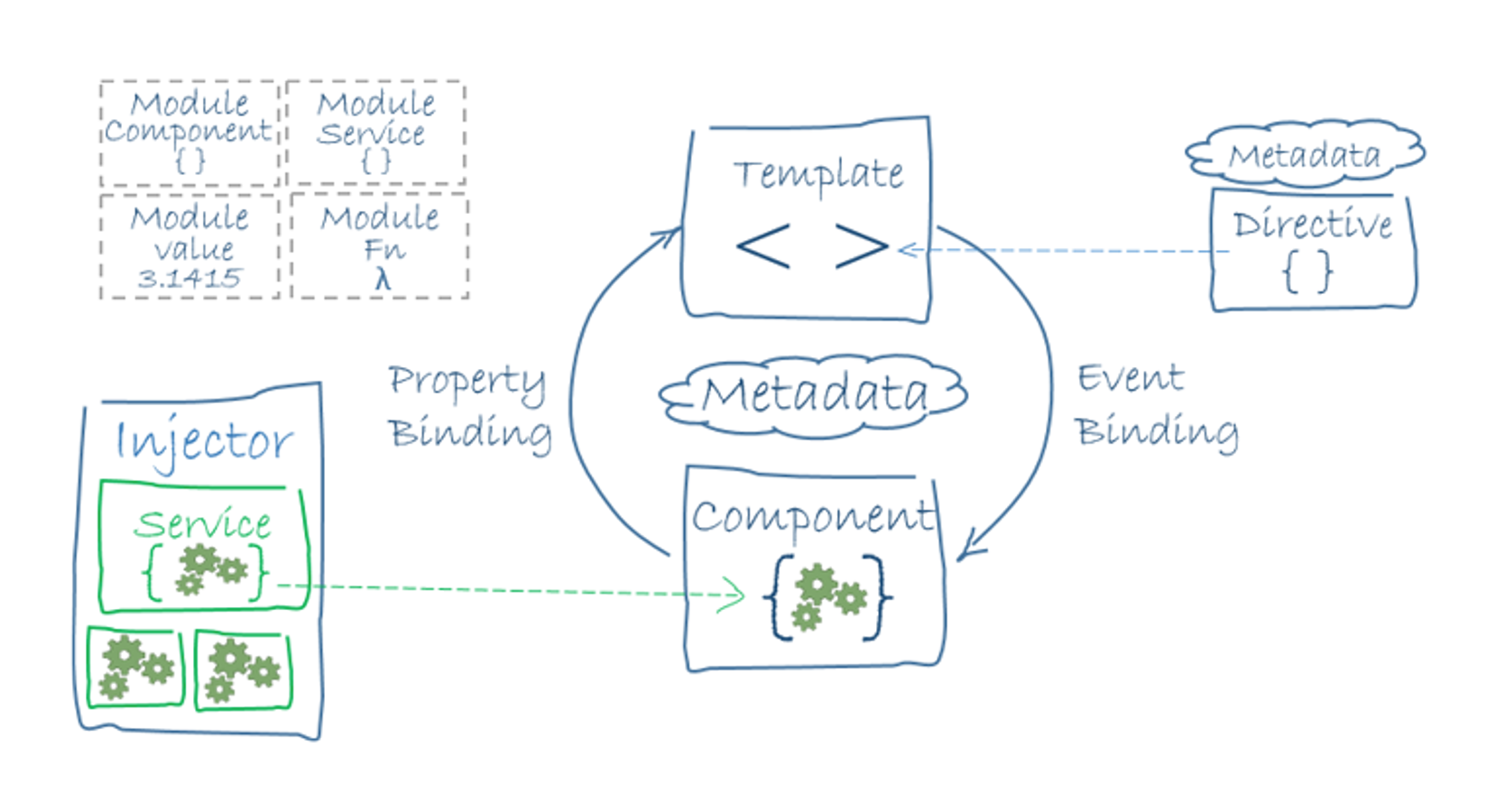
上图中的关系概要:
- 组件和模板共同定义了 Angular 的视图。
- 组件类上的装饰器为其添加了元数据,其中包括指向相关模板的指针。
- 组件模板中的指令和绑定标记会根据程序数据和程序逻辑修改这些视图。
- 依赖注入器会为组件提供一些服务,比如路由器服务能让开发人员定义如何在视图之间导航。
参考
Angular 发展历程概述
Angular和AngularJS之间的关系?
有关Angular 2.0的一切
Web Components - MDN Web Docs
Angular 文档
")
async & await 的前世今生(Updated)
async & await 的前世今生(Updated)
2014-02-24 08:24 by Jesse Liu, 10129 阅读, 90 评论, 收藏, 编辑async 和 await 出现在C# 5.0之后,给并行编程带来了不少的方便,特别是当在MVC中的Action也变成async之后,有点开始什么都是async的味道了。但是这也给我们编程埋下了一些隐患,有时候可能会产生一些我们自己都不知道怎么产生的Bug,特别是如果连线程基础没有理解的情况下,更不知道如何去处理了。那今天我们就来好好看看这两兄弟和他们的叔叔(Task)爷爷(Thread)们到底有什么区别和特点,本文将会对Thread 到 Task 再到 .NET 4.5的 async和 await,这三种方式下的并行编程作一个概括性的介绍包括:开启线程,线程结果返回,线程中止,线程中的异常处理等。
内容索引
- 创建线程
- 线程池
- 参数
- 返回值
- 共享数据
- 线程安全
- 锁
- Semaphore
- 异常处理
- 一个小例子认识async & await
- await的原形
创建
1
2
3
4
5
6
7
8
9
static void Main(){
new Thread(Go).Start(); // .NET 1.0开始就有的
Task.Factory.StartNew(Go); // .NET 4.0 引入了 TPL
Task.Run(new Action(Go)); // .NET 4.5 新增了一个Run的方法
}
public static void Go(){
Console.WriteLine("我是另一个线程");
}
这里面需要注意的是,创建Thread的实例之后,需要手动调用它的Start方法将其启动。但是对于Task来说,StartNew和Run的同时,既会创建新的线程,并且会立即启动它。
线程池
线程的创建是比较占用资源的一件事情,.NET 为我们提供了线程池来帮助我们创建和管理线程。Task是默认会直接使用线程池,但是Thread不会。如果我们不使用Task,又想用线程池的话,可以使用ThreadPool类。
1
2
3
4
5
6
7
8
9
10
static void Main() {
Console.WriteLine("我是主线程:Thread Id {0}", Thread.CurrentThread.ManagedThreadId);
ThreadPool.QueueUserWorkItem(Go);
Console.ReadLine();
}
public static void Go(object data) {
Console.WriteLine("我是另一个线程:Thread Id {0}",Thread.CurrentThread.ManagedThreadId);
}

传入参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static void Main() {
new Thread(Go).Start("arg1"); // 没有匿名委托之前,我们只能这样传入一个object的参数
new Thread(delegate(){ // 有了匿名委托之后...
GoGoGo("arg1", "arg2", "arg3");
});
new Thread(() => { // 当然,还有 Lambada
GoGoGo("arg1","arg2","arg3");
}).Start();
Task.Run(() =>{ // Task能这么灵活,也是因为有了Lambda呀。
GoGoGo("arg1", "arg2", "arg3");
});
}
public static void Go(object name){
// TODO
}
public static void GoGoGo(string arg1, string arg2, string arg3){
// TODO
}
返回值
Thead是不能返回值的,但是作为更高级的Task当然要弥补一下这个功能。
1
2
3
4
5
static void Main() {
// GetDayOfThisWeek 运行在另外一个线程中
var dayName = Task.Run<string>(() => { return GetDayOfThisWeek(); });
Console.WriteLine("今天是:{0}",dayName.Result);
}
共享数据
上面说了参数和返回值,我们来看一下线程之间共享数据的问题。
1
2
3
4
5
6
7
8
9
10
11
12
private static bool _isDone = false;
static void Main(){
new Thread(Done).Start();
new Thread(Done).Start();
}
static void Done(){
if (!_isDone) {
_isDone = true; // 第二个线程来的时候,就不会再执行了(也不是绝对的,取决于计算机的CPU数量以及当时的运行情况)
Console.WriteLine("Done");
}
}

线程之间可以通过static变量来共享数据。
线程安全
我们先把上面的代码小小的调整一下,就知道什么是线程安全了。我们把Done方法中的两句话对换了一下位置 。
1
2
3
4
5
6
7
8
9
10
11
12
13
private static bool _isDone = false;
static void Main(){
new Thread(Done).Start();
new Thread(Done).Start();
Console.ReadLine();
}
static void Done(){
if (!_isDone) {
Console.WriteLine("Done"); // 猜猜这里面会被执行几次?
_isDone = true;
}
}

上面这种情况不会一直发生,但是如果你运气好的话,就会中奖了。因为第一个线程还没有来得及把_isDone设置成true,第二个线程就进来了,而这不是我们想要的结果,在多个线程下,结果不是我们的预期结果,这就是线程不安全。
锁
要解决上面遇到的问题,我们就要用到锁。锁的类型有独占锁,互斥锁,以及读写锁等,我们这里就简单演示一下独占锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private static bool _isDone = false;
private static object _lock = new object();
static void Main(){
new Thread(Done).Start();
new Thread(Done).Start();
Console.ReadLine();
}
static void Done(){
lock (_lock){
if (!_isDone){
Console.WriteLine("Done"); // 猜猜这里面会被执行几次?
_isDone = true;
}
}
}
再我们加上锁之后,被锁住的代码在同一个时间内只允许一个线程访问,其它的线程会被阻塞,只有等到这个锁被释放之后其它的线程才能执行被锁住的代码。
Semaphore 信号量
我实在不知道这个单词应该怎么翻译,从官方的解释来看,我们可以这样理解。它可以控制对某一段代码或者对某个资源访问的线程的数量,超过这个数量之后,其它的线程就得等待,只有等现在有线程释放了之后,下面的线程才能访问。这个跟锁有相似的功能,只不过不是独占的,它允许一定数量的线程同时访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static SemaphoreSlim _sem = new SemaphoreSlim(3); // 我们限制能同时访问的线程数量是3
static void Main(){
for (int i = 1; i <= 5; i++) new Thread(Enter).Start(i);
Console.ReadLine();
}
static void Enter(object id){
Console.WriteLine(id + " 开始排队...");
_sem.Wait();
Console.WriteLine(id + " 开始执行!");
Thread.Sleep(1000 * (int)id);
Console.WriteLine(id + " 执行完毕,离开!");
_sem.Release();
}

在最开始的时候,前3个排队之后就立即进入执行,但是4和5,只有等到有线程退出之后才可以执行。
异常处理
其它线程的异常,主线程可以捕获到么?
1
2
3
4
5
6
7
8
9
10
public static void Main(){
try{
new Thread(Go).Start();
}
catch (Exception ex){
// 其它线程里面的异常,我们这里面是捕获不到的。
Console.WriteLine("Exception!");
}
}
static void Go() { throw null; }
那么升级了的Task呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static void Main(){
try{
var task = Task.Run(() => { Go(); });
task.Wait(); // 在调用了这句话之后,主线程才能捕获task里面的异常
// 对于有返回值的Task, 我们接收了它的返回值就不需要再调用Wait方法了
// GetName 里面的异常我们也可以捕获到
var task2 = Task.Run(() => { return GetName(); });
var name = task2.Result;
}
catch (Exception ex){
Console.WriteLine("Exception!");
}
}
static void Go() { throw null; }
static string GetName() { throw null; }
一个小例子认识async & await
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static void Main(string[] args){
Test(); // 这个方法其实是多余的, 本来可以直接写下面的方法
// await GetName()
// 但是由于控制台的入口方法不支持async,所有我们在入口方法里面不能 用 await
Console.WriteLine("Current Thread Id :{0}", Thread.CurrentThread.ManagedThreadId);
}
static async Task Test(){
// 方法打上async关键字,就可以用await调用同样打上async的方法
// await 后面的方法将在另外一个线程中执行
await GetName();
}
static async Task GetName(){
// Delay 方法来自于.net 4.5
await Task.Delay(1000); // 返回值前面加 async 之后,方法里面就可以用await了
Console.WriteLine("Current Thread Id :{0}", Thread.CurrentThread.ManagedThreadId);
Console.WriteLine("In antoher thread.....");
}

await 的原形
await后的的执行顺序

感谢 locus的指正, await 之后不会开启新的线程(await 从来不会开启新的线程),所以上面的图是有一点问题的。
await 不会开启新的线程,当前线程会一直往下走直到遇到真正的Async方法(比如说HttpClient.GetStringAsync),这个方法的内部会用Task.Run或者Task.Factory.StartNew 去开启线程。也就是如果方法不是.NET为我们提供的Async方法,我们需要自己创建Task,才会真正的去创建线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
static void Main(string[] args)
{
Console.WriteLine("Main Thread Id: {0}\r\n", Thread.CurrentThread.ManagedThreadId);
Test();
Console.ReadLine();
}
static async Task Test()
{
Console.WriteLine("Before calling GetName, Thread Id: {0}\r\n", Thread.CurrentThread.ManagedThreadId);
var name = GetName(); //我们这里没有用 await,所以下面的代码可以继续执行
// 但是如果上面是 await GetName(),下面的代码就不会立即执行,输出结果就不一样了。
Console.WriteLine("End calling GetName.\r\n");
Console.WriteLine("Get result from GetName: {0}", await name);
}
static async Task<string> GetName()
{
// 这里还是主线程
Console.WriteLine("Before calling Task.Run, current thread Id is: {0}", Thread.CurrentThread.ManagedThreadId);
return await Task.Run(() =>
{
Thread.Sleep(1000);
Console.WriteLine("''GetName'' Thread Id: {0}", Thread.CurrentThread.ManagedThreadId);
return "Jesse";
});
}

我们再来看一下那张图:

- 进入主线程开始执行
- 调用async方法,返回一个Task,注意这个时候另外一个线程已经开始运行,也就是GetName里面的 Task 已经开始工作了
- 主线程继续往下走
- 第3步和第4步是同时进行的,主线程并没有挂起等待
- 如果另一个线程已经执行完毕,name.IsCompleted=true,主线程仍然不用挂起,直接拿结果就可以了。如果另一个线程还同有执行完毕, name.IsCompleted=false,那么主线程会挂起等待,直到返回结果为止。
只有async方法在调用前才能加await么?
1
2
3
4
5
6
7
8
9
10
11
12
13
static void Main(){
Test();
Console.ReadLine();
}
static async void Test(){
Task<string> task = Task.Run(() =>{
Thread.Sleep(5000);
return "Hello World";
});
string str = await task; //5 秒之后才会执行这里
Console.WriteLine(str);
}
答案很明显:await并不是针对于async的方法,而是针对async方法所返回给我们的Task,这也是为什么所有的async方法都必须返回给我们Task。所以我们同样可以在Task前面也加上await关键字,这样做实际上是告诉编译器我需要等这个Task的返回值或者等这个Task执行完毕之后才能继续往下走。
不用await关键字,如何确认Task执行完毕了?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static void Main(){
var task = Task.Run(() =>{
return GetName();
});
task.GetAwaiter().OnCompleted(() =>{
// 2 秒之后才会执行这里
var name = task.Result;
Console.WriteLine("My name is: " + name);
});
Console.WriteLine("主线程执行完毕");
Console.ReadLine();
}
static string GetName(){
Console.WriteLine("另外一个线程在获取名称");
Thread.Sleep(2000);
return "Jesse";
}

Task.GetAwaiter()和await Task 的区别?

- 加上await关键字之后,后面的代码会被挂起等待,直到task执行完毕有返回值的时候才会继续向下执行,这一段时间主线程会处于挂起状态。
- GetAwaiter方法会返回一个awaitable的对象(继承了INotifyCompletion.OnCompleted方法)我们只是传递了一个委托进去,等task完成了就会执行这个委托,但是并不会影响主线程,下面的代码会立即执行。这也是为什么我们结果里面第一句话会是 “主线程执行完毕”!
Task如何让主线程挂起等待?
上面的右边是属于没有挂起主线程的情况,和我们的await仍然有一点差别,那么在获取Task的结果前如何挂起主线程呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
static void Main(){
var task = Task.Run(() =>{
return GetName();
});
var name = task.GetAwaiter().GetResult();
Console.WriteLine("My name is:{0}",name);
Console.WriteLine("主线程执行完毕");
Console.ReadLine();
}
static string GetName(){
Console.WriteLine("另外一个线程在获取名称");
Thread.Sleep(2000);
return "Jesse";
}

Task.GetAwait()方法会给我们返回一个awaitable的对象,通过调用这个对象的GetResult方法就会挂起主线程,当然也不是所有的情况都会挂起。还记得我们Task的特性么? 在一开始的时候就启动了另一个线程去执行这个Task,当我们调用它的结果的时候如果这个Task已经执行完毕,主线程是不用等待可以直接拿其结果的,如果没有执行完毕那主线程就得挂起等待了。
await 实质是在调用awaitable对象的GetResult方法
1
2
3
4
5
6
7
8
9
10
11
12
13
static async Task Test(){
Task<string> task = Task.Run(() =>{
Console.WriteLine("另一个线程在运行!"); // 这句话只会被执行一次
Thread.Sleep(2000);
return "Hello World";
});
// 这里主线程会挂起等待,直到task执行完毕我们拿到返回结果
var result = task.GetAwaiter().GetResult();
// 这里不会挂起等待,因为task已经执行完了,我们可以直接拿到结果
var result2 = await task;
Console.WriteLine(str);
}

到此为止,await就真相大白了,欢迎点评。Enjoy Coding! :)
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。
【关注】Jesse Liu
原文地址: http://www.cnblogs.com/jesse2013/p/async-and-await.html

Boosting算法之Adaboost和GBDT
Boosting是串行式集成学习方法的代表,它使用加法模型和前向分步算法,将弱学习器提升为强学习器。Boosting系列算法里最著名的算法主要有AdaBoost和梯度提升系列算法(Gradient Boost,GB),梯度提升系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Decision Tree,GBDT)。
一、Adaboost
1、Adaboost介绍
Adaboost算法通过在训练集上不断调整样本权重分布,基于不同的样本权重分布,重复训练多个弱分类器,最后通过结合策略将所有的弱分类器组合起来,构成强分类器。Adaboost算法在训练过程中,注重减少每个弱学习器的误差,在训练下一个弱学习器时,根据上一次的训练结果,调整样本的权重分布,更加关注那些被分错的样本,使它们在下一次训练中得到更多的关注,有更大的可能被分类正确。
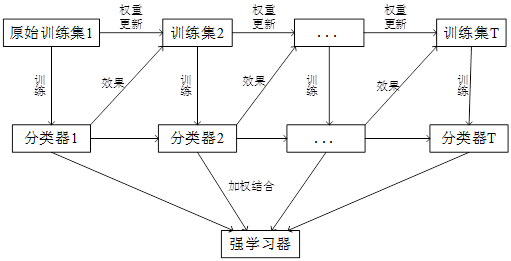
Adaboost算法框架图
2、Adaboost算法过程
1)初始化样本权重,一共有n个样本,则每个样本的权重为1/n
2)在样本分布Dt上,训练弱分类器,for t=1,2,……T:
a、训练分类器ht
b、计算当前弱分类器的分类误差率

c、判断误差率是否小于0.5,是则继续,否则退出循环
d、计算当前弱分类器的权重系数alpha值
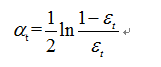
e、根据alpha值调整样本分布Dt+1
如果样本被正确分类,则该样本的权重更改为:
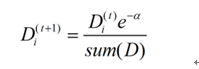
如果样本被错误分类,则该样本的权重更改为:
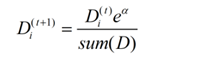
3)组合弱分类器得到强分类器
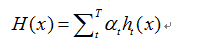
3、算法伪代码:

AdaBoost算法每一轮都要判断当前基学习器是否满足条件,一旦条件不满足,则当前学习器被抛弃,且学习过程停止。Adaboost算法使用指数损失函数,通过最小化指数损失函数,得到在每次迭代中更新的权重参数计算公式。AdaBoost算法使用串行生成的序列化方法,多个基学习器之间存在强依赖关系。Adaboost的每一个弱分类器的目标,都是为了最小化损失函数,下一个弱分类器是在上一个分类器的基础上对错分样本进行修正,所以, AdaBoost算法是注重减小偏差的算法。
Adaboost提供的是一种框架,可使用任何分类器作为基学习器,适用很多分类场景,通常可以获得不错的分类效果,例如,基于Adaboost的人脸检测算法。
二、GBDT
1、GBDT介绍
GBDT在竞赛和工业中都经常使用,能有效的应用于分类,回归,排序问题,通常能有不错的效果,是一种应用非常广泛的算法。GBDT是梯度提升算法,也是采用加法模型。GBDT以CART回归树作为基学习器,通过迭代,每次通过拟合负梯度来构建新的CART回归树,通过构建多颗CART树来降低模型的偏差,实现更好的分类性能。GBDT的核心思想是在每次创建新的CART回归树时,通过拟合当前模型损失函数的负梯度,来最小化损失函数。GBDT用于分类和回归时都使用CART回归树,分类时使用指数损失或对数损失,回归时使用平方误差损失函数,绝对值损失函数,Huber损失函数等。当GBDT使用平方误差作为损失函数时,负梯度正好是残差。
GBDT用CART回归树为基分类器,在每次构建新树时,将样本在当前模型的残差作为样本标签来训练下一颗树,经过多次迭代提升模型的分类性能。决策树和GBDT虽然结果相同,但是决策树容易过拟合,泛化能力差,可能在当前训练集上表现较好,在其他数据集上效果较差,而GBDT是结合了多颗树模型,具有较好的泛化能力。
2、GBDT回归算法
GBDT算法过程就是创建多颗CART回归树的过程,只是在创建下一颗树的时候拟合当前模型的负梯度,就是将样本在当前模型的负梯度作为标签,去构建下一颗树。GBDT用于分类时也使用CART回归树,输出类别值,不能直接拟合负梯度,这里只介绍GBDT回归算法。
输入:训练集D={(x1,y1),(x2,y2),……,(xm,ym)},最大迭代次数T,损失函数L
输出:强学习器f(X)
1) 初始化弱学习器

2) 对迭代次数t=1,2,……,T有:
a.对样本i=1,2,……,m,计算负梯度
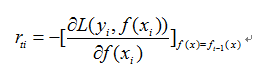
b.利用(xi,rti),拟合一颗CART回归树,得到第t可回归树,其对应的叶子节点区域为Rtj,J=1,2,……,J。其中J表示回归树t的叶子节点的个数。
c.对叶子区域j=1,2,……,J,计算最佳拟合值
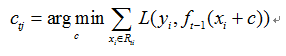
d.更新强学习器
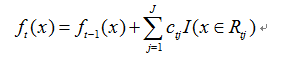
3) 得到强学习器表达式
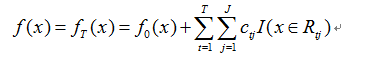
3、GBDT算法负梯度拟合
GBDT是加法模型,当前模型可表示为
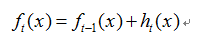
其中,是第m颗树。
当前损失函数为
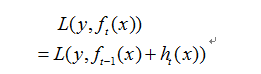
泰勒一阶展开公式为:
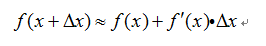
对当前损失函数泰勒一阶展开
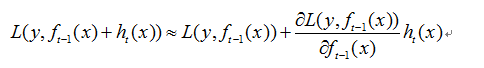
梯度下降公式

其中,表示损失函数,是关于参数的式子
在梯度方向损失函数减少最快,最小化损失函数,用梯度下降法求解参数
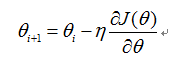
同理,最小化损失函数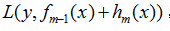 ,用梯度下降法求解,则
,用梯度下降法求解,则

故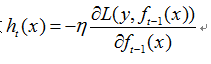
所以GBDT算法每次迭代创建新的CART树ht(x),实质上是在拟合损失函数的负梯度,利用梯度下降算法在函数空间求解。当GBDT使用均方误差作为损失函数时,此时的负梯度正好是残差。
GBDT的优点:
(1)可用于所有回归问题(包括线性和非线性问题)
(2)可构造组合特征,通常用GBDT构造的组合特征加上原来的特征一起输入LR模型做分类
(3)可得到特征的重要权重值
GBDT的正则化有三种方式:
(1)子采样
(2)步长
(3)CART树剪枝
4、CART回归树
CART假设决策树是二叉树,递归地二分每个特征,将输入空间划分为有限个单元,并在这些单元上确定预测的概率分别,也就是在输入给定的条件下输出的条件概率分布。
CART算法由两步组成:
(1)决策树生成
(2)决策树剪枝
CART回归树的建树过程和其他决策树一样,同样是寻找最优划分特征和最优切分点。
CART回归树用平方误差最小化划分节点

当输入空间的划分确定时,用平方误差来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优输出值。所以,单元Rm上的cm的最优值是Rm上的所有输入实例xi对应的输出yi的均值,在一个划分单元Rm上的样本的取值相同。
故单元Rm的值cm是
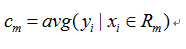
回归树生成过程:
(1)寻找最优切分变量和最优切分点,遍历所有特征j的所有划分点s,求解
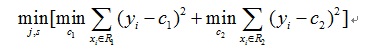
c1、c2是左右两个节点上的实例的y的平均值。
(2)用选定的(j,s)对划分区域并计算相应的输出值:
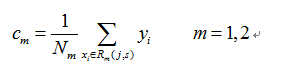
(3)继续对两个子区域调用步骤(1),(2),直至满足停止条件。
(4)将输入空间划分为M个区域R1,R2,……,RM,生成决策树:

")
ES6-前世今生(0)
1、ECMAScript是什么? 和 JavaScript 有着怎样的关系?
1996 年 11 月,Netscape 创造了javascript并将其提交给了标准化组织 ECMA,次年,ECMA 发布 262 号标准文件(ECMA-262)的第一版,规定了浏览器脚本语言的标准,并将这种语言称为 ECMAScript,这个版本就是 1.0 版。
ECMAScript更新了6个版本,最新正式版 ES6(ECMAScript 6)是 JavaScript 语言的下一代标准,早已在 2015 年 6 月正式发布。要问两者之间的关系,可以用 ECMAScript 是 JavaScript 语言的国际标准,JavaScript 是 ECMAScript 的实现这句话来形容。
说的通俗易懂点:如果说设计图是标准,盖好的房子是实现,那么 ECMAScript就是设计图,JavaScript是盖好的房子。
2、历史进化过程

感悟:长路漫漫,吾将上下而求索!
3、ES6兼容性分析
3.1 横向对比
(1)桌面端浏览器对ES2015的支持情况
- Chrome:51 版起便可以支持 97% 的 ES6 新特性。
- Firefox:53 版起便可以支持 97% 的 ES6 新特性。
- Safari:10 版起便可以支持 99% 的 ES6 新特性。
- IE:Edge 15可以支持 96% 的 ES6 新特性。Edge 14 可以支持 93% 的 ES6 新特性。(IE7~11 基本不支持 ES6)
(2)移动端浏览器对ES2015的支持情况
- iOS:10.0 版起便可以支持 99% 的 ES6 新特性。
- Android:基本不支持 ES6 新特性(5.1 仅支持 25%)
(3)服务器对ES2015的支持情况
- Node.js:6.5 版起便可以支持 97% 的 ES6 新特性。(6.0 支持 92%)
3.2 纵向对比

引用地址 https://caniuse.com/#search=es6

引用地址 https://caniuse.com/#search=es5
结论:现在的Chrome浏览器对ES6的支持已经做的相当棒了,但是有些低版本的浏览器还是不支持ES6的语法,例如IE8及其以下,说的就是你,不用再怀疑。
4、为什么学习ES6?

如果把前端开发比作成伐木头,那么ES3是斧头,ES5是钢锯,而ES6则是电锯,随着前端项目日趋复杂和移动端越来越主流,Vue、React、Angular等技术栈的大行其道,ES6 成为前端开发人员必须掌握的基本技能。掌握了ES6 不仅仅能够更加便捷的开发、大幅度的提高工作效率,更能够为学习Vue、React、Angular等技术栈甚至是NodeJS打下坚实的基础。
说的这么666,那么……
4.1 使用ES6编程,到底好在哪里?
例一:
在ES5中,我们不得不使用以下方法来表示多行字符串:
var str =''<div id="ul1">''+
''<li>青年问禅师:</li>''+
''<li>“大师终日答疑解惑、普渡众生,如何不为俗物所扰,静心修行?”</li>''+
''<li>禅师微微一笑:“我每天晚上睡觉前都关机!”</li>''+
''</div>'';
然而在ES6中,仅仅用反引号就可以解决了:
var str = `<div id="ul1">
<li>青年问禅师:</li>
<li>“大师终日答疑解惑、普渡众生,如何不为俗物所扰,静心修行?”</li>
<li>禅师微微一笑:“我每天晚上睡觉前都关机!”</li>
</div>`;
例二:
在ES5中实现对象拷贝效果:
var createAssigner = function(keysFunc, undefinedOnly) {
return function(obj) {
var length = arguments.length;
if (length < 2 || obj == null) return obj;
for (var index = 1; index < length; index++) {
var source = arguments[index],
keys = keysFunc(source),
l = keys.length;
for (var i = 0; i < l; i++) {
var key = keys[i];
if (!undefinedOnly || obj[key] === void 0) obj[key] = source[key];
}
}
return obj;
};
};
var allKeys = function(obj){
var keys = [];
for(var key in obj) keys.push(key);
return keys;
}
var extend = createAssigner(allKeys);
extend({a:111},{b:222});
在ES6中实现对象拷贝效果:
Object.assign({a:111},{b:222});
同样实现一个对象拷贝效果,用ES5写需要20多行代码,但是用ES6写,只需要 1 行代码!!!
当然,ES6还有很多强大的新特性等着我们去学习,ES6引入的新特性是ES5无法比拟的!
4.2 ES6的新功能简介
ES6过渡版本,ES4激进被废掉,ES5遗留很多问题,而ES6 兼容性还好,代码简洁,易用。
(1)块级作用域绑定
1 let声明
2 const声明Constant Declarations
3 循环中的块级绑定
4 循环中的函数
(2)函数的新增特性
1 带默认参数的函数
2 默认参数对 arguments 对象的影响
3 默认参数表达式 Default Parameter Expressions
4 未命名参数问题
5 函数中的扩展运算符
(3)全新的函数箭头函数
1 箭头函数语法
2 使用箭头函数实现函数自执行
3 箭头函数中无this绑定No this Binding
4 无arguments绑定
(4)对象功能的扩展
1 对象类别
2 对象字面量的语法扩展
2.1 简写的属性初始化
2.2 简写的方法声明
2.3 在字面量中动态计算属性名
3 新增的方法
3.1 Objectis
3.2 Object assign
(5)字符串功能的增强
1 查找子字符串
2 repeat方法
3 字符串模板字面量
3.1 基本语法
3.2 多行字符串
3.3 字符串置换
3.4 模板标签
3.4.1 什么是模板标签
3.4.2 定义模板标签
(6)解构
1 解构的实用性
2 对象解构
2.1 对象解构的基本形式
2.2 解构赋值表达式
2.3 对象解构时的默认值
2.4 赋值给不同的变量名
3 数组解构
3.1 数组解构基本语法
3.2 解构表达式
(7)新的基本类型Symbol
1 创建Symbol
2 识别Symbol
3 Symbol作为属性名
4 Symbol属性名的遍历
5 Symbolfor字符串和SymbolkeyForsymbol类型的值
(8)Set数据结构
1 创建Set和并添加元素
2 Set中不能添加重复元素
3 使用数组初始化Set
4 判断一个值是否在Set中
5 移除Set中的元素
6 遍历Set
7 将Set转换为数组
(9)Map数据结构
1 创建Map对象和Map的基本的存取操作
2 Map与Set类似的3个方法
3 初始化Map
4 Map的forEach方法
(10)迭代器和forof循环
1 循环问题
2 什么是迭代器
3 生成器函数
4 生成器函数表达式
5 可迭代类型和for-of迭代循环
6 访问可迭代类型的默认迭代器
7 自定义可迭代类型
(11)类
1 ES5之前的模拟的类
2 ES6中基本的类声明
2 匿名类表达式
3 具名类表达式
4 作为一等公民的类型
5 动态计算类成员的命名
6 静态成员
7 ES6中的继承
7.1 继承的基本写法
7.2 在子类中屏蔽父类的方法
7.3 静态方法也可以继承
使用ES6之后,可以节约很多开发时间,用来。。。
5、 如何使用ES6的新特性,又能保证浏览器的兼容?

针对 ES6 的兼容性问题,很多团队为此开发出了多种语法解析转换工具,把我们写的 ES6 语法转换成 ES5,相当于在 ES6 和浏览器之间做了一个翻译官。比较通用的工具方案有 babel,jsx,traceur,es6-shim 等。下一节,我们将具体讲解该部分的知识。
6、总结
通过本节,我们了解了ECMAScript的发展进化史,以及ES6的一些新特性。
随着JavaScript应用领域越来越广, 以及ES6 优雅的编程风格和模式、强大的功能,越来越多的程序正在使用ES6更好地实现。

是不是对学习ES6充满了动力?OK,下节课开始,我们就讲讲如何搭建ES6的开发环境搭建,进行ES6开发。
今天关于Boosting算法的前世今生和下篇的介绍到此结束,谢谢您的阅读,有关Angular 的前世今生、async & await 的前世今生(Updated)、Boosting算法之Adaboost和GBDT、ES6-前世今生(0)等更多相关知识的信息可以在本站进行查询。
本文标签:




